一、RNN
1.1 前言
对于序列类型数据(如:如文本、语音、股票、时间序列等数据)即当前数据内容与前面的数据有关,对于这类数据传统神经网络无法训练出具有顺序的数据,因为模型搭建时没有考虑数据上下之间的关系。
那么对于这类数据有没有一种更好的方案呢?RNN
1.2 RNN简介
在处理序列输入时具有记忆性 ,可以保留之前输入的信息并继续作为后续输入的一部分进行计算。
RNN的特点:
引入了隐状态h的概念,隐状态h可以对序列类形的数据提取特征,接着再转换为输出。
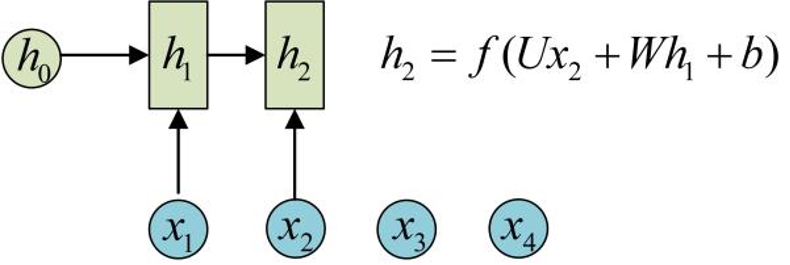
h1的计算:
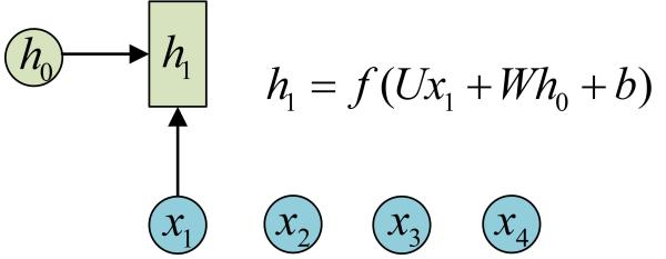
基于上一个隐藏层的状态
 和当前的输入
和当前的输入 计算得来,总结一下即
计算得来,总结一下即,而这里的𝑓一般是tanh、sigmoid、ReLU等非线性的激活函数
h2的计算:
这里需要注意:
1、在计算时,每一步使用的参数U、W、b都是一样的,也就是说每个步骤的参数都是共享的,这是RNN的重要特点;
2、下文的LSTM和GRU中的权值则不共享。
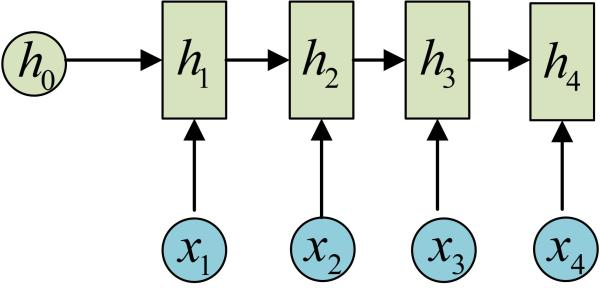
依次类推(使用相同的参数U、W、b):
这里为了方便,只画出序列长度为4的情况,实际上,这个计算过程可以无限地持续下去。
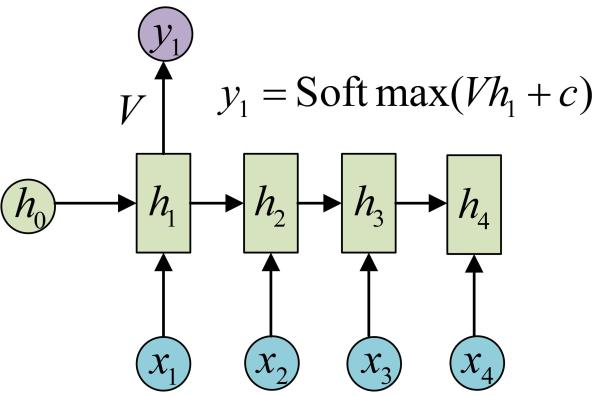
y1输出:
同理,依次类推:
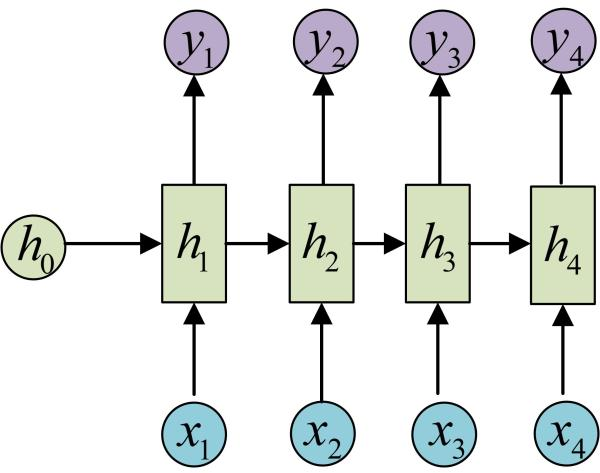
在此过程中,需要注意:
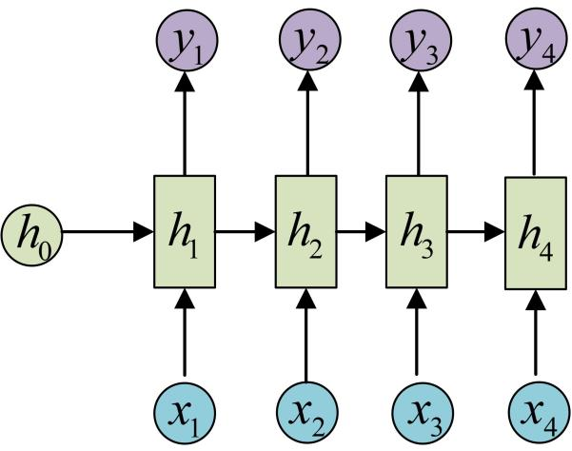
