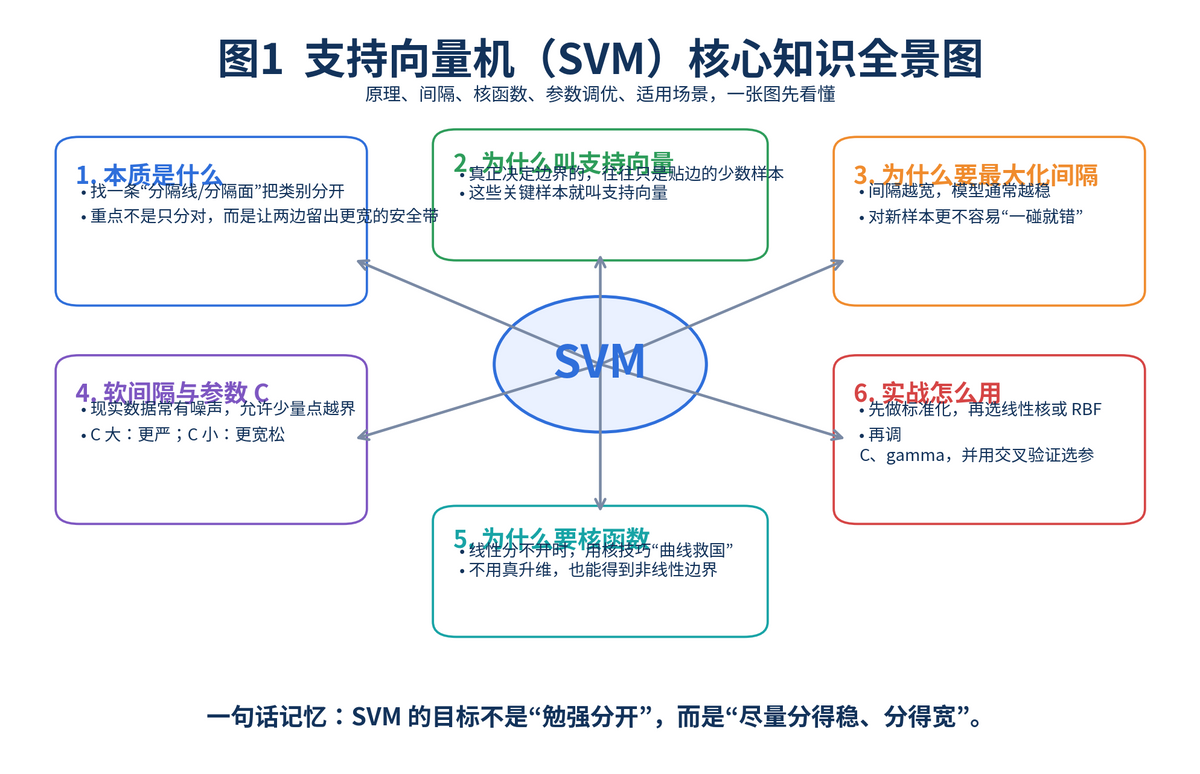
1. 什么是支持向量机(SVM)?
支持向量机本质上是一类监督学习方法,既能做分类,也能做回归,还能做异常检测。它最经典的用途,是在二分类任务里找到一条最合适的分界线,把两类样本尽量稳地分开。scikit-learn 的官方文档也把 SVM 明确归为可用于分类、回归和离群点检测的一组监督学习方法。
很多人第一次接触 SVM,会把它理解成"画一条线把两类分开"。这个理解只对了一半。SVM 真正厉害的地方,不是随便找一条能分开的线,而是找一条让两边都尽量留出更宽安全距离的边界。这个"安全距离",就是后面经常出现的"间隔"。
所以,面试里如果被问"简述 SVM 原理",最稳的说法是:SVM 通过寻找最大间隔超平面来实现分类,真正决定边界位置的是离边界最近的少数样本,也就是支持向量。
1.1 支持向量到底是什么?
