文章:Heuristic-inspired Reasoning Priors Facilitate Data-Efficient Referring Object Detection
代码:https://github.com/xuzhang1199/HeROD
单位:悉尼大学、拉筹伯大学、武汉大学、新加坡南洋理工大学
一、问题背景
指称目标检测(Referring Object Detection, ROD)旨在根据自然语言描述,在图像中定位唯一指定的目标物体,是机器人交互、增强现实AR、医疗影像分析等真实落地场景的核心技术。
当前SOTA模型(如Grounding DINO、UNINEXT、GLIP)均面向数据充足场景 设计,依靠大规模预训练+端到端隐式学习,在标注极度稀缺的实际部署中存在明显缺陷:
-
模型必须从少量样本中从零重新学习"左右、上下、颜色、属性、相对位置"等基础常识,样本效率极低;
-
细粒度空间与语义线索学习不充分,导致定位精度大幅下降;
-
小样本下训练不稳定、收敛慢、极易过拟合,泛化能力差。

更关键的是,现有研究缺少专门针对"低数据/小样本ROD"的标准评测协议 。为此,本文首次提出De-ROD(Data-efficient Referring Object Detection) 基准,专门用于系统评估模型在极低数据(0.1%--5%) 和小样本泛化下的性能,填补领域空白。
二、方法创新(详细完整版)
本文提出HeROD(Heuristic-inspired Referring Object Detection) 框架,核心思路:不再让模型从稀缺数据中隐式学习基础推理规则,而是直接注入显式、可解释的启发式推理先验,引导模型快速收敛、提升数据效率。
HeROD是轻量级、模型无关的插件式框架,可无缝接入任意DETR-style检测器,不改动主干网络结构。
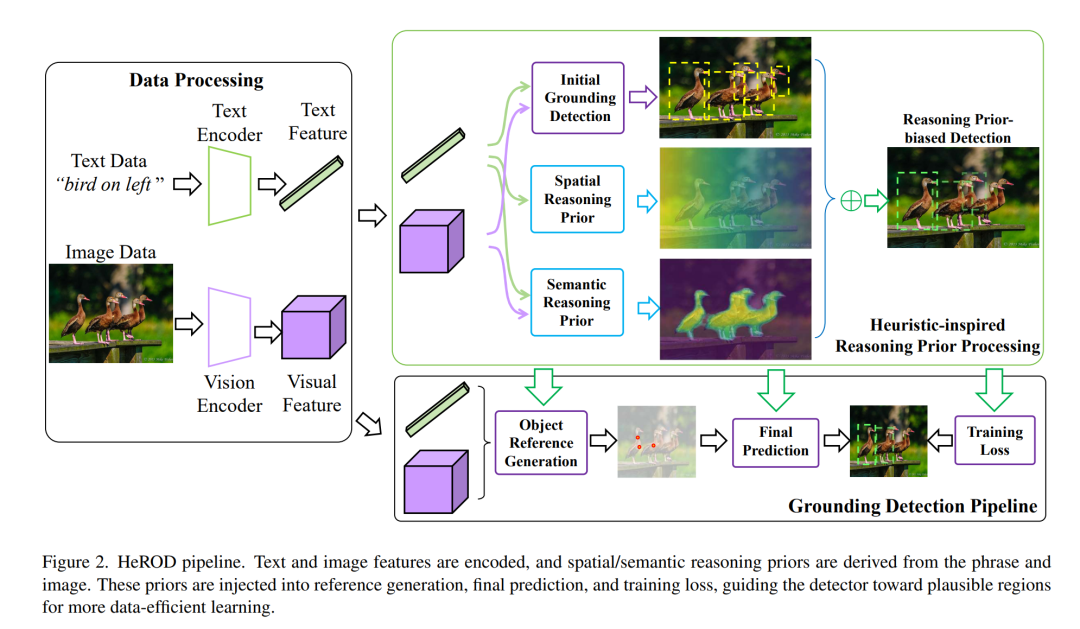
(一)核心先验设计:空间先验 + 视觉语义先验(论文中没有提供流程图,只有公式)
HeROD从文本描述与图像中自动提取两类可解释先验,无需任何额外标注。
1. 启发式空间先验 (H_s)
-
目标:显式建模"left/right/top/bottom/top-left"等方位约束,直接缩小目标搜索范围。
-
实现步骤:
-
构建空间描述词表 (T),包含基础方位与复合方位;
-
