【多模态大语言模型】Qwen-VL 系列解读,持续更新中。。。
文章目录
- [【多模态大语言模型】Qwen-VL 系列解读,持续更新中。。。](#【多模态大语言模型】Qwen-VL 系列解读,持续更新中。。。)
-
- [0. 介绍](#0. 介绍)
- [1. Qwen-VL(1.0版本)](#1. Qwen-VL(1.0版本))
-
- [1.1 视觉编码器(Visual Encoder)](#1.1 视觉编码器(Visual Encoder))
- [1.2 输入投影层:感知位置的视觉-语言适配器(Position-aware Vision-Language Adapter )](#1.2 输入投影层:感知位置的视觉-语言适配器(Position-aware Vision-Language Adapter ))
- [1.3 输入和输出](#1.3 输入和输出)
- [1.4 训练过程](#1.4 训练过程)
- [2. Qwen2-VL](#2. Qwen2-VL)
-
- [2.1 原生动态分辨率(Naive Dynamic Resolution)](#2.1 原生动态分辨率(Naive Dynamic Resolution))
-
- [2.1.1 Patch' Pack 保留原生分辨率](#2.1.1 Patch' Pack 保留原生分辨率)
- [2.1.2 ViT引入2D-RoPE位置编码](#2.1.2 ViT引入2D-RoPE位置编码)
- [2.2 输入投影层:压缩Vision token + MLP Adapter](#2.2 输入投影层:压缩Vision token + MLP Adapter)
- [2.3 Multimodal Rotary Position Embedding (M-RoPE)](#2.3 Multimodal Rotary Position Embedding (M-RoPE))
- [2.4 统一的图像和视频理解框架](#2.4 统一的图像和视频理解框架)
- [2.5 模型训练](#2.5 模型训练)
- [3. Qwen2.5-VL](#3. Qwen2.5-VL)
- [4. Qwen3-VL](#4. Qwen3-VL)
- [5. Qwen-3.5](#5. Qwen-3.5)
- 参考
0. 介绍
网上关于QwenVL系列整理的不太好看,自己整理整理,方便自己看。问最新的AI,回复的也不是最新的进展。
在通用的MM-LLM(Multi-Modality LLM)框架里,共有五个模块,整体以LLM为核心主干,具体描述如下:
- 模态编码器(Modality Encoder):将多模态的数据编码成向量空间特征,该模块通常是单独进行预训练的,典型的方法有基于CNN的ResNET,基于Transformer的ViT等。
- 输入投影层(Input Projector):将模态编码器的输出映射到LLM的输入特征空间的适配层,一般模型结构比较简单,不同的多模态模型一般是随机初始化该模块的参数做冷启训练。典型的网络层:MLP,Cross-Attention等
- LLM主干网络(LLM Backbone):LLM是经过预训练的模型,一般还要串联多个模块继续做Post-Pretrain和微调,使得模型能识别多模态的特殊token和多模态的特征输入。
- 输出投影层(Output Projector):将LLM生成的数据,映射成Modality Generator 可理解的特征空间,一般是简单的Transformer层或MLP层。
- 模态生成器(Modality Generator):多模态的生成器,最终输出多模态的结果如图像、语音、视频等。模型基本都是基于LDM(Latent Diffusion Models)的衍生模型,如图片领域的Stable Diffusion方法。
在多模态场景,通常包括两类任务:理解任务 和 生成任务。对应的模型分别是多模态理解模型和多模态生成模型。
- 多模态理解模型: 主要包括前三个模块(模态编码器,输入投影层,LLM主干网络),即模型接受多模态数据输入,以文本形式输出。
- 多模态生成模型:包括全部5个模块,即多模态数据输入,多模态数据输出,多模态生成模型通常要更复杂,也很难建模。
以上介绍完了通用的MM-LLM的框架。本文主要梳理的Qwen-VL模型是一系列视觉+文本多模态理解模型,即LVLM(Large-scale Vision-Language Model),主要处理文本和视觉特征,输入Text、Image、Video,输出Text。
