1. 进程切换的基本概念
进程切换,也叫上下文切换,是指操作系统为了让多个进程 "同时" 运行,暂停当前正在 CPU 上执行的进程,保存其运行现场,再恢复另一个就绪进程的运行环境并让它开始执行的过程。每个进程都有独立的运行信息(如寄存器值、程序计数器、内存地址等),这些信息统称为进程上下文。切换时,内核会先将旧进程的上下文保存到 PCB 中,再从 PCB 里加载新进程的上下文,使 CPU 无缝切换到新进程执行。进程切换是操作系统实现并发、多任务的核心机制,保证了多个进程可以分时复用 CPU,让系统看起来能够同时运行多个程序。
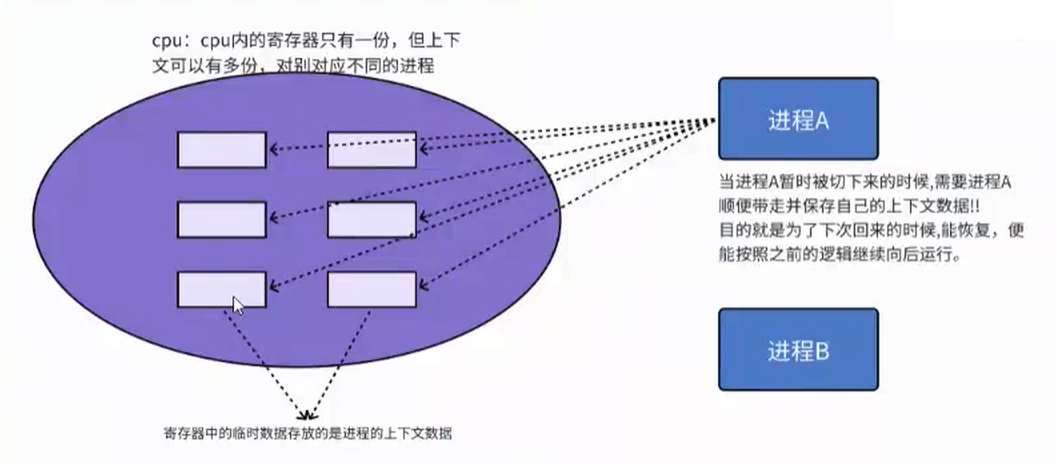
进程切换能帮我们解决的最主要问题就是:并发问题。
并发 是指多个任务在宏观上同时进行,但在微观上,CPU 会不断切换执行这些任务,同一时刻实际只有一个任务在运行,它是通过快速切换实现的 "伪同时"。
同时,和并发的名称相似的,还有一个并行问题:
并行 是指多个任务在同一时刻真正同时运行,必须依靠多个 CPU 核心或多个处理器才能实现,是物理层面的真实同时执行。
二者的核心区别在于:同一时刻是否有多个任务真正在同时运行。并发依赖任务切换,并行依赖多核硬件。
可以用吃饭和喝水来理解:
并发:你只有一张嘴,先喝一口水,再吃一口饭,不断交替进行,看起来像是同时在吃喝,实际同一时刻只做一件事。
并行:你一张嘴吃饭,另一个人同时帮你喝水,两件事在同一时刻真正一起完成。
2. 组织进程
在正式讲解之前,我们先介绍一个场景:
比如说有一个结构体struct A,里面存储了 int a, int b, double c, float d,现在我只知道c的地址,但是我又想知道这个结构体的起始地址,该怎么求呢?我们可以使用 &((struct A)*0 -> c) 这一行代码去获取A这个结构体的起始地址,逻辑如下:
&((struct A)*0 -> c) 的作用不是获取真实地址,而是计算:成员 c 在结构体 struct A 中的偏移量(字节数)。
