
系列文章目录
提示:这里是系列文章的专栏
提示:以下是文章目录哦!
文章目录
[一、unordered_set 的介绍与使用](#一、unordered_set 的介绍与使用)
[1.1 什么是 unordered_set](#1.1 什么是 unordered_set)
[1.2 模板参数详解](#1.2 模板参数详解)
[1.3 常用接口演示(带详细注释)](#1.3 常用接口演示(带详细注释))
[1.4 unordered_set 与 set 的核心对比](#1.4 unordered_set 与 set 的核心对比)
[二、unordered_map 的介绍与使用](#二、unordered_map 的介绍与使用)
[2.1 什么是 unordered_map](#2.1 什么是 unordered_map)
[2.2 模板参数](#2.2 模板参数)
[2.3 常用接口演示](#2.3 常用接口演示)
[2.4 unordered_map 与 map 的核心对比](#2.4 unordered_map 与 map 的核心对比)
[三、重点展开:平均 O (1),最坏 O (N) 到底是什么意思?](#三、重点展开:平均 O (1),最坏 O (N) 到底是什么意思?)
[3.1 平均 O (1):哈希表的正常工作状态](#3.1 平均 O (1):哈希表的正常工作状态)
[3.2 最坏 O (N):哈希冲突极端场景](#3.2 最坏 O (N):哈希冲突极端场景)
[四、重点展开:为什么 unordered 迭代器只能 ++,不能 --?(前向迭代器)](#四、重点展开:为什么 unordered 迭代器只能 ++,不能 --?(前向迭代器))
[4.1 底层结构决定了迭代器行为](#4.1 底层结构决定了迭代器行为)
[4.2 为什么不能 --?](#4.2 为什么不能 --?)
[4.3 前向迭代器的限制](#4.3 前向迭代器的限制)
[4.4 对比记忆](#4.4 对比记忆)
[五、unordered_multiset 与 unordered_multimap 简述](#五、unordered_multiset 与 unordered_multimap 简述)
[六、性能实测:set 与 unordered_set 对比](#六、性能实测:set 与 unordered_set 对比)
[6.1 测试代码](#6.1 测试代码)
[6.2 结果分析](#6.2 结果分析)
[七.unordered_map /unordered_set 底层实现详细讲解](#七.unordered_map /unordered_set 底层实现详细讲解)
[7.1 整体结论(先给结论,再讲细节)](#7.1 整体结论(先给结论,再讲细节))
[7.2 底层实现](#7.2 底层实现)
[7.2.1 节点结构](#7.2.1 节点结构)
[7.2.2 哈希表整体结构](#7.2.2 哈希表整体结构)
[7.2.4 查找流程](#7.2.4 查找流程)
[7.3 为什么要扩容?](#7.3 为什么要扩容?)
[7.3.1 扩容规则(STL 标准)](#7.3.1 扩容规则(STL 标准))
[7.3.2 扩容步骤](#7.3.2 扩容步骤)
[7.3.3 扩容代码(STL 简化版)](#7.3.3 扩容代码(STL 简化版))
[7.4 封装 unordered_set](#7.4 封装 unordered_set)
[7.5 封装 unordered_map](#7.5 封装 unordered_map)
前言
提示:这里可以添加本文要记录的大概内容:
前面我们已经系统学习了红黑树的原理与实现,以及 map/set 等有序关联容器的使用。而在 C++ STL 中,还有一组功能相似但性能截然不同的无序关联容器:unordered_map 和 unordered_set
它们的底层是我们上一篇文章详细讲解过的哈希表 ,凭借平均 O (1) 的增删查效率,在海量数据处理场景中表现远超红黑树容器。很多开发者只会直接调用库函数,却不懂它们的模板参数、底层特性、与 map/set 的核心差异,以及如何为自定义类型提供哈希支持
本文将从使用方法、模板参数解析、与有序容器对比、性能实测等多个维度,带你彻底吃透这两个容器,并通过一个简易版哈希桶的实现,帮你理解其底层逻辑
提示:以下是本篇文章正文内容
一、unordered_set 的介绍与使用
1.1 什么是 unordered_set
unordered_set 是 C++11 引入的无序关联容器,底层基于哈希表(链地址法) 实现。它的主要特性有:
- 无序存储:元素的存储顺序和插入顺序无关,遍历结果是无序的
- 自动去重:容器中不允许存在重复的元素
- 高效操作:插入、查找、删除的平均时间复杂度为 O (1)
1.2 模板参数详解
cpp
template <class Key,
class Hash = hash<Key>,
class Pred = equal_to<Key>,
class Alloc = allocator<Key>>
class unordered_set;Key:容器中存储的元素类型Hash:哈希函数对象,负责将Key类型的值转换为哈希表的索引。默认使用标准库提供的hash模板Pred:相等比较函数对象,用于判断两个元素是否相等,以处理哈希冲突和去重Alloc:内存分配器,用于管理容器的内存

