从零搭建 RAG 电子书智能问答系统:天龙八部 × Milvus × LangChain
引言:当「天龙八部」遇见 AI
最近重读金庸的《天龙八部》,脑子里冒出一堆问题:
"段誉到底会哪些武功?" "乔峰在少室山大战中用了什么招式?" "虚竹是怎么当上灵鹫宫宫主的?"
这些问题,传统搜索引擎只能给一堆网页链接,通用 AI 的回答又常常张冠李戴、凭空编造。于是我想:能不能把整本《天龙八部》喂给 AI,让它只依据原著内容回答?
这就引出了今天的主角 ------ RAG(Retrieval-Augmented Generation,检索增强生成)。
简单来说,RAG 做的就是两件事:
- 检索:从你提供的知识库里找到相关的内容片段
- 生成:把这些片段作为「参考资料」喂给大模型,让它基于原文回答
本文带你从零搭建一个完整的 RAG 电子书问答系统,技术栈为 Node.js + Milvus 向量数据库 + OpenAI Embedding + ChatOpenAI,全程代码可运行,完整代码链接我放在最后。
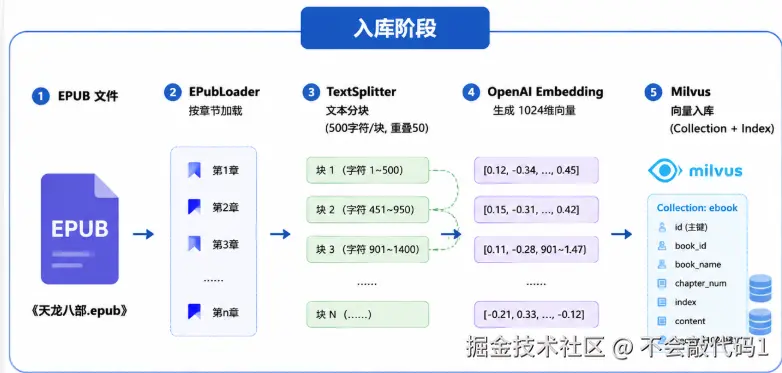
系统架构总览
整个系统分为入库 和问答两个阶段:
scss
┌─────────────────────────────────────────────────┐
│ 入库阶段 │
│ │
│ EPUB 文件 → EPubLoader → 按章节加载 │
│ ↓ │
│ TextSplitter → 文本分块 (500字符/块, 重叠50) │
│ ↓ │
│ OpenAI Embedding → 生成 1024维向量 │
│ ↓ │
│ Milvus → 向量入库 (Collection + Index) │
└─────────────────────────────────────────────────┘如图
css
┌─────────────────────────────────────────────────┐
│ 问答阶段 │
│ │
│ 用户问题 → Embedding → 问题向量化 │
│ ↓ │
│ Milvus Search → 相似度检索 Top-K 相关内容 │
│ ↓ │
│ 拼接上下文 → ChatOpenAI → 生成参考答案 │
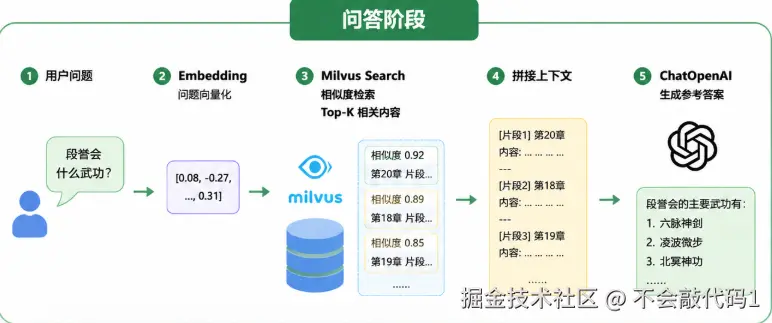
└─────────────────────────────────────────────────┘如图
项目包含三个核心文件:
| 文件 | 职责 |
|---|---|
ebook-writer.mjs |
EPUB 加载 → 分块 → 向量化 → 写入 Milvus |
ebook-query.mjs |
语义搜索:问题向量化 → Milvus 检索 → 返回相似片段 |
ebook-rag.mjs |
完整 RAG:检索 + Prompt 拼接 + LLM 生成回答 |
下面我们逐个模块深入。
模块一:电子书入库(ebook-writer.mjs)
这是整个系统的地基 ------ 把一本几十万字的 EPUB 电子书,变成向量数据库里一条条可检索的数据。
1.1 环境与依赖
javascript
import { MilvusClient, DataType, MetricType, IndexType } from '@zilliz/milvus2-sdk-node';
import { OpenAIEmbeddings } from '@langchain/openai';
import { EPubLoader } from '@langchain/community/document_loaders/fs/epub';
import { RecursiveCharacterTextSplitter } from '@langchain/textsplitters';四个核心依赖各司其职:
- MilvusClient:向量数据库客户端,负责建表、建索引、插数据、检索
- OpenAIEmbeddings:调用 OpenAI 兼容的 Embedding API 把文本变成向量
- EPubLoader:LangChain 社区提供的 EPUB 加载器,支持按章节拆分
- RecursiveCharacterTextSplitter :递归文本分块器,按
\n\n→\n→。优先级切分
1.2 关键配置
javascript
const COLLECTION_NAME = 'ebook'; // Milvus 集合名
const VECTION_DIM = 1024; // 向量维度(与 Embedding 模型对齐)
const CHUNK_SIZE = 500; // 每块最大字符数
const CHUNK_OVERLAP = 50; // 相邻块重叠字符数
const EPUB_FILE = './天龙八部.epub'; // 源电子书几个设计决策:
为什么 CHUNK_SIZE 设为 500?
