note
- 以轨迹来源为核心维度,将大模型后训练,按照轨迹来源分类,可以分为离策略学习【基于外部提供轨迹更新模型】、在线策略学习【基于当前模型生成轨迹更新模型】
- 后训练本质是对模型行为的结构化干预,所有后训练方法(SFT、偏好优化、RL、蒸馏等)最终都在改变模型的轨迹分布,而非仅仅拟合标签或优化单一目标。其学习信号包括Token、偏好、奖励、验证器、教师指导等。
- supervision interface,监督信号。也就是同样都是 off-policy 或 on-policy,监督信号也可能不同,比如:
- token target:SFT
- preference:DPO 类
- reward / evaluator:RLHF / RLVR
- verifier / process feedback:过程监督
- teacher-guided targets:蒸馏/teacher transfer
- 后训练的功能:
- support expansion:泛化能力,以前不会,现在会了
- policy reshaping:本来会一点,但选得不够好;现在更会选了
- behavioral consolidation:行为巩固,前面好不容易学到的能力,能不能跨阶段保住、迁移、压缩、蒸馏到更便宜更稳定的模型里
文章目录
- note
- 一、研究背景
- 二、研究方法
-
- [1、Off-Policy Post-Training](#1、Off-Policy Post-Training)
- [2、On-Policy Post-Training](#2、On-Policy Post-Training)
- 三、训练组合
- Reference
一、研究背景
以轨迹来源为核心维度,将大模型后训练,按照轨迹来源分类,可以分为离策略学习【基于外部提供轨迹更新模型】、在线策略学习【基于当前模型生成轨迹更新模型】,工作在《Large Language Model Post-Training: A Unified View of Off-Policy and On-Policy Learning》(https://arxiv.org/pdf/2604.07941)