1.3 常用接口演示(带详细注释)
由于我们的禁言已经很丰富了,因此这里直接展示代码,还有不熟的小伙伴可以仔细看看:
这里展示了定义,插入,查找,删除,遍历,以及获取大小和判空
cpp
#include <iostream>
#include <unordered_set>
using namespace std;
void TestUnorderedSet()
{
// 1. 定义一个存储int类型的无序集合
unordered_set<int> us;
// 2. 插入元素:重复的元素会被自动忽略
us.insert(5);
us.insert(2);
us.insert(8);
us.insert(5); // 插入失败,因为5已经存在
// 3. 遍历容器:注意,输出顺序是无序的
cout << "unordered_set 遍历结果:";
for (auto val : us)
{
cout << val << " ";
}
cout << endl;
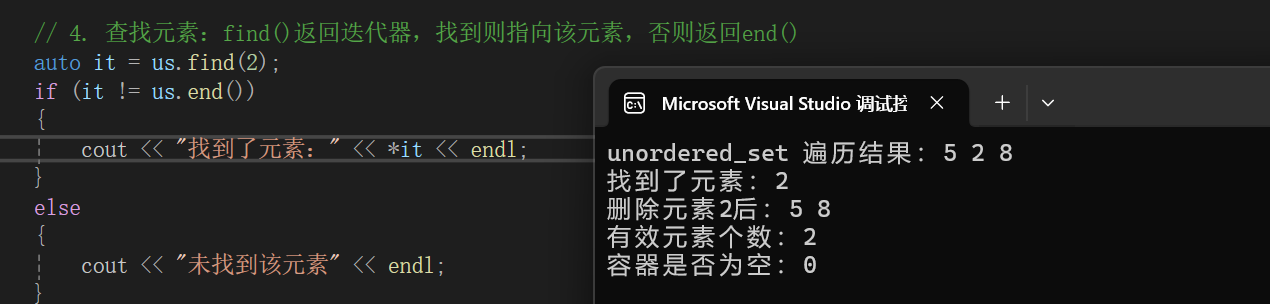
// 4. 查找元素:find()返回迭代器,找到则指向该元素,否则返回end()
auto it = us.find(2);
if (it != us.end())
{
cout << "找到了元素:" << *it << endl;
}
else
{
cout << "未找到该元素" << endl;
}
// 5. 删除元素:可以通过值或迭代器删除
us.erase(2);
cout << "删除元素2后:";
for (auto val : us)
{
cout << val << " ";
}
cout << endl;
// 6. 获取容器大小和判空
cout << "有效元素个数:" << us.size() << endl;
cout << "容器是否为空:" << us.empty() << endl;
}
int main()
{
TestUnorderedSet();
return 0;
}运行结果如下:
1.4 unordered_set 与 set 的核心对比
| 对比维度 | set | unordered_set |
| 底层结构 | 红黑树 | 哈希表(链地址法) |
| 存储特性 | 有序、去重 | 无序、去重 |
| Key 要求 | 支持 < 比较 | 支持哈希转换和 == 比较 |
| 迭代器类型 | 双向迭代器(可 ++/--) | 前向迭代器(仅可 ++) |
| 时间复杂度 | O(logN) | 平均 O (1),最坏 O (N) |
| 适用场景 | 需要有序遍历或范围查询 | 仅需增删查,不关心顺序 |
|---|
二、unordered_map 的介绍与使用
2.1 什么是 unordered_map
unordered_map 同样是基于哈希表实现的无序关联容器,它存储的是键值对(pair<const Key, T>)。其特性与 unordered_set 类似:
- 无序存储:键值对的存储顺序和插入顺序无关
- 键唯一:不允许存在重复的键
- 高效操作:插入、查找、删除的平均时间复杂度为 O (1)
2.2 模板参数
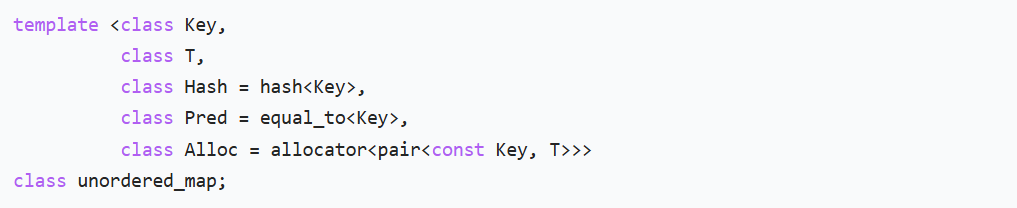
Key:键的类型,必须唯一T:值的类型Hash、Pred、Alloc:作用与unordered_set相同,针对的是键Key
2.3 常用接口演示
cpp
#include <iostream>
