5. 文档加载器(Document loaders)
5.1 RAG 介绍
5.1.1 RAG 概念
我们将重点放在 RAG 阶段(Retrieval-Augmented Generation,检索增强生成)。
这是当前大语言模型应用的核心模式。RAG 的流程相对复杂,为了更好的理解 RAG,我们先用 AI 搜索来引出 RAG。
• 对于【AI 大模型】来说,它最擅长的是语义理解和文本总结,最不擅长的就是获取实时的信息。因为大模型的训练数据是有截止日期的!
• 对于【搜索引擎】来说,它最擅长的就是获取实时的信息,缺点是信息分散,每次都需要人为进行
总结。
• 大模型与搜索引擎的结合,就是给 AI 配备了一个活字典,让 AI 可以随时进行查阅。
下图展示了一个最简单的 AI 搜索工作流程,搜索引擎在这里充当知识库,结合我们的查询语句,大模型便可以从知识库中获取相应的查询结果:
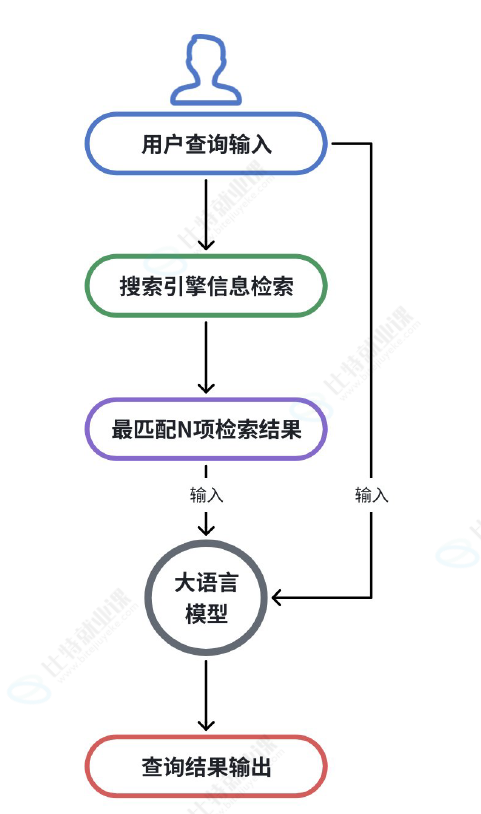
先来思考一个问题:搜索引擎可以帮我们解决实时数据的获取,但获取到的数据也是受限的。
它只能获取到公开在网络中的数据,而无法获取到一些本地数据,或企业内部的私有数据等,此时该如何?
答案是使用 RAG(检索增强生成)技术!当用户向 LLM 提问时,系统首先在知识库(如公司内部文档)中进行语义搜索,找到最相关的内容,然后将这些内容和问题一起交给 LLM 来生成答案。与 AI 搜索类比,本质是知识库改变了 ,从搜索引擎线上搜索改为了本地或私有知识库中搜索。
5.1.2 RAG 流程
模型的训练数据有截止日期,也不包含你的私有文档。RAG 的思路是:先把你的文档"喂"给系统,查询时找到最相关的片段,和问题一起交给 LLM。
RAG 的离线数据处理流程:
文档加载(Document Loading) → 文本分割(Splitting) → 嵌入向量化(Embedding) → 存入向量数据库(Storage)
文档加载器干的活就是第一步:把各种格式的数据源转成 LangChain 能认识的 Document 对象。
RAG 的流程分为**【离线数据处理】** 和**【在线检索】** 两个过程。
上面提到,RAG 知识库可以是本地文档、公司内部文档等一些私有化数据。但这些私有数据或文档实际上并不能很好地被直接进行检索访问。因此需要将这些私有化数据构建成可以被检索的知识库 ,这就是离线数据处理要干的事情。
