摘要
1. 混合检索
混合检索(Hybrid Search)是一种结合了稀疏向量(Sparse Vectors) 和 密集向量(Dense Vectors) 优势的先进搜索技术。旨在同时利用稀疏向量的关键词精确匹配能力和密集向量的语义理解能力,以克服单一向量检索的局限性,从而在各种搜索场景下提供更准确、更鲁棒的检索结果。
混合检索 = 关键词检索(BM25) + 向量检索(Embedding) + 归一化 + 融合算法(如 RRF)。 它不改变底层索引结构,而是在查询时并行调用两种检索器,再用一个聪明的数学公式把两套排名合并 。最终效果就是:既能像搜索引擎一样精确匹配术语,又能像向量数据库一样理解语义,兼顾精确率和召回率。
1.1. 稀疏向量 vs 密集向量
1.1.1. 稀疏向量
稀疏向量,也常被称为"词法向量",是基于词频统计的传统信息检索方法的数学表示。它通常是一个维度极高(与词汇表大小相当)但绝大多数元素为零的向量。它采用精准的"词袋"匹配模型,将文档视为一堆词的集合,不考虑其顺序和语法,其中向量的每一个维度都直接对应一个具体的词,非零值则代表该词在文档中的重要性(权重)。这类向量的经典权重计算方法是 TF-IDF。在信息检索领域,BM25则是基于这种稀疏表示的成功且应用广泛的排序算法之一,其核心公式如下:
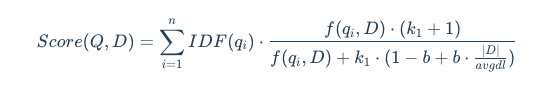
其中:
- IDF(qi) 查询词 qi的逆文档频率,用于衡量一个词的普遍程度。越常见的词,IDF值越低。
- f(qi,D): 查询词 qi在文档 D中的词频。
- ∣D∣: 文档 D的长度。
- avgdl*:*集合中所有文档的平均长度。
- k1,b:可调节的超参数。 k1用于控制词频饱和度(一个词在文档中出现10次和100次,其重要性增长并非线性), b用于控制文档长度归一化的程度。
这种方法的优点是可解释性极强(每个维度都代表一个确切的词),无需训练,能够实现关键词的精确匹配,对于专业术语和特定名词的检索效果好。主要缺点是无法理解语义,例如它无法识别"汽车"和"轿车"是同义词,存在"词汇鸿沟"。
1.1.2. 密集向量
密集向量,也常被称为"语义向量",是通过深度学习模型学习到的数据(如文本、图像)的低维、稠密的浮点数表示。这些向量旨在将原始数据映射到一个连续的、充满意义的"语义空间"中来捕捉"语义"或"概念"。在理想的语义空间中,向量之间的距离和方向代表了它们所表示概念之间的关系。一个经典的例子是 vector('国王') - vector('男人') + vector('女人') 的计算结果在向量空间中非常接近 vector('女王'),这表明模型学会了"性别"和"皇室"这两个维度的抽象概念。它的代表包括 Word2Vec、GloVe、以及所有基于 Transformer 的模型(如 BERT、GPT)生成的嵌入(Embeddings)。
其主要优点是能够理解同义词、近义词和上下文关系,泛化能力强,在语义搜索任务中表现卓越。但缺点也同样明显:可解释性差(向量中的每个维度通常没有具体的物理意义),需要大量数据和算力进行模型训练,且对于未登录词(OOV)的处理相对困难。
OOV(Out-of-Vocabulary)未登录词 :指在模型训练时没有出现在词汇表中,但在实际使用时遇到的新词汇。例如,如果模型训练时词汇表中没有"ChatGPT"这个词,那么在实际应用中遇到它时就是OOV。传统的稀疏向量方法(如BM25)对OOV词汇会完全忽略,而现代的密集向量方法通过子词分割(如BPE、WordPiece)可以更好地处理OOV问题。
1.1.3. 稀疏向量 vs 密集向量实例对比
稀疏向量表示: 稀疏向量的核心思想是只存储非零值。例如,一个8维的向量 [0, 0, 0, 5, 0, 0, 0, 9],其大部分元素都是零。用稀疏格式表示,可以极大地节约空间。常见的稀疏表示法有两种:
-
字典 / 键值对 (Dictionary / Key-Value): 这种方式将非零元素的
索引(0-based) 作为键,值作为值。上面的向量可以表示为:// {索引: 值}
{
"3": 5,
"7": 9
} -
坐标列表 (Coordinate list - COO): 这种方式通常用一个元组
(维度, [索引列表], [值列表])来表示。上面的向量可以表示为(8, [3, 7], [5, 9])
这种格式在 SciPy 等科学计算库中非常常见。
假设在一个包含5万个词的词汇表中,"西红柿"在第88位,"炒"在第666位,"蛋"在第999位,它们的BM25权重分别是1.2、0.8、1.5。那么它的稀疏表示(采用字典格式)就是:
// {索引: 权重}
{
"88": 1.2,
"666": 0.8,
"999": 1.5
}如果采用坐标列表(COO)格式,它会是这样:
(50000, [88, 666, 999], [1.2, 0.8, 1.5])这两种格式都清晰地记录了文档的关键信息,但它们的局限性也很明显:如果我们搜索"番茄炒鸡蛋",由于"番茄"和"西红柿"是不同的词条(索引不同),模型将无法理解它们的语义相似性。
密集向量表示: 与稀疏向量不同,密集向量的所有维度都有值,因此使用数组 [] 来表示是最直接的方式。一个预训练好的语义模型在读取"西红柿炒蛋"后,会输出一个低维的密集向量:
// 这是一个低维(比如1024维)的浮点数向量
// 向量的每个维度没有直接的、可解释的含义
[0.89, -0.12, 0.77, ..., -0.45]这个向量本身难以解读,但它在语义空间中的位置可能与"番茄鸡蛋面"、"洋葱炒鸡蛋"等菜肴的向量非常接近,因为模型理解了它们共享"鸡蛋类菜肴"、"家常菜"、"酸甜口味"等核心概念。因此,当我们搜索"蛋白质丰富的家常菜"时,即使查询中没有出现任何原文关键词,密集向量也很有可能成功匹配到这份菜谱。
1.2. 混合检索
通过上文可以看出稀疏向量和密集向量各有千秋,那么将它们结合起来,实现优势互补,就成了一个不错的选择。混合检索便是基于这个思路,通过结合多种搜索算法(最常见的是稀疏与密集检索)来提升搜索结果相关性和召回率。
主要目标 :解决单一检索技术的局限性。例如,关键词检索无法理解语义,而向量检索则可能忽略掉必须精确匹配的关键词(如产品型号、函数名等)。混合检索旨在同时利用稀疏向量的精确性和密集向量的泛化性,以应对复杂多变的搜索需求。
1.2.1. 混合检索技术原理与融合方法
混合检索通常并行执行两种检索算法,然后将两组异构的结果集融合成一个统一的排序列表。以下是两种主流的融合策略:
1.2.1.1. 倒数排序融合 (Reciprocal Rank Fusion, RRF)
RRF 不关心不同检索系统的原始得分,只关心每个文档在各自结果集中的排名。其思想是:一个文档在不同检索系统中的排名越靠前,它的最终得分就越高。
