摘要
雷达电子战仿真是现代电子战系统设计与验证的关键环节,而仿真实体间的通信机制是仿真系统的中枢神经。本文深入探讨了雷达电子战仿真的通信需求特性,分析了Python语言在这一领域的优势与挑战,提出了面向未来的通信架构设计思路。我们将从雷达电子战的特殊需求出发,系统分析分布式仿真中的通信模式、实时性要求、数据特征,并探讨Python生态在满足这些需求时的技术选型、性能优化策略及工程实践方案。通过理论与实践相结合的方式,为后续系列文章奠定坚实的技术基础。
1. 引言
1.1 雷达电子战仿真的重要性
雷达电子战(Radar Electronic Warfare, REW)仿真是通过计算机模拟电磁环境、雷达系统、干扰设备和目标特性之间相互作用的技术。在现代军事系统中,电子战能力的优劣直接影响战场态势感知和作战效果。由于实际电子战训练成本高昂、环境复杂且难以复现,高保真度的仿真系统成为电子战装备研发、战术验证和人员训练的关键工具。
随着雷达技术的飞速发展,现代雷达系统呈现出多样化、智能化和网络化的特点,相应的电子对抗手段也日趋复杂。在这样的背景下,雷达电子战仿真的需求从简单的信号模拟扩展到包含信号级、脉冲级、跟踪级和认知级的多层次仿真,对仿真系统的通信机制提出了前所未有的挑战。
1.2 通信技术在仿真系统中的核心地位
在分布式雷达电子战仿真系统中,通信机制扮演着中枢神经的角色。不同的仿真实体(如雷达发射机、接收机、干扰机、目标、环境等)需要通过高效的通信机制进行数据交换,以模拟真实的电磁环境交互过程。通信系统的性能直接影响仿真的实时性、准确性和规模扩展能力。
传统的集中式仿真架构在应对大规模复杂场景时面临性能瓶颈,而分布式仿真架构通过将计算负载分散到多个节点,提供了更好的可扩展性。然而,分布式架构的成功实施高度依赖于高效的通信中间件和合理的通信协议设计。通信机制不仅需要处理仿真实体间的数据交换,还需要管理仿真时间同步、事件调度、状态一致性等复杂问题。
1.3 Python在雷达电子战仿真中的机遇与挑战
近年来,Python凭借其简洁的语法、丰富的生态系统和强大的科学计算能力,在科学计算、数据分析和机器学习领域取得了巨大成功。在雷达电子战仿真领域,Python也逐渐展现出其独特优势:
机遇方面:
-
丰富的科学计算库:NumPy、SciPy、Pandas等库为信号处理、数据分析和可视化提供了强大支持
-
快速原型开发:Python的简洁语法和动态特性使得算法验证和系统原型开发更加高效
-
强大的集成能力:Python可以方便地集成C/C++、Fortran等高性能计算模块
-
活跃的社区生态:丰富的第三方库和活跃的开发社区为问题解决提供了便利
挑战方面:
-
实时性能限制:Python的全局解释器锁(GIL)和动态类型特性影响了实时性能
-
内存管理开销:Python对象的内存开销较大,对内存密集型应用不够友好
-
分布式计算支持:虽然Python有多个分布式计算框架,但在高并发、低延迟场景下仍有不足
-
工业级部署:雷达电子战仿真对可靠性和稳定性要求极高,Python在此方面经验相对较少
1.4 本文目标与结构安排
本文旨在深入分析雷达电子战仿真的通信需求,探讨Python实现中的关键技术挑战,并提出可行的解决方案。通过本文,读者可以:
-
理解雷达电子战仿真的通信需求特性和技术挑战
-
掌握Python在实时分布式系统中的性能优化方法
-
了解适用于雷达电子战仿真的通信架构设计思路
-
为后续深入探讨具体通信技术和实现方案奠定基础
本文结构安排如下:
-
第2章深入分析雷达电子战仿真的通信需求,包括数据特征、实时性要求和可扩展性需求
-
第3章探讨分布式仿真通信的关键技术,包括通信模式、中间件选型和协议设计
-
第4章重点分析Python实现中的性能挑战,包括GIL、内存管理和并发模型
-
第5章提出面向雷达电子战仿真的Python通信架构设计
-
第6章通过一个简单案例展示Python通信框架的实现
-
第7章对关键技术点进行总结,并展望后续研究方向
2. 雷达电子战仿真通信需求深度分析
2.1 雷达电子战仿真的数据特征
雷达电子战仿真涉及多种类型的数据交换,每种数据都有其独特的特征和要求。理解这些数据特征是设计高效通信系统的基础。
2.1.1 信号级数据
信号级仿真是最精细的仿真层次,直接模拟雷达信号的产生、传播、反射、接收和处理过程。信号级数据具有以下特征:
python
class SignalLevelData:
"""信号级数据特征分析"""
def __init__(self):
# 数据特征
self.data_rate = 100e6 # 数据率可达100MB/s以上
self.data_precision = np.complex128 # 复数数据,高精度
self.dimensionality = 3 # 时域、频域、空域三维数据
self.correlation = "high" # 数据相关性高,存在冗余
def characteristics(self):
return {
"volume": "极大", # 数据量大
"timeliness": "严格实时", # 实时性要求高
"reliability": "中等", # 允许少量数据丢失
"order": "不敏感" # 时序要求相对宽松
}信号级数据的主要挑战在于其巨大的数据量。以典型的脉冲多普勒雷达为例,假设脉冲重复频率为10kHz,每个脉冲采样点数为1024,I/Q两路数据采用16位量化,则单个雷达通道的数据产生速率约为:
10,000×1,024×4×2=81.92 MB/s在多通道、多雷达的复杂电磁环境中,总数据速率可达GB/s级别。
2.1.2 脉冲描述字(PDW)数据
脉冲描述字是脉冲级仿真的核心数据单元,用于描述雷达脉冲的特征参数:
python
@dataclass
class PulseDescriptorWord:
"""脉冲描述字数据结构"""
# 基本参数
timestamp: int # 纳秒级时间戳
frequency: float # 载频(MHz)
amplitude: float # 幅度(dBm)
pulse_width: float # 脉宽(μs)
# 方向参数
azimuth: float # 方位角(度)
elevation: float # 俯仰角(度)
# 调制参数
modulation_type: str # 调制类型
chirp_rate: Optional[float] # 线性调频斜率(MHz/μs)
# 来源信息
emitter_id: str # 辐射源标识
pulse_id: int # 脉冲序号
def data_volume(self) -> int:
"""计算单个PDW的数据量"""
# 假设使用高效二进制编码
return 64 # 字节PDW数据的特点是结构化强、数据量适中但频率高。在密集电磁环境中,脉冲密度可达每秒数百万个,对通信系统的吞吐量和处理能力提出较高要求。
2.1.3 跟踪与态势数据
跟踪级数据描述目标运动状态,态势数据描述整体战场环境:
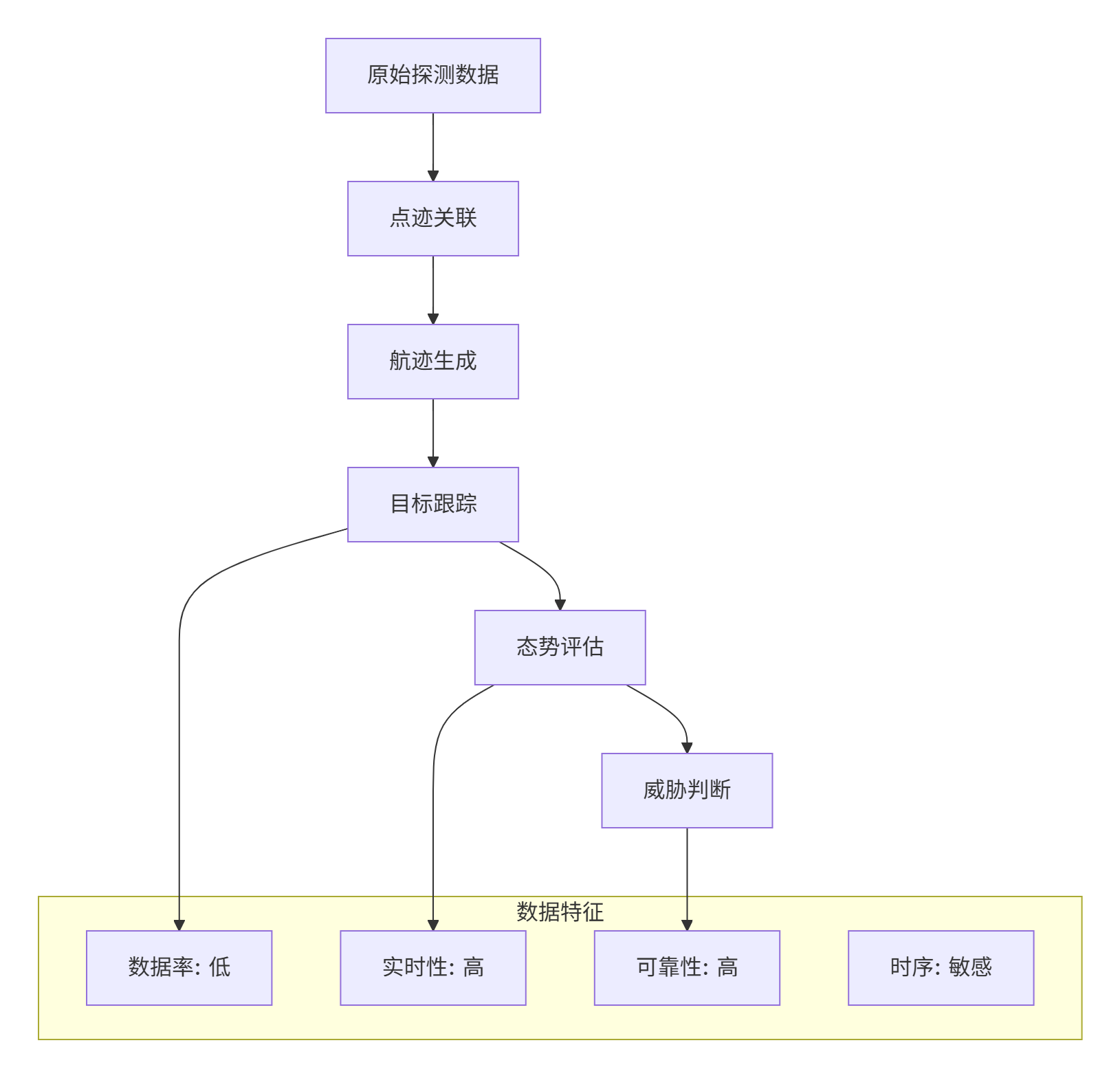
跟踪与态势数据具有以下特点:
-
数据量相对较小:通常为结构化状态向量
-
实时性要求高:跟踪延迟直接影响决策质量
-
可靠性要求高:关键态势信息不能丢失
-
时序敏感:数据必须按正确顺序处理
2.2 实时性需求分析
实时性是雷达电子战仿真的核心要求,不同层次的仿真有不同的实时性标准。
2.2.1 硬实时、软实时和准实时
在雷达电子战仿真中,不同类型的通信对实时性的要求不同:
python
class RealTimeRequirements:
"""实时性需求分析"""
HARD_REAL_TIME = {
"max_latency": "1ms", # 最大延迟
"jitter": "10μs", # 抖动
"applications": ["信号级闭环控制", "硬件在环仿真"]
}
SOFT_REAL_TIME = {
"max_latency": "10ms",
"jitter": "100μs",
"applications": ["PDW传输", "交互式控制"]
}
NEAR_REAL_TIME = {
"max_latency": "100ms",
"jitter": "1ms",
"applications": ["态势显示", "事后分析"]
}
@staticmethod
def calculate_latency_budget(simulation_type: str) -> dict:
"""计算不同类型仿真的延迟预算"""
budgets = {
"signal_level": {
"processing": 0.2, # 处理延迟占比
"communication": 0.3, # 通信延迟占比
"synchronization": 0.1, # 同步延迟占比
"margin": 0.4 # 余量
},
"pulse_level": {
"processing": 0.3,
"communication": 0.4,
"synchronization": 0.1,
"margin": 0.2
},
"track_level": {
"processing": 0.4,
"communication": 0.3,
"synchronization": 0.2,
"margin": 0.1
}
}
return budgets.get(simulation_type, {})2.2.2 端到端延迟分析
通信延迟由多个部分组成,需要进行系统级分析:
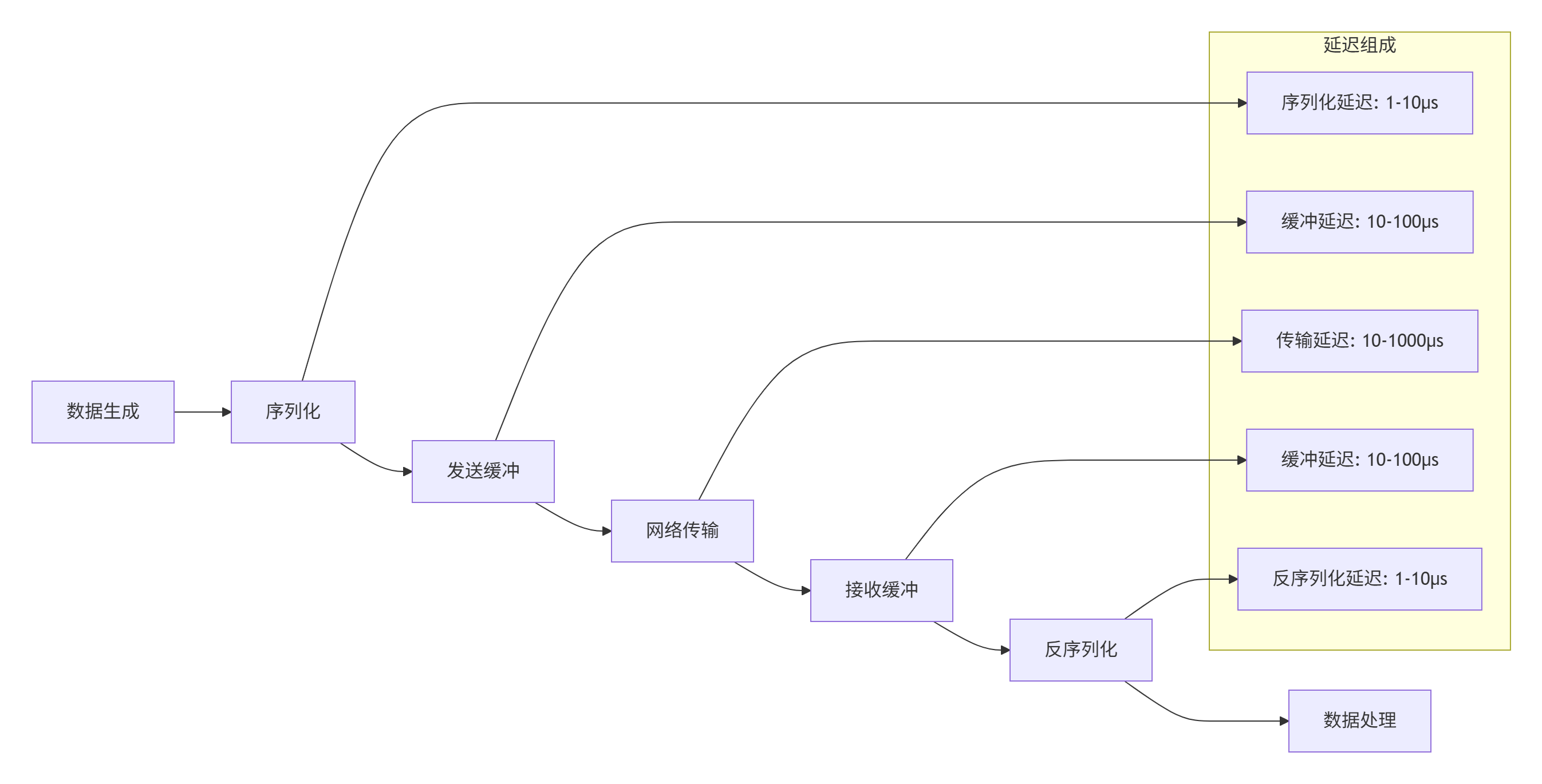
端到端延迟计算公式:
Ttotal=Tserial+Tsend_buffer+Ttransmit+Treceive_buffer+Tdeserial+Tprocess其中,网络传输延迟 Ttransmit可进一步分解为:
Ttransmit=Tpropagation+Ttransmission+Tqueuing+Tprocessing2.3 可扩展性与可靠性需求
现代雷达电子战仿真系统需要支持从单机到大规模分布式集群的平滑扩展。
2.3.1 可扩展性模型
可扩展性包括垂直扩展(增强单节点能力)和水平扩展(增加节点数量):
python
class ScalabilityModel:
"""可扩展性模型分析"""
def __init__(self):
self.components = {
"compute": {
"scalable": True,
"strategy": ["垂直扩展", "水平扩展"],
"bottleneck": "GIL限制"
},
"memory": {
"scalable": True,
"strategy": ["共享内存", "分布式内存"],
"bottleneck": "数据拷贝开销"
},
"network": {
"scalable": False, # 网络带宽有限
"strategy": ["优化协议", "数据压缩"],
"bottleneck": "带宽限制"
},
"io": {
"scalable": True,
"strategy": ["SSD加速", "并行IO"],
"bottleneck": "磁盘IOPS"
}
}
def analyze_bottlenecks(self, node_count: int) -> dict:
"""分析不同规模下的瓶颈"""
bottlenecks = {}
if node_count <= 4:
bottlenecks["primary"] = "计算能力"
bottlenecks["secondary"] = "内存带宽"
elif node_count <= 16:
bottlenecks["primary"] = "网络带宽"
bottlenecks["secondary"] = "数据同步"
else:
bottlenecks["primary"] = "管理开销"
bottlenecks["secondary"] = "通信协调"
return bottlenecks2.3.2 可靠性要求
雷达电子战仿真对可靠性有严格要求,特别是在训练和评估场景中:
-
数据完整性:关键数据不能丢失或损坏
-
系统可用性:需要高可用架构,支持故障转移
-
状态一致性:分布式系统中的状态需要保持一致
-
故障恢复:支持从故障中快速恢复
2.4 安全性与保密性需求
军事仿真系统对安全性和保密性有特殊要求:
-
数据加密:敏感数据在传输过程中需要加密
-
