1. 链表
一、链表的核心概念
1. 顺序表 vs 链表(类似火车车厢连接起来)
| 特性 | 顺序表(数组) | 链表 |
|---|---|---|
| 物理存储 | 连续内存 | 离散内存,用指针连接 |
| 随机访问 | O (1) 直接下标访问 | O (n) 只能遍历 |
| 插入 / 删除 | 平均 O (n),需搬移元素 | O (1)(已知结点位置时) |
| 扩容 | 固定大小,需手动扩容 | 按需申请结点,无需扩容 |
2. 链表的本质
- 结点 :每个结点 包含「数据域 + 指针域 」,单链表中**
next指针指向后继结点**。 - 头结点 / 哨兵位:额外的不存数据的结点,用来简化空表、首结点操作。
二、单链表的基础定义
1. 结点结构体定义(不能用匿名结构体)
typedef int LDataType;
typedef struct ListNode {
LDataType data; // 存储数据
struct ListNode* next; // 指向后继结点
} LNode, *LinkList;LNode:结点类型LinkList:结点指针类型 ,等价于**LNode***
2. 不带头结点(没有 "引导员")
- 结构 :头指针
L直接指向第一个有效结点(就是存数据的第一个结点)。 - 空表状态 :链表为空时,
L = NULL(头指针啥也不指)。 - 举个例子 :链表
10 -> 20 -> 30,头指针L直接指向10。空表时,L就是NULL,连个占位的都没有。 - 问题:插入 / 删除第一个结点时,要单独处理空表和首结点的情况,代码容易写错。
3. 带头结点(有 "引导员")
- 结构 :头指针
L指向哨兵结点 ,哨兵结点的**next才指向第一个有效结点**。 - 空表状态 :链表为空时,哨兵结点永远存在 ,
L->next = NULL(哨兵后面啥也不指)。 - 举个例子 :链表
10 -> 20 -> 30,结构是哨兵 -> 10 -> 20 -> 30,头指针**L指向哨兵** 。空表时,L一直指向哨兵 ,只是哨兵的next是NULL。 - 好处:不管链表空不空,插入 / 删除操作的代码逻辑都完全一样,不用单独处理首结点,不容易出错。
三、核心接口实现(带头结点)
1. 创建新结点
LNode* BuyListNode(int data) {
LNode* newNode = (LNode*)malloc(sizeof(LNode));
if (newNode == NULL) {
printf("BuyListNode失败!\n");
exit(-1);
}
newNode->data = data;
newNode->next = NULL;
return newNode;
}2. 初始化链表(创建哨兵头结点)
LNode* ListInit() {
LNode* head = BuyListNode(-1); // 哨兵结点,数据无意义
return head;
}3. 尾插法(在链表末尾插入)
void ListPushBack(LNode* L, LDataType x) {
