C语言基础(一)
C语言介绍
编程语言
指编写计算机程序(即代码)的语⾔
可以通过是否需要编译来区分为编译型语言和解释性语言:
编译型语言:C C++ JAVA GO等
解释性语言:JavaScript python php等
也可以根据特性来区分:
面向过程:C JavaScript(两者皆可) python(两者皆可)等
面向对象:Java C++ C# 等
C语言
起源可以追溯到1972年,由⻉尔实验室的Dennis Ritchie开发,最初是为了开发UNIX操作系统⽽设
计的⼀种⾼级编程语⾔
在1978年,美国国家标准学会(ANSI)发表了C语⾔的第⼀个标准,被称为ANSIC或C89
1990年,国际标准化组织(ISO)也发布了⼀个与ANSIC兼容的国际标准,称为ISO C90
1999年,ISO发布了⼀个新的C语⾔标准,称为C99
2011年,ISO发布了最新的C语⾔标准,称为C11
C17/C18(ISO/IEC 9899:2017/2018): 这个版本主要是对C11的⼀个技术修正版,旨在修复已知问题⽽不添加重⼤新功能
特点:
1、系统编程
2、高效性
3、可移植性
4、轻量灵活
5、通用语言
C程序标准架构
文件以.c结尾,有I/O头文件,main主函数和返回值
eg:
C语言编译过程
在Linux系统中,需要将.c文件编译输出为.out文件才能执行,而在Windows当中则需要将.c文件编译为.exe文件
编译是指将高级语言翻译为机器语言,即将我们能读懂的人类语言翻译为机器能识别的二进制语言
使用gcc(GNU Complier Collection)
gcc工作流程:
预处理 --> 编译 --> 汇编 --> 链接
.c --> .i --> .s --> .o
预处理阶段:
包含了去掉注释,加载头⽂件,代替宏定义,条件编译等内容,这个阶段就会把.c编译成.i
后缀的同名⽂件。gcc -E xxx.c -o xxx.i
编译阶段:
经过语法分析和优化之后将源代码⽣成相应的汇编代码的过程。得到.s文件,汇编语言原始程序。gcc -S xxx.i -o xxx.s
汇编阶段 :
将第⼆步⽣成的汇编语⾔转为机器码⽂件。得到.o文件。gcc -c xxx.s -o xxx.o
链接阶段:
将第三步的机器码⽂件和其他引⼊的头⽂件及相关的⽂件进⾏链接,然后打包为⼀个最终可执⾏的⽂件。gcc xxx.o -o xxx
gcc参数:
-E:预编译,生成.i预编译文件
-S:汇编,生成.s汇编源文件
-c:只编译,不生成可执行文件,通常用于编译不包含主程序的子程序文件,将.c生成.o文件
-o:产生目标文件,不给文件输出名默认a.out
C语言注释
注释分为单行和多行
单行:最前面加 // ,符号所在行符号后面所有内容会被注释掉
多行:/**/,在/*和*/之间的所有内容会被注释掉
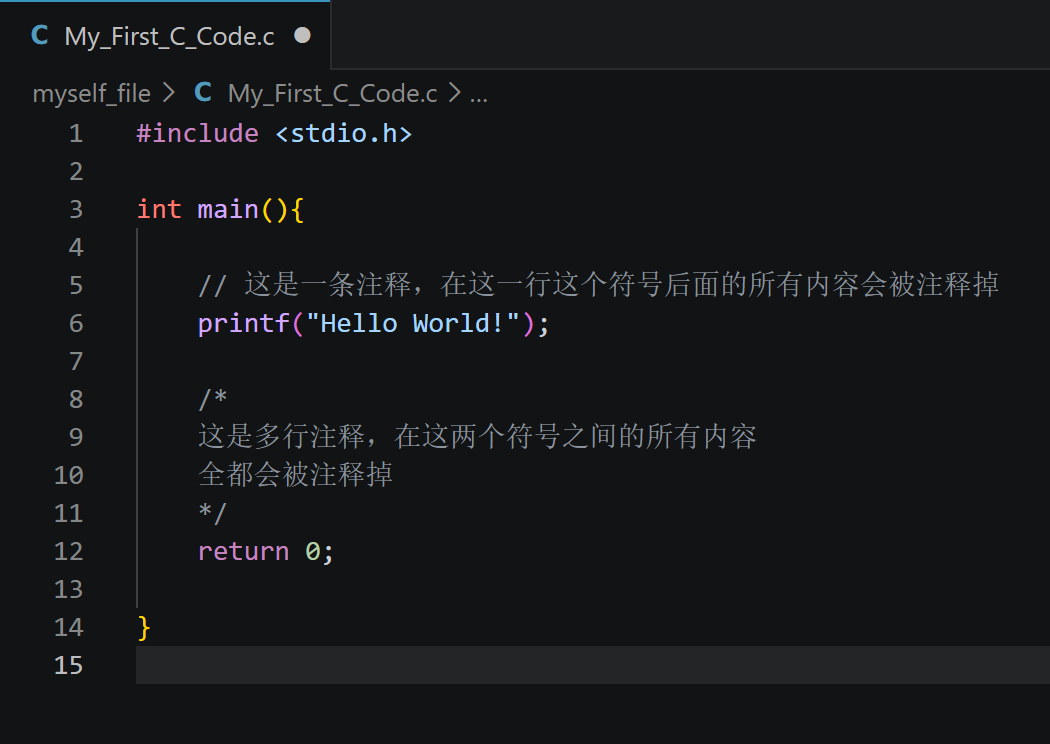
注释还是很有必要的,毕竟能增加代码可读性,标注代码的功能和参数等其他的东西,也方便后续的维护(主要是过比较久后你也不一定记得你写了个啥玩意儿)
C语言的变量
变量指可以保存数据的容器,定义变量并且赋值后,就可以在程序中反复使用某个数据
语法:
数据类型 变量名;
数据类型 变量名1,变量名2 ... //定义多个变量
