什么是数据结构
数据结构是计算机中组织、存储和管理数据的方式,目的是让数据能被高效地查找、插入、删除、修改。
常见的数据结构
- 线性结构(数据排成一条线)
数组(Array)
链表(Linked List):单链表、双向链表、循环链表
栈(Stack):后进先出 LIFO
队列(Queue):先进先出 FIFO(扩展:双端队列、优先队列)
- 树形结构(分层、分支结构)
二叉树
二叉搜索树(BST)
平衡二叉树(AVL 树)
堆(Heap):大顶堆、小顶堆
哈夫曼树(Huffman Tree)
B 树 / B+ 树(数据库索引常用)
- 图形结构(多对多复杂关系)
无向图
有向图
网(带权图)
- 其他常用结构
哈希表(Hash Table)
集合(Set)
串(字符串)
二叉树性质
叶节点数=双分支节点数+1(n0=n2+1)
数组vs 链表
一句话总结:数组连续存、查找快、增删慢;链表分散存、增删快、查找慢。
| 对比项 | 数组 | 链表 |
|---|---|---|
| 存储方式 | 内存连续,一块完整空间 | 内存分散,节点通过指针相连 |
| 访问方式 | 随机访问,下标直接定位 | 顺序访问,只能从头遍历 |
| 大小 | 固定,创建后不可变 | 动态,可随时增删节点 |
| 内存占用 | 小,只存数据 | 大,每个节点还要存指针 |
| 增删效率 | 慢,需要移动元素 | 快,只需改指针 |
栈与队列核心区别
一句话:栈是后进先出(LIFO),队列是先进先出(FIFO)。
| 对比项 | 栈 Stack | 队列 Queue |
|---|---|---|
| 进出规则 | 后进先出 Last In First Out | 先进先出 First In First Out |
| 操作端 | 只能在栈顶插入、删除 | 队尾入队,队头出队 |
| 常见操作 | push、pop、top/peek | enqueue、dequeue、front |
| 结构类比 | 叠盘子、弹匣 | 排队、水管 |
栈的应用
函数调用栈(递归、方法嵌套)
括号匹配检查
()[]{}浏览器前进后退
表达式求值(后缀表达式 / 逆波兰式)
深度优先搜索 DFS
撤销操作(Ctrl+Z)
队列的应用
任务排队、消息队列
操作系统进程调度
打印机任务队列
广度优先搜索 BFS
消息缓冲、异步处理
