libRaptorQ(RFC 6330 RaptorQ 前向纠错码实现)源码的系统性分析。我从「算法原理 → 架构分层 → 模块交互 → 数据流转」四个维度展开。
源码地址:https://github.com/LucaFulchir/libRaptorQ.git
一、RaptorQ 算法原理概述
RaptorQ 属于 Fountain Code(喷泉码 / 无码率码),核心思想:
- 发送端把 K 个源符号编码成"任意多"个修复符号
- 接收端不关心丢失顺序,只要累计收到任意 ≥ K(+ε) 个符号就能恢复整包数据(K 很大时 ε ≈ 0,典型情况 2 个 overhead 已能 > 99.99% 成功解码)
它属于「预编码 + LT 码」的级联结构(Raptor 家族),比普通 LT 码在 K 较大时更稳定。
1. 有限域 GF(256) --- Octet.hpp
所有符号内容按字节看作 GF(2⁸) 上的元素:
- 加/减/异或是同一运算:
a ± b == a ^ b(见Octet::operator+=直接用data ^= a.data) - 乘除通过对数/指数查表
oct_exp[]/oct_log[]完成,单次 O(1)
这使得整套矩阵运算既快又满足线性代数性质。
2. 核心参数 --- Parameters.hpp
给定源符号数 K,按 RFC6330 table2.hpp 查表得到一组固定参数:
| 符号 | 含义 |
|---|---|
K_padded (K') |
填充到表里最近的"系统友好" K |
S |
LDPC 冗余符号数 |
H |
HDPC(高密度 MDS)冗余符号数 |
W |
LT 符号数 |
L = K' + S + H |
中间符号总数(intermediate symbols) |