访问控制:严格的权限管理和身份验证
-
审计追踪:完整的操作日志和审计记录
-
物理隔离:关键系统可能需要物理隔离
3. 分布式仿真通信关键技术
3.1 通信模式分析
不同的通信模式适用于不同的仿真场景,需要根据具体需求进行选择。
3.1.1 点对点通信
点对点通信是最基本的通信模式,适用于确定性的数据交换:
python
class PointToPointCommunication:
"""点对点通信模式"""
def __init__(self):
self.patterns = {
"一对一": {
"description": "单个发送方到单个接收方",
"use_case": "控制指令传输",
"advantages": ["简单可靠", "延迟可预测"],
"disadvantages": ["扩展性差", "连接数爆炸"]
},
"一对多": {
"description": "单个发送方到多个接收方",
"use_case": "雷达辐射广播",
"advantages": ["高效广播", "发送方负载低"],
"disadvantages": ["可靠性难以保证", "接收方同步困难"]
},
"多对一": {
"description": "多个发送方到单个接收方",
"use_case": "数据融合中心",
"advantages": ["数据集中", "易于管理"],
"disadvantages": ["接收方瓶颈", "数据冲突"]
}
}
def pattern_selection_guide(self, requirements: dict) -> str:
"""通信模式选择指南"""
if requirements["sender_count"] == 1:
if requirements["receiver_count"] == 1:
return "一对一"
else:
return "一对多"
else:
if requirements["receiver_count"] == 1:
return "多对一"
else:
return "多对多"3.1.2 发布-订阅模式
发布-订阅模式是分布式仿真中最常用的通信模式之一:
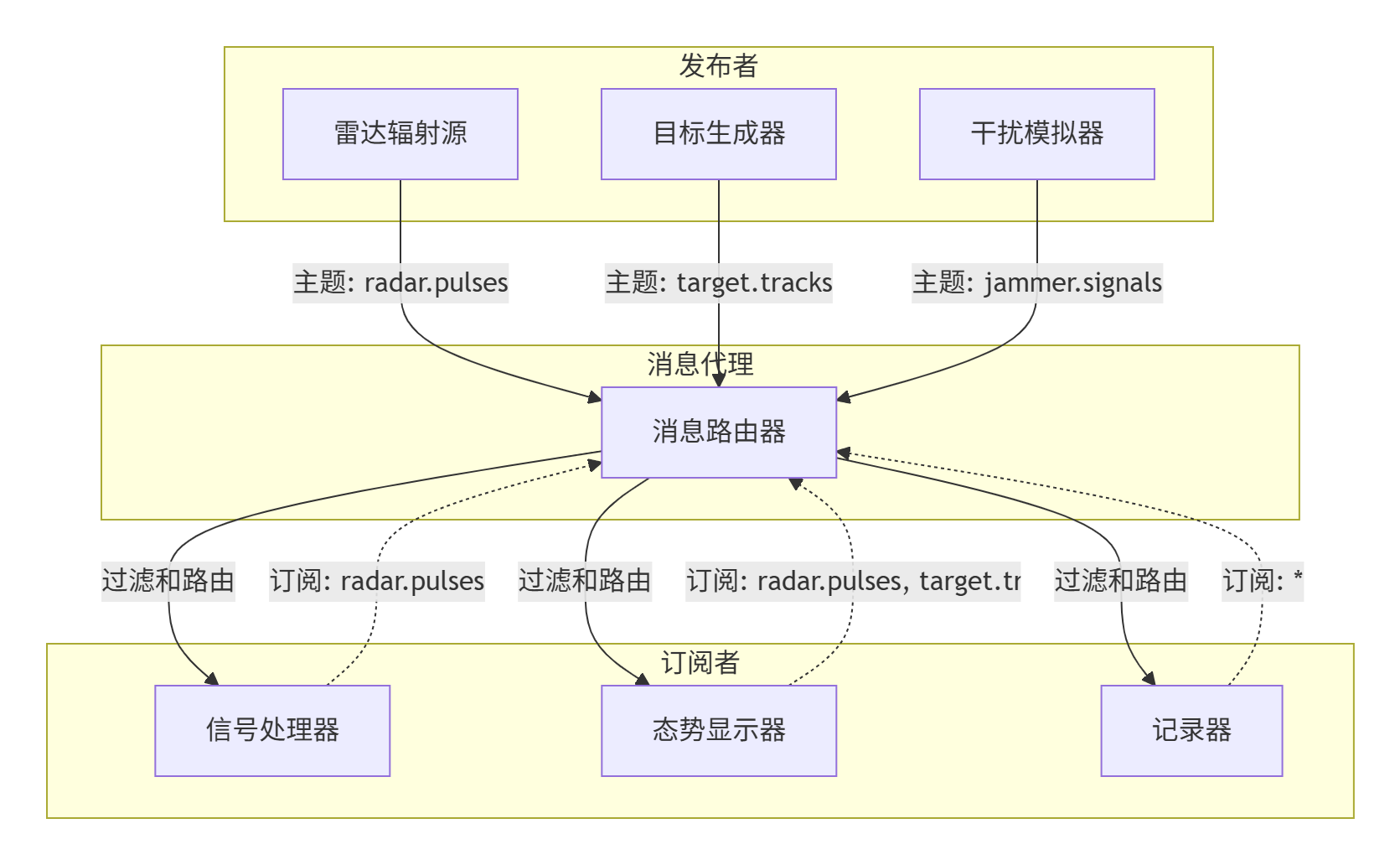
发布-订阅模式的关键优势:
-
解耦合:发布者和订阅者不需要知道对方的存在
-
动态性:可以动态添加/删除发布者或订阅者
-
过滤性:支持基于主题的内容过滤
-
扩展性:易于扩展到大规模系统
3.1.3 请求-响应模式
请求-响应模式适用于需要确认的交互场景:
python
class RequestResponsePattern:
"""请求-响应模式实现"""
async def handle_command(self, command: dict) -> dict:
"""处理控制指令请求"""
start_time = time.time()
try:
# 解析指令
cmd_type = command.get("type")
params = command.get("params", {})
# 执行相应操作
if cmd_type == "GET_STATUS":
response = await self.get_status(params)
elif cmd_type == "SET_PARAM":
response = await self.set_parameter(params)
elif cmd_type == "EXECUTE":
response = await self.execute_command(params)
else:
response = {"error": f"Unknown command: {cmd_type}"}
# 添加性能统计
response["metadata"] = {
"processing_time": time.time() - start_time,
"timestamp": time.time_ns()
}
return response
except Exception as e:
return {
"error": str(e),
"metadata": {
"processing_time": time.time() - start_time,
"timestamp": time.time_ns()
}
}3.2 中间件技术选型
选择合适的通信中间件是构建高效仿真系统的关键。
3.2.1 主流中间件对比
下表对比了几种适用于雷达电子战仿真的通信中间件:
| 中间件 | 通信模式 | 延迟 | 吞吐量 | Python支持 | 适用场景 |
|---|---|---|---|---|---|
| ZeroMQ | 多种模式 | 极低 | 高 | 优秀 | 实时数据传输 |
| Redis Pub/Sub | 发布-订阅 | 低 | 中 | 优秀 | 状态共享、配置分发 |
| RabbitMQ | 多种模式 | 中 | 高 | 优秀 | 可靠消息传递 |
| gRPC | 请求-响应 | 低 | 高 | 优秀 | 服务调用、流式数据 |
| Apache Kafka | 发布-订阅 | 中 | 极高 | 良好 | 日志、事件流 |
| DDS | 多种模式 | 极低 | 高 | 一般 | 硬实时系统 |
3.2.2 ZeroMQ深入分析
ZeroMQ是轻量级、高性能的消息传递库,特别适合雷达电子战仿真:
python
import zmq
import asyncio
from typing import List, Dict, Any
import json
import msgpack
class ZeroMQCommunicationFramework:
"""ZeroMQ通信框架实现"""
def __init__(self, config: Dict[str, Any]):
self.config = config
self.context = zmq.Context()
# 不同类型的socket
self.sockets = {
"pub": None, # 发布
"sub": None, # 订阅
"req": None, # 请求
"rep": None, # 响应
"push": None, # 推送
"pull": None, # 拉取
"dealer": None, # 异步请求
"router": None # 异步响应
}
# 序列化器选择
self.serializers = {
"json": lambda data: json.dumps(data).encode("utf-8"),
"msgpack": msgpack.packb,
"pickle": pickle.dumps
}
# 反序列化器
self.deserializers = {
"json": lambda data: json.loads(data.decode("utf-8")),
"msgpack": msgpack.unpackb,
"pickle": pickle.loads
}
self.serializer = config.get("serializer", "msgpack")
def create_socket(self, socket_type: str, endpoint: str, bind: bool = True):
"""创建并配置socket"""
if socket_type not in self.sockets:
raise ValueError(f"Unsupported socket type: {socket_type}")
socket = self.context.socket(getattr(zmq, socket_type.upper()))
# 配置socket选项
if socket_type in ["pub", "sub"]:
# 发布-订阅模式配置
socket.setsockopt(zmq.LINGER, 0) # 立即关闭
socket.setsockopt(zmq.SNDHWM, 1000) # 发送高水位标记
socket.setsockopt(zmq.RCVHWM, 1000) # 接收高水位标记
elif socket_type in ["req", "rep"]:
# 请求-响应模式配置
socket.setsockopt(zmq.LINGER, 100) # 100ms后关闭
socket.setsockopt(zmq.REQ_CORRELATE, 1) # 请求关联
socket.setsockopt(zmq.REQ_RELAXED, 1) # 宽松模式
if bind:
socket.bind(endpoint)
else:
socket.connect(endpoint)
self.sockets[socket_type] = socket
return socket
async def publish(self, topic: str, data: Dict[str, Any]):
"""发布消息"""
if not self.sockets["pub"]:
raise RuntimeError("Publisher socket not initialized")
# 构造消息:主题 + 分隔符 + 数据
topic_bytes = topic.encode("utf-8")
data_bytes = self.serializers[self.serializer](data)
# ZeroMQ发布消息
self.sockets["pub"].send_multipart([topic_bytes, data_bytes])
async def subscribe(self, topic: str, callback):
"""订阅消息"""
if not self.sockets["sub"]:
raise RuntimeError("Subscriber socket not initialized")
# 设置订阅主题
self.sockets["sub"].setsockopt_string(zmq.SUBSCRIBE, topic)
# 启动接收循环
while True:
try:
# 接收消息
message = await asyncio.get_event_loop().run_in_executor(
None, self.sockets["sub"].recv_multipart
)
if len(message) >= 2:
received_topic = message[0].decode("utf-8")
data = self.deserializers[self.serializer](message[1])
# 调用回调函数
await callback(received_topic, data)
except asyncio.CancelledError:
break
except Exception as e:
print(f"Error receiving message: {e}")
def optimize_for_radar_simulation(self):
"""针对雷达仿真优化ZeroMQ配置"""
# 提高缓冲区大小
for socket in self.sockets.values():
if socket:
socket.setsockopt(zmq.SNDBUF, 1024 * 1024) # 1MB发送缓冲区
socket.setsockopt(zmq.RCVBUF, 1024 * 1024) # 1MB接收缓冲区
# 使用TCP_NODELAY减少延迟
for socket in self.sockets.values():
if socket and socket.type in [zmq.PUB, zmq.SUB]:
socket.setsockopt(zmq.TCP_NODELAY, 1)
# 配置多线程I/O
self.context.set(zmq.IO_THREADS, 4)3.2.3 混合通信架构
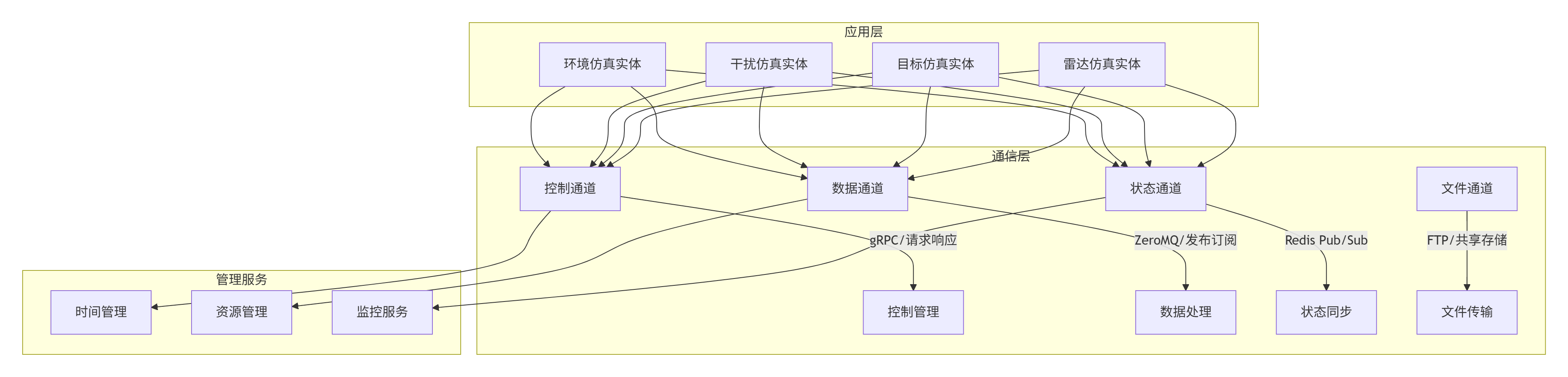
在实际雷达电子战仿真中,通常需要混合使用多种通信模式:
3.3 协议设计考虑
通信协议设计直接影响系统性能和可维护性。
3.3.1 消息格式设计
消息格式需要在效率和可读性之间取得平衡:
python
