Redis分布式缓存三大核心架构:主从、哨兵、分片,落地实战与选型
作者 :Weisian
发布时间:2026年4月

直击痛点:
"Redis用了好几年,主从、哨兵、分片傻傻分不清?面试官问'你们生产环境用的什么架构',你只能说'用了Redis集群',却说不清主从怎么配、哨兵怎么搭、分片怎么扩------架构选错,半夜OnCall。"
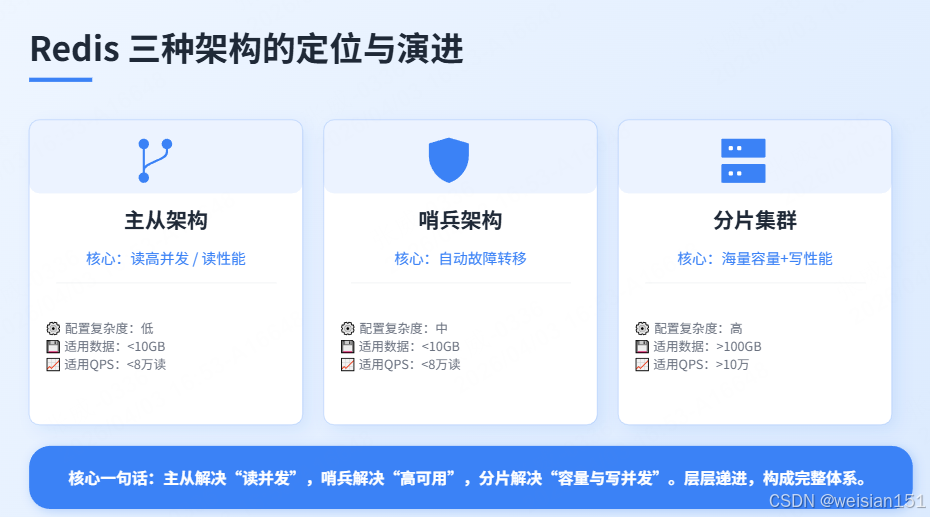
Redis作为分布式缓存的事实标准,其核心架构围绕三个目标展开:高可用、大容量、高并发。但很多开发者对这三种架构的认知是混乱的:
- 主从架构:一主多从,读写分离,解决"读高并发",但主节点宕机需要人工介入;
- 哨兵架构:在主从基础上增加自动故障转移,解决"高可用",但存储容量仍是单机瓶颈;
- 分片集群:数据分片存储,解决"大容量",同时内置高可用,是大型系统的终极形态;
- 面试高频问:"哨兵主观下线和客观下线的区别?""Redis Cluster的Hash Slot为什么是16384?""主从、哨兵、分片如何组合使用?"------答不上来=错失P7 offer。
本文将从Redis落地实践 的视角,结合底层原理 、代码实战 、避坑指南,彻底讲透Redis的三大核心架构:
✅ 架构一:主从架构------读写分离,夯实基础;
✅ 架构二:哨兵架构------自动故障转移,实现高可用;
✅ 架构三:分片集群------数据分片,突破容量瓶颈;
✅ 组合落地:主从+哨兵+分片的工业级部署方案;
✅ 避坑指南:复制风暴、脑裂、槽位迁移;
✅ 高频面试题标准答案(直接背);
✅ 生产环境选型决策树。
📌 核心一句话 :
主从架构解决"读高并发",哨兵架构解决"高可用",分片集群解决"大容量+高并发"。三者层层递进,从基础到完备,构成了Redis分布式缓存的完整落地体系。
📌 面试金句先记牢:
- 主从架构:一主多从,主写从读,异步复制,解决读压力,但主节点宕机需人工干预;
- 哨兵架构:在主从基础上增加哨兵节点,监控主从健康状态,实现自动故障转移,解决高可用;
- 分片集群:数据分片存储,每个分片内又有主从,内置故障转移,解决容量和写并发瓶颈;
- 主观下线 :单个哨兵判断主节点不可达;客观下线:多数哨兵(quorum)确认主节点不可达,触发故障转移;
- Raft选举:哨兵集群通过Raft算法选举Leader,由Leader执行故障转移;
- Hash Slot:Redis Cluster将key空间划分为16384个槽位,每个key通过CRC16(key)%16384计算归属;
- 生产环境终极架构:分片集群(主从+自动故障转移) = Redis Cluster,一站式解决高可用+大容量+高并发。
一、开篇:Redis三种架构的定位
Redis的架构演进,本质上是解决不同量级的问题:
| 架构 | 核心解决 | 配置复杂度 | 适用数据量 | 适用QPS |
|---|---|---|---|---|
| 主从架构 | 读高可用、读性能 | 低 | <10GB | <8万读 |
| 哨兵架构 | 自动故障转移 | 中 | <10GB | <8万读 |
| 分片集群 | 容量+写性能 | 高 | >100GB | >10万 |
生活类比:
-
主从架构:图书馆主馆+分馆,主馆管入库,分馆管借阅。主馆着火,分馆可借阅但不能入库新书。
-
哨兵架构:图书馆+自动监控系统,主馆着火自动切换到分馆当主馆,服务不中断。
-
分片集群:按图书类别分馆,文学馆、科技馆、历史馆,每个馆又有主从+自动监控。
┌─────────────────────────────────────────────────────────────────┐
│ Redis三种架构的演进关系 │
├─────────────────────────────────────────────────────────────────┤
│ │
│ 单机Redis ──→ 主从架构 ──→ 哨兵架构 ──→ 分片集群 │
│ │ │ │ │ │
│ ▼ ▼ ▼ ▼ │
│ 基础读写 读扩展 高可用 容量+写扩展 │
│ 有单点故障 主需人工介入 自动故障转移 终极方案 │
│ │
└─────────────────────────────────────────────────────────────────┘
二、架构一:Redis主从架构------读写分离的基础
2.1 核心痛点:为什么需要主从?