支持向量不是"所有训练样本",而是最关键的那一小撮贴着边界的点。你可以把它理解为两边阵营里最靠前的士兵。SVM 在训练时,真正把边界顶出来的,往往就是这些点。其他离边界很远的点,即使删掉一些,对最终边界的影响也可能没那么大。
这也是 SVM 名字里"支持向量"的来源:不是数据量多就强,而是关键点把边界"支撑"住了。
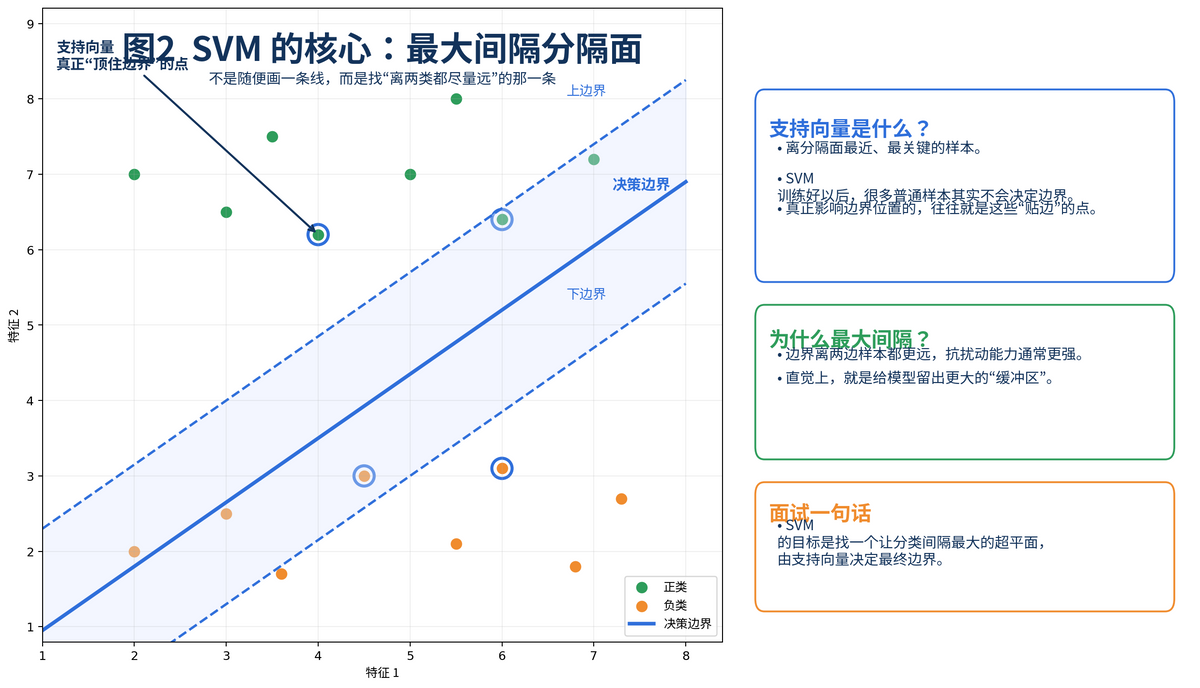
2. 为什么 SVM 要采用间隔最大化?
面试里这一问特别高频。很多人只会回答"因为效果更好",但这样太空了。更好的回答应该分三层:第一,间隔更宽,模型对输入扰动通常更不敏感;第二,它不只追求训练集分对,还追求边界更稳;第三,从泛化角度看,留出更大的缓冲区,往往意味着对新样本更友好。
直观地说,如果两种方案都能把训练数据分开,一种边界几乎贴着样本,另一种边界离两边都更远,你一般会更相信第二种。因为现实数据是有噪声的,稍微抖一下,贴边那条线就可能把新样本分错;而间隔更宽的那条边界,容错空间更大。
这也是为什么 SVM 不是简单追求"训练正确率 100%",而是更关注"边界质量"。在很多面试场景里,你完全可以把"最大间隔"解释成"给分类边界两侧留足安全带"。这个说法既通俗,又不失专业。
2.1 超平面是什么意思?