1. Qwen-VL(1.0版本)
Qwen-VL 是以 Qwen-7B Base 为主干模型,通过引入视觉感知器(Visual receptor)来增强视觉特征的感知能力。视觉感知器包括一个跟语言模型对齐视觉编码器(visual encoder)和一个位置感知的适配器(position- aware adapter)。套用上面的通用多模态框架,Qwen-VL包括了典型的前3个模块:
- 模态编码器(Modality Encoder) : 视觉编码器(visual encoder),只用来编码图片视觉特征
- 输入投影层(Input Projector):位置感知的适配器(position-aware adapter)
- LLM主干网络(LLM Backbone): Qwen-7B Base 模型
下面我们分别来看看Qwen-VL的两个核心模块:视觉编码器、感知位置的适配器。接着描述一些规范化样本处理过程,最后描述下模型的训练过程。
1.1 视觉编码器(Visual Encoder)
Qwen-VL的视觉编码器使用的是ViT架构(Vision Transformer),ViT的网络设置和初始化参数使用了 OpenCLIP 预训练好的 ViT-bigG 模型。OpenCLIP是 laion.ai 组织的一个开源项目,是对OpenAI's的CLIP(Contrastive Language-image Pre-training)的开源实现。laion.ai 发布了一系列基于CLIP框架训练的不同size模型,同时他也为CV领域贡献了大量的开源数据,ViT-bigG是经过了 2B 的训练数据训出来的ViT模型。
Qwen-VL使用的ViT(ViT-bigG)是基于CLIP框架训练的,CLIP是通过Contrastive Learning的方式来学习Vision和文本的表征。对于一个Batch的数据,以样本集中原始图文pair 为正例pair,Batch内与其他样本组成为负例pair。模型训练采用了对比损失函数,通过最大化正例Pair的相似度,同时最小化负例Pair的相似度来训练模型。通过这种方式,能学习到视觉特征和文本特征的对齐关系。最后将训练好的Image Encoder模型(即ViT)参数保存下来,以供其他下游任务热启使用。
- 其中,ViT的原理比较简单:将图片分割成多个图像块(Patch),然后针对每个Patch通过一系列线性映射,转化成token,再将所有token拼接成序列,最终将一张图片从 (H,W,C)格式转换成 (S,H) 格式的序列特征。其中 H :高, W :宽, C : 通道数, S : 序列长度, H :特征维度。在标准的ViT实现上,输入图片会先被调整成长宽比 1:1 的正方形,然后再分割成固定的图像块。
- 因此这种标准的ViT框架的设计,只能接收固定分辨率的图片,同时Patch的大小也是模型在训练期间使用的一个固定size。
- 看下源码设置的一些参数:
- Qwen-VL 可接受的图像分辨率为 448 * 448 ,所以输入的图片会先处理成统一的尺寸:(W: 448, H: 448, C: 3)。注:Qwen-VL模型训练其实是做了三个阶段,如下面章节所述。第一阶段图像会统一处理成低像素: 224 \times 224 ,后面两个阶段统一分辨率为: 448 \times 448 。这里只以高分辨率的设置为例。
patch_size : 14 ,这个参数指定patch的大小,同时也是卷积核 W 和 H 的尺寸,也是卷积操作的stripe步长
width:1664,这个参数指定的输出通道数,即out_channels,也就是每个Patch输出的特征的维度 - 我们以batch_size(B) = 1为例:
首先,一张图片做卷积操作,处理成 width, grid, grid = 1664, 32, 32的数据。
然后,按行优先展开,处理成一个二维格式的数据sequence_len, hidden_size = 1024, 1664(类似与一条文本处理后的序列)。
最后,增加位置编码,并输入给vit transformer模型
- Qwen-VL 可接受的图像分辨率为 448 * 448 ,所以输入的图片会先处理成统一的尺寸:(W: 448, H: 448, C: 3)。注:Qwen-VL模型训练其实是做了三个阶段,如下面章节所述。第一阶段图像会统一处理成低像素: 224 \times 224 ,后面两个阶段统一分辨率为: 448 \times 448 。这里只以高分辨率的设置为例。