滑动窗口算法
超简记忆
想回头、回溯、嵌套 → 用 栈
想排队、顺序、公平 → 用 队列
什么是哈希表
哈希表(Hash Table,也叫散列表) 是一种通过哈希函数(Hash Function) ,把键(Key)直接映射到数组下标 ,从而实现O (1) 快速查找的数据结构。
用 key 计算出一个索引,直接通过索引访问数据,不用像数组 / 链表那样逐个遍历
哈希冲突是什么
不同的 key,经过哈希函数计算后,得到了相同的下标 ,这就叫哈希冲突(哈希碰撞)。
比如:key1 → hash → 下标 5key2 → hash → 下标 5两个数据抢同一个位置,就冲突了。
哈希函数构造方法
1. 直接定址法
公式:
H(key) = key或H(key) = a * key + b特点:无冲突 计算极快
缺点:key 范围不能太大,否则空间浪费严重
适用:关键字连续、分布集中(如学号、编号)
2. 除留余数法(最常用、必考)
公式:
H(key) = key % pp 选取:取小于等于表长的质数最好
特点:简单高效 冲突概率低
适用:绝大多数场景,HashMap 底层也用到类似思想
解决哈希冲突的常见方法
链地址法(拉链法,最常用)
数组每个位置不是存单个数据,而是存链表 / 红黑树
冲突的元素都挂在同一个链表上
Java 中的 HashMap、Python 字典都用这种
开放定址法
冲突了就往后找空位置,常见几种:
线性探测:依次找下一个位置
二次探测:按平方步长找
双重哈希:用第二个哈希函数重新计算位置
再哈希法
冲突时,使用第二个不同的哈希函数重新计算地址,直到不冲突。
二叉树、满二叉树、完全二叉树的定义
二叉树
每个节点最多有两个子节点,分别称为左孩子和右孩子,次序不能颠倒。
满二叉树
每一层的节点数都达到最大值
所有叶子节点都在最底层
高度为 h,则总节点数为2h−1
形象理解:一层都不缺,一个位置都不空。
完全二叉树
除了最后一层外,其他层节点数都达到最大
最后一层的节点靠左连续排列,右边可以空,但不能中间空
形象理解:按从上到下、从左到右顺序排满,只允许最后一层右边缺节点。
二叉搜索树(BST)的核心性质
二叉搜索树也叫二叉排序树,核心就是:左小右大,中序有序。
1. 基本性质
若左子树不为空,则左子树上所有节点值 < 根节点值
若右子树不为空,则右子树上所有节点值 > 根节点值
