目录
-
- [1 前言](#1 前言)
- [2 什么是 vLLM:高吞吐推理的秘密](#2 什么是 vLLM:高吞吐推理的秘密)
-
- [2.1 核心技术突破:PagedAttention](#2.1 核心技术突破:PagedAttention)
- [2.2 vLLM 的主要功能与特性](#2.2 vLLM 的主要功能与特性)
- [2.3 性能表现](#2.3 性能表现)
- [3 环境准备与基础配置](#3 环境准备与基础配置)
-
- [3.1 配置虚拟环境](#3.1 配置虚拟环境)
- [3.2 安装 vLLM 核心库](#3.2 安装 vLLM 核心库)
- [4 准备模型文件](#4 准备模型文件)
-
- [4.1 模型支持矩阵](#4.1 模型支持矩阵)
- [4.2 选择合适的权重格式](#4.2 选择合适的权重格式)
- [5 下载模型文件](#5 下载模型文件)
-
- [5.1 方式 1:使用 HuggingFace 官方库及镜像](#5.1 方式 1:使用 HuggingFace 官方库及镜像)
- [5.2 方式 2:使用 ModelScope (魔搭社区)](#5.2 方式 2:使用 ModelScope (魔搭社区))
- [6 部署 OpenAI 兼容的 API 服务](#6 部署 OpenAI 兼容的 API 服务)
-
- [6.1 服务启动详解](#6.1 服务启动详解)
- [6.2 关键参数详解](#6.2 关键参数详解)
- [6.3 关于聊天模板 (Chat Template)](#6.3 关于聊天模板 (Chat Template))
- [7 服务验证与调用](#7 服务验证与调用)
-
- [7.1 使用 Curl 进行快速验证](#7.1 使用 Curl 进行快速验证)
- [7.2 使用 Python Requests 进行接口测试](#7.2 使用 Python Requests 进行接口测试)
- [7.3 使用 OpenAI 官方 SDK 调用](#7.3 使用 OpenAI 官方 SDK 调用)
- [8 结语](#8 结语)
- [9 参考资料](#9 参考资料)
1 前言
在大型语言模型(LLM)的落地应用中,推理性能往往是决定用户体验与运营成本的关键瓶颈。传统的推理框架在处理高并发请求时,常常受限于显存碎片化和静态批处理的低效,导致 GPU 利用率低下。为了解决这些痛点,由加州大学伯克利分校 Sky Computing Lab 开发的 vLLM 应运而生。它凭借创新的 PagedAttention 技术,彻底改变了 KV 缓存的管理方式,将推理吞吐量提升到了新的高度。
本文将为您提供一份详尽的 vLLM 部署指南。从核心原理的深度解析到环境搭建、模型下载,再到生产环境的服务部署与性能优化,我们将全方位覆盖。无论您是希望在本地验证模型的开发者,还是需要在生产集群中构建高可用 API 服务的架构师,这篇长文都将为您提供极具价值的参考。
2 什么是 vLLM:高吞吐推理的秘密
vLLM 是一个专为大模型设计的快速、易用的推理和服务库。它的核心使命是"让推理更廉价、更快速"。在当今学术界和工业界的共同驱动下,它已经支持了几乎所有主流的开源大模型。