P = L − W, U = P − H, B = W − S, P1 |
其它派生量 |
J(K) |
系统索引,影响 tuple 生成的随机性 |
3. 预编码矩阵 A (L × L) --- Precode_Matrix_Init.hpp
A 是 RaptorQ 的"灵魂",由 6 个子矩阵按块拼成:
B列 S列 P列
┌───────────┬────────┬────────┐
S行 │ LDPC1 │ I_S │ LDPC2 │
├───────────┴────────┼────────┤
H行 │ MT · GAMMA │ I_H │ ← HDPC
├────────────────────┴────────┤
K'行 │ G_ENC (LT) │
└─────────────────────────────┘
LDPC1:由循环移位构造的 SxB 稀疏矩阵(init_LDPC1)LDPC2:每行连续两个 1、逐行右移(init_LDPC2)HDPC = MT · GAMMA:MT每行两个随机 1 + 一列 α^i;GAMMA是 α^(i-j) 下三角。保证 H 行接近 MDSG_ENC:LT 码部分,第 i 行由get_idxs(i)给出的列置 1(由随机 tupled,a,b,d1,a1,b1决定)
编码时求解:A · C = D,其中 D 前 S+H 行为 0,接着是 K' 个源符号(末尾 0 填充)。解得的 C 就是 L 个中间符号。
4. 5 阶段高斯消元求解器 --- Precode_Matrix_Solver.hpp
RFC 6330 规定的"O(L²)均摊"特殊消元流程(intermediate()):
| 阶段 | 关键动作 |
|---|---|
| Phase 0 | 修复符号替换:把丢失源符号行替换为修复符号依赖行(仅解码路径) |