1.2 输入投影层:感知位置的视觉-语言适配器(Position-aware Vision-Language Adapter )
经过上述ViT处理后,对于 448 \times 448 分辨率的图像,生成一个1024, 1664的序列,也就是向量维度为1664的长度为1024的序列。为了压缩视觉token的输入长度,Qwen-VL引入了一个Adapter来压缩图像特征。这个Adaper就是一个随机初始化的单层Cross-Attention模块。该模块使用一组可学习的query向量,将来自ViT的图像特征作为Key向量。通过Cross-Attention操作后将视觉特征序列压缩到固定的256长度。
此外,考虑到位置信息对于精细图像理解的重要性,Qwen-VL将二维绝对位置编码(三角位置编码)整合到Cross-Attention的 q,k 中,以减少压缩过程中可能丢失的位置细节。随后将长度为256的压缩图像特征序列输入到大型语言模型中。
1.3 输入和输出
对于输入LLM前的特征序列,为了区分图片和文本的输入信息,对图片的feature使用了特殊的token包裹,图像特征的开始和结束用 和 token圈定,来明确标识图像特征的起止位置。同时为了做grounding任务,对图像中bounding box 统一用一个"左上-右下"坐标框格式表示:" (X_{topleft},Y_{topleft}),(X_{bottomright},Y_{bottomright}) " ,坐标值统一做归一化处理,规范化到 (0,1000) 区间。并用 、 特殊token圈定。 对于描述bounding box的文本,也用 、 两个特殊的token圈定起来。下图是一条典型的grounding 任务的样本实例:

1.4 训练过程
Qwen-VL共分成3个训练阶段,包括两个预训练阶段和一个SFT阶段。
第一阶段:单任务大规模预训练(Pre-training ),主要使用大量网上抓取和内部的图文pair数据做预训练,训练数据有1.4B,英文数据占比77.3%,中文占比22.7%,训练数据的图片统一处理成224 \times224 的尺寸。该阶段LLM模型参数是frozen的,ViT和Cross-Attention层的参数是激活更新的,这个阶段主要通过大规模数据训练模型的vision模态对齐语言模型的能力。
第二阶段:多任务预训练(Multi-task Pre-training),这个阶段使用了更高分辨率、更高质量的数据,同时引入图文混排的数据。该阶段是个多任务的预训练阶段,包括7个任务,其中有6个Vision任务(包括Captioning ,VQA,grounding等)和1个文本生成任务,这个阶段模型是全参数激活的。该阶段之所以引入文本生成任务,主要是为了保证模型的通用文本处理能力。该阶段的训练数据,Vision数据的分辨率从 224 \times 224 提升到 448\times 448 ,数据做了精选处理,包括多模态数据69M和 文本数据7.8M。第二阶段的数据量比第一阶段少了2个量级。该阶段训练完成后,最终产出了Qwen-VL base模型。
第三阶段: 指令微调(Supervised Fine-tuning),主要提升模型的指令遵循能力和对话能力。在这个阶段作者对数据做了些数据增强,通过人工标注、模型生成和策略拼接等方式构造多模态的多轮会话数据。该阶段指令集数据共收集了350K。
三个阶段详细的训练过程,包括:样本、模型和建模任务等细节,如下图所示。
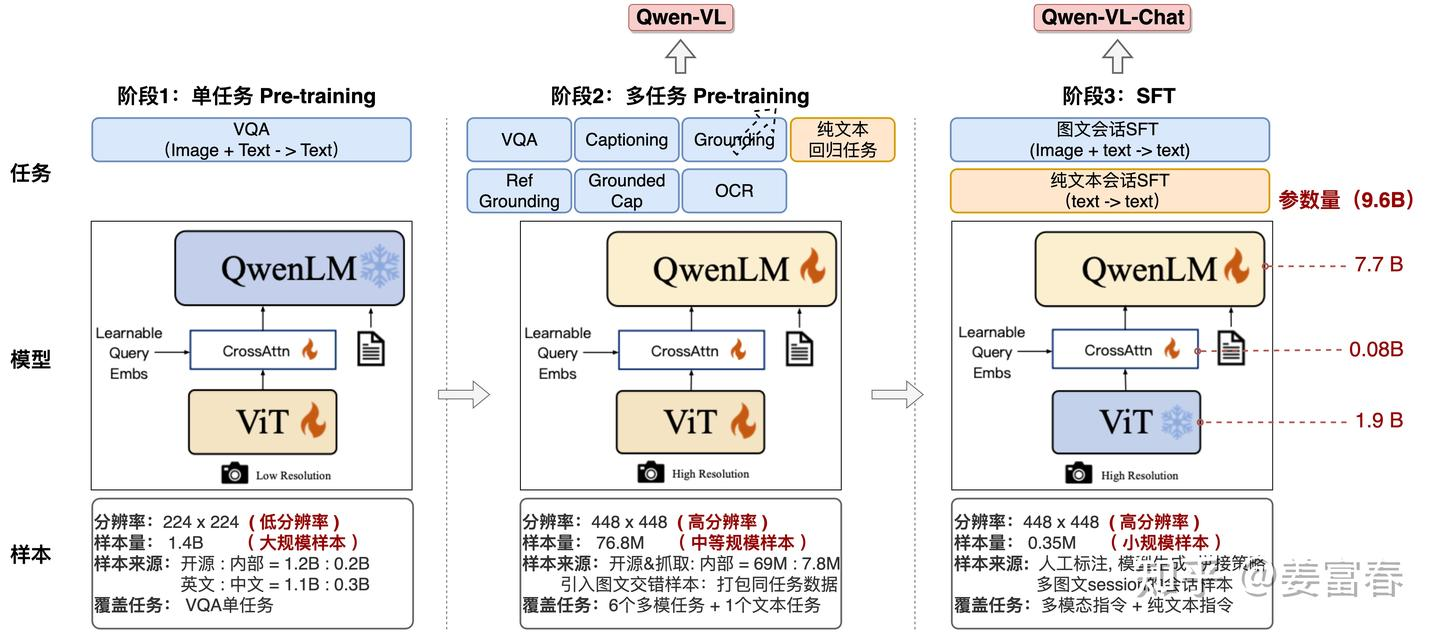
上面完整描述了Qwen-VL的核心工作,具体做法没有什么大的创新,数据规模和数据多样性上也没有明显的优势,所以Qwen-VL的模型效果基本就是中规中矩,没有太强的表现。
2. Qwen2-VL
相对于Qwen-VL,Qwen2-VL整体模型架构做的比较大的升级,首先从模型命名上可知,主体模型从Qwen升级到了Qwen2。并且发布了三个size的模型,分别是Qwen2-VL-2B,Qwen2-VL-7B,Qwen2-VL-72B (这里遵从Qwen官网发布的命名,后缀并不能准确表示模型的参数量,模型详细参数)。
- Qwen2-VL系列模型,针对Vision Encoder采用了相同size(675M)的模型结构,这里应该是做了一些ablation的实验,取得一个合适的size。
- 另外相对于Qwen-VL系列,Qwen2-VL并没有显示描述Vision-Language Adapter的参数。Qwen2-VL对 Adapter 做了简化处理,并没有采用一个Cross-Attention的结构,而是使用了简单的线性变换层,这层参数比较少,相对于总参数规模,可以忽略不计。