左、右子树也分别是二叉搜索树
树中没有值相等的节点(默认定义)
2. 重要性质
- 中序遍历结果一定是递增有序序列这是判断一棵树是不是 BST 最常用的方法。
3. 简单例子
5 / \ 3 7 / \ / \ 2 4 6 8中序遍历:
2 3 4 5 6 7 8→ 严格递增。4. 缺点
如果插入数据有序(1→2→3→4→5),BST 会退化成链表,查找效率从 O (log n) 变成 O (n)。所以才有了 AVL 树、红黑树等平衡二叉树。
为什么要有平衡二叉树(AVL 树)
因为普通二叉搜索树 BST 可能退化成链表,导致查找效率从 O(logn) 变成 O(n),速度大幅下降。
AVL 树就是为了解决这个问题:
保证树始终接近平衡
左右子树高度差不超过 1
查找、插入、删除稳定保持 O(logn)
平衡因子(BF)
每个节点的平衡因子 = 左子树高度 − 右子树高度AVL 要求:所有节点的平衡因子只能是 -1、0、1一旦超出,就要旋转恢复平衡。
四种失衡情况 + 对应旋转方式
- 左左(LL)------ 右旋(单旋)
插入在左子树的左孩子
处理:对失衡节点右旋
- 右右(RR)------ 左旋(单旋)
插入在右子树的右孩子
处理:对失衡节点左旋
- 左右(LR)------ 先左旋,再右旋(双旋)
插入在左子树的右孩子
先对左孩子左旋
再对根节点右旋
- 右左(RL)------ 先右旋,再左旋(双旋)
插入在右子树的左孩子
先对右孩子右旋
再对根节点左旋
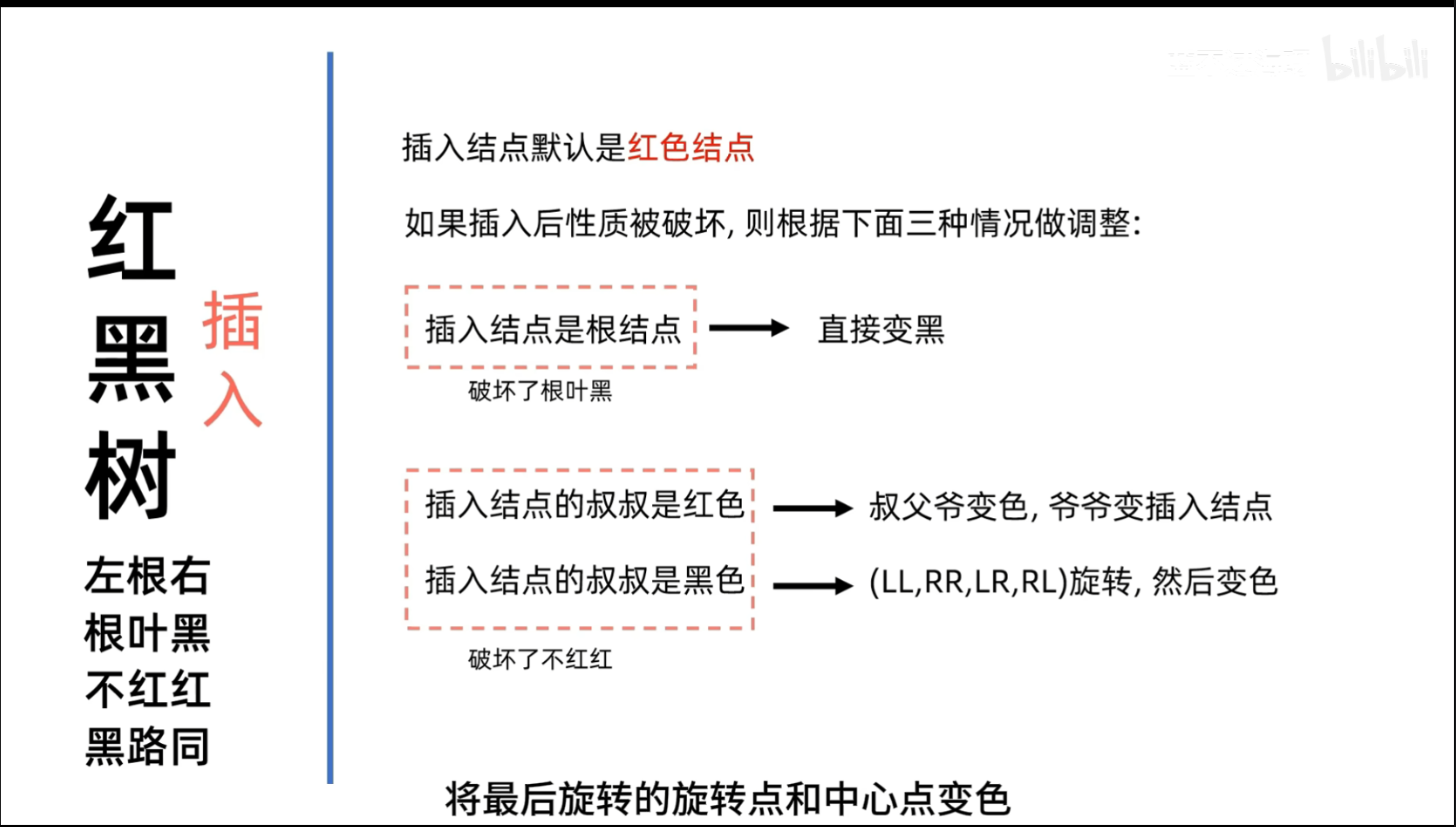
红黑树是什么
红黑树是一种自平衡的二叉搜索树 ,每个节点带有红 / 黑颜色,通过严格的颜色规则保证树不会 "歪" 得太厉害。
红黑树 5 条核心规则(必背)
每个节点只能是 红色 或 黑色
根节点一定是黑色
所有 叶子节点(空节点 NIL)都是黑色
如果一个节点是 红色 ,那么它的两个子节点一定都是黑色 → 不能有两个红色节点连在一起
从任意节点到其每个叶子节点的所有路径,都包含相同数量的黑色节点
满足这些规则,树就不会严重失衡,高度始终控制在 O(log n)。
为什么红黑树比 AVL 更常用
核心一句话:AVL 追求绝对平衡,旋转多、开销大;红黑树是 "弱平衡",旋转更少,插入删除更快,更适合工程实际。
1. 平衡程度不同
