LSTM实战:遗忘门、输入门与输出门解决长期依赖
本文是上篇《Word2Vec与CBOW算法实战》的续篇 。上篇解决了"如何用词向量表示词语"的问题,但还有一个关键问题没解决:如何让模型理解前后词语之间的关联关系? 这就是 RNN 到 LSTM 要解决的问题。
一、为什么RNN无法处理长期依赖
1.1 RNN的基本结构
RNN(循环神经网络)的核心思想是:每个时间步的隐藏状态不仅取决于当前输入,还取决于上一时间步的隐藏状态。
x(t) ──→ [U] ──┐
├──→ [激活] ──→ h(t) ──→ y(t)
h(t-1) ─→ [W] ──┘RNN 的三个特点:
- 每个时间步使用的参数 U、W、b 都是共享的,这是 RNN 的重要特点
- 引入隐状态 h(hidden state)来提取序列特征
- 输入和输出序列必须等长
1.2 RNN 的致命缺陷:梯度消失
问题来源:
"当出现'我的职业是程序员,...,我最擅长的是电脑'。需要预测最后的词'电脑',需要先前提到的'职业是程序员'的上下文。相关信息和当前预测位置之间的间隔相当大。"
根本原因:
反向传播时,梯度需要从时间步 t 传回到时间步 1。每经过一个时间步,梯度就要乘以参数 W。当 W<1 时:
梯度 = W^n × 初始梯度 → 随着 n 增大,趋近于 0这就是梯度消失(Vanishing Gradient):距离越远,早期信息对当前预测的影响越弱,最终完全消失。
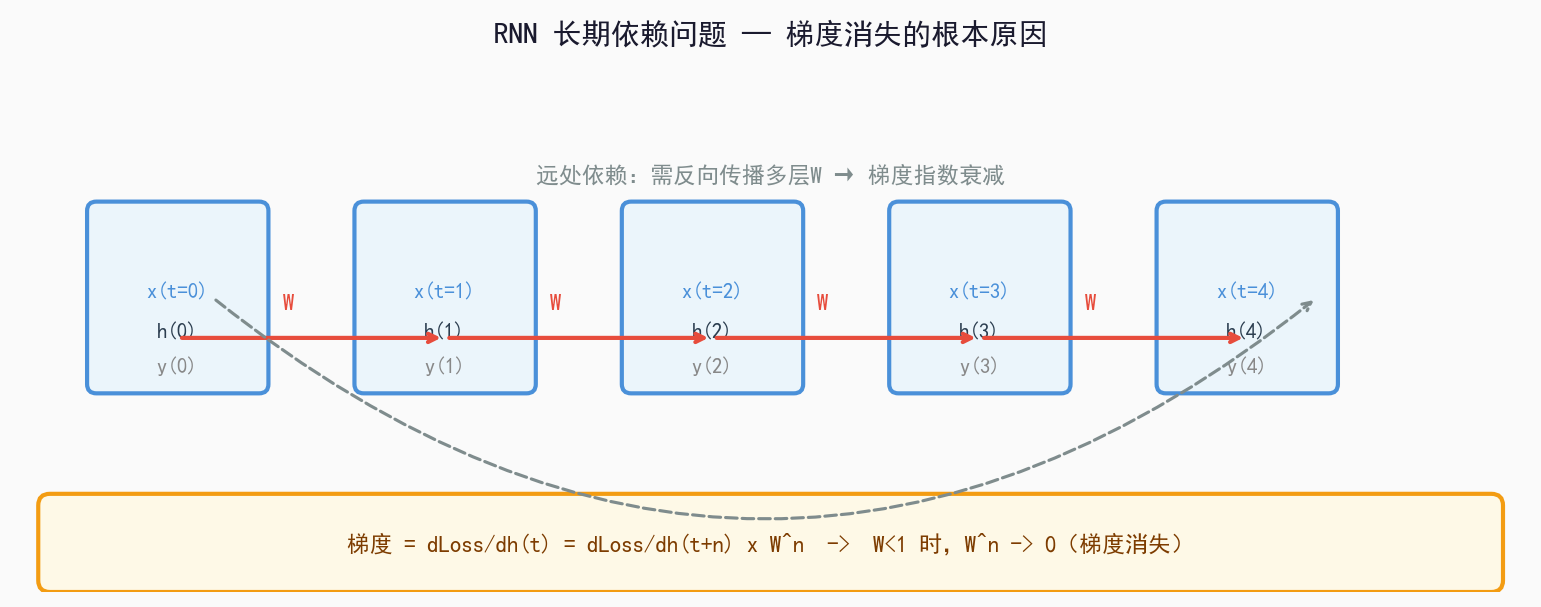
图解:虚线箭头表示远处词语的信息传递,随着距离增加,梯度指数衰减,导致 RNN 只能记住短期依赖,无法捕捉长序列中的语义关联。
二、LSTM登场:选择性记忆的解决方案
2.1 LSTM的核心思想
LSTM(Long Short-Term Memory Network,长短时记忆网络) 由 Sepp Hochreiter 和 Jürgen Schmidhuber 于 1997 年提出,专门解决 RNN 的长期依赖问题。
生动比喻:
"当你想在网上购买生活用品时,会查看用户评价。大脑下意识记住'好看'、'真酷'等关键词,而不关心'我'、'也'、'是'等字样。第二天你问评价说了什么,你不可能会全部记住,而是说出大脑里记得的主要观点,比如'下次肯定还会来买'。"
LSTM 的核心思想:记忆能力有限,记住重要的,忘记无关紧要的。
2.2 LSTM vs RNN 的根本区别
| 区别 | RNN | LSTM |
|---|---|---|
| 信息传递方式 | 仅隐状态 h(t) | 隐状态 h(t) + 细胞状态 C(t) |