单机Redis:所有读写请求都打在一个节点,读多场景下CPU/内存直接打满,且一旦宕机数据全部丢失。
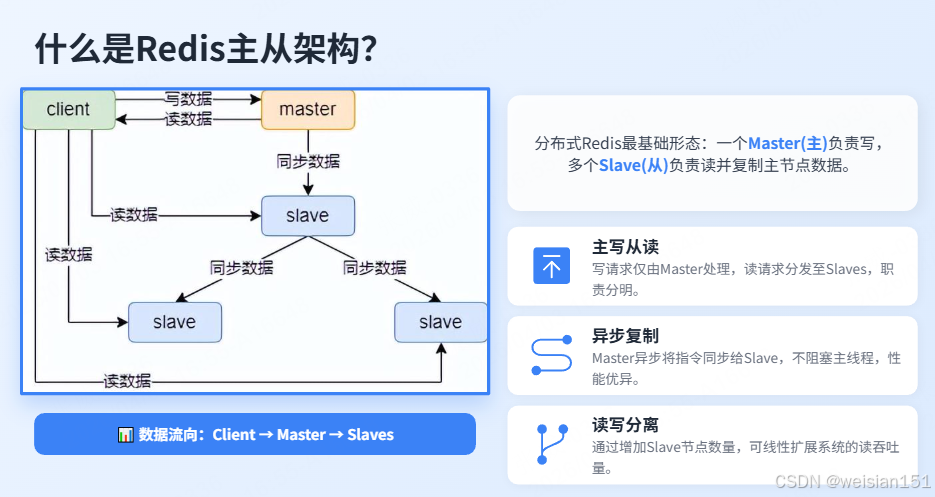
2.2 什么是主从架构?
主从架构是最基础的分布式Redis形态:一个主节点(Master)负责写操作,多个从节点(Slave/Replica)复制主节点数据,负责读操作。
生活类比:图书馆主馆负责新书入库(写操作),多个分馆同步主馆藏书,读者只在分馆借书(读操作)。主馆着火,分馆不能入库新书,但还能借书。
2.3 主从复制原理
Redis主从复制采用异步复制,核心流程如下:
┌─────────────────────────────────────────────────────────────────┐
│ 主从复制完整流程 │
├─────────────────────────────────────────────────────────────────┤
│ │
│ 从节点 主节点 │
│ │ │ │
│ │──── 1. SLAVEOF 命令 ────────────→│ │
│ │ │ │
│ │←─── 2. +OK 响应 ─────────────────│ │
│ │ │ │
│ │──── 3. PSYNC {runid} {offset} ──→│ │
│ │ │ │
│ │ 判断复制类型 │ │
│ │ ├─ 首次连接 → 全量复制 │ │
│ │ └─ 断线重连 → 增量复制 │ │
│ │ │ │
│ │←─── 4. +FULLRESYNC (全量复制) ───│ │
│ │←─── 5. RDB文件传输 ──────────────│ │
│ │ │ │
│ │ 加载RDB,清空自身数据 │ │
│ │ │ │
│ │←─── 6. 积压缓冲区命令 (增量复制) ─│ │
│ │ │ │
│ │ 执行命令,追平数据 │ │
│ │ │ │
└─────────────────────────────────────────────────────────────────┘核心原理:主从复制机制
- 全量复制:从节点第一次连接主节点,主节点生成RDB文件发送给从节点,从节点加载完成数据初始化;
- 增量复制 :后续主节点写入的数据,以
repl_backlog缓冲区形式同步给从节点; - 读写分离:业务代码中,写请求走主节点,读请求走从节点,分摊压力。
两种复制模式对比:
| 模式 | 触发条件 | 传输内容 | 数据量 | 耗时 |
|---|---|---|---|---|
| 全量复制 | 首次连接、offset落后太多 | RDB文件 + 积压缓冲区命令 | 大 | 秒~分钟级 |
| 增量复制 | 网络短暂断开后重连 | 积压缓冲区命令 | 小 | 毫秒级 |

2.4 实战配置:一主二从搭建
环境准备
3台Redis节点(端口:6379主,6380从,6381从)

主节点(6379)配置 redis-6379.conf
ini
bind 0.0.0.0
port 6379
daemonize yes
logfile "6379.log"
dbfilename "dump-6379.rdb"从节点(6380)配置 redis-6380.conf
ini
bind 0.0.0.0
port 6380
daemonize yes
logfile "6380.log"
dbfilename "dump-6380.rdb"
# 声明主节点地址
replicaof 127.0.0.1 6379
# 从节点只读(默认开启)
replica-read-only yes从节点(6381)配置 redis-6381.conf
ini
bind 0.0.0.0
port 6381
daemonize yes
logfile "6381.log"
dbfilename "dump-6381.rdb"
replicaof 127.0.0.1 6379
replica-read-only yes启动&验证
bash
redis-server redis-6379.conf
redis-server redis-6380.conf
redis-server redis-6381.conf
# 连接主节点查看主从状态
redis-cli -p 6379 info replication验证结果 :主节点显示2个从节点在线,主从复制状态为up。
Java代码实现读写分离
java
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import java.util.Arrays;
import java.util.List;
import java.util.concurrent.atomic.AtomicInteger;
/**
* Redis主从读写分离实现
* 写请求 → 主节点(6379)
* 读请求 → 轮询从节点(6380/6381)
*/
public class RedisMasterSlave {
// 主节点连接池
private static final JedisPool MASTER_POOL = new JedisPool("127.0.0.1", 6379);
// 从节点列表
private static final List<JedisPool> SLAVE_POOLS = Arrays.asList(
new JedisPool("127.0.0.1", 6380),
new JedisPool("127.0.0.1", 6381)
);
// 轮询计数器
private static final AtomicInteger INDEX = new AtomicInteger(0);
/**
* 写数据:主节点
*/
public static void set(String key, String value) {
try (Jedis jedis = MASTER_POOL.getResource()) {
jedis.set(key, value);
System.out.println("主节点写入成功:" + key);
}
}
/**
* 读数据:轮询从节点
*/
public static String get(String key) {
// 轮询算法选择从节点
int current = INDEX.getAndIncrement() % SLAVE_POOLS.size();
JedisPool pool = SLAVE_POOLS.get(current);
try (Jedis jedis = pool.getResource()) {
String value = jedis.get(key);
System.out.println("从节点" + jedis.getClient().getPort() + "读取成功:" + key);
return value;
}
}
public static void main(String[] args) {
set("user:1", "张三");
System.out.println(get("user:1"));
System.out.println(get("user:1"));
}
}2.5 主从架构的优缺点
| 维度 | 评价 | 说明 |
|---|---|---|
| 读性能 | ⭐⭐⭐⭐⭐ | 多从节点分担读压力,线性扩展 |
| 写性能 | ⭐⭐ | 仍是单节点瓶颈 |
| 高可用 | ⭐⭐ | 主节点宕机需人工切换 |
| 数据安全 | ⭐⭐⭐⭐ | 多副本冗余 |
| 容量 | ⭐⭐ | 每节点存全量数据,受单机内存限制 |
| 一致性 | ⭐⭐⭐ | 异步复制,存在延迟 |

2.6 适用场景
- 读多写少(读写比 > 10:1)
- 数据量较小(<10GB)
- 可接受主从延迟(毫秒~秒级)
- 可接受人工故障转移
三、架构二:哨兵架构------自动化故障转移,高可用保障
3.1 为什么需要哨兵?
