目录
[1. 写在前面](#1. 写在前面)
[2. 题目背景与任务概述](#2. 题目背景与任务概述)
[3. 整体建模思路总览](#3. 整体建模思路总览)
[第 1 层:指标层](#第 1 层:指标层)
[第 2 层:风险层](#第 2 层:风险层)
[第 3 层:决策层](#第 3 层:决策层)
[4. 第一问:关键指标筛选与体质风险贡献分析](#4. 第一问:关键指标筛选与体质风险贡献分析)
[4.1 这一问到底在解决什么](#4.1 这一问到底在解决什么)
[4.2 数据处理:先把输入口径统一](#4.2 数据处理:先把输入口径统一)
[4.3 多源指标筛选:不是跑一个模型就结束](#4.3 多源指标筛选:不是跑一个模型就结束)
[4.4 第一问的结果:哪些指标最关键](#4.4 第一问的结果:哪些指标最关键)
[4.5 高血脂预警模型:这一问里真正"跑得好"的部分](#4.5 高血脂预警模型:这一问里真正“跑得好”的部分)
[4.6 九种体质对风险的贡献差异](#4.6 九种体质对风险的贡献差异)
[4.7 第一问小结](#4.7 第一问小结)
[5. 第二问:三级风险预警模型怎么搭起来](#5. 第二问:三级风险预警模型怎么搭起来)
[5.1 这一问的关键,不是"训练个分类器"这么简单](#5.1 这一问的关键,不是“训练个分类器”这么简单)
[5.2 特征工程:先把"异常"翻译成模型能理解的量](#5.2 特征工程:先把“异常”翻译成模型能理解的量)
[5.3 融合风险得分:专家先验 + 数据驱动](#5.3 融合风险得分:专家先验 + 数据驱动)
[5.4 三级风险阈值不是拍脑袋定的](#5.4 三级风险阈值不是拍脑袋定的)
[5.5 三分类模型:让分层规则能泛化到新样本](#5.5 三分类模型:让分层规则能泛化到新样本)
[5.6 哪些特征真正把风险拉高了](#5.6 哪些特征真正把风险拉高了)
[5.7 痰湿体质高风险人群的核心特征组合](#5.7 痰湿体质高风险人群的核心特征组合)
[6. 第三问:6 个月个体化干预方案怎么做](#6. 第三问:6 个月个体化干预方案怎么做)
[6.1 这一问为什么必须上动态规划](#6.1 这一问为什么必须上动态规划)
[6.2 先把约束和收益写清楚](#6.2 先把约束和收益写清楚)
[6.3 动态规划核心代码](#6.3 动态规划核心代码)
[6.4 第三问整体结果:群体层面表现怎么样](#6.4 第三问整体结果:群体层面表现怎么样)
[6.5 最优策略长什么样:不是"越猛越好"](#6.5 最优策略长什么样:不是“越猛越好”)
[6.6 样本 1、2、3 的最优方案](#6.6 样本 1、2、3 的最优方案)
[样本 1](#样本 1)
[样本 2](#样本 2)
[样本 3](#样本 3)
[6.7 患者特征如何映射到最优方案](#6.7 患者特征如何映射到最优方案)
[7. 整体结果总结与建模反思](#7. 整体结果总结与建模反思)
[7.1 这套方案最大的优点](#7.1 这套方案最大的优点)
[1. 三问之间逻辑非常顺](#1. 三问之间逻辑非常顺)
[2. 解释性和效果兼顾](#2. 解释性和效果兼顾)
[3. 第三问选动态规划很贴题](#3. 第三问选动态规划很贴题)
[4. 输出结果很完整](#4. 输出结果很完整)
[7.2 这份项目的不足也很明显](#7.2 这份项目的不足也很明显)
[1. 第一问的痰湿回归效果偏弱](#1. 第一问的痰湿回归效果偏弱)
[2. 九种体质 OR 结果显著性不强](#2. 九种体质 OR 结果显著性不强)
[3. 第三问里有工程化假设](#3. 第三问里有工程化假设)
[4. 第三问目前更像"单体优化"](#4. 第三问目前更像“单体优化”)
[7.3 如果我继续迭代这份项目](#7.3 如果我继续迭代这份项目)
[8. 完整复盘总结](#8. 完整复盘总结)
1. 写在前面
这次 C 题给我的最大感受,不是"又做了一道预测题",而是它其实更像一个完整的健康管理项目:
- 第一问先回答"该看哪些指标"
- 第二问再回答"怎么把人分成低中高风险"
- 第三问继续回答"已经识别出重点人群后,6 个月怎么干预最划算"
也正因为这个题目天然带着"筛选指标 -> 风险分层 -> 干预优化"的递进关系,所以整个项目特别适合做一次完整复盘。
这篇文章不是论文照搬,而是基于项目里真实存在的三个脚本和结果文件,按照技术博客的方式,把建模思路、核心代码和结果结论串起来讲清楚。正文里只展示最有代表性的代码片段,完整代码更适合放仓库或附录。
项目的主体结构非常清晰:
C题/
├─ 附件1:样例数据.xlsx
├─ question1/
│ ├─ mathorcup_c_q1.py
│ └─ output_q1/
├─ question2/
│ ├─ mathorcup_c_q2.py
│ └─ output_q2/
└─ question3/
├─ mathorcup_c_q3.py
└─ output_q3/每一问都有独立的 Python 脚本和输出目录,output_q1 / output_q2 / output_q3 里已经包含了表格、测试结果和图表,这一点很有工程感,也很适合复盘。
2. 题目背景与任务概述
题目围绕 中老年人群高血脂症的风险预警及干预方案优化 展开,数据来自 1000 例样本,字段包括:
- 九种中医体质积分与主导体质标签
- ADL / IADL 活动量表
- 血脂指标:TC、TG、LDL-C、HDL-C
- 代谢指标:空腹血糖、血尿酸、BMI
- 高血脂二分类标签与血脂异常分型