数据类型 变量名 = 数据; // 定义数据并赋值
修改变量的值和赋值一样:
变量名 = 新数据;
相当于直接用新的值覆盖掉原来的值
变量名规范:
1、字母数字下划线,变量名赋值只能在0-9 a-z A-Z _之间选择,而其中下划线开头一般有特殊作用,不建议用下划线开头
2、不能以数字开头
3、避免关键字
4、建议使用驼峰命名法命名
5、不能重复定义,需要先定义再使用
变量的本质
在C语⾔中,变量的本质是⼀个内存位置的名字或标识符。这个内存位置⽤于存储特定类型的数据,⽐如整数、浮点数或其他数据类型。当你声明⼀个变量时,实际上是请求系统为你分配⼀定数量的内存空间来存储该变量的值。这个内存空间的⼤⼩取决于变量的数据类型。
(1)c语⾔程序的执⾏过程
加载程序到内存中
当你运⾏⼀个C程序(a.out)时,操作系统会先创建⼀个进程,并利⽤系统加载器会将你的程序(也就是编译后⽣成的可执⾏⽂件,⽐如a.out)加载到内存(Ram)中。这个过程包括将程序的代码(指令)和初始数据加载到内存的不同部分。
分配内存给变量
在C程序中,当你声明变量时,编译器会根据变量的类型来为它分配内存空间。例如,如果你声明了⼀个整型int变量,编译器可能会在内存中为该变量分配4个字节(具体⼤⼩取决于编译器和平台)。
程序执⾏
程序⼀旦开始执⾏(即主线程执⾏main函数),CPU会从内存中读取指令和操作数据。这包括执⾏算术运算、控制结构、函数调⽤等。(这部分信息在进程的pcb:程序控制块中)
程序结束
当程序执⾏完成后,变量的⽣命周期随着代码的退出⽽结束,操作系统负责清理进程(可执⾏⽂件本身)使⽤的所有资源,包括释放所有的内存。
(2)内存划分
c语⾔在执⾏程序时,会给改程序创建⼀个进程⽤于加载该程序以及执⾏程序。进程本身会得到⼀个固定⼤⼩的虚拟内存空间。那么虚拟空间和物理空间会通过MMU来进⾏映射。进程会认为⾃⼰的空间是⼀段连续空间,但实际使⽤的物理内存是分散的。⽽每个进程的虚拟空间就⼀般会划分为5个区域:栈、堆、全局或静态区、常量区、代码区。
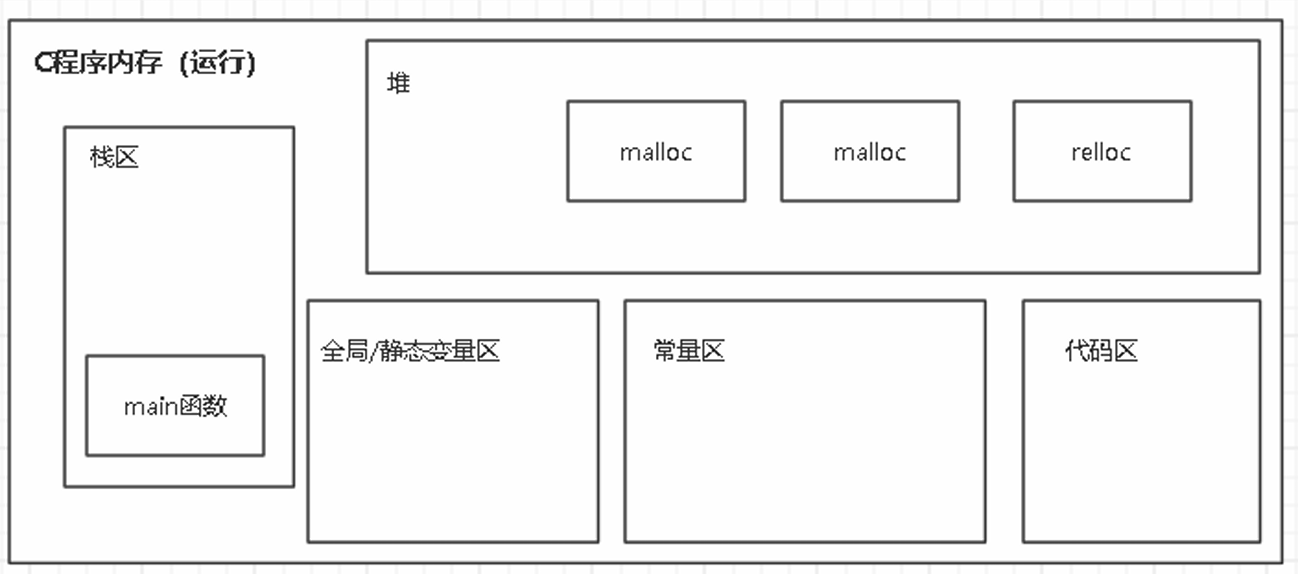
栈区(Stack):
⽣命周期:函数调⽤时创建栈帧并进⾏⼊栈,函数调⽤结束时进⾏出栈及释放函数调⽤所占内存。
⽤于存储局部变量和函数调⽤时的信息。每⼀次函数调⽤,栈区都会划分⼀部分空间来保存该函数执⾏的情况以及局部变量,简称函数帧
由编译器⾃动管理,当⼀个函数被调⽤时,其参数和局部变量会被推⼊栈中;当函数返回时,这些参数和变量会被清除(出栈)。
总结:c程序运⾏时系统会分配⼀块空间(固定)来作为栈的数据结构,栈的每⼀个数据(栈帧)都是保存函数调⽤⼀次要使⽤的局部变量、函数返回地址、参数等,当任意函数调⽤时,栈就会创建⼀个栈帧,该栈帧中就包含该次函数调⽤要使⽤的各种数据(局部变量、参数、返回地址),当函数调⽤完毕,该栈帧就会被释放(出栈),栈帧⾥⾯的内容也会被释放。
⼯作流程
当程序启动时,就会在栈中分配⼀个函数帧⽤于保存main函数要使⽤的局部变量以及其他内
容。当main函数⾥调⽤其他函数(⽐如demo),栈就会新建⼀个函数栈并进⾏⼊栈,作为
栈顶,当函数结束后,出栈,出栈后,main函数栈⼜变成栈顶(当前执⾏函数)
堆(Heap):
⽣命周期:动态分配时创建,分配的空间必须⼿动释放,直到程序结束。