其计分公式为:
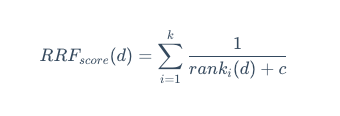
其中:
- d 是待评分的文档。
- k 是检索系统的数量(这里是2,即稀疏和密集)。
- ranki (d ) 是文档 dd 在第 ii 个检索系统中的排名。
- c是一个常数(通常设为60),用于降低排名靠前文档的相对权重,实现更稳健的排名融合。
1.2.1.2. 加权线性组合
这种方法需要先将不同检索系统的得分进行归一化(例如,统一到 0-1 区间),然后通过一个权重参数 α 来进行线性组合。

通过调整 α 的值,可以灵活地控制语义相似性与关键词匹配在最终排序中的贡献比例。例如,在电商搜索中,可以调高关键词的权重;而在智能问答中,则可以侧重于语义。
1.2.2. 混合检索理解
混合检索(Hybrid Search) 就是同时使用"关键词检索"和"向量检索"两种方法,然后把它们的结果智能地合并起来,最终选出最相关的Top-K结果 。它的原理可以概括为:用关键词检索保证精确匹配,用向量检索理解语义意图,两者互补,最后融合排序。
1.2.2.1. 为什么需要混合检索?
单一检索方法都有其固有的"盲点":
|--------------------------------|---------------------------|----------------------------------------------------|----------------------------------------------------|
| 检索方法 | 原理 | 擅长场景 | 致命弱点 |
| 关键词检索 (如 BM25) | 基于词频和逆文档频率,匹配用户输入的精确词汇 | 搜索"iPhone 15 充电口型号"这种包含专有名词、产品型号、代码的查询。 | 无法理解同义词。搜"笔记本电脑"找不到包含"便携式计算机"的文档。 |
| 向量检索 (如 Embedding + 余弦相似度) | 将文本转换为语义向量,在向量空间里找"意思相近"的 | 搜索"如何缓解工作压力?"这种意图和概念相关的查询,能找到讲"冥想、休假、时间管理"的文档。 | 对精确词汇不敏感。搜"GPT-4参数规模"可能会找到一堆讲"大语言模型"但没提"GPT-4"的文档。 |
混合检索的思路就是:两个都上,取长补短。
1.2.2.2. 步骤一:并行执行两种检索
当用户输入一个查询(比如:"2023年财报中关于净利润增长的描述")时,系统同时做两件事:
- 关键词检索(通常是BM25算法) :把查询拆成词("2023"、"财报"、"净利润"、"增长"),在倒排索引中快速找到包含这些词的文本块。得到一个相关性分数(比如
docA: 0.85)。 - 向量检索(Embedding模型) :把整个查询转成一个向量,在整个向量数据库中做相似度搜索。找到语义上最接近的文本块,得到另一个相似度分数(比如
docA: 0.92)。
1.2.2.3. 步骤二:归一化(Normalization)------ 关键一步
这里有个问题:关键词检索的分数(如 BM25 分数可以是0到无穷大)和向量检索的分数(通常是0到1之间的余弦相似度)量纲不同,不能直接相加 。所以需要归一化 ,把两种分数都映射到一个可比的区间,比如 [0, 1]。常用方法:
- Min-Max归一化
- 对数变换
- Rank归一化(只关心排序位置,不关心原始分数)
1.2.2.4. 步骤三:融合与重排序(Fusion & Re-ranking)
归一化后,用融合算法 把两个分数合并成一个最终分数,然后按最终分数排序,取出Top-K。最常用且鲁棒的融合算法是 RRF(倒数排名融合,Reciprocal Rank Fusion)。
final_score(doc) = Σ ( 1 / (k + rank_i(doc)) )rank_i(doc):该文档在第 i 种检索方法中的排名(第1名、第2名...)。k:一个常数,通常取60,用于平滑排名的影响。
1.2.2.5. 混合检索 vs. 单一检索
|----------|----------------------------|----------------------------------------------|--------------------------------|------------------------|
| 场景 | 用户查询 | 纯关键词检索 | 纯向量检索 | 混合检索 (Hybrid) |
| 精确匹配 | "iPhone 15 USB-C 接口速率" | ✅ 精准找到包含这些词的技术文档 | ❌ 可能找到一堆讲"接口"、"速率"但没提具体型号的通用文档 | ✅ 关键词部分保证精确命中 |
| 语义理解 | "怎么让团队工作效率更高?" | ❌ 只找包含"工作"、"效率"、"高"这些词的文档,可能漏掉讲"敏捷开发"、"OKR"的 | ✅ 能理解"效率高"的同义词和上下文,找到相关方法论 | ✅ 向量部分召回语义相关文档 |
| 复杂查询 | "2024年发布的、作者是李明的、关于RAG的论文" | ✅ 精确匹配"2024"、"李明"、"RAG" | ❌ 可能会把"2023年"、"王芳"的相似论文也混进来 | ✅ 两者互补,精确+语义 |
1.2.3. 混合检索优势与局限
|---------------------------------------|--------------------------------|
| 优势 | 局限 |
| 召回率与准确率高:能同时捕获关键词和语义,显著优于单一检索。 | 计算资源消耗大:需要同时维护和查询两套索引。 |
| 灵活性强:可通过融合策略和权重调整,适应不同业务场景。 | 参数调试复杂:融合权重等超参数需要反复实验调优。 |
| 容错性好:关键词检索可部分弥补向量模型对拼写错误或罕见词的敏感性。 | 可解释性仍是挑战:融合后的结果排序理由难以直观分析。 |
1.3. 通过 Milvus 实现混合检索示例
接下来使用 Milvus 来实现一个完整的混合检索流程,从定义 Schema、插入数据,到执行查询。
1.3.1. 定义 Collection
在上一章中我们实现了多模态图文检索,现在还是同样的步骤先创建一个 Collection。
import json
import os
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com"
import numpy as np
from pymilvus import connections, MilvusClient, FieldSchema, CollectionSchema, DataType, Collection, AnnSearchRequest, RRFRanker
