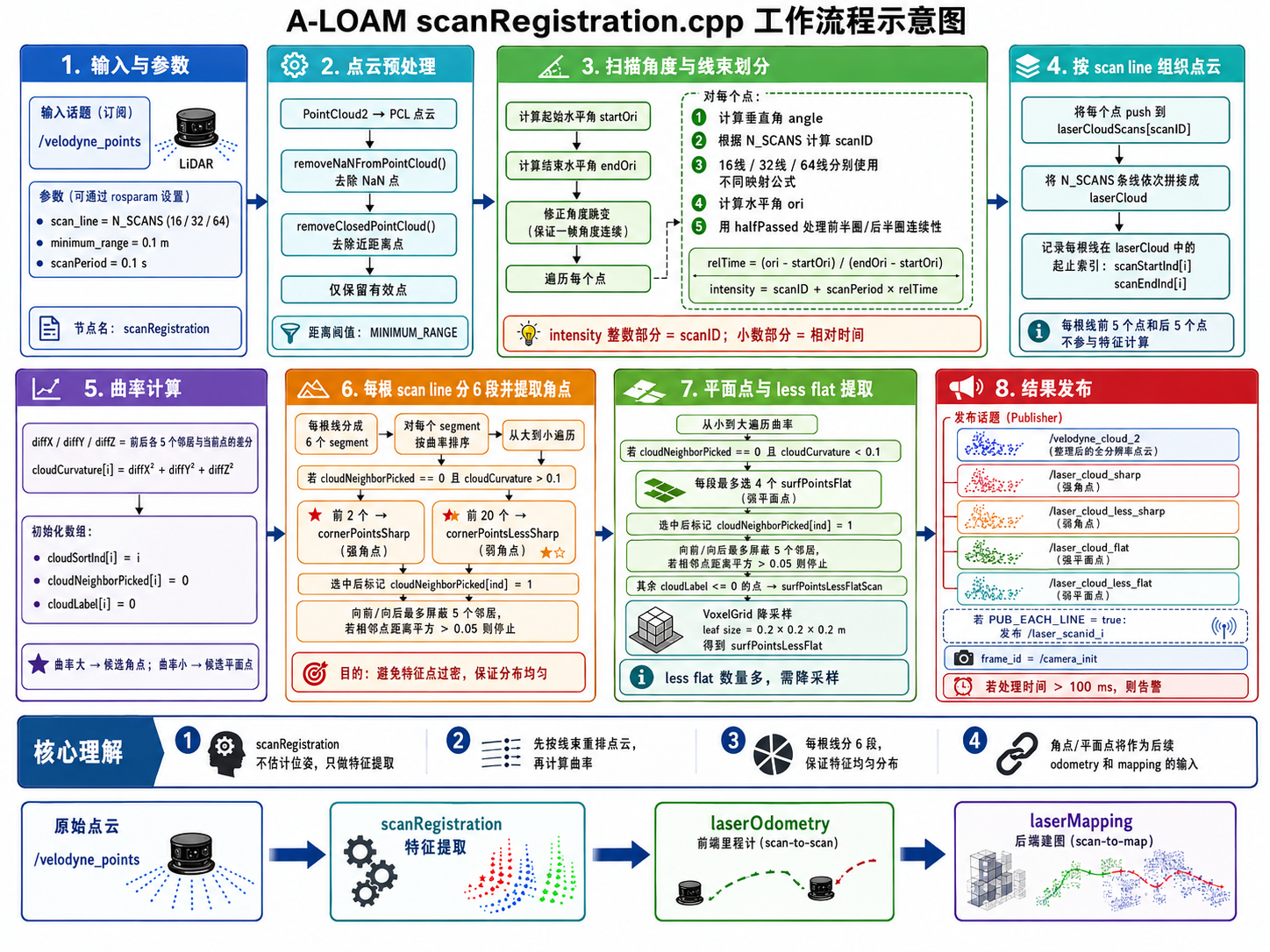
1. 这个文件整体是干什么的?