⽤于动态内存分配,程序员可以在运⾏时使⽤malloc , calloc , realloc 和 free 等函数来分配和释放内存。
管理不善会导致内存泄露或碎⽚化。
全局/静态存储区:
⽤于存储全局变量和静态变量(static)。
⽣命周期:程序启动时创建且⼤⼩固定,程序结束时销毁。具体⼤⼩是由c程序的可执⾏⽂件来决定。
在程序的整个运⾏周期内都存在,直到程序结束。
根据全局变量或静态变量是否显性初始化将区域分为bss段和数据段
bss(Block Started by Symbol)段:存放的是代码中未初始化的变量。在程序启动时,操作系统负责将这些变量初始化为默认值(通常是0或NULL)。
数据段:存放的是代码中被初始化的变量
细节:
对于静态变量,如果定义位置仍在函数外⾯,那么就跟普通的全局变量是⼀样的。但如果静
态变量定义在某个函数内。虽然静态变量存在全局内存区域,不会随着函数调⽤的结束⽽释
放,但同时会限制该静态变量的活动返回仅限该函数⾥。
全局变量默认都会进⾏初始化。初始化为{0}
代码区:
存储程序的⼆进制代码,⽐如函数等代码。
通常是只读的,尝试写⼊这部分内存通常会导致程序崩溃。
代码区的⼤⼩在程序编译时通常是固定的,因为它包含了程序的实际可执⾏指令
总结:程序中可能会⽤到的函数就会存放在这区域。当要执⾏某个函数时,程序会在该区域中找到要执⾏函数的代码,并封装成⼀个栈帧,并给局部变量和参数分配空间(栈中),分配后就进⾏⼊栈并执⾏函数⾥的代码。
常量区(只读数据段):
常量区存储常量数据,如字符串常量以及⽤const定义的变量。
尝试修改常量区的数据会导致错误。
在程序运⾏时⼤⼩固定。
栈与堆的区别:
管理⽅式不同:堆的申请malloc()与释放free()由程序员来完成,栈由系统编译器⾃动分配
空间⼤⼩不同:堆空间⼤于栈空间
栈在内存中连续分配,不会产⽣碎⽚。堆的频繁申请可能造成内存空间的不连续性,产⽣⼤量碎⽚
增⻓⽅式不同:栈向内存地址减⼩的⽅向增⻓,堆则相反
分配效率不同:栈的申请效率通常⾼于堆,计算机在底层提供寄存器存放栈的地址,压栈出栈有专⻔的指令;堆由c函数库提供,动态内存分配需要有⼀定的算法去寻找申请⾜够⼤的地址空间。
数据类型
基本数据类型:
整形 字符型 浮点型 布尔型(C99标准新增)
int/short/long char float/double bool
构造数据类型:
数组 结构 联合 枚举
指针类型
空类型
| 数据类型 | 存储大小 | 值范围 | 描述 |
|---|---|---|---|
| char | 1字节 | -128 -- 127 / 0 -- 255 | 存储字符类型数据 |
| int | 4字节 | -2147483648 -- 2147483647 | 存储整数 |
| short | 2字节 | -32768 -- 32767 | 存储较小整数 |
| long | 8字节 | -2147483648 -- 2147483647/更大 | 存储较大整数 |
| unsigned short | 依基类型决定 | 0 -- 65535 / 0 -- 4294967295 | 存储非负数 |
| bool | 1字节 | true(1)/ false(0) | 存储布尔值,需要stdbool.h头文件 |
