在数据爆炸的时代,如何让用户在海量信息中毫秒级找到目标内容,是衡量系统体验的关键指标。传统的数据库 LIKE 查询在面对大数据量时往往力不从心,不仅性能低下,还难以支持分词、模糊匹配等高级功能。本文将带你从零开始,基于 Elasticsearch (ES) 构建一个高可用、实时的全文检索系统。我们将采用 Canal 监听数据库变更,通过 Kafka 进行消息削峰填谷,最终实现数据从 MySQL 到 ES 的实时同步。
1. Elasticsearch 概述
Elasticsearch 是一个基于 Lucene 构建的开源、分布式、RESTful 风格的搜索和数据分析引擎。它能以毫秒级的速度存储、搜索和分析海量数据。
Elasticsearch 基础内容可参考:Elasticsearch从入门到实战:核心概念与全平台部署及开发详解
2. 全文检索
Elasticsearch 是一个基于 Lucene 构建的开源、分布式、RESTful 风格的搜索和数据分析引擎。它能以毫秒级的速度存储、搜索和分析海量数据。
2.1. 什么是全文检索
全文检索是指计算机索引程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置。当用户查询时,检索程序根据用户输入的关键词在索引中查找,并将结果返回。
2.2. 与传统查询的区别
传统查询,类似于字典的部首查字,必须精确匹配(如 SQL 中的 = 或 LIKE),无法处理语义模糊的情况。
全文检索,类似于书籍的目录索引(倒排索引),支持分词、同义词、权重打分,能够理解"什么是相关的"。
2.3. 常见场景
- 电商搜索: 商品名称、描述的模糊搜索,支持高亮、聚合筛选。
- 日志分析: 也就是著名的 ELK 技术栈,用于运维监控和故障排查。
- 内容平台: 博客文章、新闻资讯的关键词检索。
- 代码托管: 如 GitHub 的代码搜索功能。
3. 全文检索实现方式
实现全文检索通过有以下几种主流方式。
3.1. 基于数据库的模糊查询
当前方式主要是使用 SQL 中的LIKE '%keyword%'。
缺点主要是全表扫描,性能极差,无法利用索引,不支持相关性排序。
仅适用于数据量极小的场景。
3.2. 基于Lucene的直接开发
当前方式主要是直接使用 Lucene 库编写代码。
缺点主要是 Lucene 只是一个核心库,缺乏分布式支持,扩展性和容错性需要自己实现,开发成本高。
3.3. 基于ES的成熟中间件
当前方式则是使用成熟的搜索引擎中间件。
其优点就是开箱即用,支持分布式集群、高可用、实时索引、丰富的分词器和 RESTful API。
这是目前企业级开发的首选方案。
4. 实时数据同步与全文检索实战
4.1. 技术栈
前端:这里暂不考虑。
后端:SpringBoot
数据库:MySQL
数据库变更捕获:Canal
消息中间件:Kafka
搜索引擎:Elasticsearch
4.2. 技术链路
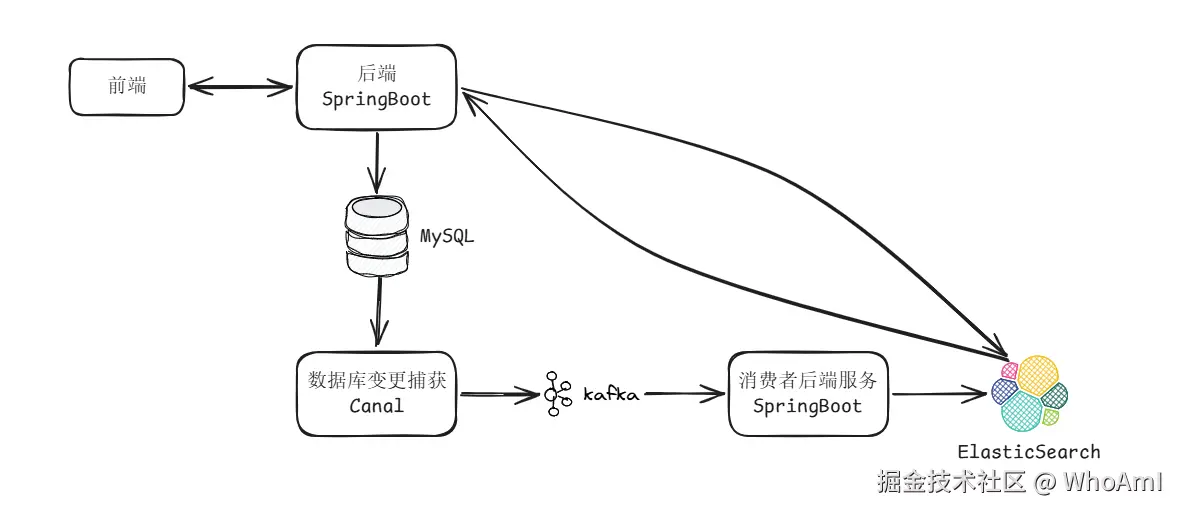
数据异步写入ES:
-
数据持久化:前端请求,调用后端接口,由后端接收、处理,最后持久化到 MySQL 数据库。
-
数据监听与同步Kafka:由 Canal 伪装成数据库的 Slave 节点,并实时监听 Binlog 文件,当 Canal 监听到
INSERT、UPDATE和DELETE操作时,将数据推送到 Kafka 指定的 Topic 中。 -
消息消费与同步ES:另一个后端服务,作为 Kafka 的消费者,监听对应的 Topic,接收 Canal 发送的 JSON 消息,解析出数据内容。
-
如果是新增/修改,调用 ES 的
IndexRequest,将数据索引到 ES 中。 -
如果是删除,调用 ES 的
DeleteRequest,根据主键删除文档。
-
全文检索:
-
前端搜索:用户可以在搜索栏中输入关键词进行搜索,调用后端接口;
-
后端构建查询:由后端根据关键词,构建查询条件,根据需求使用
match、term,或者bool等,并将结果中的关键字设置为高亮,将 ES 查询结果响应给前端展示。
4.3. 技术实现
以下只展示核心代码片段。
4.3.1. 需求说明
这里还是以一个书籍为例,可以根据书籍名称(nameText)和摘要(commentText)分词检索,也可以根据作者精确查询。
4.3.2. MySQL表结构
SQL
CREATE TABLE `books` (
`id` VARCHAR(64) NOT NULL COMMENT '主键ID',
`name` VARCHAR(255) NOT NULL COMMENT '书名',
`author` VARCHAR(255) DEFAULT NULL COMMENT '作者',
`score` VARCHAR(4) DEFAULT NULL COMMENT '评分',
`comment` VARCHAR(2000) DEFAULT NULL COMMENT '摘要',
`publishTime` DATETIME DEFAULT NULL COMMENT '发布时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='书籍信息表';4.3.3. ES 文档结构
bash
PUT /book_index
{
"settings": {
"number_of_replicas": 1,
"number_of_shards": 2
},
"mappings": {
"properties": {
"nameText": {
"search_analyzer": "ik_smart",
"analyzer": "ik_max_word",
"type": "text"
},
"author": {
"type":"text",
"fields":{
"keyword":{
"ignore_above":256,
"type":"keyword"
}
}
},
"score":{
"type":"float"
},
"commentText": {
"search_analyzer": "ik_smart",
"analyzer": "ik_max_word",
"type": "text"
},
"publishTime":{
"type":"date",
"format": "yyyy-MM-d HH:mm:ss"
}
}
}
}4.3.4. Canal 逻辑
由 Canal 监听 MySQL 的 Binlog 文件,将对应操作捕获,并发送到 Kafka 指定 Topic 中。
Canal 部署的话,后期单独写一篇文章,这里只把 Canal 抓取的数据结构示例给出。