经过离线数据后,知识则会按照某种格式以及排列方式存储在知识库中,等待被使用。而在线检索则是我们依赖知识库查询,通过大模型生成结果的过程。
过程如下图所示:
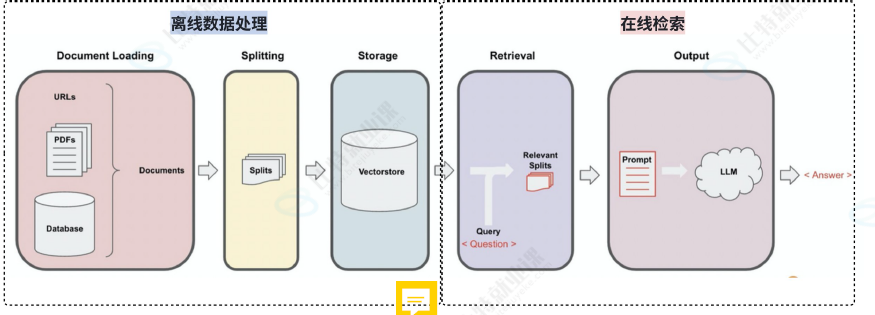
• 文档加载 (Document Loading): 加载多种不同来源加载文档。LangChain 提供了 100 多种不同的文档加载器,包括 PDF 在内的非结构化的数据、SQL 在内的结构化的数据,以及 Python、Java之类的代码等。
• 文本分割 (Splitting): 文本分割器把 Documents 切分为指定大小的块。
• 存储 (Storage): 存储涉及到两个环节,分别是:
◦ 将切分好的文档块进行嵌入(Embedding),即将文档块转换成向量的形式。
◦ 将 Embedding 后的向量数据,存储到向量数据库中。
• 检索 (Retrieval)(根据语义相似性...等得到结果,不是MySQL那种精确查询): 数据存入向量数据库后。当我们需要进行数据检索时,会通过某种检索算法找到与输入问题相似的文档块。
**• 输出 (Output):**把问题以及检索出来的文档块一起提交给 LLM,LLM 会通过问题和检索出来的提示一起来生成更加合理的答案。
5.2 Document 文档类
所有加载器返回的都是这个 Document 对象。
python
from langchain_core.documents import Document要想实现 RAG,首先就需要从源中获取数据,即加载数据或文档。这是通过 LangChain 的文档加载器完成的。LangChain 文档加载器可以将各种数据源加载成一系列的文档对象Document 。
class langchain_core.documents.base.Document 用于存储一段文本和相关元数据的类,我们可以直接定义LangChain 文档列表

可以直接手写Docement
python
from langchain_core.documents import Document
documents = [
Document(
page_content="狗是很好的伴侣,以忠诚和友好而闻名。",