主从架构最大的痛点是:主节点宕机后,需要人工介入将从节点提升为主节点。哨兵(Sentinel)解决了这个问题------它是一个独立的进程,监控主从节点,实现自动故障转移。
生活类比:高速公路抢修队,平时巡逻监控(监控),发现事故(主节点下线),快速抢修(选新主),恢复通车(故障转移)。
3.2 哨兵核心原理
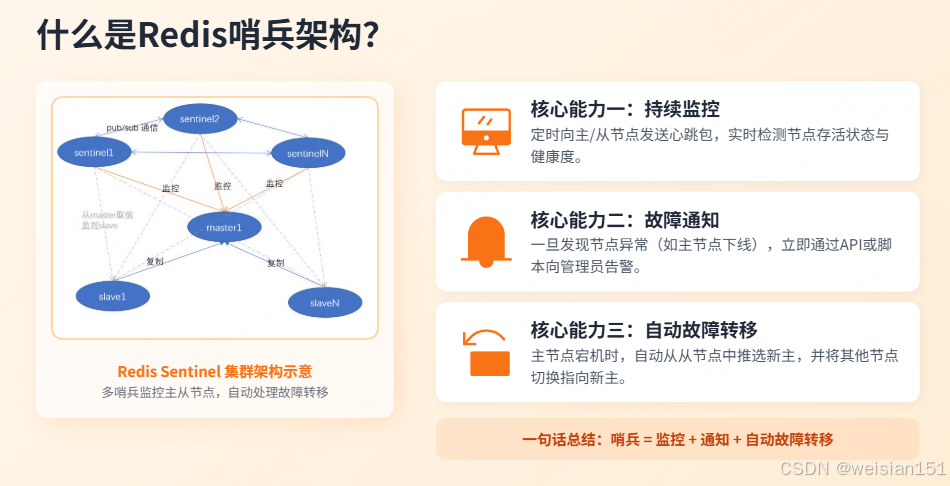
3.2.1 哨兵集群架构
┌─────────────────────────────────────────────────────────────────┐
│ 哨兵集群架构 │
├─────────────────────────────────────────────────────────────────┤
│ │
│ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐ │
│ │ 哨兵节点1 │ │ 哨兵节点2 │ │ 哨兵节点3 │ │
│ │ (监控) │ │ (监控) │ │ (监控) │ │
│ └──────┬──────┘ └──────┬──────┘ └──────┬──────┘ │
│ │ │ │ │
│ └────────────────┼────────────────┘ │
│ │ │
│ ┌──────▼──────┐ │
│ │ 主节点 │ │
│ │ 6379 │ │
│ └──────┬──────┘ │
│ │ 异步复制 │
│ ┌────────────────┼────────────────┐ │
│ │ │ │ │
│ ┌────▼────┐ ┌────▼────┐ ┌────▼────┐ │
│ │ 从节点1 │ │ 从节点2 │ │ 从节点3 │ │
│ │ 6380 │ │ 6381 │ │ 6382 │ │
│ └─────────┘ └─────────┘ └─────────┘ │
│ │
└─────────────────────────────────────────────────────────────────┘核心原理:哨兵三大核心能力
- 监控:定时发送心跳,检测主从节点状态;
- 通知:节点故障时,发送通知给管理员/业务系统;
- 自动故障转移:主节点下线,自动从从节点中选新主,其余节点指向新主。
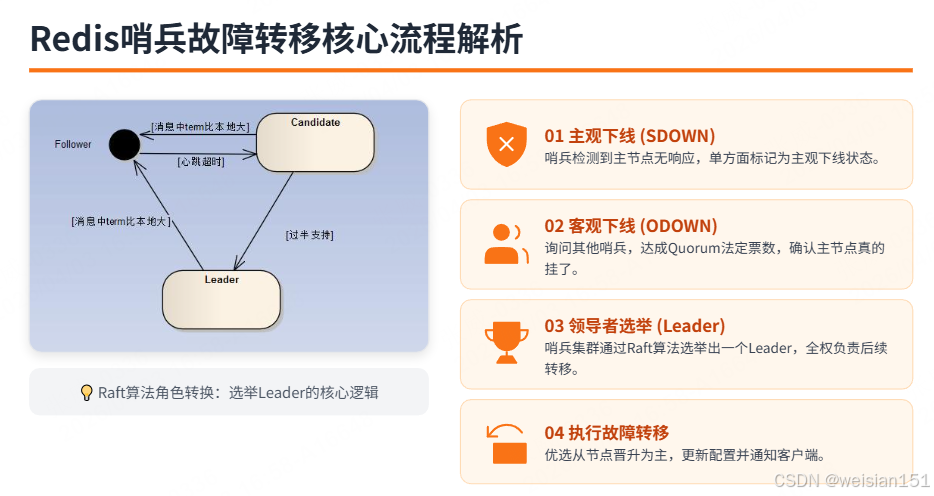
3.2.2 主观下线 vs 客观下线
| 状态 | 含义 | 触发条件 | 后果 |
|---|---|---|---|
| 主观下线(SDOWN) | 单个哨兵认为主节点不可达 | 哨兵向主节点发送PING,在down-after-milliseconds内无响应 | 仅该哨兵标记,不触发故障转移 |
| 客观下线(ODOWN) | 多数哨兵认为主节点不可达 | 至少quorum个哨兵同意主观下线 | 触发故障转移 |

3.2.3 故障转移流程
┌─────────────────────────────────────────────────────────────────┐
│ 哨兵故障转移流程 │
├─────────────────────────────────────────────────────────────────┤
│ │
│ 1. 主观下线 │
│ └─ 哨兵A检测到主节点无响应 → 标记SDOWN │
│ │
│ 2. 客观下线 │
│ └─ 哨兵A询问其他哨兵 → 达到quorum → 标记ODOWN │
│ │
│ 3. 领导者选举 │
│ └─ 哨兵集群通过Raft算法选举Leader │
│ │
│ 4. 故障转移 │
│ ├─ 从所有从节点中选最优从节点 │
│ │ ├─ 优先级最高(replica-priority) │
│ │ ├─ 复制偏移量最大(数据最新) │
│ │ └─ 运行ID最小(兜底) │
│ ├─ 执行 SLAVEOF NO ONE 提升为主 │
│ ├─ 修改其他从节点指向新主 │
│ └─ 通知客户端更新配置 │
│ │
└─────────────────────────────────────────────────────────────────┘
3.3 实战配置:3节点哨兵集群

哨兵配置 sentinel-26379.conf
ini
bind 0.0.0.0
port 26379
daemonize yes
logfile "26379.log"
# 监控主节点:mymaster是集群名,2表示客观下线票数
sentinel monitor mymaster 127.0.0.1 6379 2
# 心跳检测时间(毫秒)
sentinel down-after-milliseconds mymaster 3000
# 故障转移超时时间
sentinel failover-timeout mymaster 18000另外两个哨兵配置(端口26380、26381),仅修改端口即可。
启动哨兵
bash
redis-sentinel sentinel-26379.conf
redis-sentinel sentinel-26380.conf
redis-sentinel sentinel-26381.conf故障模拟验证
- 杀死主节点:
redis-cli -p 6379 shutdown; - 哨兵日志:检测主节点主观下线→客观下线→选举领导者→提升从节点为新主;
- 查看新主节点:
redis-cli -p 26379 sentinel get-master-addr-by-name mymaster。