- 新增数据
JSON
{
"data": [
{
"id": "book_001",
"name": "深入理解计算机系统",
"author": "Randal E. Bryant",
"score": "9.8",
"comment": "被誉为计算机科学的圣经,内容全面且深入。",
"publishTime": "2026-02-18 10:00:00"
}
],
"database": "testdb",
"es": 1698372000000,
"id": 12345,
"isDdl": false,
"mysqlType": {
"id": "VARCHAR(64)",
"name": "VARCHAR(255)",
"author": "VARCHAR(255)",
"score": "VARCHAR(4)",
"comment": "VARCHAR(2000)",
"publishTime": "DATETIME"
},
"old": [],
"pkNames": [
"id"
],
"sql": "",
"sqlType": {
"id": -9,
"name": 12,
"author": 12,
"score": 12,
"comment": 12,
"publishTime": 93
},
"table": "books",
"ts": 1771383060000,
"type": "INSERT"
}- 修改数据。
JSON
{
"data": [
{
"id": "book_001",
"name": "深入理解计算机系统",
"author": "Randal E. Bryant",
"score": "9.9",
"comment": "被誉为计算机科学的圣经,内容全面且深入,强烈推荐。",
"publishTime": "2026-02-18 10:00:00"
}
],
"database": "testdb",
"es": 1698372100000,
"id": 12346,
"isDdl": false,
"mysqlType": {
"id": "VARCHAR(64)",
"name": "VARCHAR(255)",
"author": "VARCHAR(255)",
"score": "VARCHAR(4)",
"comment": "VARCHAR(2000)",
"publishTime": "DATETIME"
},
"old": [
{
"score": "9.8",
"comment": "被誉为计算机科学的圣经,内容全面且深入。"
}
],
"pkNames": [
"id"
],
"sql": "",
"sqlType": {
"id": -9,
"name": 12,
"author": 12,
"score": 12,
"comment": 12,
"publishTime": 93
},
"table": "books",
"ts": 1771383060000,
"type": "UPDATE"
}- 删除数据。
JSON
{
"data": [
{
"id": "book_001",
"name": "深入理解计算机系统",
"author": "Randal E. Bryant",
"score": "9.9",
"comment": "被誉为计算机科学的圣经,内容全面且深入,强烈推荐。",
"publishTime": "2026-02-18 10:00:00"
}
],
"database": "testdb",
"es": 1698372200000,
"id": 12347,
"isDdl": false,
"mysqlType": {
"id": "VARCHAR(64)",
"name": "VARCHAR(255)",
"author": "VARCHAR(255)",
"score": "VARCHAR(4)",
"comment": "VARCHAR(2000)",
"publishTime": "DATETIME"
},
"old": [],
"pkNames": [
"id"
],
"sql": "",
"sqlType": {
"id": -9,
"name": 12,
"author": 12,
"score": 12,
"comment": 12,
"publishTime": 93
},
"table": "books",
"ts": 1771383060000,
"type": "DELETE"
}参数说明:
| 字段名 | 描述 |
|---|---|
| type | 变更操作的类型,值为 INSERT、UPDATE 或 DELETE。 |
| data | 包含变更后的行数据。对于 INSERT 和 UPDATE,是新值;对于 DELETE,是被删除的旧值。 |
| old | 仅在 UPDATE 操作中存在,包含发生变更的字段及其旧值。 |
| database | 发生数据变更的数据库名称。 |
| table | 发生数据变更的表名。 |
| es | 数据变更事件在 MySQL 中发生的时间戳(毫秒)。 |
| ts | Canal 将该消息发送到 Kafka 的时间戳(毫秒)。 |
| pkNames | 表的主键字段名列表。 |
4.3.5. Kafka 消费者逻辑
监听指定 Topic,接收消息并处理,根据操作不同,将数据更新到ES,或者删除ES的文档。
- 核心依赖。
XML
<dependencies>
<!-- Kafka -->
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
<!-- Elasticsearch -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
<!-- JSON 处理 (如 Jackson 或 Hutool,这里以 Jackson 为例) -->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
</dependency>
</dependencies>- 创建 ES 对应实体类
Java
package com.example.demo.model;
import lombok.Data;
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.DateFormat;
import org.springframework.data.elasticsearch.annotations.Document;