#include <unordered_map>
#include <string>
using namespace std;
void TestUnorderedMap()
{
// 1. 定义一个键为int、值为string的无序映射
unordered_map<int, string> um;
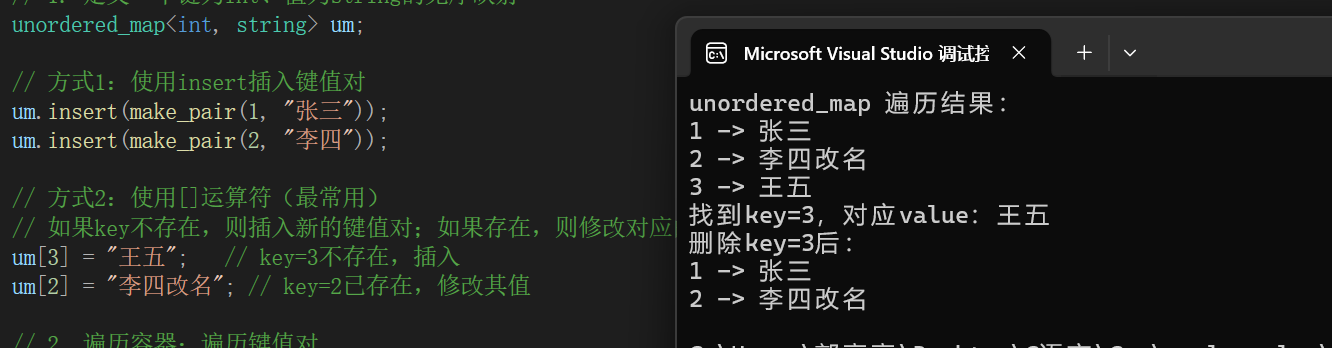
// 方式1:使用insert插入键值对
um.insert(make_pair(1, "张三"));
um.insert(make_pair(2, "李四"));
// 方式2:使用[]运算符(最常用)
// 如果key不存在,则插入新的键值对;如果存在,则修改对应的值
um[3] = "王五"; // key=3不存在,插入
um[2] = "李四改名"; // key=2已存在,修改其值
// 2. 遍历容器:遍历键值对
cout << "unordered_map 遍历结果:" << endl;
for (auto& kv : um)
{
// kv是pair类型,first是key,second是value
cout << kv.first << " -> " << kv.second << endl;
}
// 3. 查找元素:通过key查找
auto it = um.find(3);
if (it != us.end())
{
cout << "找到key=3,对应value:" << it->second << endl;
}
// 4. 删除元素:通过key删除
um.erase(3);
cout << "删除key=3后:" << endl;
for (auto& kv : um)
{
cout << kv.first << " -> " << kv.second << endl;
}
}
int main()
{
TestUnorderedMap();
return 0;
}运行结果如下:
2.4 unordered_map 与 map 的核心对比
| 对比维度 | map | unordered_map |
| 底层结构 | 红黑树 | 哈希表(链地址法) |
| 存储特性 | 按键有序存储 | 无序存储 |
| Key 要求 | 支持 < 比较 | 支持哈希转换和 == 比较 |
| 迭代器类型 | 双向迭代器 | 前向迭代器 |
| 时间复杂度 | O(logN) | 平均 O (1) |
[] 运算符 |
支持,key 不存在时插入默认值 | 支持,key 不存在时插入默认值 |
|---|
三、重点展开:平均 O (1),最坏 O (N) 到底是什么意思?
3.1 平均 O (1):哈希表的正常工作状态
正常场景下:
- 哈希函数设计合理,元素均匀分布在各个桶中;
- 每个桶上挂的链表长度极短(几乎 0~1 个节点)
- 插入 / 查找 / 删除只需要:
- 算一次哈希 → 得到桶下标
- 直接访问桶
- 最多比较一两个节点
- 整个过程和数据规模 N 无关 → 时间复杂度 O(1)
这也是 unordered 系列在99% 的业务场景都飞快的原因
3.2 最坏 O (N):哈希冲突极端场景
极端坏情况:
- 哈希函数设计极差,所有元素全部哈希到同一个桶
- 整个哈希表退化成一条单链表
- 此时查找 / 插入需要从头到尾遍历整条链表
- 时间复杂度直接退化为 O(N)
什么场景会触发?
- 自定义类型没有提供合适的哈希函数;
- 故意构造恶意数据攻击哈希表;
