把 OpenClaw 接进电商后台之后,我对 AI 落地这件事的理解变了
过去一段时间,我一直在做一件事:尝试把 OpenClaw 接进一个电商平台后台,让"龙虾"这个智能体去承担一部分后台辅助工作。
最开始我对这件事的判断其实挺乐观。 因为从表面上看,它不像训练一个大模型那么重,也不像重构整套业务架构那么复杂。无非是把一个有一定理解和执行能力的 Agent 接进来,让它帮忙处理后台里那些高频、重复、跨系统的信息整理和流程辅助工作。
但真正做进去之后,我很快发现,问题根本不在"能不能接",而在于:接进去之后,它到底能不能在真实业务环境里稳定地发挥作用。
今天来复盘一下吧:记录我在这次尝试里踩过的坑、做过的取舍,以及为什么我后来越来越觉得,AI 项目最难的部分,从来都不是"模型够不够聪明",而是"系统能不能长期跑稳"。
一、为什么会想到让 Agent 来帮电商后台"干活"
做过电商后台的人应该都有类似感受:后台系统不像前台那样直观,但它几乎是整个业务运转的中枢。
商品、订单、库存、活动、售后、客服、风控、工单、告警,这些东西平时分散在不同系统里,各自都有状态、有规则、有依赖。只要业务规模稍微上来,后台同学每天就会花很多时间在信息切换、规则核对、异常排查和重复操作上。
我当时对 OpenClaw 的期待,不是做一个"能聊天的机器人",而是希望它能往更实用的方向走一步。 比如:
- 帮忙汇总订单异常并给出排查建议;
- 根据运营提问,把相关后台数据和入口串起来;
- 对库存、活动、商品状态之间的冲突做初步检查;
- 整理日志和告警,把明显噪音先过滤掉;
- 把一些重复性的 SOP 问题先接住。
换句话说,我更想让"龙虾"扮演一个后台协作助手,而不是一个"看起来很聪明"的聊天窗口。
这个想法在最开始是成立的。因为只要跑通了几个简单流程,你会很容易产生一种感觉:这件事已经差不多了,剩下只是补细节。
后来我才知道,真正麻烦的,恰恰就是这些"细节"。

二、我踩到的第一个坑,是把后台问题想得太像"问答问题"了
刚开始做的时候,我的思路比较直接: 给 OpenClaw 足够的上下文,补上工具调用,再把后台文档、接口说明、一些 SOP 和规则喂进去,它应该就能处理不少问题。
但很快我就发现,电商后台里的很多问题,本质上不是"语义理解问题",而是状态系统问题。
比如一个看起来很简单的问题:
"为什么这个商品昨天还能卖,今天活动页就没了?"
这类问题背后,可能同时牵涉:
- 商品主状态有没有变化;
- 类目审核是否卡住;
- 活动配置是否过期;
- 库存池是否切换;
- 是否命中了某条风控规则;
- 某个异步任务是否延迟执行;
- 缓存是否还没刷新。
也就是说,真正有用的答案,不是生成一段解释,而是要能把问题拆开、去多个系统里拿信息、再按业务逻辑把这些结果串起来。