除了主干模型的升级,论文中还提到了一些重要的升级点,总结如下:
- 重新训练了 nav ViT
- 采用原生动态分辨率:单一分辨率 -> 任意分辨率, Qwen-VL模型输入只接受单一分辨率的图片,Qwen2-VL可输入不同分辨率的图像,避免了Vision数据适配单一分辨率而导致的失真问题。
- Vision Encoder位置编码:绝对位置编码 -> 相对位置编码,从二维三角位置编码升级到二维RoPE位置编码,RoPE对长序列有更好的泛化能力,有利于提升对长序列Vision特征的建模能力
- LLM主体模型位置编码:多模态位置编码从projector转移到了LLM。1D->3D RoPE,引入多模态旋转位置编码技术(M-RoPE),刻画多模态(时序、高、宽)三维数据。进一步提升对时空数据的建模能力。
统一多模态数据: 单图片 -> 统一图片和视频,统一框架处理图片和视频数据,进一步提升对真实世界认知和理解能力 - 训练数据: 1.4B -> 1.4T,数据量提升了3个量级,同时数据覆盖了多领域任务。
下面详细介绍下这些升级点。
2.1 原生动态分辨率(Naive Dynamic Resolution)
2.1.1 Patch' Pack 保留原生分辨率
回顾 Qwen-VL 使用的视觉编码器是标准的ViT,这要求输入的图片要统一处理成单一的、固定的分辨率,才能feed到模型进行处理。一般标准的预训练好的ViT,通常是将图片处理成正方形(长:宽=1:1)。这样处理后通常图片会失真,导致模型理解上有信息损失或引入一些误导。对于一些宽高比差距较大的图片,处理后通常会造成图片扭曲。
而Qwen2-VL实现的原生动态分辨率方法则会保留原始图片的宽高比,将图片resize到适当的大小,使图片像素满足一个适当的区间,再对图片做Patch处理,将每个图片处理成变长的Vision token序列,再输入给LLM模型。
目前看上述的方法是比标准的ViT更合理的,因为它保留了图片的原始分辨率,但是同时也引入了一个问题。
- 传统的ViT会将任何图片数据都处理成定长的Patch序列,然后输入给Vision Encoder,这种统一定长的输入是对硬件计算非常友好的,非常好组Batch,并且不需要任何padding处理。Batch序列中每个位置的计算都是有效的。
而对于上面提到的原生动态分辨率方法会将不同图片处理成不同长度的Patch序列。对于不同的长度的输入,做并行计算时,我们自然会想到类似于文本数据的操作,对数据做padding,再Feed给模型。但这相比传统的ViT方法(无Padding)会更慢(因为为了适配一个Batch中最长的序列,要做适当的Padding处理,导致会有些冗余计算)。因此这并不是一个完美的方法。Qwen2-VL采用的原生动态分辨率方法实现上同时也考虑了性能问题。
- 核心方法是采用了NaViT的Patch n' Pack技术,把不同图像的多个patch打包到一个序列,能保留不同图片的可变分辨率。同时在一个次序列计算中同时可处理多个图像,提升了模型计算的吞吐,在性能上始终优于传统的ViT。其性能提升主要来源于Pack处理后,一个序列包括多个图片能同时计算,使得在固定计算预算下,动态分辨率方法能训练更多样本,从而带来更好的性能。
2.1.2 ViT引入2D-RoPE位置编码
在Qwen2-VL系列的ViT网络中,并没有沿用Qwen-VL的2D绝对位置编码,而是引入了2D-RoPE相对位置编码。之所以引入2D-RoPE,我个人理解主要考虑Qwen2-VL系列处理的图片Patch是变长的,对于超长的一些位置,如果采用绝对位置编码,由于数据稀疏性, 并不能得到充分训练。但RoPE本身是具有一定的外推性,对长序列建模有更好的泛化能力。
我们都知道1维的旋转位置编码(1D-RoPE)对序列增加相对位置的处理过程。RoPE从1维扩展到2维一个简单的结论:针对一个位置,将输入向量分成两半,前一半向量用 x 坐标的一维RoPE矩阵处理,后一半向量用 y 坐标的一维RoPE矩阵处理,然后再将两半处理后的结果拼接在一起,就做完了2维的RoPE处理。
2.2 输入投影层:压缩Vision token + MLP Adapter
Qwen-VL在输入投影层做了Vision token的压缩处理,是采用了Cross-Attention的架构,通过一个组可学习的Query向量来压缩原始的特征序列。那么Qwen2-VL为什么没有继续沿用Cross-Attention的架构?