from pymilvus.model.hybrid import BGEM3EmbeddingFunction
# 1. 初始化设置
COLLECTION_NAME = "dragon_hybrid_demo"
MILVUS_URI = "http://localhost:19530" # 服务器模式
DATA_PATH = "../../data/C4/metadata/dragon.json" # 相对路径
BATCH_SIZE = 50
# 2. 连接 Milvus 并初始化嵌入模型
print(f"--> 正在连接到 Milvus: {MILVUS_URI}")
connections.connect(uri=MILVUS_URI)
print("--> 正在初始化 BGE-M3 嵌入模型...")
ef = BGEM3EmbeddingFunction(use_fp16=False, device="cpu")
print(f"--> 嵌入模型初始化完成。密集向量维度: {ef.dim['dense']}")
# 3. 创建 Collection
milvus_client = MilvusClient(uri=MILVUS_URI)
if milvus_client.has_collection(COLLECTION_NAME):
print(f"--> 正在删除已存在的 Collection '{COLLECTION_NAME}'...")
milvus_client.drop_collection(COLLECTION_NAME)
fields = [
FieldSchema(name="pk", dtype=DataType.VARCHAR, is_primary=True, auto_id=True, max_length=100),
FieldSchema(name="img_id", dtype=DataType.VARCHAR, max_length=100),
FieldSchema(name="path", dtype=DataType.VARCHAR, max_length=256),
FieldSchema(name="title", dtype=DataType.VARCHAR, max_length=256),
FieldSchema(name="description", dtype=DataType.VARCHAR, max_length=4096),
FieldSchema(name="category", dtype=DataType.VARCHAR, max_length=64),
FieldSchema(name="location", dtype=DataType.VARCHAR, max_length=128),
FieldSchema(name="environment", dtype=DataType.VARCHAR, max_length=64),
FieldSchema(name="sparse_vector", dtype=DataType.SPARSE_FLOAT_VECTOR),
FieldSchema(name="dense_vector", dtype=DataType.FLOAT_VECTOR, dim=ef.dim["dense"])
]
# 如果集合不存在,则创建它及索引
if not milvus_client.has_collection(COLLECTION_NAME):
print(f"--> 正在创建 Collection '{COLLECTION_NAME}'...")
schema = CollectionSchema(fields, description="关于龙的混合检索示例")
# 创建集合
collection = Collection(name=COLLECTION_NAME, schema=schema, consistency_level="Strong")
print("--> Collection 创建成功。")
# 创建索引
print("--> 正在为新集合创建索引...")
sparse_index = {"index_type": "SPARSE_INVERTED_INDEX", "metric_type": "IP"}
collection.create_index("sparse_vector", sparse_index)
print("稀疏向量索引创建成功。")
dense_index = {"index_type": "AUTOINDEX", "metric_type": "IP"}
collection.create_index("dense_vector", dense_index)
print("密集向量索引创建成功。")
collection = Collection(COLLECTION_NAME)
collection.load()
print(f"--> Collection '{COLLECTION_NAME}' 已加载到内存。")fields字段类型分析:
- pk : 主键设计,
auto_id=True让 Milvus 自动生成唯一标识,避免主键冲突 - 标量字段 : 7个VARCHAR字段用于存储元数据,
max_length根据实际数据分布优化存储 - 稀疏向量 :
SPARSE_FLOAT_VECTOR类型,存储关键词权重 - 密集向量 :
FLOAT_VECTOR类型,固定1024维,存储语义特征
1.3.2. BGE-M3 双向量生产
这里使用 BGE-M3 作为向量生成器,它能够同时生成稀疏向量和密集向量。
1.3.2.1. 数据加载与预处理
if collection.is_empty:
print(f"--> Collection 为空,开始插入数据...")
with open(DATA_PATH, 'r', encoding='utf-8') as f:
dataset = json.load(f)
docs, metadata = [], []
for item in dataset:
parts = [
item.get('title', ''),
item.get('description', ''),
item.get('location', ''),
item.get('environment', ''),
]
docs.append(' '.join(filter(None, parts)))
metadata.append(item)Collection 此时已加载到内存但为空状态。通过 is_empty 检查避免重复插入。多字段文本合并中每个实体对应一个完整的数据记录。
1.3.2.2. 向量生成
print("--> 正在生成向量嵌入...")