这时候我才意识到,我一开始有点把这件事想简单了。 OpenClaw 能理解"人在问什么",这当然重要;但如果它不理解后台系统是怎么运转的,那它再会说,也只是个说得比较像样的外行。

三、第二个坑:后台场景里,"半对半错"比直接不会更危险
做 AI 应用的时候,很多人最先关注的是准确率。 但在这次实践里,我越来越觉得,后台场景最危险的情况,往往不是"完全不会",而是"看起来懂了,但只懂了一半"。
举几个很典型的例子。
它可能知道如何查库存,但不知道活动库存和实际可售库存口径不同。 它可能能读懂订单状态,但没有意识到售后单已经锁住了后续流程。 它可能能总结出日志里的高频报错,但分不清哪些是历史噪音,哪些是这次变更真正引起的异常。
这类问题在演示阶段很难暴露,因为 Demo 往往只挑最顺的路径。 可一旦进了真实后台,只要上下文复杂一点、流程岔出去一点,这种"半对半错"的回答就会给人很强的误导感。
我后来很明确地把项目目标改了一下: 不再追求"龙虾什么都能答",而是追求它能在自己真正有把握的范围内,给出可靠、可追踪、可交还人工的辅助结果。
这听起来像在收缩能力,但实际上这是项目第一次真正朝可落地的方向靠近。
四、最让我头疼的,其实不是 Agent 逻辑,而是工程化问题开始成片出现
很多人聊 Agent,喜欢聊规划、记忆、反思、工具调用。 这些我也折腾过,但这次真正把我拖进泥里的,还是更底层的东西:环境、链路、资源和成本。
1. 环境一复杂,问题就不再是"模型问题"了
一旦 OpenClaw 开始接后台接口、日志系统、报表服务、权限模块,整个工程复杂度会一下子上来。
你会遇到非常多这种情况:
- 某条链路不是推理失败,而是底层服务超时了;
- 某个工具调用不是逻辑错,而是接口字段悄悄变了;
- 同样一套代码,在测试环境可以跑,在预发环境却会因为依赖版本不同而出问题;
- 你以为是 Prompt 没写好,后来发现是错误信息根本没被抛干净。
我前期为了图快,确实走过一些弯路。 比如先把链路堆起来,想着后面再慢慢梳理。结果就是系统一复杂,问题定位会变得特别痛苦。 很多时候你并不知道是 Agent 判断错了,还是工具没调通,还是某个中间层吞掉了异常。
这也让我第一次很强烈地意识到: AI 系统一旦接入真实业务,最忌讳的就是"所有问题都长得像模型问题"。
2. 成本问题,比我原来预估得来得更早
做之前我以为,这类后台 Agent 场景主要是推理和少量编排,应该不会太重。 后来才发现,只要你想把它做得稍微扎实一点,资源消耗会很快上来。
上述按月份算的还好,按量计算,有时挺烧钱的。
因为你不会只跑一次成功路径。 你还要:
- 跑多轮工具调用验证;
- 对比不同模型/策略效果;
- 回放历史问题做复盘;
- 做一些专项任务调优;
- 处理长上下文和中间状态缓存;
- 验证异常路径和人工兜底。
这些事情单看都不算夸张,但叠在一起之后,资源使用会迅速变得碎片化。 最典型的问题不是"卡不够",而是试错成本越来越高,资源空转越来越多。
