【室内户型图重建】【深度学习】Windoes11下RoomFormer官方代码Pytorch实现
文章目录
- 【室内户型图重建】【深度学习】Windoes11下RoomFormer官方代码Pytorch实现
- 前言
- 环境搭建
-
- 前置准备
- [Conda 虚拟环境搭建](#Conda 虚拟环境搭建)
- 数据集和关于预训练权重
-
-
- [1.Structured3D 数据集](#1.Structured3D 数据集)
- [2. SceneCAD 数据集](#2. SceneCAD 数据集)
- [3. 预训练权重(Checkpoints)](#3. 预训练权重(Checkpoints))
- [4.MonteFloorData 数据集](#4.MonteFloorData 数据集)
-
- 模型评估
-
- 基础版评估(无语义)
-
- [Structured3D 评估](#Structured3D 评估)
- [紧凑版 Structured3D 评估](#紧凑版 Structured3D 评估)
- [SceneCAD 评估](#SceneCAD 评估)
- 语义增强版评估
-
- [Structured3D 评估](#Structured3D 评估)
- 模型训练
-
- 基础版训练(无语义)
-
- [Structured3D 训练](#Structured3D 训练)
- [### 紧凑版 Structured3D 训练](### 紧凑版 Structured3D 训练)
- [SceneCAD 评估](#SceneCAD 评估)
- 语义增强版评估
-
- [Structured3D 训练](#Structured3D 训练)
- [附录 1](#附录 1)
- [附录 2](#附录 2)
- 总结
前言
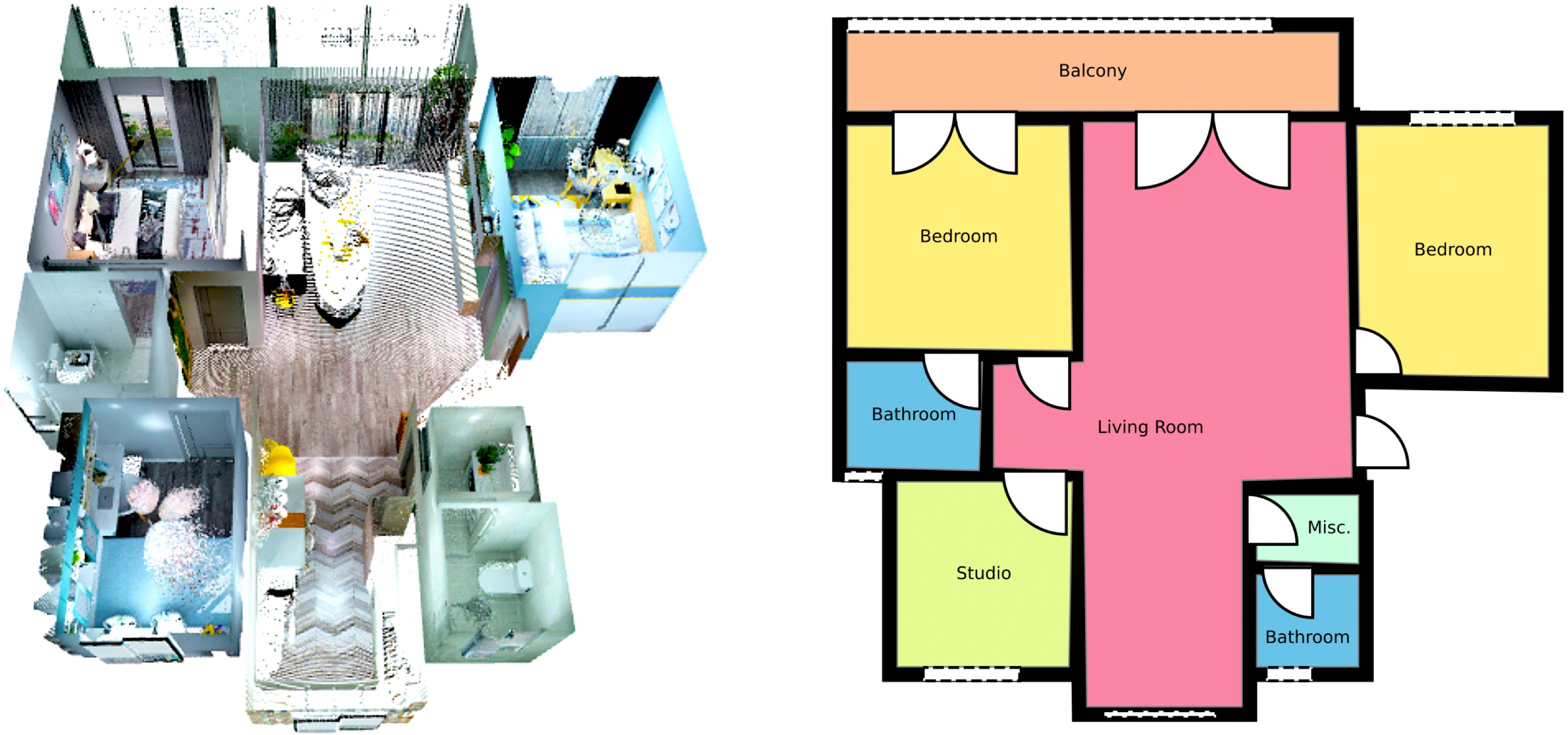
RoomFormer 是由苏黎世联邦理工学院的 Yuanwen Yue 等人在 《Connecting the Dots: Floorplan Reconstruction Using Two-Level Queries【CVPR-2023】》 【论文地址】提出的 室内平面图全自动重建方法 ,其核心是基两级查询机制的端到端 Transformer 架构,直接从 3D 扫描得到的鸟瞰密度图生成结构化、带有序顶点的房间多边形,解决了传统平面图重建多阶段、依赖后处理、结构不完整的问题。
该方法以物理空间结构先验 为驱动,结合 Transformer 集合预测思想,设计了房间级查询 + 角点级查询 的双层表示,通过可学习查询直接输出房间数量、房间语义、房间边界有序顶点,无需手工规则、轮廓优化或图优化,实现了从特征到完整平面图的单阶段、端到端推理 ,在 Structured3D、SceneCAD 等权威室内重建数据集上达到 SOTA,成为基于 3D 点云/密度图的平面图重建领域的经典范式。
在详细解析 RoomFormer 网络结构、两级查询设计、多边形匹配损失与实验结论之前,首要任务是搭建该方法【官方代码地址】所需运行环境,完成数据集预处理、模型训练与推理可视化,为讲解后续结构分析、 消融实验与改进拓展奠定基础。
环境搭建
室内户型图重建项目通常基于 Python + PyTorch 深度学习框架,以下步骤适配Windows 系统。
前置准备
确保本地系统已安装以下基础工具:
-
Anaconda/Miniconda :用于管理虚拟环境【参考教程】
-
Git :用于克隆仓库【参考教程】
-
CUDA & cuDNN 【参考教程】:若有 NVIDIA 显卡,根据主机情况安装匹配的 CUDA 版本(建议 11.3~12.0+),无 GPU 可跳过(仅支持 CPU 推理,速度极慢)
bash# 查看主机支持的cuda版本(最高) nvidia-smi
Conda 虚拟环境搭建
-
打开终端(cmd),执行以下命令克隆仓库:
bashgit clone https://github.com/ywyue/RoomFormer.git cd RoomFormer -
创建并虚拟环境(指定 Python 版本)
bashconda create -n roomformer python=3.10 -y activate roomformer -
安装核心依赖(PyTorch + TorchVision)
bashpip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118 -
安装其他第三方依赖
bashpip install -i https://pypi.tuna.tsinghua.edu.cn/simple -r requirements.txt # 安装额外工具(可选,用于可视化) pip install -i https://pypi.tuna.tsinghua.edu.cn/simple open3d scikit-learn plyfilerequirements.txt中所有依赖项不再指定版本
opencv-python
numpy
matplotlib
imageio
wandb
scipy
fvcore
cloudpickle
omegaconf
fairscale
timm
shapely
tqdm
pycocotools
descartes
-
编译可变形注意力模块和可微光栅化模块:注意这里使用管理员身份运行x64 Native Tools Command Prompt for VS 2019(Visual Studio 2019 自带的专用命令行工具) ,而不是CMD(缺少编译 CUDA 扩展的关键环境)。
核心区别在于是否预装编译原生代码(C/C++/CUDA)的完整环境,编译 RoomFormer CUDA 扩展必须用前者的关键原因。