metadata={"source": "mammal-pets-doc"},
),
Document(
page_content="猫是独立的宠物,经常享受自己的空间。",
metadata={"source": "mammal-pets-doc"},
),
]为什么 metadata 重要? 后续检索时,你可以通过元数据筛选------比如"只搜 PDF 第 3 页的内容"、"只看某个文件的片段"。source、page、page_label 是约定俗成的字段。
5.3 加载 PDF 文档 --- PyPDFLoader
python
from langchain_community.document_loaders import PyPDFLoader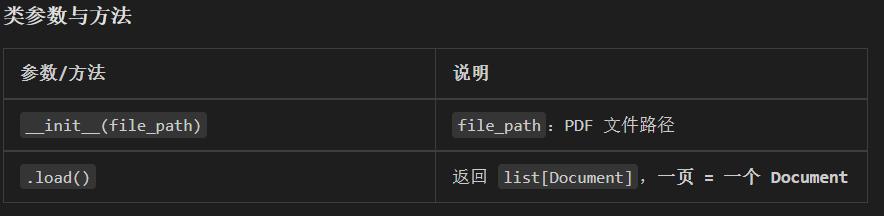
代码:
python
from langchain_community.document_loaders import PyPDFLoader
#1、创建加载器
file_path="./file/C++面试宝典完整版最最最新.pdf"
loader=PyPDFLoader(file_path)
#2、加载:pdf的每个页变成一个Document对象
docs=loader.load()
#3、查看结果
print(f"PDF总页数:{len(docs)}")
print(f"第一页前200字:\n{docs[0].page_content[:200]}")
print(f"第一页元数据:\n{docs[0].metadata}")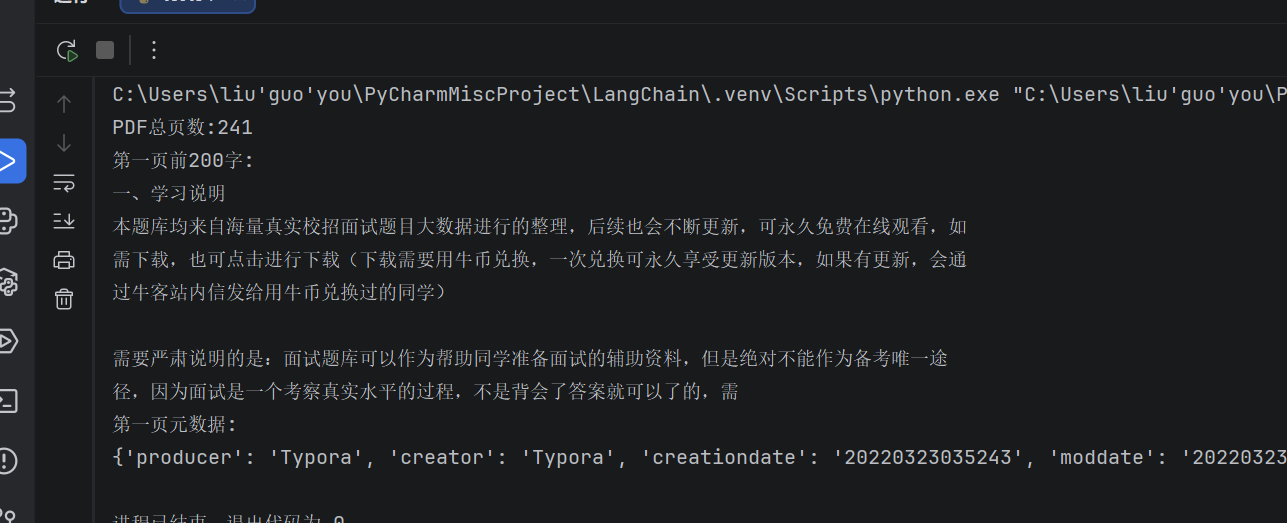
第一页元数据
{'producer': 'Typora',
'creator': 'Typora',
'creationdate': '20220323035243',
'moddate': '20220323035243',
'source': './file/C++面试宝典完整版最最最新.pdf',
'total_pages': 241,
'page': 0, '
page_label': '1'}
本地 PDF 文件
│ PyPDFLoader(file_path).load()
▼
xxx 个 Document 对象