import org.springframework.data.elasticsearch.annotations.Field;
import org.springframework.data.elasticsearch.annotations.FieldType;
@Data
@Document(indexName = "book_index")
public class Book {
@Id
private String id; // 对应 MySQL 的 id
@Field(type = FieldType.Text, analyzer = "ik_max_word", searchAnalyzer = "ik_smart")
private String nameText; // 对应 MySQL 的 name
@Field(type = FieldType.Text)
private String author;
@Field(type = FieldType.Float)
private Float score;
@Field(type = FieldType.Text, analyzer = "ik_max_word", searchAnalyzer = "ik_smart")
private String commentText; // 对应 MySQL 的 comment
@Field(type = FieldType.Date, format = DateFormat.custom, pattern = "yyyy-MM-dd HH:mm:ss")
private String publishTime;
}- 创建接收 Canal 数据的实体类。
Java
package com.example.demo.model;
import lombok.Data;
import java.util.List;
@Data
public class CanalMessageDTO {
// INSERT, UPDATE, DELETE
private String type;
private String database;
private String table;
// 变更后的数据
private List<Map<String, Object>> data;
// 变更前的数据(仅 UPDATE 时有)
private List<Map<String, Object>> old;
// 事件发生时间
private Long es;
// Canal 处理时间
private Long ts;
}- Kafka 消费者实现。
Java
package com.example.demo.consumer;
import com.example.demo.model.Book;
import com.example.demo.model.CanalMessageDTO;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.elasticsearch.core.ElasticsearchRestTemplate;
import org.springframework.data.elasticsearch.core.IndexOperations;
import org.springframework.data.elasticsearch.core.document.Document;
import org.springframework.data.elasticsearch.core.query.Criteria;
import org.springframework.data.elasticsearch.core.query.CriteriaQuery;
import org.springframework.data.elasticsearch.core.query.Query;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Component;
import java.util.List;
import java.util.Map;
@Slf4j
@Component
public class BookSyncConsumer {
@Autowired
private ElasticsearchRestTemplate elasticsearchRestTemplate;
@Autowired
private ObjectMapper objectMapper;
// 替换为你的 Kafka Topic 名称
private static final String TOPIC_NAME = "canal_topic";
@KafkaListener(topics = TOPIC_NAME, groupId = "es-sync-group")
public void consume(String message) {
log.info("接收到 Kafka 消息: {}", message);
try {
// 1. 解析 Canal JSON 消息
CanalMessageDTO canalMessage = objectMapper.readValue(message, CanalMessageDTO.class);
// 简单校验,确保是 books 表的数据
if (!"books".equals(canalMessage.getTable())) {
return;
}
// 2. 根据操作类型处理
String type = canalMessage.getType();
List<Map<String, Object>> dataList = canalMessage.getData();
if (dataList == null || dataList.isEmpty()) {
log.warn("数据列表为空,忽略消息");
return;
}
// 获取主键 ID (假设 Canal 消息中 data 的第一条数据的 id 即为文档 ID)
// 注意:Canal flatMessage=true 时,data 是一个列表,通常包含一行
Map<String, Object> rowData = dataList.get(0);
String docId = String.valueOf(rowData.get("id"));
switch (type) {
case "INSERT":
handleInsert(rowData, docId);
break;
case "UPDATE":
handleUpdate(rowData, docId);