bash# 同样需要激活环境 activate roomformerbash# 编译可变形注意力模块 cd RoomFormer/models/ops # 设置用 Windows SDK 中配置的 MSVC 编译器环境,而非系统默认的编译器设置。 # 仅当前命令行窗口生效 set DISTUTILS_USE_SDK=1 pip install --no-build-isolation . # 编译可微光栅化模块 cd RoomFormer/diff_ras pip install --no-build-isolation .-
可能出现的问题1:
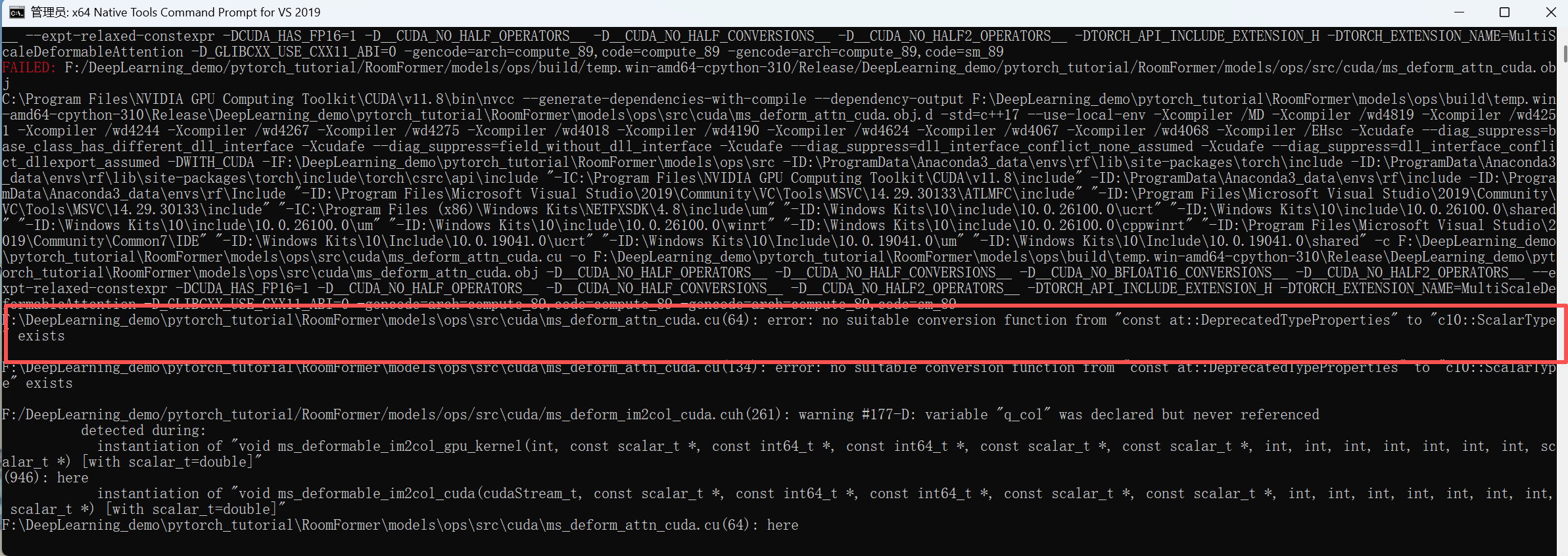
问题分析:遇到的核心错误是:
no suitable conversion function from "const at::DeprecatedTypeProperties" to "c10::ScalarType" exists,这是因为PyTorch版本不兼容 导致的。at::DeprecatedTypeProperties是旧版PyTorch(1.10及之前)的API,在新版PyTorch(1.11+)中被废弃并替换为c10::ScalarType,而RoomFormer的ms_deform_attn_cuda.cu代码仍在使用旧API。
解决方案:修改核心CUDA代码(关键)打开文件,找到以下所有类型错误并修改:
错误位置 原代码(旧版 PyTorch) 改为(新版 PyTorch) models\ops\src\cuda\ms_deform_attn_cuda.cuXXX.type().is_cuda() XXX.is_cuda() models\ops\src\cuda\ms_deform_attn_cuda.cuXXX.type() XXX.scalar_type() models\ops\src\ms_deform_attn.hXXX.type() XXX.scalar_type() diff_ras\rasterize_cuda.cppXXX.type().is_cuda() XXX.is_cuda() diff_ras\rasterize_cuda_kernel.cuXXX.type() XXX.scalar_type() -
可能出现的问题2:
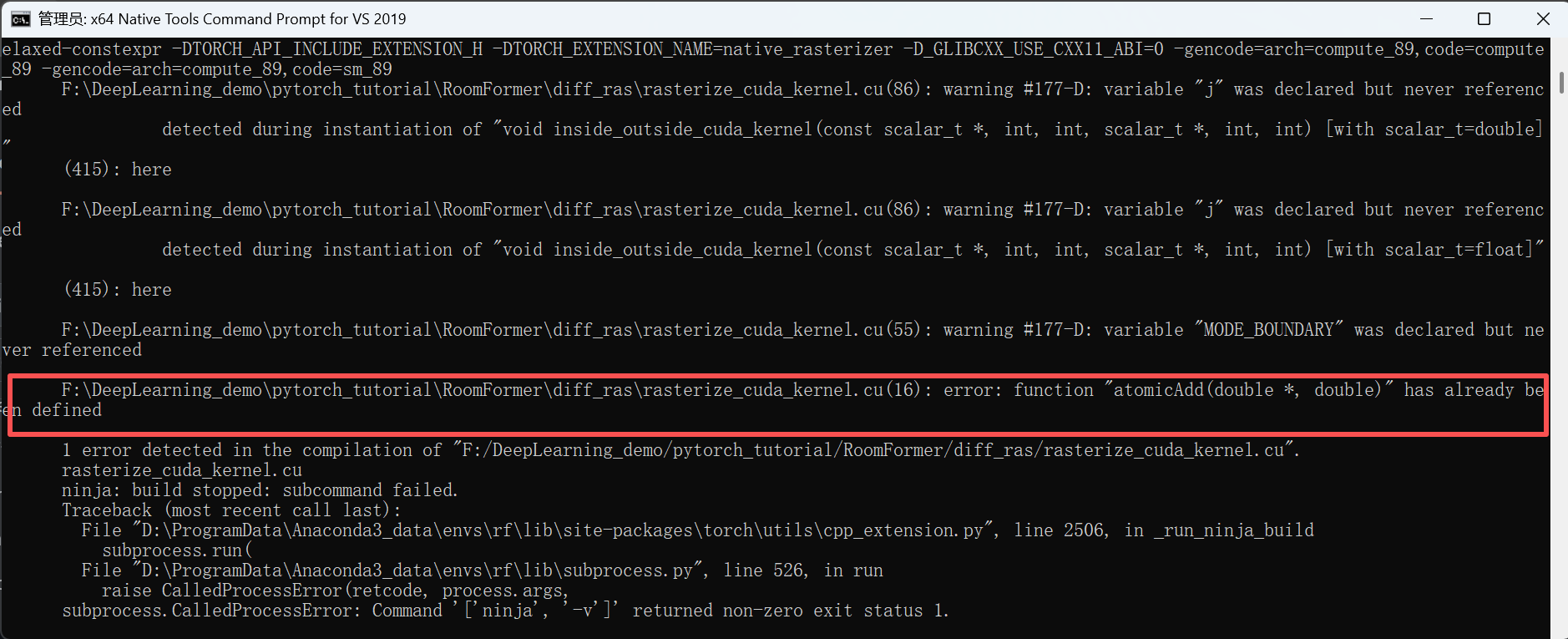
问题分析:现在的核心错误是:
function "atomicAdd(double *, double)" has already been defined(atomicAdd(double*, double)函数已被定义)。问题的根源是CUDA 11.0+ 版本已经原生支持double类型的atomicAdd,但代码中又手动实现了一遍该函数,导致重复定义冲突 。
解决方案:注释
rasterize_cuda_kernel.cu中中手动定义atomicAdd(double*, double)的位置(第16行)代码。cpp// // for the older gpus atomicAdd with double arguments does not exist // #if __CUDA_ARCH__ < 600 and defined(__CUDA_ARCH__) // static __inline__ __device__ double atomicAdd(double* address, double val) { // unsigned long long int* address_as_ull = (unsigned long long int*)address; // unsigned long long int old = *address_as_ull, assumed; // do { // assumed = old; // old = atomicCAS(address_as_ull, assumed, // __double_as_longlong(val + __longlong_as_double(assumed))); // // Note: uses integer comparison to avoid hang in case of NaN (since NaN != NaN) } while (assumed != old); // } while (assumed != old); // return __longlong_as_double(old); // } // #endif
-
数据集和关于预训练权重
关于数据集组织与预训练权重的简要说明。
1.Structured3D 数据集
-
数据来源 :RoomFormer官方已将 Structured3D 数据集转化成COCO 格式数据集格式。【链接】
-
目录结构要求 :
RoomFormer/ └── data/ └── stru3d/ ├── train/ # 训练集密度图 ├── val/ # 验证集密度图 ├── test/ # 测试集密度图 └── annotations/ ├── train.json ├── val.json └── test.json -
用途:从多视角 RGB-D 全景图转换为点云,再投影为鸟瞰密度图,用于训练房间多边形重建模型。
2. SceneCAD 数据集
-
数据来源 :RoomFormer官方同样将 SceneCAD 数据集转化成COCO 格式数据集格式。【链接】
-
目录结构要求 :
RoomFormer/ └── data/ └── scenecad/ ├── train/ # 训练集密度图 ├── val/ # 验证集密度图 └── annotations/ ├── train.json └── val.json -
用途:与 Structured3D 流程一致,用于验证模型在真实场景下的泛化能力。
3. 预训练权重(Checkpoints)
-
获取方式 :下载官方预训练模型权重【链接】
-
目录结构要求 :
RoomFormer/ └── checkpoint/ └── roomformer_structured3d.pth -