- 这里主要是因为Cross-Attention架构适合处理固定长度的kv,当长短不一时,是不适合做Attention计算的。而Qwen2-VL通过原生动态分辨率方法处理的每个图片的token序列恰恰是变长的,无法使用Cross-Attention架构做特征压缩处理。
因此,Qwen2-VL采用了一种更简单的压缩方法:
- 对空间位置临近的patch 特征做拼接,再经过2层MLP线性变换,这样将原来长度n的序列,可压缩到n/4,最终将压缩后的特征序列输入给LLM模型。
- 为了区分Vision token和文本token,Qwen2-VL也引入了两个特殊的token。
2.3 Multimodal Rotary Position Embedding (M-RoPE)
Qwen2-VL模型输入增加了视频模态,视频可以看做是在图片二维空间上,增加了时序维度,是三维时空分布的数据:
- M-RoPE将位置编码信息从1维扩展到了3维,这样就能清晰刻画视频模态数据时空位置信息。对于文本(一维)和图像(二维)的数据如何统一表示成3维的位置ID呢?处理也比较简单直接:
- 文本:因为文本是一维空间序列,三个维度的值保持一致,也就退化成1D-RoPE。
- 图像:图像只有宽高两个维度,所以对于一张图片,时序维度的位置始终保持固定。
- 对于混合多模态数据,每个模态的起始position ID是前面模态三维位置ID中取最大的ID并加1得到。
有了三维的位置,最终怎么映射成3D-RoPE,映射方式类似与2D-RoPE,针对一个位置 ,对的输入向量的维度分成三份分别处理,然后再将三份处理后的结果拼接在一起,就做完了3维的RoPE处理。
2.4 统一的图像和视频理解框架
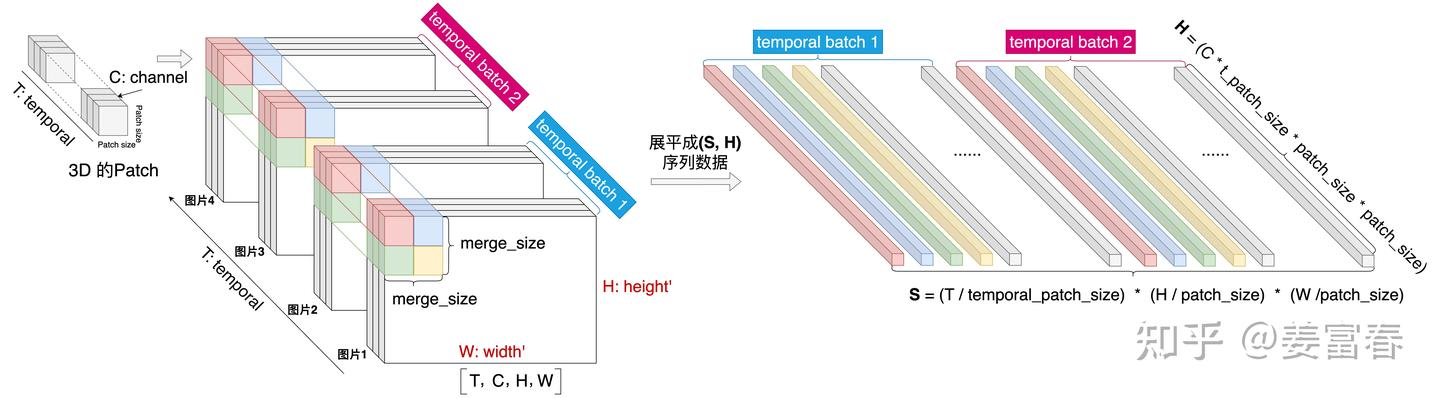
Qwen2-VL统一了视频和图像的理解框架,能混合输入图像和视频数据进行理解。为了保证图片和视频的处理一致,对视频和图像分别做如下处理:
视频处理:以每秒两帧的速率对视频进行采样,最终可采样偶数个帧序列。对于长视频为了平衡序列长度和计算效率,通过动态调整每一帧的分辨率,将视频总token限制在16K以内。
图像处理:对图像做复制操作,使得单一图片,变成一个时序为2的帧序列。
使用3D的卷积对帧序列做特征抽取,每两张图片为一组进行卷积操作抽取特征。这样通过将卷积核扩充了时序维度,可以进一步压缩序列长度,因此也能进一步提升模型处理更多帧的能力。
2.5 模型训练
Qwen2-VL采用了与Qwen-VL一致的三阶段训练方式。Qwen2-VL在训练数据上相比Qwen-VL做了大量的有价值的工作。
数据来源除了获取开源数据、经过清洗的网页数据,还做的大量数据合成的工作。数据涉及多种场景,包括图像-文本对,OCR数据,视觉问答数据,视频对话数据等多样化数据。
此外Qwen2-VL数据规模大幅提升,Qwen-VL整体训练样本1.4B左右,Qwen2-VL直接翻了3个量级达到了1.4T。

通过大幅提升样本规模和样本多样性,使得Qwen2-VL的模型效果在多任务的评估中保持领先,也碾压了GPT-4o的效果。
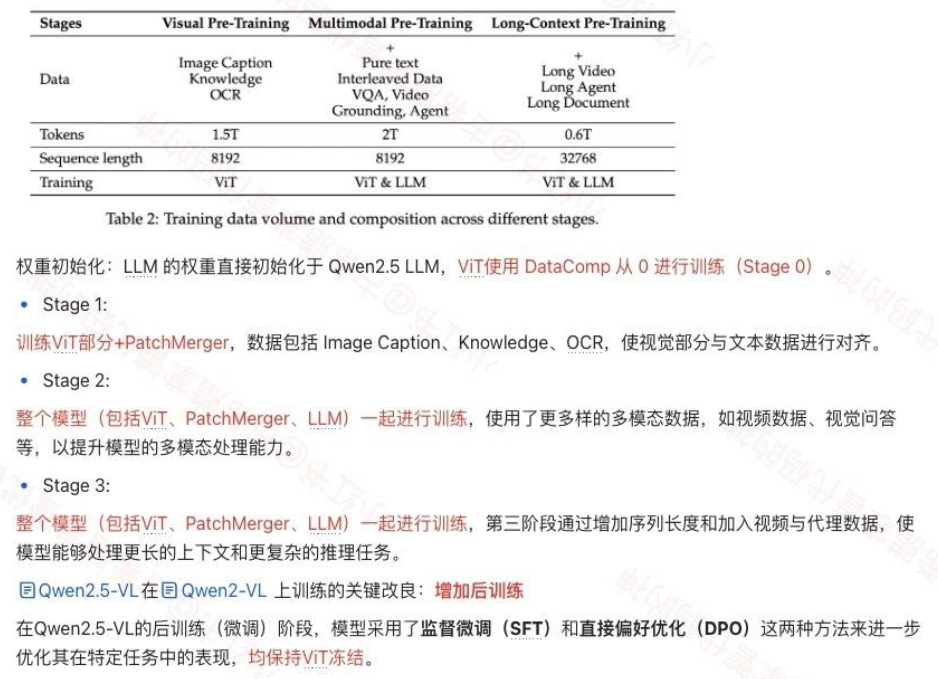
3. Qwen2.5-VL
在 Qwen2-VL基础上:
- ViT:使用了更接近LLM的架构。
- Attention结构上使用了交错的Window Attention。
- 使用SwiGLU的FFN结构,hidden_act="silu"并且增加bias,注意这里在llama这样的语言模型中是默认无偏置。
- 标准化使用RMSNorm。
- Projector:仍然使用的是PatchMerger,但是替换了LayerNorm为RMSNorm
- LLM:语言模型升级使用了Qwen2.5。MRoPE(在视频输入)对齐了现实video的帧率,即对齐了绝对时间。
- 训练
4. Qwen3-VL