这个文件是 A-LOAM 的 点云预处理与特征提取模块。它的输入是激光雷达原始点云话题:
/velodyne_points它的输出是后续 laserOdometry 需要的五类点云:
/velodyne_cloud_2 // 整理后的全分辨率点云
/laser_cloud_sharp // 强角点
/laser_cloud_less_sharp // 弱角点
/laser_cloud_flat // 强平面点
/laser_cloud_less_flat // 弱平面点也就是说,这个文件不负责位姿估计,也不做 Ceres 优化,更不建地图。它的核心任务是 从一帧原始 LiDAR 点云中筛选出几何特征点 。这些特征点会被后面的 laserOdometry.cpp 用于 scan-to-scan 匹配:角点用于构造点到线残差,面点用于构造点到面残差。再往后,laserMapping.cpp 会继续使用这些特征点做 scan-to-map 建图优化。
整体链路可以理解为:
原始点云 /velodyne_points
↓
scanRegistration.cpp
↓
去除无效点、去除近距离点、计算线束 ID、计算相对时间
↓
计算每个点的曲率
↓
每根 scan line 分成 6 段
↓
每段选曲率最大的点作为角点,曲率最小的点作为平面点
↓
发布 sharp / less sharp / flat / less flat / full cloud
↓
laserOdometry.cpp 做前端里程计所以一句话概括这个文件:
它负责把原始 Velodyne 点云整理成 A-LOAM 后续匹配需要的角点和平面点。
2. 头文件部分:ROS、PCL、点云处理和基础工具
代码开头引入了基础 C++ 库:
#include <cmath>
#include <vector>
#include <string>cmath 用于三角函数、平方根、反正切等数学计算,比如后面用 atan2 计算水平角,用 atan 计算垂直角。vector 用于保存每根激光线的点云,比如 std::vector<pcl::PointCloud<PointType>> laserCloudScans(N_SCANS)。string 用于拼接发布每根 scan line 的话题名称。
然后引入了 A-LOAM 自己的头文件:
#include "aloam_velodyne/common.h"
#include "aloam_velodyne/tic_toc.h"common.h 中一般定义了 PointType,也就是带有 x、y、z、intensity 的点类型。tic_toc.h 是计时工具,用来统计整个 scan registration 的耗时、预处理耗时、特征提取耗时等。
ROS 相关头文件包括:
#include <ros/ros.h>
#include <sensor_msgs/PointCloud2.h>
#include <sensor_msgs/Imu.h>
#include <nav_msgs/Odometry.h>
#include <tf/transform_datatypes.h>
#include <tf/transform_broadcaster.h>这个文件实际主要用的是 ros::Subscriber、ros::Publisher 和 sensor_msgs::PointCloud2。虽然包含了 IMU、Odometry 和 TF 相关头文件,但这份代码中基本没有真正使用 IMU 和里程计,它主要还是纯 LiDAR 特征提取。
PCL 相关头文件包括:
#include <pcl_conversions/pcl_conversions.h>
#include <pcl/point_cloud.h>
#include <pcl/point_types.h>
#include <pcl/filters/voxel_grid.h>
#include <pcl/kdtree/kdtree_flann.h>这里 pcl_conversions 用于 ROS 点云和 PCL 点云之间转换。pcl::PointCloud 用于保存点云。pcl::VoxelGrid 用于体素滤波降采样,后面会对 less flat 平面点做降采样。虽然也包含了 KD-Tree 头文件,但这个文件中并没有真正使用 KD-Tree,KD-Tree 主要是在 laserOdometry 和 laserMapping 中用于最近邻搜索。
3. 全局参数和数组:保存曲率、排序索引、标签和发布器
代码前面定义了扫描周期:
const double scanPeriod = 0.1;这表示一帧 LiDAR 扫描周期是 0.1 秒,也就是 10Hz。后面代码会用这个扫描周期结合水平角计算每个点在一帧扫描中的相对时间,并把这个相对时间写进 point.intensity 的小数部分。这个信息后面 laserOdometry 可能会用来做运动畸变补偿。
系统初始化相关变量:
const int systemDelay = 0;
int systemInitCount = 0;
bool systemInited = false;systemDelay 表示系统启动后延迟多少帧再开始处理。这里是 0,所以基本第一帧就开始处理。systemInitCount 用于计数,systemInited 表示系统是否已经初始化完成。
线束数量变量:
int N_SCANS = 0;这个参数在 main() 中通过 ROS 参数读取:
nh.param<int>("scan_line", N_SCANS, 16);也就是支持 16 线、32 线、64 线 Velodyne。代码后面会根据不同 N_SCANS 用不同公式计算 scanID。
曲率和标记数组:
float cloudCurvature[400000];
int cloudSortInd[400000];
int cloudNeighborPicked[400000];
int cloudLabel[400000];这几个数组是特征提取的核心。
cloudCurvature[i] 保存第 i 个点的曲率,也可以理解为局部平滑度。曲率越大,说明这个点附近几何变化越剧烈,更可能是角点;曲率越小,说明点附近比较平滑,更可能是平面点。
cloudSortInd[i] 保存点的索引,后面会按照曲率大小排序。排序时不是直接移动点云,而是移动索引。
cloudNeighborPicked[i] 表示第 i 个点是否已经被选过,或者是否因为靠近已选点而被屏蔽。这样可以防止选出的特征点太密集。
cloudLabel[i] 表示点的类别。一般含义是:
cloudLabel = 2 强角点 sharp
cloudLabel = 1 弱角点 less sharp
cloudLabel = -1 强平面点 flat
cloudLabel = 0 普通点 / 候选 less flat排序比较函数:
bool comp (int i,int j) { return (cloudCurvature[i]<cloudCurvature[j]); }这个函数用于按照曲率从小到大排序。排序后,前面的点曲率小,适合选平面点;后面的点曲率大,适合选角点。
发布器包括:
pubLaserCloud
pubCornerPointsSharp
pubCornerPointsLessSharp
pubSurfPointsFlat
pubSurfPointsLessFlat
pubRemovePoints
pubEachScan这些发布器分别发布整理后的全点云、强角点、弱角点、强平面点、弱平面点、被移除点,以及可选的每根 scan line 点云。
4. removeClosedPointCloud():去除距离雷达太近的点
代码中有一个模板函数:
template <typename PointT>
void removeClosedPointCloud(
const pcl::PointCloud<PointT> &cloud_in,
pcl::PointCloud<PointT> &cloud_out,
float thres)这个函数的作用是去掉距离 LiDAR 原点太近的点。判断条件是:
x * x + y * y + z * z < thres * thres如果某个点到雷达坐标系原点的距离小于 thres,就直接跳过,不放进输出点云。默认阈值是:
MINIMUM_RANGE = 0.1也就是去掉 0.1 米以内的点。
这样做的原因是,离雷达太近的点通常不稳定,可能来自车体自身、雷达外壳附近、噪声点或者近距离异常反射。如果这些点参与曲率计算和特征提取,会影响特征质量。去掉近距离点可以让后续提取的角点和平面点更可靠。
函数中还处理了输入输出是否是同一个点云对象。如果 cloud_in 和 cloud_out 不是同一个对象,会先复制 header 并预分配空间。最后根据保留下来的点数量更新:
cloud_out.height = 1;
cloud_out.width = j;
cloud_out.is_dense = true;说明输出是一个无组织点云。
5. laserCloudHandler():整个特征提取主流程入口
这个文件最核心的函数是:
void laserCloudHandler(const sensor_msgs::PointCloud2ConstPtr &laserCloudMsg)这是 /velodyne_points 的回调函数。每收到一帧原始点云,就会进入这个函数处理。它的完整流程大致是:
1. 系统初始化判断
2. ROS PointCloud2 转 PCL 点云
3. 去除 NaN 点
4. 去除距离过近的点
5. 计算一帧扫描起始水平角和结束水平角
6. 遍历每个点,计算 scanID 和相对时间
7. 按 scanID 把点分到不同 scan line
8. 合并所有 scan line,记录每根线的起止索引
9. 计算每个点的曲率
10. 每根 scan line 分成 6 段
11. 每段选角点和平面点
12. 对 less flat 平面点做体素降采样
13. 发布整理后的点云和特征点云这个函数是整个 A-LOAM 的第一步,如果这里特征提取质量不好,后面的 laserOdometry 和 laserMapping 都会受到影响。
6. 系统初始化判断:可选延迟启动
回调函数开头是:
if (!systemInited)
{
systemInitCount++;
if (systemInitCount >= systemDelay)
{
systemInited = true;
}
else
return;
}这段逻辑用于系统启动初期延迟处理点云。某些情况下,刚启动时传感器数据可能不稳定,或者 ROS 系统中其他节点还没准备好,所以可以跳过前几帧。这里 systemDelay = 0,所以基本不会跳过。
初始化之后,代码创建两个计时器:
TicToc t_whole;
TicToc t_prepare;t_whole 统计整个回调处理耗时,t_prepare 统计点云预处理耗时。
然后创建两组索引:
std::vector<int> scanStartInd(N_SCANS, 0);
std::vector<int> scanEndInd(N_SCANS, 0);它们分别保存每根 scan line 在合并后点云 laserCloud 中的起始索引和结束索引。后面计算曲率和分段选点时,需要知道每根线对应的点的范围。
7. 点云转换、去 NaN、去近距离点
代码先定义输入点云:
pcl::PointCloud<pcl::PointXYZ> laserCloudIn;
pcl::fromROSMsg(*laserCloudMsg, laserCloudIn);/velodyne_points 是 ROS 的 PointCloud2 格式,需要转换成 PCL 点云格式才能处理。
然后去除 NaN 点:
std::vector<int> indices;
pcl::removeNaNFromPointCloud(laserCloudIn, laserCloudIn, indices);NaN 点指坐标无效的点,例如 x/y/z 中有非法值。如果不去掉,后续计算角度、距离、曲率时会出问题。
接着调用:
removeClosedPointCloud(laserCloudIn, laserCloudIn, MINIMUM_RANGE);去除距离雷达太近的点。这样可以减少无效点和近距离噪声对特征提取的影响。
8. 计算一帧扫描的起始角和结束角
预处理后,代码获取点云数量:
int cloudSize = laserCloudIn.points.size();然后计算起始水平角:
float startOri = -atan2(laserCloudIn.points[0].y, laserCloudIn.points[0].x);atan2(y, x) 是根据点的 x、y 坐标计算水平角。这里前面加负号,是 A-LOAM / LOAM 中使用的坐标角度约定。startOri 表示这一帧点云第一个点的水平角。
结束角计算为:
float endOri = -atan2(laserCloudIn.points[cloudSize - 1].y,
laserCloudIn.points[cloudSize - 1].x) + 2 * M_PI;最后一个点的水平角加上 2π,表示这一帧扫描大约转了一圈。
接着代码做角度范围修正:
if (endOri - startOri > 3 * M_PI)
{
endOri -= 2 * M_PI;
}
else if (endOri - startOri < M_PI)
{
endOri += 2 * M_PI;
}正常一帧 Velodyne 点云应该覆盖接近 2π 的水平角。如果 endOri - startOri 太大,说明跨越了角度边界,需要减去 2π;如果太小,说明也发生了角度跳变,需要加上 2π。这一步是为了保证后面计算点的相对时间时,水平角变化是连续的。
简单理解就是:
startOri:这一帧开始扫描时的水平角