用途:可直接用于测试/推理,跳过完整训练流程,快速验证模型效果。
4.MonteFloorData 数据集
-
获取方式 :下载MonteFloor的真实数据(评估代码需要),并将其解压。【链接】
-
目录结构要求 :
RoomFormer/ └── s3d_floorplan_eval/ └── montefloor_data └── train/ └── val/ └── test/ -
用途:MonteFloorData 是一个专注于平面图重建的大规模合成数据集,包含多样化的室内场景平面图(支持顶视密度图、多边形轮廓标注、语义标签),可替代 Structured3D/SceneCAD 用于 RoomFormer 模型的训练 / 评估。
模型评估
基础版评估(无语义)
Structured3D 评估
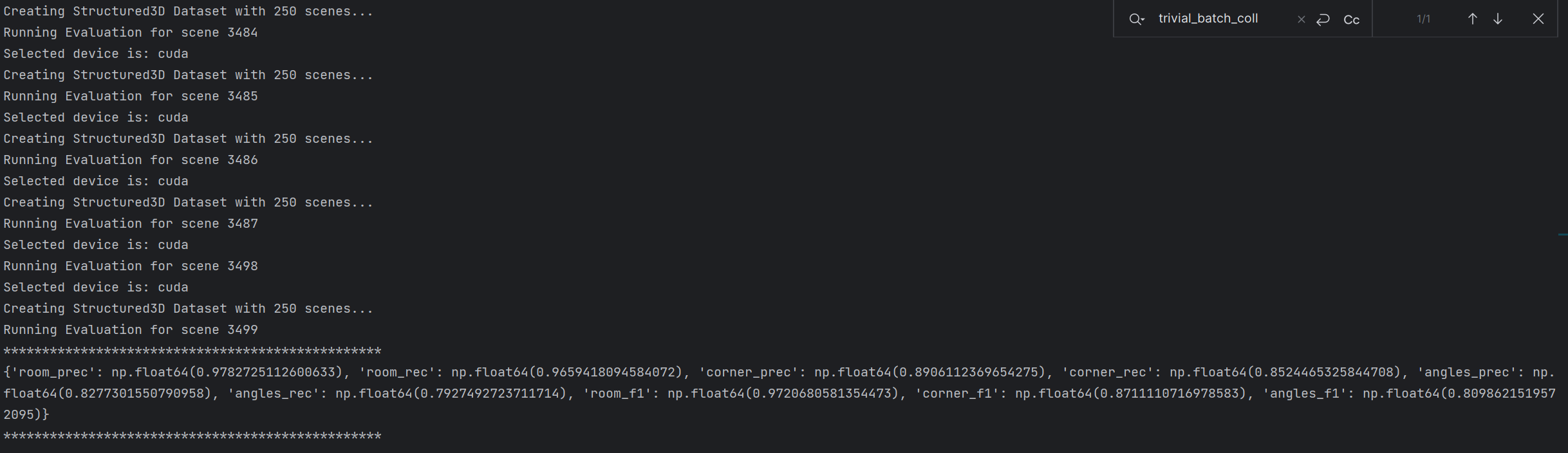
eval_stru3d.sh 是 RoomFormer 项目中用于评估 Structured3D 数据集上基础版(无语义)RoomFormer 模型的核心脚本,负责加载训练好的模型权重、执行推理、计算评估指标并可选可视化结果。博主直接脚本内容放在命令行执行。以下是详细说明:
bash
# 评估 Structured3D 基础版
python eval.py --dataset_name=stru3d --dataset_root=data/stru3d --eval_set=test --checkpoint=checkpoints/roomformer_stru3d.pth --output_dir=eval_stru3d --num_queries=800 --num_polys=20 --semantic_classes=-1 注意!!!!!: Windoes下将eval.py中的"--num_workers" 默认设置为 0。
特殊参数说明:
--dataset_name=stru3d:指定评估使用的数据集类型为 Structured3D,这是 RoomFormer 模型常用的户型重建数据集,也是该命令默认评估的核心数据集,可选值还包括 SceneCAD 数据集;--dataset_root=data/stru3d:设置 Structured3D 数据集的根目录路径,用于告诉代码去哪里读取数据集文件,必须与实际存放 Structured3D 数据的目录保持一致(需包含 train、val、test 子目录及 annotations 标注文件);--eval_set=test:指定评估的数据集划分,这里为测试集(test),主要用于获取论文汇报所需的最终评估指标,可选划分还包括训练集(train)和验证集(val),一般不用于正式指标汇报;--checkpoint=checkpoints/roomformer_stru3d.pth:指定要加载的模型预训练权重文件路径,用于加载训练好的 RoomFormer 基础版(无语义)模型,必须确保该 .pth 权重文件真实存在,否则会出现权重加载失败报错;--output_dir=eval_stru3d:设置评估结果的保存目录,评估过程中生成的指标日志、推理结果、可选的可视化图片等,都会自动保存到该目录下,若目录不存在会自动创建;--num_queries=800:设定模型最大可预测的角点数量为800个(20 个多边形 × 40 个角点),这是 RoomFormer 双层级查询(房间多边形+角点)中角点查询的固定超参数,对应 Structured3D 数据集的官方默认设置;--num_polys=20:设定模型最大可预测的房间(多边形)数量为20个,即单张户型图中模型最多可输出20个房间轮廓,是适配 Structured3D 数据集场景的固定参数;--semantic_classes=-1:关闭语义预测功能,仅评估基础的房间轮廓重建,该参数用于控制是否启用房间类型、门窗等语义信息的预测,-1 代表不启用语义,对应基础版 RoomFormer 模型的评估需求。
| 指标说明 | 核心含义 | 补充说明 |
|---|---|---|
room_prec |
房间检测精度 | 模型预测出的所有房间中,正确预测的房间数量 占总预测房间数量的比例。 (正确预测:房间轮廓与真实标注匹配度达到设定阈值) |
room_rec |
房间检测召回率 | 数据集中所有真实房间中,被模型正确预测出的房间数量 占总真实房间数量的比例。 |
corner_prec |
角点检测精度 | 模型预测出的所有角点中,正确预测的角点数量 占总预测角点数量的比例。 (正确预测:角点坐标与真实角点的距离小于设定阈值) |
corner_rec |
角点检测召回率 | 数据集中所有真实角点中,被模型正确预测出的角点数量 占总真实角点数量的比例。 |
angles_prec |
角度预测精度 | 模型预测的房间轮廓角度中,正确预测的角度数量 占总预测角度数量的比例。 (正确预测:预测角度与真实角度的差值小于设定阈值) |
angles_rec |
角度预测召回率 | 数据集中所有真实房间轮廓角度中,被模型正确预测出的角度数量 占总真实角度数量的比例。 |
room_f1 |
房间检测F1分数 | 房间精度(room_prec)和召回率(room_rec)的调和平均数,综合衡量房间检测的整体效果。 |
corner_f1 |
角点检测F1分数 | 角点精度和召回率的调和平均数,综合衡量角点预测的整体效果。 |
angles_f1 |
角度预测F1分数 | 角度精度和召回率的调和平均数,综合衡量角度预测的整体效果。 |
公式: F 1 = 2 × ( p r e c × r e c ) / ( p r e c + r e c ) F1 = 2 × (prec × rec) / (prec + rec) F1=2×(prec×rec)/(prec+rec)
结果输出路径在 RoomFormer\checkpoints\eval_stru3d:

-
可能出现的问题1: PyTorch 2.6 版本将