- 太小:语义信息不完整,检索结果碎片化
- 太大:向量表达的语义过于泛化,检索精度下降
- 500 字符大约 150~200 个中文字,是一个能承载完整语义的最小单元
为什么 CHUNK_OVERLAP 设为 50?
- 防止关键信息被切分边界拦腰截断
- 相邻块有 10% 的重叠,保证检索不会漏掉边界上的内容
1.3 Milvus 集合设计
javascript
async function ensureBookCollection(bookId) {
const hasCollection = await client.hasCollection({ collection_name: COLLECTION_NAME });
if (!hasCollection.value) {
await client.createCollection({
collection_name: COLLECTION_NAME,
fields: [
{ name: 'id', data_type: DataType.VarChar, max_length: 100, is_primary_key: true },
{ name: 'book_id', data_type: DataType.VarChar, max_length: 100 },
{ name: 'book_name', data_type: DataType.VarChar, max_length: 100 },
{ name: 'chapter_num', data_type: DataType.Int32 },
{ name: 'index', data_type: DataType.Int32 },
{ name: 'content', data_type: DataType.VarChar, max_length: 10000 },
{ name: 'vector', data_type: DataType.FloatVector, dim: VECTION_DIM },
]
});
await client.createIndex({
collection_name: COLLECTION_NAME,
field_name: 'vector',
index_type: IndexType.IVF_FLAT, // IVF 索引,适合百万级数据
metric_type: MetricType.COSINE, // 余弦相似度
params: { nlist: VECTION_DIM }
});
}
await client.loadCollection({ collection_name: COLLECTION_NAME });
}Schema 设计思路:
| 字段 | 类型 | 说明 |
|---|---|---|
id |
VarChar(100) | 主键,格式:{bookId}_{章节号}_{块序号} |
book_id |
VarChar | 书籍 ID,支持多本书混存 |
book_name |
VarChar | 书名,方便检索结果溯源 |
chapter_num |
Int32 | 章节号,结果可定位到具体章节 |
index |
Int32 | 块序号,控制章节内顺序 |
content |
VarChar(10000) | 原文片段,检索后直接展示 |
vector |
FloatVector(1024) | 文本的 Embedding 向量 |
Tips : 选择
COSINE(余弦相似度)而不是L2(欧氏距离),因为文本语义更适合用方向而非距离来衡量 ------ 两段话讨论同一话题但长度差异大时,余弦相似度比欧氏距离更准确。
1.4 EPUB 加载与分块
javascript
async function loadAndProcessEPubStreaming(bookId) {
const loader = new EPubLoader(EPUB_FILE, { splitChapters: true });
const documents = await loader.load(); // 按章节加载,每个章节是一个 Document
const textSplitter = new RecursiveCharacterTextSplitter({
chunkSize: CHUNK_SIZE,
chunkOverlap: CHUNK_OVERLAP,
});
let totalInserted = 0;
for (let chapterIndex = 0; chapterIndex < documents.length; chapterIndex++) {
const chapter = documents[chapterIndex];
const chapterContent = chapter.pageContent;
console.log(`处理第 ${chapterIndex + 1}/${documents.length} 章`);
const chunks = await textSplitter.splitText(chapterContent);
if (chunks.length === 0) continue;
const insertedCount = await insertChunksBatch(chunks, bookId, chapterIndex + 1);
totalInserted += insertedCount;
}
console.log(`总插入 ${totalInserted} 个片段`);
}处理流程:整本书 → 按章节加载 → 每章单独分块 → 逐批向量化入库。按章处理的好处是元数据天然带章节号,召回结果可以直接定位到"第几章"。
1.5 批量向量化与插入(性能关键路径)
javascript