| Phase 1 | 选择 V 区"r 最小"的行;若 r=2 则用并查集图(util/Graph.hpp)选择最大连通分量里的边,做行/列交换及消元 |
| Phase 2 | 对 U_lower 做标准高斯消元,成功 ⇒ 秩 = L |
| Phase 3 | 用 X 更新 A 与 D 的前 i 行,使 U_upper 稀疏化 |
| Phase 4 | 回代消去 U_upper 中的非零项 |
| Phase 5 | 前 i 行最终归一化,A 变为单位阵 |
每步记录在 std::deque<Operation>(Operation.hpp,SWAP/ADD_MUL/DIV/BLOCK/REORDER),可以回放到 I_L 上构造出 A⁻¹,进而压缩缓存(LZ4)到 Decaying_LF 以后复用 ------ 这是 libRaptorQ 性能优化的关键。
5. 生成 Source / Repair 符号 --- Precode_Matrix::encode()
获得中间符号矩阵 C 后,任意 ESI(0..K'-1 是源,K'~ 是修复)的符号通过同一个 LT 过程产出:
t = tuple(ISI) // 随机 tuple
ret = Cb
for j=1..d-1: b=(b+a)%W; ret += Cb // 主 LT
... // PI 分量
for j=1..d1-1: b1=(b1+a1)%P1; while b1>=P: b1=(b1+a1)%P1
ret += CW+b1
XOR(GF 加)若干行即可,编码极快。
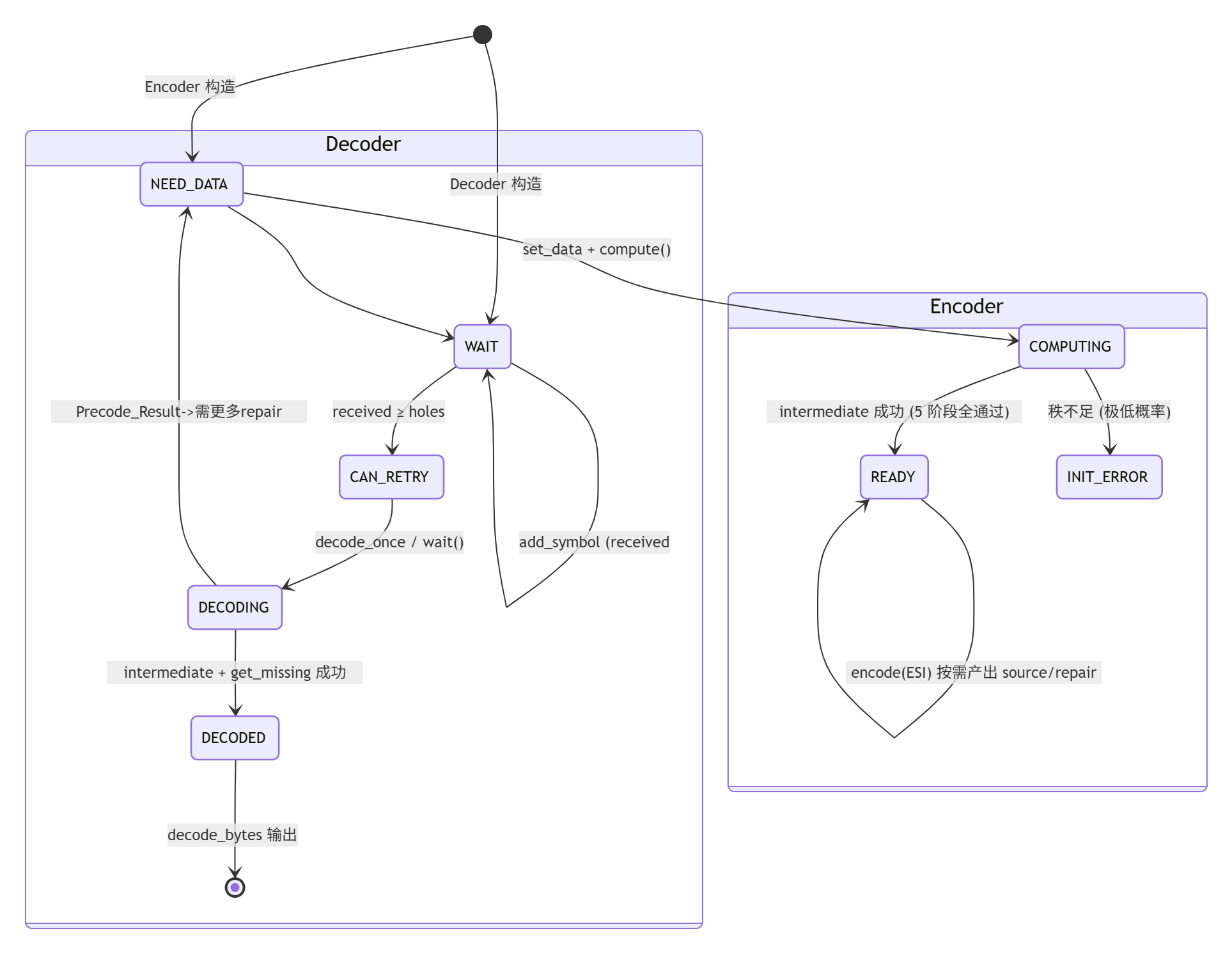
6. 解码 --- Decoder.hpp
- 累积 source + repair,直到