torch.load()的weights_only参数默认值从False改为了True,这个安全机制会阻止加载包含非权重数据(比如argparse.Namespace对象)的 checkpoint 文件。当前官方的 checkpoint 文件中不仅包含模型权重,还包含了argparse.Namespace类型的配置参数,触发了 PyTorch 的安全校验。
解决方案: 显式设置weights_only=False。python# checkpoint = torch.load(args.checkpoint, map_location='cpu') checkpoint = torch.load(args.checkpoint, map_location='cpu', weights_only=False) -
可能出现的问题2: NumPy 1.20 及以上版本正式移除了
np.int这个已废弃的别名 ,它原本是 Python 内置int的别名。代码plot_utils.py使用了np.int,在高版本 NumPy 中会触发AttributeError。
解决方案: 将np.int替换为np.int32或int/np.int64,推荐用np.int32明确指定精度。 -
可能出现的问题3: 代码 plot_utils.py 中
regions列表中的元素是形状不一致的序列(比如不同长度的数组/列表) ,当尝试用np.array(regions)[ind]转换为 NumPy 数组时,NumPy 无法处理这种"非均匀形状"的数据。具体来说,regions列表有7个元素,但这些元素的维度/长度各不相同(比如有的是2维数组,有的是1维数组,或长度不同),导致数组转换失败。
解决方案: 保留原始逻辑但避免数组转换失败,可以改用列表索引,放弃NumPy数组转换。python# regions = np.array(regions)[ind] regions = [regions[i] for i in ind] if ind is not None else regions
紧凑版 Structured3D 评估
eval_stru3d_tight.sh 是 RoomFormer 项目中用于在 Structured3D 数据集上以紧凑布局(tight layout)形式评估基础版(无语义)RoomFormer 模型 的专用评估脚本,负责加载训练好的模型权重、执行推理、计算紧凑户型墙线对应的评估指标并可选可视化结果。博主直接脚本内容放在命令行执行。以下是详细说明:
bash
# 评估 Structured3D 基础版 紧凑版
python eval.py --dataset_name=stru3d --dataset_root=data/stru3d --eval_set=test --checkpoint=checkpoints/roomformer_stru3d_tight.pth --output_dir=eval_stru3d_tight --num_queries=800 --num_polys=20 --semantic_classes=-1 可能出现的错误的解决方式参考基础版 Structured3D 评估小节。
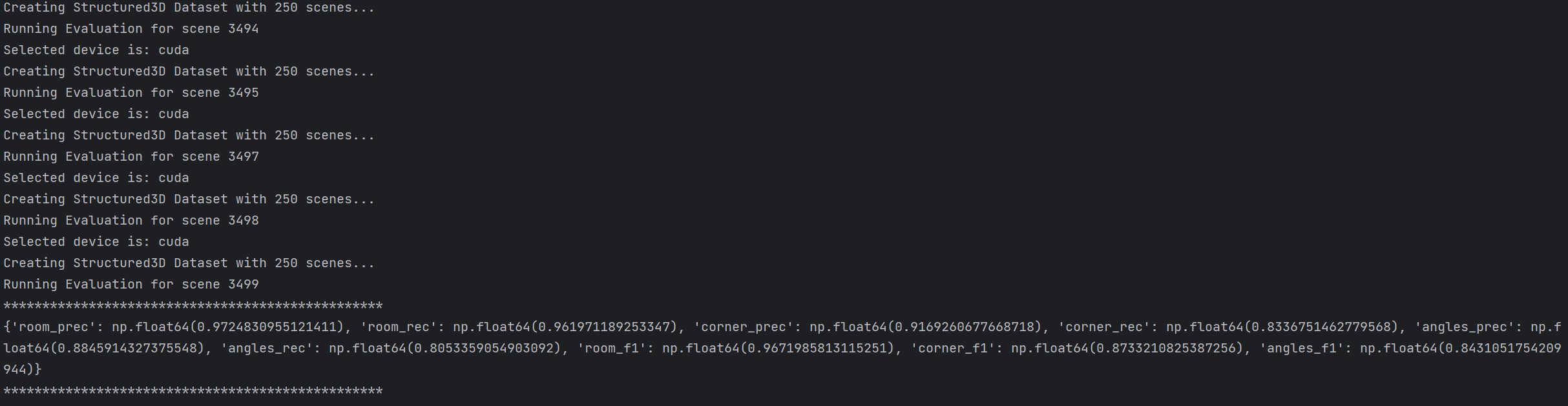
结果输出路径在 RoomFormer\checkpoints\eval_stru3d_tight:

SceneCAD 评估
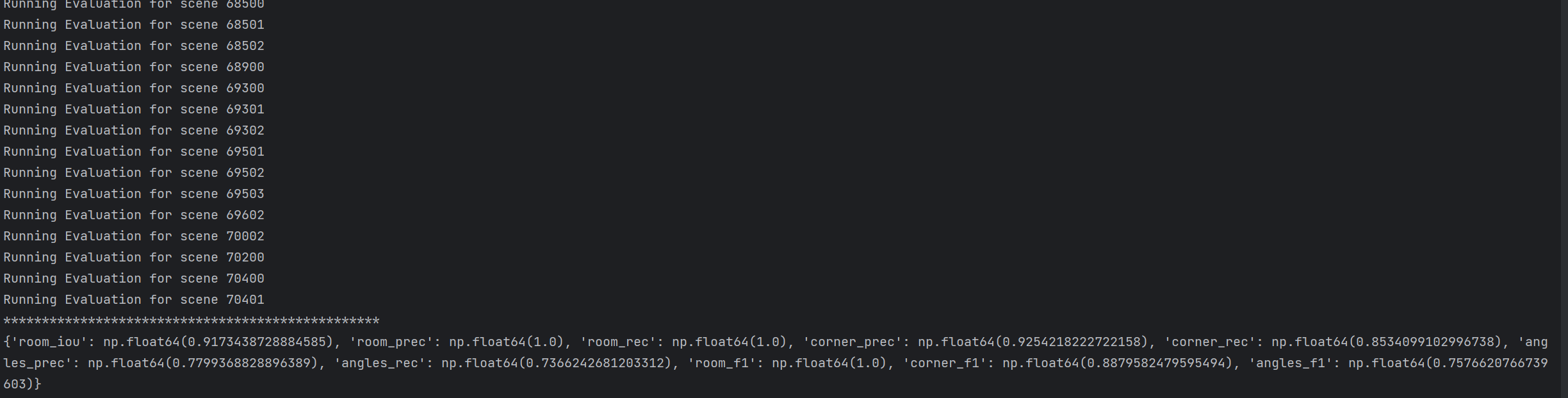
eval_scenecad.sh 是 RoomFormer 项目中专门用于评估 SceneCAD 数据集上 RoomFormer 模型 的脚本,功能和核心逻辑与 eval_stru3d.sh 一致,但针对 SceneCAD 数据集的特性调整了参数配置。博主直接脚本内容放在命令行执行。以下是详细说明:
bash
# 评估 SceneCAD
python eval.py --dataset_name=scenecad --dataset_root=data/scenecad --eval_set=val --checkpoint=checkpoints/roomformer_scenecad.pth --output_dir=eval_scenecad --num_queries=800 --num_polys=20 --semantic_classes=-1 可能出现的错误的解决方式参考基础版 Structured3D 评估小节。
| 指标说明(新增) | 核心含义 | 补充说明 |
|---|---|---|
room_iou |
房间多边形交并比 | 模型预测的房间轮廓与真实房间轮廓的交集面积除以并集面积,是衡量房间轮廓预测准确性的核心指标,数值越接近1表示轮廓匹配度越高。 |
其他指标已经在前文介绍过,不再赘述。
结果输出路径在 RoomFormer\checkpoints\eval_scenecad:

语义增强版评估
Structured3D 评估
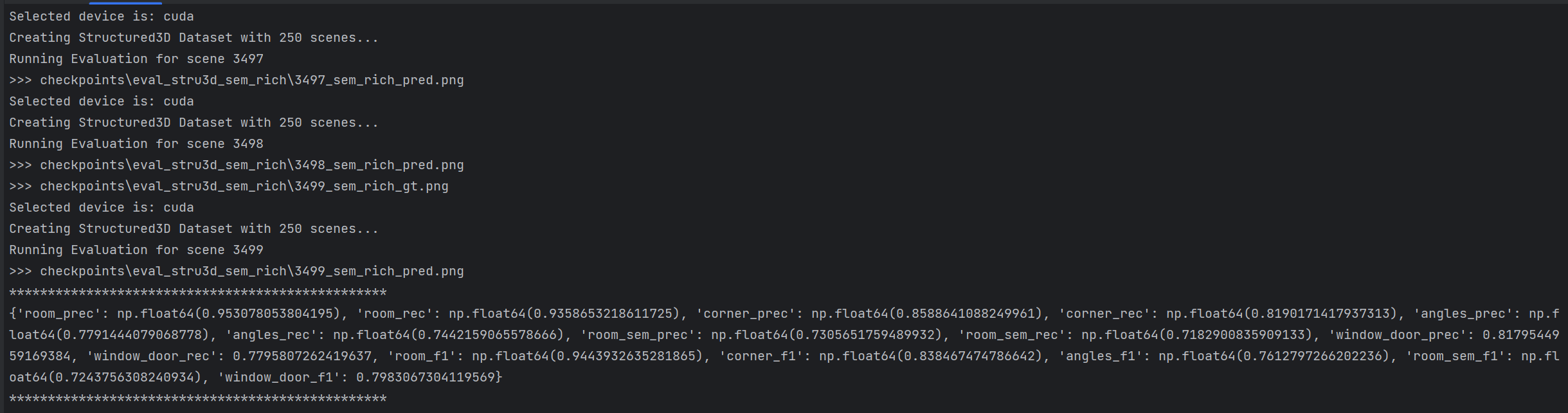
eval_stru3d_sem_rich.sh 是 RoomFormer 项目中针对 Structured3D 语义增强版模型 的评估脚本,相比基础版评估脚本,新增了房间类型、门、窗等语义信息的评估维度,核心适配语义增强版模型的参数和评估逻辑。博主直接脚本内容放在命令行执行。以下是详细说明:
bash
python eval.py --dataset_name=stru3d --dataset_root=data/stru3d --eval_set=test --checkpoint=checkpoints/roomformer_stru3d_semantic_rich.pth --output_dir=eval_stru3d_sem_rich --num_queries=2800 --num_polys=70 --semantic_classes=19部分新增/特殊参数说明:
--num_queries=2800:语义增强版需预测房间+门+窗三类多边形(共70个),因此最大角点数量设为 70×40=2800(适配语义版模型结构);--num_polys=70:设定模型最大可预测的多边形数量(包含房间、门、窗,基础版仅预测20个房间多边形);--semantic_classes=19:开启语义预测并指定语义类别数(16类房间类型+1类门+1类窗+1类空类别),是语义增强版的核心配置。
19类完整语义表格参见附录1。
| 指标说明(新增) | 核心含义 | 补充说明 |
|---|---|---|
room_sem_prec |
房间语义分类精度 | 模型预测出的所有房间中,房间类别预测正确且房间轮廓匹配 的数量,占总预测房间数量的比例。 |
room_sem_rec |
房间语义分类召回率 | 数据集中所有真实房间中,房间类别预测正确且房间轮廓匹配 的数量,占总真实房间数量的比例。 |
window_door_prec |
门窗检测精度 | 模型预测出的所有门窗中,被正确预测的门窗数量 占总预测门窗数量的比例。 (正确预测:门窗位置/轮廓与真实标注匹配度达到设定阈值) |
window_door_rec |
门窗检测召回率 | 数据集中所有真实门窗中,被模型正确预测出的门窗数量 占总真实门窗数量的比例。 |
room_sem_f1 |
房间语义分类F1分数 | 房间语义精度(room_sem_prec)和召回率(room_sem_rec)的调和平均数,综合衡量房间语义分类的整体效果。 |
window_door_f1 |
门窗检测F1分数 | 门窗检测精度和召回率的调和平均数,综合衡量门窗预测的整体效果。 |
其他指标已经在前文介绍过,不再赘述。
结果输出路径在 RoomFormer\checkpoints\eval_stru3d_sem_rich:
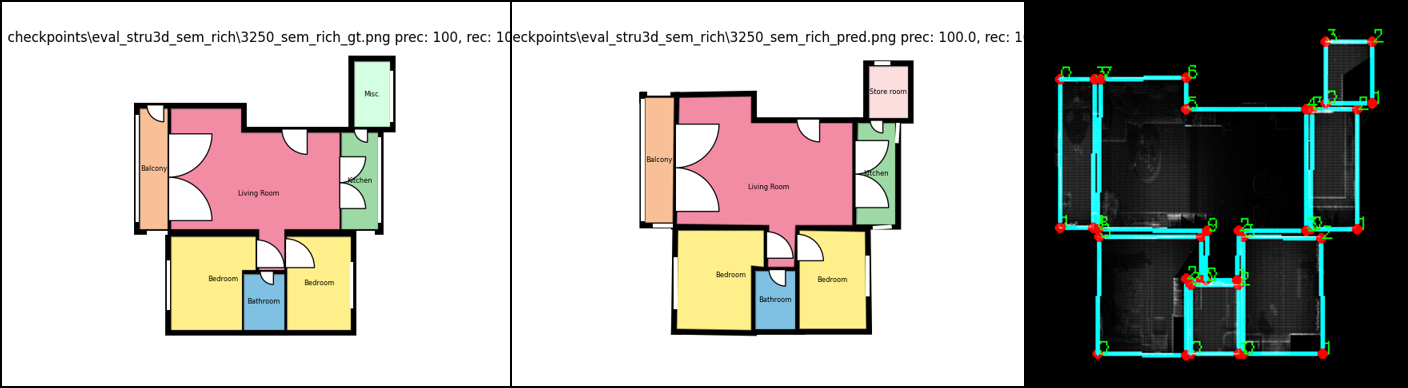
-
可能出现的问题1: 新版
shapely(2.0+)与descartes库存在不兼容问题,descartes内部解析Polygon.exterior坐标时返回 0 维数组,导致索引时报错:IndexError: too many indices for array: array is 0-dimensional, but 2 were indexed。即使输入的多边形坐标合法有效,依然会触发该错误。
解决方案: 弃用不兼容的descartes.PolygonPatch,改用 matplotlib 原生绘制 Shapely 多边形 ,直接从多边形 exterior 提取坐标,不再依赖 descartes 库。python# 修改位置1: # from descartes.patch import PolygonPatch # 这行直接替代 descartes,功能完全一样,不报错! from matplotlib.patches import Polygon as PolygonPatch # 修改位置2 else: # regular room polygon = Polygon(poly) # ########## 修复开始:原生绘制 shapely 多边形,不再用 descartes ########## polygon = list(polygon.exterior.coords) patch = PolygonPatch(polygon, facecolor='#FFFFFF', alpha=1.0, linewidth=0) ax.add_patch(patch) patch = PolygonPatch(polygon, facecolor=semantics_cmap[poly_type], alpha=0.5, linewidth=1, capstyle='round', edgecolor='#000000FF') ax.add_patch(patch) ax.text(np.mean(poly[:, 0]), np.mean(poly[:, 1]), semantics_label[poly_type], size=6, horizontalalignment='center', verticalalignment='center') # 修改位置3 for (line, line_type) in polygons_windows: line = LineString(line) poly = line.buffer(1.5, cap_style=2) # ########## 修复开始:原生绘制 shapely 多边形,不再用 descartes ########## poly = list(poly.exterior.coords) patch = PolygonPatch(poly, facecolor='#FFFFFF', alpha=1.0, linewidth=1, linestyle='dashed') ax.add_patch(patch) -
可能出现的问题2: 在无桌面环境 / 远程终端 / Windows 后台运行 时,matplotlib 默认使用 Tkinter 图形界面绘图,尝试创建窗口图标时失败,触发错误:
_tkinter.TclError: failed to create an iconphoto with image "pyimage4422"。
该错误与模型推理无关,仅由matplotlib 图形后端无法创建界面 导致。
解决方案: 在绘图脚本最顶部添加无界面后端设置 ,强制 matplotlib 使用非交互式后端Agg,不创建任何图形窗口,直接保存图片。python# 在 import matplotlib.pyplot as plt 前面添加俩行代码 import matplotlib matplotlib.use('Agg') import matplotlib.pyplot as plt
模型训练
基础版训练(无语义)
Structured3D 训练