Java代码使用哨兵
java
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisSentinelPool;
import redis.clients.jedis.JedisPoolConfig;
import java.util.HashSet;
import java.util.Set;
/**
* Redis哨兵架构客户端实现
* 类比:高速公路抢修队 - 自动故障转移,客户端无感知
*/
public class SentinelDemo {
private static JedisSentinelPool sentinelPool;
static {
// 哨兵节点列表
Set<String> sentinels = new HashSet<>();
sentinels.add("127.0.0.1:26379");
sentinels.add("127.0.0.1:26380");
sentinels.add("127.0.0.1:26381");
// 连接池配置
JedisPoolConfig poolConfig = new JedisPoolConfig();
poolConfig.setMaxTotal(100);
poolConfig.setMaxIdle(20);
// 创建哨兵连接池(自动处理主从切换)
// 参数:master名称、哨兵集合、连接池配置、连接超时
sentinelPool = new JedisSentinelPool(
"mymaster", // 主节点名称(与sentinel.conf一致)
sentinels, // 哨兵节点列表
poolConfig, // 连接池配置
2000 // 连接超时(ms)
);
}
/**
* 获取当前主节点连接
*/
public static Jedis getMaster() {
return sentinelPool.getResource();
}
/**
* 写入数据
*/
public static void write(String key, String value) {
try (Jedis jedis = getMaster()) {
jedis.set(key, value);
System.out.println("[写操作] " + key + " = " + value);
}
}
/**
* 读取数据(哨兵模式下读写都走主节点)
* 如需读写分离,需自行实现从节点获取逻辑
*/
public static String read(String key) {
try (Jedis jedis = getMaster()) {
String value = jedis.get(key);
System.out.println("[读操作] " + key + " = " + value);
return value;
}
}
public static void main(String[] args) throws InterruptedException {
System.out.println("=== Redis哨兵架构演示 ===\n");
// 1. 查看当前主节点
String currentMaster = sentinelPool.getCurrentHostMaster().toString();
System.out.println("当前主节点: " + currentMaster);
// 2. 写入数据
write("user:1001", "张三");
write("user:1002", "李四");
// 3. 读取数据
read("user:1001");
// 4. 模拟主节点故障(手动停止主节点)
System.out.println("\n=== 模拟主节点故障 ===");
System.out.println("请手动停止主节点Redis,哨兵将自动进行故障转移");
System.out.println("故障转移后,客户端会自动切换到新主节点\n");
// 等待故障转移
for (int i = 0; i < 30; i++) {
Thread.sleep(1000);
try {
String master = sentinelPool.getCurrentHostMaster().toString();
if (!master.equals(currentMaster)) {
System.out.println("主节点已切换: " + master);
break;
}
} catch (Exception e) {
System.out.println("等待故障转移...");
}
}
// 5. 故障转移后继续写入
write("user:1003", "王五");
read("user:1001");
read("user:1003");
sentinelPool.close();
}
}3.4 哨兵架构的优缺点
| 维度 | 评价 | 说明 |
|---|---|---|
| 高可用 | ⭐⭐⭐⭐⭐ | 自动故障转移,无需人工干预 |
| 读性能 | ⭐⭐⭐⭐ | 可配置读写分离,但客户端需额外实现 |
| 写性能 | ⭐⭐ | 仍是单节点瓶颈 |
| 容量 | ⭐⭐ | 每节点存全量数据 |
| 运维复杂度 | ⭐⭐⭐ | 需额外部署哨兵节点 |
| 一致性 | ⭐⭐⭐ | 异步复制+故障转移可能丢数据 |
3.5 哨兵数量为什么是奇数?