received ≥ K时设can_retry - 以 bitmask 记"洞",用 repair 行替换丢失源行的依赖
- 再次解
A · C = D→ 用get_missing()对每个"洞" ESI 调encode()还原 - 失败(秩不足)则继续等更多 repair;成功后解锁 source_symbols
二、整体架构分层图
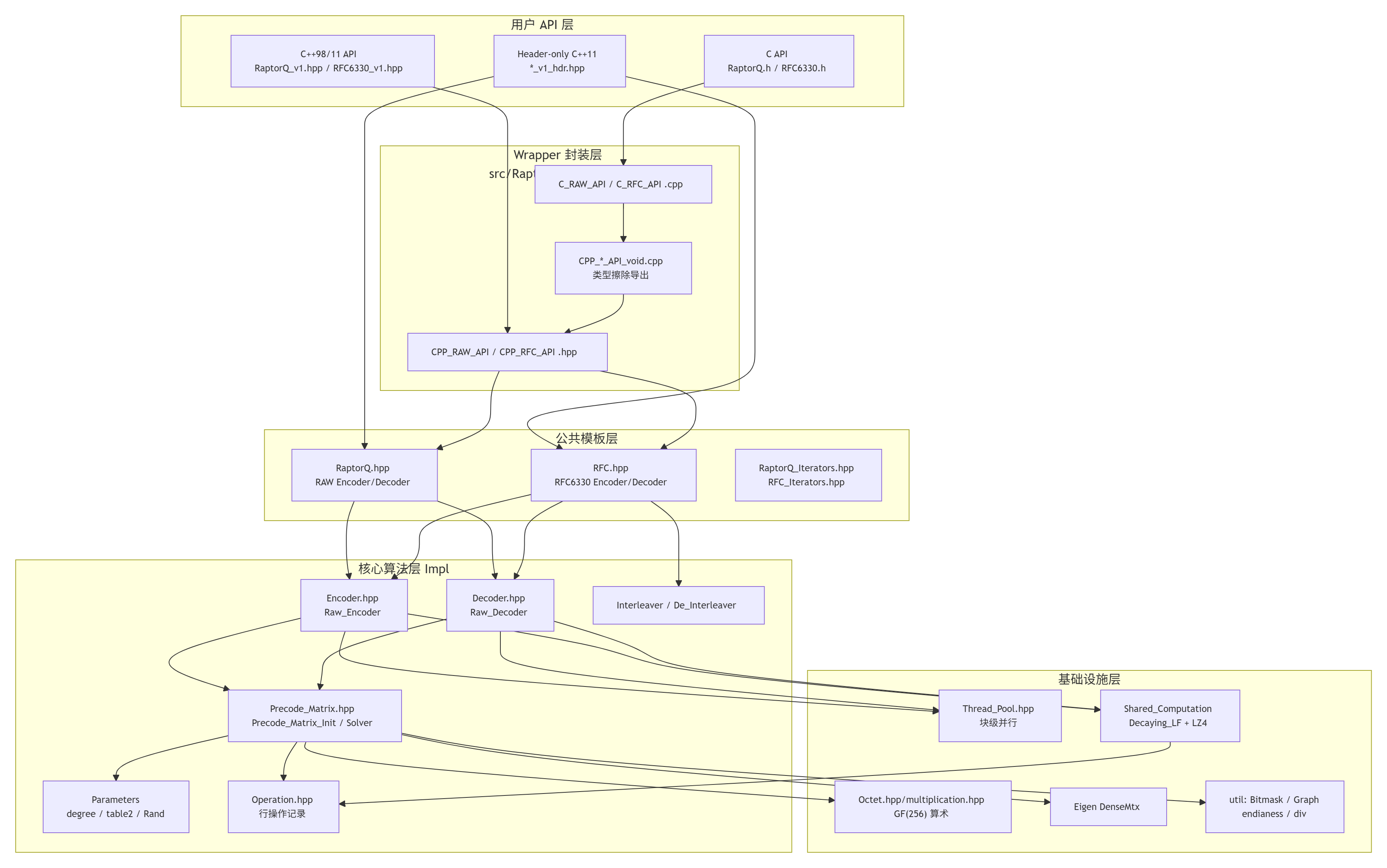
分层说明
| 层 | 职责 |
|---|---|
| 用户 API | 三种语言绑定、头文件-only 与链接库两种交付方式 |
| Wrapper | 把模板实例化后通过 void* 类型擦除导出 ABI 稳定的符号 |
| 公共模板 | 对外开放的 Encoder/Decoder 模板,内部持有 Raw_Encoder/Raw_Decoder |
| 核心算法 | Raw_* + Precode_Matrix + Interleaver 构成 RFC 6330 主逻辑 |
| 基础设施 | GF(256) 查表、矩阵、线程池、计算缓存(LZ4 压缩)、位图、并查集 |
三、数据流转图(编码 → 传输 → 解码 全链路)

关键数据对象
| 对象 | 维度 | 含义 |
|---|---|---|
D |
(L+overhead) × symbol_size | 约束向量:0 + 源符号 + 填充 + repair |
A |
L × L (+overhead 行) | 预编码约束矩阵,解 A·C=D |
C |
L × symbol_size | 中间符号,LT 码的"输入" |
Operation 队列 |
--- | 复原 A⁻¹ 用的行操作序列(SWAP/ADD_MUL/DIV/BLOCK/REORDER) |