2.1 核心技术突破:PagedAttention
在 LLM 生成文本的过程中,所有的键(Key)和值(Value)向量都会被缓存起来以避免重复计算。这种 KV 缓存体量巨大且动态增长,传统框架往往会预分配一段连续的显存,这导致了严重的碎片化问题(Internal/External Fragmentation)。
vLLM 借鉴了操作系统中虚拟内存的分页思想,开发了 PagedAttention。它将 KV 缓存划分为若干个固定大小的"物理块",并不要求这些块在显存中连续。这种灵活的映射机制使得显存浪费率降低至 4% 以下,从而能够容纳更多的并发请求。
2.2 vLLM 的主要功能与特性
为了方便您快速了解 vLLM 的技术全貌,下表汇总了其核心功能及其带来的技术收益:
| 核心功能 | 技术描述 | 用户收益 |
|---|---|---|
| PagedAttention | 像操作系统分页一样管理 KV 缓存 | 极高的显存利用率,支持更大并发 |
| 连续批处理 (Continuous Batching) | 随到随处理,不再等待整个 Batch 结束 | 显著降低平均响应延迟 (Latency) |
| 多样化量化支持 | 支持 GPTQ, AWQ, INT4/8, FP8 等多种精度 | 降低显存占用,适配不同硬件 |
| 分布式推理 | 支持张量并行 (TP) 与流水线并行 (PP) | 能够运行超大规模参数模型 (如 Llama-405B) |
| 多后端适配 | 兼容 NVIDIA, AMD, Intel, TPU 及 AWS Neuron | 硬件选择灵活,无厂商锁定 |
| 推测性解码 | 使用小模型辅助大模型进行预测 | 在不损失精度的情况下提升生成速度 |
2.3 性能表现
vLLM 的最强项在于服务吞吐量。在处理典型的对话任务时,其吞吐量通常能达到 HuggingFace Transformers 库的 10 到 20 倍。这种性能提升不仅意味着更快的响应速度,更直接转化为计算成本的直线下降。
3 环境准备与基础配置
在正式部署之前,我们需要确保底层环境的稳定与兼容性。vLLM 对 Python 版本和 CUDA 驱动有一定的要求。
3.1 配置虚拟环境
建议使用 Conda 创建独立的虚拟环境,以避免不同库之间的依赖冲突。vLLM 目前支持 Python 3.9 到 3.12 版本。
PowerShell
# Python: 3.9 -- 3.12
conda create -n vllm python=3.12 -y
conda activate vllm3.2 安装 vLLM 核心库
安装过程非常简单,直接通过 pip 即可完成。由于 vLLM 依赖较多底层算子,建议在网络环境稳定的情况下进行。
pip install --upgrade pip
pip install vllm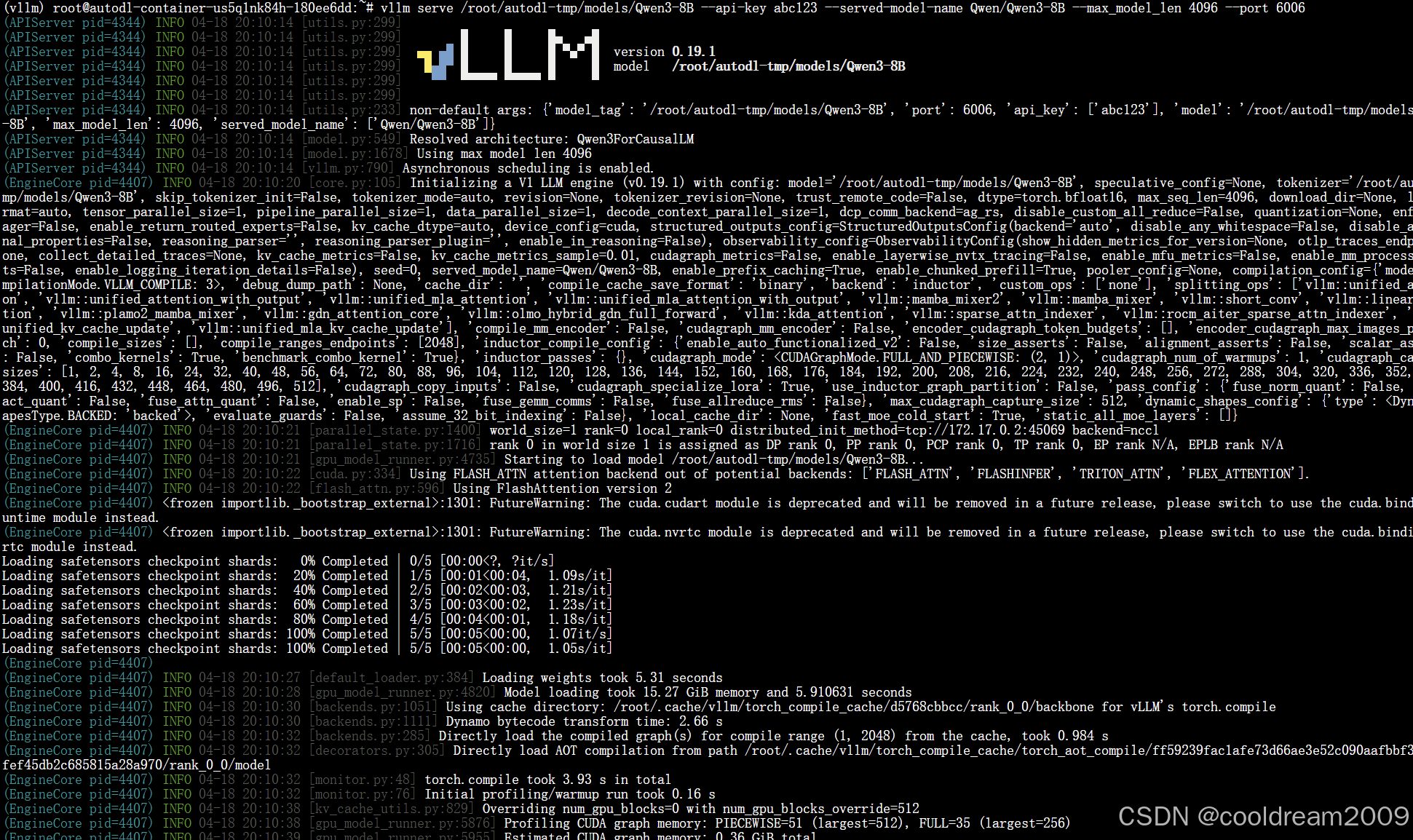
# 验证安装
pip show vllm
安装完成后,建议通过简单的 python -c "import vllm" 命令来检查是否存在底层驱动或库的缺失。
4 准备模型文件