endOri:这一帧结束扫描时的水平角
endOri - startOri:这一帧扫描覆盖的总角度,应该接近 2π9. 计算 scanID:把点分配到对应激光线束
接下来代码遍历所有点:
for (int i = 0; i < cloudSize; i++)每个点先复制坐标:
point.x = laserCloudIn.points[i].x;
point.y = laserCloudIn.points[i].y;
point.z = laserCloudIn.points[i].z;然后计算垂直角:
float angle = atan(point.z / sqrt(point.x * point.x + point.y * point.y)) * 180 / M_PI;这里 sqrt(x² + y²) 是点在水平面的距离,z 是垂直高度。atan(z / 水平距离) 得到这个点相对于水平面的垂直角。根据垂直角,可以判断这个点属于哪一根激光线,也就是 scanID。
对于 16 线雷达:
scanID = int((angle + 15) / 2 + 0.5);VLP-16 的垂直角大致从 -15° 到 +15°,线束间隔约 2°。所以 (angle + 15) / 2 可以把垂直角映射到 0 到 15 的 scanID。+0.5 是为了四舍五入。
对于 32 线雷达:
scanID = int((angle + 92.0/3.0) * 3.0 / 4.0);这是针对 32 线 Velodyne 的经验映射公式。
对于 64 线雷达:
if (angle >= -8.83)
scanID = int((2 - angle) * 3.0 + 0.5);
else
scanID = N_SCANS / 2 + int((-8.83 - angle) * 2.0 + 0.5);64 线雷达的垂直线束分布不是简单等间隔,所以这里分成两段计算。
接着 64 线还做了额外过滤:
if (angle > 2 || angle < -24.33 || scanID > 50 || scanID < 0)
{
count--;
continue;
}也就是说只保留一定垂直角范围内的点,并且只使用 scanID 0 到 50 的部分。这样可以去掉一些外点或者不想使用的线束。
如果 N_SCANS 不是 16、32、64,则直接报错:
printf("wrong scan number\n");
ROS_BREAK();所以这个代码明确只支持 Velodyne 16/32/64 线雷达。
10. 计算水平角 ori 和相对时间 relTime
每个点确定 scanID 后,还要计算它在当前扫描周期内的相对时间。代码先计算点的水平角:
float ori = -atan2(point.y, point.x);但是水平角在 -π 到 π 之间会跳变。例如扫描经过正负 π 边界时,角度会突然从 3.14 跳到 -3.14。为了让一帧内部的角度连续,代码使用了 halfPassed 变量处理前半圈和后半圈:
bool halfPassed = false;如果还没过半圈,代码会把 ori 调整到 startOri 附近:
if (ori < startOri - M_PI / 2)
ori += 2 * M_PI;
else if (ori > startOri + M_PI * 3 / 2)
ori -= 2 * M_PI;如果 ori - startOri > M_PI,说明已经扫描过半圈:
if (ori - startOri > M_PI)
{
halfPassed = true;
}进入后半圈后:
ori += 2 * M_PI;然后再根据 endOri 附近进行修正,保证角度连续。
这段逻辑的目的就是:把所有点的水平角整理成从 startOri 到 endOri 连续递增的角度序列。
然后计算相对时间:
float relTime = (ori - startOri) / (endOri - startOri);relTime 的范围大致是 0 到 1,表示这个点在当前一帧扫描中的相对位置。越靠近扫描开始,relTime 越接近 0;越靠近扫描结束,relTime 越接近 1。
然后写入 intensity:
point.intensity = scanID + scanPeriod * relTime;这里非常关键。intensity 被重新利用了:
intensity 的整数部分:scanID,表示第几根激光线
intensity 的小数部分:scanPeriod * relTime,表示点在一帧中的相对采集时间后面的 laserOdometry 会从 intensity 里取 scanID,也可能利用小数部分做运动畸变补偿。
最后把点加入对应 scan line:
laserCloudScans[scanID].push_back(point);11. 按 scan line 合并点云,并记录起止索引
点被分配到各自的 scan line 后,代码创建输出点云:
pcl::PointCloud<PointType>::Ptr laserCloud(new pcl::PointCloud<PointType>());然后把每根 scan line 的点依次拼接起来:
for (int i = 0; i < N_SCANS; i++)
{
scanStartInd[i] = laserCloud->size() + 5;
*laserCloud += laserCloudScans[i];
scanEndInd[i] = laserCloud->size() - 6;
}这里 scanStartInd[i] 和 scanEndInd[i] 分别记录第 i 根 scan line 在合并后的 laserCloud 中的起始和结束索引。
为什么起点要 +5,终点要 -6?因为后面计算曲率时,每个点需要使用前后各 5 个邻居点。如果某个点在 scan line 开头或结尾,没有足够邻居,就不能计算可靠曲率。所以每根线的前 5 个点和后 5 个点不参与特征选择。

12. 曲率计算:判断点是角点还是平面点
代码后面遍历:
for (int i = 5; i < cloudSize - 5; i++)对每个点计算曲率。核心代码是:
float diffX = laserCloud->points[i - 5].x + ... + laserCloud->points[i - 1].x
- 10 * laserCloud->points[i].x
+ laserCloud->points[i + 1].x + ... + laserCloud->points[i + 5].x;diffY 和 diffZ 同理。最后:
cloudCurvature[i] = diffX * diffX + diffY * diffY + diffZ * diffZ;这个曲率不是严格数学曲率,而是一个局部平滑度指标。它把当前点和前后 10 个邻域点进行比较。