embeddings = ef(docs)
print("--> 向量生成完成。")
# 获取两种向量
sparse_vectors = embeddings["sparse"] # 稀疏向量:词频统计
dense_vectors = embeddings["dense"] # 密集向量:语义编码1.3.2.3. Collection 批量数据插入
# 为每个字段准备批量数据
img_ids = [doc["img_id"] for doc in metadata]
paths = [doc["path"] for doc in metadata]
titles = [doc["title"] for doc in metadata]
descriptions = [doc["description"] for doc in metadata]
categories = [doc["category"] for doc in metadata]
locations = [doc["location"] for doc in metadata]
environments = [doc["environment"] for doc in metadata]
# 插入数据
collection.insert([
img_ids, paths, titles, descriptions, categories, locations, environments,
sparse_vectors, dense_vectors
])
collection.flush()- 字段映射: 严格按照 Schema 定义的字段顺序插入,9个字段(7个标量+2个向量)
- **flush()**作用: 强制将内存缓冲区数据写入磁盘,使数据立即可搜索
- 最终状态 : Collection 包含6个Entity,索引层使用稀疏向量的
SPARSE_INVERTED_INDEX和密集向量的AUTOINDEX
1.3.3. 实现混合检索
最后使用 milvus 中封装好的 RRF 排序算法来完成混合检索:
1.3.3.1. 查询向量生成
# 6. 执行搜索
search_query = "悬崖上的巨龙"
search_filter = 'category in ["western_dragon", "chinese_dragon", "movie_character"]'
top_k = 5
print(f"\n{'='*20} 开始混合搜索 {'='*20}")
print(f"查询: '{search_query}'")
print(f"过滤器: '{search_filter}'")
# 生成查询向量
query_embeddings = ef([search_query])
dense_vec = query_embeddings["dense"][0]
sparse_vec = query_embeddings["sparse"]._getrow(0)尝试打印向量信息可以看到如下输出:
=== 向量信息 ===
密集向量维度: 1024
密集向量前5个元素: [-0.0035305 0.02043397 -0.04192593 -0.03036701 -0.02098157]
密集向量范数: 1.0000
稀疏向量维度: 250002
稀疏向量非零元素数量: 6
稀疏向量前5个非零元素:
- 索引: 6, 值: 0.0659
- 索引: 7977, 值: 0.1459
- 索引: 14732, 值: 0.2959
- 索引: 31433, 值: 0.1463
- 索引: 141121, 值: 0.1587
稀疏向量密度: 0.00239998%1.3.3.2. 混合检索执行
使用 RRF 算法进行混合检索,通过 milvus 封装的 RRFRanker 实现。RRFRanker 的核心参数是 k 值(默认60),用于控制 RRF 算法中的排序平滑程度。其中 k 值越大,排序结果越平滑;越小则高排名结果的权重越突出
# 定义搜索参数
search_params = {"metric_type": "IP", "params": {}}
# 先执行单独的搜索
print("\n--- [单独] 密集向量搜索结果 ---")
dense_results = collection.search(
[dense_vec],
anns_field="dense_vector",
param=search_params,
limit=top_k,
expr=search_filter,
output_fields=["title", "path", "description", "category", "location", "environment"]
)[0]
for i, hit in enumerate(dense_results):
print(f"{i+1}. {hit.entity.get('title')} (Score: {hit.distance:.4f})")
print(f" 路径: {hit.entity.get('path')}")
print(f" 描述: {hit.entity.get('description')[:100]}...")
print("\n--- [单独] 稀疏向量搜索结果 ---")
sparse_results = collection.search(
[sparse_vec],
anns_field="sparse_vector",
param=search_params,
limit=top_k,
expr=search_filter,
output_fields=["title", "path", "description", "category", "location", "environment"]
)[0]
for i, hit in enumerate(sparse_results):
print(f"{i+1}. {hit.entity.get('title')} (Score: {hit.distance:.4f})")
print(f" 路径: {hit.entity.get('path')}")
print(f" 描述: {hit.entity.get('description')[:100]}...")
print("\n--- [混合] 稀疏+密集向量搜索结果 ---")
# 创建 RRF 融合器
rerank = RRFRanker(k=60)
# 创建搜索请求
dense_req = AnnSearchRequest([dense_vec], "dense_vector", search_params, limit=top_k)
sparse_req = AnnSearchRequest([sparse_vec], "sparse_vector", search_params, limit=top_k)
# 执行混合搜索
results = collection.hybrid_search(
[sparse_req, dense_req],
rerank=rerank,
limit=top_k,
output_fields=["title", "path", "description", "category", "location", "environment"]
)[0]
# 打印最终结果
for i, hit in enumerate(results):
print(f"{i+1}. {hit.entity.get('title')} (Score: {hit.distance:.4f})")
print(f" 路径: {hit.entity.get('path')}")
print(f" 描述: {hit.entity.get('description')[:100]}...")最终输出如下:
--- [单独] 密集向量搜索结果 ---
1. 悬崖上的白龙 (Score: 0.7219)
路径: ../../data/C3/dragon/dragon02.png
描述: 一头雄伟的白色巨龙栖息在悬崖边缘,背景是金色的云霞和远方的海岸。它拥有巨大的翅膀和优雅的身姿,是典型的西方奇幻生物。...
2. 中华金龙 (Score: 0.5131)
路径: ../../data/C3/dragon/dragon06.png
描述: 一条金色的中华龙在祥云间盘旋,它身形矫健,龙须飘逸,展现了东方神话中龙的威严与神圣。...
3. 驯龙高手:无牙仔 (Score: 0.5119)
路径: ../../data/C3/dragon/dragon05.png
描述: 在电影《驯龙高手》中,主角小嗝嗝骑着他的龙伙伴无牙仔在高空飞翔。他们飞向灿烂的太阳,下方是岛屿和海洋,画面充满了冒险与友谊。...