在二维平面里,超平面就是一条线;在三维空间里,它是一个平面;在更高维特征空间里,它就是一个更抽象的分隔面。面试时不用把这个概念说得太玄,直接说"超平面就是高维空间里的分界面"就够了。
3. 硬间隔、软间隔和参数 C 到底是什么关系?
最早的 SVM 假设数据是完全线性可分的,也就是可以找到一条边界,让所有正样本都在一侧、所有负样本都在另一侧,而且没有任何点越界。这叫硬间隔。
但真实业务数据几乎不可能这么干净:噪声点、异常值、标注错误、边界模糊,都会让"一个都不能错"的要求变得不现实。于是,SVM 引入了软间隔思想:允许少量样本越界或者被分错,但会对这种违规行为收取代价。
这时候,参数 C 就登场了。你可以把 C 理解成"对犯错有多敏感"。C 大,说明模型更不愿意看到训练集犯错,于是会努力把每个点都照顾到,边界可能更贴近训练数据;C 小,说明模型允许少量点犯错,换来更宽松、更平滑的边界。
所以,面试里被问"C 大小怎么理解",很适合用一句话回答:C 大时,模型更强调训练集少犯错;C 小时,模型更强调保留更宽的间隔和更强的泛化。
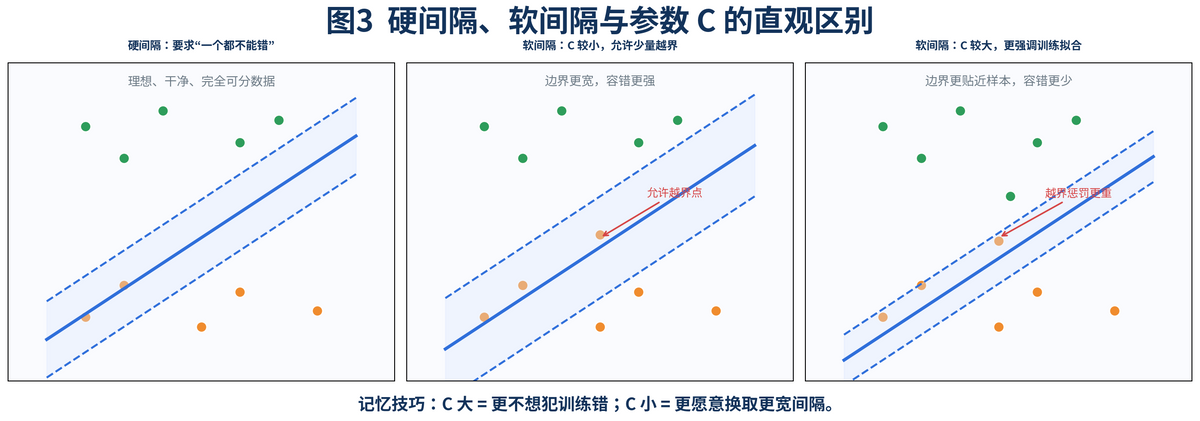
3.1 为什么 SVM 不是一味让 C 越大越好?
因为 C 太大时,模型可能为了照顾训练集里的个别噪声点,把边界拧得太紧,导致过拟合。相反,C 太小时,模型又可能过于宽松,出现欠拟合。所以 C 本质上是在"训练拟合"和"泛化稳健"之间找平衡。scikit-learn 的 SVM 示例也明确展示了:C 大时模型会更多关注靠近分界线的点,C 小时会把更多样本都纳入间隔考虑。
4. 为什么要引入核函数?