| 门控机制 | 无 | 有(3个门) |
| 长期依赖 | ❌ 无法处理 | ✅ 通过门控选择性地传递 |
| 梯度消失 | 严重 | 通过门控机制缓解 |
三、LSTM核心:三大门机制
LSTM 引入了**门(Gate)**的概念,每个门是一个神经网络层,输出 0~1 之间的值,控制信息流动的比例。
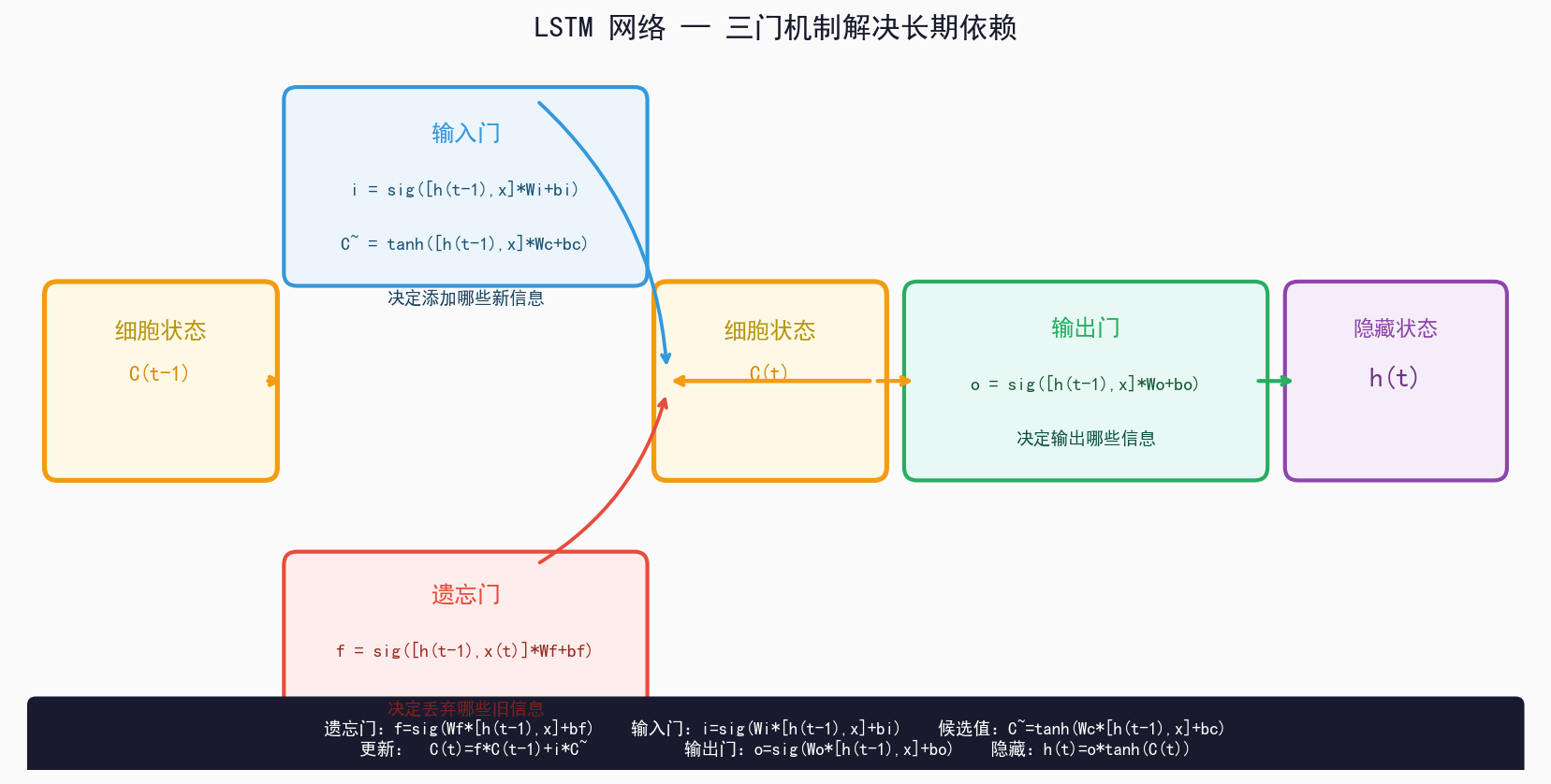
3.1 遗忘门(Forget Gate)
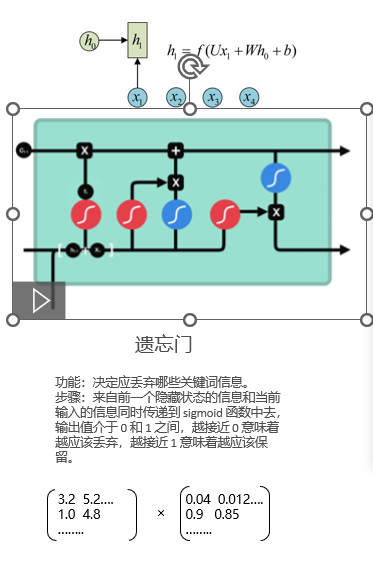
功能 :决定从上一个细胞状态中丢弃哪些信息。
f = σ(Wf · [h(t-1), x(t)] + bf)- 将 h(t-1) 和 x(t) 同时传入 sigmoid 层
- 输出 f ∈ 0, 1:0 表示完全丢弃,1 表示完全保留
- 例如:当新输入是新的主语时,遗忘门会降低旧主语相关信息的权重
3.2 输入门(Input Gate)
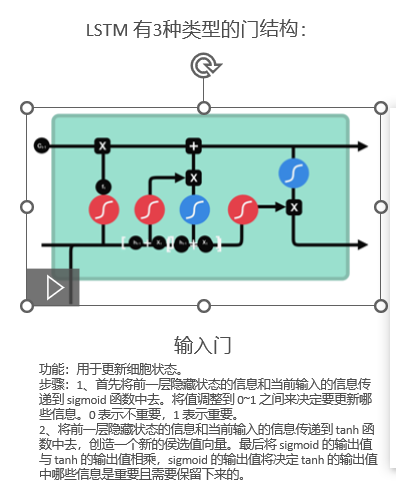
功能 :决定向细胞状态中添加哪些新信息。
分为两步:
第一步:候选值生成
C~ = tanh(Wc · [h(t-1), x(t)] + bc)