核心原因 :哨兵集群通过Raft算法选举Leader,需要多数派(> N/2) 同意。
- 3个哨兵:允许1个故障,2个正常即可选举
- 4个哨兵:允许1个故障,但3个正常才能选举(3 > 4/2)
- 4个哨兵比3个哨兵多一个节点,但容错能力相同(都是允许1个故障)
结论:奇数个哨兵可以在相同容错能力下节省资源。

3.6 适用场景
- 对高可用要求高(SLA > 99.9%)
- 数据量较小(<10GB)
- 可接受主从延迟
- 不想人工介入故障处理
四、架构三:分片集群------容量与并发的终极方案
4.1 为什么需要分片集群?
主从架构和哨兵架构都解决了高可用和读性能问题,但存储容量和写性能仍是单机瓶颈。当数据量超过单机内存(如100GB+),或写QPS超过单节点上限(如10万+),就需要分片集群。
生活类比:京东亚洲一号仓,全国多个仓库分片存储。上海仓存华东订单,北京仓存华北订单。单仓容量有限,多仓协同覆盖全国。
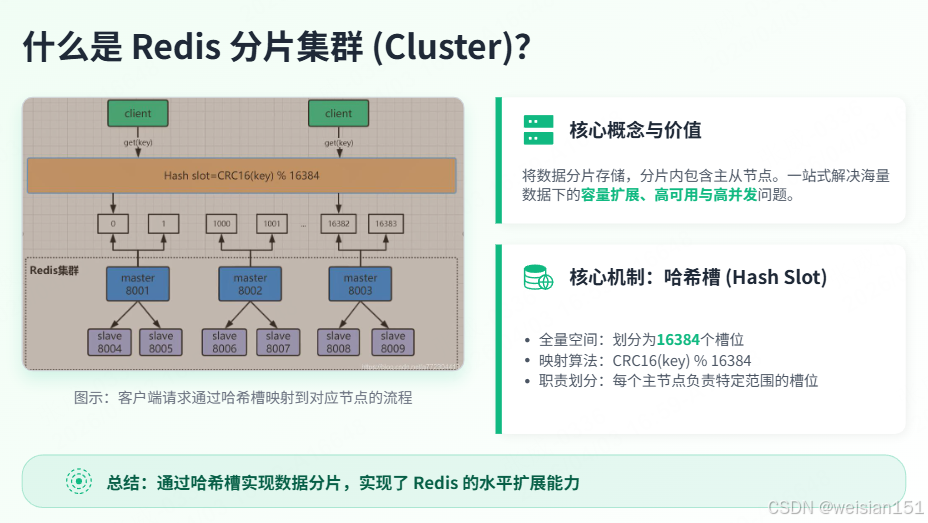
4.2 Redis Cluster核心原理
4.2.1 哈希槽(Hash Slot)
Redis Cluster将整个key空间划分为16384个哈希槽 ,每个key通过CRC16(key) % 16384计算归属槽位,每个主节点负责一部分槽位。
┌─────────────────────────────────────────────────────────────────┐
│ Redis Cluster 哈希槽分布 │
├─────────────────────────────────────────────────────────────────┤
│ │
│ 槽位: 0 ─────────────────────────────────────────────── 16383 │
│ │ │ │ │
│ ▼ ▼ ▼ │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │ 节点A │ │ 节点B │ │ 节点C │ │
│ │ 主+从 │ │ 主+从 │ │ 主+从 │ │
│ │ 槽0-5460 │ │槽5461-10922│ │槽10923-16383│ │
│ └──────────┘ └──────────┘ └──────────┘ │
│ │
│ 每个主节点都有从节点做高可用备份 │
│ 写入key时,根据槽位自动路由到对应节点 │
│ │
└─────────────────────────────────────────────────────────────────┘核心原理:哈希槽(Hash Slot)
- Redis Cluster默认有16384个哈希槽;
- 集群启动时,哈希槽均匀分配给所有主节点;
- 数据写入时,计算
key的CRC16值 % 16384,得到槽位,路由到对应节点; - 每个主节点搭配从节点,保证高可用。
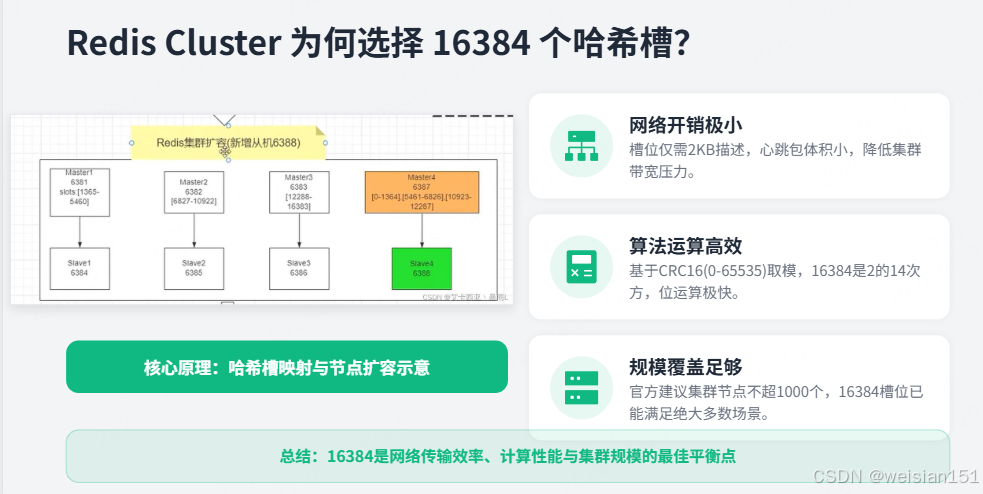
4.2.2 为什么是16384个槽?