- 年龄、性别、吸烟史、饮酒史
从任务设计上看,三问分别是:
- 第一问:从血常规和活动量表里筛出关键指标,并分析九种体质对高血脂风险的贡献差异。
- 第二问:建立低、中、高三级风险预警模型,并解释阈值和高风险特征组合。
- 第三问:针对痰湿体质患者,在预算、年龄和活动能力约束下,给出 6 个月最优干预方案。
这三问不是孤立的。第一问在做"指标筛选",第二问在做"风险判定",第三问在做"干预决策"。虽然代码实现上三份脚本是独立运行的,但建模逻辑是一条完整链路。
3. 整体建模思路总览
如果用一句话概括这份项目的建模主线,就是:
用多源指标找出风险驱动因素,用规则与模型结合完成风险分层,再把风险高、且体质明确的人群送入动态优化模型做干预设计。
我最后把整套方案理解成 3 层:
第 1 层:指标层
目标是找到哪些指标既能解释 痰湿严重程度 ,又能用于 高血脂风险预警 。
这里不能只做一个相关性分析,也不能只跑一个分类器,所以代码采用了多种评价方式交叉排序。
第 2 层:风险层
目标是输出 低 / 中 / 高三级风险 。
这里如果完全依赖黑箱模型,会很难解释"为什么是高风险";如果完全依赖人工规则,又很难泛化到新样本。
所以第二问采用了一个很实用的思路:
- 先基于医学阈值构造风险分量
- 再用锚点规则自动校准阈值
- 最后训练一个三分类模型学习这套分层结果
第 3 层:决策层
目标是给痰湿体质患者安排 6 个月干预方案 。
这一步不是普通回归或分类,而是一个典型的 多阶段序贯决策问题 。因为每个月的痰湿积分会变化,而下一月可选的中医调理等级又取决于当前积分区间,所以代码最后选择了 动态规划。
这套拆法我觉得是这份项目最有价值的地方:不是在一个模型里硬塞所有问题,而是按问题结构拆成了三个层次。
4. 第一问:关键指标筛选与体质风险贡献分析
4.1 这一问到底在解决什么
第一问看似只是"筛指标",但实际上有两个目标:
- 找到能表征 痰湿体质严重程度 的指标
- 找到能预警 高血脂发病风险 的指标
如果只对着痰湿积分做回归,可能筛出的是"体质描述指标";
如果只对着高血脂标签做分类,可能筛出的是"诊断型指标"。
而题目要的是两者兼顾,所以代码没有走单模型路线,而是把这两个目标都纳入了指标评价体系。
4.2 数据处理:先把输入口径统一
原始数据有 37 个字段,进入建模前,代码先做了三件很关键的事:
- 统一列名,去掉空格、换行和全角字符
- 数值列转成数值型,缺失值用中位数填补
- 对连续变量做 1% 到 99% 分位缩尾,削弱极端值影响
核心代码如下:
python
def preprocess_data(df):
df = standardize_columns(df)
constitution_cols = ['平和质', '气虚质', '阳虚质', '阴虚质', '痰湿质', '湿热质', '血瘀质', '气郁质', '特禀质']
activity_cols = ['ADL总分', 'IADL总分', '活动量表总分(ADL总分+IADL总分)']
blood_cols = ['HDL-C(高密度脂蛋白)', 'LDL-C(低密度脂蛋白)', 'TG(甘油三酯)',
'TC(总胆固醇)', '空腹血糖', '血尿酸', 'BMI']
numeric_cols = constitution_cols + activity_cols + blood_cols + ['年龄组', '性别', '吸烟史', '饮酒史']
for c in numeric_cols:
df[c] = pd.to_numeric(df[c], errors='coerce')
if df[c].isna().sum() > 0:
df[c] = df[c].fillna(df[c].median())
for c in constitution_cols + activity_cols + blood_cols:
low, high = df[c].quantile([0.01, 0.99])
df[c] = df[c].clip(lower=low, upper=high)
return df这段代码虽然不复杂,但它决定了后面所有分析的稳定性。
对应到公式上,缩尾处理可以写成:
其中,xij表示第 i 个样本在第 j 个指标上的原始值,Q0.01,Q0.99分别表示 1% 和 99% 分位数。
这个操作的实际作用是:不删除样本,但把极端异常值收回到合理范围内。
4.3 多源指标筛选:不是跑一个模型就结束
这部分是第一问的核心。
代码没有简单地用一个"特征重要性"排序,而是同时从两条证据链打分:
- 痰湿表征能力
- 高血脂预警能力
具体用了 7 个量:
- Spearman 相关系数
- 痰湿互信息
- LASSO 绝对系数
- 高血脂互信息
- Logistic 绝对系数
- 随机森林重要性
- 置换重要性
核心实现如下:
python
def build_feature_ranking(df, feature_cols, cfg):
X = df[feature_cols].copy()
y_reg = df['痰湿质'].copy()
y_clf = df['高血脂症二分类标签'].copy().astype(int)
spearman_series = pd.Series(
{c: abs(spearmanr(df[c], y_reg).correlation) for c in feature_cols},
name='|Spearman(痰湿)|'
)