Bitmask |
K bit | 接收端"洞"跟踪 |
DLF<vector<u8>, Cache_Key> |
--- | Decaying LeastFrequent 缓存,LZ4 压缩 A⁻¹,跨会话复用 |
四、编码器 / 解码器内部状态机
五、分块与并行模型(RFC 6330 层次)--- Interleaver.hpp
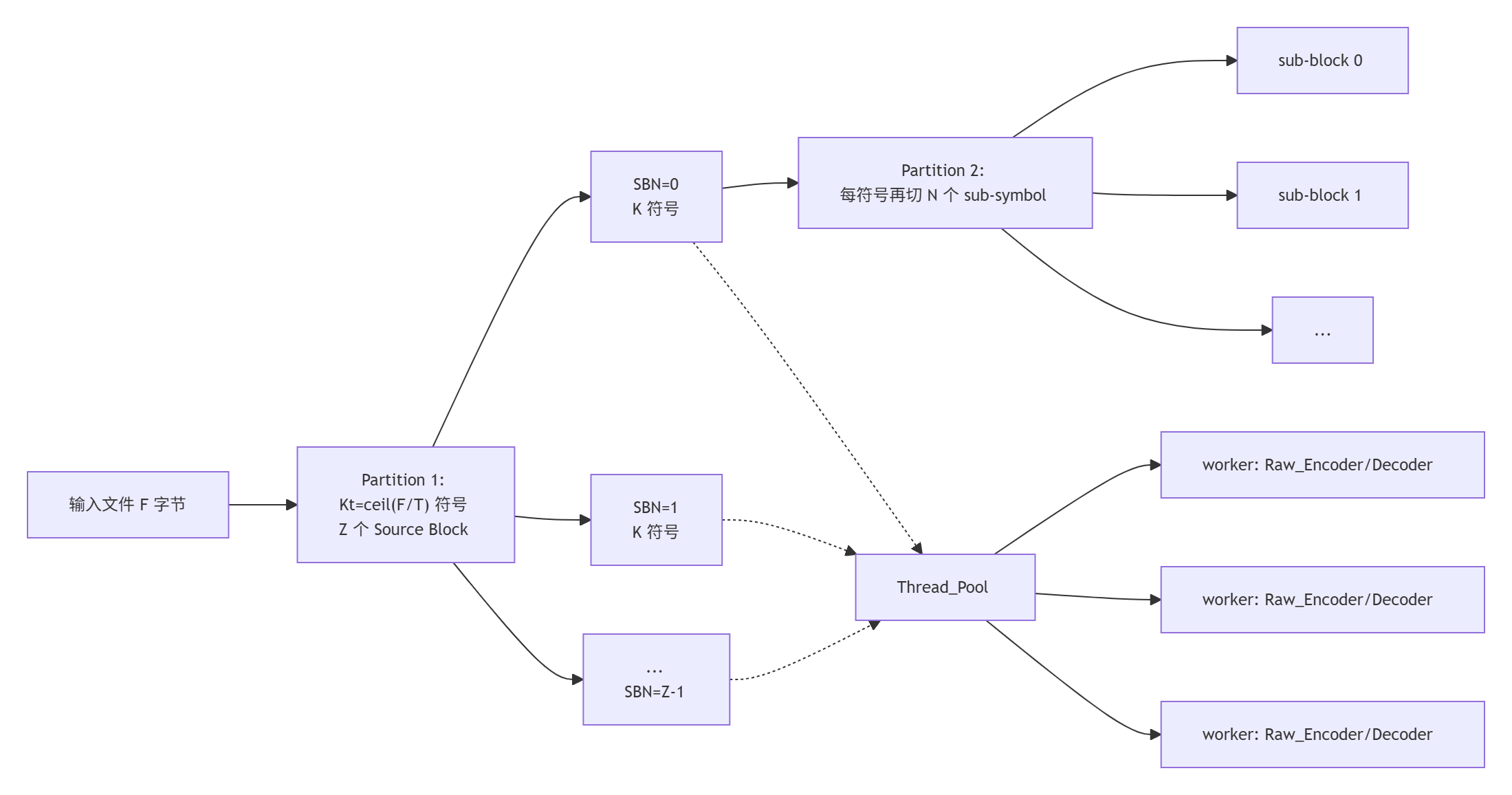
要点
- 块间并行:每个 Source Block(SBN)完全独立,由
Thread_Pool分派到 N 个 worker 并行编/解码 - 块内交织:sub-block 让"突发丢 1 个 symbol"实际上只丢了每个 sub-symbol 的一小段,抗突发错误能力更强
- 单块内的 GF 运算由 Eigen 向量化(
DenseMtx = Eigen::Matrix<Octet, ..., RowMajor>)
六、计算缓存(关键性能优化)--- Shared_Computation/Decaying_LF.hpp
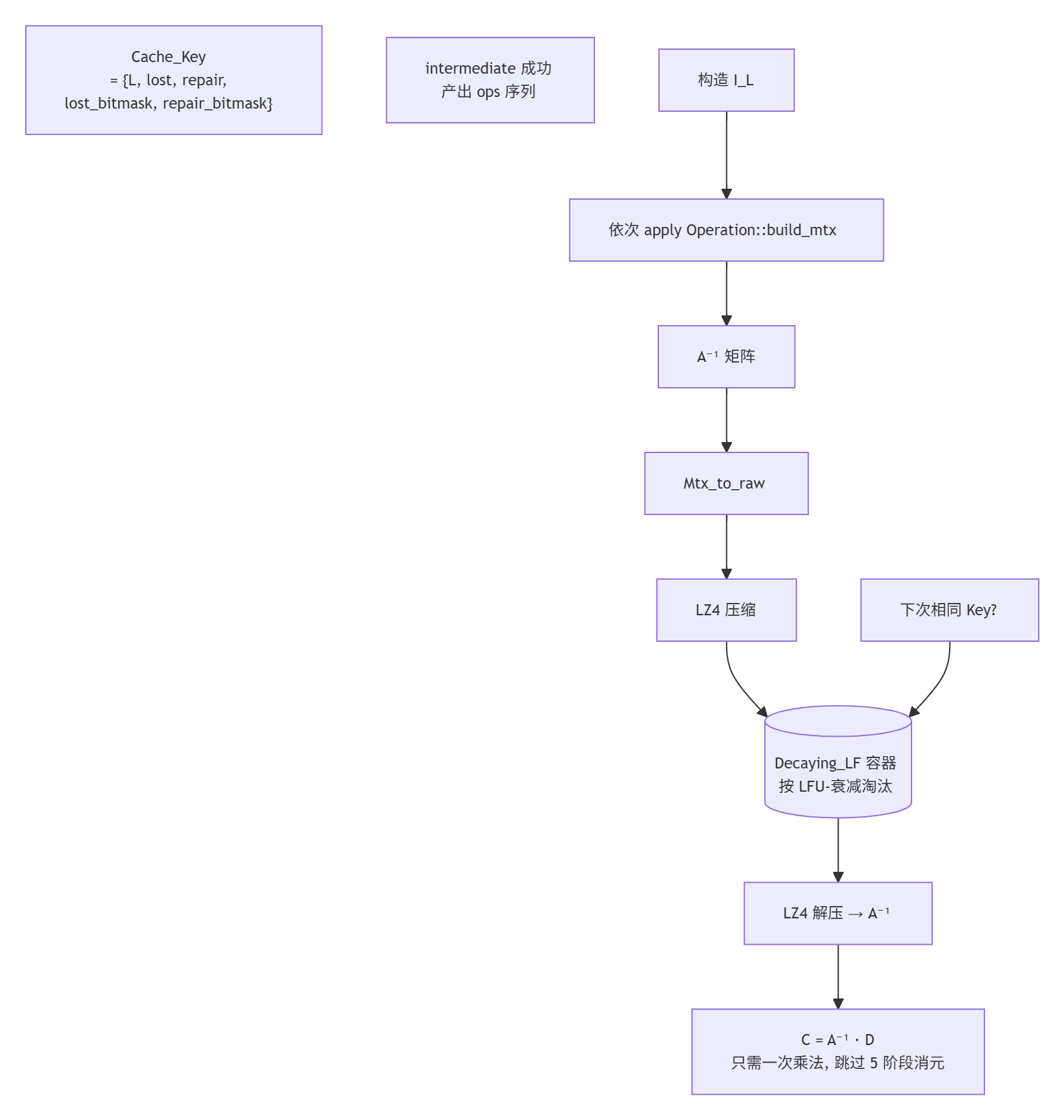
这样第二次及以后遇到同样 K、同样丢包模式时,从"求解"退化为"一次矩阵乘",带来数量级加速。
七、GF(256) 运算与矩阵乘(Hotspot)
| 运算 | 实现(Octet.hpp / multiplication.hpp) |
复杂度 |
|---|---|---|
a + b, a − b |
a ^ b |
1 XOR |
a * b |
oct_exp[oct_log[a-1] + oct_log[b-1]](a,b ≠ 0) |
2 查表 + 1 加 |
a / b |