- 哈希表长期不扩容,负载因子过高。
总结:
- 正常用:平均 O (1)
- 哈希雪崩:最坏 O (N)
- 红黑树(map/set)永远稳定 O (logN),不会剧烈波动
四、重点展开:为什么 unordered 迭代器只能 ++,不能 --?(前向迭代器)
4.1 底层结构决定了迭代器行为
unordered_map / unordered_set 底层是: 哈希桶数组 + 挂在桶上的多条链表
迭代器遍历逻辑:
- 先遍历完当前桶的链表
- 再跳到下一个非空桶
- 继续遍历链表
4.2 为什么不能 --?
-
链表是单向的 桶上的节点只有
next指针,没有 prev 指针,无法向前回退 -
桶之间没有双向连接 迭代器不知道上一个非空桶在哪里,只能向后找
-
遍历无序,没有 "前驱" 的概念 有序容器(map/set)是中序遍历,有严格前驱后继; 无序容器遍历顺序随机,不支持反向迭代
4.3 前向迭代器的限制
- 支持:
++it、*it、-> - 不支持 :
--it、reverse_iterator、it -= 1等反向操作
4.4 对比记忆
map/set:双向迭代器 → 可++可--unordered_map/unordered_set:前向迭代器 → 仅可++
五、unordered_multiset 与 unordered_multimap 简述
这两个容器是 unordered_set 和 unordered_map 的 "多值" 版本:
unordered_multiset:允许存储重复的元素unordered_multimap:允许存储重复的键
它们的底层结构、接口用法、时间复杂度与对应的非多值版本基本一致,唯一的区别是:
- 插入重复的
Key或元素时,不会被自动去重 - 查找时,会返回第一个匹配元素的迭代器,如需获取所有匹配项,需使用
equal_range
在实际开发中,它们的使用频率远低于 unordered_set 和 unordered_map
六、性能实测:set 与 unordered_set 对比
为了直观感受两种容器的性能差异,我们编写一个简单的测试程序,对比它们在海量数据下的插入、查找和删除耗时
6.1 测试代码
cpp
#include <iostream>
#include <unordered_set>
#include <set>
#include <vector>
#include <cstdlib>
#include <ctime>
using namespace std;
int main()
{
// 设定测试数据量:100万条
const size_t N = 1000000;
unordered_set<int> us;
set<int> s;
vector<int> v;
v.reserve(N);
// 设置随机数种子
srand(time(0));
// 生成测试数据
for (size_t i = 0; i < N; ++i)
{
v.push_back(rand() + i); // 降低数据重复率
}
// ---------------- 插入性能测试 ----------------
size_t begin1 = clock();
for (auto e : v) s.insert(e);
size_t end1 = clock();
cout << "set insert 耗时:" << end1 - begin1 << endl;
us.reserve(N); // 提前预留空间,避免多次rehash