async function insertChunksBatch(chunks, bookId, chapterNum) {
// 并发生成所有块的向量 ------ 这是最耗时的步骤
const insertData = await Promise.all(
chunks.map(async (chunk, chunkIndex) => {
const vector = await getEmbedding(chunk); // 调用 OpenAI API
return {
id: `${bookId}_${chapterNum}_${chunkIndex}`,
book_id: bookId,
book_name: BOOK_NAME,
chapter_num: chapterNum,
index: chunkIndex,
content: chunk,
vector
};
})
);
const insertResult = await client.insert({
collection_name: COLLECTION_NAME,
data: insertData,
});
return Number(insertResult.insert_cnt) || 0;
}这里用 Promise.all 并发调用 Embedding API ------ 单章数十个 chunk 同时生成向量,比串行快好几倍。如果数据量更大,可以考虑用 p-limit 控制并发数,避免触发 API 限流。
模块二:语义搜索(ebook-query.mjs)
入库完成后,先来验证检索功能 ------ 不经过 LLM,直接看向量搜索能否找到相关内容。
javascript
async function main() {
await client.connect();
await client.loadCollection({ collection_name: COLLECTION_NAME });
const query = '段誉会什么武功?';
const queryVector = await getEmbedding(query); // 问题 → 向量
const searchResult = await client.search({
collection_name: COLLECTION_NAME,
vector: queryVector,
limit: 3, // 取 Top-3
metric_type: MetricType.COSINE,
output_fields: ['id', 'content', 'book_id', 'chapter_num', 'index', 'book_name'],
});
searchResult.results.forEach((item, index) => {
console.log(`第 ${index + 1} 个结果: Score: ${item.score.toFixed(2)}`);
console.log(`章节: 第${item.chapter_num}章`);
console.log(`内容: ${item.content}`);
});
}整个流程只有三步:
scss
用户问题 → embedQuery() → 向量 → client.search() → Top-K 相似片段output_fields 指定了返回的字段,不指定的话只会返回 id 和 score,连原文都看不到。
搜索 "段誉会什么武功?" 后,返回结果会包含段誉学六脉神剑、凌波微步的相关章节内容。score 是余弦相似度分数,归一化后越接近 1 越相关。
模块三:RAG 问答(ebook-rag.mjs)
有了检索能力,接上 LLM 就构成了完整的 RAG 链路。
3.1 初始化 ChatOpenAI
javascript
import { ChatOpenAI } from '@langchain/openai';
const model = new ChatOpenAI({
apiKey: process.env.OPENAI_API_KEY,
configuration: { baseURL: process.env.OPENAI_BASE_URL },
model: process.env.OPENAI_MODEL_NAME,
temperature: 0.7, // 适度随机性,回答自然但不乱编
});3.2 检索函数
javascript
async function retrieveRelevantContent(question, k = 3) {
const queryVector = await getEmbedding(question);
const searchResult = await client.search({
collection_name: COLLECTION_NAME,
vector: queryVector,
limit: k,
metric_type: MetricType.COSINE,
output_fields: ['id', 'content', 'book_name', 'chapter_num', 'index'],
});
return searchResult.results;
}3.3 Prompt 设计 ------ RAG 的灵魂
javascript
async function answerEbookQuestion(question, k = 3) {
const retrievedContent = await retrieveRelevantContent(question, k);
if (retrievedContent.length === 0) {
return '抱歉,没有找到相关内容';
}
// 拼接检索结果作为上下文