如果数据在线性空间里本来就能分开,那线性 SVM 就够用了。但很多业务问题并不是直线就能切开的。比如典型的 XOR 结构:你在二维平面里画一百条直线,也没法把两类完美分开。
这时,SVM 的思路不是死磕原空间,而是换一个更有利的观察角度。核函数的核心价值,就是让模型在不显式把所有样本真的搬到高维空间的情况下,仍然能够利用"高维可分"的效果。这就是人们常说的核技巧。
很多候选人一说核函数,就陷进复杂公式里。其实面试时更推荐这样解释:核函数本质上是一种相似度计算方式,它帮助 SVM 在原来分不开的情况下,间接得到更灵活的非线性边界。
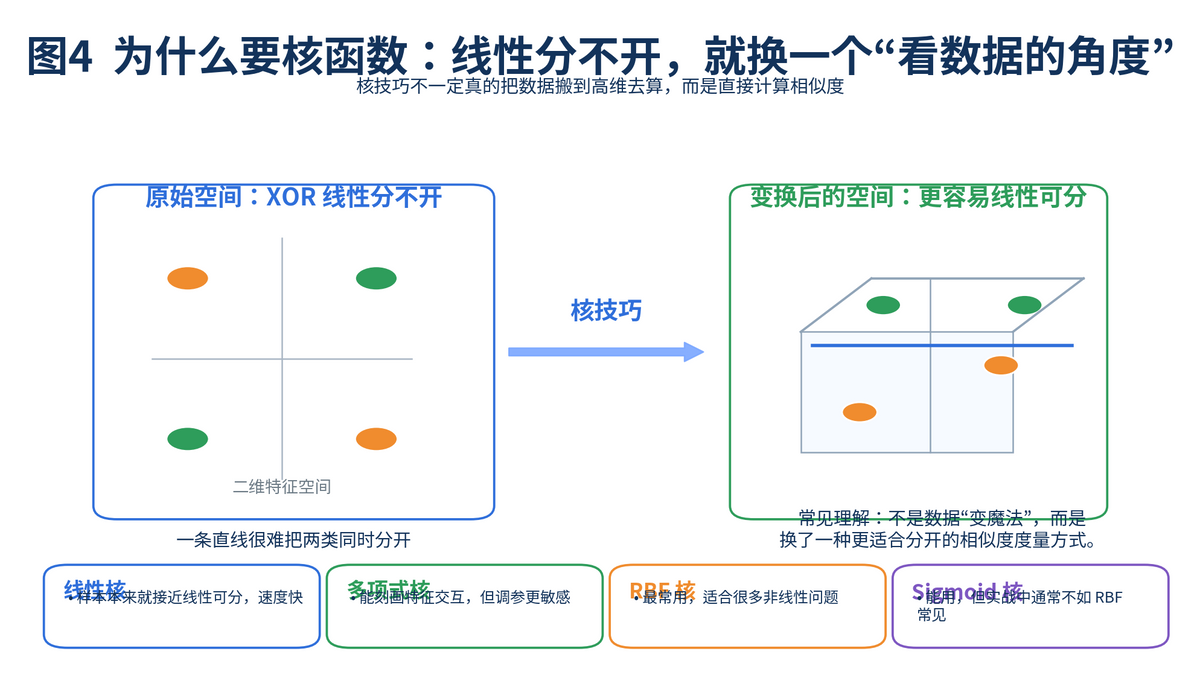
4.1 常见核函数有哪些?