size_t begin2 = clock();
for (auto e : v) us.insert(e);
size_t end2 = clock();
cout << "unordered_set insert 耗时:" << end2 - begin2 << endl << endl;
// ---------------- 查找性能测试 ----------------
int m1 = 0, m2 = 0;
size_t begin3 = clock();
for (auto e : v) if (s.find(e) != s.end()) m1++;
size_t end3 = clock();
cout << "set find 耗时:" << end3 - begin3 << " 命中数:" << m1 << endl;
size_t begin4 = clock();
for (auto e : v) if (us.find(e) != us.end()) m2++;
size_t end4 = clock();
cout << "unordered_set find 耗时:" << end4 - begin4 << " 命中数:" << m2 << endl << endl;
// ---------------- 删除性能测试 ----------------
size_t begin5 = clock();
for (auto e : v) s.erase(e);
size_t end5 = clock();
cout << "set erase 耗时:" << end5 - begin5 << endl;
size_t begin6 = clock();
for (auto e : v) us.erase(e);
size_t end6 = clock();
cout << "unordered_set erase 耗时:" << end6 - begin6 << endl;
return 0;
}debug情况运行结果如下:
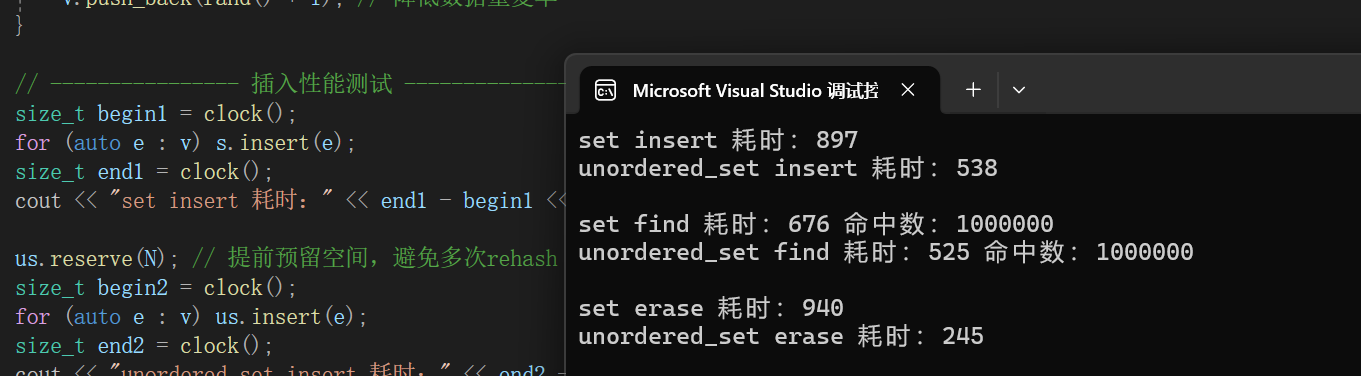
6.2 结果分析
运行上述代码,你会发现:
- 插入、查找、删除操作中,
unordered_set的耗时远低于set - 这印证了哈希表平均 O (1) 的时间复杂度优势,在数据量越大时,这种差距越明显
us.reserve(N)是unordered系列容器的一个重要优化,它可以提前为哈希表分配足够的桶空间,避免在插入过程中因负载因子过高而频繁 rehash(重新分配和映射所有元素),从而大幅提升性能
七.unordered_map /unordered_set 底层实现详细讲解
我们已经知道哈希表的原理,现在直接聚焦:STL 里的 unordered_map 和 unordered_set 到底是怎么封装出来的?底层长什么样?怎么跑起来的?
7.1 整体结论(先给结论,再讲细节)
- unordered_map /unordered_set 底层 = 开散列哈希表(链地址法)
- 它们不是自己实现数据结构,而是复用同一个哈希表底层,用适配器模式封装
- 底层结构 = 哈希桶数组 + 单向链表
- 核心流程:哈希映射 → 寻址桶 → 链表挂接 → 负载因子检查 → 扩容重哈希
- unordered_set 存 key,unordered_map 存 pair<key, value>,底层逻辑完全一样
7.2 底层实现
7.2.1 节点结构