RNN结构中输入是x1, x2, .....xn,输出为y1, y2, ...yn,也就是说,输入和输出序列必须要是等长的
1.3 RNN的应用
RNN可以被看做是同一神经网络的多次复制,每个神经网络模块会把消息传递给下一个。所以,如果我们将这个循环展开:
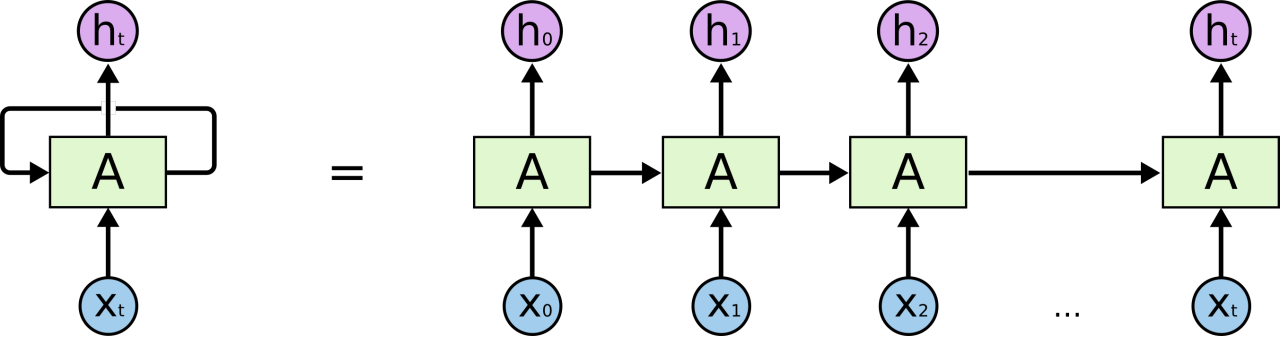
链式的特征揭示了RNN本质上是与序列和列表相关的,它们是对于这类数据的最自然的神经网络架构。
1.4 RNN的局限
上文提到RNN网络可以根据历史数据,推测当前数据,但是存在一个问题:历史数据中的相关信息与此处推测位置的数据相距不能过大。如果相距过大,RNN会丧失学习到连接如此远的信息的能力。即在实际上,RNN无法处理长期依赖问题。
原因:梯度会随着时间的推移不断下降减少,而当梯度值变得非常小时,就不会继续学习。
示例:
当出现"我的职业是程序员,...(此处省略10000字),我最擅长的是电脑"。当需要预测最后的词"电脑"。当前的信息建议下一个词可能是一种技能,但是如果我们需要弄清楚是什么技能,需要先前提到的离当前位置很远的"职业是程序员"的上下文。这说明相关信息和当前预测位置之间的间隔就变得相当的大。
那么该怎么缓解这个问题呢?LSTM/GRU
二、LSTM
2.1 LSTM简介
是一种RNN特殊的类型,可以学习长期依赖信息 。大部分与RNN模型相同,但它们用了不同的函数来计算隐状态。
LSTM网络可以学习只保留相关信息 来进行预测,并忘记不相关的数据。通俗来说:因记忆能力有限,记住重要的,忘记无关紧要的。
注意:
LSTM通过刻意的设计来避免长期依赖问题。记住长期的信息在实践中是LSTM的默认行为,而非需要付出很大代价才能获得的能力!