mi_reg = pd.Series(mutual_info_regression(X, y_reg, random_state=cfg.random_state),
index=feature_cols, name='互信息(痰湿)')
mi_clf = pd.Series(mutual_info_classif(X, y_clf, random_state=cfg.random_state),
index=feature_cols, name='互信息(高血脂)')
reg_model, reg_metrics, lasso_coef, reg_result = train_lasso_regression(df, feature_cols, cfg)
clf_model, rf_model, clf_metrics, logit_coef, rf_imp, perm_imp, clf_result = train_risk_models(df, feature_cols, cfg)
ranking = pd.concat([
spearman_series, mi_reg, lasso_coef, mi_clf, logit_coef, rf_imp, perm_imp
], axis=1)
norm_cols = []
for c in ranking.columns:
ranking[f'{c}_标准化得分'] = minmax_series(ranking[c])
norm_cols.append(f'{c}_标准化得分')
ranking['综合得分'] = ranking[norm_cols].mean(axis=1)
ranking['综合排序'] = ranking['综合得分'].rank(ascending=False, method='dense').astype(int)
return ranking.sort_values('综合得分', ascending=False)这一段代码背后的建模思想可以写成:
其中:
- Gj 是第 jj个指标的综合得分
- zjk 是第 j 个指标在第 k 种评价指标上的归一化得分
- K=7
归一化采用极差标准化:
这个设计的好处非常直接:
既看和痰湿的关系,也看和高血脂的关系;既看线性模型,也看非线性模型。
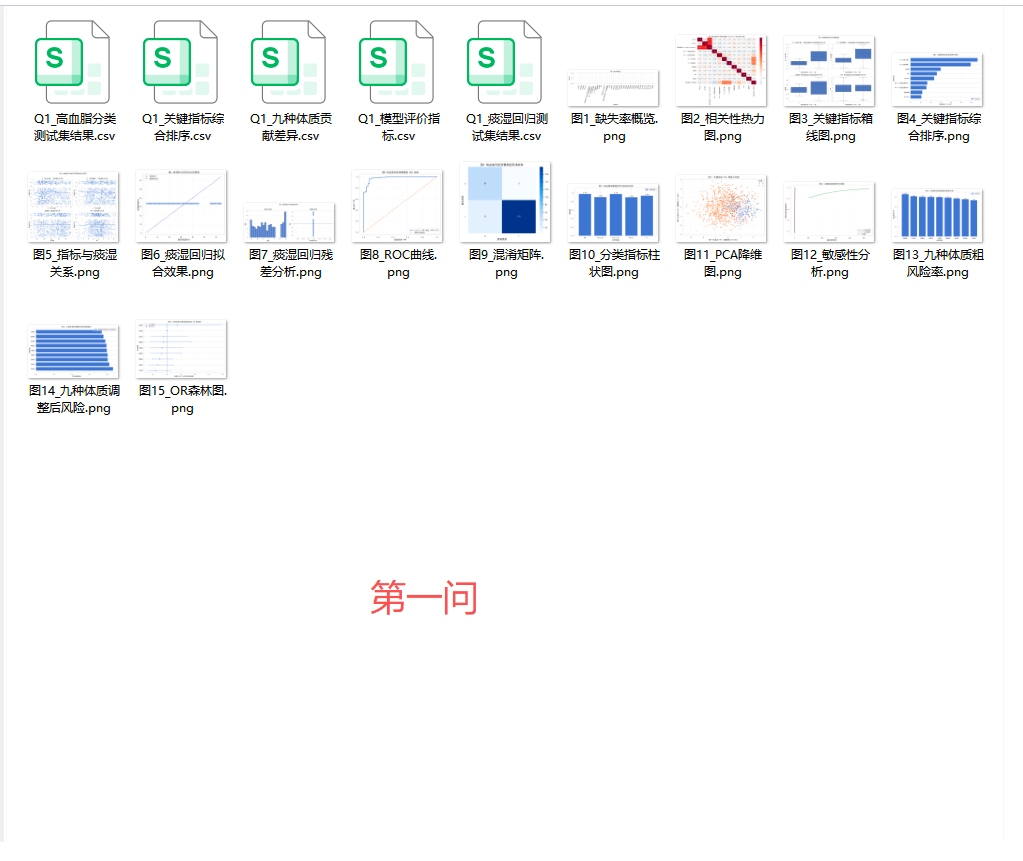
4.4 第一问的结果:哪些指标最关键
综合排序结果里,前 6 个指标分别是:
| 排名 | 指标 | 综合得分 |
|---|---|---|
| 1 | TG(甘油三酯) | 66.323 |
| 2 | TC(总胆固醇) | 59.537 |
| 3 | 血尿酸 | 29.912 |
| 4 | BMI | 25.962 |
| 5 | ADL总分 | 23.366 |
| 6 | HDL-C(高密度脂蛋白) | 16.703 |
这个结果挺有意思:
- TG、TC 稳居前二,说明血脂异常本身仍然是风险识别的最核心因素
- 血尿酸、BMI 排在中间位置,说明代谢异常和肥胖相关信息也在驱动高血脂风险
- ADL 总分 比 IADL 更重要,说明基础活动能力比工具性活动能力更能反映当前样本的健康差异
从图上会更直观看出:前两名和后面指标之间其实是有明显梯度差的。
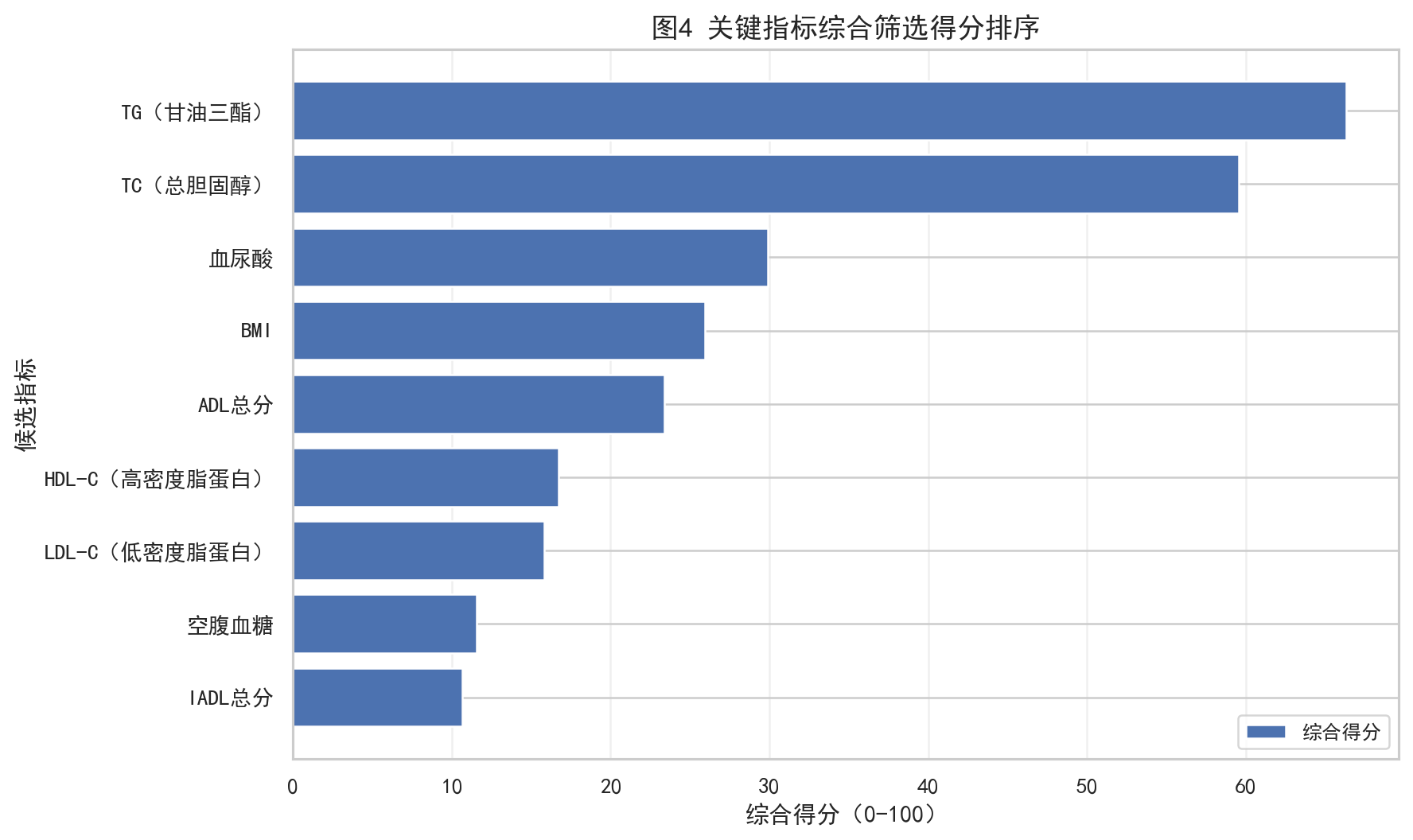
4.5 高血脂预警模型:这一问里真正"跑得好"的部分
第一问里,代码同时做了两类模型:
- 用 LASSO 回归预测痰湿积分
- 用 Logistic 回归预测高血脂二分类标签
其中 LASSO 回归的效果并不好,输出结果是:
- R2=−0.0084R2=−0.0084
- RMSE = 19.701
- MAE = 16.826
这说明:仅靠当前候选指标,用线性模型去拟合连续痰湿积分,解释能力很弱。
但 Logistic 回归的效果非常亮眼:
- AUC = 0.9786
- Accuracy = 0.9080
- Precision = 0.9781
- Recall = 0.9040
- F1 = 0.9396
核心模型代码如下:
python
logit_model = Pipeline([
('imputer', SimpleImputer(strategy='median')),
('scaler', StandardScaler()),
('logit', LogisticRegression(max_iter=1000, class_weight='balanced', random_state=cfg.random_state))
])
logit_model.fit(X_train, y_train)
pred_prob = logit_model.predict_proba(X_test)[:, 1]
pred_label = (pred_prob >= 0.5).astype(int)它对应的数学表达式就是标准 Logistic 模型:
其中:
- xi是第i个样本的特征向量
- yi=1表示高血脂阳性
- β0,β是待估计参数
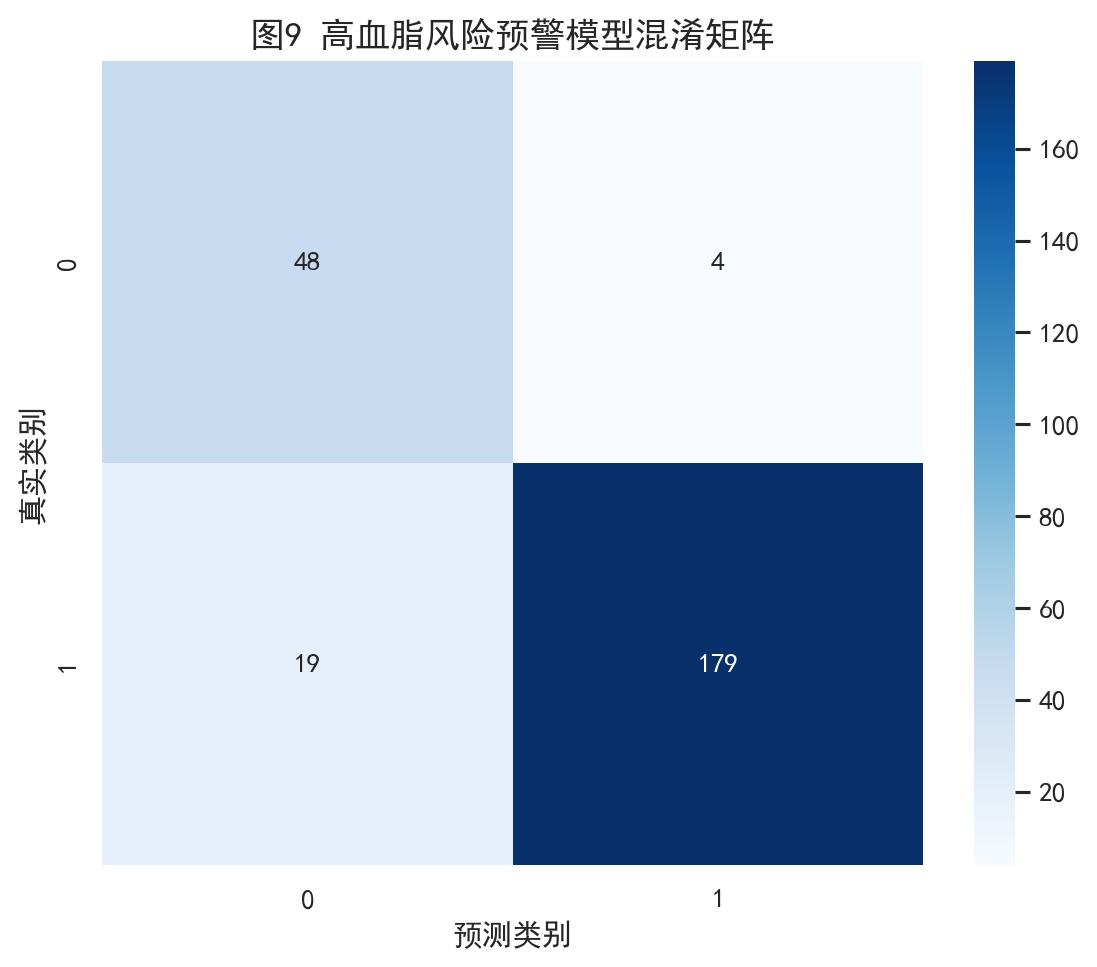
测试集混淆矩阵实际对应的是:
| 真实类别 | 预测为 0 | 预测为 1 |
|---|---|---|
| 0 | 48 | 4 |
| 1 | 19 | 179 |
这个结果说明模型有两个特点:
- 对阳性样本识别非常敏感
- 假阳性控制得也比较好
如果这里配图,最推荐插入:
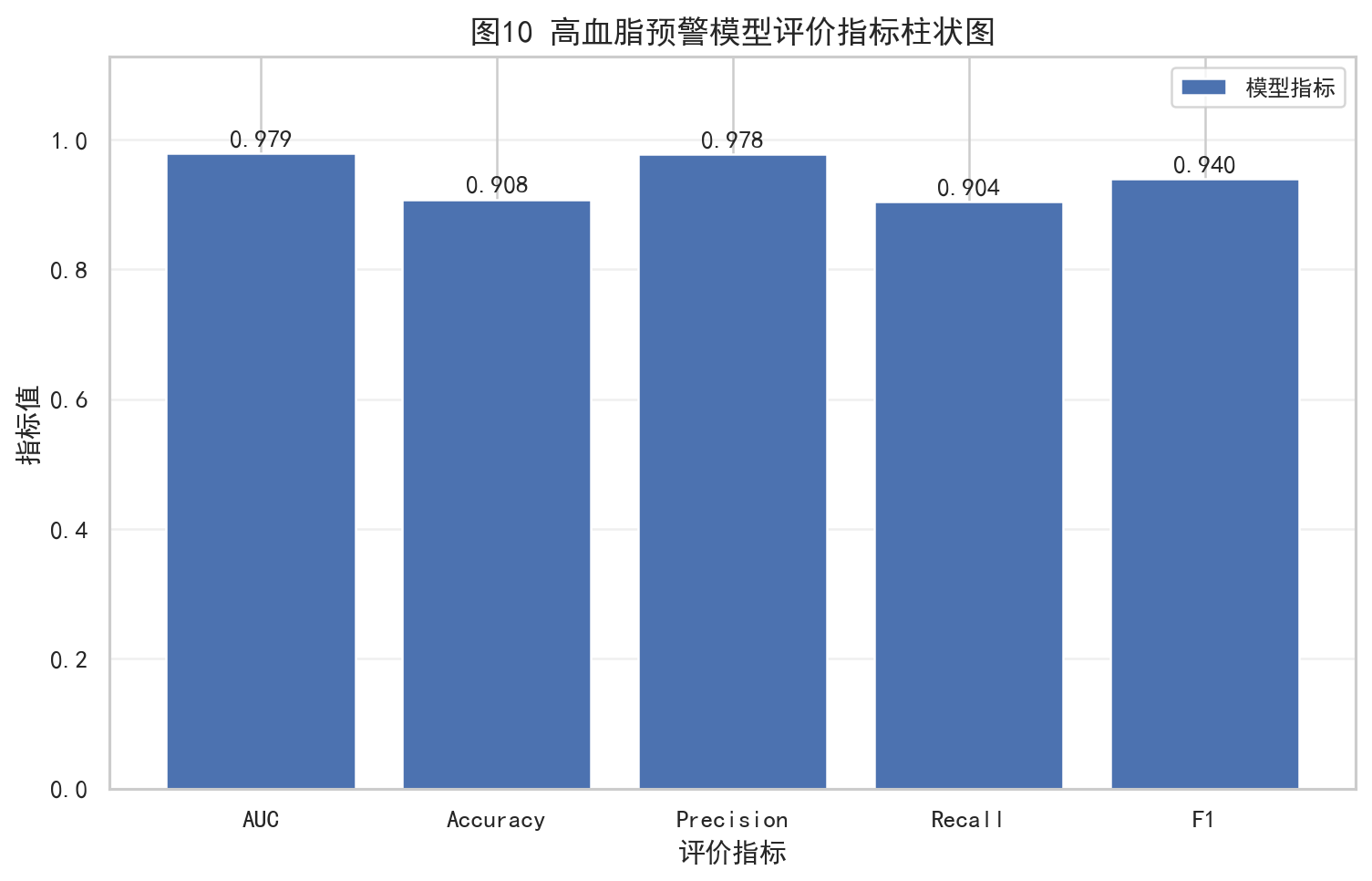