(struct A)*0相当于是把 地址 0 强制转换成 struct A* 类型的指针。即:假设结构体的起始地址就是 0x00000000 。所以再用箭头指向c,表示访问这个结构体中的c变量,因为结构体起始地址是 0,所以成员的地址 = 偏移量。
struct A {
int a; // 4字节
int b; // 4字节
double c; // 8字节
float d; // 4字节
};从第 0 位置开始,a变量存储 4 个字节,b 变量存储 4 个字节,所以到c位置开头的时候,c的起始位置就是第 8 个字节,所以 &((struct A)*0 -> c) 的结果就是 8 。
然后再看我们的前提就是:只知道c的地址,所以我们就可以用c的地址减去 8 ,就可以推算出结构体的地址。
这是一种利用空指针计算结构体成员偏移量 的经典方法,通过已知成员的地址,反向推导出整个结构体的起始地址。
而在Linux操作系统中,所有的 task_struct 都是以双链表的形式存在:
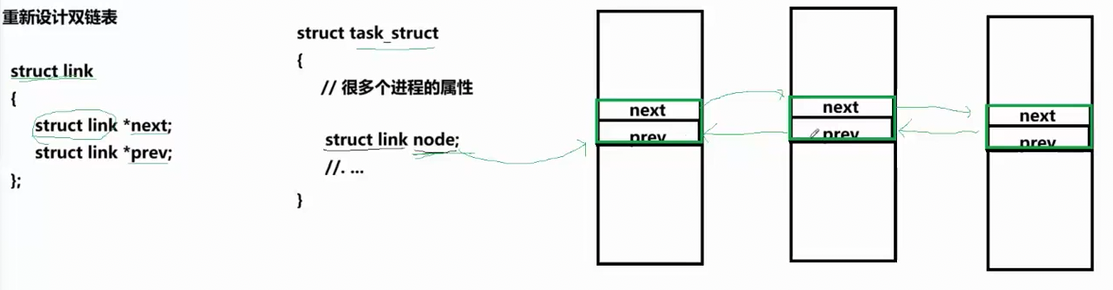
并且这个 struct link 中,只存储 next 和 prev 指针,是一个纯表示地址的结构体,不含任何数据。相当于是,Linux内核使用通用双向链表节点结构 struct link,并将其作为成员嵌入到 task_struct 内部。所有进程的 task_struct 通过各自的 node 成员,以双向链表的形式串联起来,形成全局进程链表。
而之所以这样去设计,而不是像普通链表那样直接去访问 task_struct 的地址,是因为Linux内核当中实际存在大量的结构体,如果要为每一个结构体都去写一个对应 struct link xxx 的节点,那样不仅代码量会很大,而且很冗余,也不好维护。所以就设计出这样通用的一个链表节点。
cpp
//Linux内核中大致的实际情况
struct list_head
{
struct list_head *next, *prev;