AVL:左右子树高度差 ≤ 1 → 高度更低,查询略快
红黑树:允许一定不平衡,最长路径 ≤ 2× 最短路径 → 高度稍高,查询几乎没差别
2. 旋转开销(关键)
AVL:插入 / 删除时可能要旋转 多次
红黑树:插入最多 2 次旋转,删除最多 3 次旋转→ 增删效率远高于 AVL
3. 实际场景
大部分系统都是读多、写也不少,更看重综合性能:
Java:
TreeMap、TreeSetC++:
std::map、std::setLinux:进程调度、内存管理→ 全都用红黑树,几乎不用 AVL
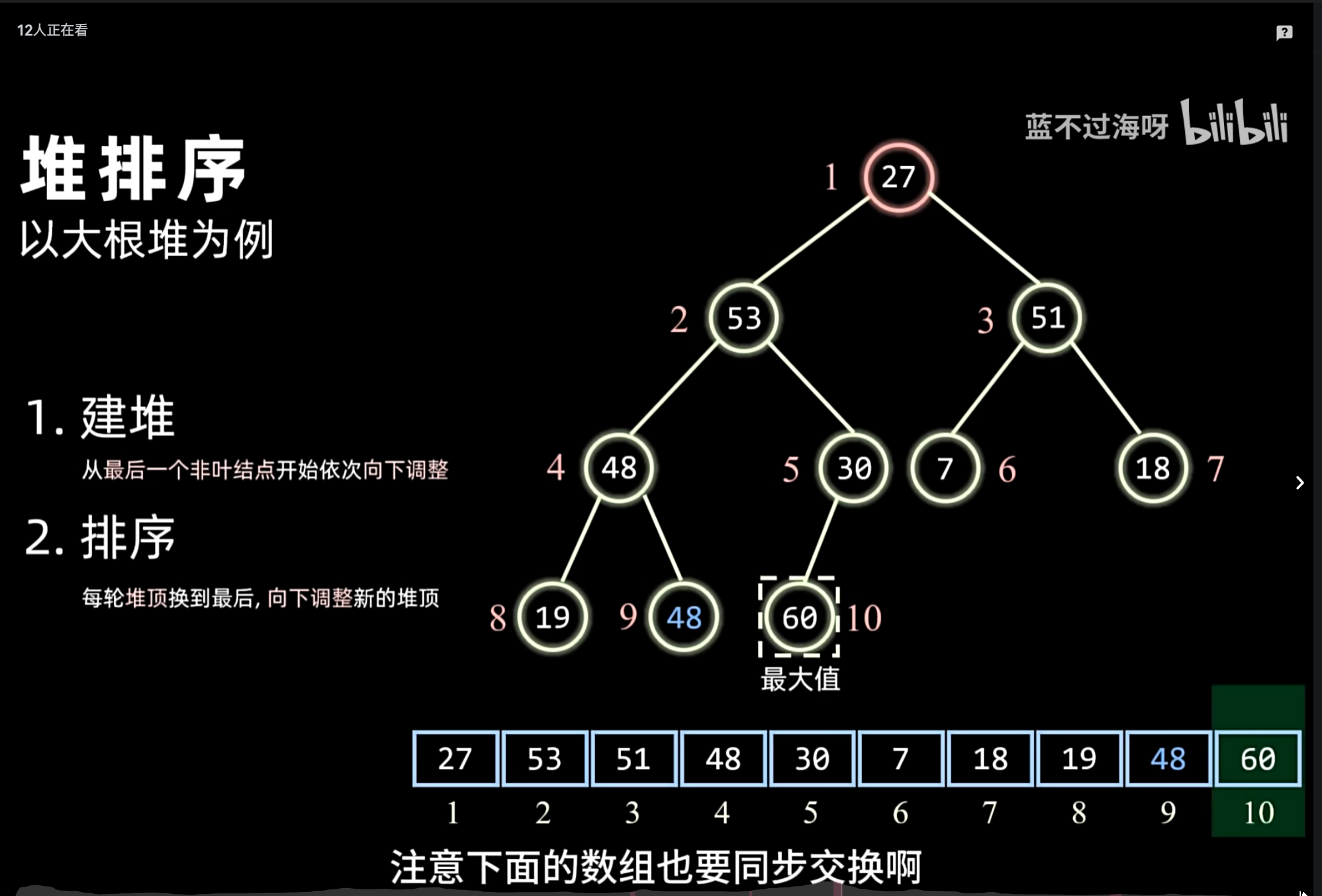
堆是什么
堆(Heap) 是一种完全二叉树 结构,通常用数组实现。它不是普通二叉树,也不是二叉搜索树,核心特点:
必须是完全二叉树
堆顶元素永远是最大值或最小值
只保证堆顶最大 / 最小,不保证整体有序
大顶堆 vs 小顶堆
- 大顶堆(最大堆)
任意父节点 ≥ 左右子节点
堆顶是整棵树最大值
- 小顶堆(最小堆)
任意父节点 ≤ 左右子节点
堆顶是整棵树最小值
一句话区分:大顶堆:爸爸最大;小顶堆:爸爸最小
堆的常见操作(简单了解)
插入:放到最后,向上调整(sift up)
删除堆顶:用最后元素覆盖,向下调整(sift down)
建堆:从最后一个非叶子节点往前遍历,依次向下调整
时间复杂度:
插入、删除堆顶:O(log n)
建堆:O(n)
典型应用场景
堆排序用大顶堆 / 小顶堆实现排序,时间复杂度 O (n log n)
**优先队列(Priority Queue)**Java PriorityQueue、C++ priority_queue 底层都是堆
Top K 问题求第 K 大、第 K 小、前 K 个最大 / 最小数
求前 K 大 → 用小顶堆
求前 K 小 → 用大顶堆
合并 K 个有序链表用小顶堆每次取最小节点
定时器、任务调度按时间优先级取出最早 / 优先级最高的任务
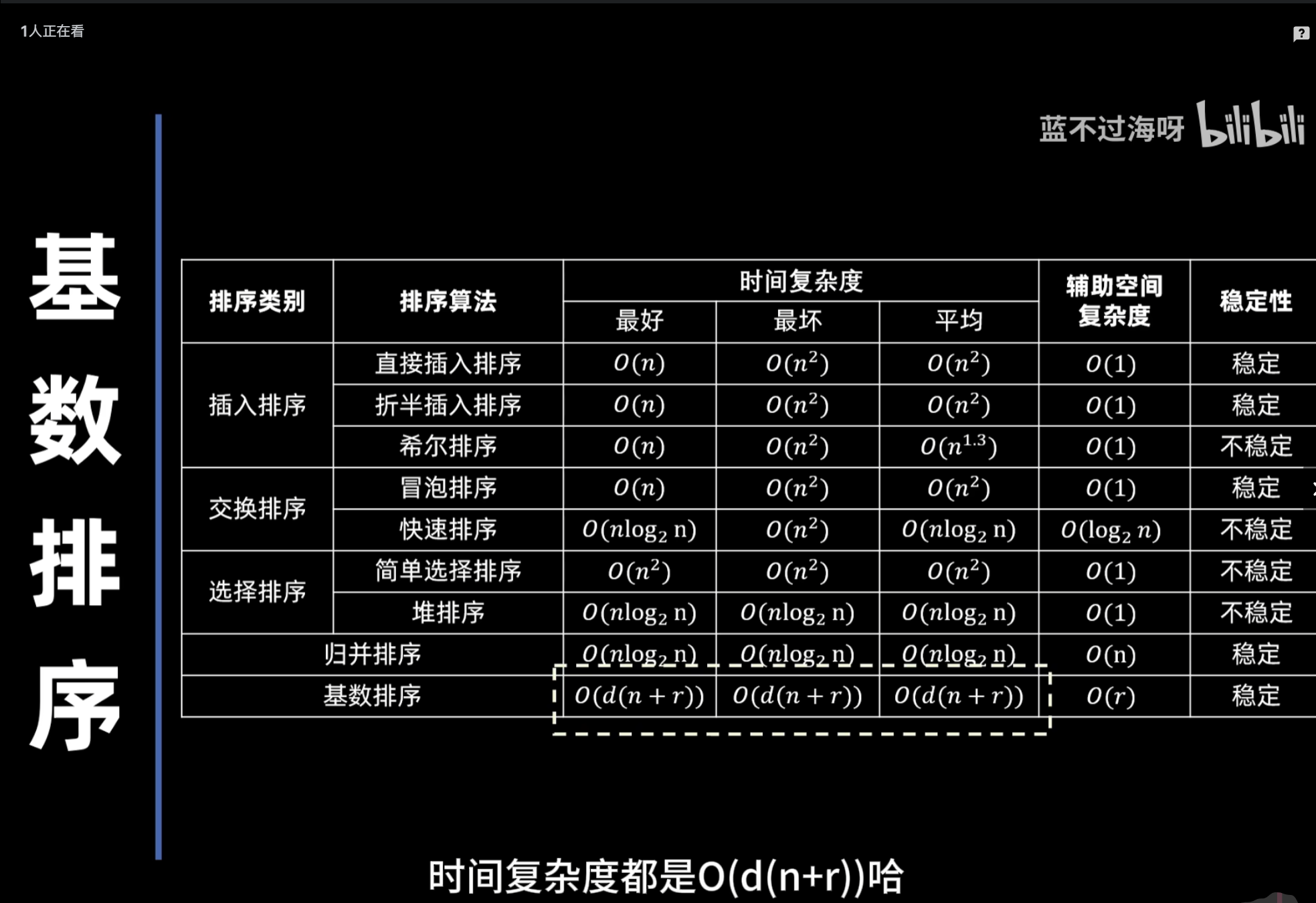
直接插入排序

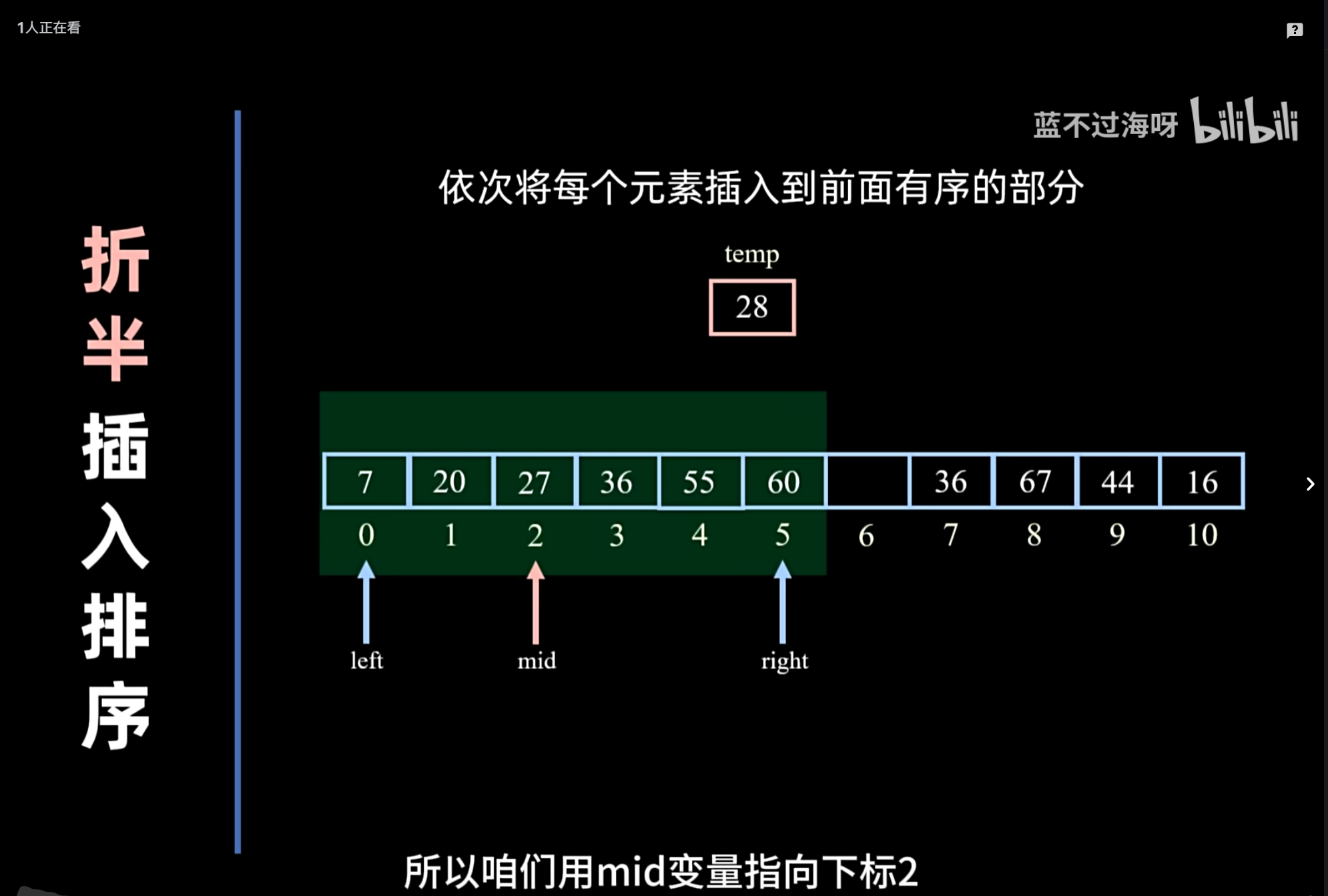
折半插入排序
希尔排序

冒泡排序

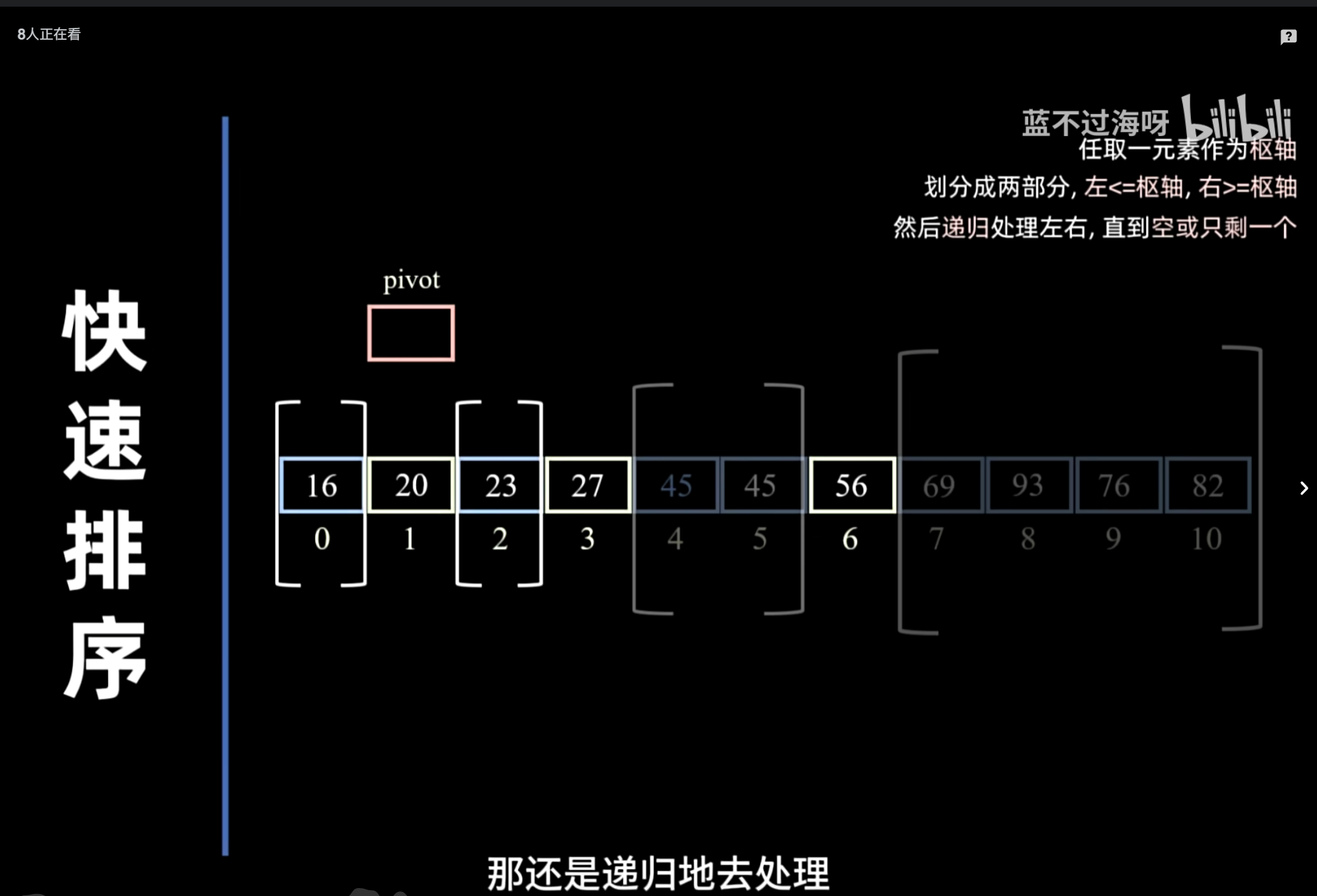
快速排序