2.2 与RNN在网络结构上的区别
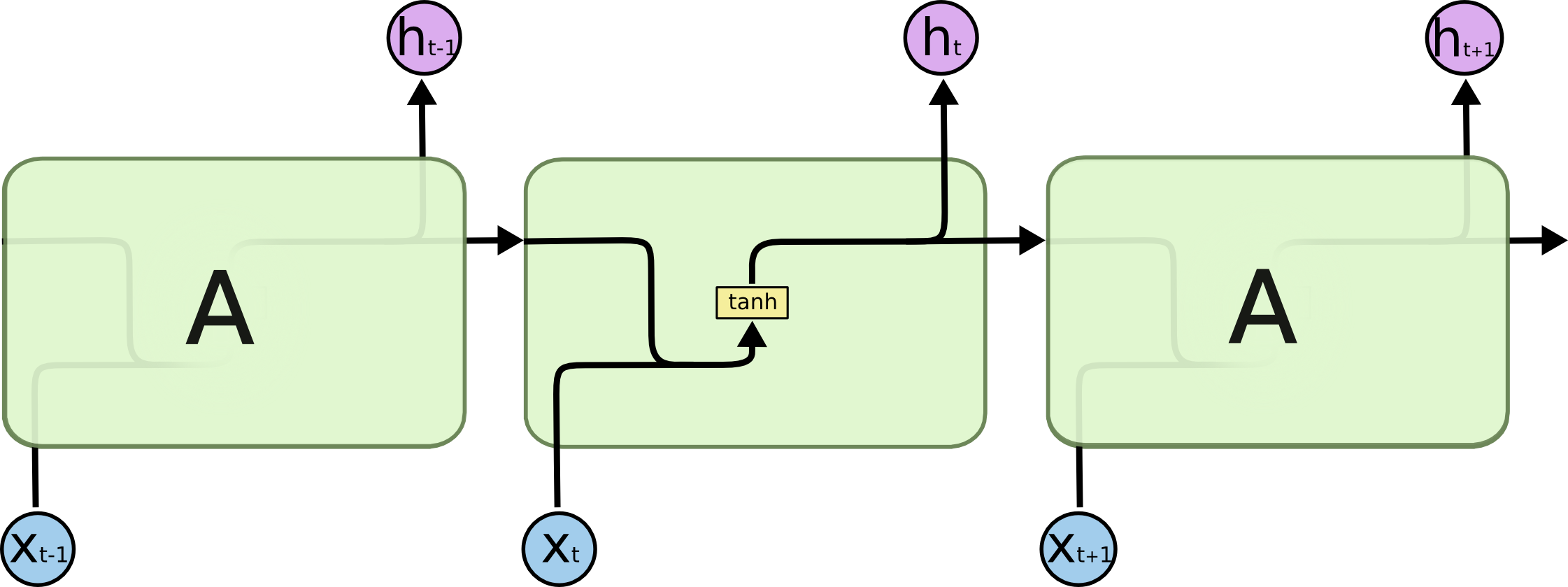
2.2.1 RNN的网络结构
所有RNN都具有一种重复神经网络模块的链式的形式。在标准的RNN中,这个重复的 模块只有一个非常简单的结构,例如一个tanh层。
2.2.2 LSTM的网络结构
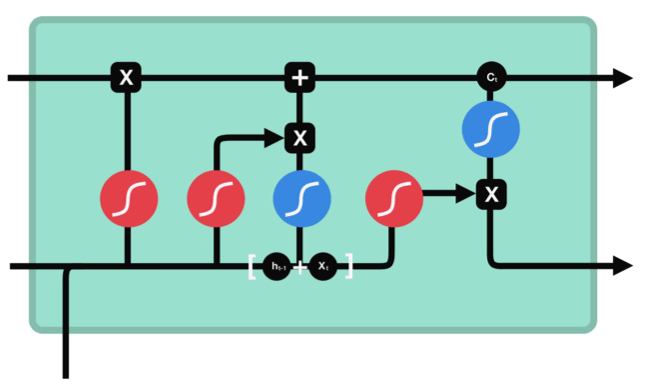
LSTM同样是这样的结构,但是重复的模块拥有一个不同的结构。具体来说,RNN是重复单一的神经网络层,LSTM中的重复模块则包含四个交互的层,三个Sigmoid 和一个tanh层,并以一种非常特殊的方式进行交互。
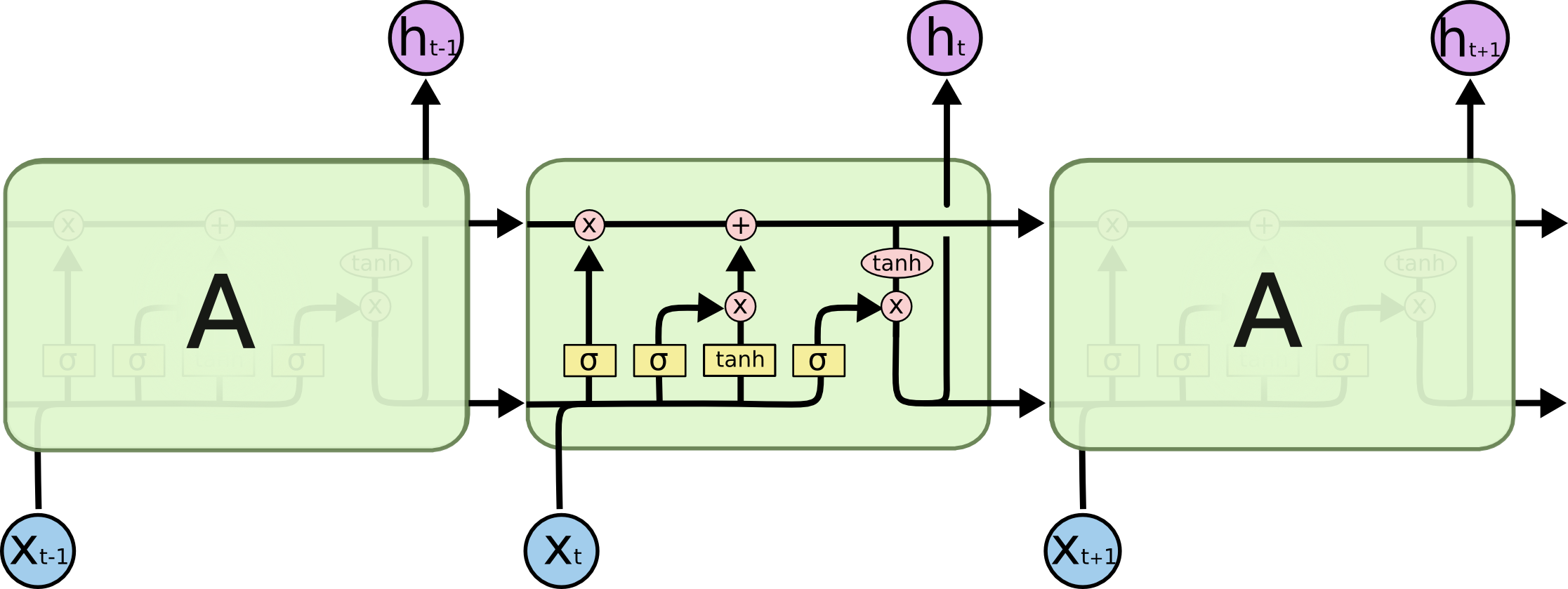