| 原因 | 说明 |
|---|---|
| 网络开销 | 16384个槽位只需2KB(16384/8)就能描述,心跳包小 |
| CRC16特性 | CRC16算法产生0-65535,取16384(2^14)运算高效 |
| 集群规模 | Redis官方建议集群不超过1000个节点,16384足够 |
4.2.3 MOVED与ASK转向
| 转向类型 | 含义 | 触发场景 | 客户端行为 |
|---|---|---|---|
| MOVED | 槽位永久迁移 | 槽位已完全迁移到另一个节点 | 更新本地路由表,重试 |
| ASK | 槽位临时迁移 | 槽位正在迁移过程中 | 先发ASKING,再重试 |
4.3 实战配置:3主3从分片集群
环境准备
6台Redis节点(端口:7001/7002/7003主,7004/7005/7006从)
节点配置 redis-7001.conf
ini
bind 0.0.0.0
port 7001
daemonize yes
logfile "7001.log"
# 开启集群模式
cluster-enabled yes
# 集群配置文件
cluster-config-file nodes-7001.conf
cluster-node-timeout 5000其余5个节点配置仅修改端口即可。
创建集群
bash
redis-cli --cluster create 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005 127.0.0.1:7006 --cluster-replicas 1--cluster-replicas 1:1个主节点对应1个从节点;- 自动分配16384个哈希槽到3个主节点。
集群验证
bash
redis-cli -p 7001 cluster info # 查看集群状态
redis-cli -p 7001 cluster nodes # 查看节点列表Java代码使用Redis Cluster
java
import redis.clients.jedis.HostAndPort;
import redis.clients.jedis.JedisCluster;
import redis.clients.jedis.JedisPoolConfig;
import java.util.HashSet;
import java.util.Set;
/**
* Redis Cluster分片集群实战
* 类比:分布式仓库 - 数据自动分片,客户端智能路由
*/
public class RedisClusterDemo {
private static JedisCluster cluster;
static {
// 集群节点(只需提供部分种子节点)
Set<HostAndPort> nodes = new HashSet<>();
nodes.add(new HostAndPort("127.0.0.1", 7001));
nodes.add(new HostAndPort("127.0.0.1", 7002));
nodes.add(new HostAndPort("127.0.0.1", 7003));
// 连接池配置
JedisPoolConfig poolConfig = new JedisPoolConfig();
poolConfig.setMaxTotal(200);
poolConfig.setMaxIdle(50);
poolConfig.setMinIdle(10);
// 创建集群客户端(自动处理MOVED/ASK转向)
cluster = new JedisCluster(nodes, poolConfig);
}
/**
* 写入数据(自动路由)
*/
public static void write(String key, String value) {
cluster.set(key, value);
System.out.println("[写操作] " + key + " = " + value);
}
/**
* 读取数据
*/
public static String read(String key) {
String value = cluster.get(key);
System.out.println("[读操作] " + key + " = " + value);
return value;
}
/**
* 查看key所在的槽位
*/
public static void showSlot(String key) {
// JedisCluster没有直接提供slot查询,通过连接任一节点执行
// 此处简化演示
int slot = getCRC16(key) & 16383;
System.out.println("[槽位] " + key + " → 槽位 " + slot);
}
private static int getCRC16(String key) {
int crc = 0xFFFF;
for (char c : key.toCharArray()) {
crc ^= (c & 0xFF);
for (int j = 0; j < 8; j++) {
if ((crc & 0x0001) != 0) {
crc = (crc >> 1) ^ 0x8408;
} else {
crc = crc >> 1;
}
}
}
return crc;
}
public static void main(String[] args) {
System.out.println("=== Redis Cluster 分片集群演示 ===\n");