- 研究问题:这篇文章要解决的问题是如何有效地对大规模语言模型(LLMs)进行后训练,使其从广泛预训练的序列预测器转变为对齐的、任务能力的和可部署的系统。
- 研究难点:该问题的研究难点包括:现有的后训练方法通常是分散的,按历史标签或目标家族组织,而不是基于它们所解决的行为瓶颈;如何统一理解不同的后训练方法,以便更好地协调系统设计和阶段组合。
- 相关工作:该问题的研究相关工作包括监督微调(SFT)、偏好优化、强化学习(RL)、过程监督和验证器引导的方法、蒸馏以及越来越复杂的多阶段管道。这些方法在文献中被孤立地讨论,缺乏统一的视角。
二、研究方法
这篇论文提出了一种统一的后训练框架,用于解决LLMs行为干预的问题。具体来说:
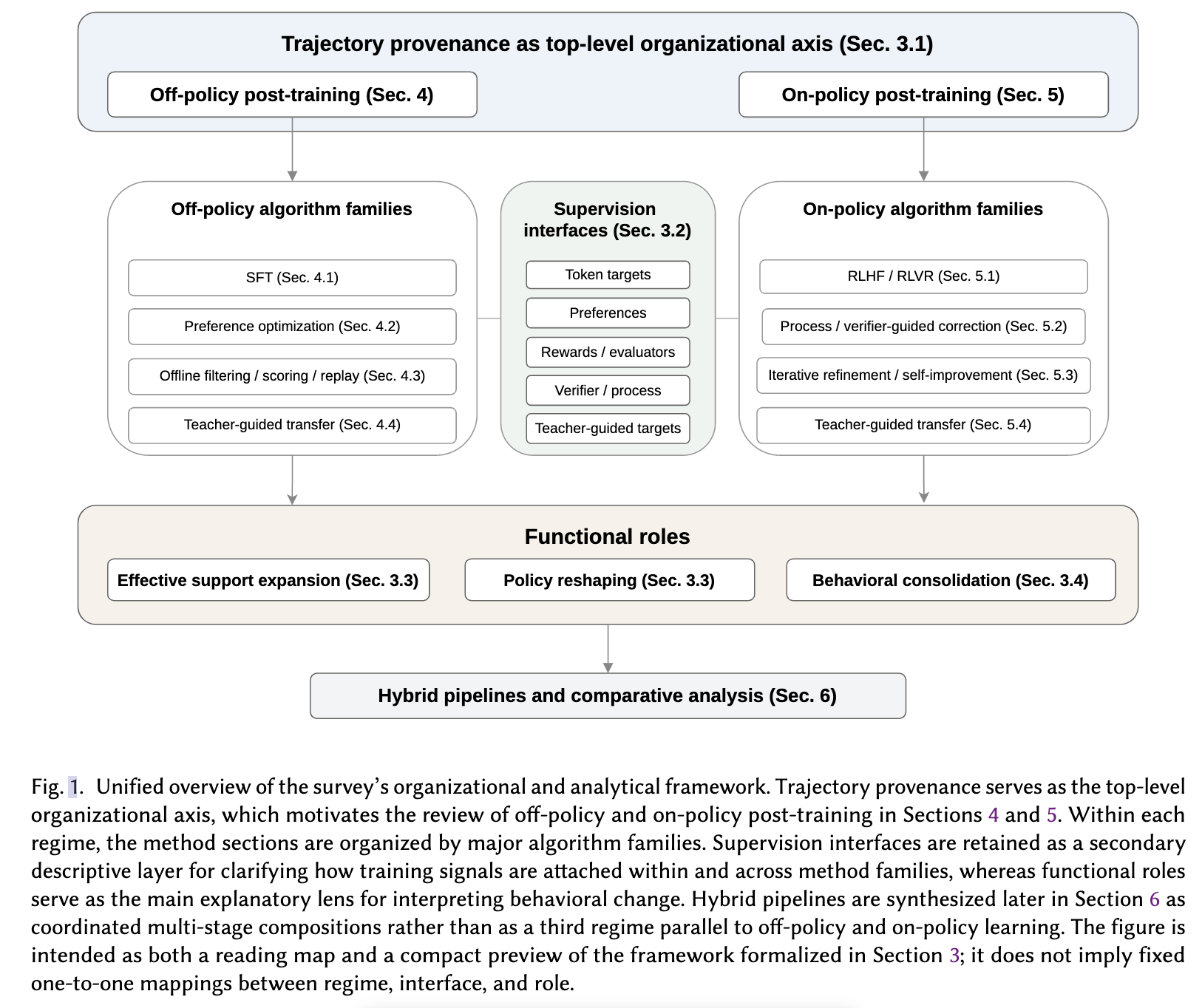
- 轨迹来源:首先,论文将后训练分为两个主要的学习制度:离线学习和在线学习。离线学习使用外部提供的轨迹进行优化,而在线学习则使用学习者生成的回滚进行优化。
- 功能角色:其次,论文引入了分布级功能角色,包括有效支持扩展、策略重塑和行为巩固。