--- [单独] 稀疏向量搜索结果 ---
1. 悬崖上的白龙 (Score: 0.2319)
路径: ../../data/C3/dragon/dragon02.png
描述: 一头雄伟的白色巨龙栖息在悬崖边缘,背景是金色的云霞和远方的海岸。它拥有巨大的翅膀和优雅的身姿,是典型的西方奇幻生物。...
2. 中华金龙 (Score: 0.0923)
路径: ../../data/C3/dragon/dragon06.png
描述: 一条金色的中华龙在祥云间盘旋,它身形矫健,龙须飘逸,展现了东方神话中龙的威严与神圣。...
3. 驯龙高手:无牙仔 (Score: 0.0691)
路径: ../../data/C3/dragon/dragon05.png
描述: 在电影《驯龙高手》中,主角小嗝嗝骑着他的龙伙伴无牙仔在高空飞翔。他们飞向灿烂的太阳,下方是岛屿和海洋,画面充满了冒险与友谊。...
--- [混合] 稀疏+密集向量搜索结果 ---
1. 悬崖上的白龙 (Score: 0.0328)
路径: ../../data/C3/dragon/dragon02.png
描述: 一头雄伟的白色巨龙栖息在悬崖边缘,背景是金色的云霞和远方的海岸。它拥有巨大的翅膀和优雅的身姿,是典型的西方奇幻生物。...
2. 中华金龙 (Score: 0.0320)
路径: ../../data/C3/dragon/dragon06.png
描述: 一条金色的中华龙在祥云间盘旋,它身形矫健,龙须飘逸,展现了东方神话中龙的威严与神圣。...
3. 霸王龙的怒吼 (Score: 0.0318)
路径: ../../data/C3/dragon/dragon03.png
描述: 史前时代的霸王龙张开血盆大口,发出震天的怒吼。在它身后,几只翼龙在阴沉的天空中盘旋,展现了白垩纪的原始力量。...
4. 奔跑的奶龙 (Score: 0.0313)
路径: ../../data/C3/dragon/dragon04.png
描述: 一只Q版的黄色小恐龙,有着大大的绿色眼睛和友善的微笑。是一部动画中的角色,非常可爱。...
5. 驯龙高手:无牙仔 (Score: 0.0310)
路径: ../../data/C3/dragon/dragon05.png
描述: 在电影《驯龙高手》中,主角小嗝嗝骑着他的龙伙伴无牙仔在高空飞翔。他们飞向灿烂的太阳,下方是岛屿和海洋,画面充满了冒险与友谊。...2. 查询构建
在前面的章节中,我们探讨了如何通过向量嵌入和相似度搜索来从非结构化数据中检索信息。然而,在实际应用中,我们常常需要处理更加复杂和多样化的数据,包括结构化数据(如SQL数据库)、半结构化数据(如带有元数据的文档)以及图数据。用户的查询也可能不仅仅是简单的语义匹配,而是包含复杂的过滤条件、聚合操作或关系查询。
2.1. 查询构建是什么?
**查询构建(Query Construction)**正是应对这一挑战的关键技术。它利用大语言模型(LLM)的强大理解能力,将用户的自然语言查询"翻译"成针对特定数据源的结构化查询语言或带有过滤条件的请求。这使得RAG系统能够无缝地连接和利用各种类型的数据,从而极大地扩展了其应用场景和能力。
查询构建(Query Construction) 的核心思想,可以一句话概括:让LLM充当一个"翻译官",把人类随意的自然语言提问,精准翻译成数据库、API或搜索引擎能听懂的"官方语言"。
没有这个翻译官,RAG系统就只能在一个"全文搜索"的层面工作(把文档切块、向量化、相似度匹配)。有了它,RAG就能直接查询结构化数据(如SQL数据库、知识图谱、Excel表格),实现精确查找、聚合统计、多表关联等复杂操作。
查询构建 = LLM翻译官 + 数据源schema + 结构化查询语言(SQL/Cypher/API)它的本质是让LLM学会"调用外部数据接口",从而让RAG系统不仅会"读文档",还会"查表格"、"算总数"、"问数据库"。这极大拓展了RAG的应用范围------从纯文本问答,延伸到商业智能、企业报表、实时数据看板等场景。
如果用一个类比来理解:
- 传统RAG:像一个图书管理员,帮你翻书找答案。
- 查询构建:像一个数据分析师,帮你跑SQL、调API、算KPI。
2.2. 为什么需要查询构建?