oct_exp[oct_log[a-1] − oct_log[b-1] + 255] |
2 查表 + 1 加 |
| 行 XOR (Eigen 矩阵行) | A.row(i) += A.row(j) 向量化 |
O(cols) |
解码 Phase 1~5 里最耗时的就是 A.row(x) += A.row(y) * m 这类操作,因此:
RowMajor存储 ⇒ 行 XOR 内存连续Octet特化成uint8_t的 POD ⇒ Eigen 能走 SIMD
八、总结:设计亮点
- 分层极其清晰:算法核心(模板) / 封装(Wrapper) / 导出(C ABI)彻底解耦,让同一份算法代码既能 header-only,又能编出 C/C++98 静态库。
- 符合 RFC 6330:
table2.hpp、degree.hpp、Rand.hpp均为 RFC 原表;变量名与 RFC 一致(K, K', S, H, W, L, P, P1, U, B, J)。 - 对 Raptor 典型优化都实现了:
- LDPC+HDPC+LT 三段 A 矩阵
- Phase 1 的图分量启发式(
util/Graph.hpp并查集) - A⁻¹ LZ4 缓存(
Decaying_LF) - 块级
Thread_Pool并行
- 接口对称:
Raw_Encoder::encode和Precode_Matrix::encode(解码时补洞)走完全相同 tuple 算法 --- 这是"系统码"的根基:ESI < K 直接返回源符号,ESI ≥ K 才做 LT XOR。 - 可中断:所有耗时循环携带
keep_working与Work_State双标志,可随时 graceful abort(对上层异步 API 友好)。
九、测试用例
下篇文章补充测试用例及效果,敬请期待。