vLLM 的灵活性体现在其对 HuggingFace 生态的深度兼容。无论是纯文本模型还是多模态模型,只要是主流架构,几乎都可以"开箱即用"。
4.1 模型支持矩阵
您可以参考下表来确认您的模型是否在官方支持列表中(部分示例):
| 模型类型 | 代表性模型列表 |
|---|---|
| Text-Only | Llama 2/3/3.1, Qwen 1.5/2/2.5, Mistral, Mixtral, Gemma, InternLM |
| Multimodal | LLava, Qwen-VL, PaliGemma, InternVL |
| Quantized | 以上模型的 GPTQ, AWQ, GGUF 版本 |
4.2 选择合适的权重格式
如果是生产环境,建议优先选择 FP16 或 BF16 格式。如果显存受限,AWQ 或 GPTQ 4-bit 量化版本是极佳的选择,vLLM 对这类权重的优化深度非常高,能够保持较高的推理速度。
5 下载模型文件
对于国内开发者,直接从 HuggingFace 官网下载可能会遇到网络障碍。我们可以选择使用镜像站或者 ModelScope。
5.1 方式 1:使用 HuggingFace 官方库及镜像
首先安装必要的下载工具,并设置环境变量以加速下载。
PowerShell
# 安装依赖
pip install -U huggingface_hub
# 设置环境变量(国内加速)
export HF_ENDPOINT=https://hf-mirror.com
# 下载模型到指定路径
hf download Qwen/Qwen3-8B --local-dir {local_path} --local-dir-use-symlinks False
# Qwen/Qwen3-8B 为 Huggingface 上的模型名称
# --local-dir 后设置本地保存路径
# --local-dir-use-symlinks False 参数禁用文件软链接,这样下载路径下所见即所得
# 示例
hf download Qwen/Qwen3-8B --local-dir ./autodl-tmp/models/Qwen3-8B5.2 方式 2:使用 ModelScope (魔搭社区)
ModelScope 提供了非常稳定的国内下载渠道,适合下载国产大模型(如 Qwen、DeepSeek)。
PowerShell
# 安装依赖
pip install modelscope
# 下载到本地路径
modelscope download --model Qwen/Qwen3-8B --local_dir {local_path}注意:{local_path} 应替换为您磁盘空间充足的目录,例如 ./models/Qwen3-8B。
6 部署 OpenAI 兼容的 API 服务
vLLM 提供了一个极度方便的 API 服务器,它完全兼容 OpenAI 的接口规范。这意味着您可以直接将 vLLM 作为后端,连接到现有的各种 LLM 应用 UI(如 NextChat, OpenWebUI)。
6.1 服务启动详解
在多显卡环境下,我们需要合理利用张量并行(Tensor Parallelism)来拆分模型。
Bash
