作者:来自 Elastic Luca Wintergerst
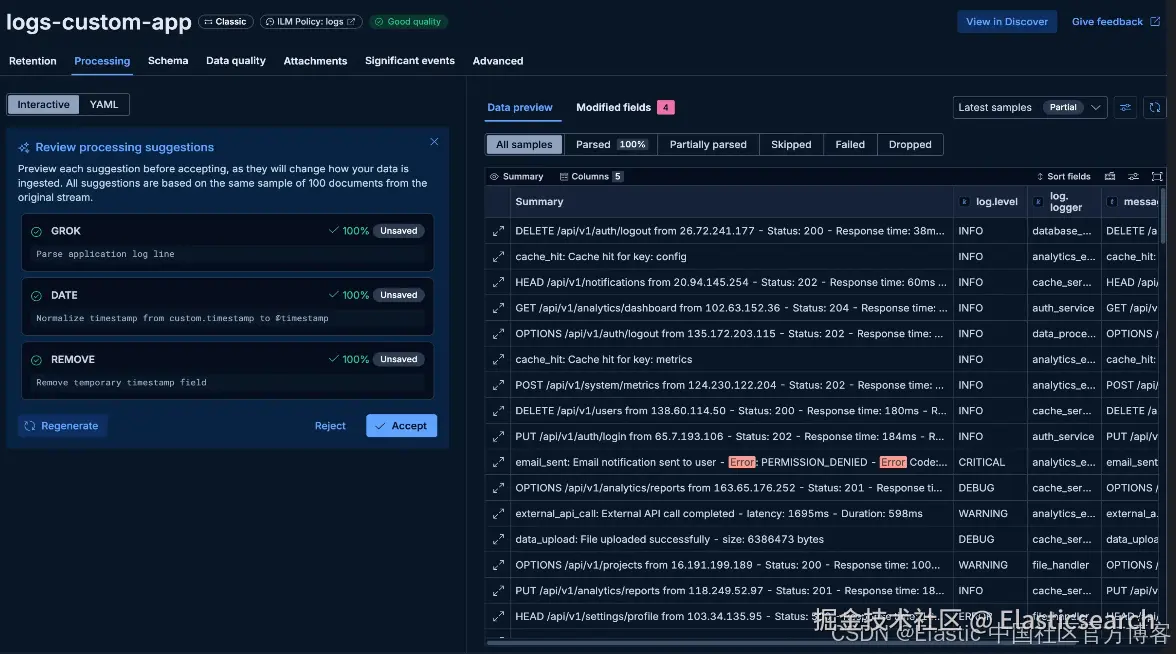
Streams 只需一次点击就能生成一个完整、经过测试的日志处理 pipeline。其背后的机制分为两个阶段:确定性指纹匹配( deterministic fingerprinting ),以及一个基于真实数据反复迭代的 reasoning agent,同时通过严格的验证阈值在结果展示前保证质量。
只需点击 Kibana Processing 标签中的 Suggest pipeline 按钮,几秒钟内你就会看到一个完整的 pipeline(Grok 模式、日期 标准化 、类型转换),并附带你的真实日志文档在该 pipeline 中的解析预览。
另一种方式则是手动完成这一切:编写 Grok pattern、进行测试、修复边界情况、发现字段名不符合 ECS、重命名字段、再添加 date processor。而这些工作仅仅只是针对一个服务的量。
每个日志 pipeline 要做的三件事
每个日志处理 pipeline 都在做同样的三件事:从原始日志消息中提取字段,将其标准化为一致的 schema,并清理不需要的数据。大多数团队过去都是手动构建和维护这些流程,但随着日志格式不断变化,这会变得很困难;尤其是当你发现编写 Grok pattern 的人已经换了团队,而除了 pattern 本身之外几乎没有任何文档时。
每增加一个新服务,就意味着要从头再来一遍:不同的格式、不同的边界情况,最终由另一个人去维护一份他自己并没有写过的 pattern。
在初始 pipeline 阶段,Streams 会自动处理这三件事,并在任何数据进入生产环境之前对结果进行验证。
点击 "Suggest pipeline" 会发生什么