上图中,σ表示的Sigmoid 激活函数与 tanh 函数类似,不同之处在于 sigmoid 是把值压缩到0~1 之间而不是 -1~1 之间。这样的设置有助于更新或忘记信息:
1、因为任何数乘以 0 都得 0,这部分信息就会剔除掉;
2、同样的,任何数乘以 1 都得到它本身,这部分信息就会完美地保存下来
即相当于要么是1则记住,要么是0则忘掉,所以还是这个原则:因记忆能力有限,记住重要的,忘记无关紧要的。
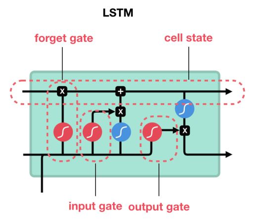
2.3 LSTM的核心思想
LSTM有通过精心设计的称作为"门"的结构来去除或者增加信息到细胞状态的能力。门是一种让信息选择式通过的方法。他们包含一个sigmoid神经网络层和一个pointwise乘法的非线性操作。
如此,0代表"不许任何量通过",1就指"允许任意量通过"!从而使得网络就能了解哪些数据是需要遗忘,哪些数据是需要保存。

2.4 LSTM的分类
2.4.1 遗忘门
功能:决定应丢弃哪些关键词信息。
步骤:
在LSTM中的第一步是决定我们会从细胞状态中丢弃什么信息。这个决定通过一个称为"忘记门"的结构完成。该忘记门会读取上一个输出和当前输入,做一个Sigmoid 的非线性映射,然后输出一个向量(该向量每一个维度的值都在0到1之间,1表示完全保留,0表示完全舍弃,相当于记住了重要的,忘记了无关紧要的),最后与细胞状态相乘。
如下图:红圈表示Sigmoid 激活函数,蓝圈表示tanh 函数
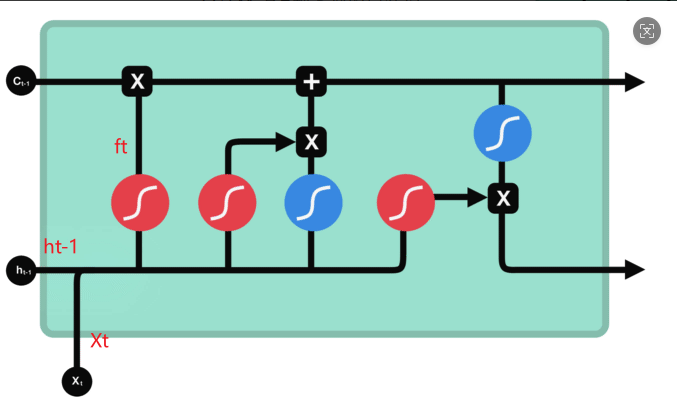
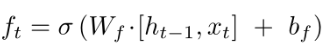
对于上图公式:
权值 ,是不共享,即是不一样的,即:
,是不共享,即是不一样的,即:
2.4.2 输入门
功能:用于更新细胞状态。