4.6 九种体质对风险的贡献差异
第一问还专门分析了九种体质对高血脂风险的贡献差异。
这一步没有只看粗风险率,而是用了 控制年龄、性别、吸烟史、饮酒史后的 Logistic 回归。
模型形式是:

然后通过
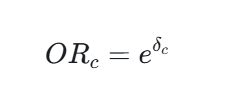
来衡量各体质相对平和质的优势比。
代码里这一段的核心实现是:
python
dummies = pd.get_dummies(work['体质标签'], prefix='体质', drop_first=True).astype(int)
X = pd.concat([work[['年龄组', '性别', '吸烟史', '饮酒史']], dummies], axis=1)
X = sm.add_constant(X)
y = work['高血脂症二分类标签']
model = sm.Logit(y, X).fit(disp=0, maxiter=200)输出结果里,按平均预测风险排序,前几位是:
| 排名 | 体质 | 粗风险率 | 平均预测风险 | OR |
|---|---|---|---|---|
| 1 | 阳虚质 | 0.8630 | 0.8634 | 1.3730 |
| 2 | 平和质 | 0.8182 | 0.8218 | 1.0000 |
| 3 | 湿热质 | 0.8052 | 0.8040 | 0.8887 |
| 4 | 特禀质 | 0.8070 | 0.8032 | 0.8842 |
这部分有一个很值得复盘的点:
从主导体质标签来看,痰湿质并不是风险贡献最高的体质;但从连续痰湿积分看,它又是后续风险建模里的核心变量。
这其实并不冲突。因为:
- "体质标签"是九选一的主导类别
- "痰湿质积分"是连续严重度变量
前者更粗,后者更细。
所以第一问的体质标签分析更适合做"组间排序",而第二问、第三问真正高价值的,是连续痰湿积分。
如果这里配图,推荐放:
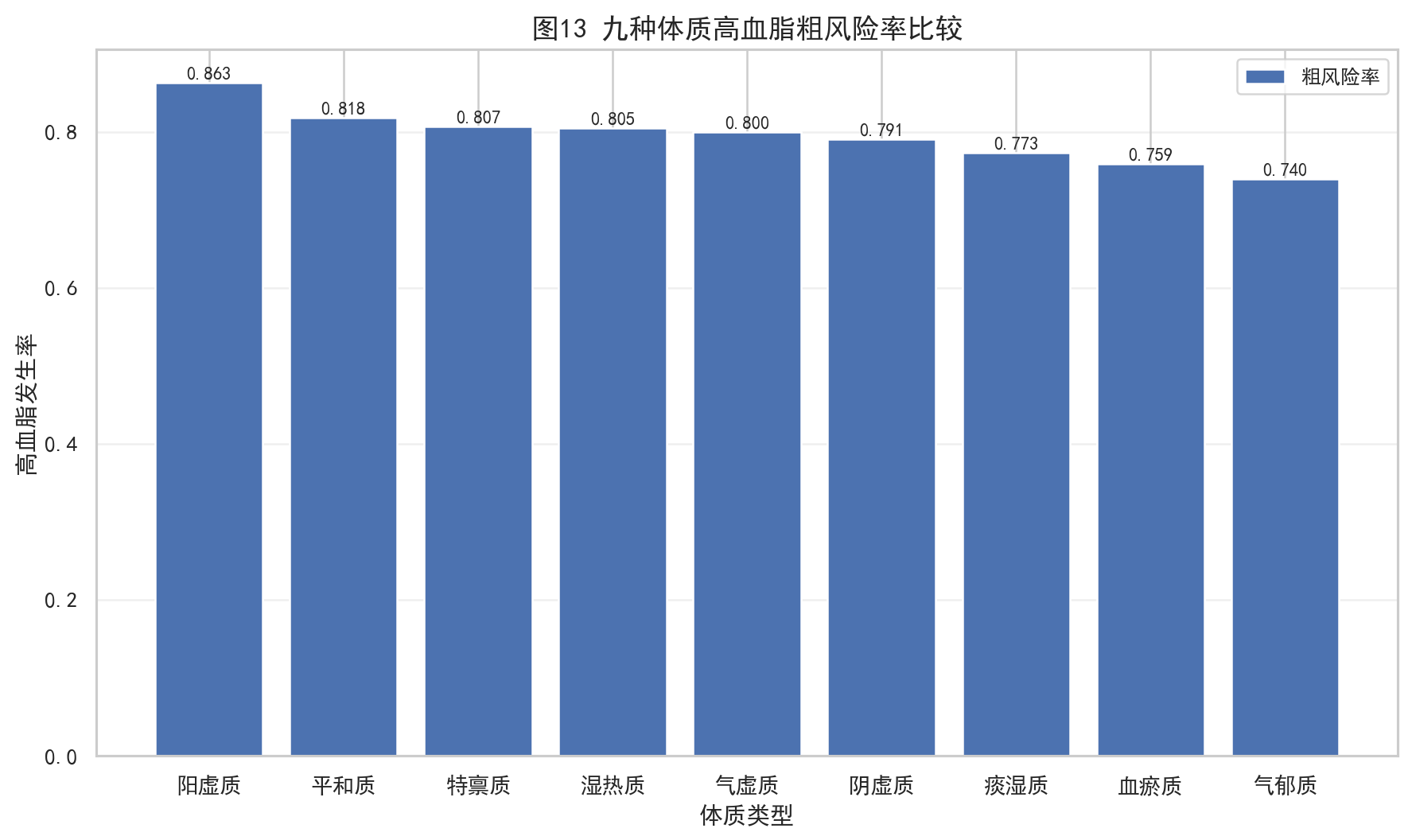
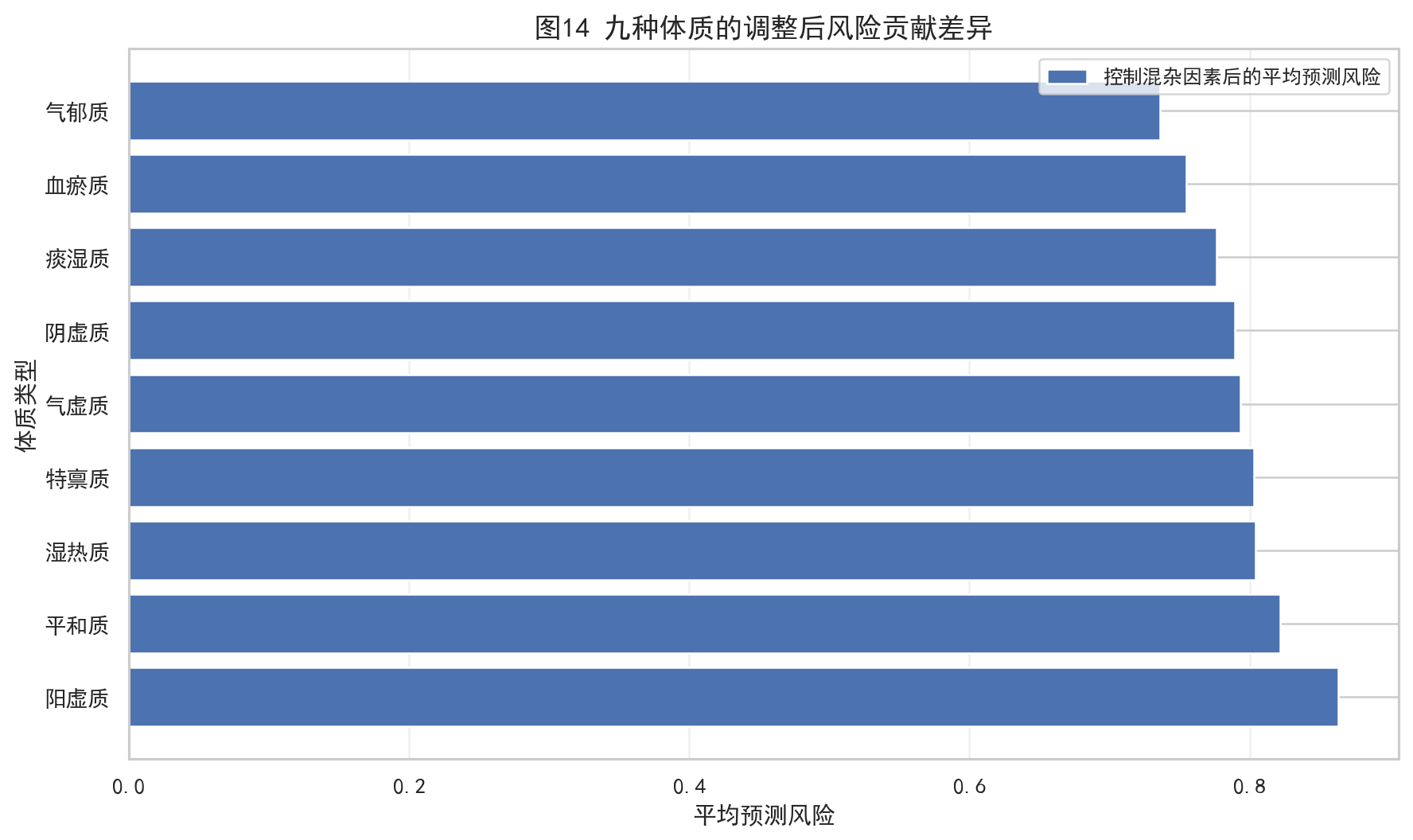
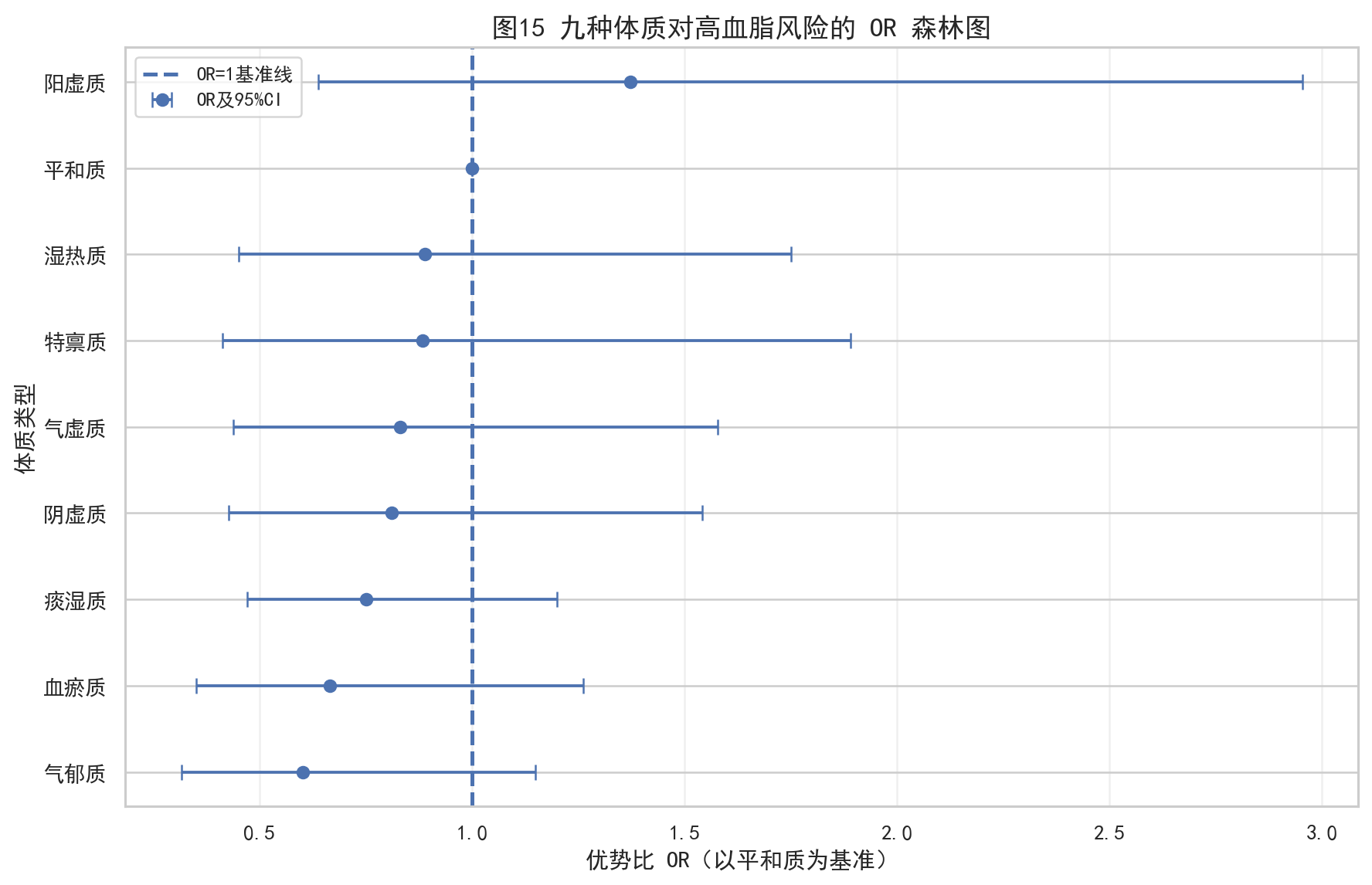
4.7 第一问小结
如果只看第一问,我觉得最重要的结论有三条:
- TG、TC 是最核心的风险指标。
- 血尿酸、BMI、ADL 总分是非常重要的辅助指标。
- 痰湿积分不太适合直接用简单线性回归去拟合,但它对风险分层仍然有高价值。
这其实直接为第二问铺了路:
既然连续痰湿严重度不好直接回归,不如把它和血脂异常、活动能力一起做成一个 融合风险模型。
5. 第二问:三级风险预警模型怎么搭起来
5.1 这一问的关键,不是"训练个分类器"这么简单
第二问要求输出:
- 低风险
- 中风险
- 高风险
并且还要说明:
- 阈值怎么来的
- 高风险人群有什么典型特征组合
也就是说,这一问不能只是随便丢个 XGBoost 然后报准确率。
因为只要阈值解释不清,这一问就很难写得服人。
所以项目里的做法很实用:
先构建有医学解释的风险分量,再做融合打分,最后再用分类模型泛化这套分层结果。
5.2 特征工程:先把"异常"翻译成模型能理解的量
这一步是整个第二问最有含金量的部分。
代码先根据题面阈值构造血脂异常标记:
python
work['TC偏高'] = (work['TC(总胆固醇)'] > 6.2).astype(int)
work['TG偏高'] = (work['TG(甘油三酯)'] > 1.7).astype(int)
work['LDL-C偏高'] = (work['LDL-C(低密度脂蛋白)'] > 3.1).astype(int)
work['HDL-C偏低'] = (work['HDL-C(高密度脂蛋白)'] < 1.04).astype(int)
work['血脂异常项数'] = work[['TC偏高', 'TG偏高', 'LDL-C偏高', 'HDL-C偏低']].sum(axis=1)再构造代谢异常标记:
python
work['空腹血糖偏高'] = (work['空腹血糖'] > 6.1).astype(int)
work['血尿酸偏高'] = np.where(
((work['性别'] == 1) & (work['血尿酸'] > 428)) |
((work['性别'] == 0) & (work['血尿酸'] > 357)), 1, 0
)
work['BMI偏高'] = (work['BMI'] > 23.9).astype(int)
work['代谢异常项数'] = work[['空腹血糖偏高', '血尿酸偏高', 'BMI偏高']].sum(axis=1)然后进一步从"是否异常"升级到"异常有多严重"。
比如血脂严重度分量定义为:
其中:
活动风险分量则反过来定义成:
也就是说,活动总分越低,风险分量越高。
这一步特别像实际项目里的"特征翻译"过程:不是把原始值硬塞模型,而是把医学规则变成模型能直接利用的结构化信号。
5.3 融合风险得分:专家先验 + 数据驱动
做完分量以后,代码没有直接人工拍脑袋定权重,而是用了一个混合方案:
- 先给一个专家先验权重
- 再用互信息估计数据驱动权重
- 最后做加权融合
核心代码如下:
python
expert_weight = np.array([0.40, 0.25, 0.15, 0.10, 0.10])
mi_weight = mutual_info_classif(domain_df, work['高血脂症二分类标签'], random_state=42)