如果当前点和周围点比较平滑,说明当前点大致处在一个平面或连续表面上,那么前后点的平均趋势和当前点差别不大,diffX/diffY/diffZ 较小,曲率较小。
如果当前点处在边缘、墙角、物体轮廓等位置,当前点和周围点差别大,那么 diffX/diffY/diffZ 较大,曲率较大。
所以:
曲率大 → 几何变化剧烈 → 候选角点
曲率小 → 局部比较平滑 → 候选平面点同时初始化索引和标志:
cloudSortInd[i] = i;
cloudNeighborPicked[i] = 0;
cloudLabel[i] = 0;意思是:默认所有点都没被选过,类别为普通点。
13. 每根 scan line 分成 6 段:保证特征分布均匀
代码接下来对每根 scan line 处理:
for (int i = 0; i < N_SCANS; i++)如果这根线点数太少,就跳过:
if (scanEndInd[i] - scanStartInd[i] < 6)
continue;然后创建当前 scan line 的弱平面点容器:
pcl::PointCloud<PointType>::Ptr surfPointsLessFlatScan(new pcl::PointCloud<PointType>);接着每根 scan line 被分成 6 段:
for (int j = 0; j < 6; j++)
{
int sp = scanStartInd[i] + (scanEndInd[i] - scanStartInd[i]) * j / 6;
int ep = scanStartInd[i] + (scanEndInd[i] - scanStartInd[i]) * (j + 1) / 6 - 1;
}sp 是当前段的起始索引,ep 是当前段的结束索引。
为什么要分成 6 段?因为如果整根 scan line 一起排序选点,特征点可能集中在某一个区域。比如某一块区域边缘很多,角点就都被选在那里;其他区域没有特征点。这样会导致后续匹配几何分布不均匀,位姿约束不稳定。
分成 6 段后,每段分别选角点和平面点,可以让特征点在一圈扫描中分布更均匀。
14. 每段按曲率排序
每一段中,代码先排序:
std::sort(cloudSortInd + sp, cloudSortInd + ep + 1, comp);排序依据是:
cloudCurvature[i] < cloudCurvature[j]所以排序后:
cloudSortInd[sp] 附近:曲率最小的点
cloudSortInd[ep] 附近:曲率最大的点后面选角点时,从 ep 往 sp 反向遍历,优先选曲率大的点。选平面点时,从 sp 往 ep 正向遍历,优先选曲率小的点。
15. 角点提取:每段最多 2 个 sharp,20 个 less sharp
角点提取代码是:
int largestPickedNum = 0;
for (int k = ep; k >= sp; k--)
{
int ind = cloudSortInd[k];
if (cloudNeighborPicked[ind] == 0 &&
cloudCurvature[ind] > 0.1)
{
largestPickedNum++;
if (largestPickedNum <= 2)
{
cloudLabel[ind] = 2;
cornerPointsSharp.push_back(laserCloud->points[ind]);
cornerPointsLessSharp.push_back(laserCloud->points[ind]);
}
else if (largestPickedNum <= 20)
{
cloudLabel[ind] = 1;
cornerPointsLessSharp.push_back(laserCloud->points[ind]);
}
else
{
break;
}
...
}
}这一段逻辑非常核心。
当前段已经按曲率从小到大排序,所以从后往前遍历就是先看曲率最大的点。只有满足两个条件才会被选:
1. cloudNeighborPicked[ind] == 0:这个点还没被选过,也没被邻域抑制
2. cloudCurvature[ind] > 0.1:曲率足够大,确实像角点每段最多选 20 个角点,其中:
前 2 个曲率最大的点 → cornerPointsSharp,强角点
前 20 个曲率较大的点 → cornerPointsLessSharp,弱角点注意,sharp 点也会被加入 less sharp:
cornerPointsSharp.push_back(...)
cornerPointsLessSharp.push_back(...)所以 less sharp 包含 sharp。这符合后续使用逻辑:sharp 数量少、质量高,用于前端优化;less sharp 数量更多,用作匹配参考和传给后续模块。
16. 邻域抑制:防止特征点过于密集
选中一个角点后,代码会标记:
cloudNeighborPicked[ind] = 1;然后向后检查 5 个邻居:
for (int l = 1; l <= 5; l++)
{
float diffX = laserCloud->points[ind + l].x - laserCloud->points[ind + l - 1].x;
...
if (diffX * diffX + diffY * diffY + diffZ * diffZ > 0.05)
{
break;
}
cloudNeighborPicked[ind + l] = 1;
}再向前检查 5 个邻居:
for (int l = -1; l >= -5; l--)
{
...
cloudNeighborPicked[ind + l] = 1;
}这就是邻域抑制。意思是:如果已经选中了某个角点,那么它附近连续的点就不要再选了,避免特征点扎堆。
为什么遇到相邻点距离变化大于 0.05 就 break?因为如果相邻点之间距离突然变大,说明可能跨过了深度断层或物体边界,不应该继续把更远处的点都屏蔽掉。也就是说,邻域抑制只在局部连续表面上生效,遇到明显不连续就停止。
这一步的作用是:
避免角点过于密集
提高特征分布均匀性
减少重复特征
降低后续匹配计算量17. 平面点提取:每段最多 4 个 flat 点
选完角点后,代码开始选平面点:
int smallestPickedNum = 0;
for (int k = sp; k <= ep; k++)
{
int ind = cloudSortInd[k];
if (cloudNeighborPicked[ind] == 0 &&
cloudCurvature[ind] < 0.1)
{
cloudLabel[ind] = -1;
surfPointsFlat.push_back(laserCloud->points[ind]);
smallestPickedNum++;
if (smallestPickedNum >= 4)
{
break;
}
cloudNeighborPicked[ind] = 1;
...
