写在前面
"现在AI这么方便,人人都是架构师。我只要把需求扔给AI,它就能自动生成CRUD代码,我为什么还要花时间设计数据库表?"
这是我最近听到的真实声音。随着GitHub Copilot、Cursor、通义灵码等AI编程助手的普及,很多开发者开始觉得:数据库设计?不就是建几张表、加几个字段吗?AI都能帮我写好了。
但现实往往事与愿违。我见过太多项目,因为初期表设计考虑不周,导致后期:
-
一个简单的需求变更,需要改5张表、重构3个接口、迁移几十万条数据
-
查询性能从毫秒级掉到秒级,加索引也无济于事------因为表结构本身就有问题
-
数据冗余、不一致、重复,业务逻辑被散落在各处,难以维护
AI可以帮你写SQL,但它无法替你做架构决策。 当需求模糊、业务边界不清、未来扩展方向不明时,AI生成的表结构往往是"看起来能跑,跑起来就崩"。
今天,我们就来聊聊数据库表设计的重要性------不是教你如何建表,而是告诉你:为什么在AI时代,这件事比以前更加重要。
一、一个真实的"翻车"案例
去年,我们接手了一个创业公司的项目。他们的核心业务是一个"社区问答平台",上线3个月,日活不到1000,但数据库已经跑不动了。
我们打开数据库一看,问题触目惊心:
问题1:一张表300个字段
用户表里有300多个字段,包括用户的基本信息、行为统计、偏好设置、第三方授权信息......全部塞在一张表里。每次查询用户信息,哪怕只需要用户名和头像,数据库也要读一整行几KB的数据。
问题2:用逗号分隔存储多值关系
一个用户可以有多个标签,设计者在一个varchar字段里用逗号存了"技术,职场,生活"。要查询所有带"技术"标签的用户,只能用LIKE '%技术%',全表扫描,索引失效。
问题3:没有主键自增,用业务字段做主键
订单表用订单号(字符串)做主键,关联查询时性能极差,而且订单号规则变更时,整个表结构都要跟着改。
问题4:枚举值用数字代替,没有注释
状态字段存0、1、2,没有人知道0代表什么。新人接手后,不敢改,不敢删,只能靠猜。
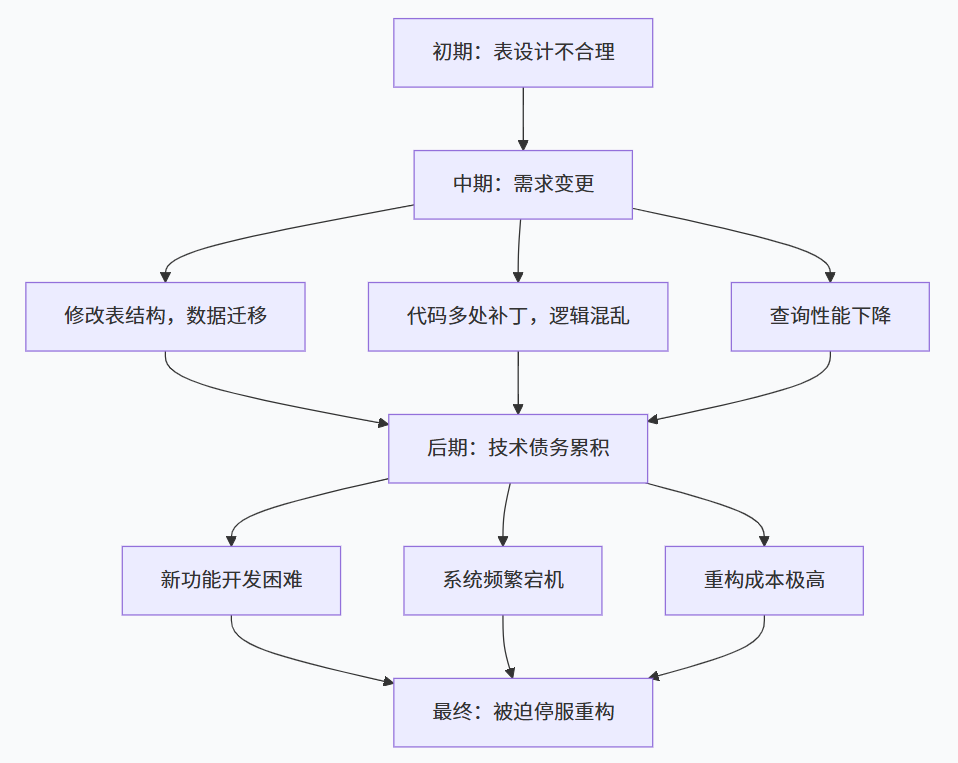
结果就是:一个简单的"按标签筛选用户"功能,需要扫描全表;一个"用户主页"接口,要读几十个字段;加上索引后,写性能又下来了。最终只能重构数据库,停服24小时迁移数据。
这个教训告诉我们:表设计阶段的偷懒,会在项目后期以10倍的成本偿还。
二、为什么AI无法替你设计好数据库表?