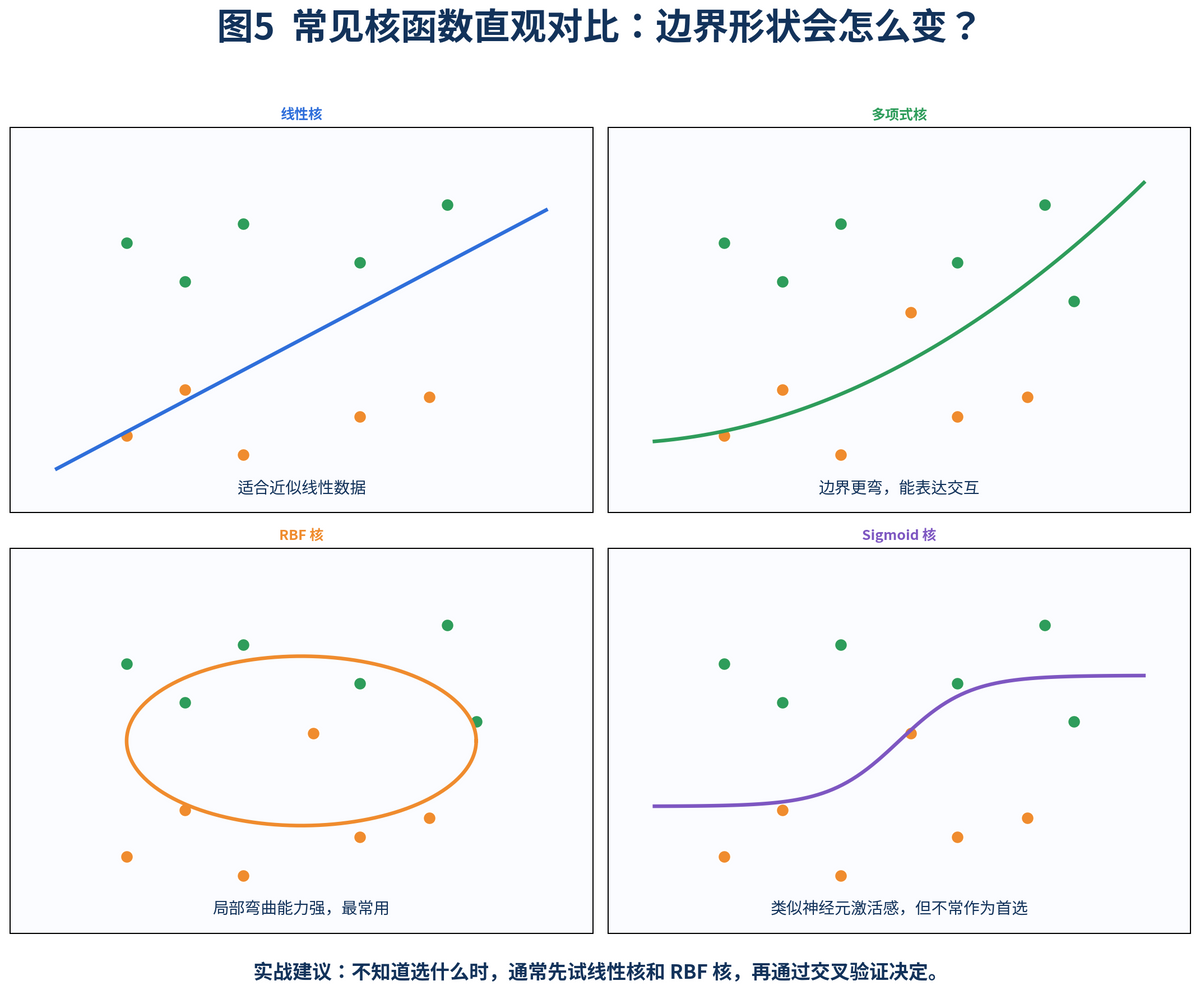
最常见的核函数有四类:线性核、多项式核、RBF 核和 Sigmoid 核。面试里最重要的是把它们的使用习惯讲清楚,而不是背公式。
• 线性核:适合本来就接近线性可分的数据,速度快,尤其适合高维稀疏文本场景。
• 多项式核:可以表达特征之间更复杂的交互关系,但参数更敏感,调不好容易不稳。
• RBF 核:最常用的非线性核,很多不知道怎么选核函数的场景,都会先试它。
• Sigmoid 核:也能用,但在实战中通常没有 RBF 那么常见。
scikit-learn 的 SVC 文档也列出了这些常见核函数,并指出默认核函数就是 RBF。
4.2 为什么很多人说 SVM 常常要用核函数?