from dataclasses import dataclass
from typing import Optional, List, Dict, Any
import struct
from enum import IntEnum
class MessageType(IntEnum):
"""消息类型枚举"""
CONTROL = 0x01 # 控制消息
DATA = 0x02 # 数据消息
STATUS = 0x03 # 状态消息
EVENT = 0x04 # 事件消息
ERROR = 0x05 # 错误消息
@dataclass
class MessageHeader:
"""消息头部结构"""
version: int = 1 # 协议版本
msg_type: int = 0 # 消息类型
msg_id: int = 0 # 消息ID
timestamp: int = 0 # 时间戳(纳秒)
source_id: int = 0 # 源ID
dest_id: int = 0 # 目的ID
body_length: int = 0 # 消息体长度
checksum: int = 0 # 校验和
# 头部固定长度:8字节对齐
HEADER_SIZE = 32
def pack(self) -> bytes:
"""打包为二进制格式"""
return struct.pack(
"!BBQIIIIH", # 格式字符串
self.version,
self.msg_type,
self.timestamp,
self.source_id,
self.dest_id,
self.body_length,
self.checksum
)
@classmethod
def unpack(cls, data: bytes) -> 'MessageHeader':
"""从二进制解析"""
if len(data) < cls.HEADER_SIZE:
raise ValueError("Header data too short")
version, msg_type, timestamp, source_id, dest_id, body_length, checksum = \
struct.unpack("!BBQIIIIH", data[:cls.HEADER_SIZE])
return cls(
version=version,
msg_type=msg_type,
timestamp=timestamp,
source_id=source_id,
dest_id=dest_id,
body_length=body_length,
checksum=checksum
)
class RadarSimulationProtocol:
"""雷达仿真通信协议"""
def __init__(self, serializer="msgpack"):
self.serializer = serializer
self.sequence_counter = 0
def create_message(self,
msg_type: MessageType,
source_id: int,
dest_id: int,
body: Dict[str, Any]) -> bytes:
"""创建完整消息"""
# 序列化消息体
if self.serializer == "msgpack":
body_bytes = msgpack.packb(body, use_bin_type=True)
elif self.serializer == "json":
body_bytes = json.dumps(body).encode("utf-8")
else:
raise ValueError(f"Unsupported serializer: {self.serializer}")
# 创建消息头
header = MessageHeader(
msg_type=msg_type.value,
msg_id=self.sequence_counter,
timestamp=time.time_ns(),
source_id=source_id,
dest_id=dest_id,
body_length=len(body_bytes)
)
# 计算校验和
header.checksum = self._calculate_checksum(body_bytes)
# 递增序列号
self.sequence_counter = (self.sequence_counter + 1) & 0xFFFFFFFF
# 组合消息
return header.pack() + body_bytes
def parse_message(self, data: bytes) -> tuple:
"""解析消息"""
# 解析头部
header = MessageHeader.unpack(data[:MessageHeader.HEADER_SIZE])
# 验证消息长度
if len(data) < MessageHeader.HEADER_SIZE + header.body_length:
raise ValueError("Incomplete message")
# 提取消息体
body_data = data[MessageHeader.HEADER_SIZE:MessageHeader.HEADER_SIZE + header.body_length]
# 验证校验和
if header.checksum != self._calculate_checksum(body_data):
raise ValueError("Checksum verification failed")
# 反序列化消息体
if self.serializer == "msgpack":
body = msgpack.unpackb(body_data, raw=False)
elif self.serializer == "json":
body = json.loads(body_data.decode("utf-8"))
else:
raise ValueError(f"Unsupported serializer: {self.serializer}")
return header, body
def _calculate_checksum(self, data: bytes) -> int:
"""计算校验和"""
checksum = 0
for byte in data:
checksum = (checksum + byte) & 0xFFFF
return checksum3.3.2 序列化性能比较
不同序列化方式的性能差异显著:
python
import timeit
import json
import msgpack
import pickle
import numpy as np
from typing import Dict, Any
class SerializationBenchmark:
"""序列化性能基准测试"""
def __init__(self):
# 测试数据:模拟雷达脉冲描述字
self.test_data = self._create_test_data()
def _create_test_data(self) -> Dict[str, Any]:
"""创建测试数据"""
return {
"emitter_id": "radar_001",
"timestamp": time.time_ns(),
"frequency": 3000.0, # MHz
"power": 100.0, # dBm
"pulse_width": 10.0, # μs
"pulse_interval": 1000.0, # μs
"azimuth": 45.0, # 度
"elevation": 10.0, # 度
"modulation": "LFM",
"chirp_rate": 10.0, # MHz/μs
"i_samples": np.random.randn(1024).tolist(), # I路采样
"q_samples": np.random.randn(1024).tolist() # Q路采样
}
def benchmark(self, iterations: int = 10000) -> Dict[str, Any]:
"""运行基准测试"""
results = {}
# JSON序列化
json_time = timeit.timeit(
lambda: json.dumps(self.test_data),
number=iterations
)
json_data = json.dumps(self.test_data)
json_size = len(json_data.encode("utf-8"))
results["json"] = {
"time_ms": json_time * 1000 / iterations,
"size_bytes": json_size,
"compression_ratio": 1.0
}
# MessagePack序列化
msgpack_time = timeit.timeit(
lambda: msgpack.packb(self.test_data),
number=iterations
)
msgpack_data = msgpack.packb(self.test_data)
msgpack_size = len(msgpack_data)
results["msgpack"] = {
"time_ms": msgpack_time * 1000 / iterations,
"size_bytes": msgpack_size,
"compression_ratio": json_size / msgpack_size
}
# Pickle序列化
pickle_time = timeit.timeit(
lambda: pickle.dumps(self.test_data),
number=iterations
)
pickle_data = pickle.dumps(self.test_data)
pickle_size = len(pickle_data)
results["pickle"] = {
"time_ms": pickle_time * 1000 / iterations,
"size_bytes": pickle_size,
"compression_ratio": json_size / pickle_size
}
return results
# 运行基准测试
benchmark = SerializationBenchmark()
results = benchmark.benchmark(1000)
print("序列化性能对比:")
for format_name, metrics in results.items():
print(f"\n{format_name}:")
print(f" 平均时间: {metrics['time_ms']:.3f} ms")
print(f" 数据大小: {metrics['size_bytes']} 字节")
print(f" 压缩比: {metrics['compression_ratio']:.2f}x")3.4 时间同步机制
分布式仿真的时间同步是关键技术挑战之一。
3.4.1 时间同步算法
python
import time
from typing import List, Tuple
import statistics
class TimeSynchronizer:
"""分布式时间同步器"""
def __init__(self, sync_interval: float = 1.0):
self.sync_interval = sync_interval
self.offset = 0.0 # 本地时钟偏移
self.drift = 1.0 # 时钟漂移率
self.last_sync = 0.0
self.offsets_history: List[float] = []
def ntp_style_sync(self, server_times: List[Tuple[float, float]]) -> float:
"""
NTP风格时间同步算法
参数:
server_times: [(T1, T2, T3, T4), ...]
