redis 数据类型
文章目录
- [redis 数据类型](#redis 数据类型)
-
- String字符串
- Hash字典
- [列表 List](#列表 List)
- Set---无序集合
- [Sorted Set---有序集合](#Sorted Set—有序集合)
- Pub/Sub---发布/订阅
- 常用操作:
- Transactions---事务
- [redis 持久化](#redis 持久化)
- 备份数据
- 恢复数据
- [RDB 方式(默认)](#RDB 方式(默认))
-
- [AOF 方式](#AOF 方式)
- [redis 性能测试](#redis 性能测试)
- 相关文档
| redis 类型 | 含义 |
|---|---|
| String | 字符串 |
| Hash | 字典 |
| List | 列表 |
| Set | 集合 |
| Sorted Set | 有序集合 |
| Pub/Sub | 订阅 |
| Transactions | 事务 |
String字符串
String 数据结构是简单的 key-value 类型,value 不仅可以是 String,也可以是数字。String 类型是二进制安全的,意思是 redis 的 String 可以包含任何数据,比如 jpg 图片或者序列化 的对象。从内部实现来看其实 String 可以看作 byte 数组,最大上限是 1G 字节。
常用操作:
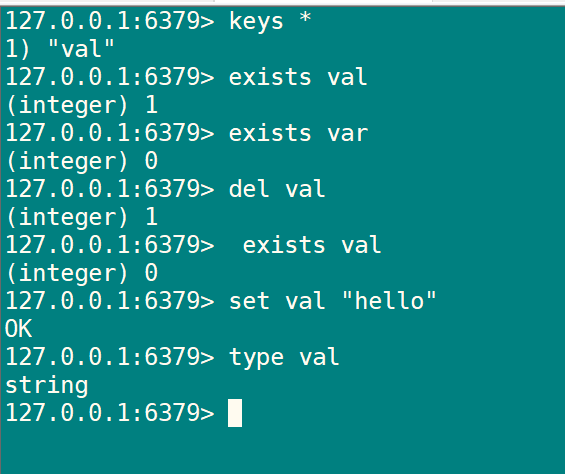
| set key value | 设置 key 对应的值为 string 类型的 value |
|---|---|
| get key | 获取 key 对应的 value 值,如果 key 不存在返回 nil |
c
redis>set val hello
redis> get val| KEYS pattern | 查找所有符合给定模式 pattern(正则表达式)的 key |
|---|---|
| EXISTS key | 返回 key 是否存在,如果存在返回 1,不存在返回 0 |
| DEL key | 删除一个 key 值 |
| TYPE key | 返回key所存储的value的数据结构类型,它可以返回string, list, set, zset 和 hash 等不同的类型。 |
| SETEX key seconds value | 设置 key 对应字符串 value,并且设置 key 在给定的 seconds 时间之后超时过期 |
|---|---|
| SETRANGE key offset value | 覆盖 key 对应的 string 的一部分,从指定的 offset 处开始,覆盖 value 的长度。如果 offset 比当前 key 对应 string 还要长,那这个 string 后面就补 0 以达到 offset。 |
| INCR key | 对存储在指定 key 的数值执行原子的加 1 操作。 |
| DECR key | 对 key 对应的数字做减 1 操作。 |
| More ActionsMSET key value | 对存对应给定的 keys 到他们相应的 values 上 |
| MGET keykey ... | 返回所有指定的 key 的 value。 |
Hash字典
redis 哈希是键值对的集合,它是是字符串字段和字符串值之间的映射,所以它们用来表示对象。

常用操作
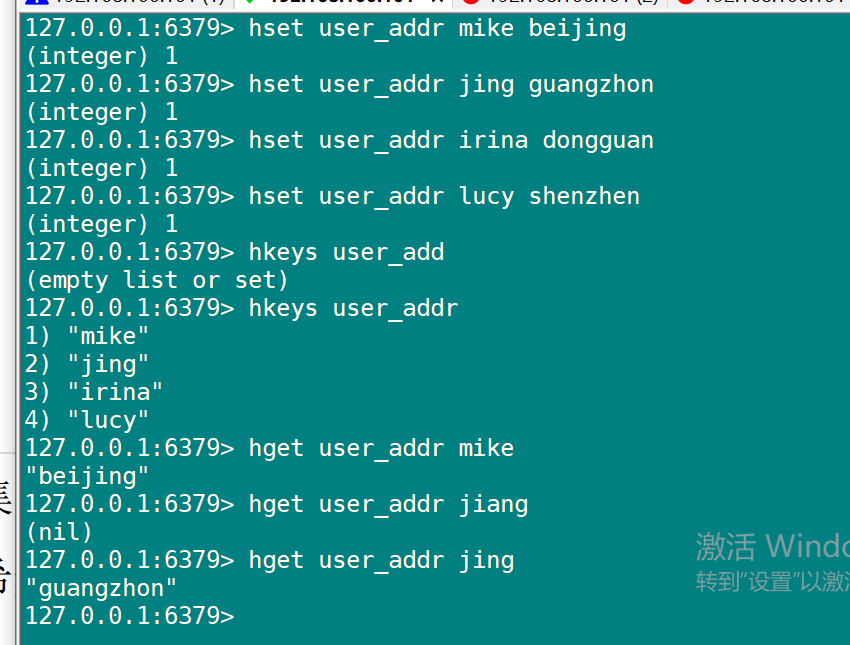