你可能会说:"把需求描述清楚,AI也能设计出规范的表结构啊。"
理论上是的。但实际开发中,需求往往是这样的:
"我们要做一个电商系统,有用户、商品、订单。用户能下单,订单有状态。"
这种模糊的需求,AI能设计出什么样的表?大概率是:用户表、商品表、订单表、订单商品关联表------四张表,搞定。
但项目上线后,业务开始复杂化:
-
用户需要会员等级、积分、优惠券
-
商品需要多规格(颜色、尺寸)、库存、限购
-
订单需要物流、售后、发票
-
运营需要统计报表、埋点数据
这时候,最初的四张表根本无法支撑。你不得不频繁修改表结构,或者用各种"临时方案"凑合。
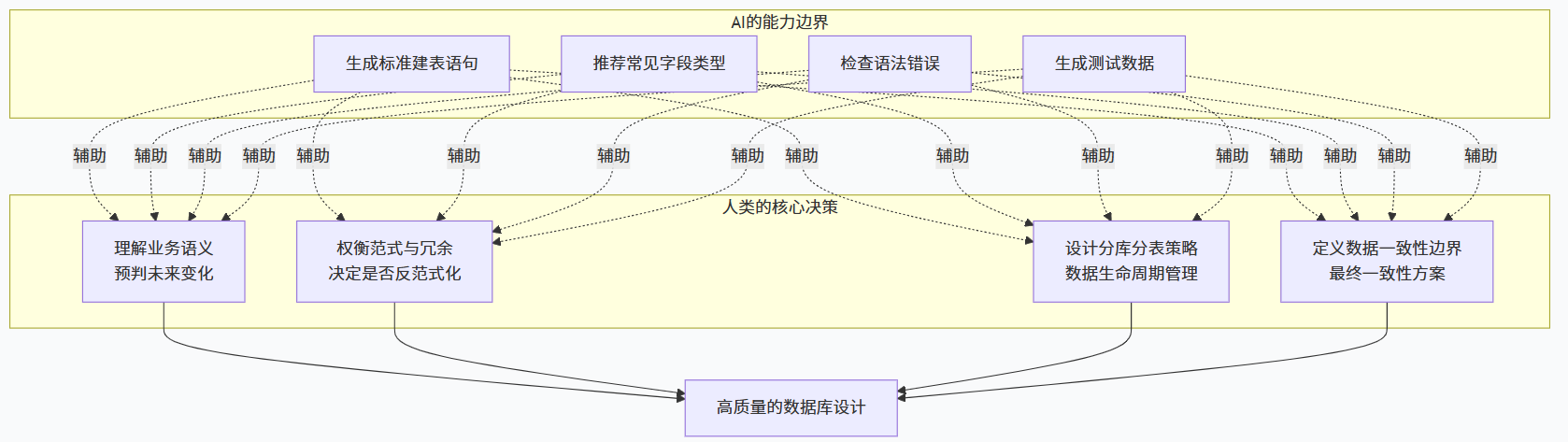
AI的局限在于:它只能基于你给出的信息做设计,无法预测未来的业务变化,也无法理解业务背后的隐含规则。 比如:
-
用户和订单是一对多,但订单是否需要归档?是否需要软删除?
-
商品和规格是多对多,但规格变更时,历史订单里的规格信息是否要保留?
-
优惠券和用户是多对多,但优惠券是否有使用条件、有效期、互斥规则?