在 Kibana 中打开某个 stream 的 Processing 标签页,点击按钮。几秒钟后,面板会生成一个建议的 pipeline(通常包含解析步骤、日期标准化、类型转换以及字段清理),同时提供一个实时预览,展示最近的文档在经过该 pipeline 处理后的结果。
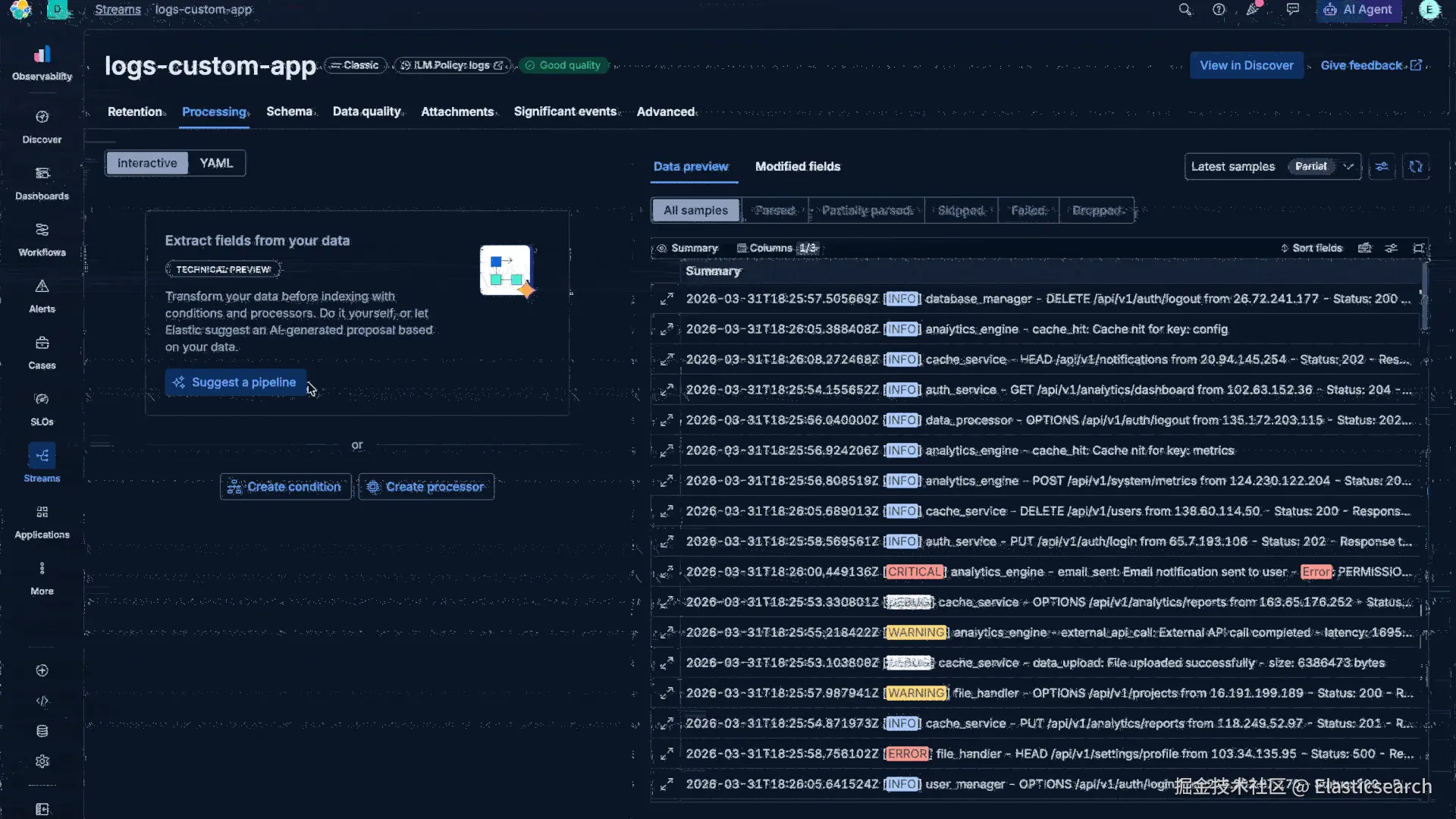
在这个视图中,你可以看到将被提取的具体字段、它们的类型,以及有多少示例文档被成功解析。如果某个字段名不正确,你也可以直接内联编辑;如果某个步骤引入了噪声,可以直接删除。如果解析率需要提升,也可以轻松调整并重新生成。在你明确确认之前,不会有任何内容写入 stream。目前来看,让人参与这一环节仍然很重要;随着这类系统的不断成熟,未来可能不再需要这一人工步骤。
接下来我们更详细地看看整个流程。
阶段 1:日志分组与模式提取
第一阶段不涉及 reasoning model。这是一个确定性过程:相同的输入始终产生相同的输出,不存在模型带来的波动。同时,它也缩小了第二阶段需要处理的范围。
在任何提取开始之前,Streams 会根据日志格式指纹对消息进行聚类。这个算法其实很简单:数字映射为 0,字母映射为 a,而标点符号保持不变。生成相同指纹的两条消息会被归入同一组。
less
`
1. # two entries from the same nginx stream
2. 2026-03-30 14:22:31 192.168.1.100 - james "GET /api/v1/health" 200
3. 2026-03-30 08:01:05 10.0.0.5 - alice "GET /api/v2/status" 404
5. # fingerprint