mi_weight = mi_weight / (mi_weight.sum() + 1e-12)
final_weight = 0.6 * expert_weight + 0.4 * mi_weight
final_weight = final_weight / final_weight.sum()
work['融合风险得分'] = (domain_df.values * final_weight).sum(axis=1)数学上就是:
其中:
- wE是专家先验权重
- wMI是互信息归一化权重
- Sik是第 ii 个样本在第 kk 个风险分量上的得分
- Ri是最终融合风险得分
最终跑出来的融合权重是:
| 分量 | 融合权重 |
|---|---|
| 血脂严重度分量 | 0.5716 |
| 痰湿严重度分量 | 0.1505 |
| 活动风险分量 | 0.0909 |
| 代谢严重度分量 | 0.1065 |
| 体质贡献分量 | 0.0805 |
这个结果很合理:
- 血脂异常还是主轴
- 痰湿积分是第二层核心解释变量
- 活动能力和代谢异常提供补充修正
分量融合权重表
|---------|------|-----------------------|---------------------|
| 分量名称 | 专家权重 | 互信息权重 | 融合权重 |
| 血脂严重度分量 | 0.4 | 0.8289065944850259 | 0.5715626377943817 |
| 痰湿严重度分量 | 0.25 | 0.0012087276734416544 | 0.1504834910694744 |
| 活动风险分量 | 0.15 | 0.0022996607305853967 | 0.0909198642922932 |
| 代谢严重度分量 | 0.1 | 0.11633599304792679 | 0.1065343972192399 |
| 体质贡献分量 | 0.1 | 0.05124902406139642 | 0.08049960962461085 |
5.4 三级风险阈值不是拍脑袋定的
第二问最漂亮的地方,在我看来是 锚点规则 + 分位数阈值 这一套。
代码先定义高风险锚点:
python
high_anchor = (
((work['高血脂症二分类标签'] == 1) & (work['血脂异常项数'] >= 1) & (work['痰湿质'] >= 60))
| ((work['血脂异常项数'] == 0) & (work['痰湿质'] >= 80) &
(work['活动量表总分(ADL总分+IADL总分)'] < 40))
| ((work['血脂异常项数'] >= 2) & (work['痰湿质'] >= 60))
)低风险锚点则是:
python
low_anchor = (
(work['高血脂症二分类标签'] == 0)
& (work['血脂异常项数'] == 0)
& (work['痰湿质'] < 60)
& (work['活动量表总分(ADL总分+IADL总分)'] >= 60)
)然后根据这些锚点样本的分布自动校准阈值:
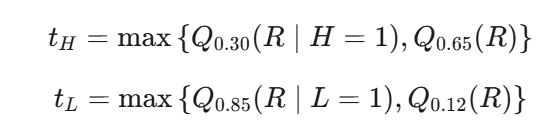
最终得到:
- 低风险阈值 tL=14.5188
- 高风险阈值 tH=39.3546
风险等级定义为:

这个设计特别适合比赛写作,因为它不是"模型自己分出来的",而是:
- 有规则依据
- 有数据校准
- 有连续评分
最后风险分布是:
| 风险等级 | 样本数 | 占比 |
|---|---|---|
| 低风险 | 121 | 12.1% |
| 中风险 | 479 | 47.9% |
| 高风险 | 400 | 40.0% |
另外,痰湿体质人群一共有 278 人,其中高风险 168 人,占比 60.43% ,明显高于总体高风险占比 40.0%。
这也解释了为什么第三问会直接聚焦痰湿体质人群。
5.5 三分类模型:让分层规则能泛化到新样本
在得到三级风险标签以后,代码又做了一步非常工程化的工作:
再训练一个三分类模型,去学习这套风险分层结果。
比较的模型包括:
- 多项逻辑回归
- 随机森林
- 梯度提升树
结果如下:
| 模型 | Accuracy | Macro-F1 | Weighted-F1 |
|---|---|---|---|
| 梯度提升树 | 0.892 | 0.8908 | 0.8919 |
| 随机森林 | 0.864 | 0.8639 | 0.8636 |
| 多项逻辑回归 | 0.836 | 0.8531 | 0.8348 |
最终选的是 梯度提升树。
这一段代码也很简洁:
python
candidates = {
'多项逻辑回归': Pipeline([
('imputer', SimpleImputer(strategy='median')),
('scaler', StandardScaler()),
('model', LogisticRegression(max_iter=3000, class_weight='balanced'))
]),
'随机森林': RandomForestClassifier(
n_estimators=500, min_samples_leaf=2,
class_weight='balanced', random_state=cfg.random_state
),
'梯度提升树': GradientBoostingClassifier(random_state=cfg.random_state)