};
struct task_struct {
// 进程各种信息
struct list_head tasks; // 链表1
struct list_head run_list; // 链表2
struct list_head children; // 链表3
};这样将地址节点直接嵌入在task_struct中,就可以利用我们刚刚讲的方法去获取task_struct的地址。不过在Linux内核里,有专门为这个逻辑设计的宏:
cpp
// 通过链表节点 node,找到整个 task_struct 的地址
struct task_struct *ts = container_of(node, struct task_struct, tasks);3. Linux 2.6 O(1) 调度队列
关于调度队列我们在前面的文章中提过,现在我们要来详细的谈一谈其中的算法和详细内容:
这是一张关于操作系统中调度队列的表:
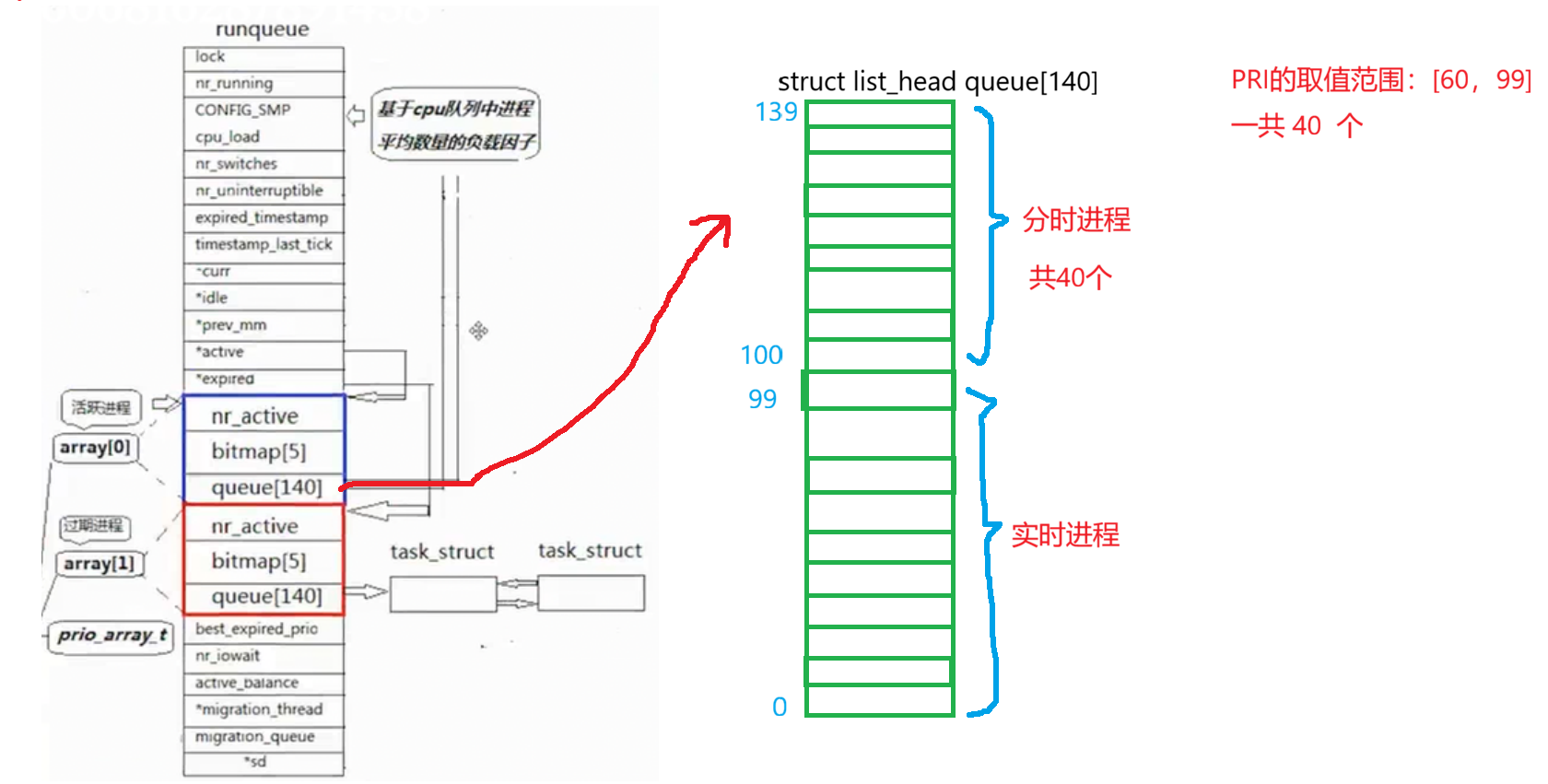
3.1 prio_arry
我们先介绍一下最关键的一个东西:prio_arry
1. queue 140 ------ 按优先级分组的进程队列
作用 :同一优先级的进程挂在同一个双向链表 上,按FIFO顺序等待执行。
优先级划分:
queue0~queue99 :实时进程(静态优先级,高优先级,暂不展开)
queue100~queue139 :普通进程 (对应 nice -20~+19;数值越小优先级越高)
组织方式 :每个 queue[i] 是链表头,进程通过 task_struct->run_list 链入对应队列。
2. bitmap 5 ------ 快速查找的 "优先级地图"
作用 :每一位对应一个优先级 ;位 = 1 → 该队列非空;位 = 0 → 队列为空。
原理:5 个无符号长整型(共 160 位)覆盖 140 个优先级。
例:优先级 100 对应位图第 100 位 → 该位 = 1 → 队列有进程。