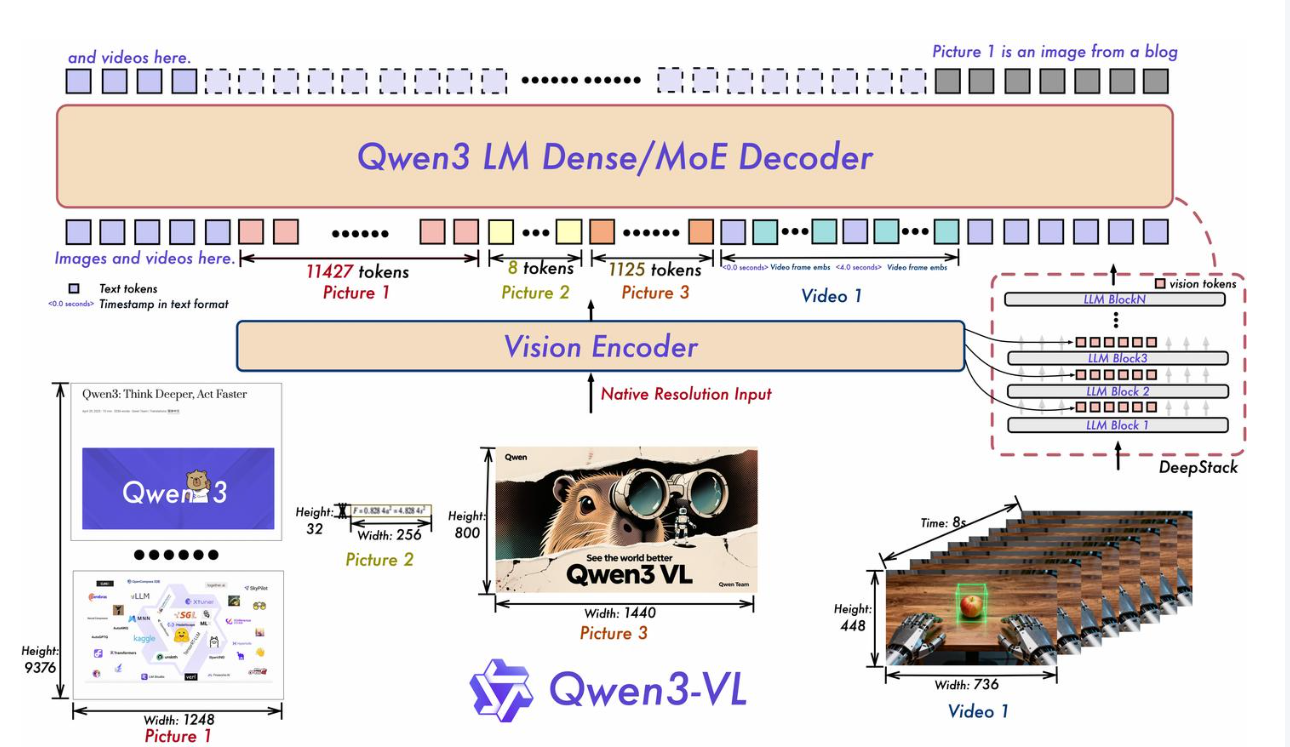
- ViT:沿用Qwen2.5 bias配置、2D-RoPE,但是替换了激活函数,PatchEmbed启用bias。
- Projector:Adaptor本次更新中使用了两个部分特征,一部分是沿用的Qwen2.5的PatchMerger。另外一部分使用了deepstack_visual_indexes,用于与LLM特征进行融合。
之前的多模态模型(包括 Qwen2-VL),通常只把Vision Encoder最后一层的输出喂给 LLM。这就像是你去旅游,只给朋友看最后修好的精修图,朋友虽然知道你去过海边,但照片里路边的野花、墙边的砖块这些的细节全丢了。
DeepStack 机制做了一个操作:它不再只走正路线,而是开了三个支线搞辅助连接。它也没有为了省参数去复用 MLP Merger 模块,而是一共部署了 4 个 MLP Merger(1 个主路 + 3 个支线)。- 主路:ViT 最后一层 -> 主 MLP Merger -> 变成 Input Embeddings(告诉 LLM 整体是啥)。
- 支线:它从 ViT 的 浅层、中层、深层 分别提取特征。注意,每一层特征都有一个独立专用的 Merger 进行投影,然后依次残差连接到 LLM 的第 1、2、3 层。
ViT 浅层(看纹理、边缘) -> 专用 Merger A -> 注入 LLM 第 1 层
ViT 中层(看形状、结构) -> 专用 Merger B -> 注入 LLM 第 2 层
ViT 深层(看语义、类别) -> 专用 Merger C -> 注入 LLM 第 3 层
怎么融?辅路的信息不是直接拼接到文本后面,而是通过残差连接直接相加到 LLM 的隐藏状态里,因为要保持维度。
- LLM:Qwen3-VL-235B-A22B使用的是Qwen3的MoE版本(还会有非MoE版本开源),架构上使用了 QKNorm,Qwen3VL使用3维多模态位置编码MRoPE,并且采用了MRoPE-Interleave,t,h,w交错分布实现对时间,高度和宽度的全频率覆盖,提升鲁棒性和外推性能。在前 K 层使用了DeepStack特征融合。
