最近在整理回顾对小龙虾openclaw的关注、学习和使用时,第一反应是让AI根据主题帮我写材料,再让AI针对这个主题提一些问题和回答。
这种借助AI来加速了解和学习一样东西的方案,据我观察,从企业CEO到中小学生都有在使用,使用的工具从NotebookLM到豆包千问都有。
我立马就让AI快速生成了一堆文档,形式上从md到html再到ppt都有,主题上从整体框架、模块拆解、分模块deep dive、业界对比、人机对比、常见问题挑战和解法思路等等。
但我转念一想,觉得人生重在体验,有意思的内容还是要在大脑里留痕,而不是被AI管道化。
所以我决定从自己的思考实践出发,记录下:
-
对小龙虾的关注变化
-
对小龙虾的了解学习和使用
-
对小龙虾带来的变化的个人理解和观察
#1 信息爆炸时代,如何关注信息?从clawdbot到openclaw,我对小龙虾的关注变化
春节前,在AI狂飙、人人FOMO、一天没上网就out、要离开电脑或者token没用完就想着多给AI布置任务的时代,我开始觉得人的注意力才是最宝贵的资源 ------ 全都跟等于全都没跟,需要选择注意哪些、不注意哪些。
比如春节前的某天,github trending第一的是名叫WiFi DensePose的项目,号称可以"用WiFi无线电波实时分析屋内人体姿势、监测生命体征和数据",star曲线直线攀升。我思考了几秒,就选择不关注。后来这个项目也无声无息了。
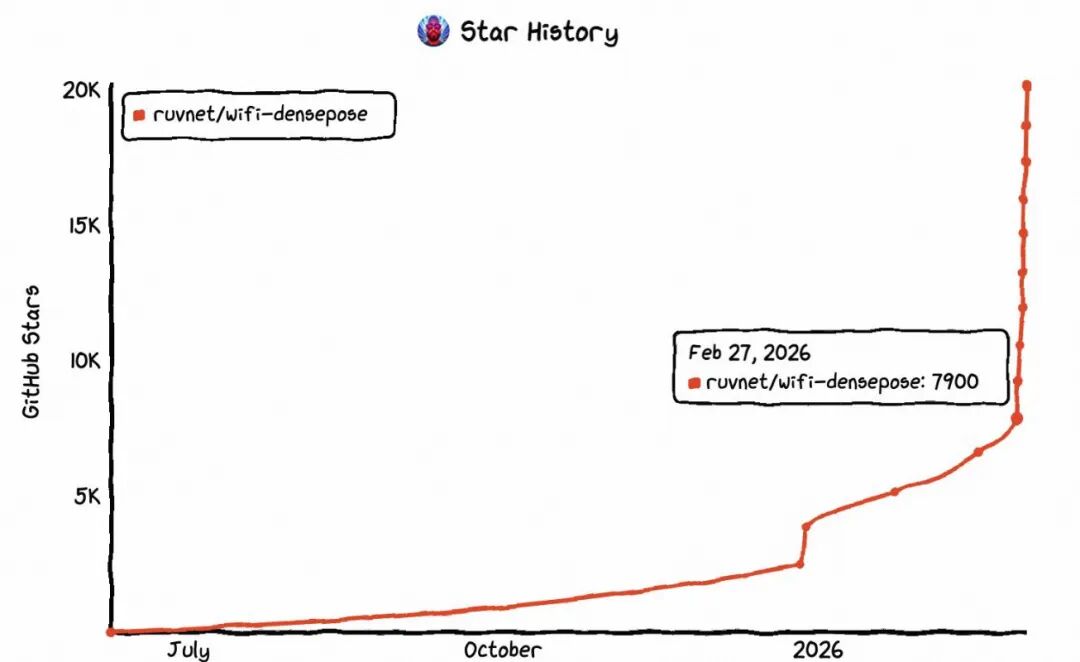
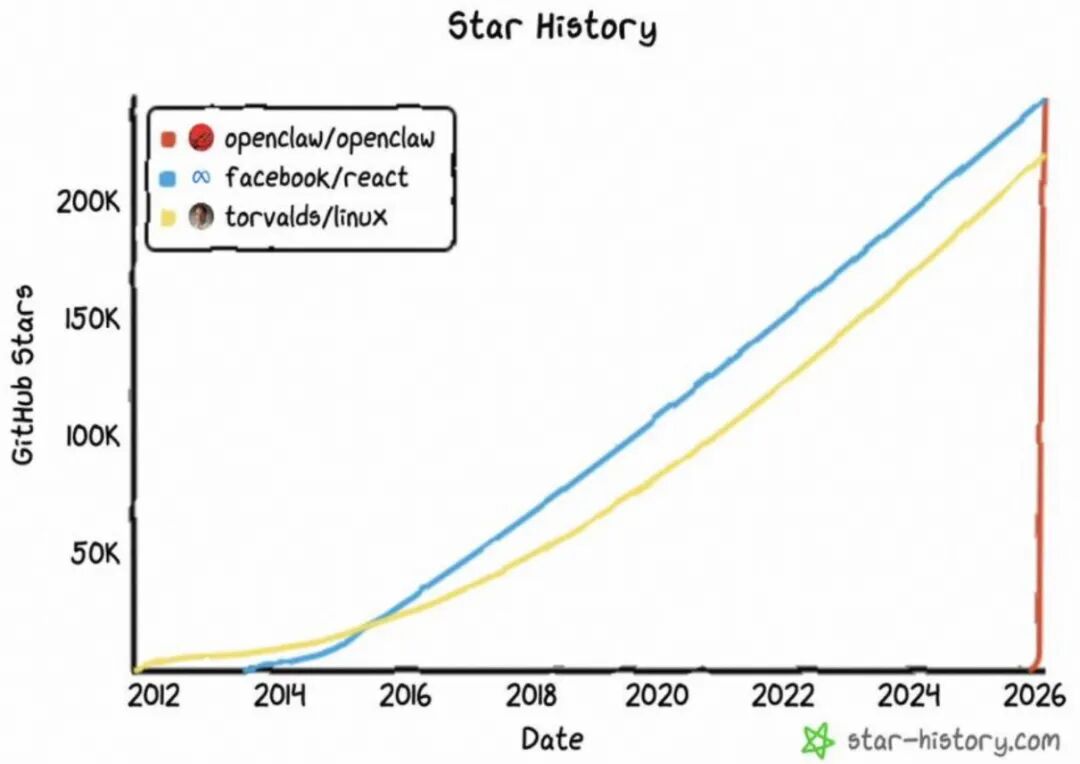
图例:某天github trending第一的项目wifi-densepose,和github历史最快第一的openclaw。
那怎么选择注意哪些、不注意哪些呢?baoyu写了一篇四象限减法的文章可以作为参考:
• 越能帮助提升生产力的、知识保鲜期越久的,越值得投入注意力。
• 离生产力越远、知识保鲜期越短的可以过滤。
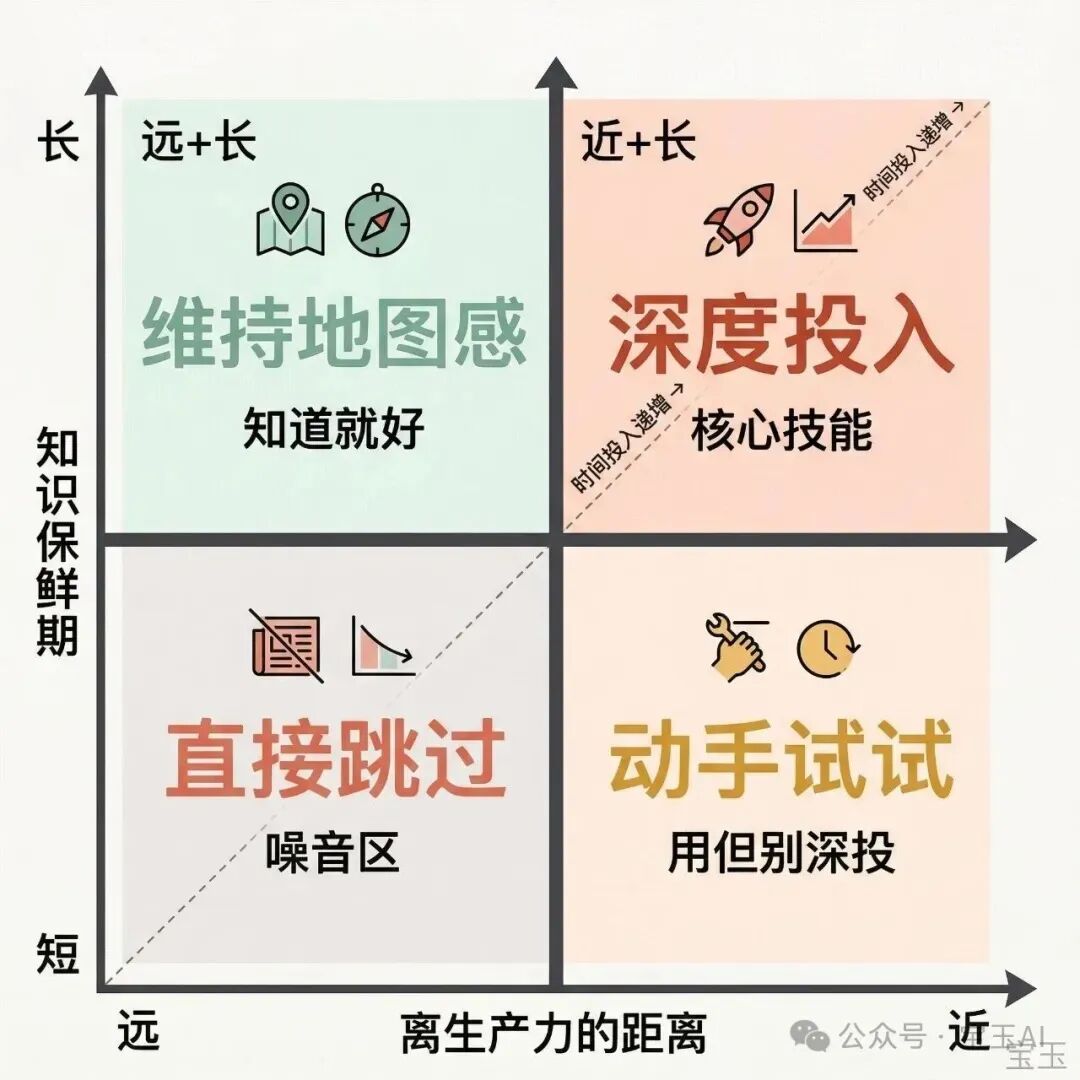
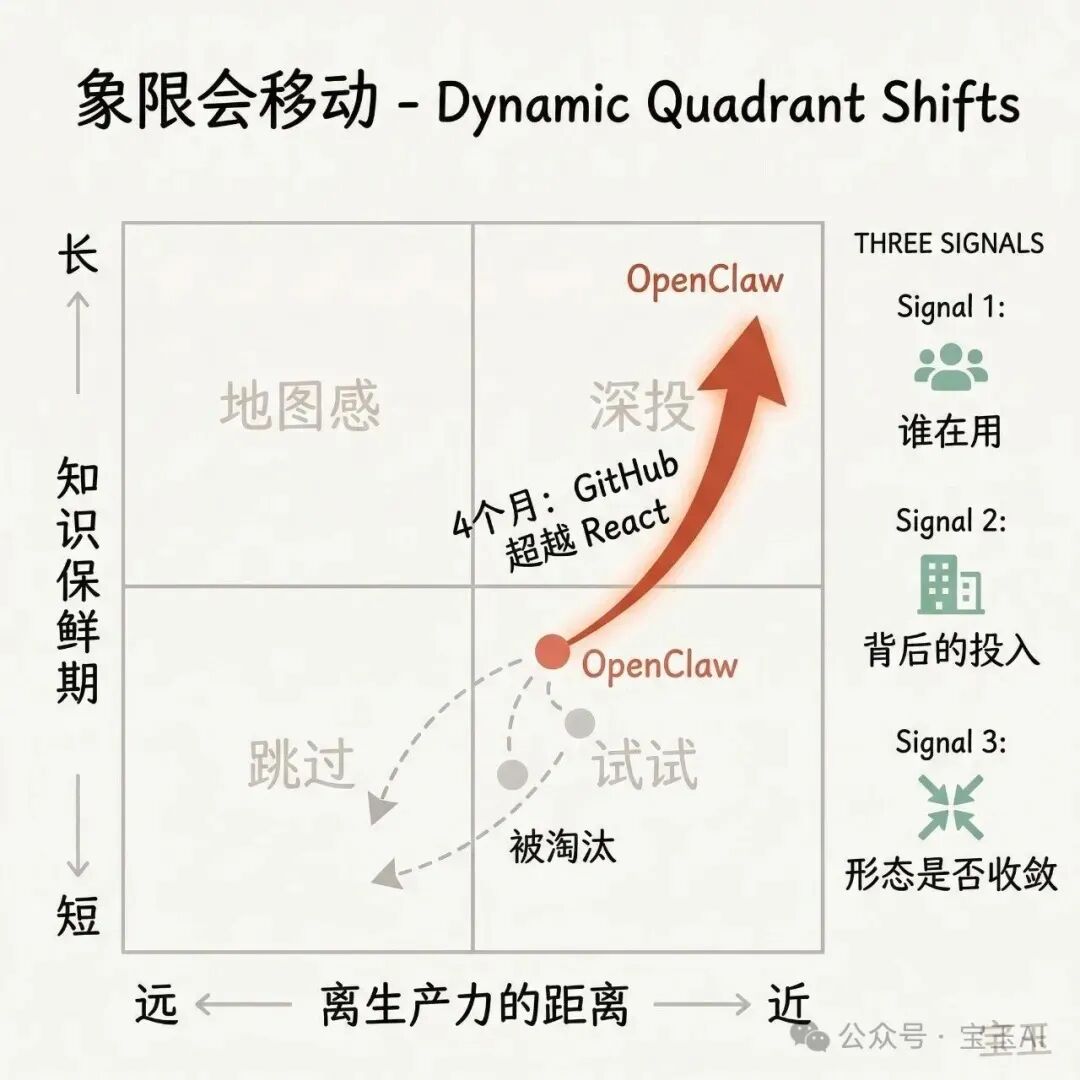
但不是绝对的,一样东西会在四象限中发生变化。比如🦞
-