| HSET key field value | 设置 key 指定的哈希集中指定字段的值。 |
|---|---|
| HGET key field | 返回 key 指定的哈希集中该字段所关联的值。 |
| HKEYS key | 返回 key 指定的哈希集中所有字段的名字 |
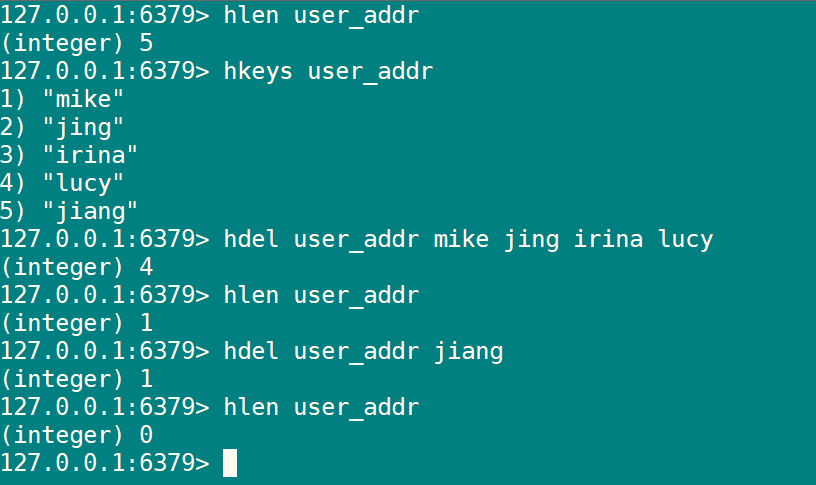
| HDEL key field field ... | 从 key 指定的哈希集中移除指定的域。 |
|---|---|
| HLEN key | 返回 key 指定的哈希集包含的字段的数量 |
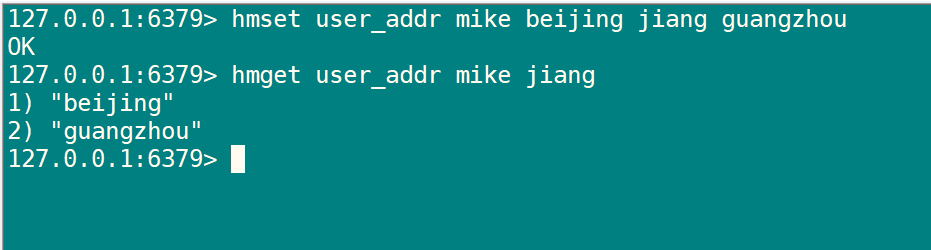
| HMSET key field value field value ... | 设置 key 指定的哈希集中指定字段的值。 |
|---|---|
| HMGET key field field ... | 返回 key 指定的哈希集中指定字段的值。 |
| HGETALL key | 返回 key 指定的哈希集中所有的字段和值。 |
|---|
列表 List
List说白了就是链表(双端链表)。使用List结构,我们可以轻松地实现最新消息排行等功能(比 如新浪微博的 TimeLine )。List 的另一个应用就是消息队列,可以利用 List 的 PUSH 操作, 将任务存在 List 中,然后工作线程再用 POP 操作将任务取出进行执行
常用操作:
| LPUSH key value value ... | 将所有指定的值插入到存于 key 的列表的头部。 |
|---|---|
| LPOP key | 移除并且返回 key 对应的 list 的第一个元素。 |
| LRANGE key start stop | 返回存储在 key 的列表里指定范围内的元素。 |
| LTRIM key start stop | 修剪(trim)一个已存在的 list,这样 list 就会只包含指定范围的指定元素 |
shell
127.0.0.1:6379> lpush it c
(integer) 1
127.0.0.1:6379> lpush it c++
(integer) 2
127.0.0.1:6379> lpush it java
(integer) 3
127.0.0.1:6379> lpush it python
(integer) 4
127.0.0.1:6379> lpysh it java
(error) ERR unknown command `lpysh`, with args beginning with: `it`, `java`,
127.0.0.1:6379> lpush it java
(integer) 5
127.0.0.1:6379> lpush it c#
(integer) 6
127.0.0.1:6379> lrange it 0 -1
1) "c#"
2) "java"
3) "python"
4) "java"
5) "c++"
6) "c"
127.0.0.1:6379>
127.0.0.1:6379> lpop it
"c#"
127.0.0.1:6379> lrange it 0 -1
1) "java"
2) "python"
3) "java"
4) "c++"
5) "c"
127.0.0.1:6379> ltrim it 0 1
OK
127.0.0.1:6379> lrange it 0 -1
1) "java"
2) "python"