T1: 客户端发送时间
T2: 服务器接收时间
T3: 服务器响应时间
T4: 客户端接收时间
返回:
计算出的时钟偏移
"""
offsets = []
delays = []
for T1, T2, T3, T4 in server_times:
# 计算偏移和延迟
offset = ((T2 - T1) + (T3 - T4)) / 2
delay = (T4 - T1) - (T3 - T2)
offsets.append(offset)
delays.append(delay)
# 过滤异常值
filtered_offsets = self._remove_outliers(offsets)
if not filtered_offsets:
return 0.0
# 使用最小延迟样本计算最终偏移
min_delay_idx = delays.index(min(delays))
return offsets[min_delay_idx]
def _remove_outliers(self, data: List[float], m: float = 2.0) -> List[float]:
"""移除异常值"""
if len(data) < 3:
return data
mean = statistics.mean(data)
std = statistics.stdev(data)
return [x for x in data if abs(x - mean) <= m * std]
def get_synchronized_time(self) -> float:
"""获取同步后的时间"""
current = time.time()
# 应用时钟偏移和漂移修正
elapsed = current - self.last_sync
corrected = current + self.offset + elapsed * (self.drift - 1.0)
return corrected
def adjust_clock(self, measured_offset: float, measured_drift: float = None):
"""调整本地时钟"""
# 平滑调整
self.offsets_history.append(measured_offset)
if len(self.offsets_history) > 10:
self.offsets_history.pop(0)
# 使用加权平均
weights = [0.5 ** i for i in range(len(self.offsets_history))]
total_weight = sum(weights)
weighted_offsets = [o * w for o, w in zip(self.offsets_history, weights)]
self.offset = sum(weighted_offsets) / total_weight
if measured_drift is not None:
# 调整时钟漂移
self.drift = 0.9 * self.drift + 0.1 * measured_drift
self.last_sync = time.time()3.4.2 仿真时间管理
python
class SimulationTimeManager:
"""仿真时间管理器"""
def __init__(self, time_scale: float = 1.0):
self.time_scale = time_scale # 时间缩放因子
self.real_time_base = time.time() # 实时基准
self.sim_time_base = 0.0 # 仿真时间基准
self.paused = False
self.pause_time = 0.0
def get_simulation_time(self) -> float:
"""获取当前仿真时间"""
if self.paused:
return self.sim_time_base
real_elapsed = time.time() - self.real_time_base
sim_elapsed = real_elapsed * self.time_scale
return self.sim_time_base + sim_elapsed
def set_simulation_time(self, sim_time: float):
"""设置仿真时间"""
self.sim_time_base = sim_time
self.real_time_base = time.time()
def pause(self):
"""暂停仿真时间"""
if not self.paused:
self.paused = True
self.pause_time = time.time()
def resume(self):
"""恢复仿真时间"""
if self.paused:
self.paused = False
pause_duration = time.time() - self.pause_time
self.real_time_base += pause_duration
def set_time_scale(self, scale: float):
"""设置时间缩放因子"""
# 保存当前仿真时间
current_sim_time = self.get_simulation_time()
# 更新参数
self.time_scale = scale
self.real_time_base = time.time()
self.sim_time_base = current_sim_time4. Python实现挑战与优化策略
4.1 Python性能瓶颈分析
Python在雷达电子战仿真中面临的主要性能挑战。
4.1.1 全局解释器锁(GIL)的影响
GIL是CPython解释器中的机制,它防止多个线程同时执行Python字节码:
python
import threading
import time
import multiprocessing as mp
from concurrent.futures import ThreadPoolExecutor, ProcessPoolExecutor
class GILImpactAnalysis:
"""GIL影响分析"""
def cpu_bound_task(self, n: int) -> float:
"""CPU密集型任务"""
result = 0
for i in range(n):
result += i * i
return result
def io_bound_task(self, duration: float) -> float:
"""I/O密集型任务"""
time.sleep(duration)
return duration
def test_threads_vs_processes(self, task_type: str = "cpu"):
"""对比线程和进程的性能"""
n_iterations = 10_000_000
n_workers = 4
if task_type == "cpu":
task = lambda: self.cpu_bound_task(n_iterations)
else:
task = lambda: self.io_bound_task(0.1)
# 多线程测试
start = time.time()
with ThreadPoolExecutor(max_workers=n_workers) as executor:
futures = [executor.submit(task) for _ in range(n_workers)]
results = [f.result() for f in futures]
thread_time = time.time() - start
# 多进程测试
start = time.time()
with ProcessPoolExecutor(max_workers=n_workers) as executor:
futures = [executor.submit(task) for _ in range(n_workers)]
results = [f.result() for f in futures]
process_time = time.time() - start
return {
"thread_time": thread_time,
"process_time": process_time,
"speedup": thread_time / process_time
}
# 分析GIL影响
analyzer = GILImpactAnalysis()
print("CPU密集型任务测试:")
cpu_results = analyzer.test_threads_vs_processes("cpu")
print(f" 线程执行时间: {cpu_results['thread_time']:.2f}s")
print(f" 进程执行时间: {cpu_results['process_time']:.2f}s")
print(f" 加速比: {cpu_results['speedup']:.2f}x")
print("\nI/O密集型任务测试:")
io_results = analyzer.test_threads_vs_processes("io")
print(f" 线程执行时间: {io_results['thread_time']:.2f}s")
print(f" 进程执行时间: {io_results['process_time']:.2f}s")
print(f" 加速比: {io_results['speedup']:.2f}x")4.1.2 内存管理挑战
Python的动态内存管理在雷达仿真中可能成为瓶颈:
python
import tracemalloc
import numpy as np
from dataclasses import dataclass
from typing import List
import gc
class MemoryUsageAnalyzer:
"""内存使用分析"""
def __init__(self):
tracemalloc.start()
def analyze_list_allocation(self, size: int) -> dict:
"""分析列表内存分配"""
snapshot1 = tracemalloc.take_snapshot()
# 创建大型列表
data = []
for i in range(size):
data.append({
"id": i,
"frequency": 1000.0 + i * 0.1,
"power": 50.0 + i * 0.01,
"timestamp": i * 1000
})
snapshot2 = tracemalloc.take_snapshot()
# 分析内存差异
stats = snapshot2.compare_to(snapshot1, 'lineno')
return {
"list_size": len(data),
"memory_used": sum(stat.size for stat in stats),
"top_allocations": stats[:5]
}
def analyze_numpy_allocation(self, size: int) -> dict:
"""分析NumPy数组内存分配"""
snapshot1 = tracemalloc.take_snapshot()
# 创建NumPy数组
data = np.zeros((size, 4), dtype=np.float64)
for i in range(size):
data[i] = [i, 1000.0 + i * 0.1, 50.0 + i * 0.01, i * 1000]
snapshot2 = tracemalloc.take_snapshot()
stats = snapshot2.compare_to(snapshot1, 'lineno')
return {
"array_shape": data.shape,
"memory_used": data.nbytes,
"allocation_stats": stats[:5]
}
def optimize_memory_usage(self):
"""内存优化策略"""
strategies = {
"使用数组代替列表": "对于数值数据,使用array.array或NumPy数组",
"使用__slots__": "减少对象内存开销",
"使用生成器": "延迟计算,减少内存占用",
"及时释放引用": "使用del语句或设置None",
"使用内存视图": "避免不必要的数据拷贝",
"调整垃圾回收": "手动控制GC时机"
}
return strategies
# 内存使用分析
analyzer = MemoryUsageAnalyzer()
print("Python列表内存使用分析:")
list_result = analyzer.analyze_list_allocation(10000)
print(f" 列表大小: {list_result['list_size']}")
print(f" 内存使用: {list_result['memory_used'] / 1024:.2f} KB")
print("\nNumPy数组内存使用分析:")
numpy_result = analyzer.analyze_numpy_allocation(10000)
print(f" 数组形状: {numpy_result['array_shape']}")
print(f" 内存使用: {numpy_result['memory_used'] / 1024:.2f} KB")
print("\n内存优化策略:")
strategies = analyzer.optimize_memory_usage()
for strategy, description in strategies.items():
print(f" {strategy}: {description}")4.2 性能优化技术
针对雷达电子战仿真的性能优化策略。
4.2.1 使用C扩展加速关键路径
python
# setup.py
from setuptools import setup, Extension
from Cython.Build import cythonize
import numpy as np
# Cython扩展模块
extensions = [
Extension(
"radar_signal_processing",
sources=["radar_signal_processing.pyx"],
include_dirs=[np.get_include()],
extra_compile_args=['-O3', '-march=native', '-fopenmp'],
extra_link_args=['-fopenmp'],
define_macros=[('NPY_NO_DEPRECATED_API', 'NPY_1_7_API_VERSION')]
),
Extension(
"communication_fast",
sources=["communication_fast.c"],
extra_compile_args=['-O3', '-march=native'],
)
]
setup(
ext_modules=cythonize(extensions, compiler_directives={
'language_level': "3",
'boundscheck': False,
'wraparound': False,
'initializedcheck': False,
'cdivision': True
}),
include_dirs=[np.get_include()]
)Cython代码
python
# radar_signal_processing.pyx
import numpy as np
cimport numpy as cnp
cimport cython
from libc.math cimport sqrt, sin, cos, exp
from cython.parallel import prange, parallel
# 定义NumPy数据类型
cnp.import_array()
DTYPE = np.float64
ctypedef cnp.float64_t DTYPE_t
@cython.boundscheck(False)
@cython.wraparound(False)
def pulse_compression_fast(cnp.ndarray[DTYPE_t, ndim=1] signal,
cnp.ndarray[DTYPE_t, ndim=1] reference,
int n_threads=4):
"""
快速脉冲压缩(使用OpenMP并行)
参数:
signal: 输入信号
reference: 参考信号
n_threads: 并行线程数
返回:
脉冲压缩结果
"""
cdef int n = signal.shape[0]
cdef int m = reference.shape[0]
cdef int result_len = n + m - 1
cdef cnp.ndarray[DTYPE_t, ndim=1] result = np.zeros(result_len, dtype=DTYPE)
cdef DTYPE_t *signal_ptr = <DTYPE_t*>signal.data
cdef DTYPE_t *reference_ptr = <DTYPE_t*>reference.data
cdef DTYPE_t *result_ptr = <DTYPE_t*>result.data
cdef int i, j, k
cdef DTYPE_t sum_val
# 并行计算互相关
with nogil, parallel(num_threads=n_threads):
for i in prange(result_len, schedule='static'):
sum_val = 0.0
for j in range(m):
k = i - j
if k >= 0 and k < n:
sum_val += signal_ptr[k] * reference_ptr[j]
result_ptr[i] = sum_val
return result
@cython.boundscheck(False)
@cython.wraparound(False)
def matched_filter_batch(cnp.ndarray[DTYPE_t, ndim=2] signals,
cnp.ndarray[DTYPE_t, ndim=1] filter_coeff,
int n_threads=4):
"""
批量匹配滤波
参数:
signals: 信号矩阵,每行一个信号
filter_coeff: 滤波器系数
n_threads: 并行线程数
返回:
滤波结果矩阵
"""
cdef int n_signals = signals.shape[0]
cdef int n_samples = signals.shape[1]
cdef int filter_len = filter_coeff.shape[0]
cdef int result_len = n_samples + filter_len - 1
cdef cnp.ndarray[DTYPE_t, ndim=2] results = np.zeros(
(n_signals, result_len), dtype=DTYPE
)
cdef DTYPE_t *signals_ptr = <DTYPE_t*>signals.data
cdef DTYPE_t *filter_ptr = <DTYPE_t*>filter_coeff.data
cdef DTYPE_t *results_ptr = <DTYPE_t*>results.data
cdef int sig_idx, i, j, k
cdef DTYPE_t sum_val
# 批量处理多个信号
with nogil, parallel(num_threads=n_threads):
for sig_idx in prange(n_signals, schedule='dynamic'):
for i in range(result_len):
sum_val = 0.0
for j in range(filter_len):
k = i - j
if k >= 0 and k < n_samples:
sum_val += (
signals_ptr[sig_idx * n_samples + k] *
filter_ptr[j]
)
results_ptr[sig_idx * result_len + i] = sum_val
return results4.2.2 异步编程优化I/O性能
python
import asyncio
import aiozmq
import zmq
import msgpack
from typing import Dict, Any, Optional
import time
from concurrent.futures import ThreadPoolExecutor, ProcessPoolExecutor
class AsyncCommunicationFramework:
"""异步通信框架"""
def __init__(self, config: Dict[str, Any]):
self.config = config
self.loop = asyncio.get_event_loop()
# 线程池用于CPU密集型任务
self.thread_pool = ThreadPoolExecutor(
max_workers=config.get("max_threads", 4)
)
# 进程池用于计算密集型任务
self.process_pool = ProcessPoolExecutor(
max_workers=config.get("max_processes", 2)
)
# ZeroMQ上下文
self.context = zmq.asyncio.Context()
# 连接管理
self.connections = {}
self.subscriptions = {}
async def start_publisher(self, endpoint: str, topic: str):
"""启动异步发布者"""
socket = self.context.socket(zmq.PUB)
socket.bind(endpoint)
async def publish_loop():
while True:
# 生成数据
data = await self.generate_radar_data()
# 异步发送
await socket.send_multipart([
topic.encode("utf-8"),
msgpack.packb(data, use_bin_type=True)
])
# 控制发布频率
await asyncio.sleep(0.001) # 1ms间隔
# 启动发布循环
asyncio.create_task(publish_loop())
self.connections["publisher"] = socket
return socket
async def start_subscriber(self, endpoint: str, topics: List[str], callback):
"""启动异步订阅者"""
socket = self.context.socket(zmq.SUB)
socket.connect(endpoint)
# 订阅主题
for topic in topics:
socket.setsockopt_string(zmq.SUBSCRIBE, topic)
async def receive_loop():
while True:
try:
# 异步接收
topic, message = await socket.recv_multipart()
# 在线程池中处理消息(避免阻塞事件循环)
await self.loop.run_in_executor(
self.thread_pool,
self.process_message,
topic,
message,
callback
)
except asyncio.CancelledError:
break
except Exception as e:
print(f"Error receiving message: {e}")
await asyncio.sleep(0.1)
# 启动接收循环
task = asyncio.create_task(receive_loop())
self.subscriptions[endpoint] = task
return socket
async def generate_radar_data(self) -> Dict[str, Any]:
"""生成雷达数据(模拟)"""
# 在实际应用中,这里可能是从硬件或模拟器获取数据
return {
"timestamp": time.time_ns(),
"frequency": 3000.0 + np.random.randn() * 10,
"power": 100.0 + np.random.randn(),
"pulse_width": 10.0 + np.random.randn() * 0.1
}
def process_message(self, topic: bytes, message: bytes, callback):
"""处理接收到的消息"""
try:
# 反序列化
data = msgpack.unpackb(message, raw=False)
# 调用回调函数
callback(topic.decode("utf-8"), data)
except Exception as e:
print(f"Error processing message: {e}")
async def start_rpc_server(self, endpoint: str):
"""启动RPC服务器"""
socket = self.context.socket(zmq.REP)
socket.bind(endpoint)
async def handle_requests():
while True:
try:
# 接收请求
request = await socket.recv()
request_data = msgpack.unpackb(request, raw=False)
# 处理请求(在进程池中执行计算密集型任务)
response_data = await self.loop.run_in_executor(
self.process_pool,
self.process_rpc_request,
request_data
)
# 发送响应
response = msgpack.packb(response_data, use_bin_type=True)
await socket.send(response)
except asyncio.CancelledError:
break
except Exception as e:
print(f"RPC error: {e}")
error_response = {"error": str(e)}
await socket.send(msgpack.packb(error_response, use_bin_type=True))
# 启动请求处理循环
task = asyncio.create_task(handle_requests())
self.connections["rpc_server"] = (socket, task)
return socket
def process_rpc_request(self, request: Dict[str, Any]) -> Dict[str, Any]:
"""处理RPC请求"""
# 这里可以执行计算密集型操作
method = request.get("method")
params = request.get("params", {})
if method == "calculate_range":
# 计算距离
delay = params.get("delay", 0.0)
range_km = delay * 299792.458 / 2 # 光速/2
return {"range": range_km}
elif method == "process_signal":
# 处理信号
signal = np.array(params.get("signal", []))
result = np.abs(np.fft.fft(signal))
return {"result": result.tolist()}
else:
return {"error": f"Unknown method: {method}"}
async def cleanup(self):
"""清理资源"""
# 取消所有任务
for task in self.subscriptions.values():
task.cancel()
# 等待任务完成
if self.subscriptions:
await asyncio.gather(*self.subscriptions.values(),
return_exceptions=True)
# 关闭连接
for name, conn in self.connections.items():
if isinstance(conn, tuple):
conn[0].close()
else:
conn.close()
# 关闭线程池和进程池
self.thread_pool.shutdown(wait=True)
self.process_pool.shutdown(wait=True)
# 关闭上下文
self.context.term()4.3 内存优化策略
针对雷达仿真的大数据量特点进行内存优化。
4.3.1 使用内存视图和缓冲池
python
import numpy as np
from array import array
from typing import List, Optional
import mmap
import os
class MemoryOptimizedBuffer:
"""内存优化缓冲区"""
def __init__(self, buffer_size: int, dtype=np.float64):
self.buffer_size = buffer_size
self.dtype = dtype
self.dtype_size = np.dtype(dtype).itemsize
# 预分配内存池
self.buffer_pool = self._create_buffer_pool()
self.current_buffer = 0
def _create_buffer_pool(self) -> List[np.ndarray]:
"""创建内存缓冲池"""
pool = []
for _ in range(4): # 4个缓冲区