春节期间,还处于左上象限"地图感",我主要是关注傅盛的龙虾日记。印象最深刻的是他在医院病床上,让龙虾写脚本爬了全公司的组织架构和员工通讯录,并根据每个员工的聊天会话记录定制拜年短信。我当时的反应是,不愧是CEO,要是我这么搞了,当天我就提包走人了,因为违反了公司安全守则。安全意识深入我心😂
-
节后返工,移动到"试一试"、"多投入"的区间。
开始在个人电脑上安装尝试,但感觉没太多使用场景,大部分人用来查个天气、模拟炒股不是我需要的。也让小孩体验了下,创建了个黑板报、让AI整理了下学习资料。其它要远程操控电脑 开个ssh或远程控制软件 就能操作电脑上的AI工具。只要通道建立了,后面就是coding agent的事了。
工作电脑上,我选择了qoderwork作为第一批内测用户,体感还不错。安全,还是安全考虑,我觉得现有的安全规章和先进的AI模型生产力之间已经存在矛盾了。
和其他人交流🦞使用案例:①有公司开始让龙虾整理历史工单和产品文档,让AI自动答疑;②有多家创业公司让龙虾自动整理邮箱、判断并写回复草稿。
#2 对小龙虾的了解学习和使用
#2.1 为什么openclaw这么火?