127.0.0.1:6379> Set---无序集合
Set 是字符串的无序集合,集合指一堆不重复值的组合。利用 Redis 提供的 Set 数据结构, 可以存储一些集合性的数据。比如在微博应用中,可以将一个用户所有的关注人存在一个集 合中,将其所有粉丝存在一个集合。因为 Redis 非常人性化的为集合提供了求交集、并集、 差集等操作,那么就可以非常方便的实现如共同关注、共同喜好、二度好友等功能,对上面 的所有集合操作,你还可以使用不同的命令选择将结果返回给客户端还是存集到一个新的集合中。
常用操作:
| SADD key member member ... | 添加一个或多个指定的 member 元素到集合的 key 中。 |
|---|---|
| SMEMBERS key | 返回 key 集合所有的元素 |
| SREM key member member ... | 在 key 集合中移除指定的元素。 |
shell
127.0.0.1:6379> sadd key1 a b c d
(integer) 4
127.0.0.1:6379> sadd key1 e
(integer) 1
127.0.0.1:6379> smembers key1
1) "d"
2) "a"
3) "c"
4) "b"
5) "e"
127.0.0.1:6379> srem key1 e
(integer) 1
127.0.0.1:6379> smembers key1
1) "a"
2) "c"
3) "b"
4) "d"
127.0.0.1:6379> | SINTER key key ... | 返回指定所有的集合的成员的交集。 |
|---|---|
redis
127.0.0.1:6379> smembers key1
1) "a"
2) "c"
3) "b"
4) "d"
127.0.0.1:6379> smembers key2
1) "c"
127.0.0.1:6379> smembers key3
1) "a"
2) "c"
3) "e"
127.0.0.1:6379> sinter key1 key2 key3
1) "c"
127.0.0.1:6379> | SUNIONSTORE destination key key ... | 返回给定的多个集合的并集中的所有成员,而是将结果存 储在 destination 集合中。 |
|---|---|
redis
127.0.0.1:6379> smembers key1
1) "c"
2) "b"
3) "a"
4) "d"
127.0.0.1:6379> smembers key2
1) "c"
127.0.0.1:6379> smembers key3
1) "a"
2) "c"
3) "e"
127.0.0.1:6379> sunionstore bingjin key1 key2 key3
(integer) 5
127.0.0.1:6379> smembers bingjin
1) "a"
2) "e"
3) "d"
4) "c"
5) "b"
127.0.0.1:6379> Sorted Set---有序集合
和 Sets 相比,Sorted Sets 是将 Set 中的元素增加了一个权重参数 score,使得集合中的元素 能够按 score 进行有序排列,比如一个存储全班同学成绩的 Sorted Sets,其集合 value 可 以是同学的学号,而 score 就可以是其考试得分,这样在数据插入集合的时候,就已经进 行了天然的排序。另外还可以用 Sorted Sets 来做带权重的队列,比如普通消息的 score 为 1,重要消息的 score 为 2,然后工作线程可以选择按 score 的倒序来获取工作任务,让重 要的任务优先执行。