}测试集三分类混淆矩阵是:
| 真实\预测 | 低风险 | 中风险 | 高风险 |
|---|---|---|---|
| 低风险 | 27 | 3 | 0 |
| 中风险 | 4 | 105 | 11 |
| 高风险 | 0 | 9 | 91 |
也就是说:
- 低风险识别率约 90%
- 中风险识别率约 87.5%
- 高风险识别率约 91%
这已经是一个比较扎实的三级分层模型了。
项目里还专门画了 One-vs-Rest 的 ROC / PR 曲线,核心绘图代码如下:
python
for i, cname in enumerate(['低风险', '中风险', '高风险']):
fpr, tpr, _ = roc_curve(y_bin[:, i], prob[:, i])
roc_auc = auc(fpr, tpr)
plt.plot(fpr, tpr, linewidth=2.2, label=f'{cname} ROC (AUC={roc_auc:.3f})')这类图在博客里非常值得放,因为它能把"不是二分类"的评估方式讲清楚。
5.6 哪些特征真正把风险拉高了
第二问的特征重要性结果很符合直觉:
| 排名 | 特征 | 置换重要性 |
|---|---|---|
| 1 | 血脂异常项数 | 0.3592 |
| 2 | 痰湿质 | 0.2077 |
| 3 | TG(甘油三酯) | 0.1343 |
| 4 | TC(总胆固醇) | 0.0240 |
| 5 | HDL-C(高密度脂蛋白) | 0.0077 |
这说明第二问的风险分层,其实就是围绕三件事展开的:
- 血脂异常有多明显
- 痰湿偏颇有多严重
- 活动能力是否不足
从这个角度看,第二问是对第一问结果的一次验证:
- 第一问筛出来的 TG、TC、ADL,在第二问里继续发挥核心作用
- 痰湿连续积分在第二问里正式被纳入风险评分主轴
5.7 痰湿体质高风险人群的核心特征组合
第二问还有一个很实战的环节:
在 体质标签 = 5 的痰湿体质人群中,挖掘高风险核心特征组合。
这里代码没有做复杂关联规则算法,而是直接用"支持度 + 置信度"筛组合:

结果前几名是:
| 组合 | 支持度 | 置信度 | 命中人数 |
|---|---|---|---|
| 活动总分<60 + TG偏高 | 0.5714 | 0.8496 | 96 |
| 痰湿积分≥60 + 活动总分<60 | 0.5536 | 0.7623 | 93 |
| 活动总分<60 + 血脂异常项数≥2 | 0.5060 | 0.9341 | 85 |
| TG偏高 + 血脂异常项数≥2 | 0.4881 | 0.9535 | 82 |
| 痰湿积分≥60 + TG偏高 | 0.4167 | 1.0000 | 70 |
| 痰湿积分≥60 + TC偏高 | 0.3810 | 1.0000 | 64 |
这组结果很有解释力:
- 低活动能力 在多个高支持度组合里反复出现
- TG / TC 偏高 仍然是最稳定的风险信号
- 当"痰湿高 + TG偏高"叠加时,置信度已经达到 1.0
换句话说,第二问其实已经把第三问的干预重点人群勾勒出来了。
6. 第三问:6 个月个体化干预方案怎么做
6.1 这一问为什么必须上动态规划
第三问不是简单的"给一个方案",而是要针对痰湿体质患者,在 6 个月内考虑:
- 中医调理等级
- 活动干预强度
- 每周训练频次
- 年龄约束
- 活动能力约束
- 总预算约束
更关键的是,患者每个月的痰湿积分会下降,而下一月的中医调理等级又取决于当前积分区间。
这就意味着:当前决策会影响未来状态。
所以第三问最自然的建模方式不是静态优化,而是多阶段序贯决策。项目里的实现选择了 动态规划,这个选择我认为非常对题。
6.2 先把约束和收益写清楚
第三问在代码里把题面条件转成了明确的规则。
中医调理等级
根据当前月痰湿积分自动确定:
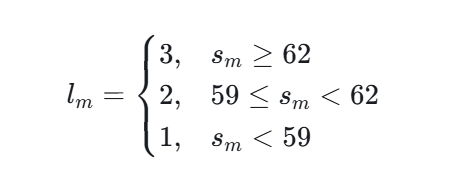
活动强度上限
由年龄和活动能力双重约束:
其中:
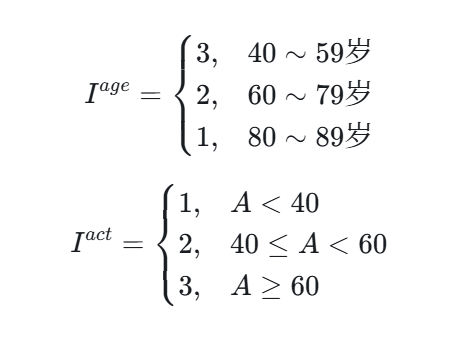
月度降分率
代码把题目里"每提升一级强度,月降约 3%;每周增加 1 次,月降约 1%"写成了:
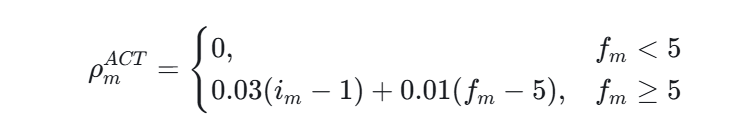
再叠加中医调理基础降分率:

并考虑年龄、活动能力和代谢异常修正后,得到总降分率:
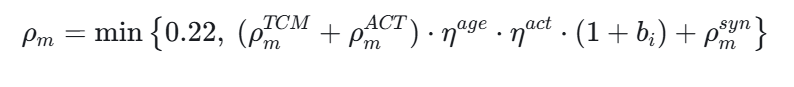
状态更新为:
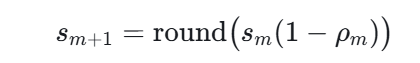
目标函数
最终不是单纯最小化末期痰湿积分,而是兼顾成本、时长和执行负担:
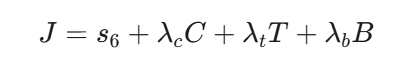
项目中取值为:
- λc=0.008
- λt=0.0003
- λb=0.15
这几个权重就是在做一个非常典型的建模平衡:
- 痰湿积分越低越好
- 但不能一味堆高频高强度
- 也不能为了最优值无视预算和依从性
6.3 动态规划核心代码
第三问的核心代码非常值得看,因为它真正体现了"代码背后的建模思路"。
python
def optimize_patient_plan(row, cfg):
init_score = int(round(float(row['痰湿质'])))
max_intensity = get_allowed_max_intensity(
int(row['年龄组']),