第二步:决定更新哪些
i = σ(Wi · [h(t-1), x(t)] + bi)- sigmoid 输出 i ∈ 0, 1:决定候选值中哪些值得保留
- tanh 输出 -1~1:生成候选值向量
- 两者的乘积才是真正添加到细胞状态的新信息
3.3 细胞状态更新
C(t) = f * C(t-1) + i * C~- f * C(t-1):遗忘门控制,丢弃旧信息
- i * C~:输入门控制,添加新候选信息
- 这就是 LSTM 的核心公式:选择性遗忘 + 选择性记忆
3.4 输出门(Output Gate)
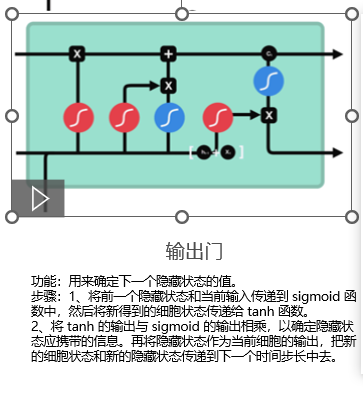
功能 :决定当前隐藏状态 h(t) 中输出哪些信息。
o = σ(Wo · [h(t-1), x(t)] + bo)
h(t) = o * tanh(C(t))- tanh 将细胞状态压缩到 -1, 1,突出重要信息
- o 控制输出比例,生成最终的隐藏状态 h(t)
- h(t) 即为当前时间步的输出向量
四、LSTM完整前向传播时序图
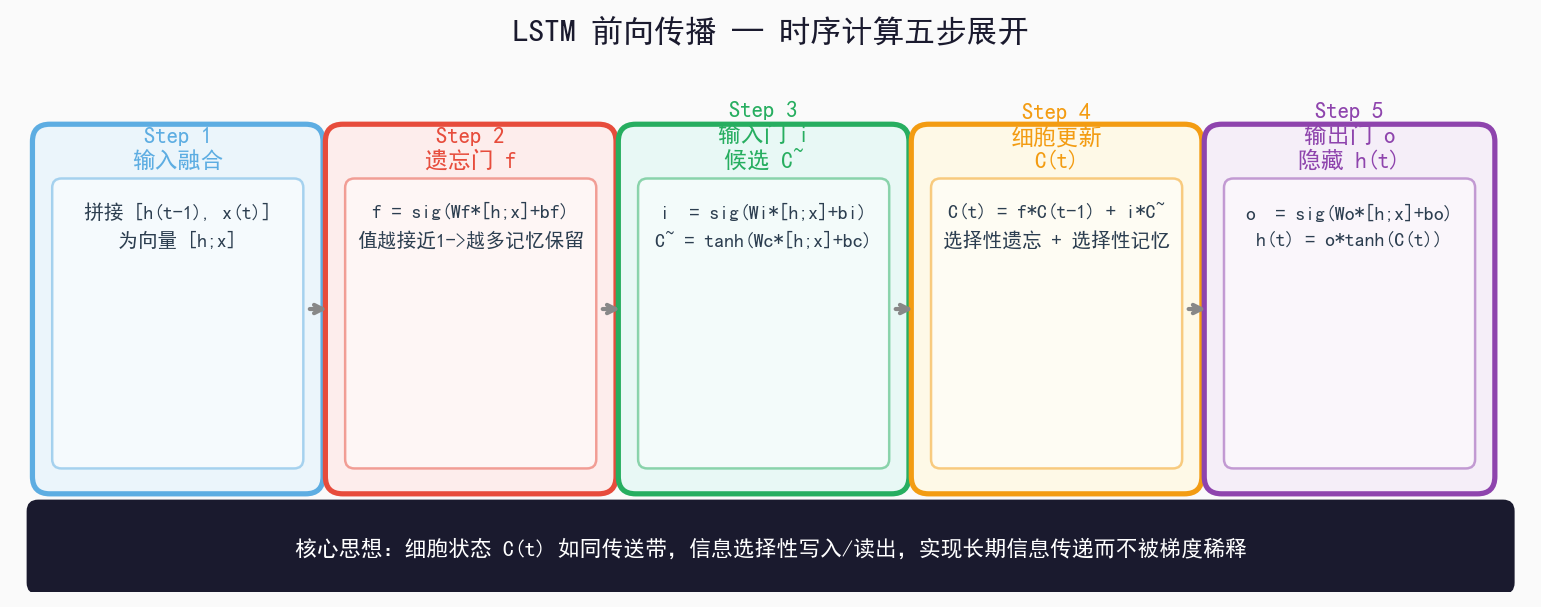
LSTM 核心思想:选择性遗忘 + 选择性记忆 = 长期依赖的精准控制
五、RNN vs LSTM vs GRU 深度对比