6. 0-0-0 0:0:0 0.0.0.0 - a "a /a/a0/a" 0
7. 0-0-0 0:0:0 0.0.0.0 - a "a /a/a0/a" 0
`AI写代码一个包含多种日志格式的 stream 会生成多个分组,每种格式对应一个分组。这是一种非常简单但非常有效的方法,可以将相似日志聚类在一起,从而使后续所有步骤更加可靠。
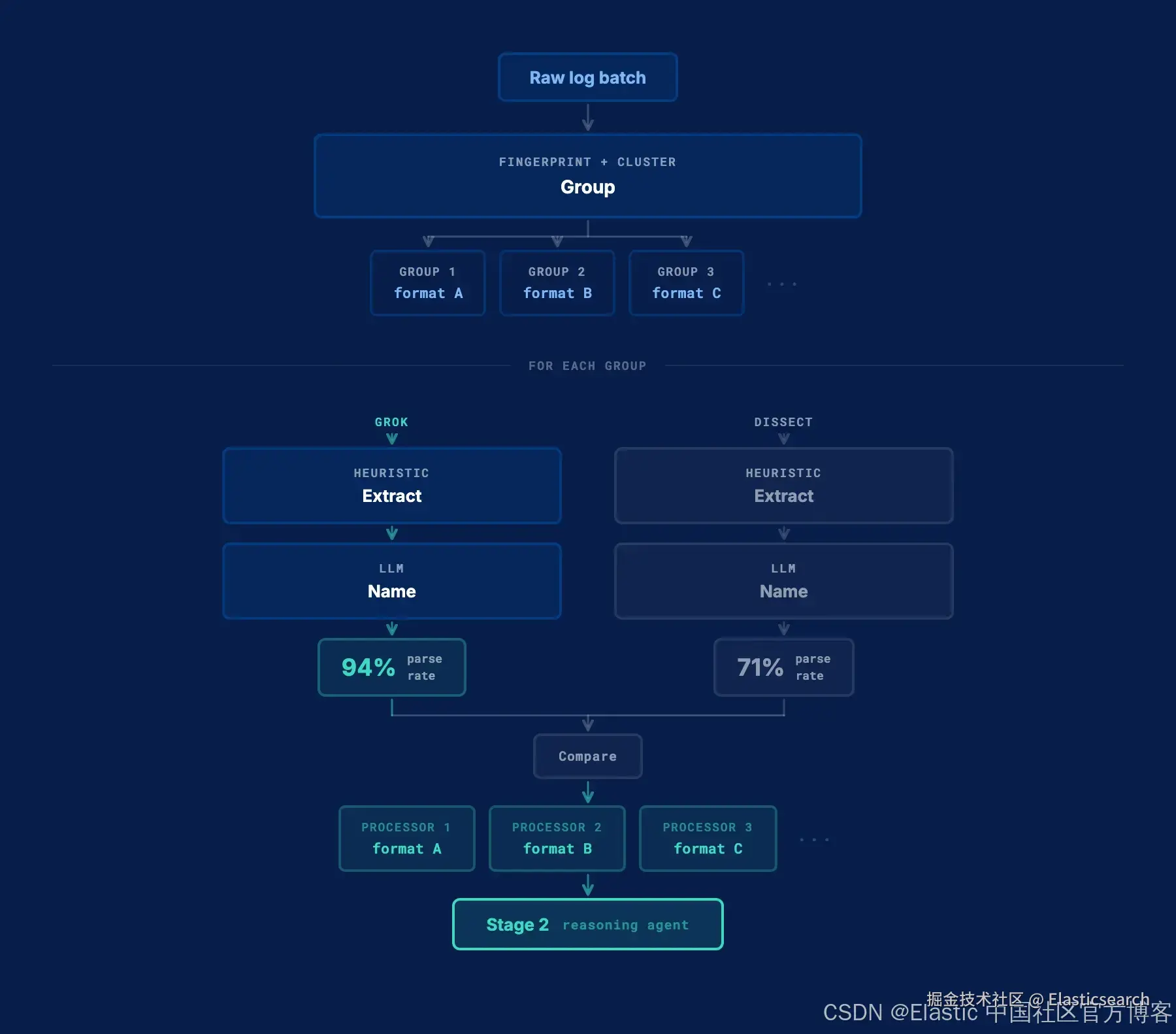
Grok 和 Dissect 都在相同的输入上运行,但它们的工作方式不同。Grok 按分组运行,因为它支持多个模式,并能分别处理每种不同格式。Dissect 只使用一个模式,因此只针对批次中最大的分组。
对于每个候选方案,一个启发式算法会分析日志消息并识别字段边界:哪些是固定文本,哪些是变化部分。它会生成一个带有位置占位符名称的模式。随后,一个 LLM 会基于最多 10 条示例消息审查这些字段位置,并将占位符重命名为更具可读性、符合 schema 规范的名称。
yaml
`
1. # grok heuristic output (positional placeholders)
2. %{IPV4:field_0} - %{USER:field_1} \[%{HTTPDATE:field_2}\] "%{WORD:field_3} %{URIPATHPARAM:field_4}..."
4. # after LLM field naming (ECS-aligned)
5. %{IPV4:source.ip} - %{USER:user.name} \[%{HTTPDATE:@timestamp}\] "%{WORD:http.request.method} %{URIPATHPARAM:url.path}..."