train_stru3d.sh 是 RoomFormer 项目中用于训练 Structured3D 数据集上基础版(无语义)RoomFormer 模型的核心启动脚本,负责配置训练参数、加载数据集、初始化模型结构、启动模型训练、保存训练权重与日志,并支持断点续训等核心训练流程。博主直接脚本内容放在命令行执行。以下是详细说明:
bash
# 训练 Structured3D 基础版
python main.py --dataset_name=stru3d --dataset_root=data/stru3d --num_queries=800 --num_polys=20 --semantic_classes=-1 --job_name=train_stru3d参数说明:
--dataset_name=stru3d:指定训练使用的数据集类型为 Structured3D,这是 RoomFormer 模型常用的户型重建数据集,也是该命令默认训练的核心数据集,可选值还包括 SceneCAD 数据集;--dataset_root=data/stru3d:设置 Structured3D 数据集的根目录路径,用于告诉代码去哪里读取数据集文件,必须与实际存放 Structured3D 数据的目录保持一致(需包含 train、val、test 子目录及 annotations 标注文件);--num_queries=800:设定模型最大可预测的角点数量为800个(20 个多边形 × 40 个角点),这是 RoomFormer 双层级查询(房间多边形+角点)中角点查询的固定超参数,对应 Structured3D 数据集的官方默认训练设置;--num_polys=20:设定模型最大可预测的房间(多边形)数量为20个,即单张户型图中模型最多可输出20个房间轮廓,是适配 Structured3D 数据集场景的固定参数,与评估脚本保持一致;--semantic_classes=-1:关闭语义预测功能,仅训练基础的房间轮廓重建任务,该参数用于控制是否启用房间类型、门窗等语义信息的学习,-1 代表不启用语义,对应基础版 RoomFormer 模型的训练需求;--job_name=train_stru3d:指定本次训练任务的名称为 train_stru3d,用于区分不同训练实验,代码会自动以此名称创建日志保存目录、模型权重保存文件夹,方便后续管理、查找训练产出文件与复现实验。
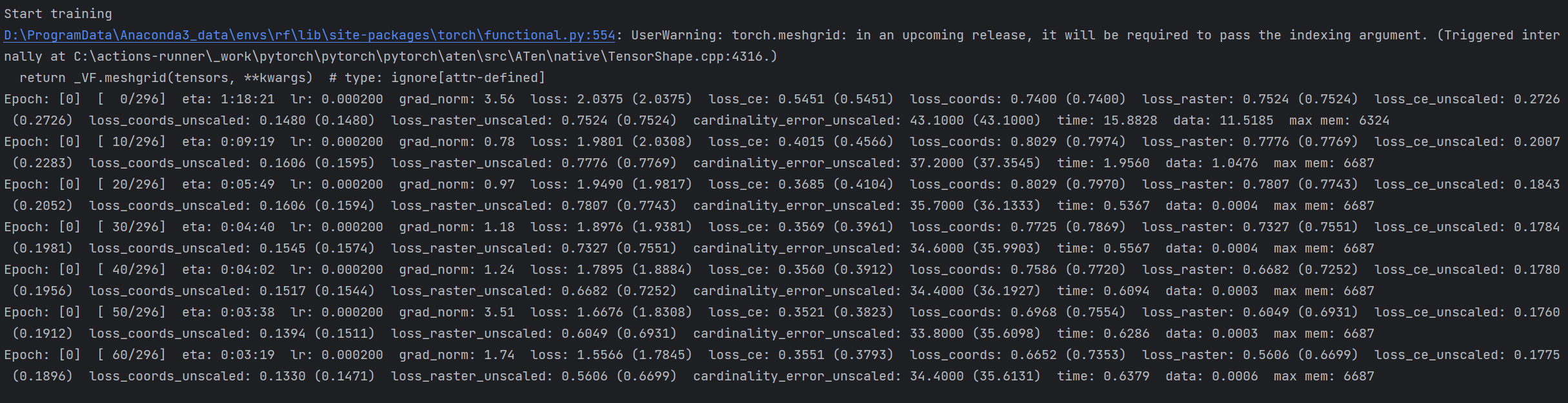
训练时不想用在线日志,直接关闭 Wandb 最省事:
bash
# 在终端运行,关闭 Wandb
wandb disabled
# 假如想使用,再打开 Wandb
wandb enabled然后重新运行训练脚本,就不会再要求输入 key 了。
-
可能出现的问题: Windows 系统下 PyTorch 多进程 DataLoader 无法序列化定义在
main()函数内部的trivial_batch_collator函数,触发报错:
AttributeError: Can't pickle local object 'main.<locals>.trivial_batch_collator'
解决方案1(最快,立刻能跑): 将数据加载的num_workers设置为 0 ,关闭多进程。运行训练命令时添加参数:
bash--num_workers 0解决方案2(根本修复,推荐,支持多进程加速):把
trivial_batch_collator函数从main()函数内部移到外部。错误代码(在 main 里面):pythondef main(args): ....... def trivial_batch_collator(batch): """ A batch collator that does nothing. """ return batch正确代码(移到 main 外面):
pythondef trivial_batch_collator(batch): """ A batch collator that does nothing. """ return batch def main(args):
结果输出路径在 RoomFormer\output\XXXX-XX-XX-XX-XX-XX_train_stru3d:
RoomFormer/
└── output/
└── XXXX-XX-XX-XX-XX-XX_train_stru3d/
├── checkpoint.pth # 训练保存的模型权重文件
└── log.txt # 训练日志文件
日志里所有指标完整说明:
| 指标名称 | 指标说明 | 核心含义 |
|---|---|---|
train_lr |
训练学习率 | 当前训练轮次使用的实时学习率,随训练过程动态变化,控制模型参数更新步长。 |
train_grad_norm |
训练梯度范数 | 模型参数梯度的归一化数值,用于监控梯度是否稳定,数值过大易导致训练震荡/不收敛。 |
train_loss |
训练总损失 | 模型训练的总目标损失值,由分类、坐标、栅格化损失加权求和得到,越小代表训练效果越好。 |
train_loss_ce |
训练分类损失(缩放后) | 房间/角点分类的交叉熵损失(已加权缩放),衡量类别预测的正确性。 |
train_loss_coords |
训练坐标损失(缩放后) | 角点坐标回归损失(已加权缩放),衡量预测角点与真实坐标的偏差程度。 |
train_loss_raster |
训练栅格化损失(缩放后) | 房间轮廓栅格化匹配损失(已加权缩放),衡量整体房间形状的还原精度。 |
train_loss_ce_unscaled |
训练分类损失(原始) | 未经过缩放的原始分类损失,用于观察分类任务本身的真实拟合程度。 |
train_loss_coords_unscaled |
训练坐标损失(原始) | 未经过缩放的原始坐标损失,用于观察角点定位任务的真实误差。 |
train_loss_raster_unscaled |
训练栅格化损失(原始) | 未经过缩放的原始形状匹配损失,直接反映房间轮廓生成的精准度。 |