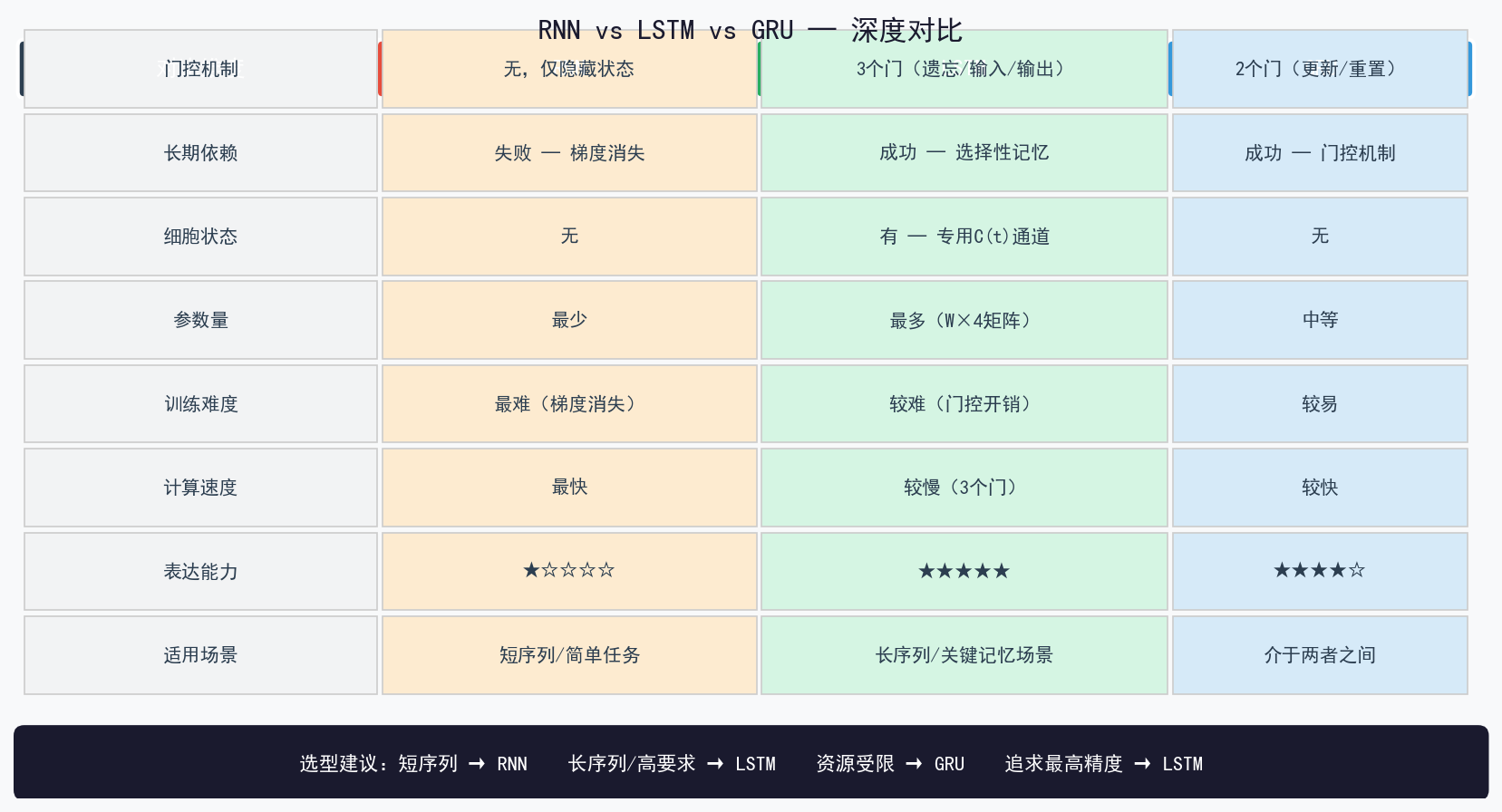
核心对比
| 特性 | RNN | LSTM | GRU |
|---|---|---|---|
| 门控机制 | 无 | 3个门(遗忘/输入/输出) | 2个门(更新/重置) |
| 长期依赖 | ❌ 梯度消失 | ✅ 门控选择记忆 | ✅ 门控处理 |
| 细胞状态 | ❌ 无 | ✅ 专有细胞状态 C(t) | ❌ 无 |
| 参数量 | 最少 | 最多(W×4矩阵) | 中等 |
| 训练难度 | 最难(梯度消失) | 较难(门控计算开销大) | 较易(结构简单) |
| 适用场景 | 短序列、简单模式 | 长序列、需长期记忆 | 性能接近LSTM,资源受限 |
| 推理速度 | 最快 | 较慢(3个门计算) | 较快 |
| 表达能力 | ★☆☆☆☆ | ★★★★★ | ★★★★☆ |
一句话选型
短序列 → RNN ,长序列 → LSTM ,资源受限 → GRU ,综合最优 → LSTM。
六、LSTM典型应用场景
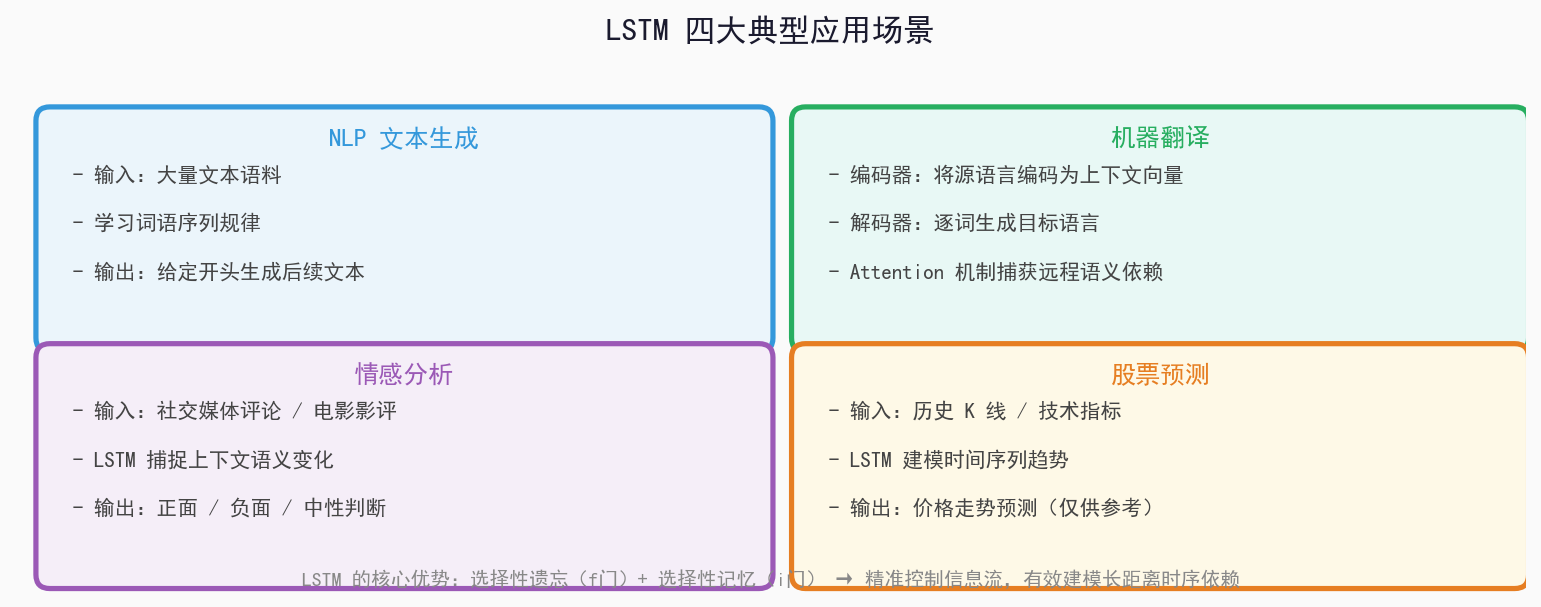
| 应用 | 说明 | 示例 |
|---|---|---|