7. # dissect heuristic output (positional placeholders)
8. %{field_0} - %{field_1} [%{field_2}] "%{field_3} %{field_4} %{?field_5}" %{field_6} %{field_7}
10. # after LLM field naming (ECS-aligned)
11. %{source.ip} - %{user.name} [%{@timestamp}] "%{http.request.method} %{url.path} %{?http_version}" %{http.response.status_code} %{http.response.body.bytes}
`AI写代码生成的处理器会在你提交的文档上进行模拟,以衡量其解析率。Grok 表达能力更强,支持类型化字段、命名捕获以及多个子模式,但最大的缺点是速度较慢。相比之下,Dissect 更快,但仅限于基于固定位置的拆分。简单的日志格式通常可以用 dissect 干净地解析;复杂的则需要 grok。
解析率更高的候选方案会成为该分组的解析处理器。这个过程会对批次中的每个分组执行。阶段 1 会为阶段 2 提供每个分组对应的一个解析处理器。
对于一批 nginx 访问日志,提取过程会为当前唯一的格式分组生成两个候选方案:
css
`
1. # input (sampled from 300 submitted documents)
2. 192.168.1.100 - james [30/Mar/2026:14:22:31 +0000] "GET /api/v1/health HTTP/1.1" 200 1234
4. # grok candidate → parse rate 94% (282/300)
5. %{IPV4:source.ip} - %{USER:user.name} \[%{HTTPDATE:@timestamp}\] "%{WORD:http.request.method} %{URIPATHPARAM:url.path} HTTP/%{NUMBER:http.version}" %{NUMBER:http.response.status_code:int} %{NUMBER:http.response.body.bytes:int}