# 使用双卡来部署 QwQ-32B
CUDA_VISIBLE_DEVICES=0,1 vllm serve {local_path} \
--api-key abc123 \ # 设置 api-key
--served-model-name Qwen/Qwen3-8B \ # API 服务的模型名称
--max_model_len 4096 \ # 最大处理长度(输入 prompt + 生成内容的 token 总数)
--tensor-parallel-size 2 \ # 张量并行数量,和你使用 GPU 卡数保持一致
--port 7890
# 综合示例
vllm serve /root/autodl-tmp/models/Qwen3-8B --api-key abc123 --served-model-name Qwen/Qwen3-8B --max_model_len 4096 --port 60036.2 关键参数详解
为了让服务运行得更稳健,下表详细解析了 vllm serve 命令中的核心参数:
| 参数名称 | 功能说明 | 推荐建议 |
|---|---|---|
--gpu-memory-utilization |
指定 vLLM 占用显存的比例 | 默认为 0.9。若同一张卡有其它进程,请调低至 0.7-0.8 |
--max-model-len |
模型的最大上下文长度 | 若显存溢出,可适当调小此值 |
--tensor-parallel-size |
GPU 并行数量 | 建议设为 1, 2, 4 或 8(取决于显卡数) |
--enable-prefix-caching |
开启前缀缓存 | 处理多轮对话或固定 System Prompt 时能大幅提升速度 |
--quantization |
指定量化方法 | 若使用量化模型,需显式指定 awq, gptq 或 fp8 |
6.3 关于聊天模板 (Chat Template)
vLLM 会自动识别 HuggingFace 模型权重中的 tokenizer_config.json 是否包含 chat_template。如果模型没有自带模板,您可以手动通过 --chat-template 参数指定一个 Jinja2 模板,确保模型能正确识别 user 和 assistant 的边界。
7 服务验证与调用
部署完成后,我们需要通过多种方式确认服务是否正常运行,并了解如何集成到自己的业务系统中。
7.1 使用 Curl 进行快速验证
这是一个最直接的方法,用于测试 API 是否能正常响应 HTTP 请求。
Bash
# 注意要设置正确的 api-key
curl http://localhost:7890/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer abc123" \
-X POST \
-d '{
"model": "Qwen/Qwen3-8B",
"messages": [{"role": "user", "content": "你是谁?"}],
"max_tokens": 1000
}'7.2 使用 Python Requests 进行接口测试