那段时间我一个很强烈的感受是: 如果底层资源方式不够灵活,很多本来应该多做几轮的验证,你会因为成本和折腾程度,开始下意识放弃。
五、真正的转折,我开始认真处理"资源和接入成本"这件事
这个项目中途有一个阶段,我其实有点卡住。 不是方向错了,而是继续推进的摩擦越来越大。
一边是业务侧会不断提新场景,希望龙虾能处理更多后台问题; 另一边是工程侧越来越重,环境复用、资源申请、模型接入、链路验证都在消耗精力。
也是在这个阶段,我开始把一部分验证和资源使用迁到蓝耘上,主要用到的是 GPU 算力,后面也试了 MaaS 平台。
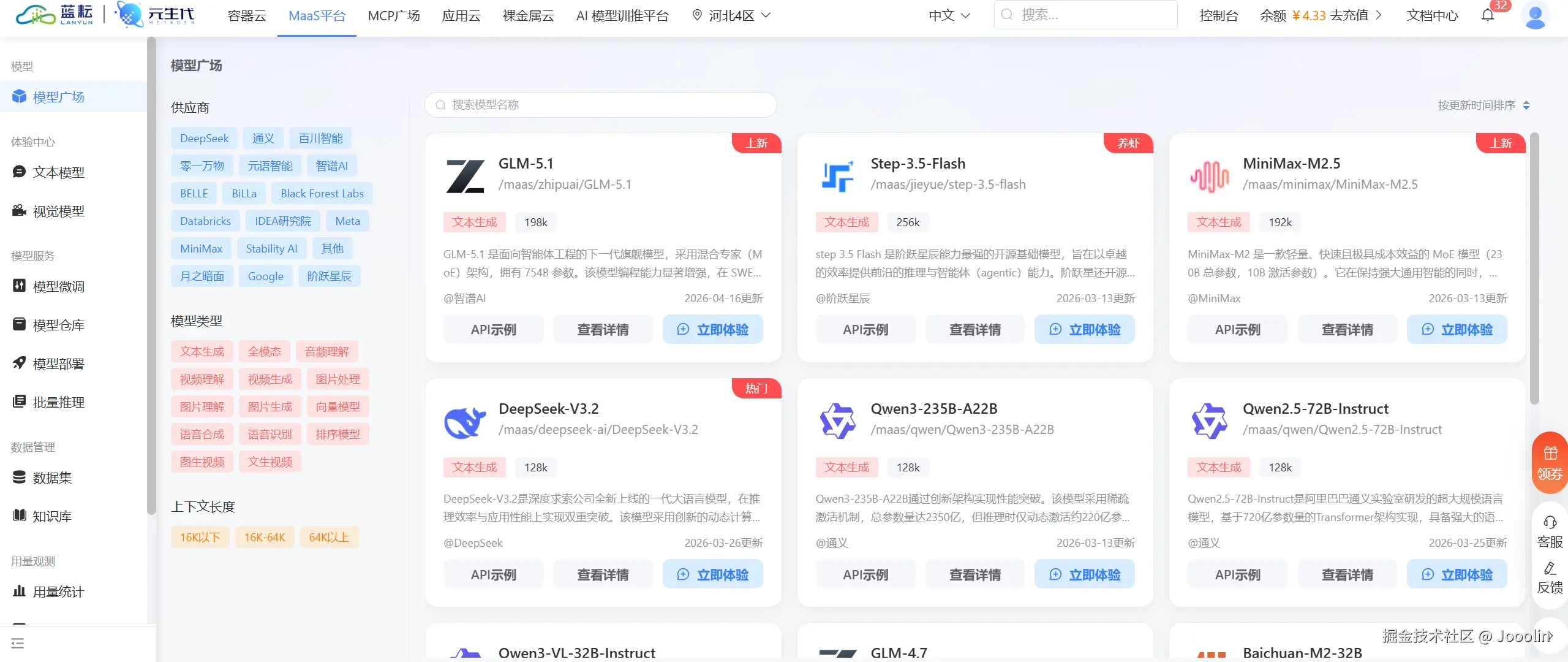
原来那些不值得反复折腾的环节,摩擦变小了。
1. 蓝耘 GPU 算力解决的,不是"有没有卡",而是"试错能不能更顺手"
这类项目有个很典型的特点: 不是持续满负载,而是会有很多阶段性的实验、验证、回放、压测。
比如我会反复做这些事情:
- 后台异常问题链路验证;
- 工具调用流程调整;
- 几套策略并行对比;
- 某个专项任务的小范围测试;
- 接入新能力后的回归检查。
这些任务有时候并不长,但很碎,很频繁。 以前如果用一种比较"固定资源"的方式去做,成本和心智负担都不低。你会不自觉地想:这轮要不要先不跑了?这个版本要不要先不试了?
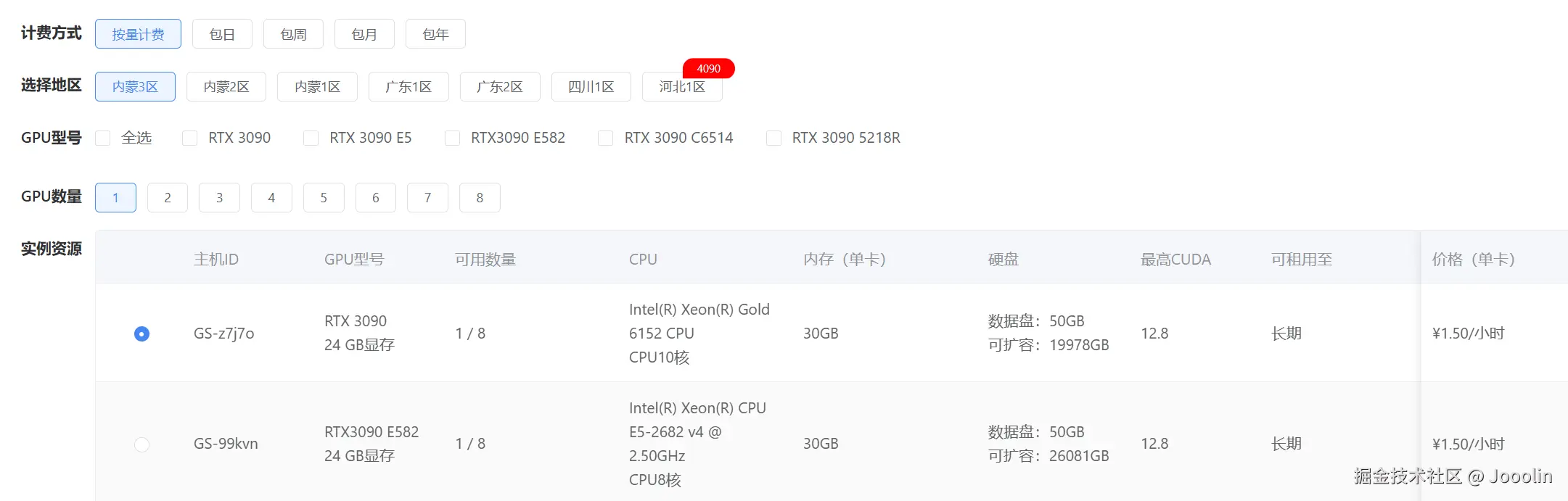
后来把一部分资源调度放到蓝耘的 GPU 算力 上后,我最直观的感受不是"算得更快了多少",而是试起来更轻了。 尤其在这种需要临时拉起、验证一轮、跑完就停的场景里,资源弹性和回收效率确实比较适合这种工作流。
比较实在的一点是,按秒计费 这件事对我不是概念,而是有感知的。 因为这类项目里,真正浪费钱的常常不是高峰负载,而是大量细碎实验中的空转时间。后来我自己粗看了一轮,类似验证周期下,整体资源成本大概比之前省了 30% 左右。这个数字不是要强调多夸张,而是它足够让我继续放心地做迭代,而不是被每一轮试错成本压着走。
2. MaaS 平台帮我少花了一部分"接模型的精力"
另一个变化,是我把一部分模型接入和验证工作放到了蓝耘的 MaaS 平台 上。
这部分的价值,我觉得很适合用"省精力"来描述。 因为在项目推进中,真正很容易把人拖住的,不一定是业务逻辑,而是你为了验证某个场景,要反复处理模型接入、接口切换、能力对比、封装适配这些事情。
有了 MaaS 之后,至少在方案验证阶段,我不需要每次都把大量精力投入到重复接线和底层切换上。 这样我的注意力就能更多放回真正重要的部分:
- 电商后台问题怎么拆;
- 哪些场景适合让龙虾先接;
- 哪些场景必须保留人工兜底;
- 工具调用链路应该怎样设计得更稳。
说到底,它没有替我完成业务设计,但它把那层"为了接模型而反复折腾"的摩擦降下来了一些。 对一个还在不断试边界的项目来说,这种帮助其实比"功能多一个、少一个"更重要。