// 1. 写入数据(自动分布到不同节点)
System.out.println("1. 写入1000条数据...");
for (int i = 0; i < 1000; i++) {
write("user:" + i, "user_value_" + i);
write("order:" + i, "order_value_" + i);
}
// 2. 查看数据分布
System.out.println("\n2. 数据槽位分布:");
showSlot("user:100");
showSlot("user:500");
showSlot("user:900");
// 3. 读取验证
System.out.println("\n3. 读取验证:");
read("user:100");
read("user:500");
read("user:900");
// 4. Hash Tag示例(确保多key在同一槽位)
System.out.println("\n4. Hash Tag示例:");
cluster.set("user:{1001}", "张三");
cluster.set("order:{1001}", "订单数据");
// 两个key在同一个槽位,支持多key操作
System.out.println("\n=== 集群信息 ===");
System.out.println("节点数: 3主3从");
System.out.println("槽位数: 16384");
System.out.println("客户端自动处理MOVED/ASK转向");
cluster.close();
}
}4.4 集群扩容与数据迁移
bash
# 1. 添加新节点
redis-server /path/to/redis-cluster-7007.conf
redis-server /path/to/redis-cluster-7008.conf
# 2. 将新节点加入集群
redis-cli --cluster add-node 192.168.1.100:7007 192.168.1.101:7000
redis-cli --cluster add-node 192.168.1.100:7008 192.168.1.101:7000
# 3. 为新节点分配槽位(迁移数据)
redis-cli --cluster reshard 192.168.1.100:7001
# 4. 设置从节点
redis-cli -p 7008 cluster replicate <新主节点ID>4.5 分片集群的优缺点
| 维度 | 评价 | 说明 |
|---|---|---|
| 容量 | ⭐⭐⭐⭐⭐ | 水平扩展,突破单机内存限制 |
| 写性能 | ⭐⭐⭐⭐⭐ | 多主节点并行写入 |
| 读性能 | ⭐⭐⭐⭐⭐ | 多主节点并行读取 |
| 高可用 | ⭐⭐⭐⭐⭐ | 内置主从+自动故障转移 |
| 运维复杂度 | ⭐⭐⭐⭐ | 需要管理集群、槽位、迁移 |
| 一致性 | ⭐⭐⭐ | 异步复制,主从切换可能丢数据 |
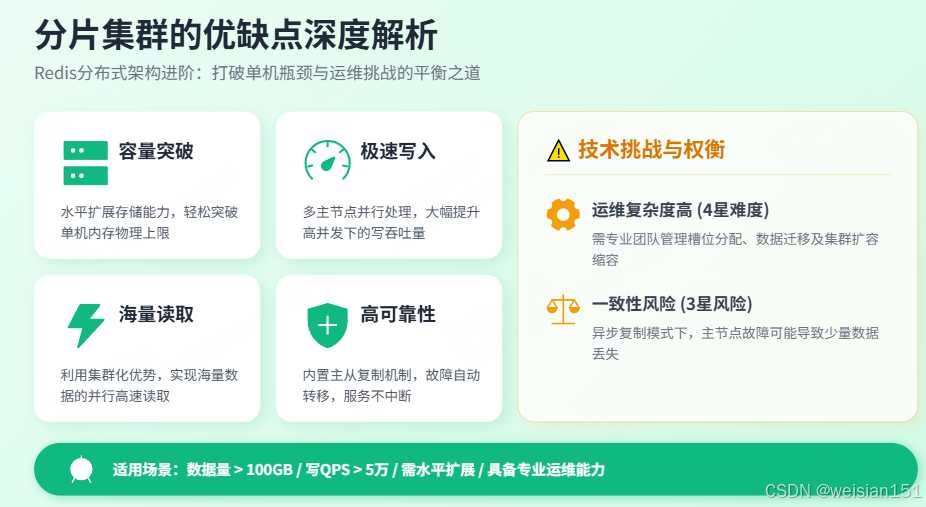
4.6 适用场景
- 数据量大(>100GB)
- 写QPS高(>5万)
- 需要水平扩展
- 有专业运维团队
五、组合落地:Redis终极架构
5.1 三者关系
┌─────────────────────────────────────────────────────────────────┐
│ Redis三种架构组合关系 │
├─────────────────────────────────────────────────────────────────┤
│ │
│ ┌─────────────────────────────────────────────────────────┐ │
│ │ Redis Cluster │ │
│ │ (分片集群 = 主从 + 哨兵) │ │
│ │ │ │
│ │ ┌─────────┐ ┌─────────┐ ┌─────────┐ │ │
│ │ │ 分片1 │ │ 分片2 │ │ 分片3 │ │ │
│ │ │ 主+从 │ │ 主+从 │ │ 主+从 │ │ │
│ │ │ 槽0-5460│ │5461-10922│ │10923-16383│ │ │
│ │ └─────────┘ └─────────┘ └─────────┘ │ │
│ │ │ │
│ │ 每个分片内部 = 主从架构(解决高可用) │ │
│ │ 分片之间 = 哈希槽路由(解决容量) │ │
│ │ 故障转移 = 内置哨兵机制(自动切换) │ │
│ └─────────────────────────────────────────────────────────┘ │
│ │
└─────────────────────────────────────────────────────────────────┘5.2 生产环境部署建议
| 数据量 | QPS | 推荐架构 | 说明 |
|---|---|---|---|
| <10GB | <5万 | 主从 + 哨兵 | 简单够用,运维成本低 |
| 10-50GB | 5-10万 | Redis Cluster(3主3从) | 初步分片 |
| 50-200GB | 10-20万 | Redis Cluster(5主5从) | 中等规模 |
| >200GB | >20万 | Redis Cluster(9主9从+) | 大规模 |

5.3 三种架构对比总结