细想一下,上面那些案例一定要用龙虾来完成吗?显然不是,用coding agent就能做到。
那为什么是龙虾带火起来的呢?我理解首先是产品概念:
-
产品理念符合大众/非技术圈对"智能体"的理解和期望 ------ 我吩咐你一件事,你去完成了,而且是可以免费搭建的、属于我的私人助手。据pete所说,他这个项目做了一年多,前期是非技术圈的朋友更感兴趣,技术圈的人可能会觉得这些技术组件/要素我都有解法、而且都在用了,反应比较淡。
-
时间节点因素,为什么现在你吩咐一件事,它就能完成了?之前吩咐AutoGPT它却完成不了?到了2026年初,coding agent能力跨过了临界点,遇到缺少的工具,它可以自己写代码添加工具,具备自主增强和进化的能力。
-
社会氛围因素,AI时代群体性FOMO,企业老板对7x24数字员工的期待,叠加国外铺很广的Agent广告宣传和国内千问豆包等AI功能宣传铺垫。
接着才是背后支撑的技术:
-
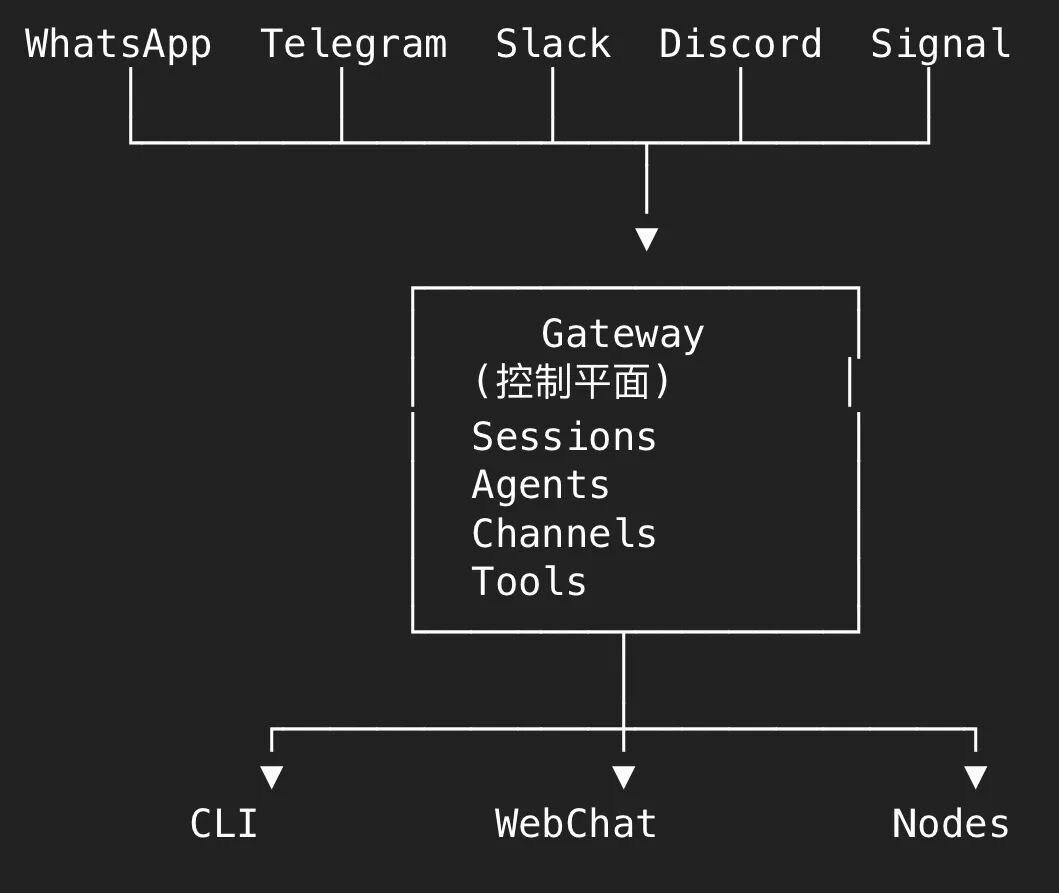
窗口:通过插件化的Channels设计,对接市面主流IM应用作为用户使用接口,让获客渠道最大化,让用户下任务零门槛化
-
大脑:经典的网关中枢型架构,和微服务的API网关一样,做归一化处理和分发,对外承接多IM设计,对内调度多Agents执行任务。
-
四肢:Agents模块负责做事:接收 Gateway 分发的请,调用 AI 模型生成回复,执行工具调用。
-
其它还有插件扩展模块、安全防护模块,但实际上默认是不安全的,所以政府部门、金融部门还有部分医疗机构都禁止安装openclaw。