关键优化 :调度器用位运算指令 (如 find first bit)O (1) 直接找到最高优先级,无需遍历 140 个队列。
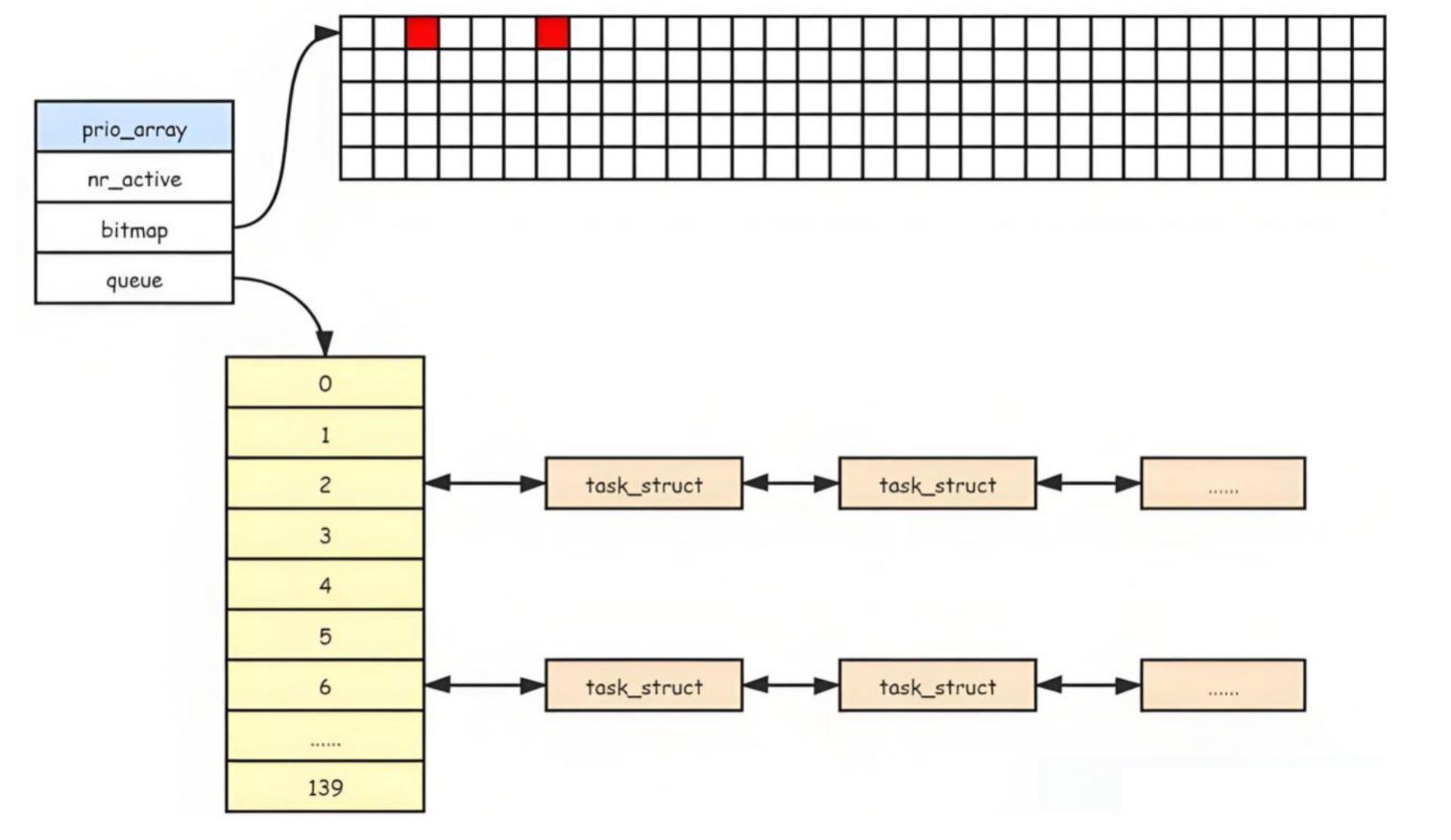
3. nr_active ------ 数组内进程总数
作用 :记录当前 prio_array 中所有队列的进程总数。
用途:
快速判断数组是否为空(nr_active == 0)。
调度器负载统计、调度决策的依据。
接着我们要探讨一下实时进程和分时进程的关系:
3.2 实时进程和分时进程
进程优先级分为两大类:实时进程优先级 与分时进程优先级,二者在取值范围、调度策略和抢占规则上完全不同。
实时进程优先级的取值范围为 0 到 99,数值越大代表优先级越高,这类进程用于对响应速度要求极高的场景,调度器会严格按照优先级高低进行调度,高优先级实时进程可以无条件抢占任何低优先级实时进程以及所有分时进程,同一优先级的实时进程则可按照先进先出或时间片轮转方式执行,一旦开始运行便会持续占用 CPU 直到主动放弃或被更高优先级进程抢占。
分时进程也就是普通进程,其优先级范围从 100 到 139,共 40 个优先级等级,与用户空间的 nice 值一一对应,nice 值越小对应的内部优先级数值越小、优先级越高,分时进程之间采用时间片轮转机制,每个进程分配固定长度的时间片,时间片耗尽后便进入过期队列等待下一轮调度。
在整体调度秩序上,所有实时进程的优先级都严格高于分时进程,调度器会优先保证实时进程执行完毕,只有当不存在可运行的实时进程时,才会调度分时进程,这种设计既满足了系统对实时性任务的严苛要求,又能保证普通进程在公平机制下有序运行。
3.3 调度逻辑
下面是这个调度队列的具体逻辑:
在 Linux 2.6 经典 O (1) 调度器中,每个 CPU 都拥有一个独立的运行队列 runqueue,用于管理当前可被调度执行的进程,其核心由 active 和 expried 两个关键结构构成。active 是指向活跃优先级数组 prio_array 的指针,该数组中存放着:当前拥有剩余时间片、可以直接参与调度的进程;expried 则是指向过期优先级数组 prio_array 的指针,用于存放时间片已经耗尽、需要等待下一轮调度周期才能再次运行的进程,