传统的RAG(向量检索)在处理以下问题时非常吃力:
|--------------------------|------------------------------------------------------|----------------------------------------------------------------------------------------------|
| 用户问题示例 | 传统RAG的困境 | 查询构建的解法 |
| "2023年销量最高的产品是什么?" | 向量搜索会找到很多包含"销量"、"产品"、"2023"的段落,但很难直接计算最大值。 | 翻译成SQL:SELECT product FROM sales WHERE year=2023 ORDER BY amount DESC LIMIT 1; 直接返回准确答案。 |
| "张三经理手下有多少员工?" | 文档里可能没有直接写这句话,需要从多个段落推理关系。 | 翻译成图查询或SQL:SELECT COUNT(*) FROM employees WHERE manager='张三'; |
| "帮我查一下北京海淀区单价低于500万的二手房" | 向量搜索能找到"北京"、"海淀区"、"二手房"等词,但无法执行"单价<500万"这种数值过滤。 | 翻译成API调用:GET /houses?city=北京&district=海淀&price_max=5000000 |
| "上个月订单总额是多少?" | 需要理解"上个月"是哪个具体月份,然后去汇总金额。 | 翻译成SQL:SELECT SUM(amount) FROM orders WHERE month = DATE_SUB(CURDATE(), INTERVAL 1 MONTH); |
核心区别:传统RAG擅长找"相似的文本",而查询构建擅长做"精确的查询"。前者是模糊匹配,后者是确定性检索/计算。
2.3. 构建工作原理
2.3.1. 理解意图并选择数据源
LLM先分析用户问题,判断需要查哪种数据源:
- 问题涉及统计、数值、表格 → 需要SQL数据库
- 问题涉及实体关系(如"A的B是什么") → 需要知识图谱(Cypher查询)
- 问题涉及实时、过滤、排序 → 需要REST API
2.3.2. 生成结构化查询
LLM根据事先提供的数据源schema (即数据库的表结构、API的参数格式),生成精确的查询语句。这个过程通常通过少样本提示(few-shot prompting) 或函数调用(function calling) 实现。
示例:
- 用户问:"给我看看2024年入职、职位是工程师的员工名单。"
- 系统提示LLM:"数据库有
employees表,字段:name,position,hire_date。请将用户问题转成SQL。" - LLM生成:
SELECT name FROM employees WHERE position = '工程师' AND YEAR(hire_date) = 2024;
2.3.3. 执行查询并回答
系统拿到这个SQL,去真实数据库执行,得到结果(比如 ['张三', '李四'])。然后把结果交给LLM,让它用自然语言回答用户:"2024年入职的工程师有张三和李四。"
2.3.4. 与RAG的关系:两种模式的融合
查询构建不是取代RAG,而是互补 。一个强大的RAG系统通常支持多路查询:
- 对于开放性问题(如"RAG技术有哪些挑战?")→ 走向量检索(从非结构化文档中找)。
- 对于精确性问题(如"2023年销量最高的产品")→ 走查询构建(查SQL数据库)。
- 对于复杂问题(如"找到张三写的文档中,提到RAG且发表时间在2024年后的")→ 可能先用查询构建找到张三的文档ID(结构化过滤),再在那些文档内做向量检索(非结构化搜索)。
这种组合被称为 "结构化检索 + 非结构化检索" 或 "混合查询"(注意和之前说的混合检索区分------这里是数据源的混合,而不是检索算法的混合)。
下图展示了查询构建在一个高级RAG流程中所处的位置:
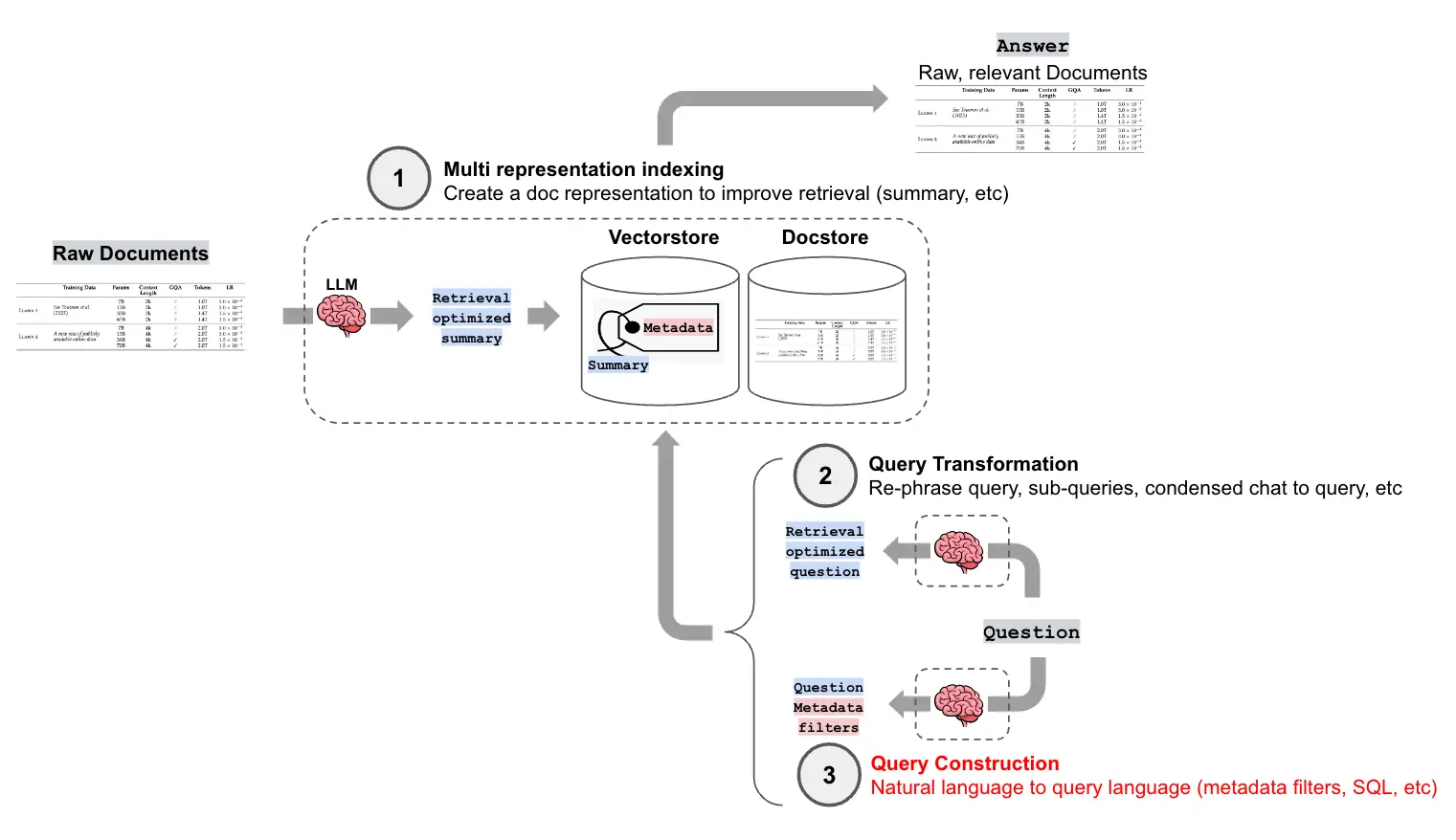
2.4. 文本到元数据过滤器
在构建向量索引时,常常会为文档块(Chunks)附加元数据(Metadata),例如文档来源、发布日期、作者、章节、类别等。这些元数据为我们提供了在语义搜索之外进行精确过滤的可能。
**自查询检索器(Self-Query Retriever)**是LangChain中实现这一功能的核心组件。它的工作流程如下:
- 定义元数据结构:首先,需要向LLM清晰地描述文档内容和每个元数据字段的含义及类型。
- 查询解析:当用户输入一个自然语言查询时,自查询检索器会调用LLM,将查询分解为两部分:
-
- 查询字符串(Query String):用于进行语义搜索的部分。
- 元数据过滤器(Metadata Filter):从查询中提取出的结构化过滤条件。
- 执行查询:检索器将解析出的查询字符串和元数据过滤器发送给向量数据库,执行一次同时包含语义搜索和元数据过滤的查询。
例如,对于查询"关于2022年发布的机器学习的论文",自查询检索器会将其解析为:
-
查询字符串: "机器学习的论文"
-
元数据过滤器 :
year == 2022import os
from langchain_deepseek import ChatDeepSeek
from langchain_community.document_loaders import BiliBiliLoader
from langchain.chains.query_constructor.base import AttributeInfo
from langchain.retrievers.self_query.base import SelfQueryRetriever
from langchain_community.vectorstores import Chroma
from langchain_huggingface import HuggingFaceEmbeddings
import logginglogging.basicConfig(level=logging.INFO)
1. 初始化视频数据
video_urls = [
"https://www.bilibili.com/video/BV1Bo4y1A7FU",