| 维度 | 主从架构 | 哨兵架构 | 分片集群 |
|---|---|---|---|
| 核心解决 | 读扩展 | 高可用 | 容量+写扩展 |
| 自动故障转移 | ❌ | ✅ | ✅ |
| 读性能扩展 | ✅(从节点) | ✅(需额外配置) | ✅(多主) |
| 写性能扩展 | ❌ | ❌ | ✅ |
| 容量扩展 | ❌ | ❌ | ✅ |
| 运维复杂度 | 低 | 中 | 高 |
| 推荐场景 | 读多写少 | 高可用要求高 | 海量数据 |
六、避坑指南
6.1 复制风暴
问题:主节点挂掉重启后,多个从节点同时发起全量复制,导致主节点CPU/网络飙升。
解决:
- 使用树状复制:从节点挂载到从节点
- 设置合理的复制积压缓冲区大小
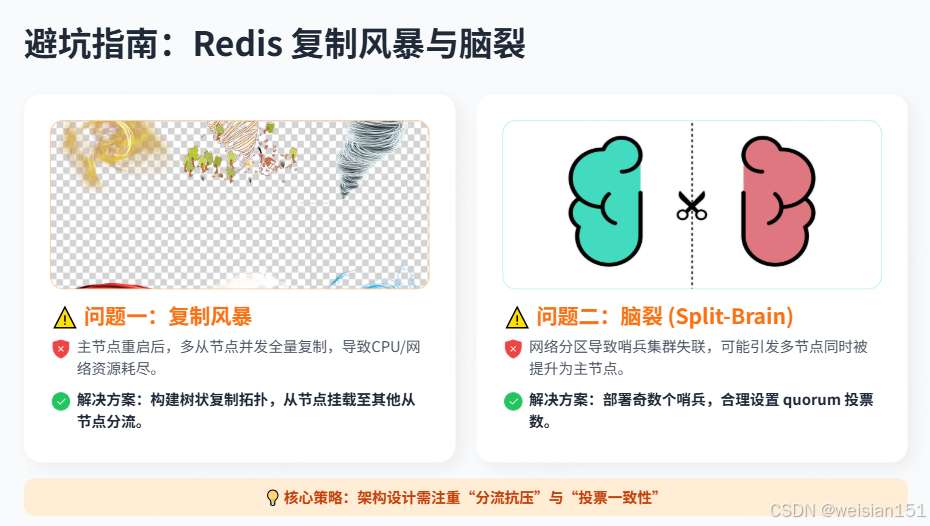
6.2 哨兵脑裂
问题:网络分区导致多个哨兵各自为政,可能同时提升多个从节点为主。
解决:
- 配置奇数个哨兵(3/5/7)
- 设置合理的quorum(如N/2+1)
6.3 集群扩容数据迁移
问题:扩容时槽位迁移会影响部分key的读写性能。
解决:
- 业务低峰期执行扩容
- 分批次迁移,监控迁移进度
6.4 主从延迟导致数据丢失
问题:主节点宕机时,尚未同步到从节点的数据会丢失。
解决:
- 配置
min-slaves-to-write和min-slaves-max-lag - 使用Redis Cluster,但仍有小概率丢失
七、高可用保障体系:缓存防护+多级缓存
7.1 哨兵模式:自动化故障转移(核心总结)
| 板块 | 内容 |
|---|---|
| 痛点 | 主从架构主节点宕机,服务无法写入 |
| 方案 | Redis Sentinel(3节点奇数起步) |
| 核心 | 主观下线(单哨兵判断)、客观下线(多数哨兵共识)、Raft选举、自动选主切换 |
| 代码 | 哨兵配置文件+故障模拟验证 |
| 局限 | 无法解决容量瓶颈,仅保证高可用 |
| 面试 | 哨兵数量必须奇数?避免脑裂;选举用Raft算法 |
7.2 多级缓存:最后一公里兜底
架构:L1本地缓存(Caffeine)+ L2分布式缓存(Redis)+ DB
- 读请求:先查本地缓存→再查Redis→最后查DB;
- 写请求:写DB→通过Canal订阅binlog→更新Redis→淘汰本地缓存;
- 优势:降低网络延迟,Redis故障时本地缓存兜底。
7.3 缓存防护:三大杀手终极解法
| 问题 | 解决方案 | 核心原理 |
|---|---|---|
| 缓存穿透 | 布隆过滤器 | 过滤不存在的key,避免直接查DB |
| 缓存雪崩 | 随机TTL+集群+熔断 | 避免key同时过期,集群分摊压力 |
| 缓存击穿 | 互斥锁+热点永不过期 | 防止并发请求击穿到DB |

八、面试高频真题(标准答案直接背)

Q1:主从架构、哨兵架构、分片集群的区别?
答案:
- 主从架构:一主多从,读写分离,解决读压力。主节点宕机需人工介入。
- 哨兵架构:在主从基础上增加哨兵节点,自动故障转移,解决高可用。
- 分片集群:数据分片存储,多主多从,内置故障转移,同时解决容量和写压力。
Q2:哨兵主观下线和客观下线的区别?
| 维度 | 主观下线(SDOWN) | 客观下线(ODOWN) |
|---|---|---|
| 判定者 | 单个哨兵 | 多数哨兵(quorum) |
| 触发条件 | PING无响应超过down-after-milliseconds | 至少quorum个哨兵同意SDOWN |
| 后果 | 仅标记,不触发故障转移 | 触发故障转移 |
Q3:为什么哨兵集群需要奇数个节点?
答案:哨兵通过Raft算法选举Leader,需要多数派(> N/2)同意。奇数个节点(如3、5)与比它多1的偶数节点(如4、6)容错能力相同,但节省资源。
Q4:Redis Cluster为什么是16384个哈希槽?
答案:
- 网络开销:16384个槽位只需2KB(16384/8)描述,心跳包小
- CRC16特性:CRC16算法产生0-65535,取16384(2^14)运算高效
- 集群规模:Redis官方建议集群不超过1000个节点,16384足够
Q5:生产环境如何选择Redis架构?
答案:
- 数据量<10GB,读多写少 → 主从+哨兵
- 数据量>100GB,写QPS高 → Redis Cluster
- 对可用性要求极高 → 无论哪种架构都建议加哨兵或直接用Cluster
总结
1. 核心知识点速记口诀
主从架构一拖N,主写从读压力分,
异步复制有延迟,主节点挂需人帮。
哨兵架构加监控,主观客观两下线,
奇数节点来选举,故障转移自动完。
分片集群哈希槽,16384槽均匀放,
每片内部主从备,容量并发一起扛。
三种架构层层进,选型要看数据量,
小用主从大用片,高可用上哨兵强。2. 核心要点回顾
- 主从架构:读写分离,解决读压力,主需人工切换
- 哨兵架构:自动故障转移,解决高可用
- 分片集群:数据分片,解决容量和写压力
- 组合逻辑:分片集群内部已包含主从+哨兵,是终极方案
3. 生产环境落地建议
- 中小规模(<10GB):主从+哨兵,简单稳定
- 大规模(>100GB):Redis Cluster,一步到位
- 核心业务:始终加哨兵或直接用Cluster
- 永远记住:没有银弹,根据业务量级选型

写在最后
Redis架构的核心逻辑是层层递进、互补短板:主从解决读并发,哨兵解决高可用,分片解决大容量。
很多开发者在生产环境踩坑,本质是架构选型错误:用单机扛海量数据、用主从不做哨兵、用哨兵不分片。记住:没有最好的架构,只有最贴合业务的架构。
如果觉得有帮助,欢迎点赞、收藏、转发!