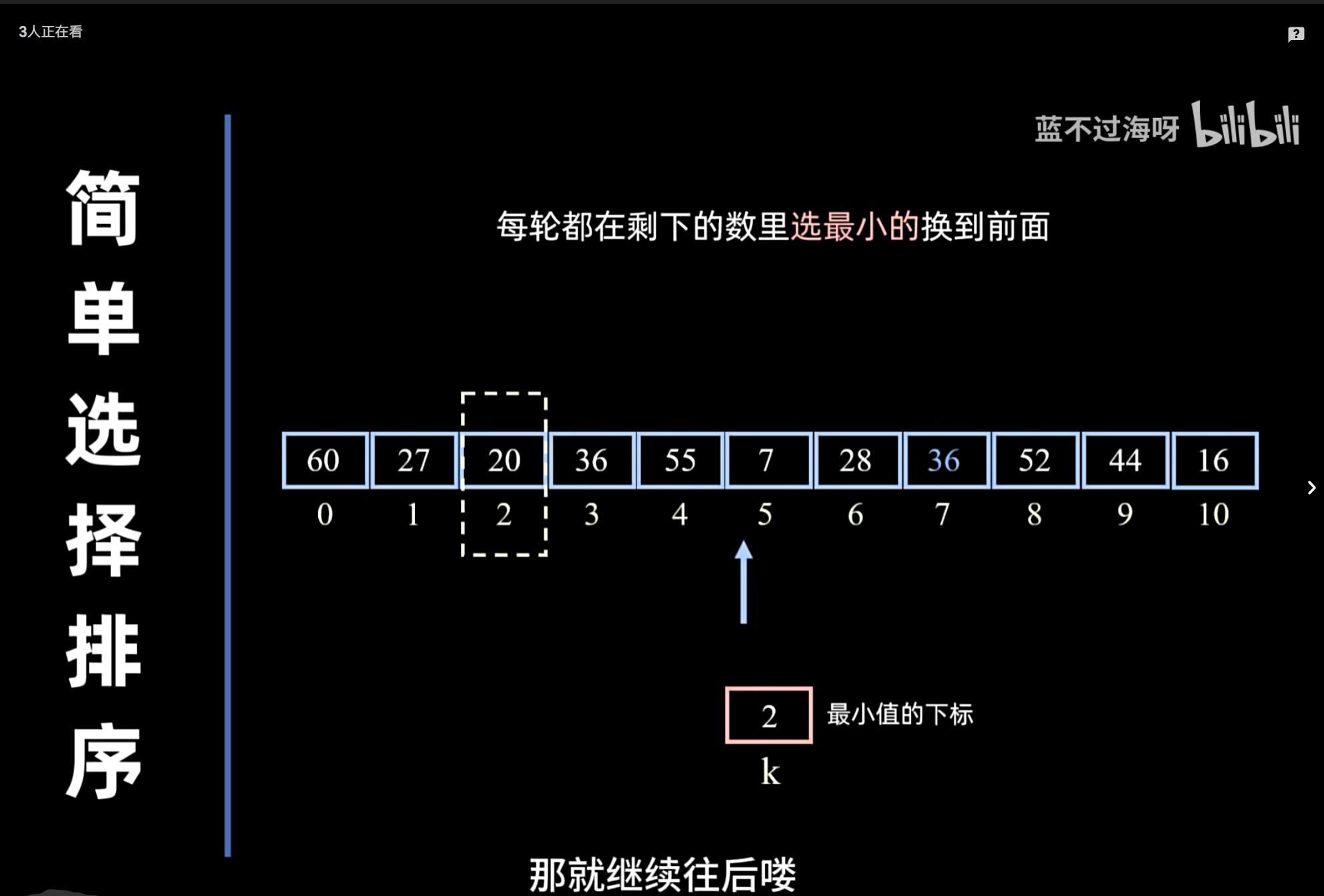
简单选择排序
堆排序
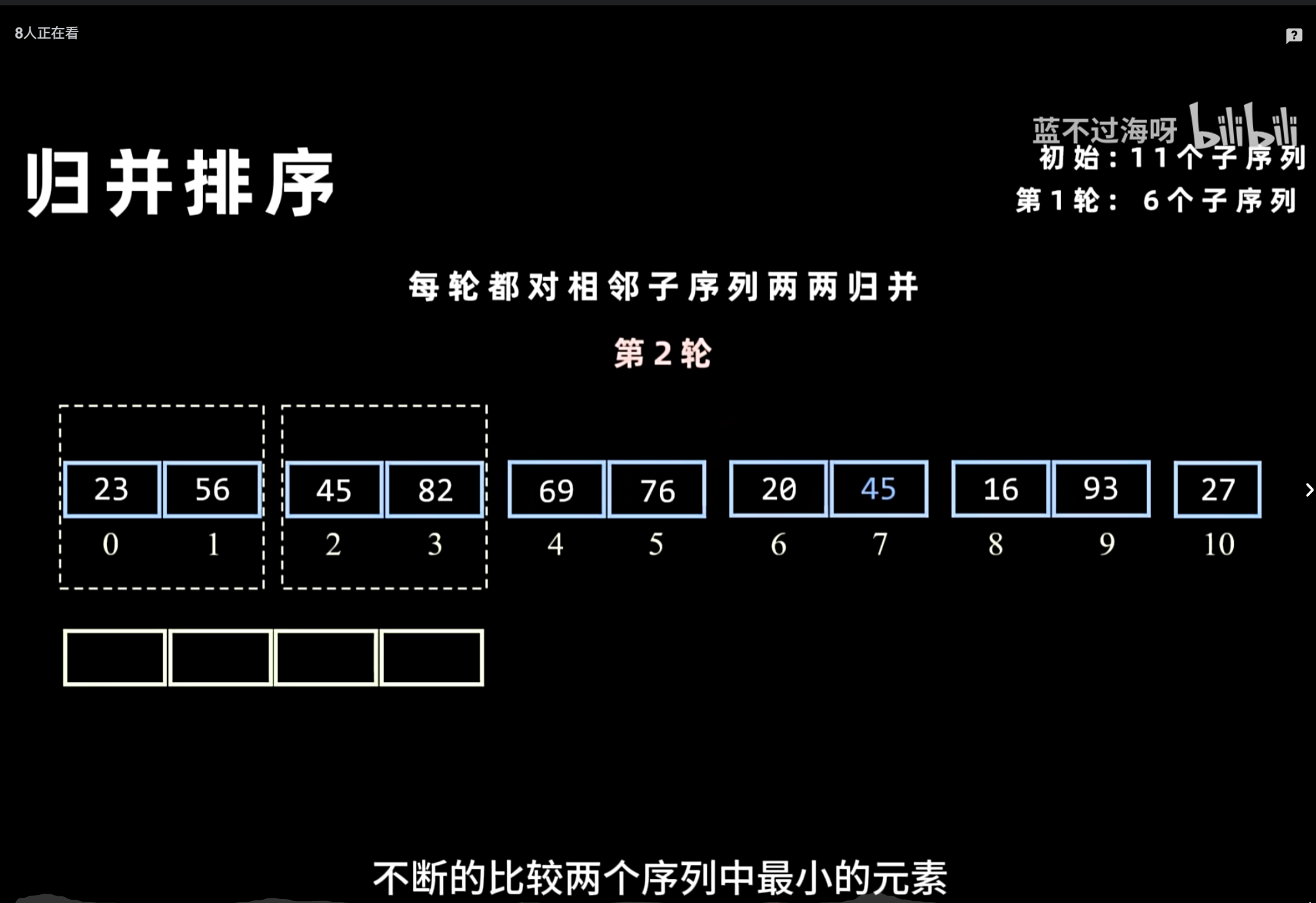
归并排序
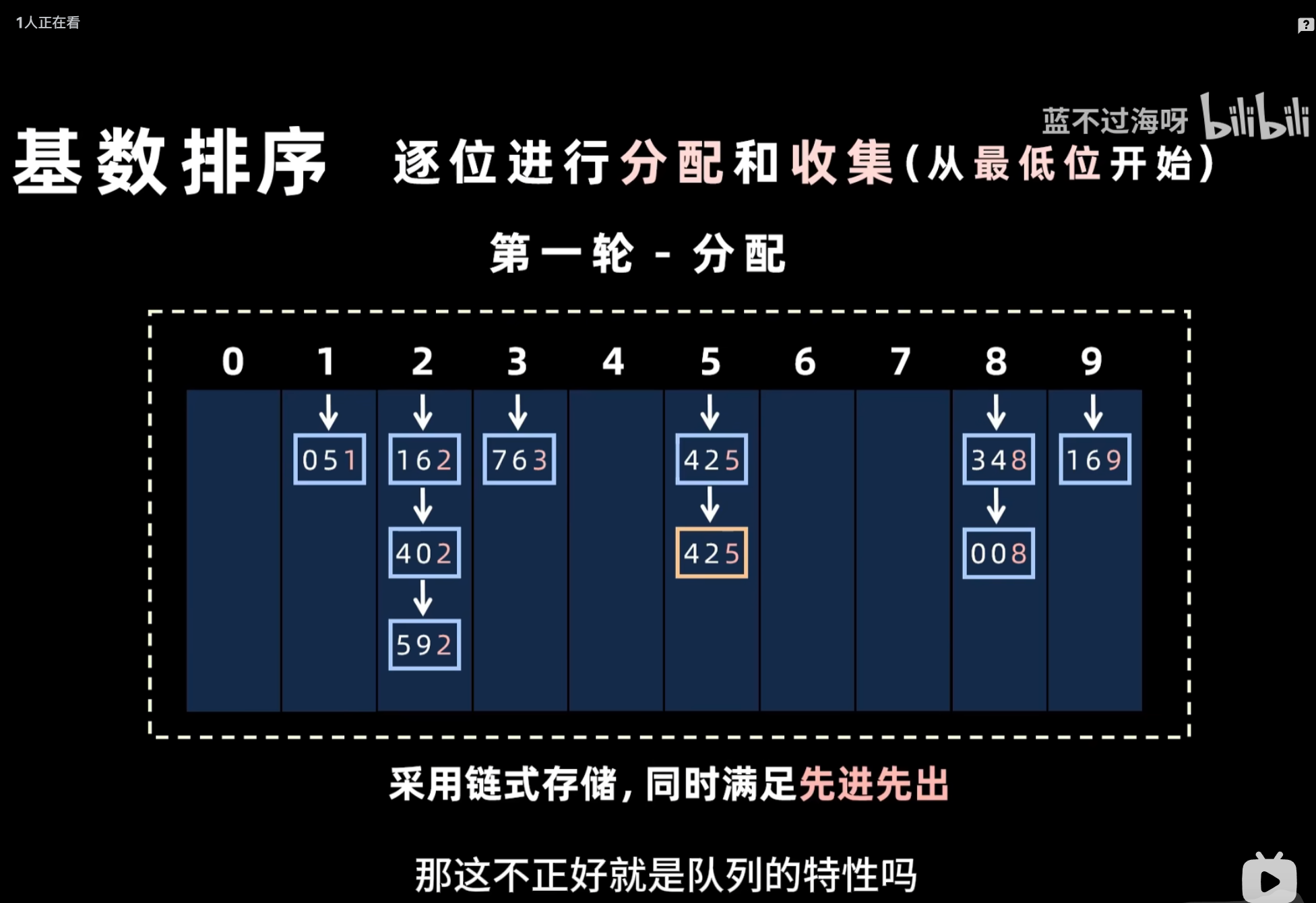
基数排序
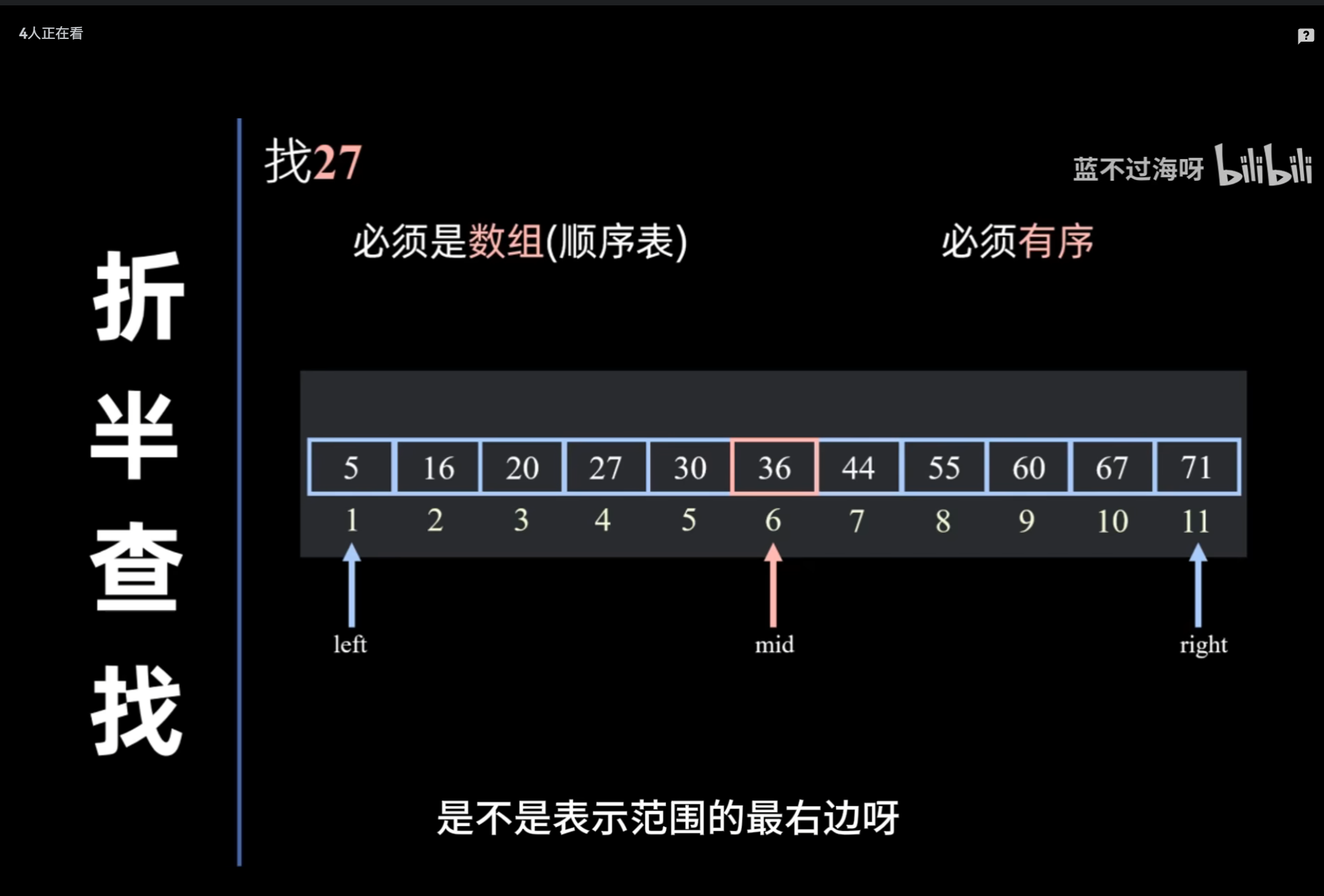
折半查找
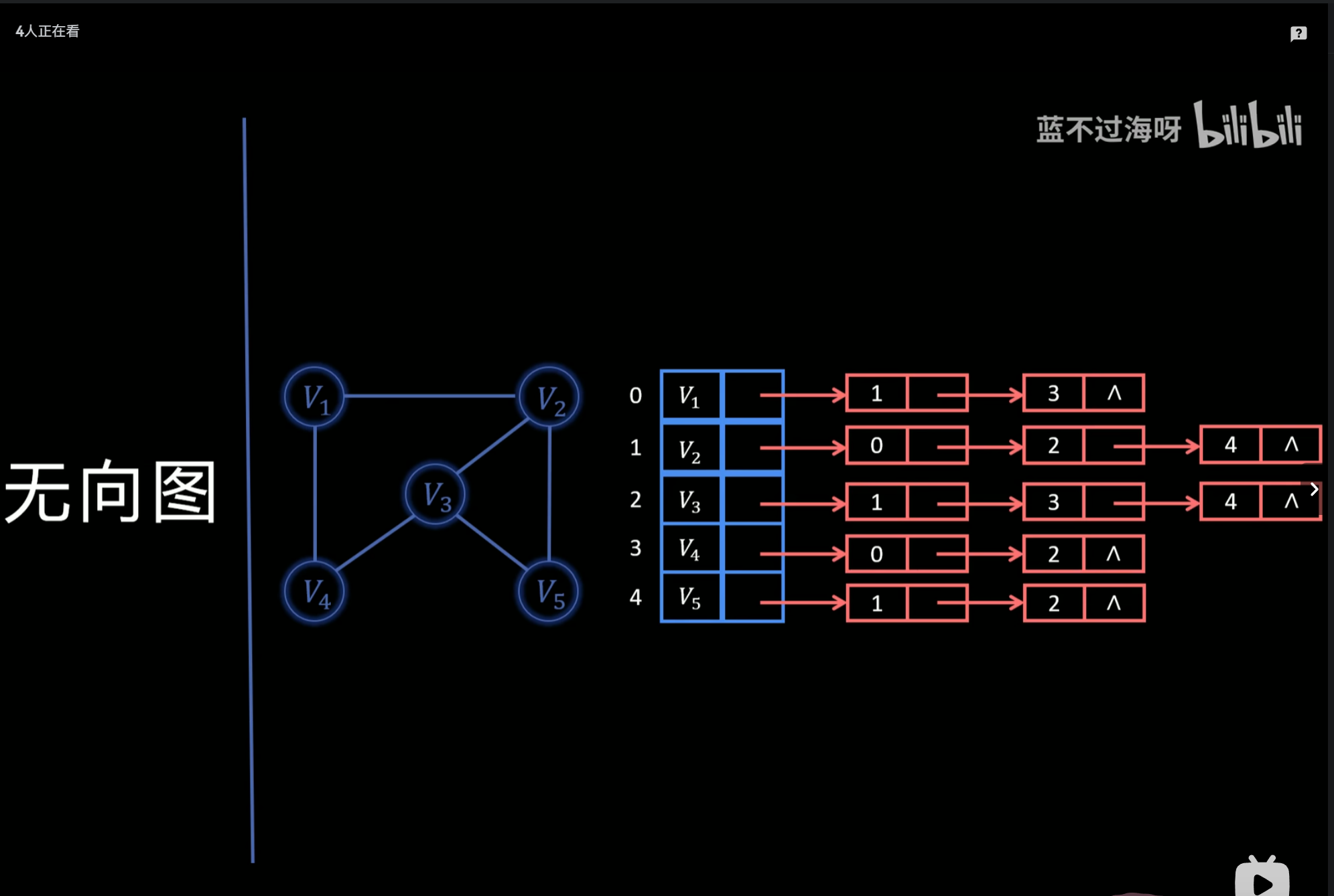
邻接矩阵和邻接表
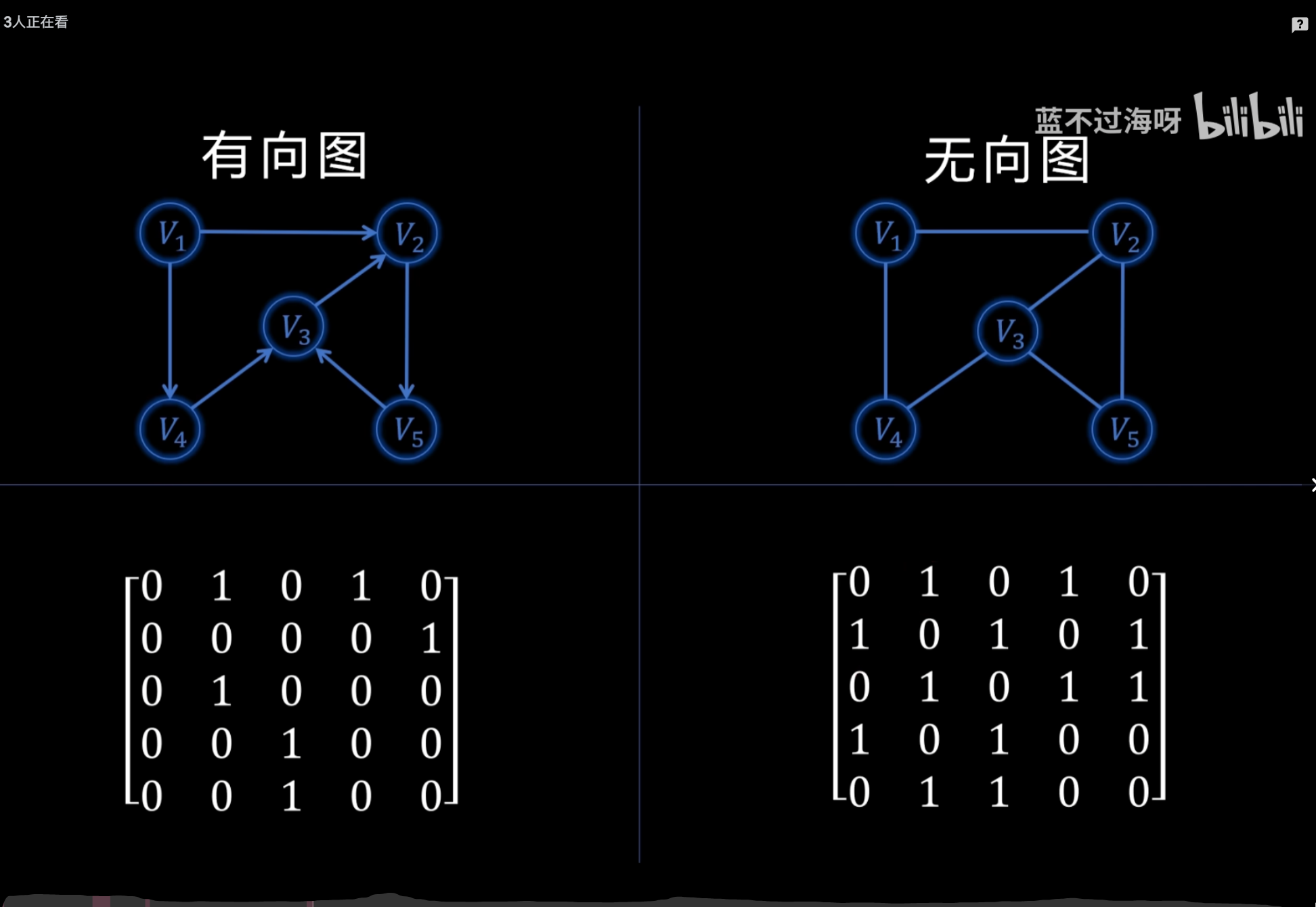
一、邻接矩阵(Adjacency Matrix)
用 二维数组 存图。优点
判断两点是否有边:O(1)
实现简单、直观
缺点
空间复杂度 O(n²),非常浪费空间
遍历所有边慢:O(n²)
适用稠密图(边很多,接近 n²)
二、邻接表(Adjacency List)
用 数组 + 链表 / 动态数组 存图。优点
空间省:O(n + e)
遍历边效率高
缺点
- 判断两点是否连通要遍历链表:O (度)
适用稀疏图(实际开发、算法题 99% 都用邻接表)
三、一句话对比
邻接矩阵:费空间、查边快
邻接表:省空间、遍历快
稠密图用矩阵,稀疏图用邻接表
深度优先遍历和广度优先遍历
一、深度优先遍历 DFS(Depth-First-Search)
核心:一条路走到黑,不撞南墙不回头,回溯
数据结构:栈(递归本质也是栈)
思想:优先往深处走,走不通再回退
实现:递归 / 栈迭代
顺序:先深入,后回溯
二、广度优先遍历 BFS(Breadth-First-Search)
核心:一圈一圈往外扩散,先近后远
数据结构:队列
思想:先访问完当前层所有节点,再访问下一层
实现:队列迭代(一般不递归)
顺序:按层次扩散
三、对比记忆
DFS 深度优先 BFS 广度优先 数据结构 栈(递归 / 手动栈) 队列 特点 深度优先,回溯 层次扩散,先近后远 空间 一般较小 宽图时空间可能很大 典型应用 连通性、拓扑排序、查找所有路径、回溯 最短路径(无权图)、层序遍历 四、一句话总结
DFS = 栈 = 递归 = 一条道走到黑 + 回溯
BFS = 队列 = 一圈圈扩散 = 最短路径首选
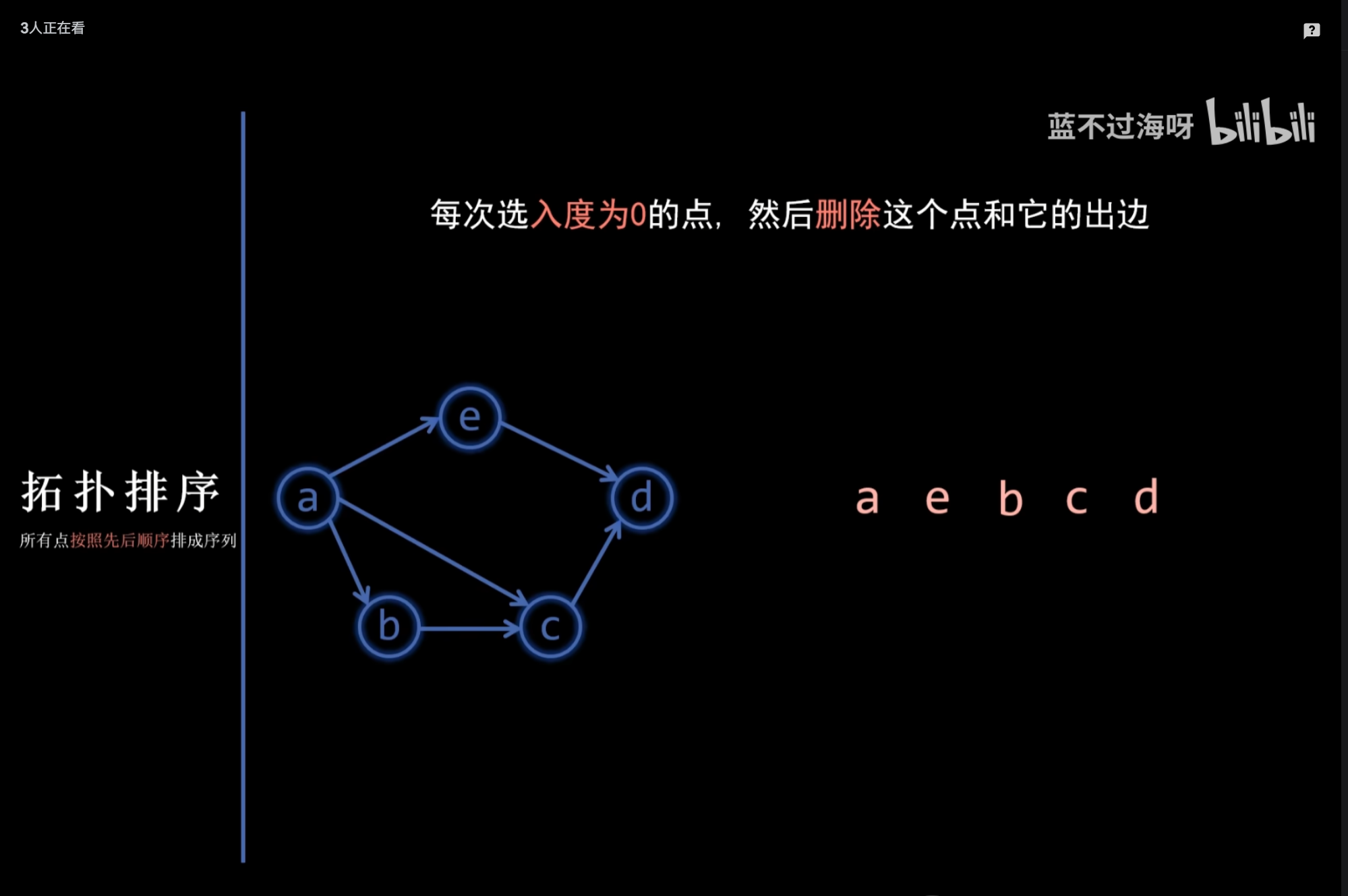
拓扑排序