7. # dissect candidate → parse rate 71% (213/300)
8. %{source.ip} - %{user.name} [%{@timestamp}] "%{http.request.method} %{url.path} %{?http_version}" %{http.response.status_code} %{http.response.body.bytes}
10. # winner: grok
`AI写代码这里 Grok 胜出,因为 %{HTTPDATE} 可以处理带方括号的时间戳格式;Dissect 尝试基于固定位置进行拆分,但在处理外围的方括号时失败。两者是并行运行的;对结果进行比较几乎不会增加额外时间,因为这一步初始模拟只是在一部分样本文档上完成。
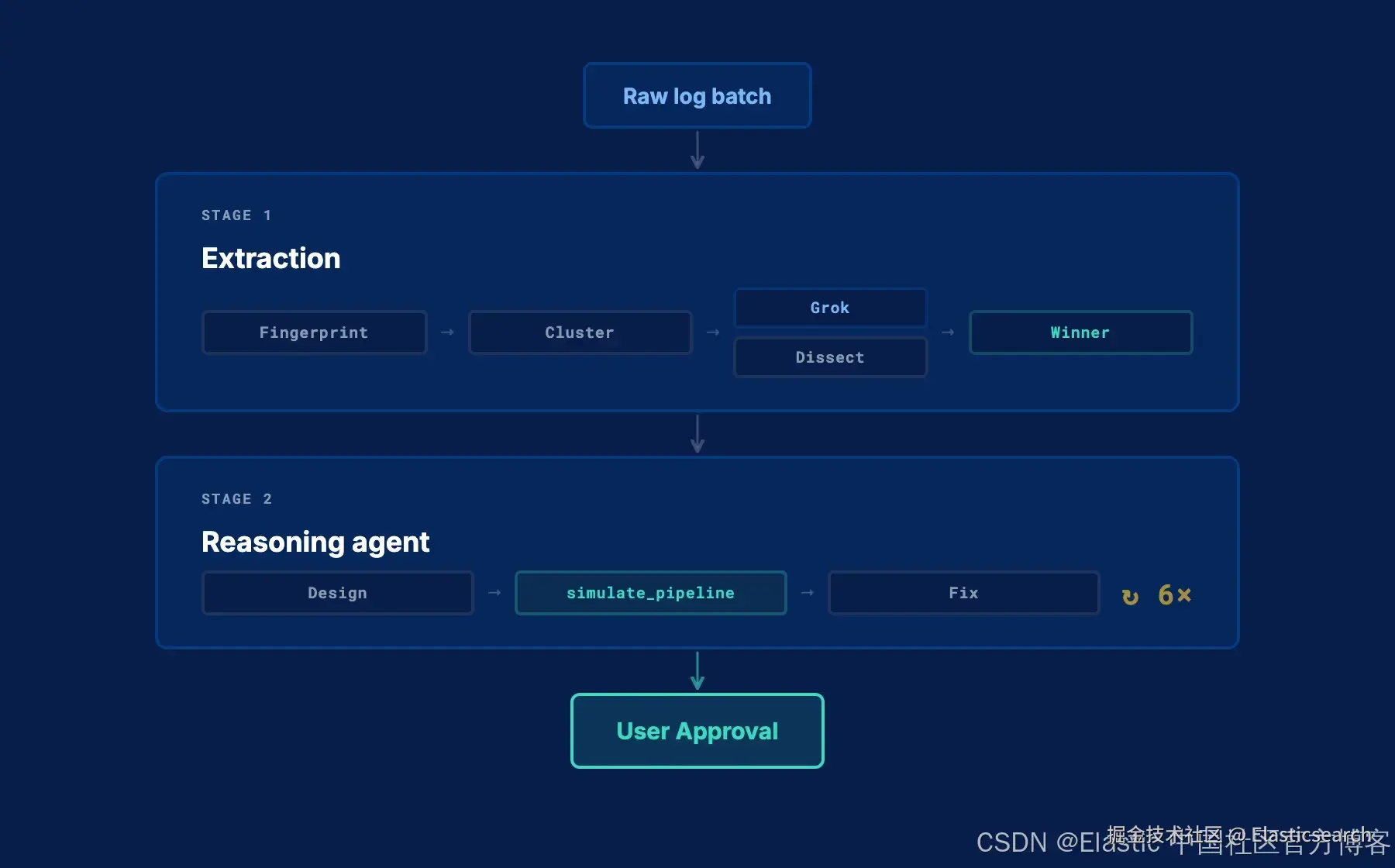
阶段 2:推理 agent
阶段 1 会生成一个解析处理器;阶段 2 则将其转化为一个完整且经过验证的 pipeline。
这个阶段使用一个推理 agent,在一个包含两个工具的循环中迭代执行,最多运行六次。
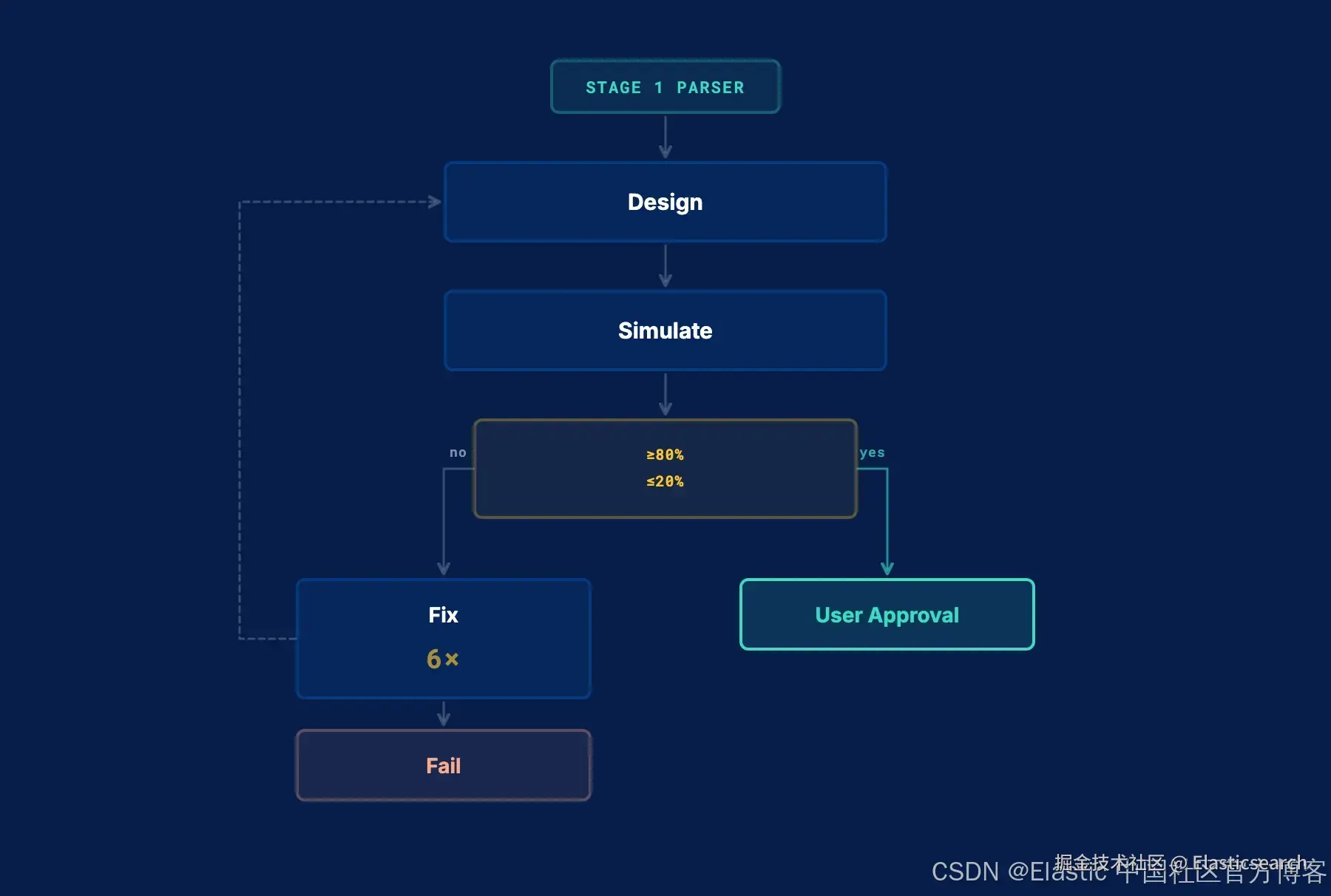
循环过程:
- 代理会接收阶段 1 生成的解析处理器,并提出额外的步骤:日期规范化、类型转换、字段清理,以及对其识别为敏感的字段进行 PII 脱敏处理。
- 随后,它会在你的原始文档(原始数据,而非预处理后的数据)上运行完整的候选 pipeline,并返回验证结果。
- 如果模拟失败,代理会读取错误信息并进行调整。这些失败信息非常具体,我们充分利用 LLM 的能力来理解它们:哪个处理器失败了、影响了多少比例的文档、以及错误类型是什么。当解析率低于 80% 时,工具会返回:
vbnet
`
1. Parse rate is too low: 67.00% (minimum required: 80%). The pipeline is not
2. extracting fields from enough documents. Review the processors and ensure
3. they handle the document structure correctly.