- 之前的 Qwen2-VL 用了一种叫 MRoPE 的位置编码,把时间(t)、水平(h)、垂直(w)分开编码。但qwen团队发现,这样做会导致频率谱不平衡,简单说就是模型在处理长视频时,对时间的感觉会变差。Qwen3-VL 改用了 Interleaved MRoPE。和名字一样,就是:它把 t, h, w 的编码像洗牌一样均匀地插在了dim维度中。这让模型在长达 256K 的上下文里,依然能精准地定位到"视频第 58 分钟左上角的那只猫"。
- Qwen2.5-VL 用绝对时间位置编码来告诉模型"这是第几秒"。结果发现,视频太长的时候,这个数字变得巨大且稀疏,模型学懵了。Qwen3-VL 改成直接用纯文本来打标签,如:<4.0 seconds>。
- 训练
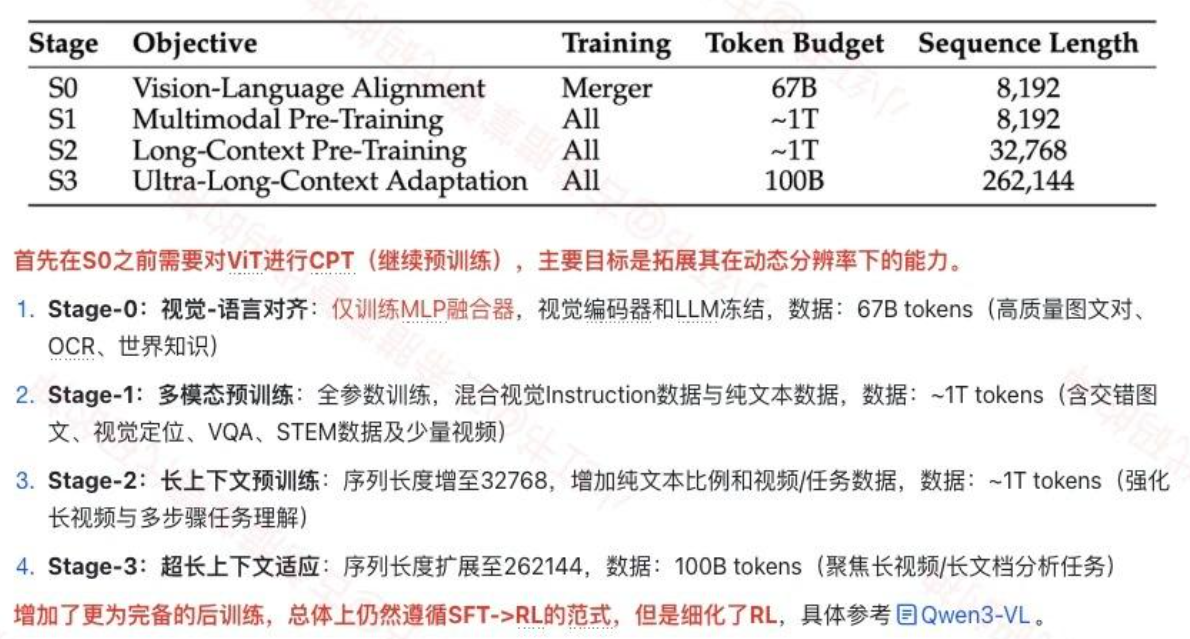
5. Qwen-3.5
Qwen-3.5是一个Dense多模态大模型(也支持Text-Only模式):
- 多模态架构上相比 Qwen3-VL 去除了复杂的DeepStack结构,回归了 Qwen2-VL/Qwen2.5-VL的NaViT + PatchMerger + LLM的三段式结构。
- LLM架构上Qwen-3.5参考 Qwen3 Next 使用支持交错Gated/Linear Attention 架构(每4层:3层GatedDeltaNet+1层Gated Attention)
- 整体上看Qwen-3.5就是多模态版的 Qwen3 Next。
- 训练
主要改进集中于预训l练视觉-文本数据、多语言数据的scaling、以及RL的infra&scaling。
参考
【1】https://zhuanlan.zhihu.com/p/25267823390