【核心差异化】:
**1.真实数据驱动:**使用Cochrane/JAMA已发表RCT的真实数据,非模拟数据,可溯源至原始文献。
**2.一条主线贯穿:**从PICOS设计→PubMed检索→AI筛选→效应量计算→DL随机效应模型→森林图→漏斗图→亚组分析→敏感性分析→Results段落,两天做完完整Meta-Analysis。
**3.AI深度提效:**用Hermes Agent自动生成检索式、批量筛选文献、运行统计脚本、生成投稿级图表、撰写Results段落------亲眼见证AI把传统2周的工作压缩到2小时。
**4.代码经双轮审阅:**所有脚本经两轮代码审阅(Codex Review),Egger检验修正为加权回归(WLS)、SMD方差统一为含J²的Hedges标准公式、PRISMA计数改为动态计算,统计公式逐项验证。
**5.带走你的专属科研智能体:**你将带走一个配置好的Hermes Agent和Meta-Analysis统计Skill,利用其自进化能力,未来可一键复用到你的任何课题中。
两天完整产出
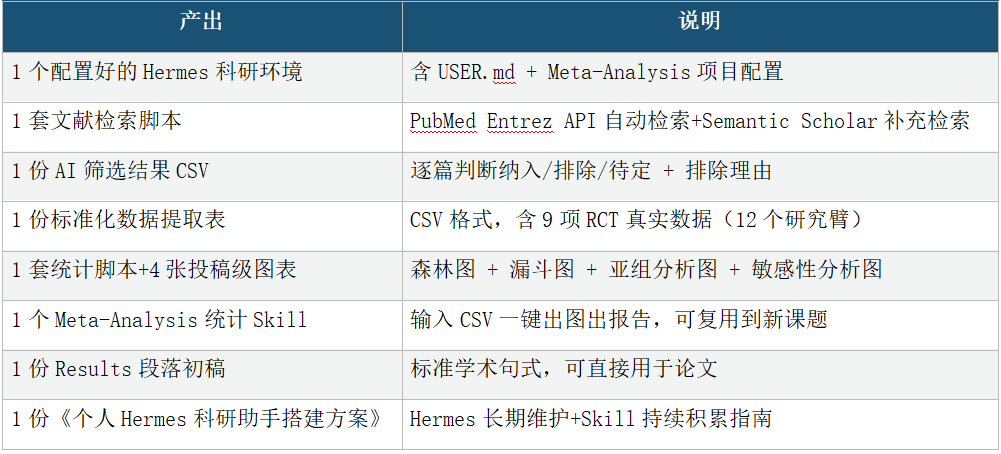
【产出图表示例】(以下均为课程真实数据生成):
▼ 森林图:运动干预对HbA1c的影响(随机效应模型)
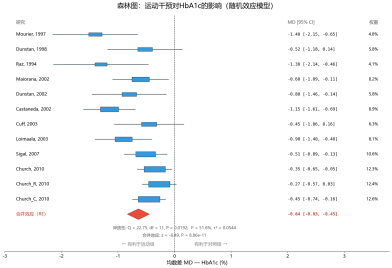
▼ 亚组分析:不同运动类型对HbA1c的影响
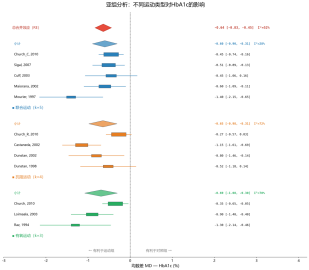
▼ 漏斗图:(含Egger加权回归检验结果)
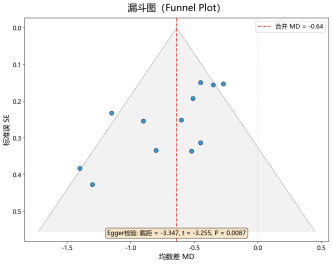
|---|---|
| 第一章:Hermes部署 + AI辅助文献检索与筛选 产出:Hermes科研环境 + 检索脚本 + 筛选结果 + 数据提取表 ||
模块一、Hermes Agent部署与科研配置
1、Hermes安装→模型接入(DeepSeek/OpenAI/Anthropic)→验证运行
2、模型选择策略:Opus写作/Sonnet编码/Haiku批量筛选/Ollama本地
3、配置USER.md:让Hermes从通用助手变成"你的课题组成员"
4、备用方案:Claude Code替代+预录数据集兜底
模块二、PICOS设计与检索策略
1、AI辅助检索策略设计:Hermes生成PubMed检索式+MeSH词扩展
2、检索式逻辑完整性检查
3、其他学科案例展示(大气科学、心理学、教育学)
模块三、AI自动化文献检索与初筛
1、PubMed Entrez API批量检索(Biopython) 产出:检索脚本
2、Semantic Scholar补充检索 + 去重合并
3、AI辅助标题摘要筛选(逐篇判断+排除理由) 产出:筛选CSV
4、PRISMA 2020流程图生成(matplotlib动态计算)
模块四、数据提取与效应量计算
1、数据提取表设计+AI辅助PDF数据提取
2、效应量计算:均数差(MD)+标准化均数差(Hedges'g,含J校正)
3、使用课程真实数据(9项RCT/12臂,含Church 2010三臂试验说明)
|----------------------------------------------------------------------------------|
| 第二章:统计分析+ Skill封装 + 个人落地 产出:4张投稿级图表 + 统计Skill + Results段落 + 个人方案 |
模块五、Meta-Analysis统计分析
1、DerSimonian-Laird随机效应模型(手动实现5步算法,纯numpy)
2、异质性检验:Q统计量、I²、τ²产出:统计报告
3、森林图:权重方块+合并钻石+数值标注(纯matplotlib)
4、亚组分析:按运动类型分组+组间异质性Q_between
5、漏斗图+Egger加权回归检验(正确WLS实现)
6、Leave-one-out敏感性分析 产出:4张投稿级图表
模块六、Skill封装与Hermes进化
1、将全套统计流程封装为Hermes Skill(输入CSV一键出图出报告)
2、Hermes自动优化Skill+团队共享方式
3、MCP扩展简介:Zotero文献管理、批量读PDF
模块七、AI辅助结果解读与写作
1、Hermes自动解读统计输出→生成Results段落初稿
2、标准学术句式模板(效应量+CI+P值+异质性描述)
3、AI写作边界:擅长格式化结果描述,需人工核验数值和引用
模块八、综合演练与个人落地
1、两天流程回顾:PICOS→检索→筛选→提取→统计→解读
2、大家自选题实操(60分钟):用自己的选题走全流程
3、Hermes长期维护方案:持续进化+Skill积累
4、Q&A+课后资源发放