这里包含两个部分:
第一,sigmoid层称"输入门层"决定什么值我们将要更新;
第二,一个tanh层创建一个新的候选值向量,会被加入到状态中
步骤:
1、首先将前一层隐藏状态的信息和当前输入的信息传递到 sigmoid 函数中去。将值调整到 0~1 之间来决定要更新哪些信息。0 表示不重要,1 表示重要。
2、将前一层隐藏状态的信息和当前输入的信息传递到 tanh 函数中去,创造一个新的侯选值向量。最后将 sigmoid 的输出值与 tanh 的输出值相乘,sigmoid 的输出值将决定 tanh 的输出值中哪些信息是重要且需要保留下来的。
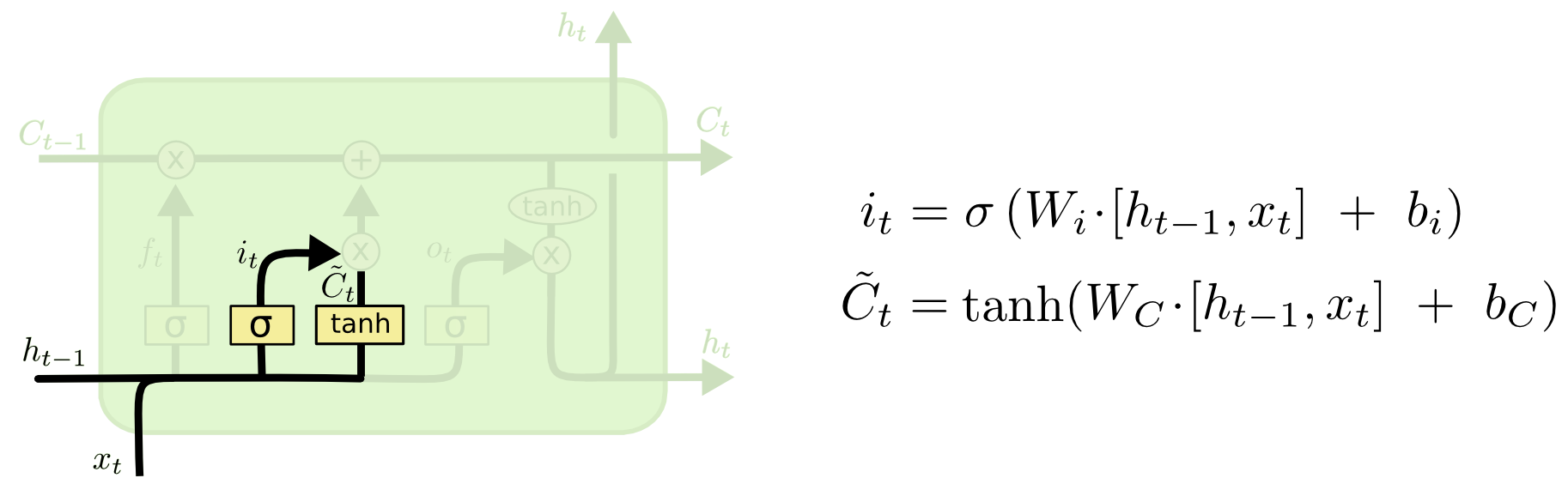
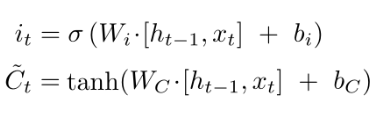
上图公式:
 、
、
