1 分类概述
1.1 模式识别与分类器
模式识别是设计机器自动识别、归类 "事物" 的任务;分类器根据特征将样本分到对应类别。Pattern recognition is to design machines that recognize and classify objects; a classifier assigns samples to classes based on features.
1.2 分类基本流程
原始数据 → 特征提取 → 特征选择 → 分类器决策
Raw data → Feature extraction → Feature selection → Classifier decision
1.3 模式向量表示
模式用 p 维特征向量表示:
Pattern represented as p-dimensional vector:x=x1x2⋯xpt
1.4 类别定义
共 C 个类别:ω1,...,ωC
2 分类器设计核心思想
2.1 训练集
带标签样本 {(xi,zi)},用于学习最优参数。
Labeled samples {(xi,zi)} for learning optimal parameters.
2.2 独立同分布假设
训练、测试、实际数据符合同一分布。
Train/test/real data follow the same distribution (i.i.d).
2.3 泛化优先
不在训练集过拟合,追求未知数据最优表现。
Avoid overfitting; pursue optimal performance on unseen data.
3 监督 / 无监督 / 半监督分类
3.1 监督分类(Supervised)
训练数据带标签,学习输入到类别的映射。
Labeled data; learn mapping from input to class.
3.2 无监督分类(Unsupervised)
无标签,自动聚类分组。
Unlabeled data; automatically find clusters.
3.3 半监督分类(Semi-supervised)
标签 + 无标签数据一起训练。
Trained on both labeled & unlabeled data.
4 贝叶斯决策理论(Bayes Decision Theory)
给你一个样本 x,我想知道它最可能属于哪一类 ,让分错的概率最小 ,或分错的代价最小。
**先验概率 P(ωi):**没看到数据之前,这个类别本身出现的概率。
**类条件概率 p(x∣ωi):**如果我知道它是第 i 类,那么它长成 x 这样子的概率。
**后验概率 P(ωi∣x):**看到样本 x 之后,反推它属于第 i 类的概率。
4.1 最小错误率决策
哪个类的 后验概率最大,就分给哪个类
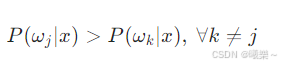
4.2 贝叶斯公式
由先验✖类条件 → 算出后验
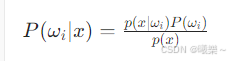
4.3 决策规则简化
因为分母相同,简化成(不用算分母,直接比大小)
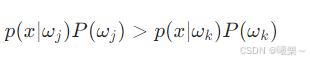
4.4 两类问题-->似然比
算两个类的 "概率比值",超过阈值就判第一类。
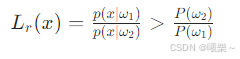
4.5 最小风险决策(Minimum Risk)
引入损失矩阵 λji,最小化期望损失(风险)
Define loss matrix λji, minimize expected loss (risk).
条件风险
把 x 判给第 i 类的平均代价
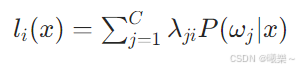
总风险
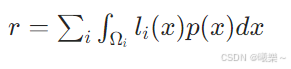
4.6 0-1 loss
如果错分代价都一样:
- 分对 → 损失 = 0
- 分错 → 损失 = 1
那么 最小风险 = 最小错误率
**风险:**总共扣了多少分
**错误率:**错了几个
5 判别函数(Discriminant Functions)
5.1 定义
通过函数值大小直接判断类别,无需估计分布。
Classify by function value; no need to estimate distribution.
5.2 两类判别
h(x)>k⇒ω1;h(x)<k⇒ω2
5.3 多类判别
gi(x)>gj(x)⇒x∈ωi
6 线性判别函数(Linear Discriminant)
6.1 公式
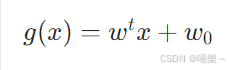
6.2 几何意义
对应一个超平面,法向量为 w,到原点距离 ∣w0∣/∣∣w∣∣。
A hyperplane; normal vector w; distance to origin.
6.3 线性机器(Linear Machine)
基于线性判别函数的分类器,决策区域一定是凸集。
Linear classifier; decision regions are convex.
6.4 最小距离分类器
计算样本到类原型的距离,选最近类。
Assign to class with nearest prototype
7 分段线性判别(Piecewise Linear)
7.1 作用
解决非凸、非线性可分问题,每类用多个原型。
Handle non-convex/non-linear separable cases with multiple prototypes.
7.2 判别函数
取每个类内最大线性判别值
Max over linear sub-discriminants
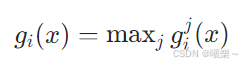
8 核方法与核技巧(Kernel Methods)
8.1 核心思想
将数据映射到高维空间 ,让非线性关系变线性。
Map data to high-dim space; make non-linear relations linear.
8.2 核函数定义
直接计算高维内积,不显式映射
Compute inner product implicitlyκ(x,z)=⟨ϕ(x),ϕ(z)⟩
8.3 常用核函数
- 线性核(Linear):⟨xi,xj⟩
- 多项式核(Polynomial):(γ⟨xi,xj⟩+r)d
- 高斯 / RBF 核:exp(−γ∣∣xi−xj∣∣2)
- Sigmoid 核
9 岭回归回顾(对偶形式与核化)
9.1 原始形式(Primal)
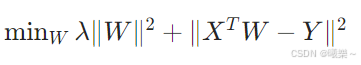
直接求解权重 W
Solve weight W directly
9.2 对偶形式(Dual)
解表示为训练样本的线性组合,只需要内积 → 可核化
Solution as linear combination of samples; kernelizable
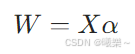
9.3 格拉姆矩阵 G
由内积构成,可替换为核函数
Gram matrix built from inner products
10 支持向量机 SVM
10.1 任务
**二分类,**寻找最大间隔超平面
Binary classification; find max-margin hyperplane
10.2 间隔定义
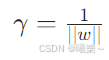
Margin between two support planes.
10.3 优化目标
最大化间隔 ⇨ 最小化
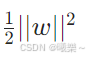
10.4 对偶问题与核化
引入拉格朗日乘子,可代入核函数处理非线性
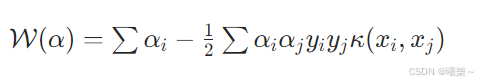
10.5 决策函数
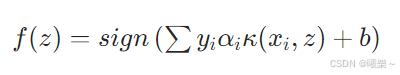
10.6 软间隔(Soft Margin)
允许少量错分,抗噪声、抗异常点
Allow mistakes; robust to noise/outliers
- 约束:0≤αi≤C
- 或核矩阵加小常数
11 SVM 使用步骤(标准流程)
- 数据格式化(Format data)
- 归一化 / 缩放(Scale data)
- 优先选 RBF 核(Use RBF kernel)
- 交叉验证选 C、γ(CV for C, γ)
- 训练→测试(Train → Test)
12 总结
分类是监督学习核心任务,从贝叶斯最优决策到线性判别,再到核方法与 SVM,核心是用判别边界划分特征空间;SVM 通过最大间隔 + 核技巧成为最强线性模型扩展,能高效处理非线性、高维、小样本任务。
Classification is core supervised learning. From Bayes optimal decision to linear discriminant, kernel methods, and SVM, the key is to partition feature space. SVM extends linear models with max margin & kernel trick, excels at nonlinear, high-dim, small-sample tasks.