# 使用内存映射文件减少物理内存压力
buffer = np.memmap(
f"buffer_{_}.dat",
dtype=self.dtype,
mode="w+",
shape=(self.buffer_size,)
)
pool.append(buffer)
return pool
def get_buffer(self) -> np.ndarray:
"""获取缓冲区"""
buffer = self.buffer_pool[self.current_buffer]
self.current_buffer = (self.current_buffer + 1) % len(self.buffer_pool)
return buffer
def process_with_memory_view(self, data: np.ndarray) -> np.ndarray:
"""使用内存视图处理数据,避免拷贝"""
# 创建内存视图
data_view = memoryview(data)
# 处理数据(不复制)
result = np.frombuffer(data_view, dtype=self.dtype)
# 应用处理
result = result * 2 # 示例操作
return result
def circular_buffer_example(self, chunk_size: int):
"""循环缓冲区示例"""
buffer = np.zeros(self.buffer_size, dtype=self.dtype)
write_pos = 0
def add_data(new_data: np.ndarray):
nonlocal write_pos
n = len(new_data)
if write_pos + n <= self.buffer_size:
# 直接写入
buffer[write_pos:write_pos+n] = new_data
write_pos += n
else:
# 环绕写入
first_part = self.buffer_size - write_pos
buffer[write_pos:] = new_data[:first_part]
buffer[:n-first_part] = new_data[first_part:]
write_pos = n - first_part
return buffer
return add_data
class RadarDataProcessor:
"""雷达数据处理器(内存优化版)"""
def __init__(self, window_size: int = 1024):
self.window_size = window_size
# 使用__slots__减少内存开销
__slots__ = ['buffer', 'position', 'dtype']
self.buffer = np.zeros(window_size * 2, dtype=np.complex128)
self.position = 0
def process_chunk(self, data: np.ndarray) -> np.ndarray:
"""处理数据块,使用原地操作"""
n = len(data)
if self.position + n > len(self.buffer):
# 需要扩展缓冲区
new_size = max(len(self.buffer) * 2, self.position + n)
new_buffer = np.zeros(new_size, dtype=self.buffer.dtype)
new_buffer[:len(self.buffer)] = self.buffer
self.buffer = new_buffer
# 将数据复制到缓冲区(使用内存视图避免临时数组)
buffer_view = self.buffer[self.position:self.position+n]
np.copyto(buffer_view, data)
self.position += n
# 处理数据(使用原地操作)
if self.position >= self.window_size:
# 获取要处理的数据
process_data = self.buffer[self.position-self.window_size:self.position]
# 原地FFT
spectrum = np.fft.fft(process_data, overwrite_x=True)
# 原地幅度计算
magnitude = np.abs(spectrum, out=process_data[:len(spectrum)])
return magnitude
return np.array([])
def memory_efficient_correlation(self, signal: np.ndarray,
template: np.ndarray) -> np.ndarray:
"""内存高效的互相关计算"""
n = len(signal)
m = len(template)
result_len = n + m - 1
# 使用预分配的输出数组
result = np.empty(result_len, dtype=np.float64)
# 使用内存视图避免临时数组
signal_view = memoryview(signal)
template_view = memoryview(template)
# 手动计算互相关(可以使用C扩展进一步优化)
for i in range(result_len):
s = 0.0
for j in range(m):
k = i - j
if k >= 0 and k < n:
s += signal_view[k] * template_view[j]
result[i] = s
return result4.3.2 使用PyPy或Numba JIT编译
python
import numpy as np
from numba import jit, njit, prange, vectorize, cuda
import numba
from typing import List, Tuple, Optional
import time
from dataclasses import dataclass
from enum import Enum
class JITOptimizedProcessing:
"""使用JIT编译优化的处理函数"""
@staticmethod
@njit(parallel=True, fastmath=True)
def pulse_compression_numba(signal: np.ndarray,
reference: np.ndarray) -> np.ndarray:
"""
使用Numba加速的脉冲压缩
参数:
signal: 输入信号
reference: 参考信号
返回:
脉冲压缩结果
"""
n = len(signal)
m = len(reference)
result_len = n + m - 1
result = np.zeros(result_len, dtype=np.complex128)
# 并行计算互相关
for i in prange(result_len):
s = 0.0 + 0.0j
for j in range(m):
k = i - j
if k >= 0 and k < n:
s += signal[k] * np.conj(reference[j])
result[i] = s
return result
@staticmethod
@njit(fastmath=True)
def cfar_detection_numba(signal: np.ndarray,
guard_cells: int = 2,
training_cells: int = 10,
threshold_factor: float = 3.0) -> Tuple[np.ndarray, np.ndarray]:
"""
使用Numba加速的CFAR检测
参数:
signal: 输入信号
guard_cells: 保护单元数
training_cells: 训练单元数
threshold_factor: 阈值因子
返回:
(检测结果, 阈值)
"""
n = len(signal)
thresholds = np.zeros(n, dtype=np.float64)
detections = np.zeros(n, dtype=np.bool_)
half_train = training_cells // 2
total_side = guard_cells + half_train
for i in range(n):
# 计算训练单元的平均值
noise_power = 0.0
count = 0
# 左侧训练单元
for j in range(1, half_train + 1):
idx = i - guard_cells - j
if idx >= 0:
noise_power += np.abs(signal[idx]) ** 2
count += 1
# 右侧训练单元
for j in range(1, half_train + 1):
idx = i + guard_cells + j
if idx < n:
noise_power += np.abs(signal[idx]) ** 2
count += 1
if count > 0:
noise_avg = noise_power / count
thresholds[i] = threshold_factor * noise_avg
# 检测判断
signal_power = np.abs(signal[i]) ** 2
detections[i] = signal_power > thresholds[i]
return detections, thresholds
@staticmethod
@jit(forceobj=True, parallel=True)
def doppler_processing_python(signal_matrix: np.ndarray,
prf: float) -> Tuple[np.ndarray, np.ndarray]:
"""
多普勒处理(自动优化)
参数:
signal_matrix: 信号矩阵(脉冲×距离单元)
prf: 脉冲重复频率
返回:
(多普勒频率轴, 多普勒谱)
"""
n_pulses, n_range_bins = signal_matrix.shape
# 沿脉冲维做FFT
doppler_spectrum = np.fft.fft(signal_matrix, axis=0)
# 计算多普勒频率轴
doppler_freq = np.fft.fftfreq(n_pulses, 1/prf)
# 计算幅度谱
amplitude_spectrum = np.abs(doppler_spectrum)
return doppler_freq, amplitude_spectrum
@staticmethod
@njit(parallel=True, fastmath=True)
def stft_processing_numba(signal: np.ndarray,
window_size: int = 256,
hop_size: int = 128) -> np.ndarray:
"""
使用Numba加速的短时傅里叶变换
参数:
signal: 输入信号
window_size: 窗口大小
hop_size: 跳幅
返回:
时频矩阵
"""
n = len(signal)
n_frames = (n - window_size) // hop_size + 1
n_freq = window_size // 2 + 1
# 预分配结果矩阵
stft_matrix = np.zeros((n_freq, n_frames), dtype=np.complex128)
# 汉宁窗口
window = 0.5 * (1 - np.cos(2 * np.pi * np.arange(window_size) / window_size))
for frame in prange(n_frames):
start = frame * hop_size
end = start + window_size
# 提取窗口信号
frame_signal = signal[start:end] * window
# 计算FFT
spectrum = np.fft.fft(frame_signal)
# 只取前一半(对称)
stft_matrix[:, frame] = spectrum[:n_freq]
return stft_matrix
@staticmethod
@njit(fastmath=True)
def pdw_clustering_numba(pdws: np.ndarray,
freq_tolerance: float = 5.0,
pw_tolerance: float = 0.5,
pri_tolerance: float = 10.0) -> np.ndarray:
"""
使用Numba加速的PDW聚类分析
参数:
pdws: PDW数组,形状为(n_pdws, 3)
每行:[频率(MHz), 脉宽(us), 重频(us)]
freq_tolerance: 频率容差
pw_tolerance: 脉宽容差
pri_tolerance: 重频容差
返回:
聚类标签数组
"""
n = pdws.shape[0]
labels = -np.ones(n, dtype=np.int32)
cluster_id = 0
for i in range(n):
if labels[i] != -1:
continue
labels[i] = cluster_id
for j in range(i + 1, n):
if labels[j] != -1:
continue
# 计算PDW之间的差异
freq_diff = abs(pdws[i, 0] - pdws[j, 0])
pw_diff = abs(pdws[i, 1] - pdws[j, 1])
pri_diff = abs(pdws[i, 2] - pdws[j, 2])
# 判断是否属于同一聚类
if (freq_diff <= freq_tolerance and
pw_diff <= pw_tolerance and
pri_diff <= pri_tolerance):
labels[j] = cluster_id
cluster_id += 1
return labels
@staticmethod
@vectorize(['float64(float64, float64)'], nopython=True)
def vectorized_range_calc(time_delay: float, speed_of_light: float = 299792.458) -> float:
"""
向量化距离计算
参数:
time_delay: 时间延迟(us)
speed_of_light: 光速(km/s)
返回:
距离(km)
"""
return time_delay * speed_of_light / 2.0
# GPU加速版本(如果可用)
class CUDAOptimizedProcessing:
"""使用CUDA GPU加速的信号处理"""
def __init__(self):
self.gpu_available = cuda.is_available()
def pulse_compression_cuda(self, signal: np.ndarray,
reference: np.ndarray) -> Optional[np.ndarray]:
"""
使用CUDA加速的脉冲压缩
参数:
signal: 输入信号
reference: 参考信号
返回:
脉冲压缩结果
"""
if not self.gpu_available:
print("CUDA not available, falling back to CPU")
return None
# 将数据传输到GPU
d_signal = cuda.to_device(signal)
d_reference = cuda.to_device(reference)
d_result = cuda.device_array(len(signal) + len(reference) - 1, dtype=np.complex128)
# 定义CUDA核函数
@cuda.jit
def pulse_compression_kernel(signal, reference, result):
i = cuda.grid(1)
n = len(signal)
m = len(reference)
if i < len(result):
s = 0.0 + 0.0j
for j in range(m):
k = i - j
if k >= 0 and k < n:
s += signal[k] * np.conj(reference[j])
result[i] = s
# 配置线程和块
threads_per_block = 256
blocks_per_grid = (len(d_result) + threads_per_block - 1) // threads_per_block
# 执行核函数
pulse_compression_kernel[blocks_per_grid, threads_per_block](d_signal, d_reference, d_result)
# 将结果传回CPU
return d_result.copy_to_host()
def batch_matched_filter_cuda(self, signals: np.ndarray,
filter_coeff: np.ndarray) -> Optional[np.ndarray]:
"""
批量匹配滤波(CUDA加速)
参数:
signals: 信号矩阵,形状为(n_signals, n_samples)
filter_coeff: 滤波器系数
返回:
滤波结果矩阵
"""
if not self.gpu_available:
return None
n_signals, n_samples = signals.shape
filter_len = len(filter_coeff)
result_len = n_samples + filter_len - 1
# 将数据传输到GPU
d_signals = cuda.to_device(signals.flatten())
d_filter = cuda.to_device(filter_coeff)
d_results = cuda.device_array(n_signals * result_len, dtype=np.complex128)
# 定义CUDA核函数
@cuda.jit
def batch_matched_filter_kernel(signals, filter_coeff, results,
n_signals, n_samples, filter_len, result_len):
# 计算全局索引
idx = cuda.grid(1)
if idx < n_signals * result_len:
# 计算信号索引和结果位置
signal_idx = idx // result_len
result_pos = idx % result_len
# 计算卷积
s = 0.0 + 0.0j
for j in range(filter_len):
k = result_pos - j
if k >= 0 and k < n_samples:
signal_pos = signal_idx * n_samples + k
s += signals[signal_pos] * np.conj(filter_coeff[j])
results[idx] = s
# 配置线程和块
threads_per_block = 256
blocks_per_grid = (n_signals * result_len + threads_per_block - 1) // threads_per_block
# 执行核函数
batch_matched_filter_kernel[blocks_per_grid, threads_per_block](
d_signals, d_filter, d_results, n_signals, n_samples, filter_len, result_len
)
# 将结果传回CPU并重塑形状
results = d_results.copy_to_host()
return results.reshape(n_signals, result_len)
# PyPy优化示例
class PyPyOptimizedCode:
"""
PyPy优化的代码模式
注意:PyPy对纯Python代码有更好的JIT优化,但
对NumPy等C扩展的支持不如CPython
"""
@staticmethod
def pure_python_radar_sim(iterations: int) -> float:
"""
纯Python雷达模拟(适合PyPy)
参数:
iterations: 迭代次数
返回:
模拟结果
"""
import random
import math
# 模拟参数
target_range = 100.0 # km
speed_of_light = 299792.458 # km/s
prf = 1000.0 # Hz
n_pulses = 100
detections = 0
for _ in range(iterations):
# 模拟雷达脉冲
for pulse in range(n_pulses):
# 计算往返时间
time_delay = 2.0 * target_range / speed_of_light
# 添加噪声
time_delay += random.gauss(0, 0.001) # 1us抖动
# 模拟接收信号
received_power = 1.0 / (time_delay ** 2) # 简化模型
received_power += random.gauss(0, 0.1) # 噪声
# 检测逻辑
if received_power > 0.5:
detections += 1
break # 检测到目标,跳出脉冲循环
detection_probability = detections / iterations
return detection_probability
@staticmethod
def optimized_list_processing(data_size: int) -> List[float]:
"""
优化的列表处理(PyPy友好)
参数:
data_size: 数据大小
返回:
处理结果
"""
# 使用列表推导式(PyPy优化良好)
data = [i * 0.1 for i in range(data_size)]
# 使用内置函数和生成器
result = [
math.sin(x) * math.cos(x) + math.sqrt(abs(x))
for x in data
]
return result
# 性能对比和优化建议
class JITPerformanceAnalysis:
"""JIT性能分析工具"""
@staticmethod
def benchmark_all_methods():
"""全面基准测试"""
import time
import statistics
# 生成测试数据
np.random.seed(42)
# 测试1:脉冲压缩
print("=== 脉冲压缩性能测试 ===")
signal = np.random.randn(10000) + 1j * np.random.randn(10000)
reference = np.random.randn(100) + 1j * np.random.randn(100)
# Numba测试
start = time.time()
for _ in range(100):
result_numba = JITOptimizedProcessing.pulse_compression_numba(signal, reference)
numba_time = time.time() - start
# NumPy测试
start = time.time()
for _ in range(100):
result_numpy = np.correlate(signal, reference, mode='full')
numpy_time = time.time() - start
print(f"Numba: {numba_time:.3f}s, NumPy: {numpy_time:.3f}s")
print(f"加速比: {numpy_time/numba_time:.2f}x")
# 测试2:CFAR检测
print("\n=== CFAR检测性能测试 ===")
signal = np.random.randn(10000) + 1j * np.random.randn(10000)
# Numba测试
start = time.time()
for _ in range(100):
detections, thresholds = JITOptimizedProcessing.cfar_detection_numba(signal)
numba_time = time.time() - start
# Python实现
def python_cfar(signal, guard_cells=2, training_cells=10, threshold_factor=3.0):
n = len(signal)
thresholds = np.zeros(n)
detections = np.zeros(n, dtype=bool)
half_train = training_cells // 2
for i in range(n):
noise_power = 0.0
count = 0
for j in range(1, half_train + 1):
idx = i - guard_cells - j
if idx >= 0:
noise_power += np.abs(signal[idx]) ** 2
count += 1
for j in range(1, half_train + 1):
idx = i + guard_cells + j
if idx < n:
noise_power += np.abs(signal[idx]) ** 2
count += 1
if count > 0:
thresholds[i] = threshold_factor * noise_power / count
detections[i] = np.abs(signal[i]) ** 2 > thresholds[i]
return detections, thresholds
start = time.time()
for _ in range(10): # Python版本较慢,减少迭代次数
detections_py, thresholds_py = python_cfar(signal)
python_time = time.time() - start
print(f"Numba: {numba_time:.3f}s, Python: {python_time:.3f}s")
print(f"加速比: {python_time*10/numba_time/100:.2f}x") # 调整比例
# 测试3:STFT处理
print("\n=== STFT处理性能测试 ===")
signal = np.random.randn(100000)
# Numba测试
start = time.time()
for _ in range(10):
stft_result = JITOptimizedProcessing.stft_processing_numba(signal)
numba_time = time.time() - start
# SciPy测试
from scipy import signal as sp_signal
start = time.time()
for _ in range(10):
f, t, Zxx = sp_signal.stft(signal, nperseg=256, noverlap=128)
scipy_time = time.time() - start
print(f"Numba: {numba_time:.3f}s, SciPy: {scipy_time:.3f}s")
print(f"加速比: {scipy_time/numba_time:.2f}x")
return {
"pulse_compression": {"numba": numba_time, "numpy": numpy_time},
"cfar": {"numba": numba_time, "python": python_time},
"stft": {"numba": numba_time, "scipy": scipy_time}
}
@staticmethod
def get_optimization_recommendations():
"""获取优化建议"""
recommendations = {
"numba": [
"使用@njit装饰器替代@jit,强制nopython模式",
"启用fastmath选项加速数学运算(注意精度损失)",
"使用parallel=True和prange进行并行循环",
"避免在nopython模式中使用Python对象",
"使用NumPy数组而不是Python列表"
],
"pypy": [
"使用纯Python代码,避免C扩展",
"利用PyPy的JIT优化循环密集型代码",
"使用Python内置函数和数据结构",
"避免频繁的类型转换和对象创建",
"使用PyPy兼容的科学计算库(如numypy)"
],
"cuda": [
"仅用于大规模并行计算",
"避免频繁的CPU-GPU数据传输",
"使用共享内存减少全局内存访问",
"优化线程块和网格大小",
"使用异步执行隐藏内存传输延迟"
],
"general": [
"先分析性能瓶颈,再针对性优化",
"考虑算法复杂度,优化算法本身",
"使用适当的数据结构",
"避免不必要的内存分配和拷贝",
"利用缓存局部性原理"
]
}
return recommendations
# 实际应用示例
class RadarSignalProcessor:
"""雷达信号处理器(集成JIT优化)"""
def __init__(self, use_jit: bool = True, use_gpu: bool = False):
self.use_jit = use_jit
self.use_gpu = use_gpu
if use_gpu:
self.gpu_processor = CUDAOptimizedProcessing()
else:
self.gpu_processor = None
# 预编译JIT函数
if use_jit:
self._precompile_functions()
def _precompile_functions(self):
"""预编译JIT函数,减少首次运行开销"""
print("预编译JIT函数...")