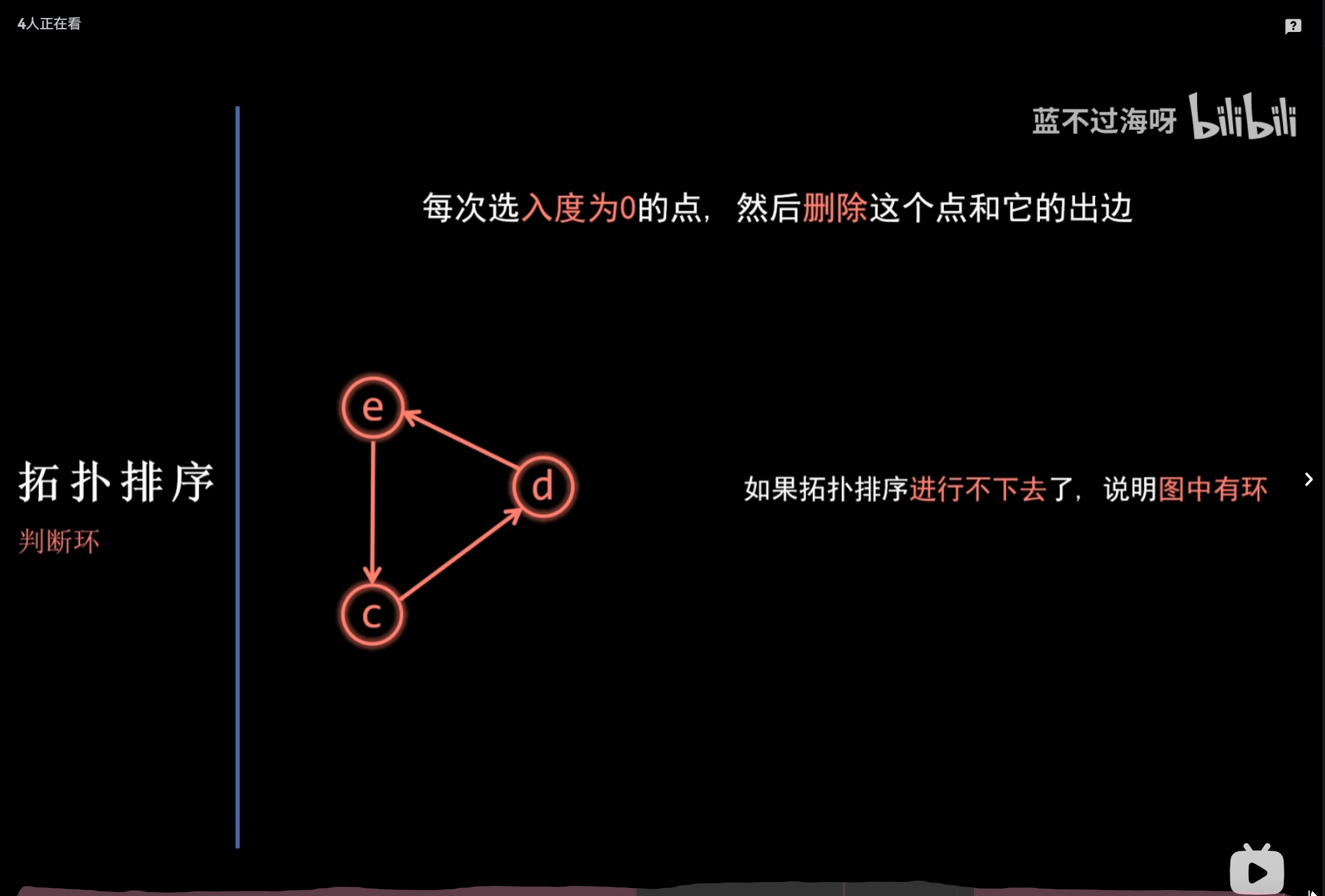
DFS、BFS
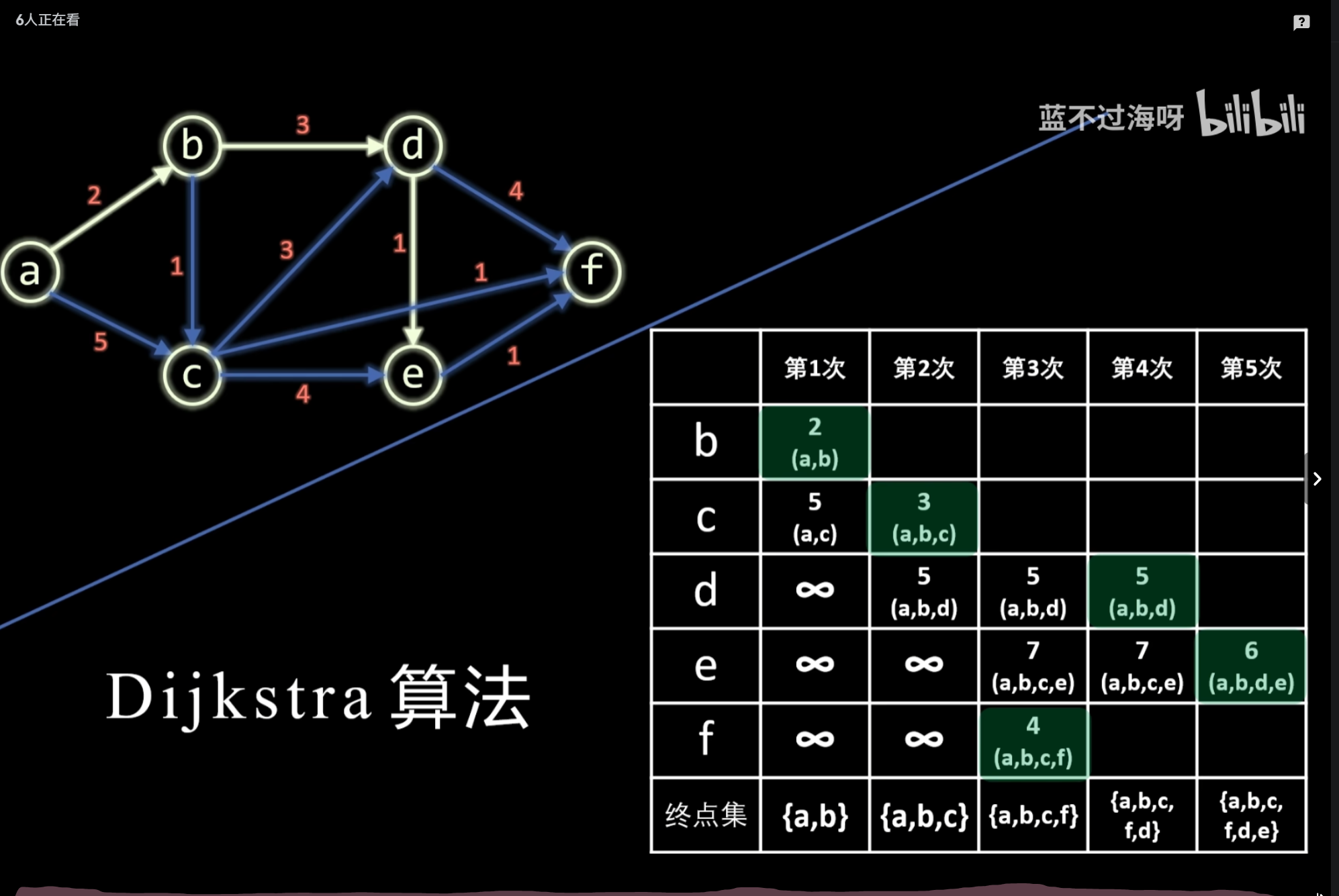
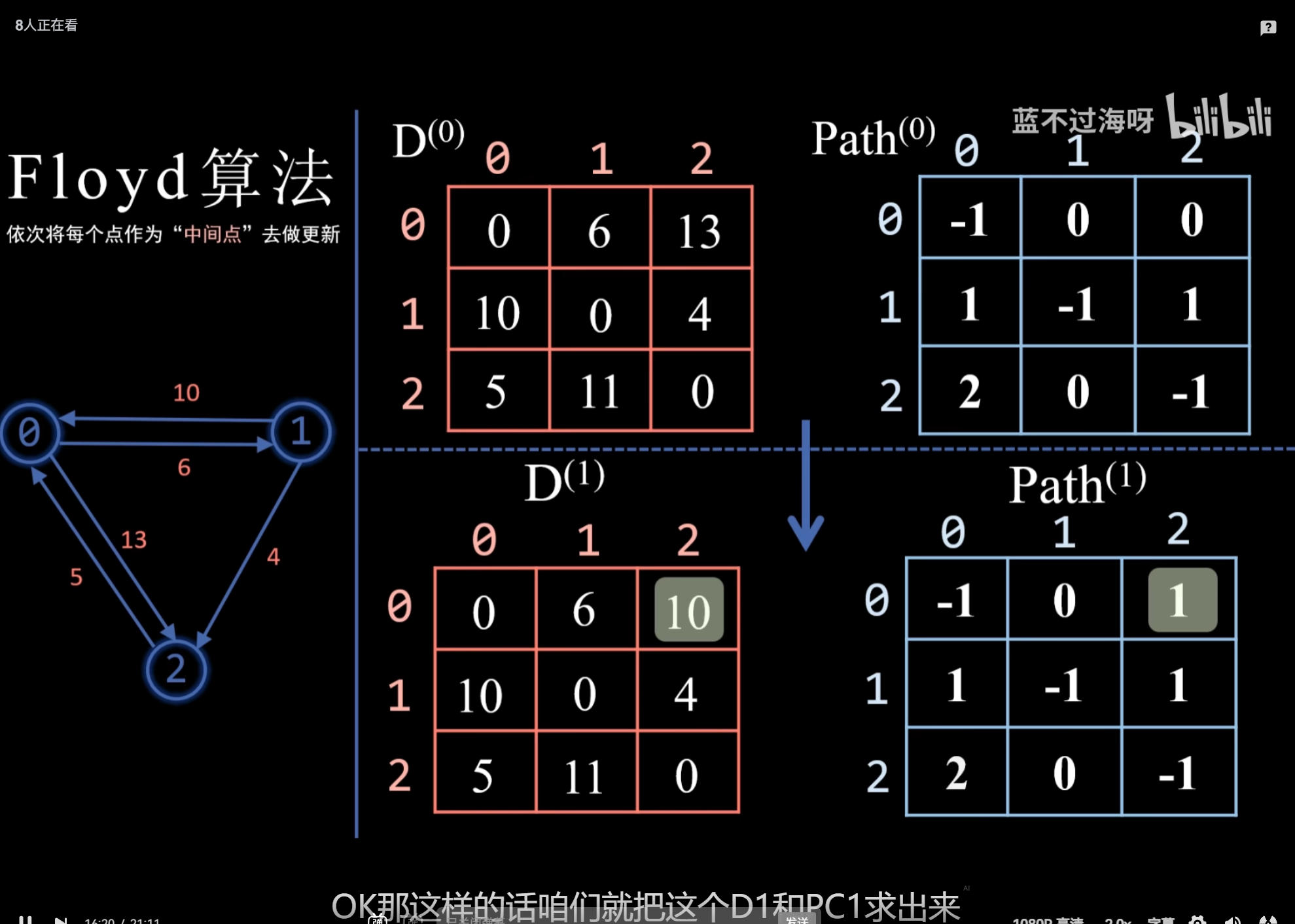
最短路径:Dijkstra、Floyd
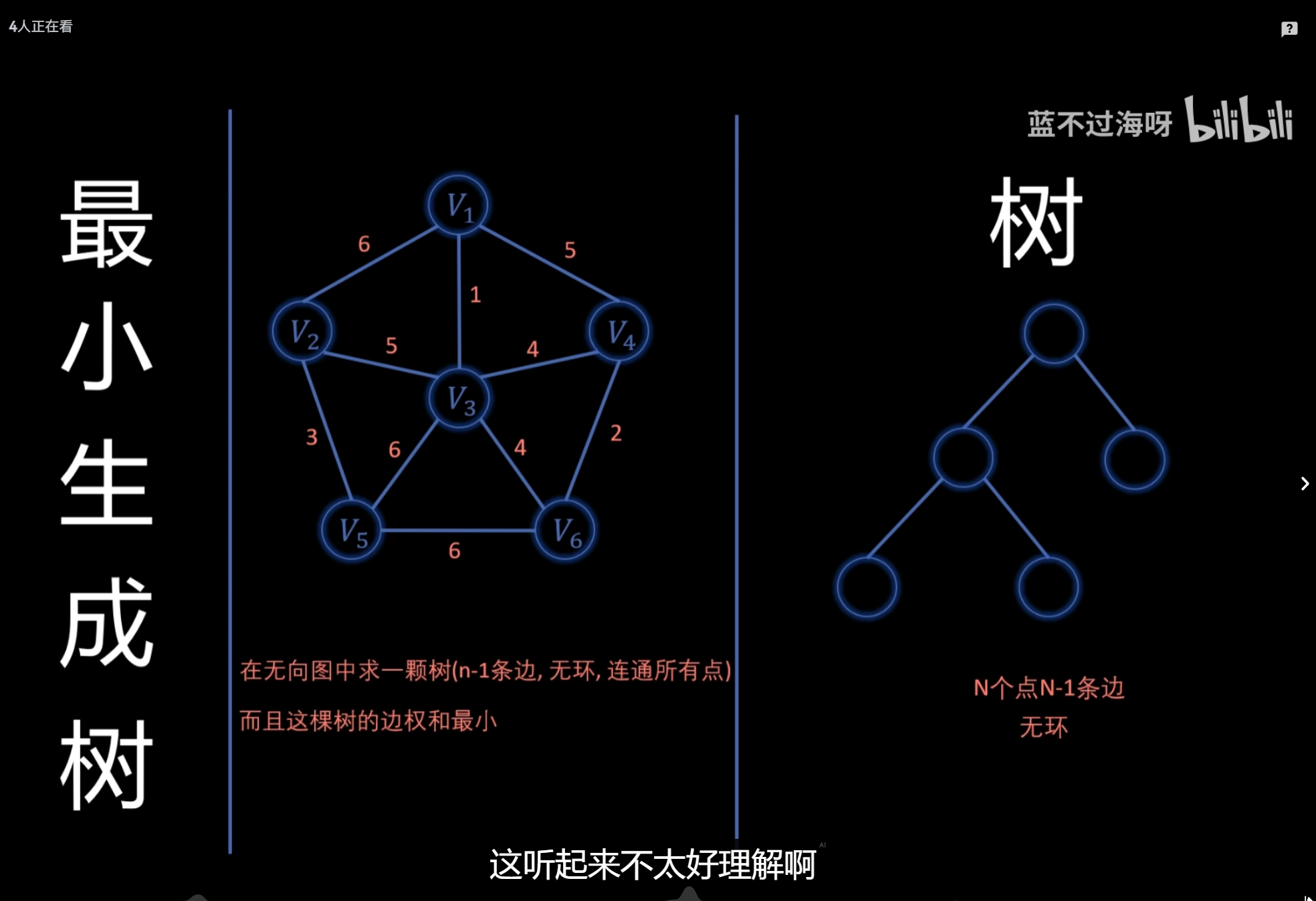
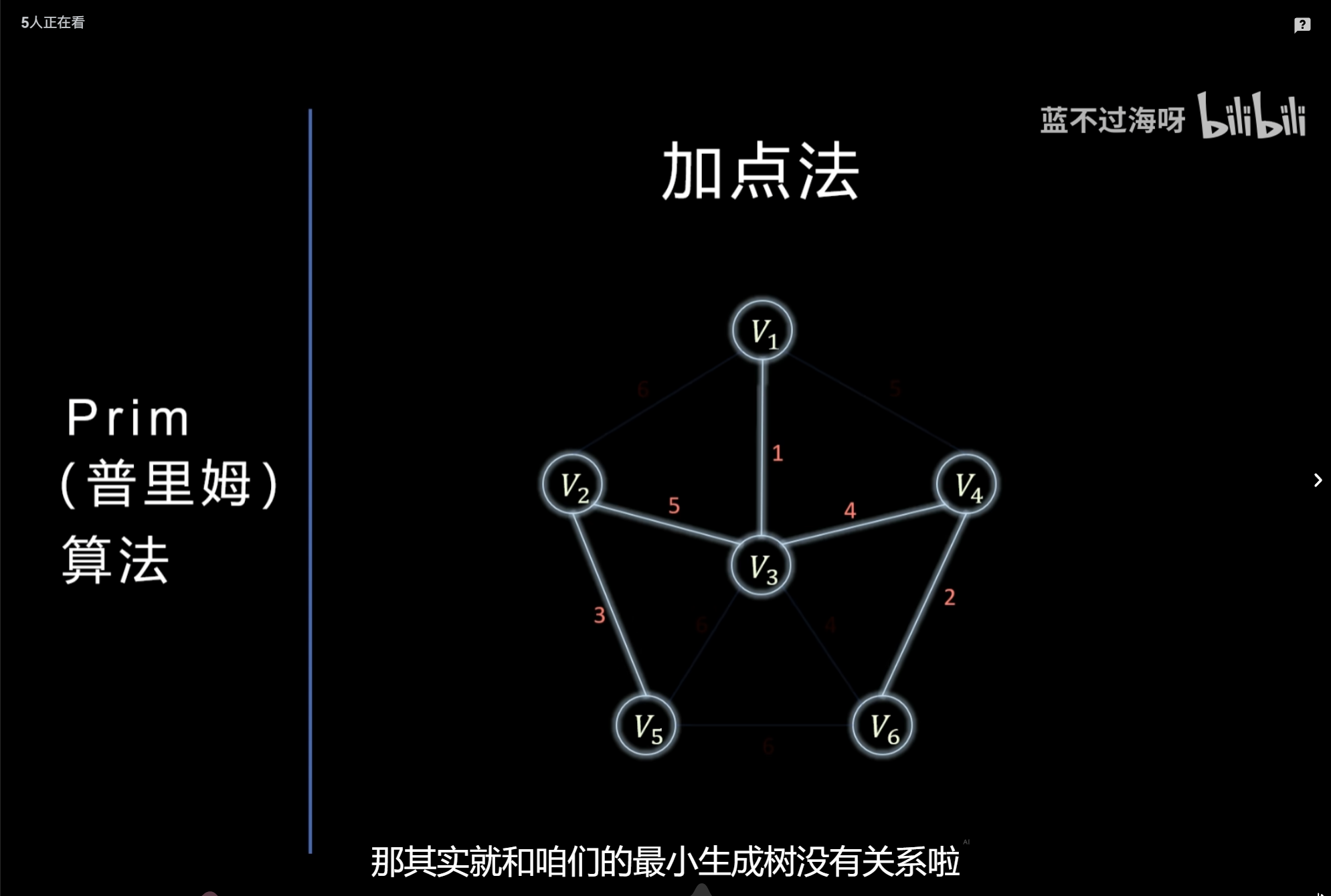
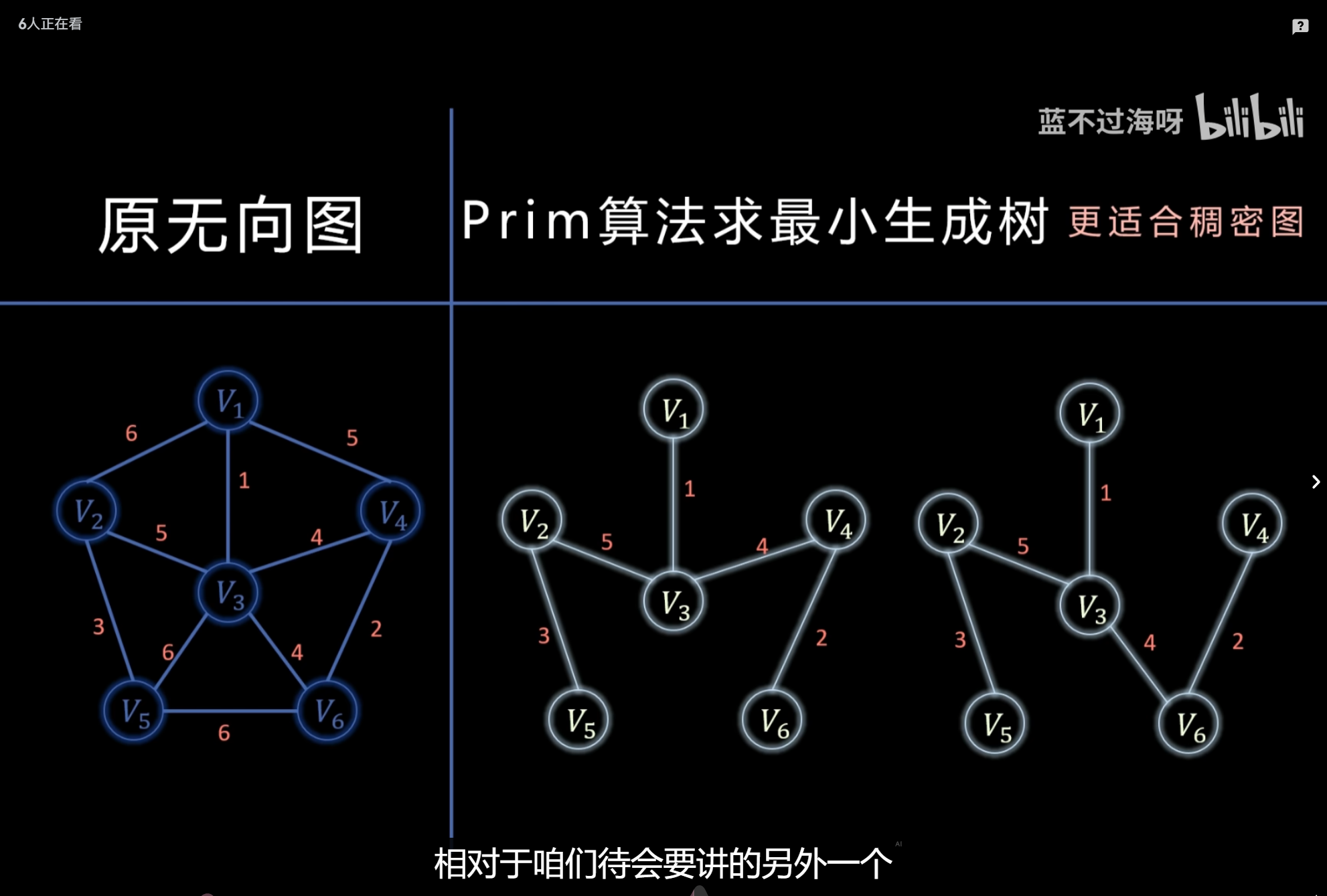
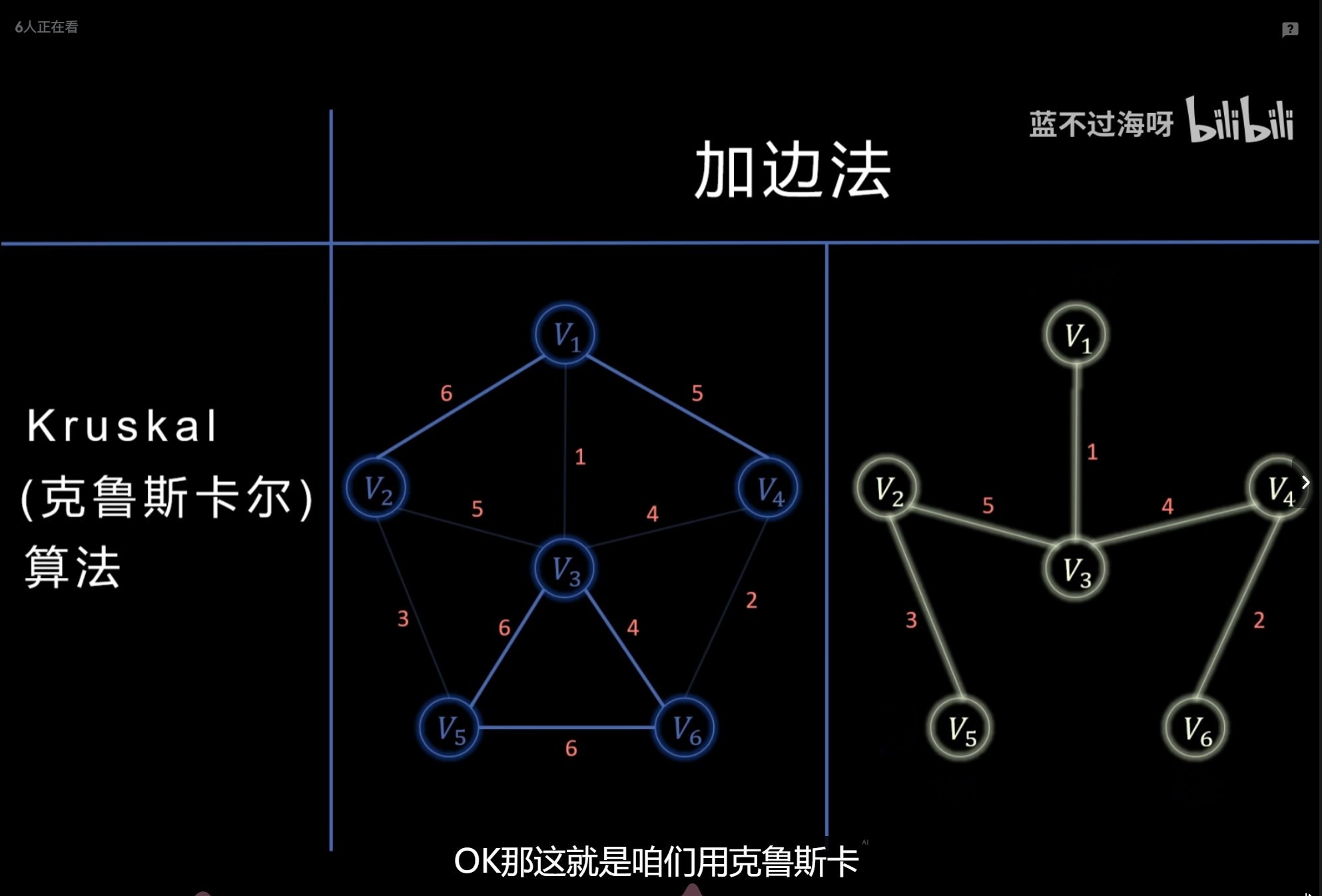
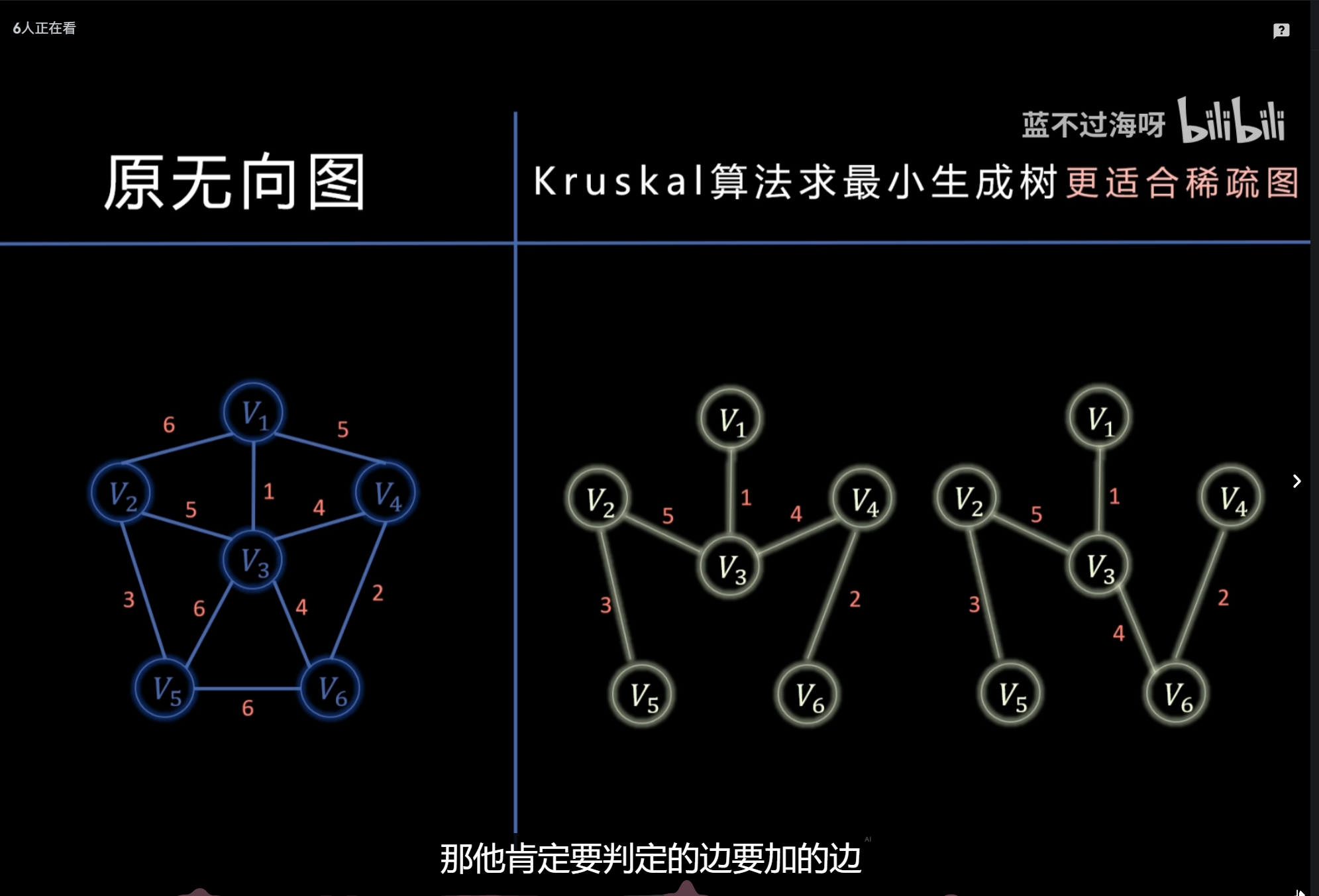
最小生成树:Kruskal、Prim
LRU 缓存实现
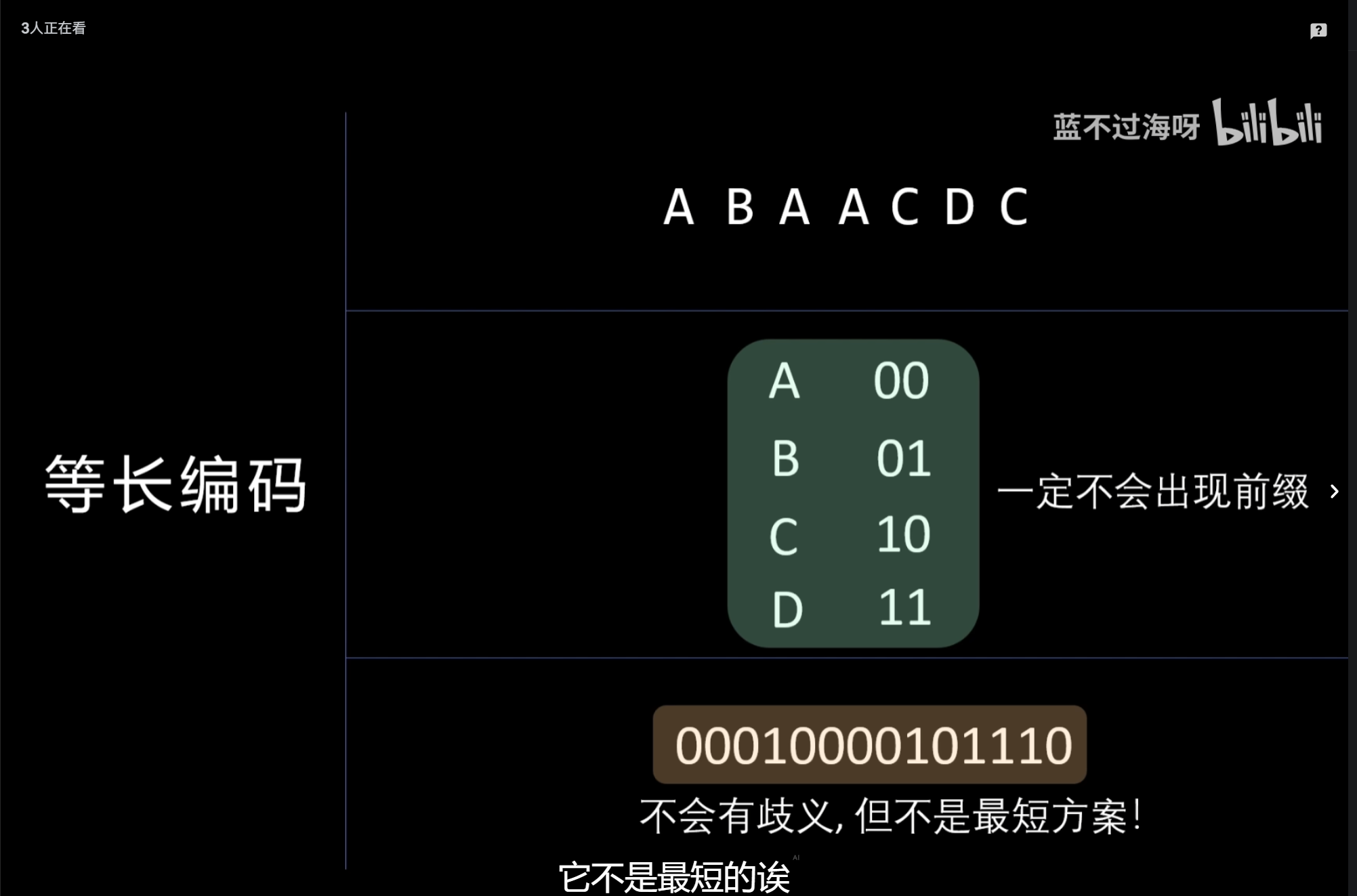
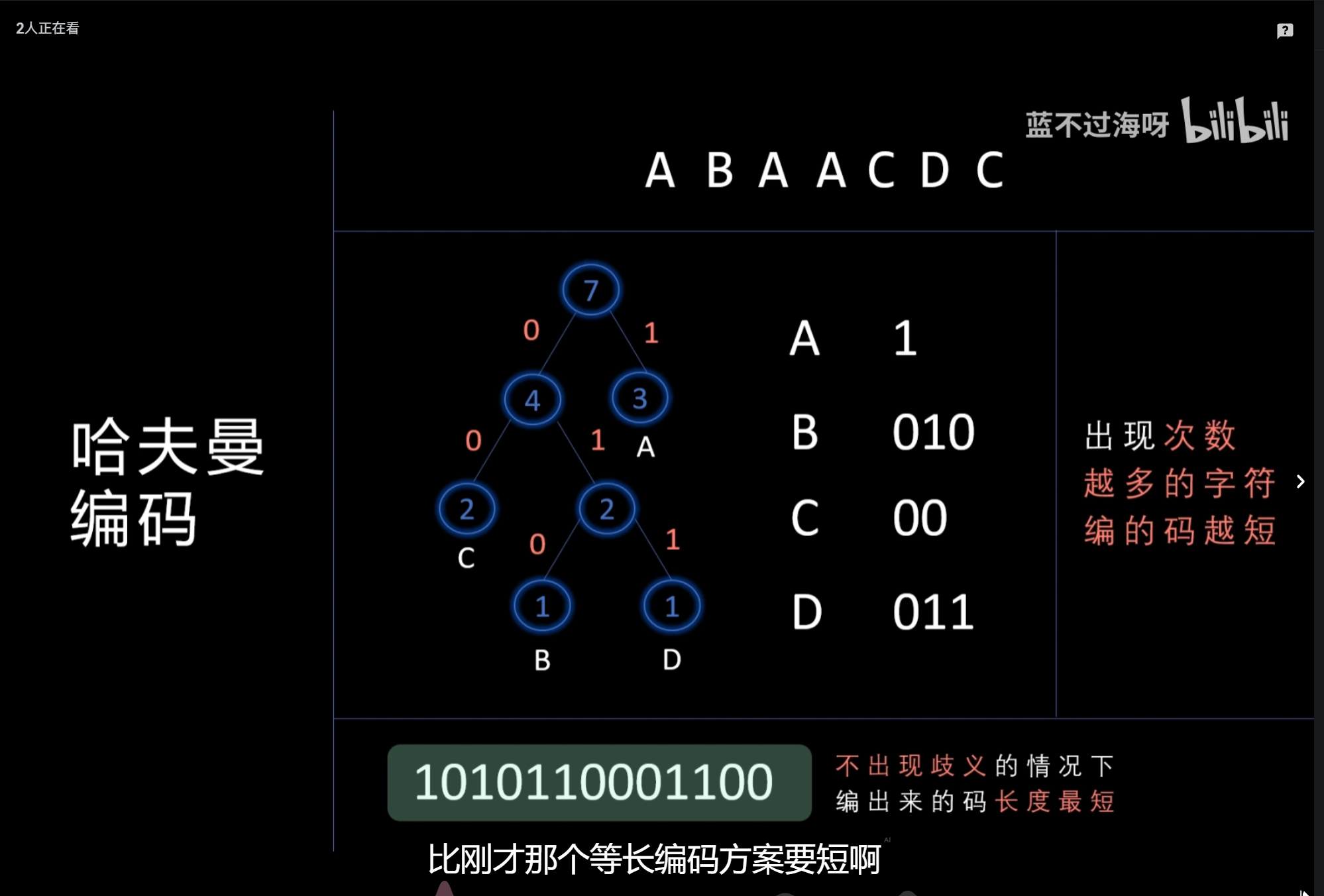
哈夫曼编码

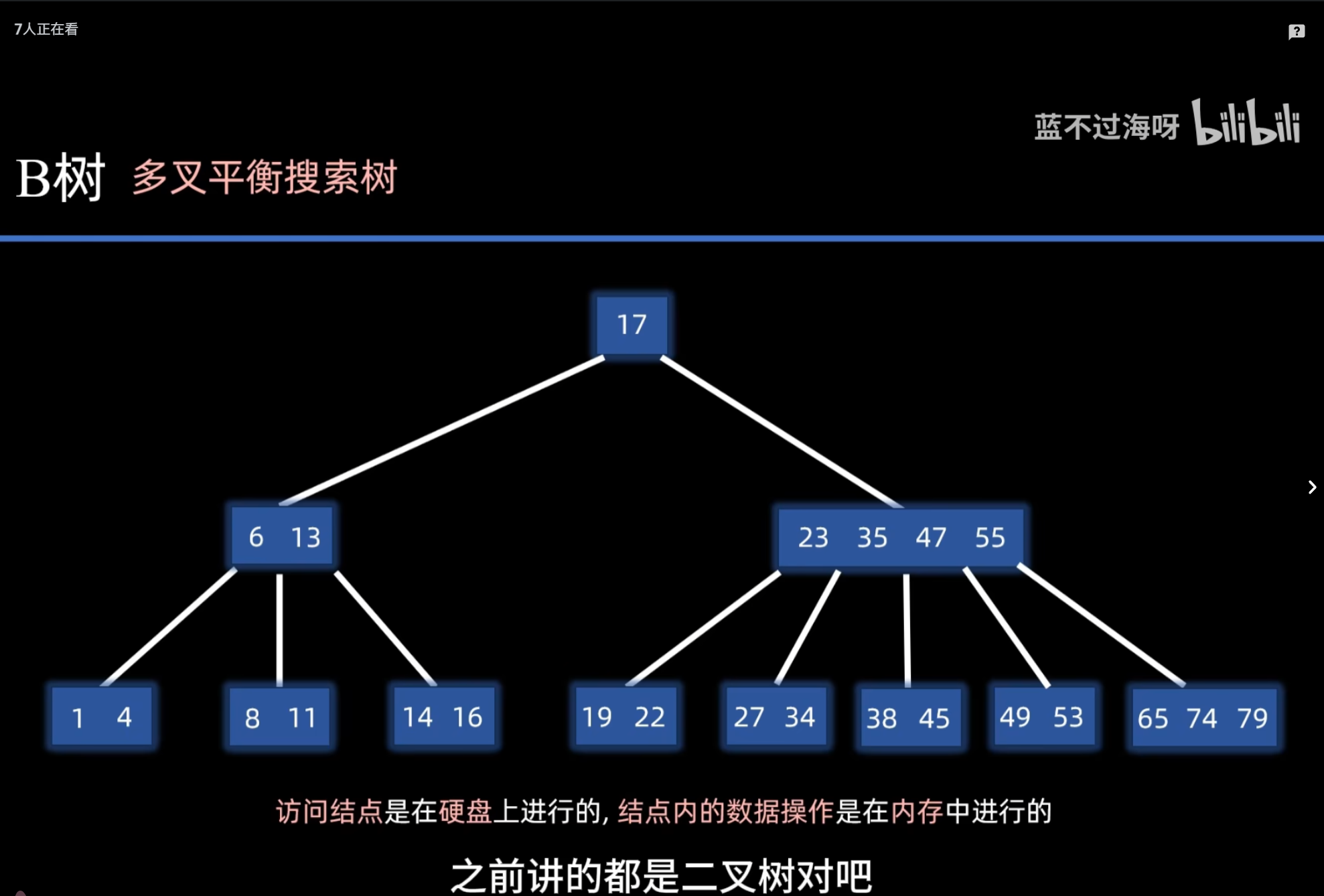
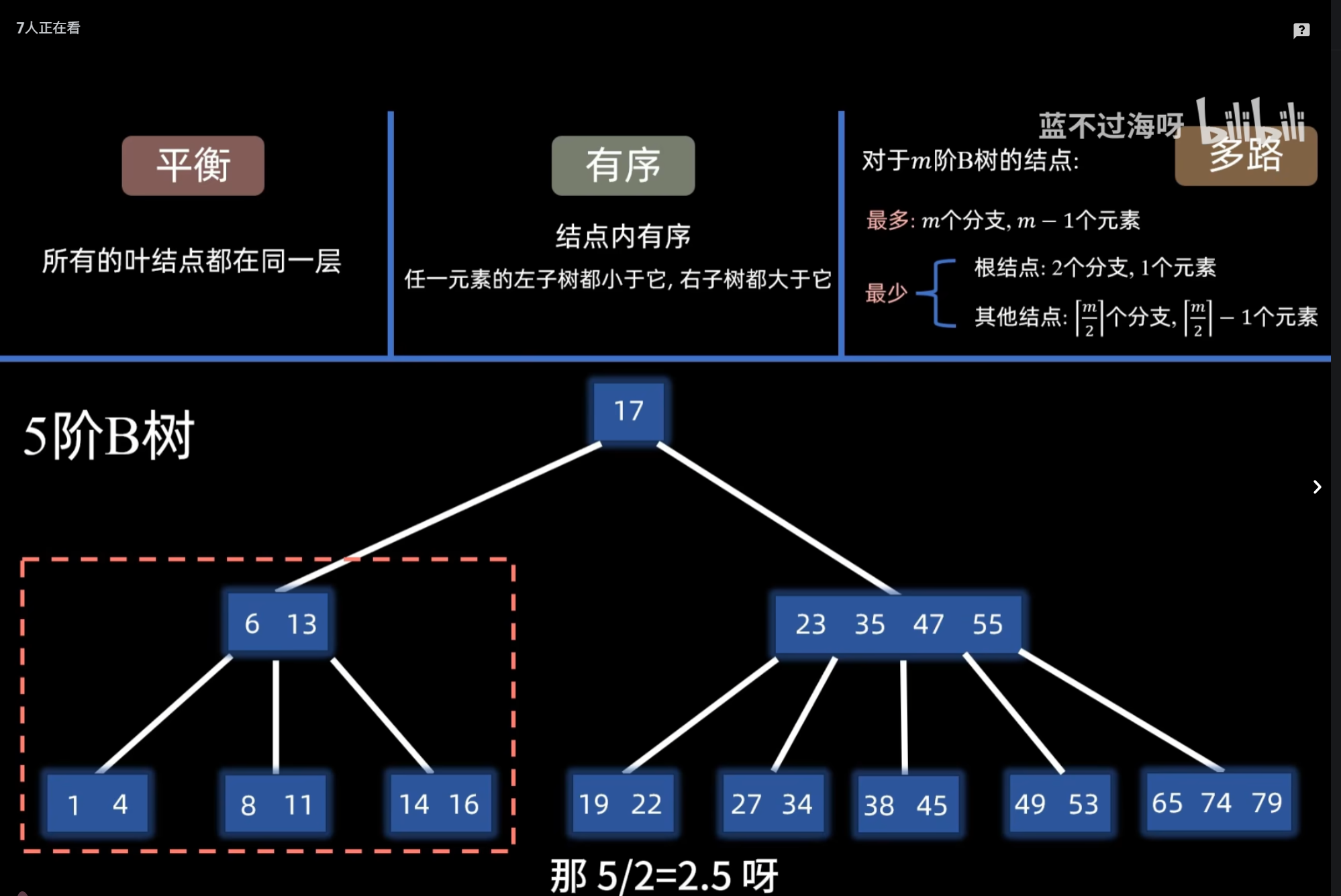
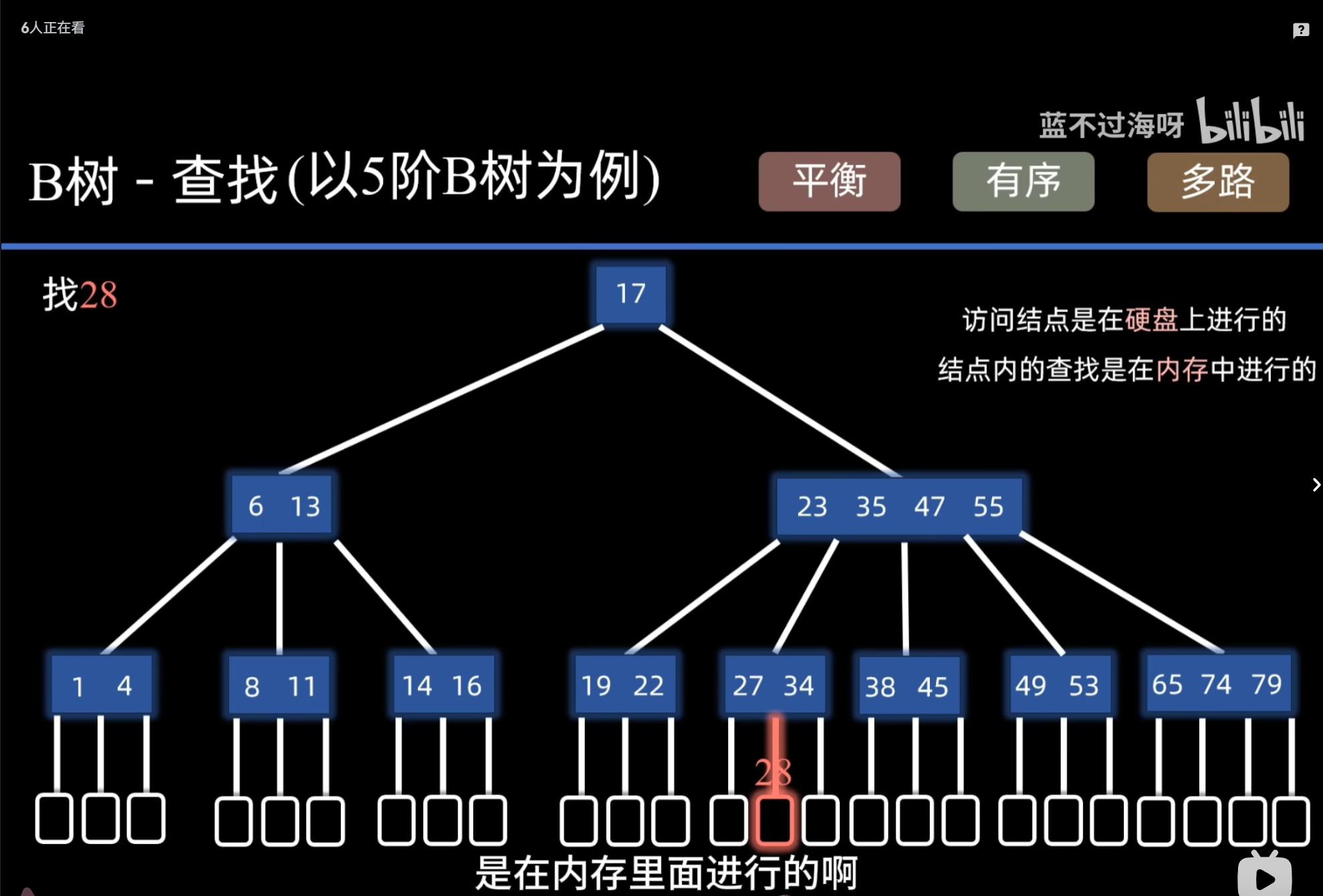
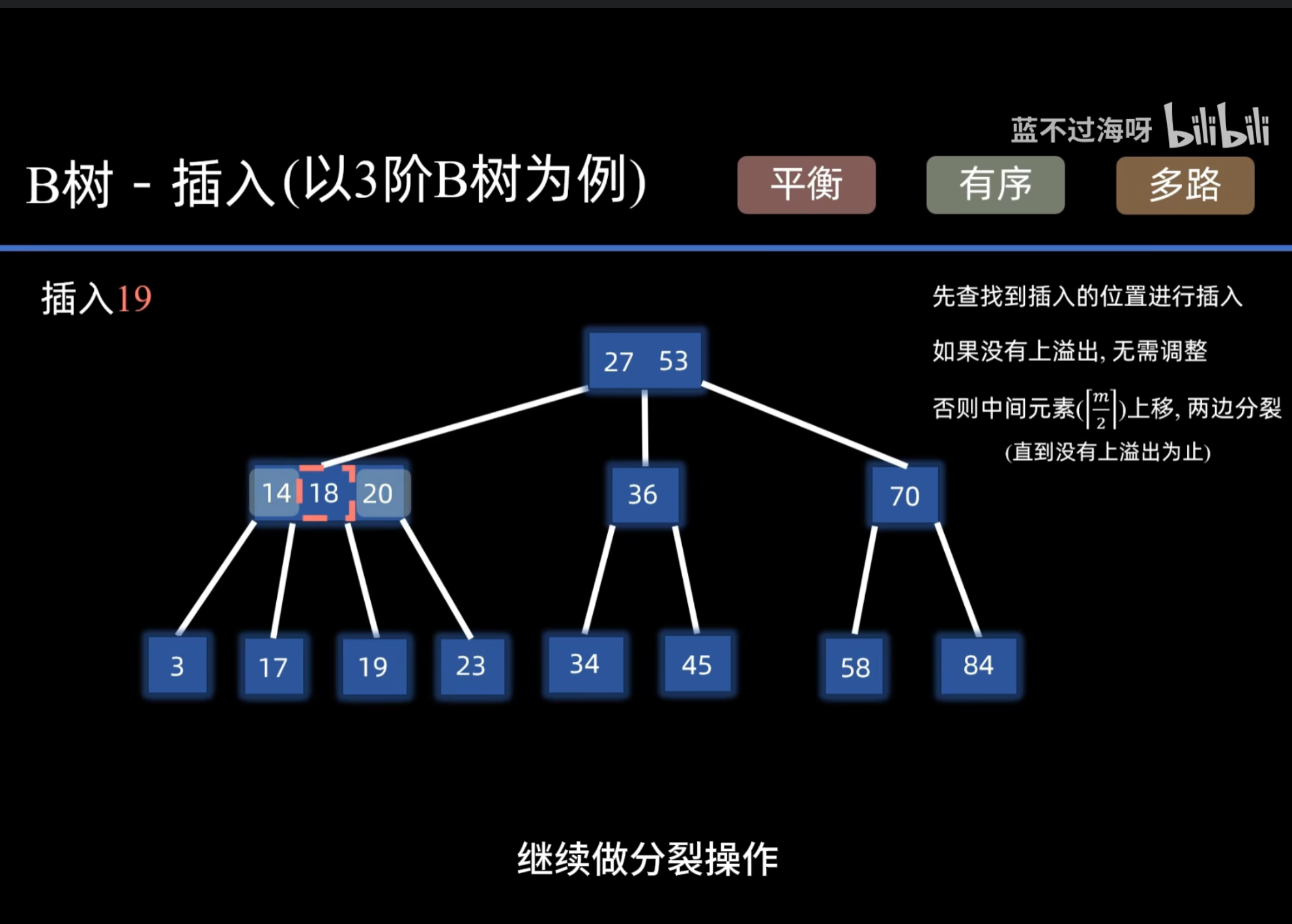
B树
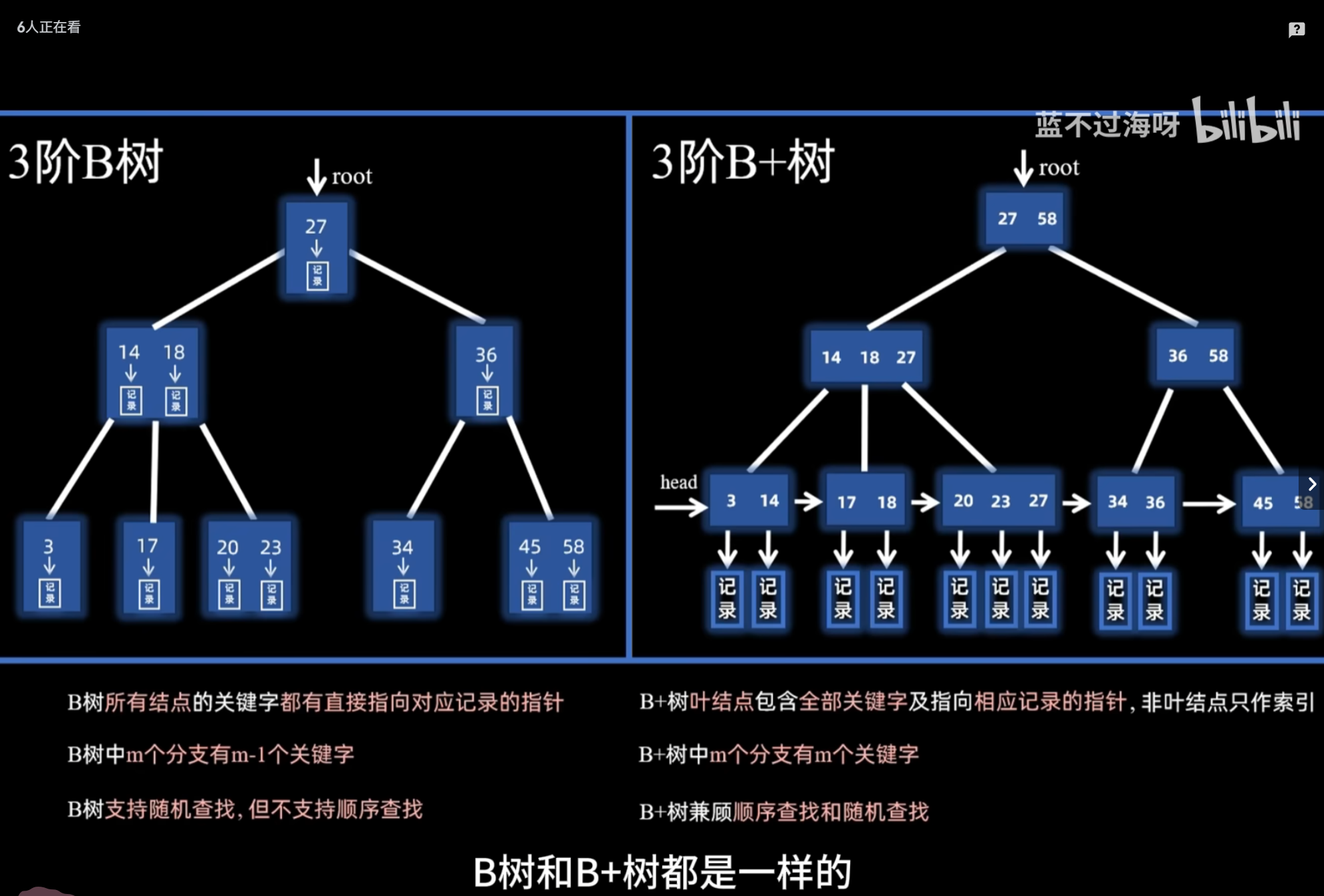
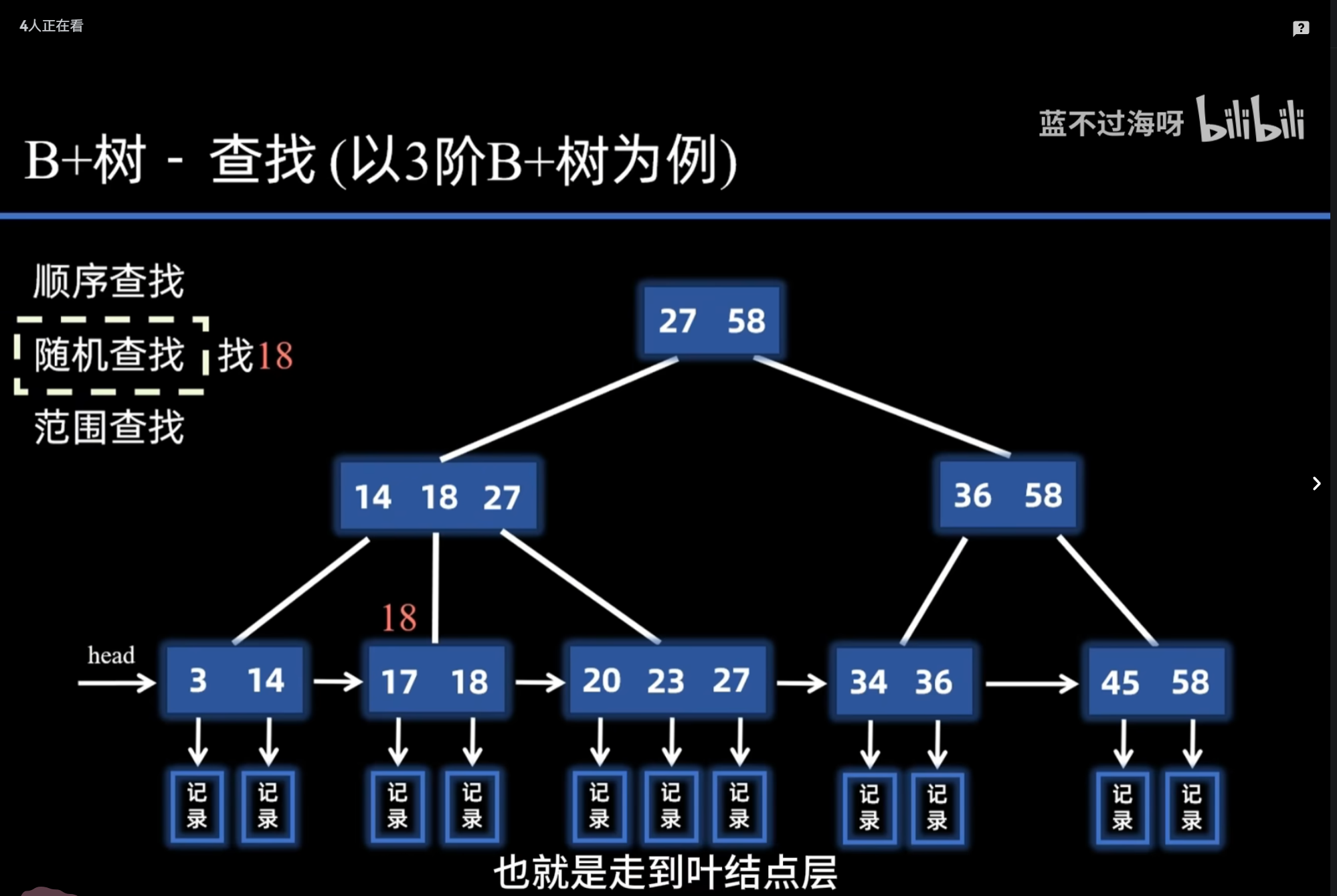
B+树
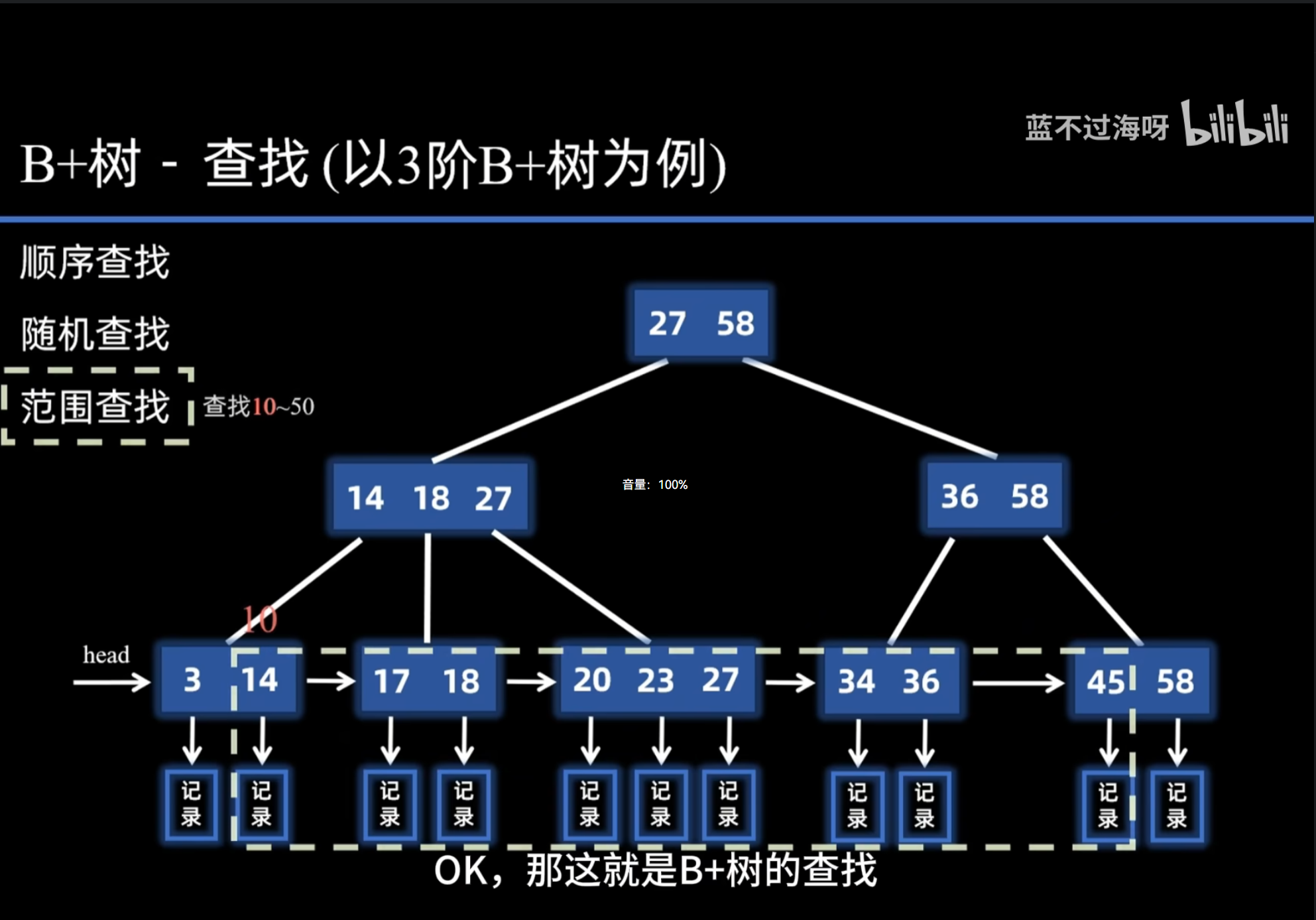
B 树 & B+ 树 核心区别
一、共同点
都是多路平衡查找树
都是为磁盘、数据库索引设计
高度低,减少磁盘 I/O,查询更快
二、核心区别(必背)
- 数据存放位置不同
B 树 :每个节点都存数据(索引 + 数据)
B+ 树 :只有叶子节点存数据,非叶子节点只存索引
- 关键字数量
B 树:n 个关键字对应 n+1 个子节点
B+ 树:n 个关键字对应 n 个子节点
- 叶子节点结构
B 树:叶子节点无指针相连
B+ 树:叶子节点用链表串联,方便范围查询
- 查询稳定性