| float | 4字节 | 1.2E-28 -- 3.4E+38 | 存储单精度浮点数 |
| double | 8字节 | 2.3E-308 -- 1.7E+308 | 存储双精度浮点数 |
输入和输出
输出:
puts() // 只能输出字符串,且输出结束后会自动换行
putchar() // 只能输出单个字符
printf() // 可以输出各种类型数据,搭配格式符和附加格式说明符使用
格式符作⽤:
| 格式符 | 作用 |
|---|---|
| d | ⼗进制整数(%d--int, %hd--short, %ld--long) |
| x,X | ⼗六进制⽆符号整数 |
| o | ⼋进制⽆符号整数 |
| u | ⽆符号⼗进制整数 |
| c | 单⼀字符 |
| s | 字符串 |
| e,E | 指数形式浮点⼩数 |
| f | ⼩数形式浮点⼩数(float--%f, double--%lf) |
| 修饰符 | 功能 |
|---|---|
| w | 输出数据域宽,数据⻓度<m,左补空格;否则按实际输出 |
| .p | 对实数,指定⼩数点后位数(四舍五⼊), 对字符串,指定实际输出位数 |
| - | 输出数据在域内左对⻬(缺省右对⻬) |
| + | 指定在有符号数的正数前显示正号(+) |
| 0 | 输出数值时指定左⾯不使⽤的空位置⾃动填0 |
| # | 在⼋进制和⼗六进制数前显示前导0,0x |
| l | 在d, o, x, u前,指定输出精度为long型 |
| l | 在e, f, g前,指定输出精度为double型 |
输入:
| 语句 | 功能 | 示例 |
|---|---|---|
| getchar() | ⽤于输⼊单个字符 | char c; c = getchar(); |
| scanf() | 接收键盘输⼊的不同类型的数据,并且将其保存到指定的内存地址中 | int a;scanf("%d", &a); // 输⼊整数并赋值给变量a ,其中&是取址符号,⽤于获取变量的内存地址,主要是⽤于能够获取数据后赋给对应的变量 |
scanf:
格式:scanf("格式控制串", 地址表);
功能:按指定格式从键盘读取数据,存入地址表指定存储单元中,并按回车结束
地址表:变量的地址,常用取地址运算符&
| 格式符号 | 作⽤ |
|---|---|
| d | ⼗进制整数 |
| x, X | ⼗六进制⽆符号整数 |
| o | ⼋进制⽆符号整数 |
| u | ⽆符号⼗进制整数 |
| c | 单⼀字符 |
| s | 字符串 |
| e | 指数形式浮点⼩数 |
| f | ⼩数形式浮点⼩数 |
| 修饰符 | 功能 |
|---|---|
| h | ⽤于d, o, x前,指定输⼊为short型整数 |
| l | ⽤于d, o, x前,指定输⼊为long型整数 ,⽤于e, f前,指定输⼊为double型实数 |
| m | 指定输⼊数据宽度,遇空格或不可转换字符结束 |
| * | 抑制符,指定输⼊项读⼊后不赋给变量 |
putchar:
格式:putchar©
参数:c为字符常量,变量或表达式
功能:把字符c输出到显示器上
puts:
格式:puts(str)
参数:str为字符串
功能:把字符串str输出到显示器上,用puts显示字符时,会自动在后面添加一个换行符