常用操作:
| ZADD key score member score member ... | 将所有指定成员添加到键为 key 有序集合(sorted set)里 面。 添加时可以指定多个分数/成员(score/member)对 |
|---|---|
| ZRANGE key start stop WITHSCORES | 返回有序集 key 中,指定区间内的成员。其中成员的位置 按 score 值递减(从小到大)来排列。 |
| ZREVRANGE key start stop WITHSCORES | 返回有序集 key 中,指定区间内的成员。其中成员的位置 按 score 值递减(从大到小)来排列 |
redis
127.0.0.1:6379> zadd score 88 mike
(integer) 1
127.0.0.1:6379> zadd score 99 jiang
(integer) 1
127.0.0.1:6379> zadd score 77 lucy
(integer) 1
127.0.0.1:6379> zrange score 0 -1
1) "lucy"
2) "mike"
3) "jiang"
127.0.0.1:6379> zrange score 0 -1 withscores
1) "lucy"
2) "77"
3) "mike"
4) "88"
5) "jiang"
6) "99"
127.0.0.1:6379> zrevrange score 0 -1 withscores
1) "jiang"
2) "99"
3) "mike"
4) "88"
5) "lucy"
6) "77"
127.0.0.1:6379> Pub/Sub---发布/订阅
Pub/Sub 从字面上理解就是发布(Publish)与订阅(Subscribe)。发件人(在 Redis 中的术语称为 发布者)发送邮件,而接收器(订户)接收它们。信息传输的链路称为通道。Redis 一个客户端 可以订阅任意数量的通道。
在 Redis 中,你可以设定对某一个 key 值进行消息发布及消息订阅,当一个 key 值上进行 了消息发布后,所有订阅它的客户端都会收到相应的消息。这一功能最明显的用法就是用作 实时消息系统,比如普通的即时聊天、群聊等功能。 常用操作:
| SUBSCRIBE channel channel ... | 订阅给指定频道的信息。一旦客户端进入订阅状态,客户 端就只可接受订阅相关的命令。 |
|---|---|
| PUBLISH channel message | 将信息 message 发送到指定的频道 channel |
启动一个客户端订阅一个主题:
redis
127.0.0.1:6379> subscribe mike
#这里可以立即收到
Reading messages... (press Ctrl-C to quit)
1) "subscribe"
2) "mike"
3) (integer) 1
1) "message"
2) "mike"
3) "hello redis"
#发布 hello redis
127.0.0.1:6379> publish mike "hello redis"
(integer) 1
127.0.0.1:6379> Transactions---事务
redis 事务允许一组命令在单一步骤中执行。事务有两个属性:
- 在一个事务中的所有命令作为单个独立的操作顺序执行。在 Redis 事务中的执行过程中 而另一客户机发出的请求,这是不可以的。
- redis 事务是原子的。原子意味着要么所有的命令都执行,要么都不执行。
redis 事务由指令 MULTI 发起的,之后传递需要在事务中和整个事务中,最后由 EXEC 命 令执行所有命令的列表。
| MULTI | 标记一个事务块的开始。 随后的指令将在执行 EXEC 时作为一个原子执行 |
|---|---|
| EXEC | 执行事务中所有在排队等待的指令并将链接状态恢复到正常。 |
redis
127.0.0.1:6379> multi
OK
127.0.0.1:6379> set foo hi
QUEUED
127.0.0.1:6379> set fun hello
QUEUED
127.0.0.1:6379> get foo
QUEUED
127.0.0.1:6379> get fun
QUEUED
127.0.0.1:6379> exec
1) OK
2) OK
3) "hi"
4) "hello"
127.0.0.1:6379> redis 持久化
redis 虽然是缓冲数据库,但也提供了持久化的方案。
备份数据
客户端敲 save 命令,即可创建当前 redis 数据库的备份,如果成功,自动在服务器启动所 在目录生成 dump.rdb 文件。可使用 CONFIG 命令查看 redis 服务器启动目录。
redis
127.0.0.1:6379> set mike jiang
OK
127.0.0.1:6379> get mike
"jiang"
#查看服务器启动所在目录
127.0.0.1:6379> config get dir
1) "dir"
2) "/home/deng/pageWuyou/redis-5.0.7"
127.0.0.1:6379> save
OK
127.0.0.1:6379> dump.rdb 文件为 redis 加密的文件内容
恢复数据
在 dump.rdb 文件所在目录下,启动 redis 服务器,服务器自动会加载当前目录下的 dump.rdb 文件:
shell
deng@itcast:~/pageWuyou/redis-5.0.7$ redis-serverRDB 方式(默认)
RDB 方式的持久化是通过快照(snapshotting)完成的,当符合一定条件时 redis 会自动将内存 中的所有数据进行快照并存储在硬盘上。进行快照的条件可以由用户在配置文件中自定义, 由两个参数构成:时间和改动的键的个数。当在指定的时间内被更改的键的个数大于指定的 数值时就会进行快照。
- RDB 是 redis 默认采用的持久化方式
redis.conf

可以存在多个条件,条件之间是"或"的关系,只要满足其中一个条件,就会进行快照。 如 果想要禁用自动快照,只需要将所有的 save 参数删除即可。
可以通过配置 dir 和 dbfilename 两个参数分别指定快照文件的存储路径和文件名: 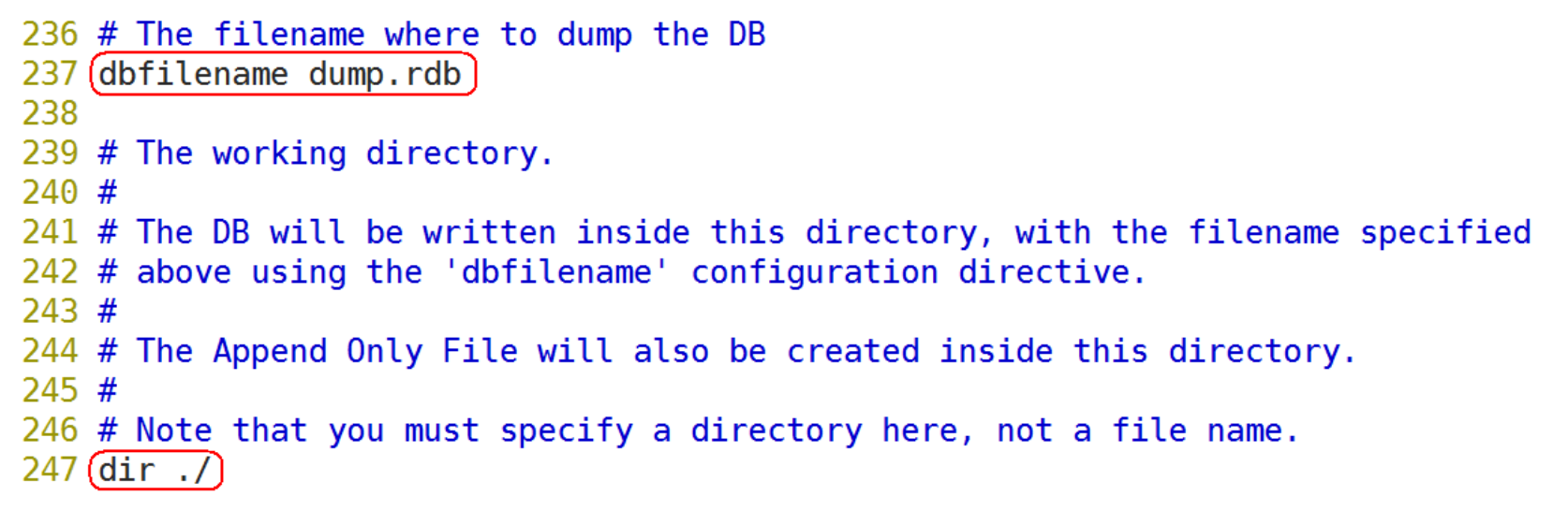
redis 实现快照的过程: redis 使用 fork 函数复制一份当前进程(父进程)的副本(子进程),父进程继续接收并处理客户 端发来的命令,而子进程开始将内存中的数据写入硬盘中的临时文件,当子进程写入完所有 数据后会用该临时文件替换旧的 RDB 文件,至此一次快照操作完成。在执行 fork 的时候操 作系统(类 Unix 操作系统)会使用写时复制(copy-on-write)策略,即 fork 函数发生的一刻父子 进程共享同一内存数据,当父进程要更改其中某片数据时(如执行一个写命令),操作系统会 将该片数据复制一份以保证子进程的数据不受影响,所以新的 RDB 文件存储的是执行 fork 一刻的内存数据。