5. Processor "grok[0]" has a failure rate of 33.00% (maximum allowed: 20%).
6. This processor is failing on too many documents.
`AI写代码代理现在会读取处理器名称、失败率以及阈值,然后在下一次迭代中调整模式。在错误被解决之前,它无法提交。
- 这一过程会不断重复,直到 pipeline 通过验证,然后才会提交并在 UI 中发送给用户进行审批。
为了保证质量,我们在工具层面(而不是依赖代理自身判断)强制执行两个硬性阈值:
- 如果成功解析的文档少于 80%,模拟将返回错误,agent 必须先修复这个问题才能继续。
- 如果任何单个处理器在超过 20% 的文档上失败,则该模拟被判定为无效。
验证机制也嵌入在工具中:模型会看到错误信息,并且必须在继续之前解决这些问题。它无法提交一个未通过这些检查的 pipeline。
在底层,我们在引导代理朝一个特定方向工作。这里的系统提示包括:"优先简化。与其添加变通方案,不如移除有问题的处理器。一个能够完美处理 95% 文档的 pipeline,要优于一个试图覆盖 100% 但表现不可预测的方案。"
如果你的数据已经是结构化良好的(例如已有规范的 @timestamp、正确的字段类型、且没有需要解析的原始文本),代理会检测到这一点并提交一个空的 pipeline,而不会为了增加步骤而增加处理器。
输出是 Streamlang
Agent 会编写 Streamlang DSL,这是 Elastic 用于流处理的语言,在底层会编译为 ingest pipeline。
字段 schema、处理器类型以及步骤格式:全部都通过 Streamlang 表达。下面是针对上述 nginx 示例、面向 ECS 数据流的用户批准后的 pipeline:
yaml
`
1. steps:
2. - action: grok
3. from: message
4. patterns:
5. - "%{IPV4:source.ip} - %{USER:user.name} \\[%{HTTPDATE:@timestamp}\\] \"%{WORD:http.request.method} %{URIPATHPARAM:url.path} HTTP/%{NUMBER:http.version}\" %{NUMBER:http.response.status_code:int} %{NUMBER:http.response.body.bytes:int}"
6. - action: date
7. from: "@timestamp"
8. formats:
9. - "dd/MMM/yyyy:HH:mm:ss Z"
10. - action: convert
11. from: http.response.status_code
12. type: integer
13. - action: remove