# 使用小数据预编译
test_signal = np.random.randn(100) + 1j * np.random.randn(100)
test_reference = np.random.randn(10) + 1j * np.random.randn(10)
# 预编译脉冲压缩
_ = JITOptimizedProcessing.pulse_compression_numba(test_signal, test_reference)
# 预编译CFAR检测
_ = JITOptimizedProcessing.cfar_detection_numba(test_signal)
# 预编译STFT
_ = JITOptimizedProcessing.stft_processing_numba(test_signal[:256])
print("预编译完成")
def process_radar_data(self, signal: np.ndarray,
reference: np.ndarray = None) -> dict:
"""
处理雷达数据
参数:
signal: 输入信号
reference: 参考信号(用于脉冲压缩)
返回:
处理结果字典
"""
results = {}
# 脉冲压缩
if reference is not None:
if self.use_gpu and self.gpu_processor:
compressed = self.gpu_processor.pulse_compression_cuda(signal, reference)
elif self.use_jit:
compressed = JITOptimizedProcessing.pulse_compression_numba(signal, reference)
else:
compressed = np.correlate(signal, reference, mode='full')
results['pulse_compression'] = compressed
# CFAR检测
if self.use_jit:
detections, thresholds = JITOptimizedProcessing.cfar_detection_numba(
signal, guard_cells=2, training_cells=10, threshold_factor=3.0
)
else:
# Python实现
n = len(signal)
thresholds = np.zeros(n)
detections = np.zeros(n, dtype=bool)
guard_cells = 2
training_cells = 10
threshold_factor = 3.0
half_train = training_cells // 2
for i in range(n):
noise_power = 0.0
count = 0
for j in range(1, half_train + 1):
idx = i - guard_cells - j
if idx >= 0:
noise_power += np.abs(signal[idx]) ** 2
count += 1
for j in range(1, half_train + 1):
idx = i + guard_cells + j
if idx < n:
noise_power += np.abs(signal[idx]) ** 2
count += 1
if count > 0:
thresholds[i] = threshold_factor * noise_power / count
detections[i] = np.abs(signal[i]) ** 2 > thresholds[i]
results['cfar_detections'] = detections
results['cfar_thresholds'] = thresholds
# STFT分析
if self.use_jit and len(signal) >= 256:
stft_result = JITOptimizedProcessing.stft_processing_numba(
signal, window_size=256, hop_size=128
)
results['stft'] = stft_result
return results
# 使用示例
if __name__ == "__main__":
# 性能分析
print("开始性能分析...")
analysis = JITPerformanceAnalysis.benchmark_all_methods()
print("\n=== 优化建议 ===")
recommendations = JITPerformanceAnalysis.get_optimization_recommendations()
for category, tips in recommendations.items():
print(f"\n{category.upper()}优化建议:")
for tip in tips:
print(f" • {tip}")
# 实际应用示例
print("\n=== 实际应用示例 ===")
# 生成测试数据
np.random.seed(42)
n_samples = 10000
signal = np.random.randn(n_samples) + 1j * np.random.randn(n_samples)
# 添加目标信号
target_pos = 5000
signal[target_pos:target_pos+100] += 10.0 # 强目标
reference = np.random.randn(100) + 1j * np.random.randn(100)
# 创建处理器
processor_jit = RadarSignalProcessor(use_jit=True, use_gpu=False)
processor_nojit = RadarSignalProcessor(use_jit=False, use_gpu=False)
# 测试JIT版本
start = time.time()
results_jit = processor_jit.process_radar_data(signal, reference)
jit_time = time.time() - start
# 测试非JIT版本
start = time.time()
results_nojit = processor_nojit.process_radar_data(signal, reference)
nojit_time = time.time() - start
print(f"JIT版本处理时间: {jit_time:.3f}s")
print(f"非JIT版本处理时间: {nojit_time:.3f}s")
print(f"加速比: {nojit_time/jit_time:.2f}x")
# 验证结果一致性
if 'pulse_compression' in results_jit and 'pulse_compression' in results_nojit:
error = np.max(np.abs(results_jit['pulse_compression'] - results_nojit['pulse_compression']))
print(f"脉冲压缩结果最大误差: {error:.6e}")
print("\n测试完成!")5. 通信架构设计
5.1 分层架构设计
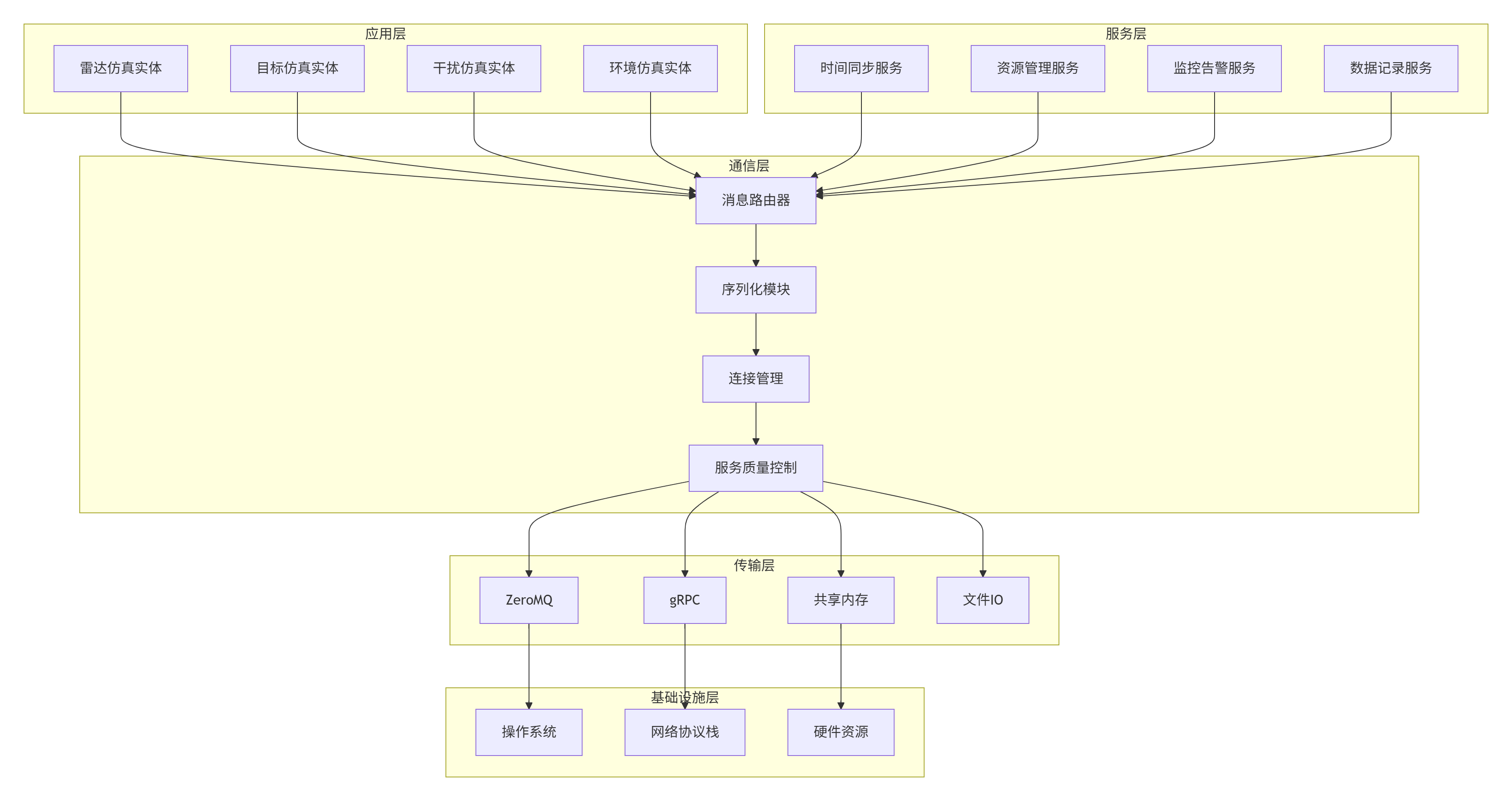
5.1.1 各层功能详述
应用层:包含所有雷达电子战仿真的具体实体,如雷达发射机、接收机、目标、干扰机等。每个实体通过定义良好的接口与通信层交互。
服务层:提供仿真系统所需的基础服务,包括:
-
时间同步:确保分布式仿真的时间一致性
-
资源管理:动态分配和管理计算资源
-
监控告警:实时监控系统状态,提供预警机制
-
数据记录:记录仿真数据用于事后分析
通信层:系统的核心,负责:
-
消息路由:根据消息类型和目的地进行智能路由
-
序列化:将Python对象转换为传输格式
-
连接管理:管理所有网络连接的生命周期
-
服务质量控制:提供消息优先级、可靠性保证等
传输层:提供底层的通信机制,支持多种传输方式以适应不同场景:
-
ZeroMQ:适用于高性能、低延迟的场景
-
gRPC:适用于需要强类型接口定义的场景
-
共享内存:适用于同一节点内的高效数据交换
-
文件IO:适用于大数据块的非实时传输
基础设施层:操作系统、网络协议栈和硬件资源,为上层提供基础支持。
5.2 核心组件设计
5.2.1 消息总线架构
python
from abc import ABC, abstractmethod
from typing import Dict, Any, Optional, List, Callable, Set
import asyncio
import threading
from concurrent.futures import ThreadPoolExecutor, ProcessPoolExecutor
from dataclasses import dataclass, field
from enum import Enum
import time
import uuid
from collections import defaultdict, deque
import heapq
class MessagePriority(Enum):
"""消息优先级枚举"""
CRITICAL = 0 # 控制指令、心跳、系统事件
HIGH = 1 # 实时数据、传感器数据
NORMAL = 2 # 常规数据、状态更新
LOW = 3 # 日志、批处理数据
BACKGROUND = 4 # 后台任务、非紧急数据
@dataclass(order=True)
class PrioritizedMessage:
"""带优先级的消息包装器"""
priority: int
timestamp: float
message: Any = field(compare=False)
def __init__(self, priority: MessagePriority, message: Any):
self.priority = priority.value
self.timestamp = time.time()
self.message = message
class MessageBus:
"""消息总线核心类"""
def __init__(self, config: Dict[str, Any]):
self.config = config
# 消息队列:优先级队列
self.message_queue = []
# 主题订阅者映射
self.topic_subscribers = defaultdict(list)
# 消息处理器映射
self.message_handlers = defaultdict(list)
# 连接管理
self.connections = {}
# 序列化器
self.serializers = {
'json': JSONSerializer(),
'msgpack': MsgPackSerializer(),
'pickle': PickleSerializer()
}
# 传输层
self.transports = {
'zmq': ZeroMQTransport(),
'grpc': GRPCTransport(config.get('grpc', {})),
'shared_memory': SharedMemoryTransport()
}
# 执行器
self.thread_pool = ThreadPoolExecutor(
max_workers=config.get('max_threads', 8)
)
self.process_pool = ProcessPoolExecutor(
max_workers=config.get('max_processes', 4)
)
# 监控
self.metrics = {
'messages_received': 0,
'messages_sent': 0,
'messages_dropped': 0,
'processing_times': deque(maxlen=1000)
}
# 运行状态
self.is_running = False
self.processing_tasks = set()
async def start(self):
"""启动消息总线"""
self.is_running = True
# 启动处理循环
asyncio.create_task(self._process_message_loop())
# 启动监控
asyncio.create_task(self._monitor_loop())
# 初始化传输层
for transport in self.transports.values():
if hasattr(transport, 'initialize'):
await transport.initialize()
print("消息总线已启动")
async def stop(self):
"""停止消息总线"""
self.is_running = False
# 等待所有处理任务完成
if self.processing_tasks:
await asyncio.gather(*self.processing_tasks, return_exceptions=True)
# 关闭传输层
for transport in self.transports.values():
if hasattr(transport, 'close'):
await transport.close()
# 关闭执行器
self.thread_pool.shutdown(wait=True)
self.process_pool.shutdown(wait=True)
print("消息总线已停止")
async def publish(self, topic: str, message: Any,
priority: MessagePriority = MessagePriority.NORMAL,
**kwargs) -> str:
"""发布消息"""
# 创建消息ID
message_id = str(uuid.uuid4())
# 构建完整消息
full_message = {
'id': message_id,
'topic': topic,
'timestamp': time.time_ns(),
'priority': priority,
'data': message,
'metadata': kwargs
}
# 添加到优先级队列
prioritized = PrioritizedMessage(priority, full_message)
heapq.heappush(self.message_queue, prioritized)
# 更新统计
self.metrics['messages_received'] += 1
return message_id
async def subscribe(self, topic: str, callback: Callable,
filter_func: Optional[Callable] = None) -> str:
"""订阅主题"""
subscription_id = str(uuid.uuid4())
self.topic_subscribers[topic].append({
'id': subscription_id,
'callback': callback,
'filter': filter_func
})
return subscription_id
async def unsubscribe(self, subscription_id: str):
"""取消订阅"""
for topic, subscribers in self.topic_subscribers.items():
self.topic_subscribers[topic] = [
sub for sub in subscribers
if sub['id'] != subscription_id
]
async def send_rpc(self, service: str, method: str,
params: Dict[str, Any],
timeout: float = 5.0) -> Any:
"""发送RPC请求"""
# 生成唯一的correlation_id
correlation_id = str(uuid.uuid4())
# 构建RPC消息
rpc_message = {
'type': 'rpc_request',
'service': service,
'method': method,
'params': params,
'correlation_id': correlation_id,
'timestamp': time.time_ns()
}
# 创建Future用于等待响应
future = asyncio.Future()
# 临时订阅响应主题
response_topic = f'rpc_response/{correlation_id}'
async def handle_response(response_message):
try:
future.set_result(response_message['result'])
except Exception as e:
future.set_exception(e)
response_subscription = await self.subscribe(
response_topic, handle_response
)
# 发送请求
await self.publish(
f'rpc_request/{service}/{method}',
rpc_message,
priority=MessagePriority.HIGH
)
try:
# 等待响应
result = await asyncio.wait_for(future, timeout=timeout)
return result
except asyncio.TimeoutError:
raise TimeoutError(f"RPC调用超时: {service}.{method}")
finally:
# 清理临时订阅
await self.unsubscribe(response_subscription)
async def _process_message_loop(self):
"""消息处理主循环"""
while self.is_running:
try:
if not self.message_queue:
await asyncio.sleep(0.001) # 短暂休眠避免CPU空转
continue
# 从优先级队列中获取消息
prioritized = heapq.heappop(self.message_queue)
message = prioritized.message
# 记录处理开始时间
start_time = time.time()
# 根据主题分发消息
topic = message['topic']
# 查找订阅者
subscribers = self.topic_subscribers.get(topic, [])
# 异步处理消息
tasks = []
for subscriber in subscribers:
# 应用过滤器
if subscriber['filter'] and not subscriber['filter'](message):
continue
# 创建处理任务
task = asyncio.create_task(
self._process_message_for_subscriber(
subscriber, message
)
)
tasks.append(task)
# 等待所有处理完成
if tasks:
await asyncio.gather(*tasks, return_exceptions=True)
# 更新统计
processing_time = time.time() - start_time
self.metrics['processing_times'].append(processing_time)
self.metrics['messages_sent'] += len(subscribers)
except Exception as e:
print(f"消息处理错误: {e}")
self.metrics['messages_dropped'] += 1
async def _process_message_for_subscriber(self, subscriber: Dict, message: Dict):
"""为订阅者处理消息"""
try:
callback = subscriber['callback']
# 如果回调是协程函数,直接await
if asyncio.iscoroutinefunction(callback):
await callback(message)
else:
# 否则在线程池中执行
await asyncio.get_event_loop().run_in_executor(
self.thread_pool, callback, message
)
except Exception as e:
print(f"订阅者处理消息错误: {e}")
async def _monitor_loop(self):
"""监控循环"""
while self.is_running:
try:
# 收集监控指标
metrics = self.get_metrics()
# 检查系统状态
await self._check_system_health(metrics)
# 发布监控数据
await self.publish(
'system/monitoring',
metrics,
priority=MessagePriority.LOW
)
# 每秒更新一次
await asyncio.sleep(1.0)
except Exception as e:
print(f"监控循环错误: {e}")
await asyncio.sleep(5.0)
def get_metrics(self) -> Dict[str, Any]:
"""获取当前监控指标"""
processing_times = list(self.metrics['processing_times'])
return {
'messages_received': self.metrics['messages_received'],
'messages_sent': self.metrics['messages_sent'],
'messages_dropped': self.metrics['messages_dropped'],
'queue_size': len(self.message_queue),
'processing_latency': {
'mean': sum(processing_times) / len(processing_times) if processing_times else 0,
'max': max(processing_times) if processing_times else 0,
'p95': np.percentile(processing_times, 95) if len(processing_times) >= 20 else 0
},
'subscription_counts': {
topic: len(subscribers)
for topic, subscribers in self.topic_subscribers.items()
},
'timestamp': time.time_ns()
}
async def _check_system_health(self, metrics: Dict[str, Any]):
"""检查系统健康状态"""
# 检查队列大小
queue_size = metrics['queue_size']
if queue_size > 10000:
print(f"警告: 消息队列过大: {queue_size}")
await self.publish(
'system/alert',
{'type': 'queue_overflow', 'size': queue_size},
priority=MessagePriority.CRITICAL
)
# 检查处理延迟
latency = metrics['processing_latency']['p95']
if latency > 0.1: # 100ms
print(f"警告: 处理延迟过高: {latency:.3f}s")
await self.publish(
'system/alert',
{'type': 'high_latency', 'latency': latency},
priority=MessagePriority.CRITICAL
)5.2.2 序列化框架
python
class SerializationFramework:
"""序列化框架,支持多种序列化格式"""
def __init__(self, default_format: str = 'msgpack'):
self.serializers = {
'json': JSONSerializer(),
'msgpack': MsgPackSerializer(),
'pickle': PickleSerializer(),
'protobuf': ProtobufSerializer(),
'avro': AvroSerializer(),
'capnproto': CapnProtoSerializer()
}
self.default_format = default_format
# 性能统计
self.performance_stats = defaultdict(list)
def serialize(self, obj: Any, format_name: str = None) -> bytes:
"""序列化对象"""
if format_name is None:
format_name = self.default_format
if format_name not in self.serializers:
raise ValueError(f"不支持的序列化格式: {format_name}")
serializer = self.serializers[format_name]
# 记录性能
start_time = time.perf_counter()
try:
result = serializer.serialize(obj)
# 记录序列化时间
elapsed = time.perf_counter() - start_time
self.performance_stats[f'{format_name}_serialize'].append(elapsed)
return result
except Exception as e:
raise SerializationError(f"序列化失败: {e}")
def deserialize(self, data: bytes, format_name: str = None) -> Any:
"""反序列化数据"""
if format_name is None:
# 自动检测格式
format_name = self._detect_format(data)
if format_name not in self.serializers:
raise ValueError(f"不支持的序列化格式: {format_name}")
serializer = self.serializers[format_name]
# 记录性能
start_time = time.perf_counter()
try:
result = serializer.deserialize(data)
# 记录反序列化时间
elapsed = time.perf_counter() - start_time
self.performance_stats[f'{format_name}_deserialize'].append(elapsed)
return result
except Exception as e:
raise DeserializationError(f"反序列化失败: {e}")
def _detect_format(self, data: bytes) -> str:
"""自动检测序列化格式"""
# 检查JSON
if data.startswith(b'{') or data.startswith(b'['):
try:
json.loads(data.decode('utf-8'))
return 'json'
except:
pass
# 检查MessagePack
if len(data) > 1 and data[0] in {0x80, 0x81, 0x82, 0x83, 0x84, 0x85, 0x86, 0x87, 0x88, 0x89, 0x8a, 0x8b, 0x8c, 0x8d, 0x8e, 0x8f}:
try:
msgpack.unpackb(data)
return 'msgpack'
except:
pass
# 检查Protocol Buffers
if len(data) >= 2 and data[0] == 0x0A: # 常见的PB消息起始字节
return 'protobuf'
# 默认返回配置的格式
return self.default_format
def get_performance_report(self) -> Dict[str, Any]:
"""获取性能报告"""
report = {}
for format_name in self.serializers.keys():
serialize_times = self.performance_stats.get(f'{format_name}_serialize', [])
deserialize_times = self.performance_stats.get(f'{format_name}_deserialize', [])
if serialize_times or deserialize_times:
report[format_name] = {
'serialize': {
'count': len(serialize_times),
'mean_ms': np.mean(serialize_times) * 1000 if serialize_times else 0,
'p95_ms': np.percentile(serialize_times, 95) * 1000 if len(serialize_times) >= 20 else 0
},
'deserialize': {
'count': len(deserialize_times),
'mean_ms': np.mean(deserialize_times) * 1000 if deserialize_times else 0,
'p95_ms': np.percentile(deserialize_times, 95) * 1000 if len(deserialize_times) >= 20 else 0
}
}
return report
class ProtobufSerializer(ISerializer):
"""Protocol Buffers序列化器"""
def __init__(self):
try:
import google.protobuf.message as message
self.message = message
except ImportError:
raise ImportError("请安装protobuf: pip install protobuf")
def serialize(self, obj: Any) -> bytes:
if hasattr(obj, 'SerializeToString'):
return obj.SerializeToString()
raise ValueError("对象不支持Protocol Buffers序列化")
def deserialize(self, data: bytes) -> Any:
# 需要在具体使用时指定消息类型
raise NotImplementedError("Protocol Buffers反序列化需要指定消息类型")
class AvroSerializer(ISerializer):
"""Apache Avro序列化器"""
def __init__(self):
try:
import avro.schema
import avro.io
import io
self.avro = avro
self.io = io
except ImportError:
raise ImportError("请安装avro: pip install avro-python3")
def serialize(self, obj: Any, schema_json: str = None) -> bytes:
if schema_json is None:
raise ValueError("Avro序列化需要schema")
schema = self.avro.schema.parse(schema_json)
writer = self.avro.io.DatumWriter(schema)
bytes_writer = self.io.BytesIO()
encoder = self.avro.io.BinaryEncoder(bytes_writer)
writer.write(obj, encoder)
return bytes_writer.getvalue()
def deserialize(self, data: bytes, schema_json: str = None) -> Any:
if schema_json is None:
raise ValueError("Avro反序列化需要schema")
schema = self.avro.schema.parse(schema_json)
reader = self.avro.io.DatumReader(schema)
bytes_reader = self.io.BytesIO(data)
decoder = self.avro.io.BinaryDecoder(bytes_reader)
return reader.read(decoder)5.2.3 连接管理器
python
class ConnectionManager:
"""连接管理器,负责管理所有网络连接"""
def __init__(self, config: Dict[str, Any]):
self.config = config
# 连接池
self.connections = {}
# 连接状态监控
self.connection_stats = defaultdict(dict)
# 重试策略
self.retry_policies = {
'exponential': lambda attempt: min(2 ** attempt, 60), # 指数退避,最大60秒
'linear': lambda attempt: attempt, # 线性退避
'fixed': lambda attempt: 1 # 固定间隔
}
# 心跳机制
self.heartbeat_interval = config.get('heartbeat_interval', 5.0)
self.heartbeat_timeout = config.get('heartbeat_timeout', 15.0)
async def get_connection(self, endpoint: str,
transport_type: str = 'zmq',
**kwargs) -> Any:
"""获取连接"""
connection_key = f"{transport_type}:{endpoint}"
if connection_key in self.connections:
connection = self.connections[connection_key]
# 检查连接是否健康
if await self._check_connection_health(connection):
return connection
else:
# 关闭不健康的连接
await self.close_connection(endpoint, transport_type)
# 创建新连接
connection = await self._create_connection(
endpoint, transport_type, **kwargs
)
self.connections[connection_key] = connection
# 初始化统计
self.connection_stats[connection_key] = {
'created_at': time.time(),
'requests': 0,
'errors': 0,
'last_used': time.time(),
'avg_latency': 0.0
}
# 启动心跳
asyncio.create_task(self._start_heartbeat(connection_key, connection))
return connection
async def _create_connection(self, endpoint: str,
transport_type: str, **kwargs) -> Any:
"""创建新连接"""
max_retries = kwargs.get('max_retries', 3)
retry_policy = kwargs.get('retry_policy', 'exponential')
for attempt in range(max_retries + 1):
try:
if transport_type == 'zmq':
return await self._create_zmq_connection(endpoint, **kwargs)
elif transport_type == 'grpc':
return await self._create_grpc_connection(endpoint, **kwargs)
elif transport_type == 'shared_memory':
return await self._create_shared_memory_connection(endpoint, **kwargs)
else:
raise ValueError(f"不支持的传输类型: {transport_type}")
except Exception as e:
if attempt < max_retries:
# 计算退避时间
backoff = self.retry_policies[retry_policy](attempt)
print(f"连接失败,{backoff}秒后重试: {e}")
await asyncio.sleep(backoff)
else:
raise ConnectionError(f"连接失败: {endpoint}, 错误: {e}")
async def _create_zmq_connection(self, endpoint: str, **kwargs) -> Any:
"""创建ZeroMQ连接"""
import zmq
import zmq.asyncio
context = zmq.asyncio.Context()
# 根据端点类型确定socket类型
if endpoint.startswith('tcp://'):
if ':push' in endpoint or ':pull' in endpoint:
socket_type = zmq.PUSH if ':push' in endpoint else zmq.PULL
elif ':pub' in endpoint or ':sub' in endpoint:
socket_type = zmq.PUB if ':pub' in endpoint else zmq.SUB
elif ':req' in endpoint or ':rep' in endpoint:
socket_type = zmq.REQ if ':req' in endpoint else zmq.REP
else:
socket_type = zmq.DEALER
socket = context.socket(socket_type)
# 配置socket
socket.setsockopt(zmq.LINGER, 0)
socket.setsockopt(zmq.SNDHWM, kwargs.get('send_hwm', 1000))
socket.setsockopt(zmq.RCVHWM, kwargs.get('receive_hwm', 1000))
if socket_type in [zmq.SUB, zmq.PUB, zmq.PULL, zmq.PUSH]:
socket.setsockopt(zmq.TCP_KEEPALIVE, 1)
socket.setsockopt(zmq.TCP_KEEPALIVE_IDLE, 60)
socket.setsockopt(zmq.TCP_KEEPALIVE_INTVL, 5)
socket.setsockopt(zmq.TCP_KEEPALIVE_CNT, 3)
# 连接或绑定
if endpoint.startswith('tcp://*:'):
# 服务器端绑定
socket.bind(endpoint.replace('tcp://*:', 'tcp://*:'))
else:
# 客户端连接
socket.connect(endpoint)
return {
'type': 'zmq',
'context': context,
'socket': socket,
'endpoint': endpoint
}
else:
raise ValueError(f"不支持的ZeroMQ端点: {endpoint}")
async def _create_grpc_connection(self, endpoint: str, **kwargs) -> Any:
"""创建gRPC连接"""
try:
import grpc
except ImportError:
raise ImportError("请安装grpcio: pip install grpcio")
# 创建通道
channel = grpc.aio.insecure_channel(
endpoint,
options=[
('grpc.max_send_message_length', kwargs.get('max_send_message_length', 100 * 1024 * 1024)),
('grpc.max_receive_message_length', kwargs.get('max_receive_message_length', 100 * 1024 * 1024)),