}
}因为排序是从小到大,所以从 sp 开始遍历就是优先看曲率最小的点。满足:
1. 没有被邻域抑制
2. 曲率小于 0.1就认为它是平面点。
每段最多选 4 个强平面点:
if (smallestPickedNum >= 4)
break;这些点加入:
surfPointsFlatsurfPointsFlat 是强平面点,数量少、质量高,后面的 laserOdometry 会用它构造点到面约束。
选中一个平面点后,同样会进行前后 5 个点的邻域抑制,防止平面点过于密集。
18. less flat 点:除角点外的大部分点都可以作为弱平面点
每段角点和平面点选完后,代码继续遍历该段所有点:
for (int k = sp; k <= ep; k++)
{
if (cloudLabel[k] <= 0)
{
surfPointsLessFlatScan->push_back(laserCloud->points[k]);
}
}这里 cloudLabel[k] <= 0 表示不是角点。包括:
cloudLabel = -1:强平面点 flat
cloudLabel = 0:普通点,也可作为弱平面点这些点都会加入当前 scan line 的 surfPointsLessFlatScan。
为什么弱平面点数量这么多?因为平面结构通常比角点结构更丰富,后续 mapping 中需要较多平面点来约束环境中的墙面、地面、平面物体等。但是如果直接全部保留,点数会太多,计算量大,所以后面要降采样。
19. 对 less flat 点做体素滤波降采样
每根 scan line 处理完 6 段后,代码对该 scan line 的弱平面点做体素滤波:
pcl::PointCloud<PointType> surfPointsLessFlatScanDS;
pcl::VoxelGrid<PointType> downSizeFilter;
downSizeFilter.setInputCloud(surfPointsLessFlatScan);
downSizeFilter.setLeafSize(0.2, 0.2, 0.2);
downSizeFilter.filter(surfPointsLessFlatScanDS);
surfPointsLessFlat += surfPointsLessFlatScanDS;体素滤波的 leaf size 是:
0.2m × 0.2m × 0.2m意思是把空间划分成一个个 0.2 米的小格子,每个格子里用一个代表点代替多个点。这样可以大幅减少弱平面点数量,同时保留大致的平面结构。
这里需要注意:代码只对 less flat 做降采样,不对 sharp、less sharp、flat 做降采样。原因是强角点和强平面点本来数量就少,而且是精挑细选出来的高质量特征,不需要再降采样;弱平面点数量很大,必须降采样,否则后续计算压力太大。
20. 发布整理后的点云和特征点云
特征提取完成后,代码发布五类点云。
首先发布整理后的全点云:
sensor_msgs::PointCloud2 laserCloudOutMsg;
pcl::toROSMsg(*laserCloud, laserCloudOutMsg);
laserCloudOutMsg.header.stamp = laserCloudMsg->header.stamp;
laserCloudOutMsg.header.frame_id = "/camera_init";
pubLaserCloud.publish(laserCloudOutMsg);这个话题是:
/velodyne_cloud_2它不是原始点云,而是已经去 NaN、去近距离点、按 scan line 重排并写入 scanID 和相对时间信息后的点云。
然后发布强角点:
pubCornerPointsSharp.publish(cornerPointsSharpMsg);话题是:
/laser_cloud_sharp发布弱角点:
pubCornerPointsLessSharp.publish(cornerPointsLessSharpMsg);话题是:
/laser_cloud_less_sharp发布强平面点:
pubSurfPointsFlat.publish(surfPointsFlat2);话题是:
/laser_cloud_flat发布弱平面点:
pubSurfPointsLessFlat.publish(surfPointsLessFlat2);话题是:
/laser_cloud_less_flat这些点云的 frame_id 都设置为:
/camera_init虽然名字叫 camera_init,但在 A-LOAM 里它通常作为初始坐标系使用。
21. 可选发布每根 scan line
代码中有:
if(PUB_EACH_LINE)
{
for(int i = 0; i< N_SCANS; i++)
{
sensor_msgs::PointCloud2 scanMsg;
pcl::toROSMsg(laserCloudScans[i], scanMsg);
...