它还有代金券可以薅!
六、这次实践最让我改变的一点,是我不再迷信"更聪明",而开始追求"更可靠"
做到后面,我对这个后台智能体的期待发生了明显变化。
一开始我希望"龙虾"尽可能像个很懂业务的人,能接住各种后台问题。 后来我越来越觉得,在后台场景里,一个真正有价值的 Agent,不一定要无所不能,但必须满足几件事:
- 知道自己什么时候能答;
- 知道自己什么时候该停;
- 知道什么时候必须把问题交还人工;
- 全程留痕,方便回放和复盘;
- 输出结果要尽量有依据,而不是只像那么回事。
这其实也让我重新理解了"智能"两个字。 在业务后台里,真正重要的很多时候不是创造性,而是守边界、讲规则、少出错。
从这个角度看,我后来做的很多优化都不算"酷":
- 明确区分哪些任务只能辅助、不能执行;
- 给高风险动作加更严格的拦截和确认;
- 把失败链路的日志打细;
- 增加人工兜底出口;
- 把多系统查询拆得更清楚,避免一步到位的"黑盒回答"。
这些工作拿去做展示并不好看,但它们恰恰决定了这套东西能不能真正进后台,而不只是停留在演示层面。
七、回头看,这更像一次技术方向上的校准
这次做 OpenClaw 接电商后台,对我个人其实也有一点影响。
以前我很容易把注意力放在"模型能力有没有提升""功能看起来够不够惊艳"这些地方。 但这次做下来,我越来越确认自己真正感兴趣的,不只是模型本身,而是怎么把模型变成一个可以长期工作的系统组件。
这个差别挺大的。
前者更像是在追一个会发光的点, 后者是在搭一套能承受真实业务摩擦的东西。
而当你开始从这个角度看问题时,你会发现算力、环境、模型服务、日志、兜底、权限、成本,全部都会重新变得重要。 它们不再是配角,而是决定项目最终形态的基础条件。
因为它不是替代我的方案思考,而是在比较关键的阶段,帮我把资源弹性和模型接入这两个高摩擦点压下去了一些。 对我来说,这已经是很实在的价值了。
八、写在最后:AI 进入真实业务,拼的不是"能不能做",而是"能不能长期做下去"
AI 落地的门槛,从来不只在模型能力上。
真正难的部分是:
- 它能不能融进现有业务;
- 能不能理解多系统状态;
- 能不能控制不确定性;
- 能不能在出错时及时止损;
- 能不能在资源和成本上跑得下去。
这也是为什么我后来会越来越重视像蓝耘 GPU 算力、MaaS 平台 这种看起来偏底层的能力。 因为做过之后你会发现,很多项目不是死在方向不对,而是死在推进过程中摩擦太大,最后没法持续迭代。
如果一定要给这段经历下一个结论,我会写:
把 AI 真正接进业务后台之后,我最深的体会不是"它有多聪明",而是"只有当资源、链路、边界和成本都被认真处理过,智能体才有资格谈落地"。
而好的算力平台在这件事里,至少对我来说,起到的就是这样一个作用: 它没有替代项目本身的复杂度,但它让我更有可能把这件事继续做下去。