14. from: message
`AI写代码两种 schema,一个生成器
并不是所有人落库日志的方式都相同,Elastic 需要支持多种格式。使用 OpenTelemetry collector 的团队希望数据采用 OTel 原生字段;而使用 Elastic 传统技术栈的团队则期望使用 ECS。这两种方式都是合理的,如果强制所有人使用同一种 schema,就意味着一半用户在开始之前就必须先重构自己的 pipeline。
因此,Streams 同时支持这两种方式,生成器也会同时处理。我们会自动判断应该使用 OTel 还是 ECS。具体来说,主要是查看 stream 的名称中是否包含 "otel",因为这是当前技术栈中的默认命名方式。
由于规范字段名称不同,两种情况下生成的 pipeline 也会有所不同:
| OTel | ECS | |
|---|---|---|
| Log body | body.text |
message |
| Log level | severity_text |
log.level |
| Service name | resource.attributes.service.name |
service.name |
| Host name | resource.attributes.host.name |
host.name |
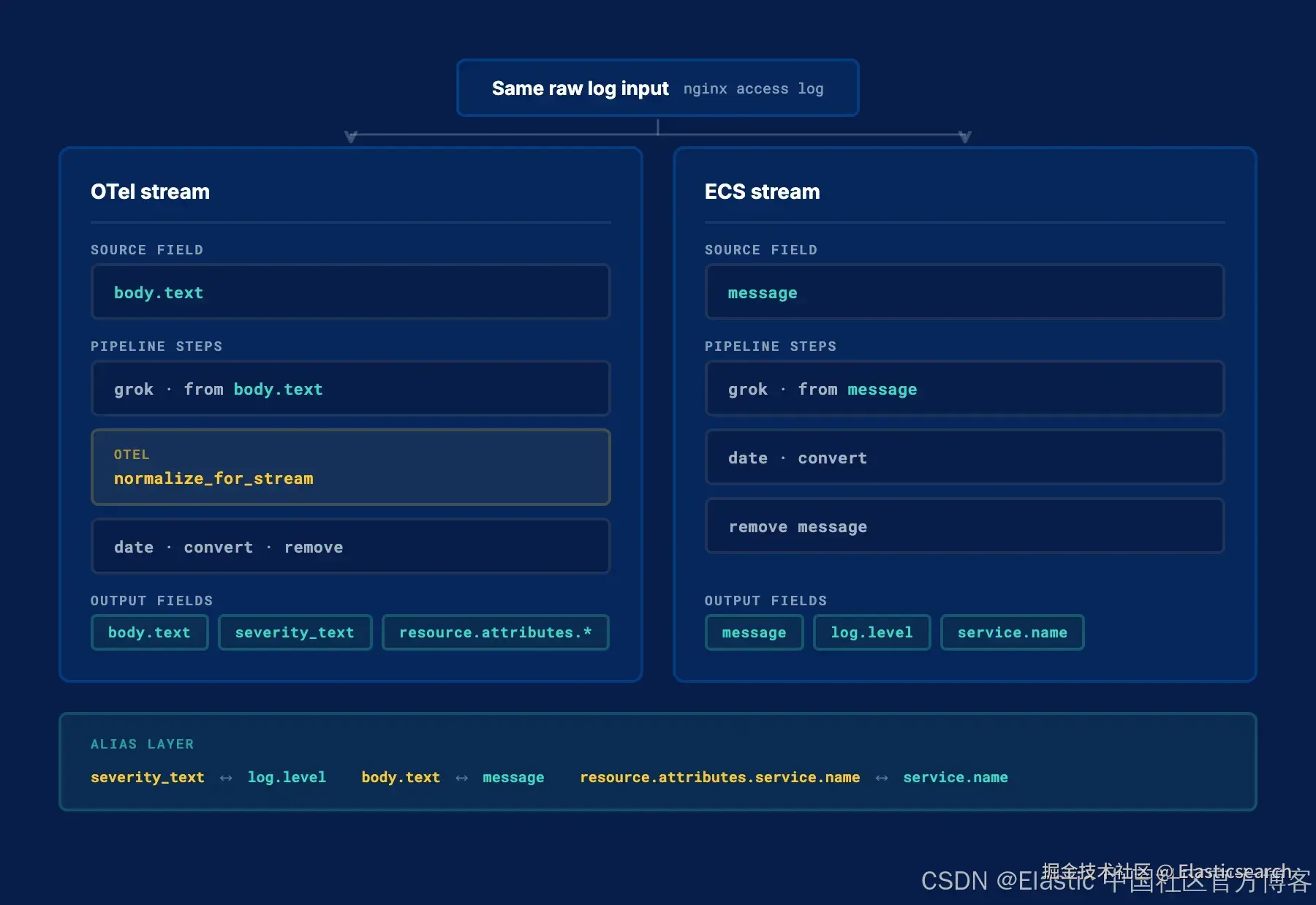
OTel 数据流会使用一个 grok 处理器,从 body.text 字段中读取数据:
json
`{ "action": "grok", "from": "body.text", "patterns": ["..."] }` AI写代码ECS 数据流则从 message 字段读取:
json
`{ "action": "grok", "from": "message", "patterns": ["..."] }` AI写代码OTel 数据流会将 ECS 字段名映射为对应的 OTel 字段别名。例如,log.level 会作为 severity_text 的别名,message 会作为 body.text 的别名。这样一来,用 ECS 编写的查询可以直接在 OTel 数据流上运行,无需修改,因为别名层会自动完成字段转换。
json
`
1. {
2. "message": { "path": "body.text", "type": "alias" },
3. "log.level": { "path": "severity_text", "type": "alias" }
4. }
`AI写代码代理会识别当前属于哪一种 schema,并据此调整行为。它不会在 OTel stream 中额外添加 severity_text → log.level 的重命名步骤,因为别名层已经提供了这种映射关系。而在 ECS stream 中,它会显式地执行这种标准化处理。
模式规范化 / schema 规范化