pubEachScan[i].publish(scanMsg);
}
}PUB_EACH_LINE 默认为:
false如果设置为 true,就会把每根 scan line 单独发布出去:
/laser_scanid_0
/laser_scanid_1
...这个功能主要用于调试。比如你想看点云线束划分是否正确,就可以打开这个开关,在 RViz 中分别查看每根线。
22. main():节点初始化、参数读取、订阅和发布
主函数是:
int main(int argc, char **argv)首先初始化 ROS 节点:
ros::init(argc, argv, "scanRegistration");
ros::NodeHandle nh;节点名是:
scanRegistration然后读取参数:
nh.param<int>("scan_line", N_SCANS, 16);
nh.param<double>("minimum_range", MINIMUM_RANGE, 0.1);scan_line 表示 LiDAR 线束数量,默认是 16。minimum_range 表示去除近距离点的距离阈值,默认 0.1 米。
接着检查线束数量:
if(N_SCANS != 16 && N_SCANS != 32 && N_SCANS != 64)
{
printf("only support velodyne with 16, 32 or 64 scan line!");
return 0;
}说明这个代码只支持 16、32、64 线 Velodyne。
然后订阅原始点云:
ros::Subscriber subLaserCloud =
nh.subscribe<sensor_msgs::PointCloud2>("/velodyne_points", 100, laserCloudHandler);也就是说,所有处理都由 /velodyne_points 的回调函数 laserCloudHandler() 触发。
接着初始化所有发布器:
pubLaserCloud = nh.advertise<sensor_msgs::PointCloud2>("/velodyne_cloud_2", 100);
pubCornerPointsSharp = nh.advertise<sensor_msgs::PointCloud2>("/laser_cloud_sharp", 100);
pubCornerPointsLessSharp = nh.advertise<sensor_msgs::PointCloud2>("/laser_cloud_less_sharp", 100);
pubSurfPointsFlat = nh.advertise<sensor_msgs::PointCloud2>("/laser_cloud_flat", 100);
pubSurfPointsLessFlat = nh.advertise<sensor_msgs::PointCloud2>("/laser_cloud_less_flat", 100);
pubRemovePoints = nh.advertise<sensor_msgs::PointCloud2>("/laser_remove_points", 100);最后:
ros::spin();进入 ROS 事件循环,等待点云消息到来。
23. 这个文件的完整流程串起来
整个 scanRegistration.cpp 可以按下面流程理解:
1. ROS 节点 scanRegistration 启动。
2. 读取参数:
scan_line:雷达线束数量,支持 16 / 32 / 64。
minimum_range:近距离点过滤阈值。
3. 订阅原始点云:
/velodyne_points。
4. 每来一帧点云,进入 laserCloudHandler()。
5. 将 ROS PointCloud2 转成 PCL 点云。
6. 去除 NaN 点。
7. 去除距离雷达过近的点。
8. 计算当前帧起始水平角 startOri 和结束水平角 endOri。
9. 遍历每个点:
计算垂直角 angle;
根据 N_SCANS 计算 scanID;
根据水平角 ori 计算该点在一帧中的相对时间 relTime;
将 scanID 和相对时间写入 intensity;
按 scanID 把点放入对应 scan line。
10. 将所有 scan line 按顺序合并成 laserCloud。
11. 记录每根 scan line 在 laserCloud 中的起止索引:
scanStartInd、scanEndInd。
12. 对每个点计算曲率:
用前后各 5 个点和当前点的差异衡量局部平滑度。
13. 对每根 scan line 分成 6 段。
14. 每段内按曲率从小到大排序。
15. 从曲率最大的一端选角点:
每段最多选 2 个 sharp 角点;
每段最多选 20 个 less sharp 角点;
选中后做邻域抑制。
16. 从曲率最小的一端选平面点:
每段最多选 4 个 flat 平面点;
选中后做邻域抑制。
17. 将剩余非角点的大部分点作为 less flat 候选点。
18. 对每根 scan line 的 less flat 点做体素滤波降采样。
19. 发布整理后的全分辨率点云:
/velodyne_cloud_2。
20. 发布强角点:
/laser_cloud_sharp。
21. 发布弱角点:
/laser_cloud_less_sharp。
22. 发布强平面点:
/laser_cloud_flat。
23. 发布弱平面点:
/laser_cloud_less_flat。
24. 后续 laserOdometry 订阅这些特征点,
用它们做 scan-to-scan 前端里程计。24. 最后总结:完整理解这个 scanRegistration.cpp
这个代码文件是 A-LOAM 前端的第一步,它的核心职责不是定位,也不是建图,而是 从原始 Velodyne 点云中提取可用于匹配的几何特征点 。它把一帧原始点云变成五类输出:整理后的全点云、强角点、弱角点、强平面点、弱平面点。后面的 laserOdometry 和 laserMapping 都依赖这些特征点进行点到线、点到面的几何匹配。因此,这个文件的特征提取质量会直接影响整个 A-LOAM 的定位和建图效果。