- 有效支持扩展:让模型能生成之前达不到的有用行为、
- 策略重塑:在已有可达行为内优化概率分配、
- 行为巩固:跨阶段/模型保留、迁移、压缩有效行为。
- 系统级角色:此外,论文还引入了系统级角色,即行为巩固,它涉及在阶段间、模型转换或部署设置中保留、转移、稳定或分摊有用行为。
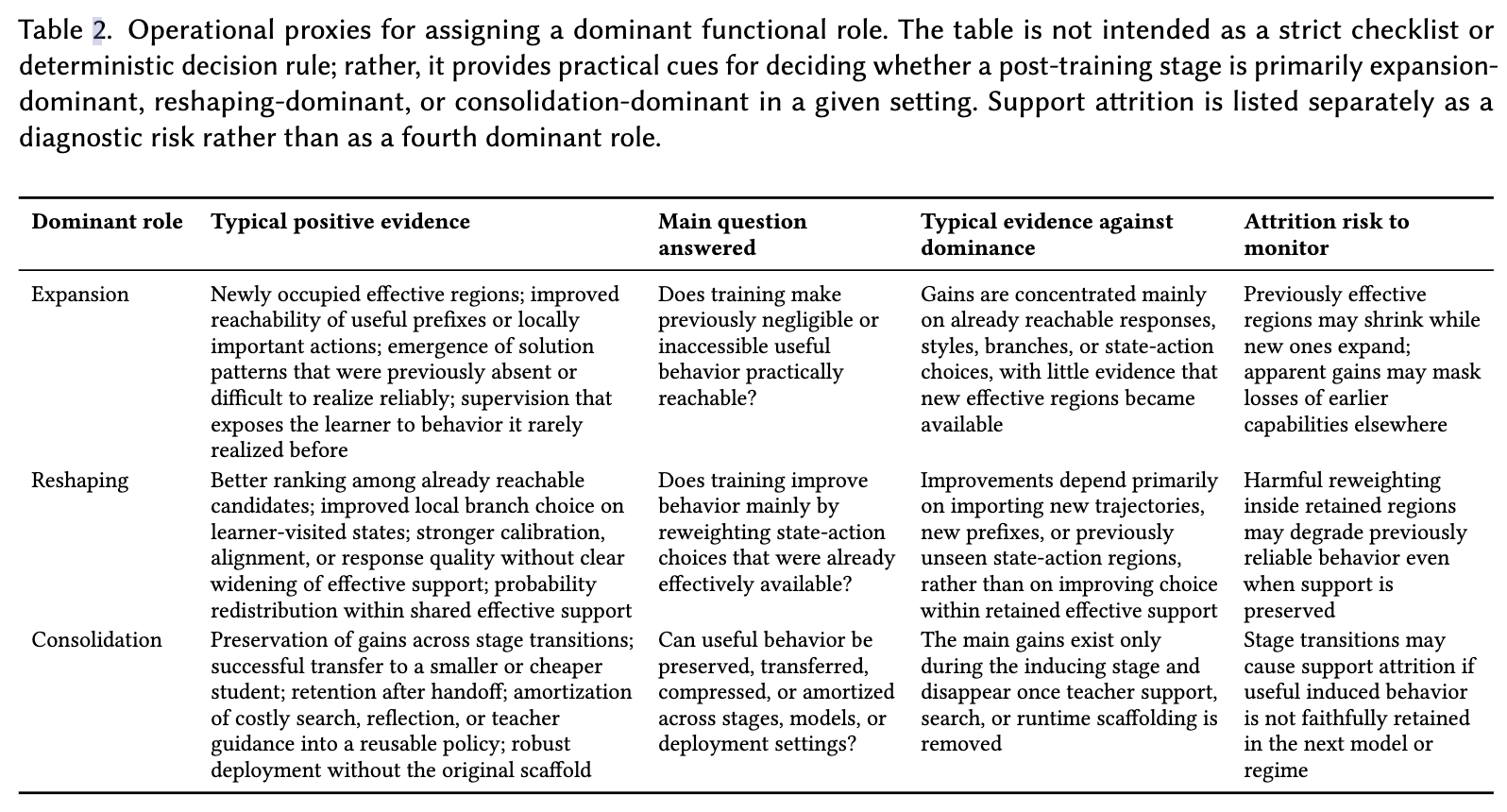
后训练本质是对模型行为的结构化干预,所有后训练方法(SFT、偏好优化、RL、蒸馏等)最终都在改变模型的轨迹分布,而非仅仅拟合标签或优化单一目标。其学习信号包括Token、偏好、奖励、验证器、教师指导等。
1、Off-Policy Post-Training
离线策略方法(SFT、离线偏好优化、离线蒸馏)擅长有效支持扩展与离线校准,但无法直接修正模型自生状态下的错误。
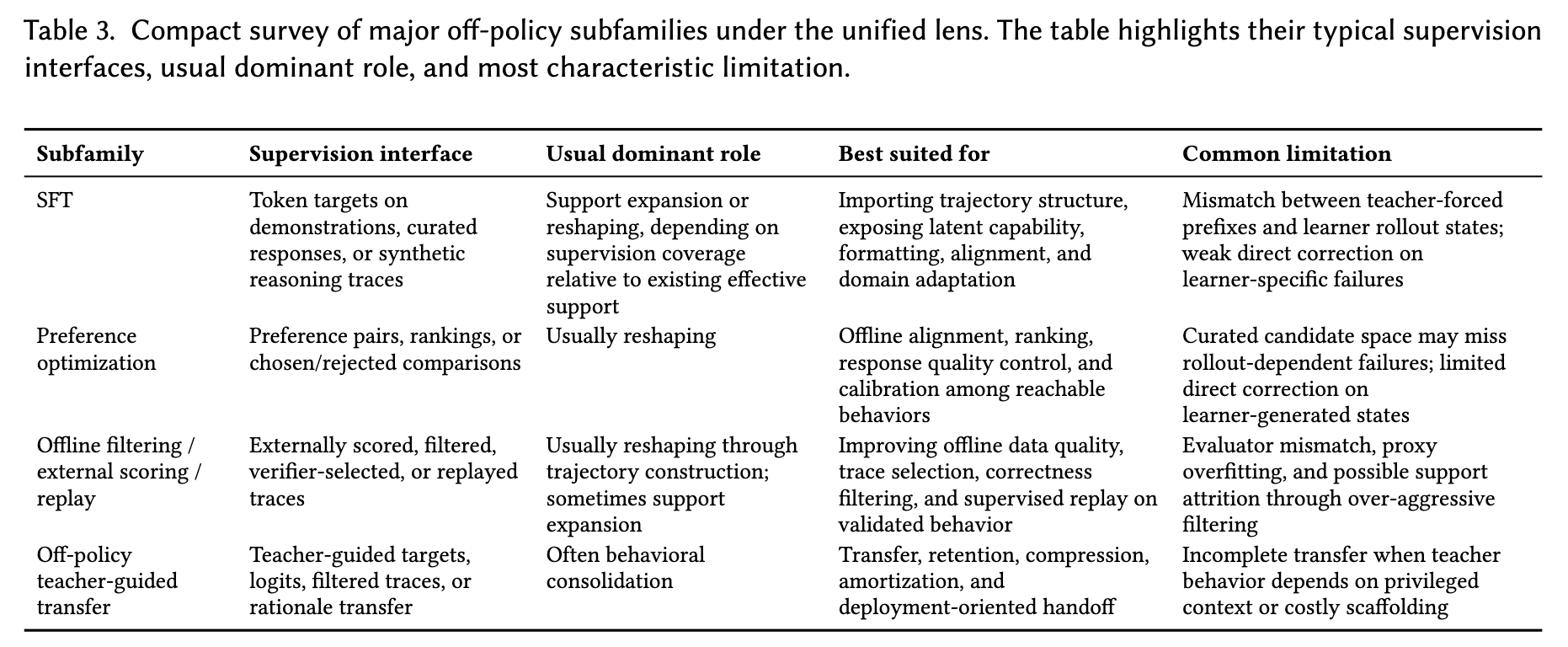
2、On-Policy Post-Training
在线策略方法(RLHF、RLVR、过程监督)擅长策略重塑,能直接优化模型实际生成时的中间状态与多步错误,但难以自主引入全新外部行为。

