目录
题目
如何得到一个数据流中的中位数?如果从数据流中读出奇数个数值,那么中位数就是所有数值排序之后位于中间的数值。如果从数据流中读出偶数个数值,那么中位数就是所有数值排序之后中间两个数的平均值。我们使用Insert()方法读取数据流,使用GetMedian()方法获取当前读取数据的中位数。
数据范围:数据流中数个数满足 1≤𝑛≤1000 1≤n≤1000 ,大小满足 1≤𝑣𝑎𝑙≤1000 1≤val≤1000
进阶: 空间复杂度 𝑂(𝑛) O(n) , 时间复杂度 𝑂(𝑛𝑙𝑜𝑔𝑛) O(nlogn)
示例1
输入:
[5,2,3,4,1,6,7,0,8]复制返回值:
"5.00 3.50 3.00 3.50 3.00 3.50 4.00 3.50 4.00 "复制说明:
数据流里面不断吐出的是5,2,3...,则得到的平均数分别为5,(5+2)/2,3... 示例2
输入:
[1,1,1]复制返回值:
"1.00 1.00 1.00 "思路
建立一个 小顶堆 A 和 大顶堆 B ,各保存列表的一半元素,且规定:
A 保存 较大 的一半,长度为 N/2( N 为偶数)或 (N+1)/2( N 为奇数);
B 保存 较小 的一半,长度为 N/2( N 为偶数)或 (N−1)/2( N 为奇数);
随后,中位数可仅根据 A,B 的堆顶元素计算得到。
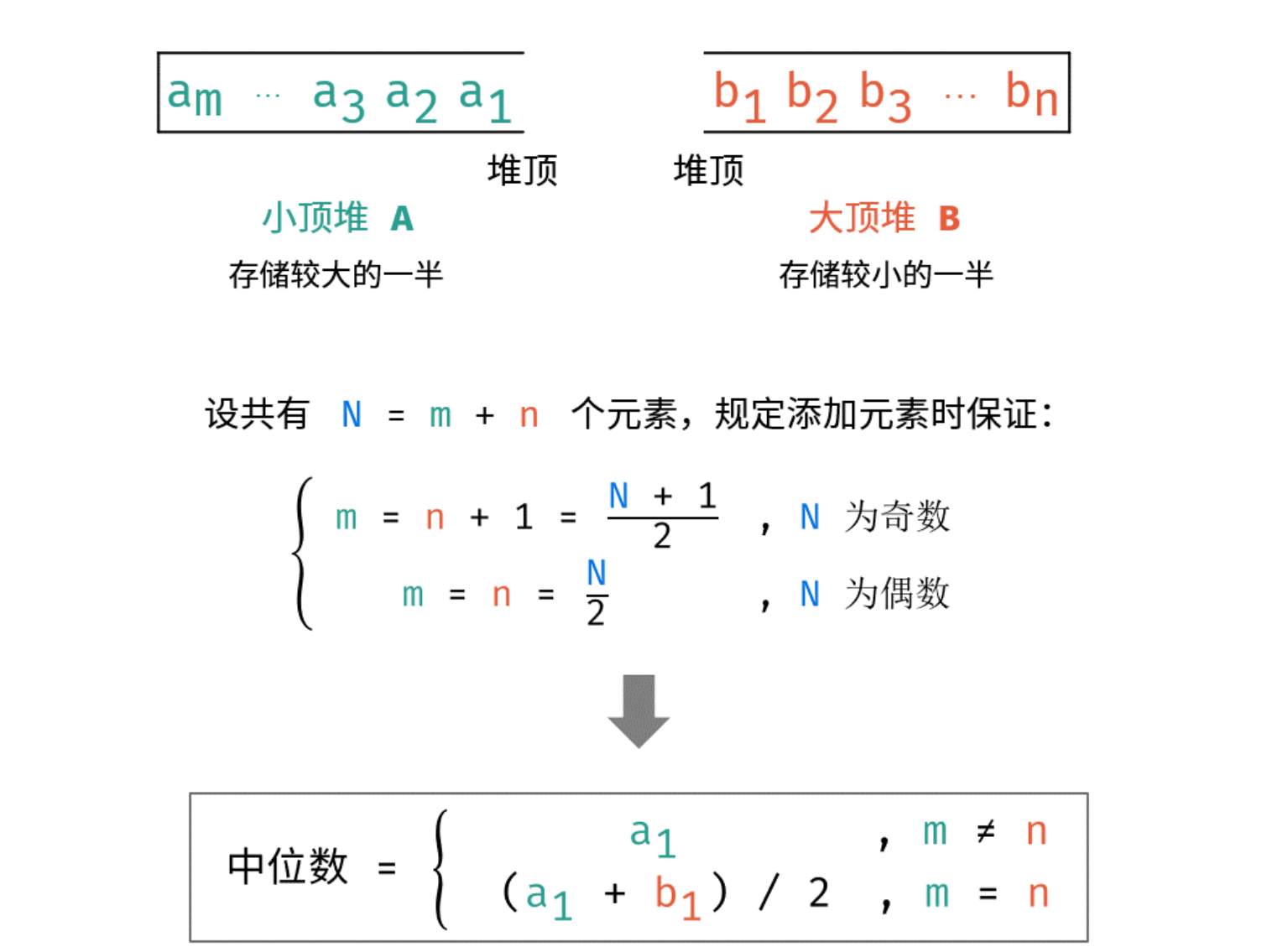
设元素总数为 N=m+n ,其中 m 和 n 分别为 A 和 B 中的元素个数。
addNum(num) 函数:
当 m=n(即 N 为 偶数):需向 A(存放的是大的) 添加一个元素。实现方法:将新元素 num 插入至 B ,再将 B 堆顶元素插入至 A (把大的顶过来) ;
当 m≠n(即 N 为 奇数):需向 B 添加一个元素(存放的是小的)。实现方法:将新元素 num 插入至 A ,再将 A 堆顶元素插入至 B ;
假设插入数字 num 遇到情况 :m=n 。由于 num 可能属于 "较小的一半" (即属于 B ),因此不能将 nums 直接插入至 A 。而应先将 num 插入至 B ,再将 B 堆顶元素插入至 A 。这样就可以始终保持 A 保存较大一半、 B 保存较小一半。
findMedian() 函数:
当 m=n( N 为 偶数):则中位数为 ( A 的堆顶元素 + B 的堆顶元素 )/2。
当 m≠n( N 为 奇数):则中位数为 A 的堆顶元素。
java代码
java
import java.util.*;
public class Solution {
Queue<Integer> a,b;
public Solution(){
a=new PriorityQueue<>();
b=new PriorityQueue<>((x,y) -> y-x);//递减
}
public void Insert(Integer num) {
if(a.size()!=b.size()){
a.add(num);
b.add(a.poll());
}else{
b.add(num);
a.add(b.poll());
}
}
public Double GetMedian() {
if(a.size()==b.size()){
return (a.peek()+b.peek())/2.0;
}else{
return a.peek()*1.0;
}
}
}python代码
python
# -*- coding:utf-8 -*-
from heapq import *
class Solution:
def __init__(self):
self.A=[]
self.B=[]
def Insert(self, num):
# write code here
if len(self.A) != len(self.B):
heappush(self.A, num)
heappush(self.B, -heappop(self.A))
else:
heappush(self.B, -num)
heappush(self.A, -heappop(self.B))
def GetMedian(self):
# write code here
return self.A[0] if len(self.A) != len(self.B) else (self.A[0] - self.B[0]) / 2.0python自带的heapq库中只有小顶堆,要实现大顶堆,只能取负,然后拿回来的时候再取正