#2.2 对记忆系统的了解学习
大模型天然是"无状态"的------每次对话都是一张白纸。记忆系统要解决的核心问题是:如何让 AI 在多轮交互中保持连贯性,同时不被历史噪音污染。 这个问题在 AI 编码助手、个人助理、客服等场景下尤为关键。
我之前会为Agent划分不同的工作目录(比如开多个cursor/qoder),在目录下设置 AGENTS.md、业界资料references、个人想法记录和工作进展,相当于把我的记忆上下文导出,让AI更理解我来帮我做事。
所以当我看到龙虾的SOUL.md、USER.md、MEMORY.md等设计时,眼前一亮。
龙虾会成为越来越理解用户的私人助手,主要来源于它的记忆系统:
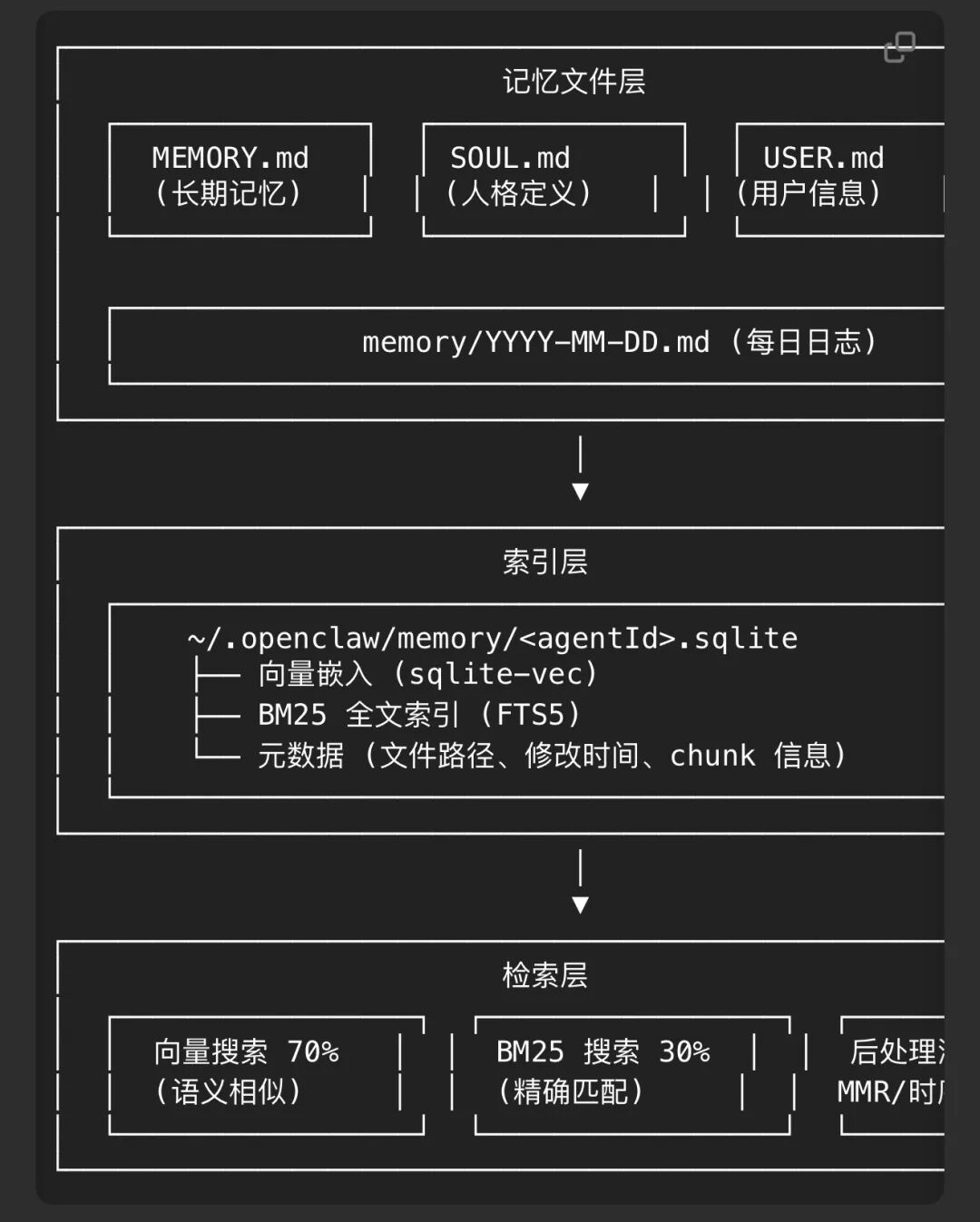
-
以.md文件为持久真相源,引入拟人化设计,包括长短期记忆和记忆衰减机制。
-
秉承本地优先原则,基于sqlite设计了语义+关键词混合召回方案。
-
配套了双阶段记忆召回工具:memory_search和memory_get,用来降低幻觉和控制召回上下文大小。
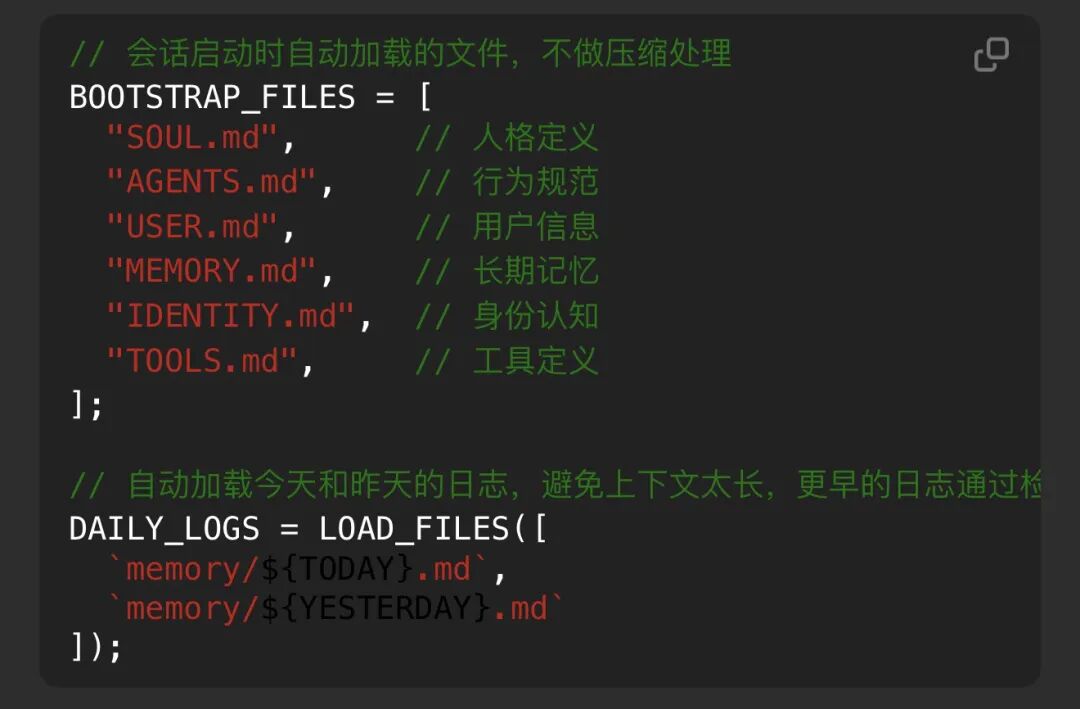
每次Agent启动或开新会话时,加载固定上下文;
当用户提问、Agent推理、工具执行需要时,会按照以下业界常见的混合搜索流程做进一步召回:
用户查询
→ Embedding(多提供商)
→ 向量搜索(sqlite-vec)+ BM25 全文搜索(FTS5)
→ 混合得分(0.7 × vector + 0.3 × text)