| NLP 文本生成 | 根据前文预测下一个词 | 输入"今"→输出"天"→输出"气"... |
| 机器翻译 | 编码器LSTM读取源语言,解码器LSTM生成目标语言 | "I love China" → "我爱中国" |
| 情感分析 | 捕捉评论中的情感倾向 | "太好吃了,下次还来" → 正面(0.92) |
| 股票预测 | 捕捉时序数据中的长期趋势 | p(t-7)...p(t) → p(t+1) |
七、总结与扩展
LSTM 的本质
LSTM = RNN + 三大门
= 信息传递通道 × 三个信息过滤器
= 遗忘门(选择性丢弃) + 输入门(选择性添加) + 输出门(选择性输出)核心优势 :通过门控机制,LSTM 解决了 RNN 的梯度消失问题,能够选择性记忆 长期信息,同时自动遗忘无关信息。
扩展方向
| 方向 | 说明 |
|---|---|
| GRU | LSTM 的简化版,只有 2 个门,参数量更少,效果接近 LSTM |
| 双向LSTM(Bi-LSTM) | 同时考虑前向和后向上下文,效果更好 |
| 多层LSTM | 堆叠多层 LSTM,提取更高级的语义特征 |
| 注意力机制 | Transformer 的核心,让模型自动关注重要信息 |
| Seq2Seq | 编码器-解码器架构,机器翻译、对话生成的基础 |