B 树:不同关键字查询路径长度可能不同
B+ 树:所有查询都走到叶子节点,性能稳定
- 范围查询
B 树:需要回溯,效率低
B+ 树:直接遍历叶子链表,范围查询极快
- 空间利用率
- B+ 树非叶子节点不存数据,同一节点能存更多关键字,树更矮,I/O 更少
三、一句话总结
B 树:节点存数据,不支持高效范围查询
B+ 树 :数据只在叶子,叶子链表相连,范围查询强、I/O 更少、更稳定
四、应用场景
MySQL InnoDB 索引 → B+ 树(范围查询多)
文件系统、部分数据库索引 → B 树
二叉搜索树,平衡二叉树,红黑树,B树,B+树依次解决什么问题
1. 二叉搜索树 BST
解决问题:
从无序数组 的 O (n) 查找 → 提升到 O(log n)
实现快速查找、插入、删除
带来问题:
- 数据有序插入时,会退化成链表,又变回 O (n)
2. 平衡二叉树 AVL
解决问题:
解决 BST 退化成链表 的问题
强制左右高度差 ≤1,保证始终 O(log n)
带来问题:
插入删除要频繁旋转,维护成本高
节点要存高度信息,开销大
3. 红黑树
解决问题:
解决 AVL 旋转太多、增删慢 的问题
用弱平衡换更少旋转,增删效率更高
查询依然稳定 O (log n)
适用:Java TreeMap、C++ map、Linux 内核
4. B 树(多路平衡查找树)
解决问题:
解决 二叉树在磁盘 / 数据库中 I/O 次数太多 的问题
从 "二叉" 变 "多路",树更矮,减少磁盘 I/O
适用:文件系统、部分数据库索引
5. B+ 树
解决问题:
解决 B 树范围查询慢、空间利用率低 的问题
非叶子只存索引,一页能存更多 key
叶子链表相连,范围查询极快
所有查询都到叶子,性能更稳定
适用:MySQL InnoDB 索引(最常用)
一句话进化链
无序数据→ BST :快查→ AVL :防止退化→ 红黑树 :增删更快→ B 树 :适配磁盘,减少 IO→ B + 树:数据库最优,范围查询强
数组(Array)时间复杂度
访问(按下标取值)
arr[i]时间复杂度:O(1)
原因:内存连续,直接通过地址计算定位。
插入
尾部插入:O(1)
头部 / 中间插入:O(n)
原因:插入后后面元素要整体后移。
删除
尾部删除:O(1)
头部 / 中间删除:O(n)
原因:删除后后面元素要整体前移。