→ 时间衰减(30 天半衰期,常青记忆豁免)
→ MMR 重排序(λ=0.7 平衡相关性与多样性)
→ Top-K 结果返回
在召回时,会基于配套工具和提示词,做双阶段特色优化:
-
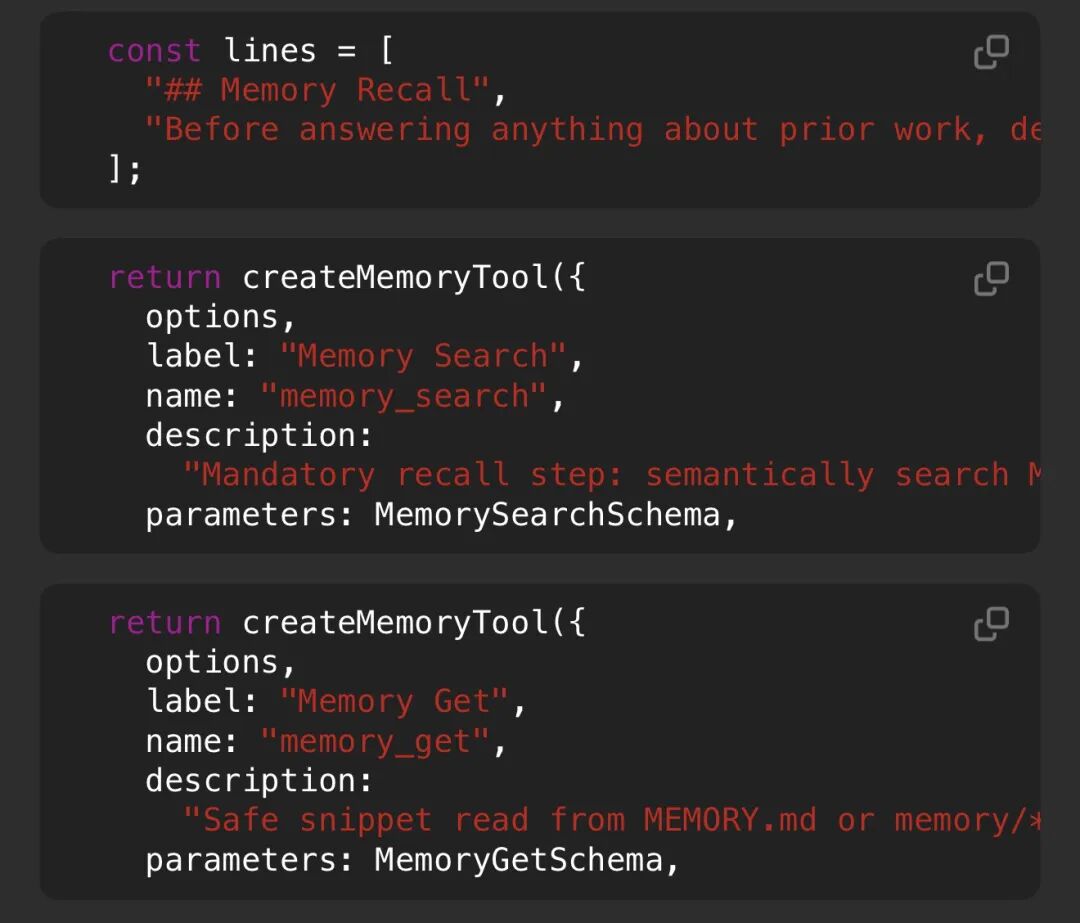
memory_search:做语义检索(hybrid:向量 + 关键词),快速找候选片段,返回文件和行号信息。
-
memory_get:在 memory_search 之后使用,仅拉取需要的lines,保持上下文精简。
-
要求在回答关于过往工作、决策、日期、人员、偏好或待办事项的问题之前,必须先对 MEMORY.md + memory/*.md(以及可选的会话记录)进行语义搜索,通过基于用户实际历史而非模型知识来降低幻觉。
当上下文过长需要压缩时,触发写入。由模型判断长期、重要或日常任务事件,分别写到MEMORY.md或者daily log。
压缩条件是openclaw套壳的pi-coding-agent来决定的,通常有两种条件触发:
-
溢出恢复:模型返回上下文溢出错误 → 压缩 → 重试。
-
阈值维护:在成功的回合后,当: contextTokens > contextWindow - reserveTokens
其中: contextWindow 是模型的上下文窗口, reserveTokens 是为提示 + 下一个模型输出保留的空间。
大致的压缩指令如下:

#2.3 对记忆系统的思考疑惑
上面的记忆系统方案看起来好像很完善,但为什么要设置 7:3 的语义和关键字权重比例,有没有对这套记忆系统的质量评测呢?