"https://www.bilibili.com/video/BV1ug4y157xA",
"https://www.bilibili.com/video/BV1yh411V7ge",
]bili = []
try:
loader = BiliBiliLoader(video_urls=video_urls)
docs = loader.load()for doc in docs: original = doc.metadata # 提取基本元数据字段 metadata = { 'title': original.get('title', '未知标题'), 'author': original.get('owner', {}).get('name', '未知作者'), 'source': original.get('bvid', '未知ID'), 'view_count': original.get('stat', {}).get('view', 0), 'length': original.get('duration', 0), } doc.metadata = metadata bili.append(doc)except Exception as e:
print(f"加载BiliBili视频失败: {str(e)}")if not bili:
print("没有成功加载任何视频,程序退出")
exit()2. 创建向量存储
embed_model = HuggingFaceEmbeddings(model_name="BAAI/bge-small-zh-v1.5")
vectorstore = Chroma.from_documents(bili, embed_model)
在上面的代码中,首先使用 BiliBiliLoader 加载了几个B站视频的文档和元数据。需要注意的是,由于 BiliBiliLoader 返回的原始元数据结构较为复杂(例如,作者和观看数信息嵌套在其他字典中),所以进行了一些预处理工作:遍历每个文档,手动提取需要的字段(如title, author, view_count, length),并构建一个干净、扁平化的新 metadata 字典。这个过程确保了后续的自查询检索器能够直接、可靠地访问这些字段。最后,将处理好的文档和元数据存入 Chroma 向量数据库中,为下一步的查询构建做好准备。
# 3. 配置元数据字段信息
metadata_field_info = [
AttributeInfo(
name="title",
description="视频标题(字符串)",
type="string",
),
AttributeInfo(
name="author",
description="视频作者(字符串)",
type="string",
),
AttributeInfo(
name="view_count",
description="视频观看次数(整数)",
type="integer",
),
AttributeInfo(
name="length",
description="视频长度,以秒为单位的整数",
type="integer"
)
]
# 4. 创建自查询检索器
llm = ChatDeepSeek(
model="deepseek-chat",
temperature=0,
api_key=os.getenv("DEEPSEEK_API_KEY")
)
retriever = SelfQueryRetriever.from_llm(
llm=llm,
vectorstore=vectorstore,
document_contents="记录视频标题、作者、观看次数等信息的视频元数据",
metadata_field_info=metadata_field_info,
enable_limit=True,
verbose=True
)
# 5. 执行查询示例
queries = [
"时间最短的视频",
"时长大于600秒的视频"
]
for query in queries:
print(f"\n--- 查询: '{query}' ---")
results = retriever.invoke(query)
if results:
for doc in results:
title = doc.metadata.get('title', '未知标题')
author = doc.metadata.get('author', '未知作者')
view_count = doc.metadata.get('view_count', '未知')
length = doc.metadata.get('length', '未知')
print(f"标题: {title}")
print(f"作者: {author}")
print(f"观看次数: {view_count}")
print(f"时长: {length}秒")
print("="*50)
else:
print("未找到匹配的视频")这部分代码是实现自查询检索的核心。主要分为三个步骤:
- 配置元数据字段 ( metadata_field_info**)** :这是与LLM沟通的蓝图。通过
AttributeInfo为每个元数据字段定义名称、类型和一份清晰的自然语言description。LLM 将依赖这份描述来理解如何处理用户的查询,例如,它会根据"视频长度(整数)"的描述来解析关于"时长"的过滤和排序请求。因此,一份准确、无歧义的描述很重要。 - 创建自查询检索器 ( SelfQueryRetriever.from_llm**)** :
from_llm方法在底层执行了两个核心操作:
-
- 加载查询构造器 :利用传入的
llm、document_contents和metadata_field_info,创建一个专门的"查询构造链"。这个链的核心职责是将用户的自然语言查询(如"时长大于600秒的视频")转换为一个通用的、结构化的查询对象。 - 获取内置翻译器 :接着,检查使用的向量数据库(这里是
Chroma),并为其匹配一个内置的"翻译器"。这个翻译器负责将上一步生成的通用查询对象,翻译成Chroma数据库能够原生理解和执行的过滤语法。
- 加载查询构造器 :利用传入的
- 执行查询 ( retriever.invoke**)** :最后,用自然语言发起调用。检索器内部会依次执行"构造"和"翻译"两个步骤,最终向
Chroma发起一个同时包含语义搜索和精确元数据过滤的复合查询,从而返回最相关的结果。