从指称语句 (d_i) 中匹配出空间词汇 (t_i);
-
生成与图像对齐的空间概率热图 (M_s(t_i)),越靠近目标方位得分越高;
-
对候选框 (o_j),取中心位置的热图分值作为空间先验:
-
作用:让模型直接知道"目标大概在图像的哪一侧",避免在错误区域浪费计算。
2. 启发式视觉语义先验 (H_v)
-
目标:显式建模物体属性、类别、文本-区域匹配度,解决相似物体歧义。
-
实现步骤:
-
采用CLIPSeg 作为文本-视觉对齐工具,输入整图与文本,输出稠密文本条件相关热图;
-
对每个候选框 (o_j),取框内所有像素的得分均值,作为该候选与描述的语义匹配度:
-
关键 :不是简单后处理融合,而是将CLIPSeg信号转化为可参与训练的推理先验,深度影响模型学习过程。
3. 先验融合
统一先验
,空间先验负责定位约束 ,视觉先验负责语义对齐 ,二者互补。
(二)三阶段深度注入DETR检测流程(核心创新)
HeROD将上述先验系统性注入DETR的三个关键阶段,从候选筛选、预测输出到训练损失全链路引导,这是区别于所有后处理/简单融合方法的本质创新。
阶段1:候选框生成(Reference Generation)------先验引导排序
-
问题:小样本下检测器置信度不可靠,Top-N筛选容易丢掉正确候选。
-
做法 :加法融合先验,直接将空间先验+视觉先验加到检测器原始置信度,再做Top-N筛选:
- 效果 :早期就保留空间合理+语义匹配的候选,显著提升后续解码质量与收敛速度。
阶段2:最终预测(Final Prediction)------自适应学习融合
-
问题:固定权重融合无法适应不同场景,先验与模型置信度需要动态平衡。
-
做法 :采用轻量级可学习MLP做自适应融合:
-
拼接 (H_s)、(H_v)、检测器置信度 (P);
-
送入小MLP学习最优权重;
-
输出最终预测得分:
- 效果:模型自动判断何时信任先验、何时信任视觉特征,鲁棒性大幅提升。
阶段3:训练目标(Training Objective)------先验增强匈牙利匹配
-
问题:小样本下分类分数噪声大,匈牙利匹配不稳定,导致损失监督错误。
-
做法1:修改匹配代价 将先验加入匹配代价函数,优先匹配符合先验的预测框:
-
做法2:增加先验置信损失 加入MSE损失,让模型预测置信度对齐启发式先验,实现强正则化:
-
效果:小样本下标签分配更稳定,训练更平滑,显著抑制过拟合。