7:3 相对好回答,因为这是常见的通用RAG经验值。在不同的应用场景可能权重比例就不同,或者要叠加其它检索方案。
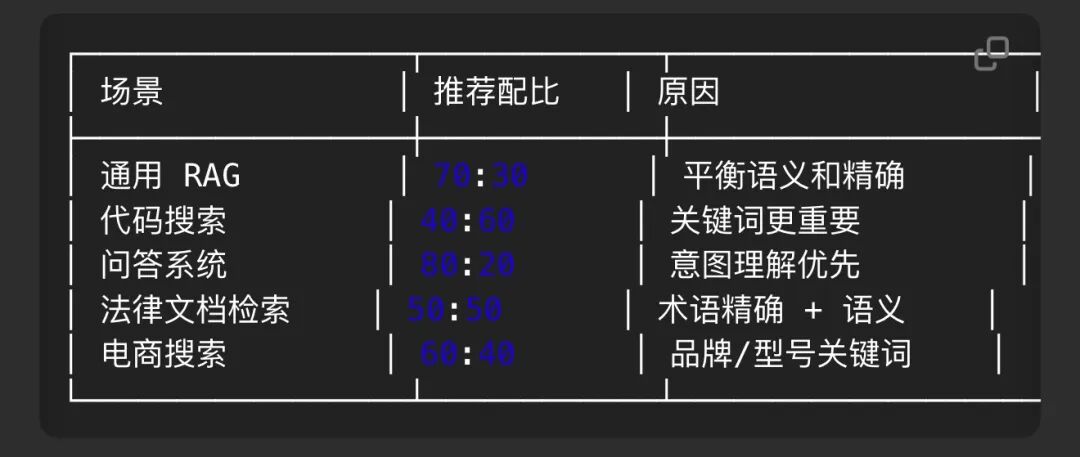
既然不同场景的权重不同,那么就应该有对应的质量评测,才好说明这个配置是有效果的。
我关注并遇到过一些AI记忆系统的问题,觉得是可以作为评测基线的:
• ChatGPT案例:2025年初,OpenAI 默认开启了 "Reference Chat History" 功能,大量用户报告 ChatGPT 严重幻觉和记忆混乱,具体表现为串用户记忆、把用户聊天记录作为回复。
• OpenClaw案例:2026年初,OpenClaw把Meta AI安全总监的几百封邮件删除了。原因是记忆压缩时,把"不要删除邮件"压缩成"删除邮件"。peter也对此做了回复,表示会进行安全优化。
• Cursor案例:用户反馈在不同会话中规则遵循度不一致,原因是用户级rules和项目级rules合并后超长被截断。
• AutoGPT案例:记住了之前的失败尝试,但没有正确标记"这是失败",每次循环都重复执行相同的失败方案,又缺少合适的中止机制,陷入烧token循环。
• Minimax M2.7案例:前一晚看到官方宣称通过模型的自我进化追平GPT-5.3-Codex、几乎追评Opus 4.6,第二天早上实测下来和Opus 4.6差距很大,写出来的代码有bug,改了几版都不对,最后删掉让Opus 4.6重写 一次就好。猜测在评测时,应该是有持续沉淀了一些正确代码的记忆,所以导致在benchmark下表现比较好,但在冷启动时表现不佳。但如果是记住失败案例呢?
• AI Coding IDE案例:在使用有记忆系统的AI IDE打磨代码模板时,多个旧版本被记录到记忆系统中,按照新的要求生成时仍然会被这些旧版本污染。
• XxClaw案例:串会话。失败案例污染:在 会话1 发现缺少 xx skill 无法完成任务,安装skill后 在会话2让执行任务,还是说 刚才已经发现缺少skill无法执行了,直接结束任务。
总结下就是:会话和用户隔离问题、上下文窗口大小限制导致的指令截断和压缩后否定翻转、未能识别标记badcase而作为记忆召回导致上下文污染。
针对这些问题,一方面是AI应用本身要进一步加强对记忆系统的安全校验机制,另一方面对用户来说:如果我们不了解背后的上下文压缩机制,可以尽量写正面提示词,避免压缩后被否定翻转,或者在结尾处重复多讲几次。

#3 对小龙虾带来的变化的个人理解
#3.1 一开源就超越,百虾大战的核心竞争力是什么
小龙虾带来的第一个变化就是百虾大战,让token更普及到千家万户。
那这么多龙虾,个人和企业会怎么选,它们有什么区别和核心竞争力?我认为是:
-
记忆系统,不同场景是有差异的,要做好也有挑战。
-
安全和品牌信任度 ------ 才能让客户愿意开放数据做深度结合,让产品越来越好用。
-
客户获取/销售能力,能够帮客户定制解决方案完成实施,快速把企业流程和经验skill/cli化,最终给客户带来收益。

当类龙虾的AI解决方案成功卖给企业或客户后,在ToB 场景需要和企业数据做深度结合,在To大C场景 能用好的记忆系统 成为越懂用户的数字助手。这就要求企业内生产关系做调整、生产资料向AI开放(cli化),也就是组织AI化。
比如现在业界不少创业新公司CTO的AI助手和他一样都具备了访问全公司资料的权限,比CTO还了解公司全局和细节。
但也有一些偏传统企业应用AI后效果不符合预期,仍然存在着AI化改造的挑战:
• 某保险公司开发的 AI 理赔系统上线后准确率仅 60%,因数据格式混乱、内容过时,需额外花 2 个月清洗数据,项目严重延期;
• 某制造企业 AI 质检系统误判率 15%(而人工仅 3%),因产线数据无法实时接入,三套老旧系统打通需半年且预算超支,系统上线三个月后"休眠";
• 某连锁超市巨头引入 AI 动态补货系统,覆盖 1200 家门店,上线后,华东区门店缺货率飙升 40%,而华南区却库存积压。
#3.2 为什么要等开源才超越,为什么是peter写出了openclaw
I don't need money. I want to have fun and impact.