train_cardinality_error_unscaled |
训练数量预测误差 | 模型预测的房间/角点数量与真实数量的平均偏差值,数值越小代表数量预测越准。 |
test_room_prec |
测试集房间精度 | 测试集上,模型预测房间中正确匹配真实房间的比例,越高越好。 |
test_room_rec |
测试集房间召回率 | 测试集上,所有真实房间中被模型成功检测出的比例,越高越好。 |
test_corner_prec |
测试集角点精度 | 测试集上,模型预测角点中正确匹配真实角点的比例,越高越好。 |
test_corner_rec |
测试集角点召回率 | 测试集上,所有真实角点中被模型成功检测出的比例,越高越好。 |
test_angles_prec |
测试集角度精度 | 测试集上,模型预测的房间角度中正确角度占预测总角度的比例。 |
test_angles_rec |
测试集角度召回率 | 测试集上,所有真实角度中被模型成功预测的比例。 |
test_loss |
测试集总损失 | 模型在测试集上的总泛化损失,反映模型在未知数据上的拟合能力。 |
test_loss_ce |
测试集分类损失(缩放后) | 测试集上的类别预测损失,衡量泛化分类能力。 |
test_loss_coords |
测试集坐标损失(缩放后) | 测试集上的角点坐标误差,衡量泛化定位能力。 |
test_loss_raster |
测试集栅格损失(缩放后) | 测试集上的房间轮廓匹配损失,衡量泛化形状生成能力。 |
test_loss_ce_unscaled |
测试集分类损失(原始) | 测试集上未缩放的原始分类误差。 |
test_loss_coords_unscaled |
测试集坐标损失(原始) | 测试集上未缩放的原始坐标误差。 |
test_loss_raster_unscaled |
测试集栅格损失(原始) | 测试集上未缩放的原始形状匹配误差。 |
test_cardinality_error_unscaled |
测试集数量预测误差 | 测试集上预测房间/角点数量与真实数量的平均偏差。 |
epoch |
当前训练轮次 | 模型已完成的训练轮数。 |
n_parameters |
模型参数量 | RoomFormer 模型的总可训练参数数量,用于衡量模型规模。 |
### 紧凑版 Structured3D 训练
注意!!!源代码这种没有紧凑房间布局(Tight Room Layout)的训练方式!!!!具体实现参考附录2的说明。 后续博主要是实现代码会补充完整。
SceneCAD 评估
train_scenecad.sh 是 RoomFormer 项目中用于训练 SceneCAD 数据集上基础版(无语义)RoomFormer 模型的核心启动脚本,负责配置训练超参数、加载 SceneCAD 数据集、初始化模型结构、启动模型训练、保存训练权重与日志,并支持断点续训等完整训练流程。博主直接脚本内容放在命令行执行。以下是详细说明:
bash
# 评估 SceneCAD
python main.py --dataset_name=scenecad --dataset_root=data/scenecad --lr=5e-5 --epochs=400 --lr_drop=[320] --num_queries=800 --num_polys=20 --semantic_classes=-1 --job_name=train_scenecad部分新增/特殊参数说明:
--lr=5e-5:设置模型训练的初始学习率为 0.00005,控制模型参数更新的步长大小,是 SceneCAD 数据集训练的官方推荐超参数;--epochs=400:设定模型的总训练轮数为400轮,即模型会完整遍历整个训练集400次,是适配 SceneCAD 数据集收敛需求的固定配置;--lr_drop=[320]:设定学习率衰减的轮次为第320轮,训练到320轮时学习率会自动按比例下降,帮助模型稳定收敛、提升最终性能;
可能出现的错误的解决方式参考基础版 Structured3D 训练小节。
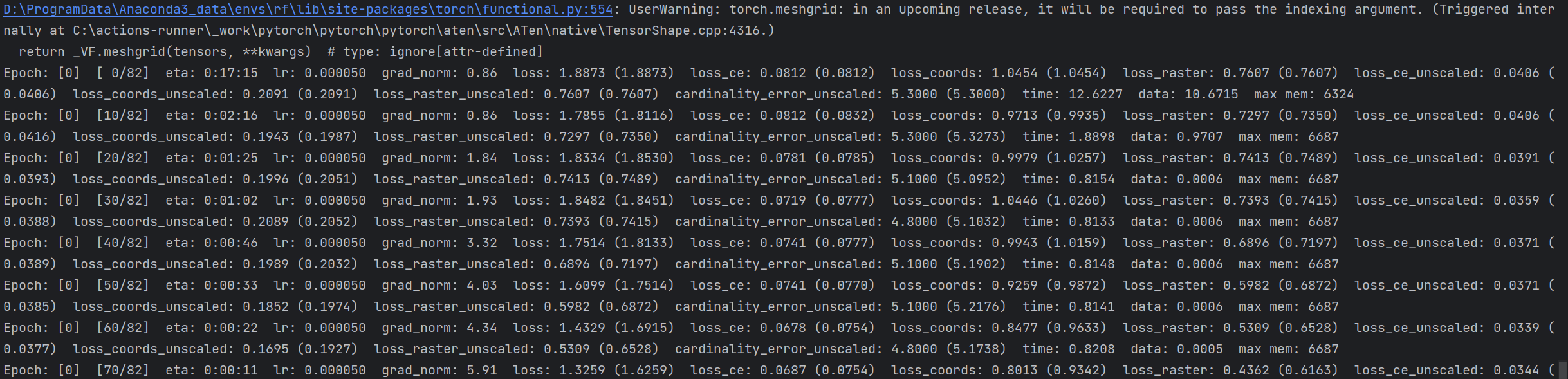
结果输出路径在 RoomFormer\output\XXXX-XX-XX-XX-XX-XX_train_scenecad:
RoomFormer/
└── output/
└── XXXX-XX-XX-XX-XX-XX_train_scenecad/
├── checkpoint.pth # 训练保存的模型权重文件
└── log.txt # 训练日志文件日志里新增指标说明:
| 指标名称 | 指标说明 | 核心含义 |
|---|---|---|
test_room_iou |
测试集房间交并比 | 预测房间与真实房间的重叠度(IoU),是布局重建最核心的指标,越大越好。 |
其他指标已经在前文介绍过,不再赘述。
语义增强版评估
Structured3D 训练
train_stru3d_sem_rich.sh 是 RoomFormer 项目中用于训练 Structured3D 数据集上语义丰富版(带语义)RoomFormer 模型的核心启动脚本,负责配置训练参数、加载带语义标注的 Structured3D 数据集、初始化带语义预测分支的模型结构、启动多任务联合训练、保存模型权重与训练日志,并支持断点续训以完成房间轮廓+语义类别联合学习的完整训练流程。博主直接脚本内容放在命令行执行。以下是详细说明:
bash
python main.py --dataset_name=stru3d --dataset_root=data/stru3d --num_queries=2800 --num_polys=70 --semantic_classes=19 --job_name=train_stru3d_sem_rich这里可以适当降低--batch_size的数量,否则会显存溢出,
部分新增/特殊参数说明:
--num_queries=2800:设定模型最大可预测的角点数量为2800个(70 个多边形 × 40 个角点),这是 RoomFormer 双层级查询(房间多边形+角点)中角点查询的超参数,对应 Structured3D 语义丰富版场景的官方默认设置;--num_polys=70:设定模型最大可预测的房间/语义区域(多边形)数量为70个,即单张户型图中模型最多可输出70个带语义的轮廓区域,是适配 Structured3D 语义丰富版数据集的核心参数;--semantic_classes=19:开启语义预测功能,设置语义类别总数为19类,用于训练房间类型、功能区、门窗等语义信息的联合学习,对应语义丰富版 RoomFormer 模型的训练需求;
19类完整语义表格参见附录1。
可能出现的错误的解决方式参考基础版 Structured3D 训练小节。

结果输出路径在 RoomFormer\output\XXXX-XX-XX-XX-XX-XX_train_stru3d_sem_rich:
RoomFormer/
└── output/
└── XXXX-XX-XX-XX-XX-XX_train_stru3d_sem_rich/
├── checkpoint.pth # 训练保存的模型权重文件
└── log.txt # 训练日志文件日志里新增指标说明:
| 指标名称 | 指标说明 | 核心含义 |
|---|---|---|
train_loss_ce_room |
训练房间语义分类损失(缩放后) | 房间语义类别 预测的交叉熵损失(已加权缩放),衡量19类房间语义分类的准确性。 |
train_loss_ce_room_unscaled |
训练房间语义分类损失(原始) | 未经过缩放的原始房间语义分类 损失,反映语义分类任务的真实误差。 |
test_room_sem_prec |
测试集房间语义精度 | 模型预测的房间中,房间类别也预测正确 的比例,是语义丰富版专属核心指标。 |
test_room_sem_rec |
测试集房间语义召回率 | 所有真实带语义标签 的房间中,被模型同时检测到且类别预测正确的比例。 |
test_window_door_prec |
测试集门窗检测精度 | 模型预测的门窗区域 中,正确匹配真实门窗的比例。 |
test_window_door_rec |
测试集门窗检测召回率 | 数据集中所有真实门窗区域,被模型成功检测出的比例。 |
test_loss_ce_room |
测试集房间语义分类损失(缩放后) | 测试集上房间语义分类 的误差,衡量泛化语义分类能力。 |
test_loss_ce_room_unscaled |
测试集房间语义分类损失(原始) | 测试集上未缩放的原始房间语义分类误差。 |
其他指标已经在前文介绍过,不再赘述。
附录 1
Structured3D 19类完整语义表格(RoomFormer官方)
| 类别ID | 语义名称 | 类别说明 |
|---|---|---|
| 0 | Living Room | 客厅 |
| 1 | Kitchen | 厨房 |
| 2 | Bedroom | 卧室 |
| 3 | Bathroom | 卫生间 |
| 4 | Balcony | 阳台 |
| 5 | Corridor | 走廊/过道 |
| 6 | Dining Room | 餐厅 |
| 7 | Study | 书房 |
| 8 | Studio | 工作室/多功能房 |
| 9 | Store Room | 储藏室 |
| 10 | Garden | 花园/庭院 |
| 11 | Laundry Room | 洗衣房 |
| 12 | Office | 办公室 |
| 13 | Basement | 地下室 |
| 14 | Garage | 车库 |
| 15 | Misc | 未定义/无效房间(原始数据集背景) |
| 16 | Door | 门(RoomFormer新增建筑开口类) |
| 17 | Window | 窗(RoomFormer新增建筑开口类) |
| 18 | Empty | 空/背景(模型填充类) |
附录 2
紧凑房间布局(Tight Room Layout)的检测/实现方式参考论文附录B专门说明紧凑房间布局 (tight room layout)的表示、训练适配与检测逻辑,核心是把相邻房间共享墙体 用单条边 表示,区别于原方法"房间独立多边形、墙体用间距表示"的标准布局。具体检测与实现方式如下:
一、紧凑房间布局的核心定义
- 标准布局(原方法)
房间用独立闭合多边形 表示,相邻房间的间距隐含内墙厚度,与Structured3D数据集原始标注完全一致。 - 紧凑布局(HEAT采用)
房间表示为平面图(planar graph) ,相邻房间的墙体共享单条边,无间距、无墙体厚度,是简化版布局。
二、紧凑房间的检测/训练适配方式
-
训练数据预处理
- 对原始Ground Truth多边形做边缘合并 :把相邻房间的相邻边融合为单条共享边,消除墙体厚度。
- 把合并后的平面图转为模型可学习的紧凑多边形标注,用于训练紧凑版RoomFormer。
-
模型推理与检测
- 模型直接输出紧凑布局平面图,无冗余顶点、无间距。
- 评估时不做后处理,直接用原始未修改的GT标注计算指标,保证公平对比。
-
与标准布局的检测差异
维度 标准布局 紧凑布局 墙体表示 房间间距隐含厚度 共享单条边,无厚度 顶点约束 顶点独立,无强制共点 强制相邻房间顶点共点 角度检测 自然角度 角度更规整、精度更高 房间IoU 更高 略低(易重叠)
三、紧凑布局检测的效果结论
- 紧凑版RoomFormer∗房间指标略降,但仍超越所有基线;
- 角度精度显著提升,因为强制顶点共点、角度互补,更符合建筑几何约束;
- 证明原方法的SOTA性能不依赖布局表示,紧凑布局同样能实现领先检测效果。
总结
尽可能简单、详细的介绍了RoomFormer的安装流程以及RoomFormer的使用方法。后续会根据自己学到的知识结合个人理解讲解RoomFormer的原理和代码。