因为真实世界里,很多分类边界本来就不是一条直线。你当然可以靠手工特征工程把问题改造成线性可分,但核函数相当于给模型提供了一条更省力的路。特别是在中小规模、边界具有明显非线性特征的问题上,RBF 核往往能给出非常有竞争力的效果。
4.3 gamma 又是什么?
如果说 C 决定"容错强弱",那 gamma 更像是在决定"每个样本的影响范围有多大"。gamma 大时,一个样本只会在自己附近产生很强影响,边界容易变得更弯、更局部;gamma 小时,单个样本影响范围更大,边界会更平滑。
所以在 RBF SVM 里,C 和 gamma 往往要一起看:一个控制惩罚力度,一个控制边界弯曲程度。很多调参失败,不是因为不懂 SVM,而是只调了 C,完全没管 gamma。
5. SVM 的优缺点怎么讲,才像真的懂?
这个问题面试官很喜欢问,因为它能快速看出你是不是只会背定义。讲优缺点,最怕空话。最好的方式,是围绕"数据规模、维度、边界复杂度、训练代价"来讲。
5.1 SVM 的优势
• 在高维空间里表现通常不错,尤其是文本分类这类稀疏高维任务。
• 当特征维度甚至大于样本数量时,依然可能表现稳定。
• 只依赖支持向量决定边界,从直觉上看比较"抓重点"。
• 配合核函数以后,能处理不少非线性分类问题。
5.2 SVM 的局限
• 对特征尺度比较敏感,通常要先做标准化。
• 核 SVC 在样本量大时训练成本会明显上升。scikit-learn 文档明确提醒,SVC 的训练时间至少是样本数的二次级增长,大到数万样本时就可能不太现实。
• 默认并不直接给出概率输出,若要概率,通常要付出额外开销。
• 参数调优对结果影响很大,尤其是 C、gamma 和核函数选择。
6. 多分类问题里,SVM 是怎么做的?
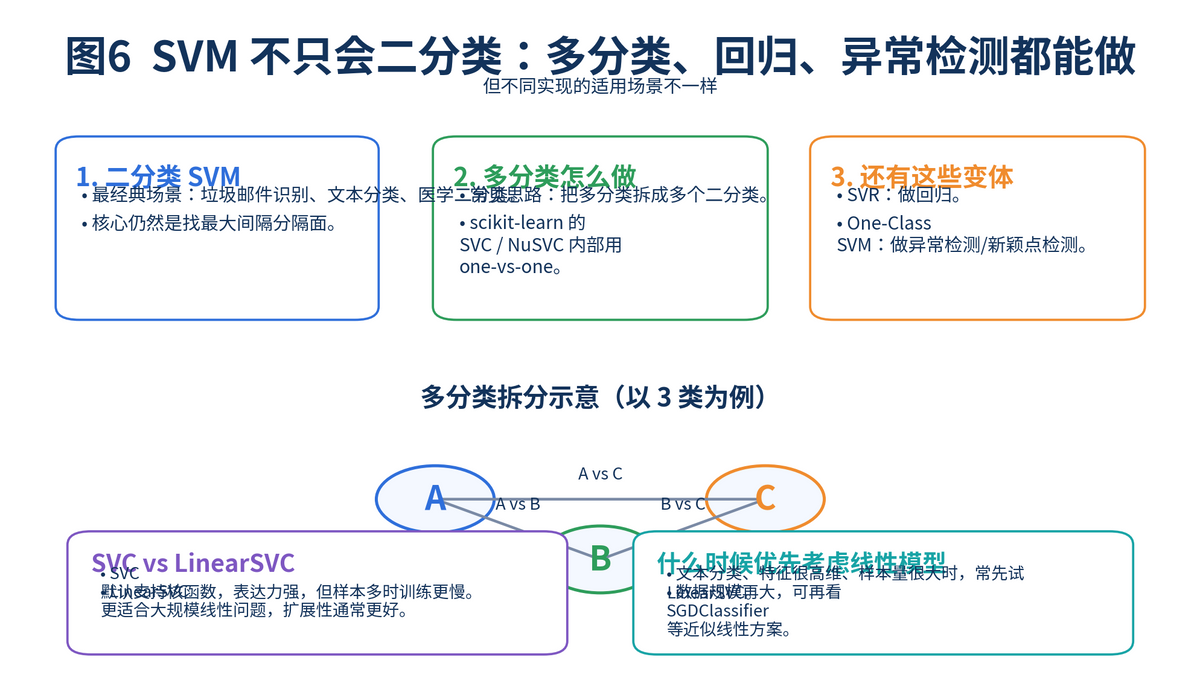
标准 SVM 最经典的是二分类。但真实业务经常是多分类,比如情感三分类、意图十分类。做法通常不是直接"天生多分类",而是把多分类拆成多个二分类。