在 Linux 2.6 经典 O (1) 调度器的运行队列设计中,为了在保证高优先级进程优先执行的同时避免低优先级进程被饿死,操作系统选择进程执行的完整逻辑围绕运行队列中的 active 活跃数组与 expried过期数组展开。
系统中每个可运行进程都会依据其优先级,被归入对应优先级编号的双向链表,而调度器只会从 active数组中挑选下一个执行的进程,具体流程为:
-
首先通过 active数组内的优先级位图快速定位当前优先级最高且非空的队列,再从该队列头部取出进程执行;
-
当一个进程时间片耗尽后,会从 active 数组中移除,并加入 expired 数组中对应的优先级队列等待下一轮调度,直到 active 数组内所有进程都执行完毕,系统才会通过直接交换指针 的方式完成数组翻转,让原本的 expired 数组成为新的 active数组,所有等待的进程得以进入新一轮调度。
但是,如果:一个进程的优先级是61,当要执行它的时候,这时进来了一个新的进程,它的进程优先级是60,那这个时候要先去执行优先级为60的进程吗?那如果源源不断地有优先级为60的进程进来,那优先级为61的进程就一直得不到执行,就被"饿死了"。所以:
- 针对可能出现的饿死问题,O (1) 调度器采用了关键的防护机制:所有新创建或被唤醒的进程,无论优先级高低,都不会直接插入当前的 active 数组插队执行,而是统一进入 expired 数组对应的优先级队列,这就保证了当前 active 数组内的所有进程都能完整执行完毕,不会被源源不断涌入的更高优先级新进程持续抢占,只有等到本轮 active数组为空并完成数组翻转后,这些新进程才会参与调度。
本文到此结束,感谢各位读者的阅读,如果有讲解错误或不到位的地方,欢迎各位读者批评或指正。