redis 在进行快照的过程中不会修改 RDB 文件,只有快照结束后才会将旧的文件替换成新的, 也就是说任何时候 RDB 文件都是完整的。这使得我们可以通过定时备份 RDB 文件来实现 redis 数据库备份。RDB 文件是经过压缩(可以配置 rdbcompression 参数以禁用压缩节省 CPU 占用)的二进制格式,所以占用的空间会小于内存中的数据大小,更加利于传输。
除了自动快照,还可以手动发送 SAVE 或 BGSAVE 命令让 redis 执行快照,两个命令的区别 在于,前者是由主进程进行快照操作, 会阻塞住其他请求,后者会通过 fork 子进程进行快照 操作。
redis 启动后会读取 RDB 快照文件,将数据从硬盘载入到内存。根据数据量大小与结构和服 务器性能不同,这个时间也不同。通常将一个记录一千万个字符串类型键、大小为 1GB 的 快照文件载入到内存中需要花费 20~30 秒钟。
通过 RDB 方式实现持久化,一旦 redis 异常退出,就会丢失最后一次快照以后更改的所有数 据。这就需要开发者根据具体的应用场合,通过组合设置自动快照条件的方式来将可能发生 的数据损失控制在能够接受的范围。如果数据很重要以至于无法承受任何损失,则可以考虑 使用 AOF 方式进行持久化
AOF 方式
默认情况下 redis 没有开启 AOF(append only file)方式的持久化,可以在 redif.conf 配置文件中 中通过 appendonly 参数开启:

开启 AOF 持久化后每执行一条会更改 redis 中的数据的命令,redis 就会将该命令写入硬盘 中的 AOF 文件。在启动时 redis 会逐个执行 AOF 文件中的命令来将硬盘中的数据载入到内 存中,载入的速度相较 RDB 会慢一些。
AOF 文件的保存位置和 RDB 文件的位置相同,都是通过 dir 参数设置的,默认的文件名是 appendonly.aof,可以通过 appendfilename 参数修改:

配置写入 AOF 文件后,要求系统刷新硬盘缓存的机制:

redis 性能测试
测试存取大小为 100 字节的数据包的性能:redis-benchmark -h 127.0.0.1 -p 6379 -q -d 100
shell
deng@itcast:~/pageWuyou/redis-5.0.7$ redis-benchmark -h 127.0.0.1 -p 6379 -q -d 100 100 个并发连接,100000 个请求,检测 host 为 localhost 端口为 6379 的 redis 服务器性 能:redis-benchmark -h 127.0.0.1 -p 6379 -c 100 -n 100000
shell
deng@itcast:~/pageWuyou/redis-5.0.7$ redis-benchmark -h 127.0.0.1 -p 6379 -c 100 -n 100000 相关文档
-
官方网站:https://redis.io/
-
中文官方网站:http://www.redis.cn/
-
W3Cschool教程:https://www.w3cschool.cn/redis/redis-install.html
-
Redis教程:https://www.redis.net.cn/
数据类型相关操作指令参考文档: http://redis.cn/commands.html