float(row['活动量表总分(ADL总分+IADL总分)'])
)
actions = [(i, f) for i in range(1, max_intensity + 1) for f in range(1, 11)]
states = {
init_score: {'cost': 0.0, 'time': 0.0, 'burden': 0.0, 'path': []}
}
for month in range(1, cfg.months + 1):
new_states = {}
for score, info in states.items():
for intensity, freq in actions:
reduction, tcm_level = monthly_reduction_rate(score, intensity, freq, row)
next_score = int(round(max(0, score * (1 - reduction))))
month_cost = TCM_COST[tcm_level] + 4 * ACTIVITY_COST_PER_SESSION[intensity] * freq
month_minutes = 4 * (10 * intensity) * freq
month_burden = max(0, freq - 8) ** 2 + max(0, intensity - 2) ** 2
if info['cost'] + month_cost > cfg.budget_cap:
continue
candidate = {
'cost': info['cost'] + month_cost,
'time': info['time'] + month_minutes,
'burden': info['burden'] + month_burden,
'path': info['path'] + [(month, tcm_level, intensity, freq, next_score)]
}
keep = new_states.get(next_score)
if keep is None or candidate['cost'] < keep['cost']:
new_states[next_score] = candidate
states = new_states这段代码做了三件事:
- 把每个月视为一个阶段
- 把"当前痰湿积分"视为状态
- 把"强度 + 频次"视为动作
最后再从所有终态里选目标函数最小的那条路径:
python
objective_value = (
final_score
+ cfg.lambda_cost * info['cost']
+ cfg.lambda_time * info['time']
+ cfg.lambda_burden * info['burden']
)这就是一个很典型的工程化动态规划写法。
6.4 第三问整体结果:群体层面表现怎么样
第三问最终优化了 278 位痰湿体质患者,整体结果非常完整:
- 平均初始痰湿积分:59.83
- 平均最终痰湿积分:35.06
- 平均总降分值:24.77
- 平均总降分率:41.36%
- 平均总成本:1179.67 元
- 平均总训练时长:3635.25 分钟
另外几个很有参考价值的范围数据:
- 成本范围:794 元 到 1602 元
- 最终痰湿积分范围:28 到 44
- 总降分率范围:28.81% 到 54.10%
这个结果说明动态规划模型并没有一味追求最低分,而是在预算约束下找到了一组比较平衡的方案。
6.5 最优策略长什么样:不是"越猛越好"
第三问里,代码还把结果归纳成了几类更容易理解的策略:
活动策略分布
| 活动策略 | 人数 |
|---|---|
| 中强稳态 | 99 |
| 强化推进 | 87 |
| 低强高频 | 74 |
| 保守维持 | 18 |
中医策略分布
| 中医策略 | 人数 |
|---|---|
| 基础维持 | 100 |
| 强化后递减 | 90 |
| 中度后递减 | 88 |
再看不同活动策略的均值:
| 活动策略 | 平均最终积分 | 平均降分率 | 平均成本 |
|---|---|---|---|
| 中强稳态 | 32.41 | 45.30% | 1310.26 |
| 强化推进 | 32.06 | 46.67% | 1337.47 |
| 低强高频 | 40.19 | 32.24% | 891.84 |
| 保守维持 | 43.00 | 31.61% | 882.00 |
这个结果特别值得复盘:
- 强化推进 / 中强稳态 效果最好,但成本和时长更高
- 低强高频 虽然降分没有那么猛,但对低活动能力和高龄患者更友好
- 保守维持 更像是强约束下的妥协解
所以第三问不是简单地告诉你"高风险就用高强度",而是给出了一个更现实的结论:
干预方案必须跟年龄、活动能力和预算匹配,不能只看最终积分。
6.6 样本 1、2、3 的最优方案
题目要求必须给出样本 1、2、3 的最优方案,这部分项目里已经单独导出了 Excel 明细。
样本 1
- 初始痰湿积分:64
- 最终痰湿积分:42
- 总降分值:22
- 总降分率:34.38%
- 总成本:940 元
- 综合方案:强化后递减 + 低强高频
关键序列:
- 中医等级序列:3-1-1-1-1-1
- 活动强度序列:1-1-1-1-1-1
- 活动频次序列:8-10-9-9-9-10
这说明样本 1 的主要限制不是预算,而是 最大允许强度只有 1 。