字段抽取只是最显而易见的一部分,但更重要的是字段对齐。
如果两个服务都在记录 HTTP 请求,但使用了不同的字段名(例如一个用 response_status,另一个用 http_code),那么针对 http.response.status_code: 5* 的查询在两者中都会得不到结果。Schema normalization 的作用就是将这些不同字段统一映射到标准名称:
bash
`
1. # before: extracted field names from two different services
2. { "response_status": 500 } # service A
3. { "http_code": 500 } # service B
5. # after: ECS normalization
6. { "http.response.status_code": 500 }
`AI写代码现在每个服务都使用 http.response.status_code,因此该查询可以在所有服务中正常工作。
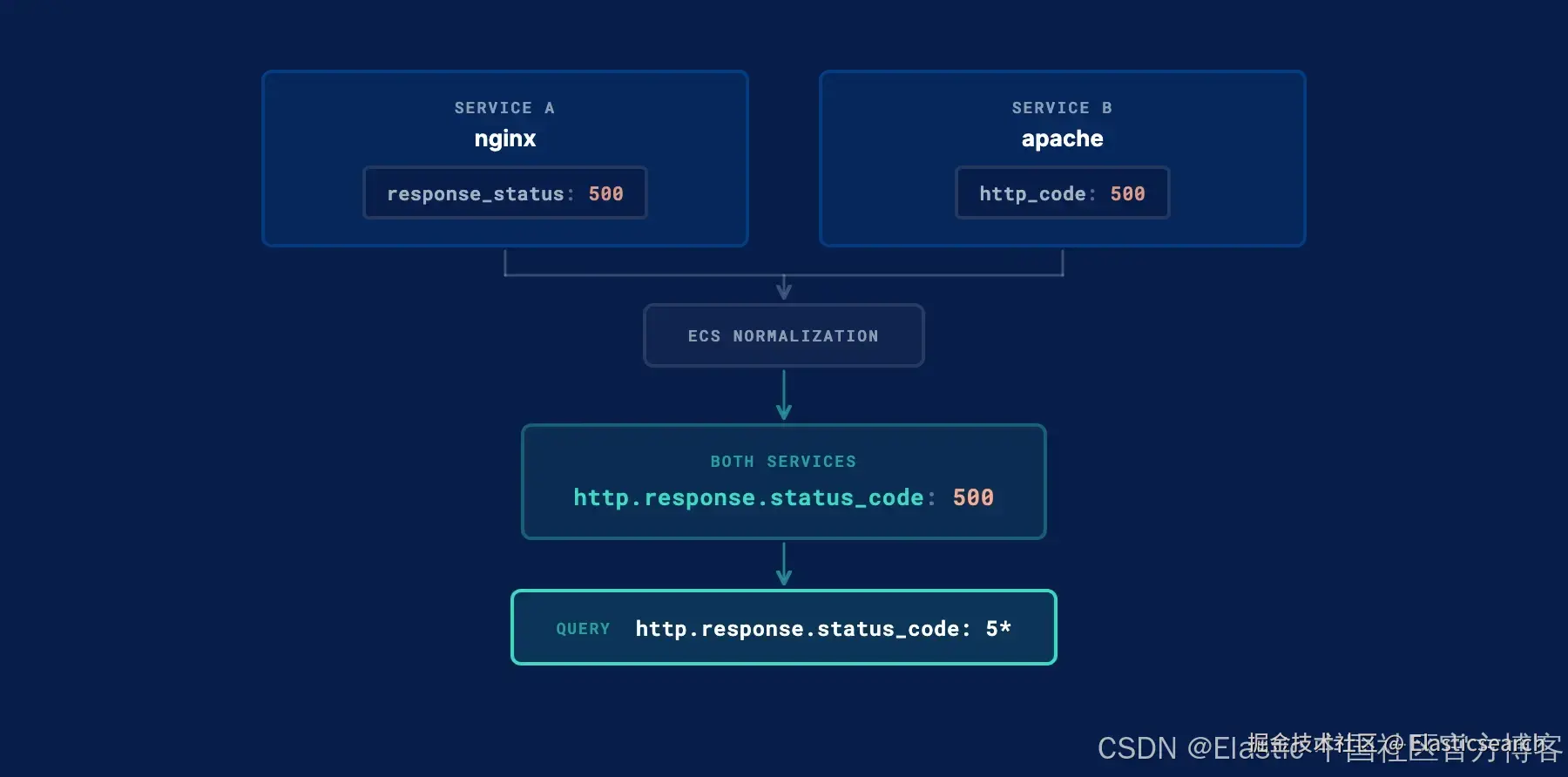
在模拟过程中,代理会为其生成的每个字段检查 ECS 和 OTel 的元数据。对于已经是标准名称的字段,会保持不变;对于能够映射到已知 ECS 字段的,会进行重命名。模拟指标会明确展示这一点:结果中的每个字段都会带有其 ECS 或 OTel 类型标识,因此你可以一眼看出哪些字段已经被规范化。
代理必须达到的标准
系统提示为用户批准的 pipeline 设置了明确的验收条件:
-
99% 的文档必须包含有效的
@timestamp -
所有字段必须符合目标 schema 的类型要求
-
整体失败率必须低于 0.5%
如果代理无法在 6 次迭代内满足所有条件,则生成失败。
总结
pipeline 生成只需要几秒,而手动流程可能需要数小时。时间节省来自于自动化了原本需要手动执行的验证循环:编写 pattern、在真实数据上测试、阅读失败结果、调整再试。代理会在最多 6 个周期内,基于 stream 最近实际接收的文档完成这一过程。
Streams 与 processing 的后续发展
当前最面向用户的改进是 refinement loop(细化循环)。现在如果建议 "接近正确但不完全正确",你需要手动编辑步骤并结束;下一版本允许你直接调整生成的 pipeline,并带着修改反馈回传给代理,使其在你的基础上继续优化,而不是从头开始。
另外两个正在开发的方向是:生成过程异步化(目前会阻塞 UI 几秒,未来将在后台运行),以及支持已有 pipeline 的 streams(目前只支持没有任何 processing steps 的 stream)。
这些能力也正在以可调用工具的形式暴露在 Streams agent builder 中,并通过 API 提供给第三方 agent 框架使用。代理可以在更大的 onboarding 工作流中直接调用完整的 pipeline 生成,而不依赖 UI。