('grpc.keepalive_time_ms', kwargs.get('keepalive_time_ms', 10000)),
('grpc.keepalive_timeout_ms', kwargs.get('keepalive_timeout_ms', 5000)),
]
)
return {
'type': 'grpc',
'channel': channel,
'endpoint': endpoint
}
async def _create_shared_memory_connection(self, endpoint: str, **kwargs) -> Any:
"""创建共享内存连接"""
import mmap
import os
# 解析共享内存名称
if endpoint.startswith('shm://'):
shm_name = endpoint[6:]
else:
shm_name = endpoint
# 创建或打开共享内存
size = kwargs.get('size', 1024 * 1024) # 默认1MB
try:
# 尝试打开现有共享内存
shm_fd = os.shm_open(shm_name, os.O_RDWR, 0o600)
except FileNotFoundError:
# 创建新的共享内存
shm_fd = os.shm_open(shm_name, os.O_CREAT | os.O_RDWR, 0o600)
os.ftruncate(shm_fd, size)
# 内存映射
shm_mmap = mmap.mmap(shm_fd, size, access=mmap.ACCESS_WRITE)
return {
'type': 'shared_memory',
'fd': shm_fd,
'mmap': shm_mmap,
'name': shm_name,
'size': size
}
async def send_via_connection(self, connection: Dict[str, Any],
data: bytes, **kwargs) -> bool:
"""通过连接发送数据"""
connection_key = self._get_connection_key(connection)
start_time = time.perf_counter()
try:
if connection['type'] == 'zmq':
socket = connection['socket']
await socket.send(data)
success = True
elif connection['type'] == 'grpc':
# 需要具体的gRPC stub
raise NotImplementedError("gRPC发送需要具体的stub")
elif connection['type'] == 'shared_memory':
mmap_obj = connection['mmap']
mmap_obj.seek(0)
mmap_obj.write(data)
success = True
else:
raise ValueError(f"不支持的连接类型: {connection['type']}")
# 更新统计
latency = time.perf_counter() - start_time
stats = self.connection_stats[connection_key]
stats['requests'] += 1
stats['last_used'] = time.time()
# 更新平均延迟(指数加权移动平均)
alpha = 0.1
stats['avg_latency'] = (alpha * latency +
(1 - alpha) * stats['avg_latency'])
return success
except Exception as e:
# 记录错误
if connection_key in self.connection_stats:
self.connection_stats[connection_key]['errors'] += 1
raise SendError(f"发送失败: {e}")
async def _check_connection_health(self, connection: Dict[str, Any]) -> bool:
"""检查连接健康状态"""
connection_key = self._get_connection_key(connection)
if connection_key not in self.connection_stats:
return True
stats = self.connection_stats[connection_key]
# 检查错误率
if stats['requests'] > 0:
error_rate = stats['errors'] / stats['requests']
if error_rate > 0.5: # 错误率超过50%
return False
# 检查最后使用时间
if time.time() - stats['last_used'] > 3600: # 1小时未使用
return False
return True
async def _start_heartbeat(self, connection_key: str, connection: Dict[str, Any]):
"""启动心跳机制"""
while connection_key in self.connections:
try:
# 发送心跳
heartbeat_data = json.dumps({
'type': 'heartbeat',
'timestamp': time.time_ns()
}).encode('utf-8')
await self.send_via_connection(connection, heartbeat_data)
# 等待下一次心跳
await asyncio.sleep(self.heartbeat_interval)
except asyncio.CancelledError:
break
except Exception as e:
print(f"心跳失败: {e}")
# 心跳失败,标记连接为不健康
if connection_key in self.connections:
del self.connections[connection_key]
break
async def close_connection(self, endpoint: str, transport_type: str = 'zmq'):
"""关闭连接"""
connection_key = f"{transport_type}:{endpoint}"
if connection_key in self.connections:
connection = self.connections[connection_key]
try:
if connection['type'] == 'zmq':
connection['socket'].close()
connection['context'].term()
elif connection['type'] == 'grpc':
await connection['channel'].close()
elif connection['type'] == 'shared_memory':
connection['mmap'].close()
import os
os.close(connection['fd'])
except Exception as e:
print(f"关闭连接时出错: {e}")
# 从连接池移除
del self.connections[connection_key]
def _get_connection_key(self, connection: Dict[str, Any]) -> str:
"""获取连接的唯一键"""
return f"{connection['type']}:{connection.get('endpoint', 'unknown')}"
def get_connection_stats(self) -> Dict[str, Any]:
"""获取所有连接统计"""
return dict(self.connection_stats)5.3 异步消息处理架构
5.4 容错与恢复机制
python
class FaultTolerantCommunication:
"""容错通信系统"""
def __init__(self, config: dict):
self.config = config
self.retry_count = config.get('max_retries', 3)
self.retry_delay = config.get('retry_delay', 1.0)
# 熔断器配置
self.circuit_breaker = CircuitBreaker(
failure_threshold=config.get('failure_threshold', 5),
recovery_timeout=config.get('recovery_timeout', 30)
)
# 消息去重
self.message_deduplicator = MessageDeduplicator(
window_size=config.get('dedup_window', 1000)
)
# 监控
self.monitor = CommunicationMonitor()
async def send_with_retry(self, message: Message, endpoint: str) -> bool:
"""带重试的消息发送"""
for attempt in range(self.retry_count + 1):
try:
# 检查熔断器状态
if not self.circuit_breaker.allow_request():
raise CircuitBreakerOpenError("Circuit breaker is open")
# 发送消息
success = await self._send_message(message, endpoint)
if success:
self.circuit_breaker.record_success()
self.monitor.record_success(endpoint)
return True
else:
raise SendFailedError(f"Send failed on attempt {attempt}")
except Exception as e:
self.circuit_breaker.record_failure()
self.monitor.record_failure(endpoint, str(e))
if attempt < self.retry_count:
delay = self.retry_delay * (2 ** attempt) # 指数退避
await asyncio.sleep(delay)
else:
# 所有重试都失败
await self._handle_final_failure(message, endpoint, e)
return False
return False
async def reliable_broadcast(self, message: Message, endpoints: List[str]) -> dict:
"""可靠广播"""
results = {}
# 为消息生成唯一ID用于去重
message.id = self._generate_message_id(message)
# 检查是否已处理过
if self.message_deduplicator.is_duplicate(message.id):
return {"status": "duplicate", "reason": "Message already processed"}
async def send_to_endpoint(endpoint: str):
try:
success = await self.send_with_retry(message, endpoint)
return endpoint, success, None
except Exception as e:
return endpoint, False, str(e)
# 并发发送到所有端点
tasks = [send_to_endpoint(ep) for ep in endpoints]
completed = await asyncio.gather(*tasks, return_exceptions=True)
# 收集结果
for result in completed:
if isinstance(result, tuple) and len(result) == 3:
endpoint, success, error = result
results[endpoint] = {
"success": success,
"error": error
}
# 检查是否达到法定人数
success_count = sum(1 for r in results.values() if r["success"])
quorum = len(endpoints) // 2 + 1
overall_success = success_count >= quorum
if overall_success:
# 标记消息为已处理
self.message_deduplicator.record_message(message.id)
return {
"overall_success": overall_success,
"success_count": success_count,
"quorum_required": quorum,
"detailed_results": results
}5.5 性能监控与调优
python
class PerformanceMonitor:
"""性能监控器"""
def __init__(self):
self.metrics = {
"message_rates": {
"incoming": [],
"outgoing": [],
"processed": []
},
"latencies": {
"send": [],
"receive": [],
"processing": []
},
"queue_sizes": {
"input": [],
"output": [],
"retry": []
},
"error_rates": {
"send_errors": 0,
"receive_errors": 0,
"processing_errors": 0
}
}
self.start_time = time.time()
def record_message_sent(self, message_size: int, latency: float):
"""记录消息发送"""
now = time.time()
self.metrics["message_rates"]["outgoing"].append((now, 1))
self.metrics["latencies"]["send"].append(latency)
def record_message_received(self, message_size: int, latency: float):
"""记录消息接收"""
now = time.time()
self.metrics["message_rates"]["incoming"].append((now, 1))
self.metrics["latencies"]["receive"].append(latency)
def record_processing_time(self, processing_time: float):
"""记录处理时间"""
now = time.time()
self.metrics["message_rates"]["processed"].append((now, 1))
self.metrics["latencies"]["processing"].append(processing_time)
def get_performance_report(self, window_seconds: int = 60) -> dict:
"""获取性能报告"""
now = time.time()
window_start = now - window_seconds
report = {}
# 计算消息率
for rate_type, data in self.metrics["message_rates"].items():
recent = [(t, count) for t, count in data if t >= window_start]
if recent:
total = sum(count for _, count in recent)
rate = total / window_seconds
report[f"{rate_type}_rate"] = rate
# 计算延迟统计
for latency_type, data in self.metrics["latencies"].items():
if data:
recent = [lat for lat in data[-1000:]] # 最近1000个样本
report[f"{latency_type}_latency"] = {
"mean": np.mean(recent) if recent else 0,
"median": np.median(recent) if recent else 0,
"p95": np.percentile(recent, 95) if recent else 0,
"p99": np.percentile(recent, 99) if recent else 0,
"max": max(recent) if recent else 0
}
# 系统负载
import psutil
report["system_load"] = {
"cpu_percent": psutil.cpu_percent(),
"memory_percent": psutil.virtual_memory().percent,
"network_io": psutil.net_io_counters()._asdict()
}
return report
def detect_bottlenecks(self) -> List[str]:
"""检测性能瓶颈"""
bottlenecks = []
report = self.get_performance_report(60)
# 检查消息率
incoming_rate = report.get("incoming_rate", 0)
processed_rate = report.get("processed_rate", 0)
if incoming_rate > 0 and processed_rate / incoming_rate < 0.8:
bottlenecks.append("处理速度跟不上接收速度")
# 检查延迟
processing_latency = report.get("processing_latency", {})
if isinstance(processing_latency, dict) and processing_latency.get("p95", 0) > 0.1:
bottlenecks.append(f"处理延迟过高: {processing_latency['p95']:.3f}s")
# 检查队列大小
for queue_name, sizes in self.metrics["queue_sizes"].items():
if sizes:
avg_size = np.mean(sizes[-100:]) if len(sizes) >= 100 else np.mean(sizes)
if avg_size > 1000:
bottlenecks.append(f"队列 {queue_name} 积压: {avg_size:.0f} 条消息")
return bottlenecks6. 总结与展望
6.1 技术总结
本文深入探讨了雷达电子战仿真中的通信需求与Python实现挑战,主要成果包括:
-
需求分析:明确了雷达电子战仿真的通信特性,包括高实时性、大数据量、分布式协调等需求
-
技术方案:提出了基于Python的通信架构,结合ZeroMQ、gRPC、异步编程等技术
-
性能优化:针对Python性能瓶颈,提出了JIT编译、内存优化、并发编程等解决方案
-
架构设计:设计了分层、模块化、可扩展的通信系统架构
6.2 实践经验
-
选择合适的通信模式:根据数据特性和实时性要求选择点对点、发布-订阅或请求-响应模式
-
优化序列化性能:MessagePack在性能和可读性之间提供了良好的平衡
-
利用异步编程:asyncio在处理高并发I/O时表现出色
-
JIT编译加速计算:Numba对数值计算密集型任务有显著加速效果
6.3 后续展望
-
AI/ML集成:将机器学习算法集成到雷达信号处理和电子对抗中
-
云原生架构:基于Kubernetes的微服务架构,提高系统弹性和可扩展性
-
硬件加速:利用FPGA、GPU等硬件加速特定计算任务
-
标准化协议:推动雷达电子战仿真通信协议的标准化
6.4 系列预告
下一篇将深入探讨ZeroMQ在分布式雷达仿真中的应用,包括:
-
ZeroMQ的多种通信模式详解
-
大规模仿真系统中的ZeroMQ架构设计
-
性能调优和故障排除
-
实际案例:基于ZeroMQ的雷达告警接收机仿真