7.2.2 哈希表整体结构

7.2.3插入流程(最核心)
步骤 1:计算哈希值,得到桶下标

通过哈希函数把 key 转成数组下标
步骤 2:遍历桶上链表,检查是否重复

步骤 3:链表头插新节点
头插效率高,不用找尾

步骤 4:检查负载因子,判断是否扩容

7.2.4 查找流程
- 计算哈希 → 找桶
- 在桶的链路上挨个比较 key
- 找到返回节点,找不到返回空

时间复杂度
- 平均:O (1) → 链表极短
- 最坏:O (N) → 所有数据挂在一个桶上,变成单链表
7.2.5 删除流程
- 找桶
- 找节点
- 单向链表删除(注意保存前驱)
- 不需要缩容

7.3 为什么要扩容?
桶太少、数据太多 → 链表变长 → 效率退化 → 必须扩容
7.3.1 扩容规则(STL 标准)
- 负载因子 load_factor = size / bucket_count
- 负载因子 超过 0.7 触发扩容
- 新桶大小 = 原大小 × 2(取质数)
7.3.2 扩容步骤
- 新建一个 2 倍大的桶数组
- 遍历旧表所有节点
- 重新计算哈希映射到新表
- 释放旧表,替换成新表
- 所有元素重新挂接 → 重哈希(Rehash)
7.3.3 扩容代码(STL 简化版)
我这个单独把扩容提取成了一个Expand()函数,当然可以直接实现到插入功能里,这里在哈希表章节讲过,但没有仔细提到,这里详细来解释一下
cpp
void Expand()
{
// 新桶数 = 旧桶数 × 2
size_t new_size = _table.size() * 2;
vector<Node*> new_table(new_size, nullptr);
// 遍历旧表所有桶
for (size_t i = 0; i < _table.size(); ++i)
{
Node* cur = _table[i];
// 把旧表节点 重新哈希映射到新表
while (cur != nullptr)
{
Node* next = cur->_next;
// 重新计算在新表中的位置
size_t new_index = cur->_data % new_size;
// 头插到新桶
cur->_next = new_table[new_index];
new_table[new_index] = cur;
cur = next;
}
_table[i] = nullptr;
}
// 交换新旧表
_table.swap(new_table);
}1. 新建一个更大的桶数组