break;
case "DELETE":
handleDelete(docId);
break;
default:
log.info("未知操作类型: {}", type);
}
} catch (JsonProcessingException e) {
log.error("JSON 解析失败: {}", e.getMessage(), e);
} catch (Exception e) {
log.error("同步 ES 失败: {}", e.getMessage(), e);
}
}
/**
* 1. 新增数据:直接保存到 ES
*/
private void handleInsert(Map<String, Object> rowData, String docId) {
log.info("执行 ES 新增操作,ID: {}", docId);
Book book = convertToBook(rowData, docId);
elasticsearchRestTemplate.save(book);
}
/**
* 2. 更新数据:根据 id 删除原有文档,然后新增
*/
private void handleUpdate(Map<String, Object> rowData, String docId) {
log.info("执行 ES 更新操作(先删后增),ID: {}", docId);
// 步骤 A: 删除旧文档
// 使用 delete 方法,如果文档不存在也不会报错(根据配置可能抛异常,这里简单处理)
try {
elasticsearchRestTemplate.delete(Book.class, docId);
} catch (Exception e) {
log.warn("删除旧文档时未找到或发生异常,继续执行新增: {}", e.getMessage());
}
// 步骤 B: 新增新文档
Book book = convertToBook(rowData, docId);
elasticsearchRestTemplate.save(book);
}
/**
* 3. 删除数据:根据 id 删除文档
*/
private void handleDelete(String docId) {
log.info("执行 ES 删除操作,ID: {}", docId);
try {
elasticsearchRestTemplate.delete(Book.class, docId);
} catch (Exception e) {
log.error("删除 ES 文档失败: {}", e.getMessage());
}
}
/**
* 将 Canal 的 Map 数据转换为 Book 实体
*/
private Book convertToBook(Map<String, Object> data, String id) {
Book book = new Book();
book.setId(id);
// 字段映射:MySQL 字段名 -> Book 属性名
// 注意:Canal 获取的数据通常是 Object 或 String,需要确保类型匹配
book.setNameText((String) data.get("name"));
book.setAuthor((String) data.get("author"));
// 处理数值类型转换
Object scoreObj = data.get("score");
if (scoreObj != null) {
book.setScore(Float.valueOf(scoreObj.toString()));
}
book.setCommentText((String) data.get("comment"));
book.setPublishTime((String) data.get("publishTime"));
return book;
}
}4.3.6. 全文检索逻辑
前端发送查询请求,后端接收到请求后,构建SearchCotroller来处理请求。
- 数据传输对象。
Java
package com.example.demo.dto;
import lombok.Data;
import java.io.Serializable;
@Data
public class BookSearchDTO implements Serializable {
// 1. 作者(精准查询)
private String author;
// 2. 关键词(用于匹配书名、摘要,分词查询)
private String keyword;
// 3. 发布时间范围开始 (格式: yyyy-MM-dd HH:mm:ss)
private String publishTimeStart;
// 4. 发布时间范围结束 (格式: yyyy-MM-dd HH:mm:ss)
private String publishTimeEnd;
// 分页参数
private Integer pageNum = 1;
private Integer pageSize = 10;
}- 核心查询逻辑实现。
Java
package com.example.demo.service;
import com.example.demo.dto.BookSearchDTO;
import com.example.demo.model.Book;
import org.elasticsearch.index.query.BoolQueryBuilder;
import org.elasticsearch.index.query.MatchQueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightBuilder;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.domain.PageRequest;
import org.springframework.data.elasticsearch.core.ElasticsearchRestTemplate;
import org.springframework.data.elasticsearch.core.SearchHit;
import org.springframework.data.elasticsearch.core.SearchHits;
import org.springframework.data.elasticsearch.core.query.NativeSearchQuery;