(三)框架特性
-
模型无关:可直接插入Grounding DINO、UNINEXT、Deformable DETR等任意检测器;
-
即插即用:不修改主干、不增加标注成本、训练推理流程不变;
-
轻量高效:仅引入极小计算与参数量开销,延迟几乎无上升;
-
可扩展:未来可加入深度先验、关系先验、领域知识先验等。
三、实验结果
实验在RefCOCO / RefCOCO+ / RefCOCOg 三大权威数据集开展,覆盖极低数据 与小样本两种硬核场景。
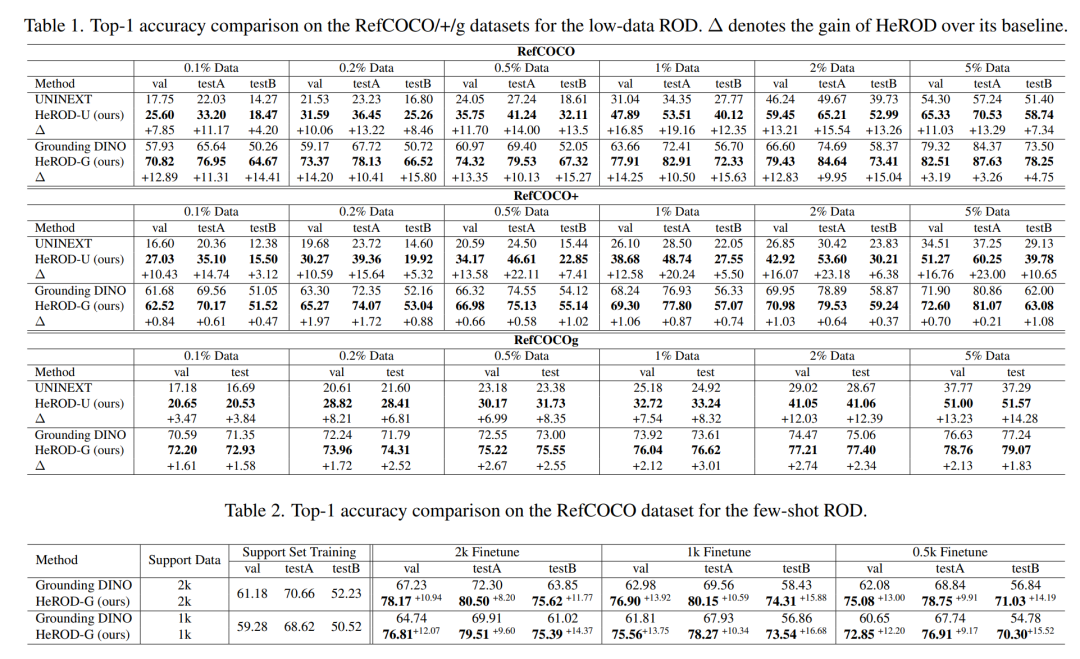
1. 极低数据场景(0.1%--5%标注)
-
HeROD在0.1%极限数据下,对Grounding DINO提升最高+12.89%;
-
对UNINEXT提升更显著,普遍+7%~+23%;
-
数据越少,增益越明显,完美解决小样本痛点。
2. 小样本泛化场景
-
以"人"为支持类,"非人类"为新类别微调;
-
基线模型出现灾难性遗忘,支持类性能明显下降;
-
HeROD新类别大涨+10%~+16%,同时保持支持类精度不下降,实现稳定泛化。
3. 全数据场景
- 性能不降反升,对Grounding DINO稳定提升+0.7~+1.0%,证明先验不限制模型表达。
4. 消融实验关键结论
-
空间先验+视觉先验共同使用效果最强,二者互补;
-
三阶段全注入 > 单阶段注入;
-
自适应MLP融合 > 固定加法融合;
-
先验增强匈牙利匹配是小样本涨点核心。
四、优势与局限
优势
-
首次定义De-ROD基准,为小样本ROD提供统一评测标准;
-
先验可解释、无额外标注,真实场景落地成本极低;
-
即插即用插件式框架,兼容所有DETR类检测器;
-
小样本增益极强,数据越稀缺效果越明显;
-
计算开销小,可直接部署到机器人、AR等端侧场景。
局限
-
空间先验仅支持基础方位词,复杂相对关系(旁边、中间、被遮挡)仍需扩展;
-
语义先验依赖CLIPSeg,医疗、工业等专业领域需适配领域专用视觉-语言模型;
-
暂未覆盖复杂逻辑推理与高阶关系先验。
五、一句话总结
HeROD通过将显式空间与语义启发式先验,深度注入DETR候选筛选、预测融合、训练匹配三大核心阶段 ,在不增加标注、不改动主干的前提下,大幅提升指称目标检测在极低数据与小样本下的精度、收敛速度与泛化能力,为真实场景落地提供了简单高效、可解释的新范式。