Peter, 一个财务自由躺平3年觉得无聊的人,要寻求乐趣和价值。
我首先是思考自己在什么样的条件下,有可能会做出openclaw。后面觉得也不用对自己太苛求,年薪1亿美元的AI人才也没写出openclaw,硅谷那么多顶尖AI企业和人才也没人写出来。而且peter也是无压力、凭乐趣地持续做了一年多才火出圈。
为什么是peter做出了 openclaw,我个人理解:
-
越有公司和业务全局观,越有big picture上下文的,越有机会触发去做openclaw这类全景AI数字员工。越做具体工作的,概率越小。
-
未来更多是被构建出来的,而不是预测出来的。国外很多CEO都是下场开发,除了peter,还有扎克伯格也在开发CEO Agent,YC的CEO也在构建AI虚拟工程团队。国内有傅盛这个CEO例子,他能无压力、有时间、拿整个公司资料来构建。
-
peter个人的特质和经验能力,从底层架构到上层产品需求定位和开发经验,财务自由后个人痛点和兴趣驱动的持续创新底气。
#3.3 更多变化观察
AI的发展从 chatbot 到 workflow 到 agent 再到 coding agent,中间有套壳大模型的manus,现在是套壳coding agent的 openclaw。
openclaw回答了之前有人提出的一个问题:在2026年,你预测AI领域会出现哪些像coding agent这样现象级的产品?
现在大家都比较明确地感受到了,新的现象级产品,从编程领域的千亿美元市场,扩展到万亿美元的劳动力市场。
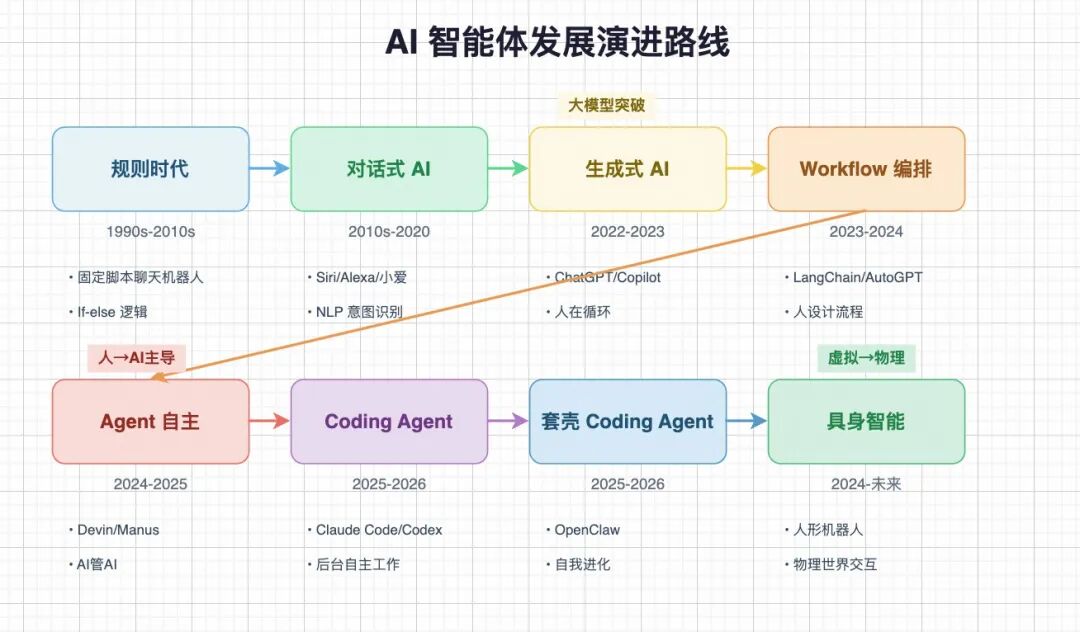
目前AI应用还处于human in the loop的阶段,因为人机转速比不匹配,创业公司的CTO都被AI评价为瓶颈,所以人类觉得更累。
接下来比较明确的发展方向就是从人管AI 向 AI管AI发展(openclaw就是),打造7x24 小时数字员工。
那么,AI越发展,如果越导致人类失业,消费力下降,那AI公司赚什么钱呢?
我问了AI这个问题,得到的回复是:
-
短期,AI先赚ToB的钱。因为一开始人类失业,是伴随着企业利润的短期增加。
-
中期,政府可能被迫介入。
-
长期,不知道。
业界AI创业公司也需要面对这个问题,他们有的回答是:我们也不知道,所以他们也不再做5年规划,只看未来3-6个月,而且策略改成"预判为辅、跟随为主"、"提高胜率而不是赔率"、"优先把确定性的事实做好"。
这不只是发生在小创业公司,而是从创业公司到OpenAI这样的领头羊。比如Anthropic只做coding agent这个确定性的事情,做到世界最好,现在倒逼OpenAI关停Sora、重新聚焦回到主线。
而我们普通个人,面对这个极大概率是和历史上其它科技革命都不一样的巨浪,也只能享受冲浪了🏄🏻 去拥抱和适应。