如果您习惯在 Python 环境下工作,可以使用 requests 库快速获取模型返回结果。
Python
import requests
url = "http://localhost:7890/v1/chat/completions"
headers = {
"Content-Type": "application/json",
"Authorization": "Bearer abc123"
}
data = {
"model": "Qwen/Qwen3-8B",
"messages": [
{"role": "user", "content": "请解释什么是连续批处理?"}
],
"max_tokens": 1000
}
response = requests.post(url, headers=headers, json=data)
print(response.json())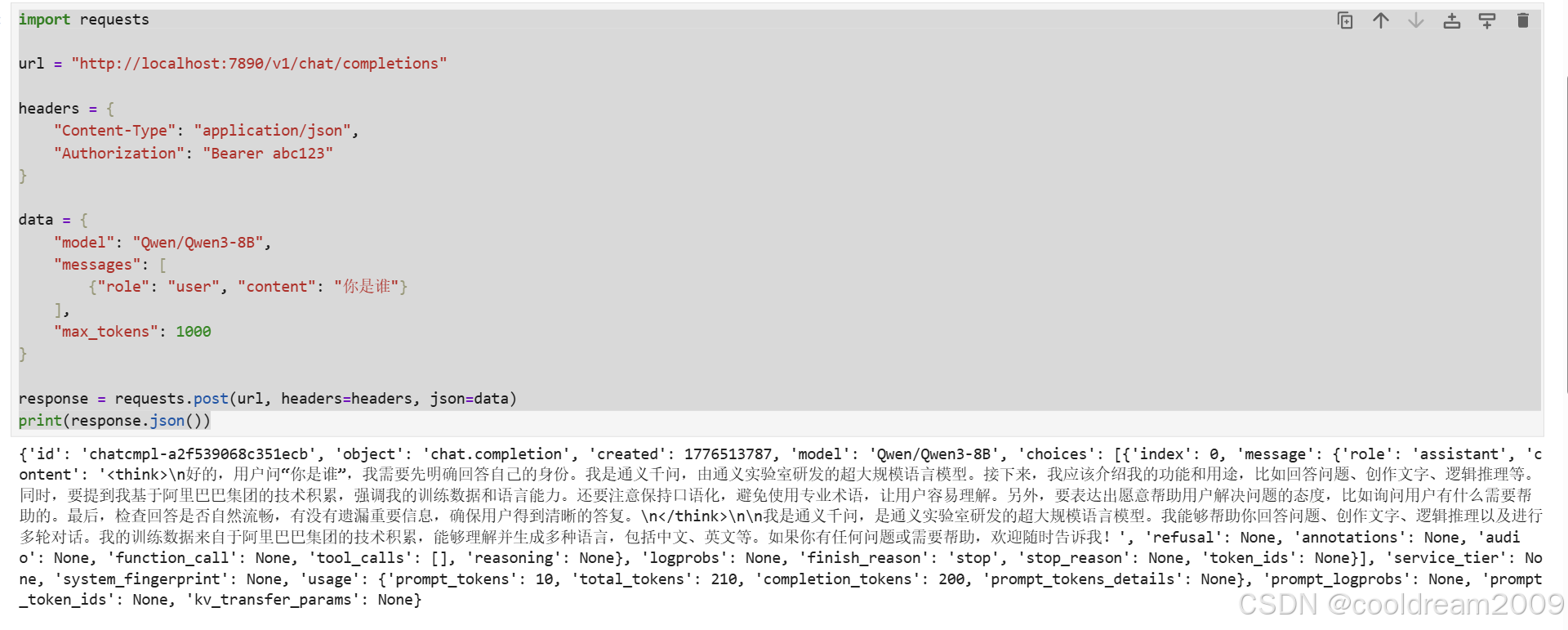
7.3 使用 OpenAI 官方 SDK 调用
这是生产环境中最推荐的方式。由于 vLLM 高度兼容 OpenAI 协议,您可以直接复用现有的工具链。
Python
from openai import OpenAI
# 这里的 base_url 指向你 vLLM 服务的 IP 和端口
client = OpenAI(
base_url="http://127.0.0.1:6003/v1",
api_key="abc123",
)
completion = client.chat.completions.create(
model="Qwen/Qwen3-8B", # 必须与启动时的 served-model-name 一致
messages=[
{"role": "user", "content": "请用一段话评价 vLLM。"}
]
)
print(completion.choices[0].message.content)8 结语
vLLM 不仅仅是一个简单的推理工具,它代表了 LLM 推理架构的一次范式转移。通过 PagedAttention 和连续批处理,它将 GPU 的算力压榨到了极致,为开发者构建高性能、低成本的大模型应用提供了坚实的基础。从环境搭建到分布式部署,再到最终的 API 调用,vLLM 展示了极高的工程化水平和用户友好性。
随着开源模型规模的不断扩大和多模态时代的到来,vLLM 也在持续迭代。掌握这一利器,将使您在处理大规模并发推理任务时更加游刃有余。希望这份指南能为您的大模型部署之路提供实质性的帮助。
9 参考资料
- vLLM 官方文档:https://docs.vllm.ai/
- vLLM GitHub 仓库:https://github.com/vllm-project/vllm
- PagedAttention 技术博客:https://blog.vllm.ai/2023/06/20/vllm.html
- OpenAI API 官方规范参考:https://platform.openai.com/docs/api-reference
- HuggingFace 模型库:https://huggingface.co/models