所以它最优的方式不是"加大强度",而是"前期中医强化 + 后期低强高频维持"。
样本 2
- 初始痰湿积分:58
- 最终痰湿积分:31
- 总降分值:27
- 总降分率:46.55%
- 总成本:1300 元
- 综合方案:基础维持 + 强化推进
关键序列:
- 中医等级序列:1-1-1-1-1-1
- 活动强度序列:2-2-2-2-2-2
- 活动频次序列:10-9-10-9-10-8
样本 2 的特点是:
中医调理并不需要升级,但活动能力允许持续使用 2 级强度,所以最优解偏向"稳定推进型"。
样本 3
- 初始痰湿积分:59
- 最终痰湿积分:28
- 总降分值:31
- 总降分率:52.54%
- 总成本:1494 元
- 综合方案:中度后递减 + 强化推进
关键序列:
- 中医等级序列:2-1-1-1-1-1
- 活动强度序列:2-3-3-2-2-2
- 活动频次序列:9-8-9-9-10-8
样本 3 是三位样本里效果最强的一个。
它最像一种"先冲一段,再回到稳态"的策略。
一个很有意思的现象:预算平台
项目里还画了预算敏感性图。
从图上能明显看到:
- 样本 1 大约在 1000 元 左右进入平台
- 样本 2 大约在 1400 元 左右进入平台
- 样本 3 大约在 1600 元 左右进入平台
这说明不同患者的"最优预算上限"并不一样。
预算不是越多越好,超过某个区间后,收益会明显递减。
6.7 患者特征如何映射到最优方案
第三问最后还做了一件非常适合写博客的事:
把"最优方案"重新总结成 可解释规则。
代码用浅层决策树学习:
python
tree = DecisionTreeClassifier(max_depth=4, min_samples_leaf=15, random_state=42)
tree.fit(X, y)
rule_text = export_text(tree, feature_names=feature_cols)同时又做了分箱统计,得到一个更适合展示的匹配表:
| 痰湿分组 | 活动能力分组 | 代表性活动策略 |
|---|---|---|
| 低痰湿 | 低活动 | 低强高频 |
| 低痰湿 | 中活动 | 中强稳态 |
| 低痰湿 | 高活动 | 强化推进 |
| 临界痰湿 | 低活动 | 低强高频 |
| 临界痰湿 | 中活动 | 中强稳态 |
| 临界痰湿 | 高活动 | 强化推进 |
| 较高痰湿 | 低活动 | 低强高频 |
| 较高痰湿 | 中活动 | 强化推进 |
| 较高痰湿 | 高活动 | 强化推进 |
这张表非常适合放在博客里,因为它把整个第三问从"算法结果"提升成了"经验规律":
- 低活动 人群优先用 低强高频
- 中活动 人群更适合 中强稳态
- 高活动 且痰湿较高的人群,可以上 强化推进
这一步其实就是把第三问从"算答案"变成了"提策略"。
7. 整体结果总结与建模反思
7.1 这套方案最大的优点
我觉得这份项目最值得肯定的地方有四个:
1. 三问之间逻辑非常顺
不是三道分散的小题,而是标准的项目链路:
- 第一问找指标
- 第二问定风险
- 第三问出方案
2. 解释性和效果兼顾
第二问没有完全走黑箱路线,而是先做规则分量,再做模型泛化。
这让结果既能解释,又能推广。
3. 第三问选动态规划很贴题
因为状态会随月份变化,所以动态规划比一次性静态优化更自然,也更能生成"前期强化、后期递减"这种真实方案。
4. 输出结果很完整
项目里不仅有模型结果,还有大量图表和 CSV 输出。
这对比赛答辩、论文撰写和赛后复盘都非常友好。
7.2 这份项目的不足也很明显
复盘不能只讲优点,几个值得诚实指出的问题是:
1. 第一问的痰湿回归效果偏弱
LASSO 回归的 R2<0R2<0,说明当前候选指标并不适合直接线性回归连续痰湿积分。
这部分更适合作为"发现问题"的结论,而不是"模型成功"的展示。
2. 九种体质 OR 结果显著性不强
从输出表看,体质贡献排序可以作为相对比较,但不适合写成"显著性结论"。
3. 第三问里有工程化假设
比如中医调理基础降分率 2%/4.5%/7%2%/4.5%/7%,以及目标函数中的权重,都是代码中人为设定的。
这很正常,但如果要进一步严谨化,需要更多随访数据去校准。
4. 第三问目前更像"单体优化"
虽然已经做了 278 人批量求解,但本质上还是逐个患者独立优化。
如果未来扩展到真实场景,可以再加入群体资源约束,比如总医生资源、社区活动容量等。
7.3 如果我继续迭代这份项目
如果这份项目继续往下做,我会优先考虑三件事:
- 给第一问补更强的非线性痰湿表征模型,比如树模型回归或分段回归。
- 给第二问补更完整的阈值稳定性分析,比如更系统的分位数扰动实验。
- 给第三问补"群体资源约束"或"多目标 Pareto 前沿",让优化从单人方案走向群体调度。
8. 完整复盘总结
这次 C 题最有价值的,不是某一个模型有多复杂,而是它很适合训练一种完整的问题拆解能力:
- 先识别关键变量
- 再建立可解释的风险体系
- 最后把识别结果转成决策方案
从代码落地上看,这份项目也有很强的复用价值:
- 第一问的多源特征筛选框架,可以复用于任何"指标筛选 + 风险分类"类题目
- 第二问的"规则锚点 + 融合得分 + 三分类模型"结构,很适合慢病风险分层问题
- 第三问的动态规划模板,基本可以迁移到任何"分阶段健康干预 / 补货 / 调度"型题目
如果把这次竞赛复盘浓缩成一句话,我会这么说:
这不是一份只会"跑代码"的解法,而是一份从指标、风险到干预逐层推进的完整建模方案
需要代码请在作者的评论区下方留言领取,制作不易,请点个关注和收藏