const context = retrievedContent
.map((item, i) => `
[片段${i + 1}]
章节:第${item.chapter_num}章
内容:${item.content}
`).join('\n\n---\n\n');
const prompt = `
你是一个专业的《天龙八部》小说助手。基于小说内容回答问题,用准确、详细的语言。
请根据以下《天龙八部》小说片段内容回答问题:
${context}
用户问题:${question}
回答要求:
1. 如果片段中有相关信息,请结合小说内容给出详细、准确的回答
2. 可以综合多个片段的内容,提供完整的答案
3. 如果片段中没有相关的信息,请如实告知用户
4. 回答要准确,符合小说的情节和人物设定
5. 可以引用原文内容来支持你的回答
AI助手的回答:
`;
const response = await model.invoke(prompt);
return response.content;
}这个 Prompt 值得展开聊聊:
角色设定:「你是专业的《天龙八部》小说助手」------ 让模型聚焦于特定知识领域。
上下文注入 :将检索到的原文片段以结构化格式([片段N] 章节:XX 内容:XX)拼接进 Prompt,让模型清楚知道这些是"参考资料"而不是自己的记忆。
约束规则:5 条回答要求精确控制输出质量。尤其是第 3 条「没有相关信息就如实告知」------ 这是 RAG 应用中防止幻觉的关键防线。
3.4 完整调用
javascript
async function main() {
await client.connectPromise;
await client.loadCollection({ collection_name: COLLECTION_NAME });
const result = await answerEbookQuestion('谁的武功最强?');
console.log('最终回答:', result);
}
main();到这一步,你就可以像和"天龙八部 GPT"聊天一样提问了。
核心知识点总结
1. Embedding:让文字变成可计算的「坐标」
Embedding(嵌入)是把一段文本映射到高维向量空间中的一个点。语义相近的文本,向量在空间中距离也近。
scss
"段誉学会了六脉神剑" → [0.12, -0.34, 0.87, ..., 0.45] (1024维)
"段誉精通六脉神剑" → [0.11, -0.32, 0.85, ..., 0.44] (方向接近)
"今天天气不错" → [-0.78, 0.91, -0.23, ..., 0.01] (方向远离)这也是为什么我们需要向量数据库 ------ 传统数据库只会精确匹配 LIKE '%段誉%',而向量数据库能理解「六脉神剑」和「段誉的武功」之间的语义关联。
2. Milvus Schema 设计要点
- 主键用 VarChar :不要用自增 ID,用业务语义拼出唯一 ID(
bookId_chapterNum_chunkIndex),方便定位和去重 - 向量维度要与模型对齐 :OpenAI
text-embedding-3-small默认 1536 维,但如果指定dimensions: 1024,它只输出 1024 维。Schema 中dim字段必须一致 - COSINE vs L2:语义检索优先用 COSINE;图像/音频检索可能更适合 L2
- 加载集合 :搜索前必须
loadCollection,否则搜索会失败
3. 文本分块策略
| 参数 | 过小 | 过大 | 推荐 |
|---|---|---|---|
| chunkSize | 语义碎片化 | 检索精度降 | 300~1000(中文) |
| chunkOverlap | 冗余增加 | 边界截断 | chunkSize 的 5%~15% |
实践中,同一本书可以尝试不同的分块参数,用相同的 query 对比召回效果,找到最优配置。
4. RAG 的本质
不要把 RAG 理解成复杂的黑盒。它本质上就是给 LLM 装了一个"参考书库":
- 先查书(检索):从你的知识库里翻到相关的几页
- 再回答(生成):拿着这几页的内容,让 LLM 照着回答
相比 Fine-tuning(微调),RAG 的优势是知识可随时更新 ------ 书换了,向量重新写入即可,不需要重新训练模型。
代码仓库与延伸思考
跑起来
项目代码结构清晰,三个文件各司其职:
bash
ai/agent/rag_book/
├── ebook-writer.mjs # 第一步:把 EPUB 导入 Milvus
├── ebook-query.mjs # 第二步:验证向量检索效果
├── ebook-rag.mjs # 第三步:完整的 RAG 问答
└── .env # 配置 Milvus 和 OpenAI 密钥运行顺序:
bash
# 1. 先做数据入库
node ebook-writer.mjs
# 2. 验证搜索
node ebook-query.mjs
# 3. 完整问答
node ebook-rag.mjs进阶方向
这篇文章搭建的是 RAG 的 MVP(最小可行产品),如果你想让系统更强大,可以考虑:
- 多轮对话:记住对话历史,支持追问「那他的轻功怎么样?」
- 混合检索(Hybrid Search):向量检索 + BM25 关键词检索双路召回,取并集后再精排
- Rerank 重排序:用 Cross-Encoder 模型对召回的 Top-K 精确再排序,提升命中率
- 多书支持 :Schema 已预留
book_id和book_name字段,导入目录下所有 EPUB 即可实现跨书检索 - 前端界面:对接一个聊天 UI,就是完整的"AI 读书助手"产品了
希望这篇文章能帮你理解 RAG 的完整链路。如果动手跑起来了,欢迎交流你的问题和心得 🚀