常见的拆分有两种:一对多(OVR)和一对一(OVO)。一对多是每个类别都和其余类别打一场;一对一是类别两两对打。scikit-learn 官方文档指出,SVC 和 NuSVC 的多分类支持是按 one-vs-one 处理的,而 LinearSVC 更适合大规模线性场景。
面试里讲到这里,加一句"多分类本质上是把复杂问题拆成多个二分类子问题",一般就很加分。
7. 为什么很多文本分类任务会先想到 SVM?
因为文本特征往往是高维、稀疏、线性可分性不错的。比如 TF-IDF 特征一展开,维度可能非常高,但很多类别边界已经相当清晰。这个时候,线性核 SVM 或 LinearSVC 常常能给出又快又强的基线。
这也是为什么很多工业级基线模型里,SVM 虽然不再像早年那样"统治一切",但依然有很强的存在感。
8. SVM 实战怎么调参?
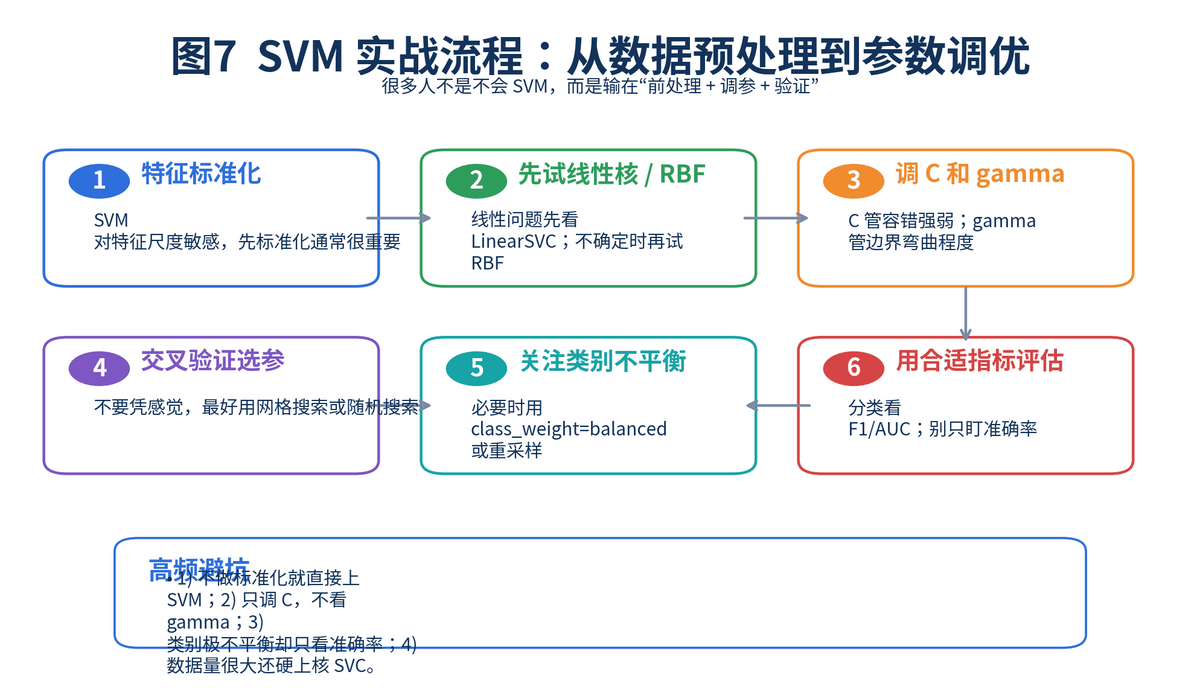
如果面试官追问"落地时怎么做",你可以按下面这个顺序回答。
• 第一步,先做特征标准化。SVM 对尺度敏感,不同量纲不处理,模型很容易失真。
• 第二步,先试线性核。如果线性效果已经够好,就不必一开始就上复杂核。
• 第三步,如果线性不够,再试 RBF 核,并联合调 C 和 gamma。
• 第四步,用交叉验证选参数,而不是靠肉眼拍脑袋。
• 第五步,如果类别不平衡明显,要考虑 class_weight、重采样或更合适的评估指标。
scikit-learn 还明确提醒:SVC 在样本数很大时可能不实用,这时候可以优先考虑 LinearSVC 或 SGDClassifier,必要时再结合核近似方法。这个点在面试里很重要,因为它体现你知道模型不只是"能不能用",还知道"能不能跑得动"。
9. 为什么 SVM 要做标准化?
这是一个很容易被忽略,但很容易被追问的点。原因不复杂:SVM 的距离、间隔和核函数计算,都和特征尺度密切相关。如果一个特征取值范围是 0 到 1,另一个特征是 0 到 10000,那后者会在距离计算里占据压倒性影响,导致模型几乎只看它。