- 旧桶太少了,放不下了
- 新建一个 2 倍大的空桶数组
- 现在:旧表小、新表大
2. 遍历旧表里的每一个桶

- 一个一个桶检查
cur指向当前桶的第一条链表
3. 遍历这个桶上的所有节点(一条链走到底)

- 旧桶挂了一条链表
- 要把链上每一个节点都搬到新家
4. 必须先保存下一个节点!非常关键

- 你马上要把 cur 搬走
- 搬走前必须记住下一个节点是谁
- 不然链就断了,找不到后面的节点
5. 给节点在新桶里重新算位置(重哈希)

- 新桶变大了
- 节点不能还待在原来的位置
- 必须重新取模 → 得到新下标
6. 把节点头插到新桶里

- 头插最快,不用找尾
- 直接把节点挂到新桶最前面
7. 继续处理旧链的下一个节点

- 回到第 3 步
- 搬下一个节点
8. 所有节点搬完了 → 新旧表交换

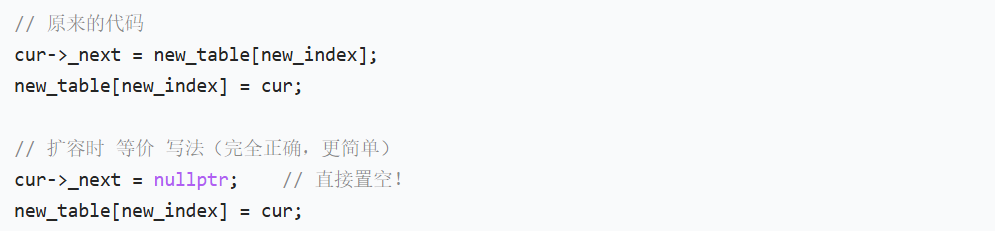
其实这两种写法等价,很多同学在刚开始学的时候可能会懵逼,为什么我要用cur->_next = new_tablenew_index,我们新创建的桶,它解引用后得到的节点都是nullptr,我们让cur->_next = new_tablenew_index,相当于cur->_next = nullptr,只是为了让我们刚拿下来的旧节点和之前旧桶的数据断开联系
这里要提醒一下扩容是哈希表最慢的操作 因为:
- 要遍历所有节点(N 个)
- 每个节点都要重新算哈希
- 每个节点都要重新插入新桶
- 整个过程是 O (N) 时间复杂度
以下的两个模拟实现都是在写出了哈希表的前提下,前面提到过哈希表这里就不在重新讲了
7.4封装 unordered_set
cpp
template<class K>
class unordered_set
{
struct KeyOfT
{
const K& operator()(const K& key)
{
return key;
}
};
private:
HashTable<K, K, KeyOfT> _ht;
public:
typedef typename HashTable<K, K, KeyOfT>::iterator iterator;
pair<iterator, bool> insert(const K& key)
{
return _ht.Insert(key);
}
iterator find(const K& key)
{
return _ht.Find(key);
}
iterator begin()
{
return _ht.begin();
}
iterator end()
{
return _ht.end();
}
size_t size()
{
return _ht.Size();
}
};7.5 封装 unordered_map
cpp
template<class K, class V>
class unordered_map
{
struct KeyOfT
{
const K& operator()(const pair<K, V>& kv)
{
return kv.first;
}
};
private:
HashTable<K, pair<K, V>, KeyOfT> _ht;
public:
typedef typename HashTable<K, pair<K, V>, KeyOfT>::iterator iterator;
pair<iterator, bool> insert(const pair<K, V>& kv)
{
return _ht.Insert(kv);
}
iterator find(const K& key)
{
return _ht.Find(key);
}
// [] 重载
V& operator[](const K& key)
{
auto ret = insert({ key, V() });
return ret.first->second;
}
iterator begin()
{
return _ht.begin();
}
iterator end()
{
return _ht.end();
}
size_t size()
{
return _ht.Size();
}
};