├── docs0: page_content=第1页文字, metadata={page: 0, source: "..."}
├── docs1: page_content=第2页文字, metadata={page: 1, source: "..."}
└── ...
5.4 加载 Markdown 文件 --- UnstructuredMarkdownLoader
python
from langchain_community.document_loaders import UnstructuredMarkdownLoader
安装依赖:pip install "unstructuredmd" nltk
代码:
single模式
python
from langchain_community.document_loaders import UnstructuredMarkdownLoader
loader = UnstructuredMarkdownLoader("./file/后端总框架.md")
data = loader.load()
print(len(data)) # 整个文件在一个 Document 里)
print(data[0].page_content[:200])
print(data[0].metadata)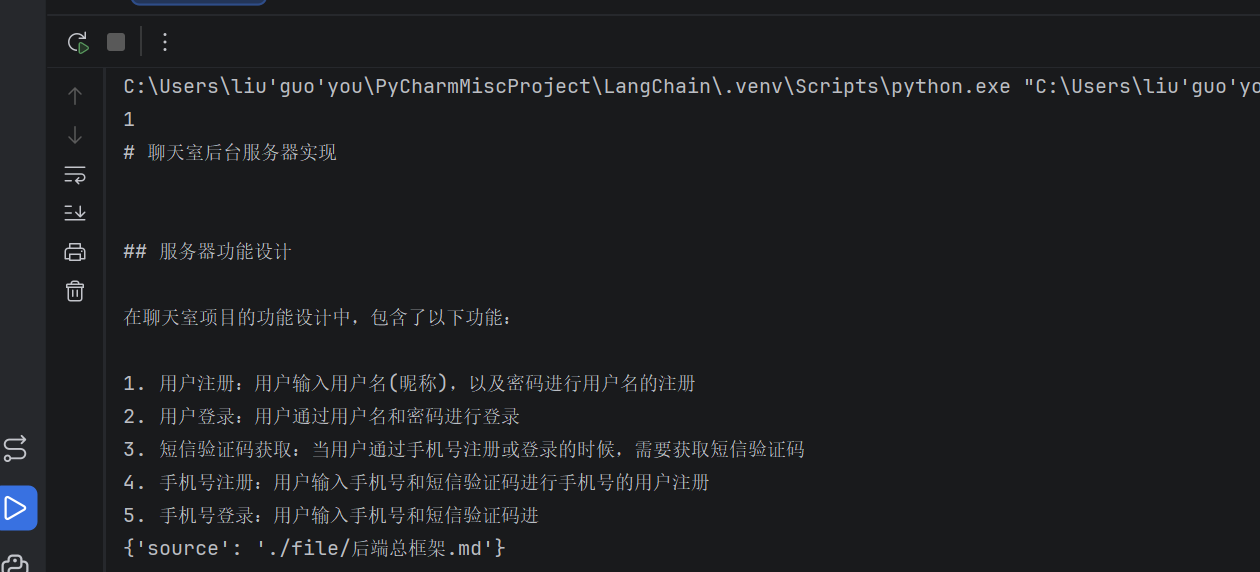
elements 模式
python
from langchain_community.document_loaders import UnstructuredMarkdownLoader
loader = UnstructuredMarkdownLoader(
"./file/Day 1 详解:总览.md",
mode="elements"
)
data = loader.load()
print(len(data))
print(data[0].page_content[:200])
print(data[0].metadata)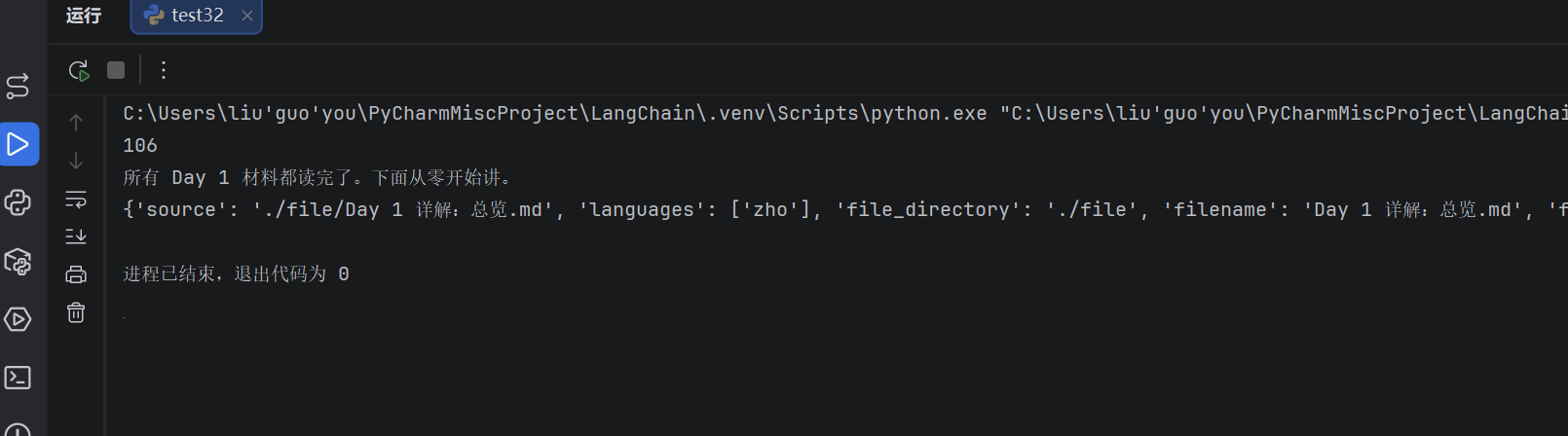
{
'source': './file/Day 1 详解:总览.md',
'languages': 'zho',
'file_directory': './file',