链表 访问 / 插入 / 删除
默认是带头结点 / 不带头结点的单链表,双向链表类似。
- 访问(按下标找第 k 个节点)
必须从头节点一个个遍历
时间复杂度:O(n)
- 插入
已知前驱节点,在其后插入:O(1)
不知道前驱,要先找到位置再插:O(n)
- 删除
已知前驱节点,删除后继:O(1)
不知道前驱,要先查找再删:O(n)
栈 & 队列
一、栈 Stack
特点:后进先出 LIFO
常用操作
入栈:
push(x)出栈:
pop()取栈顶:
top()/peek()判断空:
isEmpty()时间复杂度
- 入栈、出栈、取栈顶:O(1)
二、队列 Queue
特点:先进先出 FIFO
常用操作
入队:
enqueue(x)/add(x)出队:
dequeue()/remove()取队首:
front()/peek()判断空:
isEmpty()时间复杂度
- 入队、出队、取队首:O(1)
三、一句话区分
栈:一头进出,后进先出
队列:一头进一头出,先进先出
所有基础操作都是 O(1)
BST 查找、插入、删除(最好 / 最坏)
平衡 BST:都是 O(logn)
退化成链表:都是 O(n)
所以才需要 AVL、红黑树保证稳定 O(logn)
哈希表(散列表)增删改查时间复杂度
前提:使用链地址法(拉链法)解决哈希冲突
平均情况(正常,哈希均匀)
查找:O(1)
插入:O(1)
删除:O(1)
修改:O(1)
最坏情况(所有元素哈希到同一个位置,退化成链表)
查找:O(n)
插入:O(n)
删除:O(n)
修改:O(n)
一句话速记
平均:全都 O(1)
最坏:全都 O(n)
JDK1.8+ 当链表过长会转红黑树 ,最坏降为 O(log n)
LRU 缓存是什么
LRU = Least Recently Used(最近最少使用)
一种缓存淘汰策略
当缓存满了,删除最久没被访问过的数据,保留最近使用的
要求:
get(key):获取值,不存在返回 -1
put(key, value):插入 / 更新值,缓存满则淘汰最久未使用的
TopK:找前 K 个最大 / 最小数据
海量数据首选:堆
求最大 → 小顶堆
求最小 → 大顶堆
复杂度:O(n log K)
布隆过滤器 = 位数组 + 多个哈希
一定不存在 → 绝对可信
可能存在 → 有概率误判
极省空间、极快,适合海量数据判重、防缓存穿透。