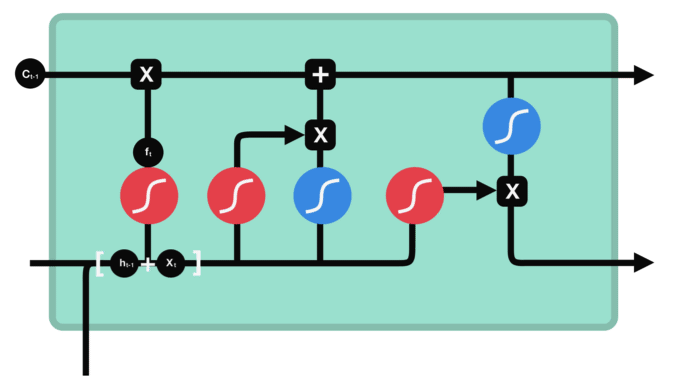
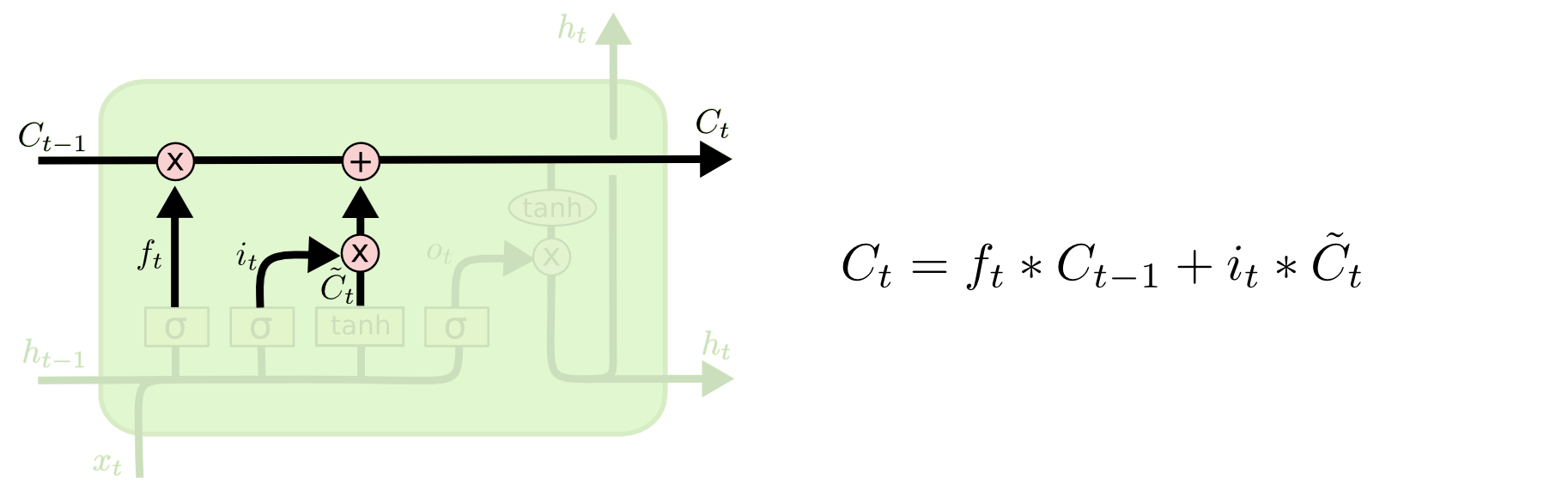
2.4.3 更新细胞状态
更新为
。前面的步骤已经决定了将会做什么,我们现在就是实际去完成把旧状态与
相乘,丢弃掉我们确定需要丢弃的信息,接着加上
。这就是新的候选值,根据我们决定更新每个状态的程度进行变化
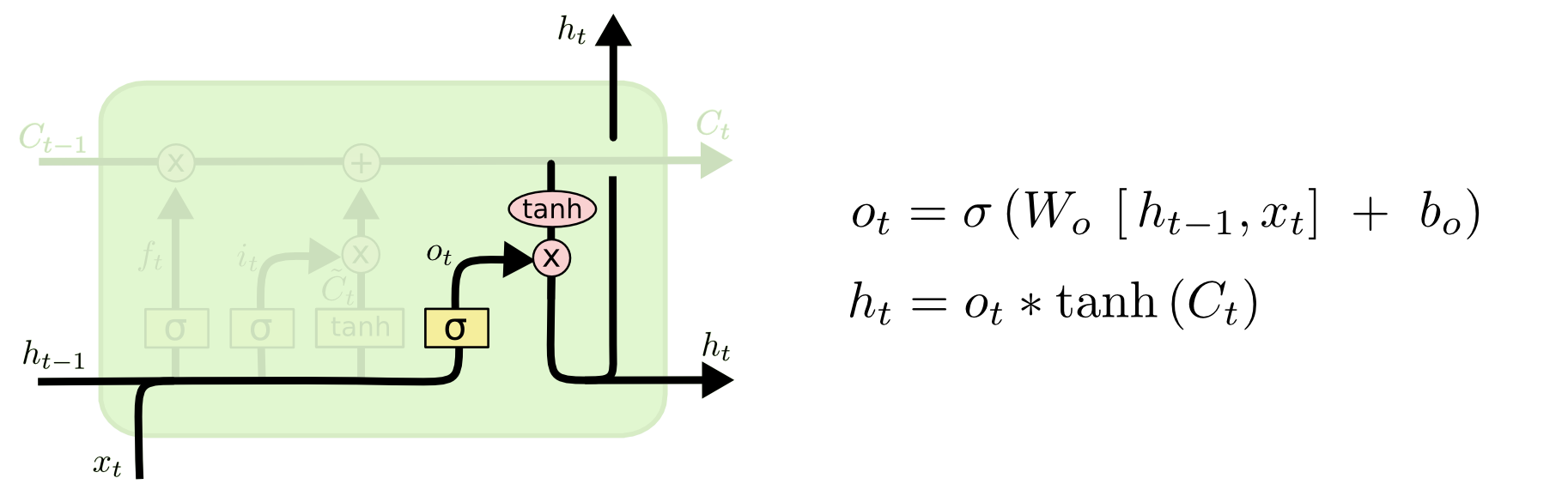
2.4.4 输出门
功能:用来确定下一个隐藏状态的值。
步骤:
1、将前一个隐藏状态和当前输入传递到 sigmoid 函数中,然后将新得到的细胞状态传递给 tanh 函数。
2、将 tanh 的输出与 sigmoid 的输出相乘,以确定隐藏状态应携带的信息。再将隐藏状态作为当前细胞的输出,把新的细胞状态和新的隐藏状态传递到下一个时间步长中去。