从输入处理上看,代码首先接收 /velodyne_points 原始点云,并把 ROS 的 PointCloud2 转成 PCL 点云。然后去除 NaN 点和距离雷达太近的点,保证后续参与计算的点是有效的。接着,代码计算当前帧的起始水平角和结束水平角,用于判断一帧扫描的角度范围。由于水平角在 -π 到 π 之间会跳变,所以代码通过 halfPassed 和角度修正逻辑,让一帧中的点具有连续的水平角变化。
从线束划分上看,代码根据每个点的垂直角计算 scanID,也就是该点属于哪一根激光线。对于 16、32、64 线雷达,代码分别使用不同的映射公式。确定 scanID 后,代码还会根据点的水平角计算该点在当前扫描周期中的相对时间 relTime,并把 scanID + scanPeriod * relTime 写入 point.intensity。这里 intensity 已经不再只是反射强度,而是被 A-LOAM 用来同时保存线束编号和相对时间。这个设计很重要,因为后续 laserOdometry 会用整数部分获取 scan line ID,也可能用小数部分进行运动畸变补偿。
从点云组织上看,代码会把所有点按 scanID 分配到不同的 laserCloudScans 中,然后再按线束顺序拼接成一个大的 laserCloud。同时记录每根线在合并后点云中的起止索引 scanStartInd 和 scanEndInd。记录起止索引的目的是后面能在每根 scan line 内独立计算曲率、排序和选点。代码还特意把每根线前后各 5 个点排除在有效范围外,因为计算某个点曲率时需要用到前后各 5 个邻居。
从曲率计算上看,代码用当前点和前后各 5 个点的坐标差异来衡量局部平滑度。具体做法是:把前后 10 个邻居点坐标相加,再减去当前点坐标的 10 倍,然后计算这个差值向量的平方和。这个值越大,说明当前点与周围点差异越明显,越可能处在边缘、墙角、物体轮廓等位置;这个值越小,说明当前点附近比较平滑,越可能位于平面上。因此,曲率大的点被作为角点候选,曲率小的点被作为平面点候选。
从特征选择上看,代码不会在整帧点云中统一选曲率最大和最小的点,而是先把每根 scan line 分成 6 段,每段分别选特征。这样做是为了保证特征点分布均匀。如果不分段,角点可能集中在某个局部区域,平面点也可能集中在某个大平面上,后续位姿估计会因为约束分布不均而不稳定。分段后,每段最多选 2 个强角点、20 个弱角点、4 个强平面点,这样每一圈扫描的不同方向上都能保留一定数量的特征。
从角点提取上看,代码在每段中从曲率最大的点开始选。满足"未被邻域抑制"和"曲率大于 0.1"的点,才可能成为角点。每段前 2 个曲率最大的点加入 cornerPointsSharp,同时也加入 cornerPointsLessSharp;后续直到第 20 个曲率较大的点只加入 cornerPointsLessSharp。因此,sharp 是更强、更稀疏的角点集合,less sharp 是更宽松、数量更多的角点集合。后面的 odometry 中,当前帧一般用 sharp 角点构造点到线约束,而 less sharp 角点会作为更丰富的匹配参考点云。
从平面点提取上看,代码在每段中从曲率最小的点开始选。满足"未被邻域抑制"和"曲率小于 0.1"的点,会被标记为强平面点并加入 surfPointsFlat。每段最多选 4 个 flat 点。强平面点数量较少,但质量较高,适合后续构造点到面残差。选完强平面点后,代码会把所有非角点,也就是 cloudLabel <= 0 的点,加入弱平面点候选集合。因为弱平面点数量通常很大,所以每根 scan line 的 weak flat 点会经过 VoxelGrid 体素滤波降采样,leaf size 为 0.2 米。这样既保留了平面结构,又降低了后续处理的点数。
从邻域抑制上看,无论选角点还是平面点,只要某个点被选中,代码都会把它前后最多 5 个邻居点标记为已选或不可再选。这样可以避免特征点在局部扎堆。如果相邻点之间距离突变较大,代码会提前停止向外扩展抑制范围,这是为了避免跨过深度断层后错误屏蔽其他物体上的点。邻域抑制保证了特征点既有代表性,又不会过密。
从发布结果上看,代码最终发布五类点云。/velodyne_cloud_2 是整理后的全分辨率点云,已经包含 scanID 和相对时间信息;/laser_cloud_sharp 是强角点;/laser_cloud_less_sharp 是弱角点;/laser_cloud_flat 是强平面点;/laser_cloud_less_flat 是降采样后的弱平面点。这些话题会被后续 laserOdometry 订阅,用于构造点到线和点到面约束。也就是说,这个文件输出的特征点就是后续前端里程计的直接输入。
从整个 A-LOAM 系统分工来看,这个文件负责"提特征",laserOdometry 负责"用当前帧和上一帧特征点估计相邻帧位姿",laserMapping 负责"把当前帧特征点和局部地图匹配,进一步修正位姿并建图"。如果这个文件提取的角点和平面点质量不好,比如角点太少、平面点太稀、特征分布不均匀、scanID 计算错误、时间信息错误,那么后面的 odometry 会匹配困难,mapping 也会建图不稳定。
所以最终可以这样概括这个文件:
scanRegistration.cpp 的完整作用是:接收原始 Velodyne 点云,去除无效点和近距离点,根据垂直角将点划分到不同 scan line,根据水平角计算每个点在一帧扫描中的相对时间,把 scanID 和时间写入 intensity;然后计算每个点的局部曲率,把每根 scan line 分成 6 段,在每段中选择曲率最大的点作为角点、曲率最小的点作为平面点,并通过邻域抑制保证特征分布均匀;最后发布 sharp、less sharp、flat、less flat 和整理后的全分辨率点云,供 laserOdometry 和 laserMapping 后续使用。
版权声明: 辛苦码字不易,转载请注明原文出处和作者信息,谢谢理解!
欢迎分享与交流,但拒绝任何形式的商业转载或洗稿。