import org.springframework.data.elasticsearch.core.query.NativeSearchQueryBuilder;
import org.springframework.stereotype.Service;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
@Service
public class BookService {
@Autowired
private ElasticsearchRestTemplate elasticsearchRestTemplate;
/**
* 综合搜索接口
*/
public List<Map<String, Object>> searchBooks(BookSearchDTO searchDTO) {
List<Map<String, Object>> resultList = new ArrayList<>();
// 1. 构建查询条件
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
// === 条件 A: 作者精准查询 ===
if (searchDTO.getAuthor() != null && !searchDTO.getAuthor().trim().isEmpty()) {
// 注意:author 是 text 类型,精准查询必须使用 .keyword 字段
boolQuery.filter(QueryBuilders.termQuery("author.keyword", searchDTO.getAuthor()));
}
// === 条件 B: 书名、摘要 分词查询 ===
if (searchDTO.getKeyword() != null && !searchDTO.getKeyword().trim().isEmpty()) {
MatchQueryBuilder matchQuery = QueryBuilders.matchQuery("nameText", searchDTO.getKeyword())
.analyzer("ik_max_word")
.minimumShouldMatch("75%"); // 可选:控制匹配度
// 也可以同时查询 commentText,使用 multiMatchQuery
// 这里为了演示简单,假设主要查书名
boolQuery.must(QueryBuilders.multiMatchQuery(searchDTO.getKeyword(), "nameText", "commentText")
.analyzer("ik_max_word"));
}
// === 条件 C: 发布时间范围查询 ===
if (searchDTO.getPublishTimeStart() != null || searchDTO.getPublishTimeEnd() != null) {
boolQuery.filter(QueryBuilders.rangeQuery("publishTime")
.gte(searchDTO.getPublishTimeStart())
.lte(searchDTO.getPublishTimeEnd())
.format("yyyy-MM-dd HH:mm:ss")); // 指定日期格式
}
// 2. 构建高亮
HighlightBuilder highlightBuilder = new HighlightBuilder();
highlightBuilder.preTags("<font color='red'>"); // 高亮前缀
highlightBuilder.postTags("</font>"); // 高亮后缀
highlightBuilder.field("nameText"); // 书名高亮
highlightBuilder.field("commentText"); // 摘要高亮
// 3. 组装查询对象
NativeSearchQuery searchQuery = new NativeSearchQueryBuilder()
.withQuery(boolQuery)
.withHighlightBuilder(highlightBuilder)
.withPageable(PageRequest.of(searchDTO.getPageNum() - 1, searchDTO.getPageSize()))
.build();
// 4. 执行查询
SearchHits<Book> searchHits = elasticsearchRestTemplate.search(searchQuery, Book.class);
// 5. 处理结果(合并高亮字段到原始数据中)
for (SearchHit<Book> hit : searchHits.getSearchHits()) {
Book content = hit.getContent(); // 原始数据
Map<String, List<String>> highlightFields = hit.getHighlightFields(); // 高亮数据
// 将高亮结果覆盖原始字段,方便前端直接展示
// 如果高亮字段存在,则替换
if (highlightFields.containsKey("nameText")) {
content.setNameText(highlightFields.get("nameText").get(0));
}
if (highlightFields.containsKey("commentText")) {
content.setCommentText(highlightFields.get("commentText").get(0));
}
// 这里简单演示将对象转为 Map返回
Map<String, Object> sourceMap = elasticsearchRestTemplate.getObjectMapper().convertValue(content, Map.class);
resultList.add(sourceMap);
}
return resultList;
}
}5. 总结
通过上述技术架构,实现了业务数据库与搜索引擎的解耦。MySQL 负责事务性数据存储,ES 负责高性能检索,Kafka 充当缓冲和削峰角色,Canal 保证了数据的实时流动。该方案不仅能支撑亿级数据的毫秒级检索,还能有效应对高并发写入场景,是企业级全文检索系统的标准答案。