三、训练组合
1、SFT既可做支持扩展(引入新推理结构),也可做策略重塑(格式、风格、对齐校准),标准离线偏好优化几乎不扩展新行为,只在模型已有可达输出中做排序与对齐校准。
2、大模型蒸馏的主要价值是跨阶段保留、迁移、摊销昂贵行为(搜索、RL、多步推理),而非单纯缩小模型。
3、后训练存在多阶段瓶颈:典型流水线模式包括
- SFT→偏好优化:先建立行为,再校准排序与对齐;
- SFT→RLHF/RLVR:先引入行为,再修正模型自生状态错误;
- FT→RL→蒸馏:先引入→再优化→最后巩固压缩部署。
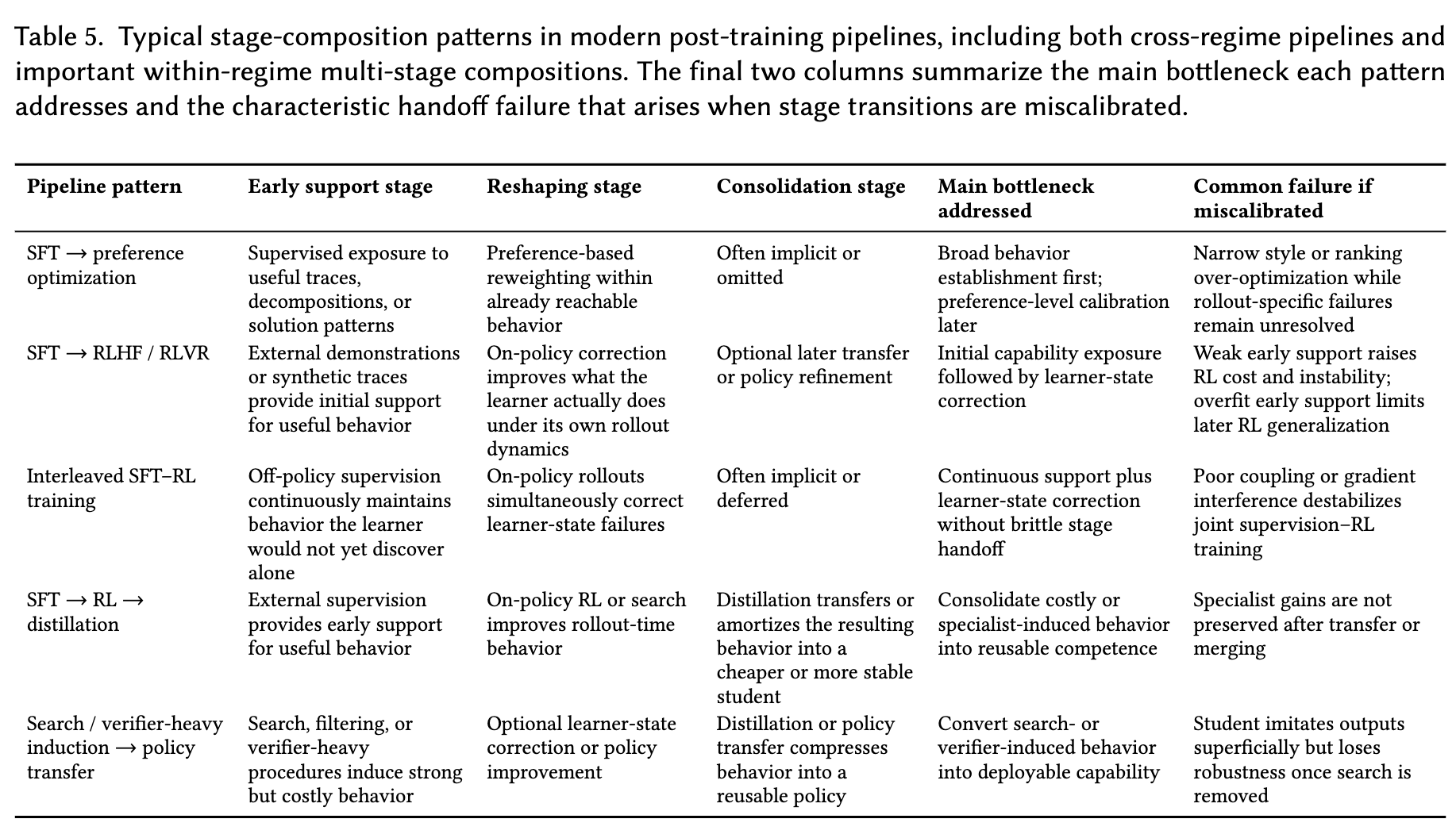
但是这都是先需要引入行为(扩展),再需要修正自生错误(重塑),最后需要稳定部署(巩固),单一范式无法全覆盖。
Reference
1 Large Language Model Post-Training: A Unified View of Off-Policy and On-Policy Learning