这些业务语义和扩展性,AI很难一次性捕捉。而一个有经验的开发者,会在设计表时就预判这些变化,提前做好冗余字段、预留扩展空间。
AI是工具,不是决策者。 它可以帮你执行设计,但不能替你做设计。
三、好的表设计是什么样的?7条核心原则

3.1 原则一:满足第三范式(3NF),但不要过度
第三范式要求:每列都和主键直接相关,而不是间接相关。例如,订单表不应该包含"用户姓名",而应该包含"用户ID",用户姓名放在用户表里。
但不要过度范式化:在查询性能要求高的场景,可以适当冗余。比如订单快照表中冗余商品名称、价格,避免商品信息变更后历史订单显示错误。
3.2 原则二:选择合适的字段类型
-
能用
int不用varchar:状态、类型等枚举值用tinyint,查询快、索引小 -
定长用
char,变长用varchar:char(2)存储性别,varchar(255)存储用户名 -
时间用
datetime或timestamp,别用varchar存"2025-01-01" -
金额用
decimal(10,2),绝对不要用float或double(精度会丢)
3.3 原则三:每个表都要有主键,推荐自增ID
主键是表的"身份证"。推荐使用自增ID或雪花ID,避免用业务字段做主键。业务字段(如手机号、身份证号)可能会变,一旦变更,所有关联表的外键都要改。
3.4 原则四:合理使用索引
-
为WHERE、JOIN、ORDER BY的字段建索引
-
区分度高的字段优先(如用户ID、订单号)
-
避免在索引列上使用函数(
WHERE DATE(create_time) = '2025-01-01'会让索引失效) -
联合索引遵循最左前缀原则
3.5 原则五:考虑数据增长,提前分区或分表
如果一张表预期会超过500万行,提前设计分区策略(按时间、按区域)或分库分表方案。不要等数据量大了再改,那时迁移成本极高。
3.6 原则六:软删除 vs 硬删除
-
核心业务表建议用
deleted_flag字段做软删除,保留数据可追溯 -
日志、临时数据可以硬删除,节省空间
-
软删除字段要配合唯一索引时,可能需要联合索引(如
user_id+deleted_flag)
3.7 原则七:注释必不可少
每个字段都要有COMMENT,说明业务含义、取值范围、单位。这是给未来的自己和同事看的文档。
sql
CREATE TABLE `order` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '订单ID,自增主键',
`order_no` varchar(32) NOT NULL COMMENT '订单号,格式:ORD+yyyyMMdd+8位随机数',
`user_id` bigint(20) NOT NULL COMMENT '用户ID,关联user表的id',
`total_amount` decimal(10,2) NOT NULL COMMENT '订单总金额,单位:元,包含优惠',
`status` tinyint(4) NOT NULL DEFAULT '0' COMMENT '订单状态:0-待支付,1-已支付,2-已发货,3-已完成,4-已取消',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
PRIMARY KEY (`id`),
UNIQUE KEY `uk_order_no` (`order_no`),
KEY `idx_user_id` (`user_id`),
KEY `idx_status` (`status`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='订单主表';四、AI时代,数据库设计能力为何更重要?
4.1 AI让"写代码"变得廉价,让"做决策"变得昂贵
以前,一个功能从设计到开发可能需要5天,其中3天在写CRUD代码。现在,AI可以帮你1天写完代码。
但设计阶段的决策------比如表结构、字段类型、索引策略------AI无法代劳。 而这些决策的错误成本,会随着项目规模的扩大而指数级增长。
4.2 人人都是"架构师",但架构师的核心能力是权衡
AI降低了技术门槛,让更多人能够快速搭建原型。但真正的架构能力体现在:
-
理解业务本质,识别哪些数据是核心、哪些是衍生
-
预判未来变化,预留扩展空间
-
在一致性、性能、可维护性之间做权衡
这些能力,AI短期内无法取代。而数据库设计,正是这些能力最直接的体现。
4.3 面试中,表设计是区分"CRUD工程师"和"架构师"的关键
很多大厂的系统设计面试,都会考察数据库设计。面试官不会问"怎么写SQL",而是问:
-
"如果用户表有1亿数据,你怎么设计分库分表?"
-
"订单表和支付表,如何保证数据最终一致?"
-
"一个多对多的关系,你是用中间表还是用JSON字段?"
这些问题,考验的就是表设计能力。而AI可以帮你写出SQL,却无法替你回答这些问题。
五、如何提升数据库设计能力?5个实战建议
-
先画ER图,再写建表语句
用工具(如PDMan、Draw.io)画出实体关系图,理清一对一、一对多、多对多关系。ER图是表设计的"蓝图"。
-
做原型时,刻意模拟未来变化
设计表时问自己:如果这个字段以后要支持多选怎么办?如果这个关系要变成多对多怎么办?预留扩展字段(如
ext_info存JSON)。 -
定期review表结构,做重构计划
每个迭代留出20%时间做数据库重构:拆分大表、合并冗余字段、优化索引。
-
用AI辅助,但不用AI替代
让AI生成初版建表语句,然后人工review:字段类型是否合理?索引是否足够?注释是否清晰?
-
学习经典案例
阅读开源项目的数据库设计(如WordPress、Magento、Shopify的schema),理解它们为什么这样设计。
总结:表设计是技术债务的"源头"
如果说代码是债务的"利息",那么表设计就是债务的"本金"。一个糟糕的表设计,会在项目生命周期内不断产生额外的复杂度:慢查询、数据不一致、代码难以维护、新功能开发受阻。
而AI时代,这种债务会加速累积------因为AI可以快速生成基于糟糕表结构的代码,让错误被更快地放大。
所以,请你在动手写第一行代码之前,先认真设计你的表。 这不仅是技术能力的体现,更是对团队和项目负责的态度。
下次当你准备把需求扔给AI让它"一键生成"时,记得先花30分钟画一张ER图。这30分钟,可能会帮你省下未来30个小时的加班。
最后留一个问题:你在项目中遇到过哪些因为表设计不当导致的"坑"?最后是怎么解决的?欢迎在评论区分享你的经历,帮助更多人避坑。