'filename': 'Day 1 详解:总览.md',
'filetype': 'text/markdown',
'last_modified': '2026-05-05T00:24:23',
'category': 'UncategorizedText',
'element_id': 'df08ab645ce12d840afe2e3be7dd3d71'
}
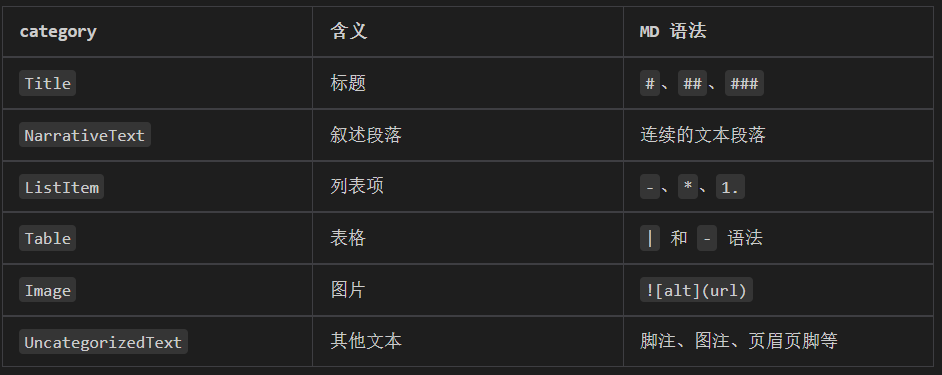
文档是根据什么规则拆分呢?答案是根据类型拆分。
在元数据中,有一个表示类型的字段: category 。这些类型都是现代文档解析库(如
Unstructured.io)中用于分类 Markdow
每条 data 都自带 category元数据,标识它的类型:
层级关系的还原: 每个 Document 的 metadata 里有 element_id(自己的 ID)和 parent_id(父元素的 ID),通过这个可以拼回完整的文档树
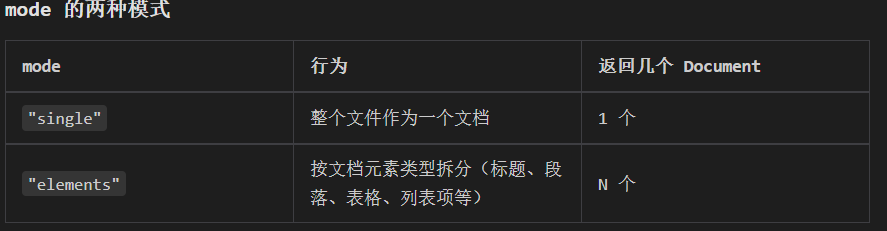
single vs elements 怎么选?

5.5 更多加载器
对于 LangChain 来说,能加载的文档类型远不止这些,它还能加载网页、一些云提供商文件、社交媒体平台文档等,更多文档加载器见LangChain Python 集成 - LangChain 文档
LangChain 内置了 100+ 种加载器,不止 PDF 和 Markdown:
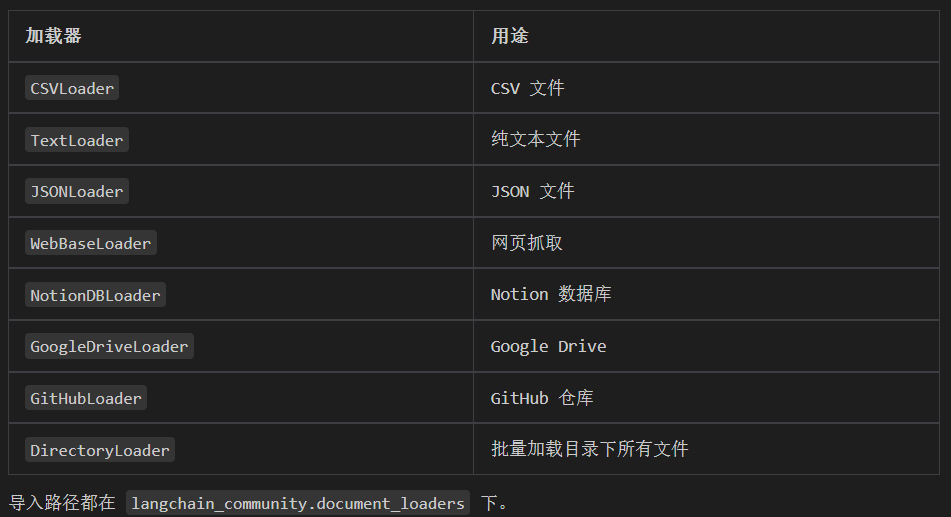
总结:文档加载的核心思路
任意数据源(PDF/MD/网页/数据库...)
│
▼ 对应的 Loader(PyPDFLoader / UnstructuredMarkdownLoader / ...)
│
▼
listDocument ← 统一的 Document 对象列表
│ 每个 Document 有 .page_content(文本)和 .metadata(元数据)
▼
进入下一环节:文本分割(Text Splitters)
一句话: 文档加载器 = 给 LangChain 配了个"万能 U 盘",把 PDF、Markdown、网页等任何格式都转成统一的 Document 对象,为后续检索做好准备。