所以实际使用 SVM,尤其是 RBF 核、多项式核时,标准化几乎是默认动作。你可以在面试中直接说:"SVM 对特征尺度敏感,不做标准化会导致某些维度支配相似度和间隔计算。"
10. 面试里怎么回答"支持向量机为什么要引入核函数"?
一个比较完整、又不显得书呆子的回答可以这么组织:SVM 最初擅长解决线性可分问题,但现实里很多数据在原空间中分不开,所以引入核函数。核函数的作用不是单纯把数据硬搬到高维,而是通过核技巧,在不显式升维的情况下计算高维空间中的相似度,从而得到非线性分类边界。常见核函数有线性核、多项式核和 RBF 核,其中 RBF 核最常作为非线性问题的默认起点。
11. 一段适合面试复述的高分答案
支持向量机是一类监督学习方法,可用于分类、回归和异常检测。它最核心的思想,是寻找一个最大间隔超平面,把不同类别尽量稳地分开。最终决定边界位置的,不是全部样本,而是离边界最近的支持向量。现实数据通常不可完全线性可分,所以会采用软间隔,并通过参数 C 在训练误差和间隔宽度之间做平衡。若原空间中线性不可分,则可通过核函数引入非线性边界,常见核函数包括线性核、多项式核和 RBF 核。实际落地时,SVM 对特征尺度敏感,通常需要先做标准化,再通过交叉验证调节 C、gamma 等参数;如果数据规模特别大,则优先考虑 LinearSVC 或更可扩展的线性方法。

12. 总结
SVM 之所以经典,不是因为它名气大,而是因为它把"分类"这件事做得非常讲究:不是只求分开,而是尽量分得稳、分得宽、分得有余量。支持向量决定边界,最大间隔提升稳健性,软间隔解决噪声问题,核函数处理非线性,这四个点连起来,基本就是 SVM 的骨架。
如果你只是为了面试,那么最值得记住的不是公式,而是这条主线:SVM = 最大间隔 + 支持向量 + 软间隔 + 核技巧 + 合理调参。把这条线讲顺,绝大多数面试追问都能接住。