提示:在代码中可以看到 temperature****参数被设置为 0**。这个值是用于控制模型输出的随机性。值越高(如 0.8),输出越随机、越有创意;值越低,输出越确定、越集中。设置为** 0****可以让模型的输出变得完全确定,即对于相同的输入,总是生成完全相同的输出。在自查询这种需要精确地将自然语言转换为结构化查询的场景下,可以确保转换结果的稳定和可复现。
--- 查询: '时间最短的视频' ---
INFO:httpx:HTTP Request: POST https://api.deepseek.com/v1/chat/completions "HTTP/1.1 200 OK"
INFO:langchain.retrievers.self_query.base:Generated Query: query=' ' filter=None limit=1
标题: 《吴恩达 x OpenAI Prompt课程》【专业翻译,配套代码笔记】02.Prompt 的构建原则
作者: 二次元的Datawhale
观看次数: 18788
时长: 1063秒
==================================================
--- 查询: '时长大于600秒的视频' ---
INFO:httpx:HTTP Request: POST https://api.deepseek.com/v1/chat/completions "HTTP/1.1 200 OK"
INFO:langchain.retrievers.self_query.base:Generated Query: query=' ' filter=Comparison(comparator=<Comparator.GT: 'gt'>, attribute='length', value=600) limit=None
WARNING:chromadb.segment.impl.vector.local_hnsw:Number of requested results 4 is greater than number of elements in index 3, updating n_results = 3
标题: 《吴恩达 x OpenAI Prompt课程》【专业翻译,配套代码笔记】03.Prompt如何迭代优化
作者: 二次元的Datawhale
观看次数: 7090
时长: 806秒
==================================================
标题: 《吴恩达 x OpenAI Prompt课程》【专业翻译,配套代码笔记】02.Prompt 的构建原则
作者: 二次元的Datawhale
观看次数: 18788
时长: 1063秒查询"时间最短的视频"返回的并不是真正时长最短的视频(806秒),而是一个1063秒的视频。这是因为 SelfQueryRetriever****并不支持"按某个字段排序后取最小值"这类聚合查询。
SelfQueryRetriever的设计目标
- 它主要解决 "带元数据过滤的语义搜索"。
- 它能生成的查询结构包括:
-
query:用于向量相似度搜索的文本(可以为空)。filter:元数据上的比较条件(eq、gt、lt、and、or等)。limit:返回的最大文档数。
- 它不能生成排序(order by)或聚合(min/max/sum)操作。
日志显示:
Generated Query: query=' ' filter=None limit=1query=' ':空字符串,被嵌入成一个零向量 (或接近零向量)。
在 Chroma 中,零向量会返回与所有文档"相似度"几乎相同的分数,最终结果取决于索引的内部顺序(可能是插入顺序或某种默认顺序)。filter=None:没有元数据过滤。limit=1:只取一条。
因此,SelfQueryRetriever 相当于 "随便返回一个文档",而不是找时长最短的。恰好第一个文档是 1063 秒的那个。
- 为什么"时长大于600秒"能正确工作?
因为那是过滤 (filter=Comparison(gt, length, 600)),属于 SelfQueryRetriever 支持的操作。
它会先过滤出 length > 600 的所有文档,然后在这些文档上做向量搜索(query=' ' 依然是空向量,但此时候选集已经缩小)。最终返回了所有满足条件的文档(3个中的2个),顺序不是按时长排序,只是按向量相似度返回。
2.5. 文本到Cypher查询
除了处理扁平化的元数据,查询构建技术还能应用于更复杂的数据结构,如图数据库。
2.5.1. 什么是 Cypher?
Cypher 是图数据库(如 Neo4j)中最常用的查询语言,其地位类似于 SQL 之于关系数据库。它采用一种直观的方式来匹配图中的模式和关系,例如 (:Person {name:"Tomaz"})-[:LIVES_IN]->(:Country {name:"Slovenia"}) 描述了一个人和一个国家以及他们之间的"居住在"关系。
2.5.2. "文本到Cypher"的原理
与"文本到元数据过滤器"类似,"文本到Cypher"技术利用大语言模型(LLM)将用户的自然语言问题直接翻译成一句精准的 Cypher 查询语句。LangChain 提供了相应的工具链(如 GraphCypherQAChain),其工作流程通常是:
- 接收用户的自然语言问题。
- LLM 根据预先提供的图谱模式(Schema),将问题转换为 Cypher 查询。
- 在图数据库上执行该查询,获取精确的结构化数据。
- (可选)将查询结果再次交由 LLM,生成通顺的自然语言答案。
由于生成有效的 Cypher 查询是一项复杂的任务,通常使用性能较强的 LLM 来确保转换的准确性。通过这种方式,用户可以用最自然的方式与高度结构化的图数据进行交互,极大地降低了数据查询的门槛。
3. Text2SQL
继上一节探讨了如何为元数据和图数据构建查询后,本节将聚焦于结构化数据领域中一个常见的应用。在数据世界中,除了向量数据库能够处理的非结构化数据,关系型数据库(如 MySQL, PostgreSQL, SQLite)同样是存储和管理结构化数据的重点。**文本到SQL(Text-to-SQL)**正是为了打破人与结构化数据之间的语言障碍而生。它利用大语言模型(LLM)将用户的自然语言问题,直接翻译成可以在数据库上执行的SQL查询语句。