assert(L != NULL);
LNode* cur = L;
// 找到尾结点
while (cur->next != NULL) {
cur = cur->next;
}
LNode* newNode = BuyListNode(x);
cur->next = newNode;
}4. 头插法(在哨兵结点后插入)
void ListPushFront(LNode* L, LDataType x) {
assert(L != NULL);
LNode* newNode = BuyListNode(x);
newNode->next = L->next;
L->next = newNode;
}5. 遍历打印链表
void ListPrint(LNode* L) {
assert(L != NULL);
LNode* cur = L->next; // 从第一个有效结点开始遍历
while (cur != NULL) {
printf("%d -> ", cur->data);
cur = cur->next;
}
printf("NULL\n");
}6. 求链表长度
int ListSize(LNode* L) {
assert(L != NULL);
int size = 0;
LNode* cur = L->next;
while (cur != NULL) {
size++;
cur = cur->next;
}
return size;
}7. 查找指定元素
LNode* ListLocateElem(LNode* L, LDataType x) {
assert(L != NULL);
LNode* cur = L->next;
while (cur != NULL) {
if (cur->data == x) {
return cur; // 找到结点,返回指针
}
cur = cur->next;
}
return NULL; // 未找到
}8. 销毁链表(释放所有结点)
void ListDestroy(LNode* L) {
assert(L != NULL);
LNode* cur = L;
while (cur != NULL) {
LNode* next = cur->next;
free(cur);
cur = next;
}
}四、遍历打印和求长度(带头结点)
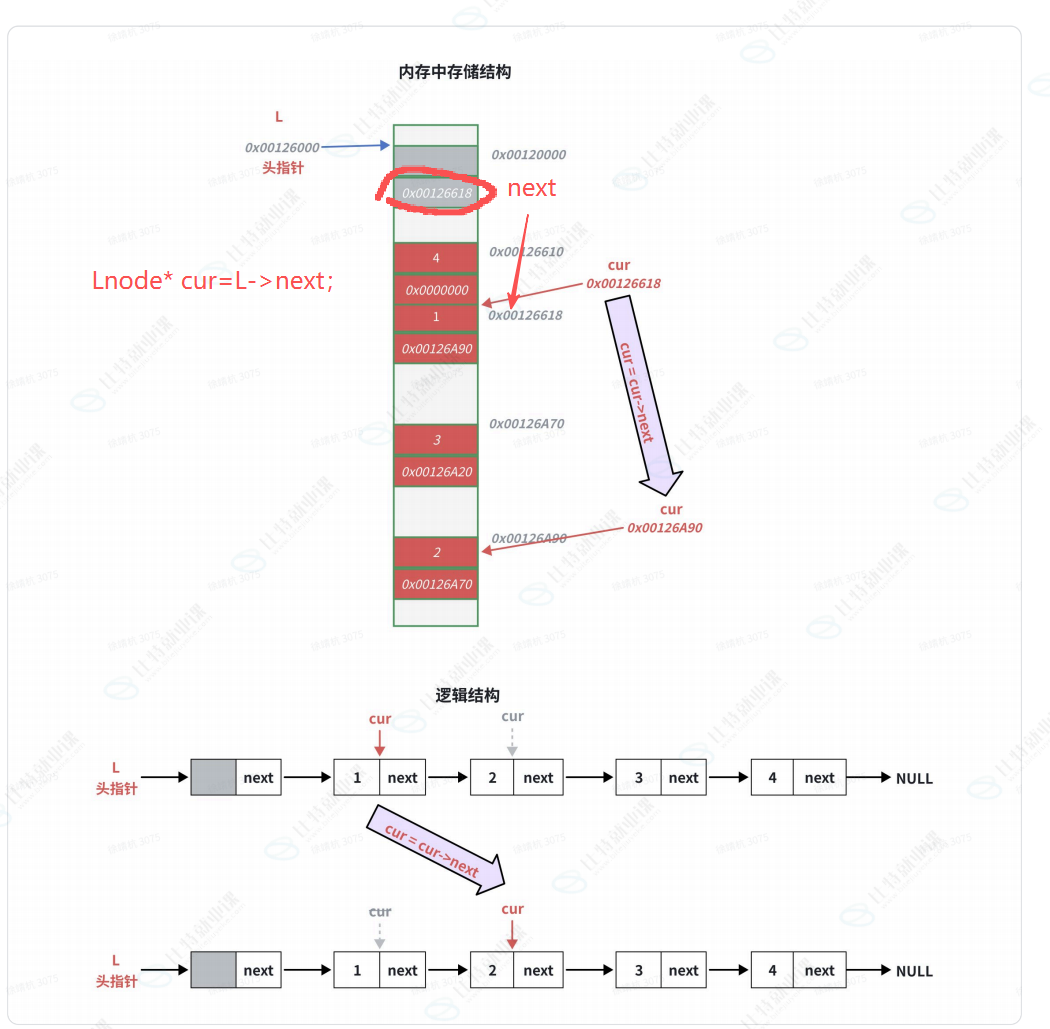
核心逻辑
- 遍历本质:通过当前节点的
next成员 ,迭代获取下一个节点地址,直到NULL结束。 - 注意:哨兵位头结点不存储有效数据 ,遍历需从
L->next开始。
代码实现
-
ListPrint:遍历并打印链表void ListPrint(LNode* L) { // 校验哨兵位头指针不为空 assert(L); printf("头结点->"); // cur指向第一个有效节点 LNode* cur = L->next; // 循环遍历,cur为空则结束 while (cur) { printf("%d->", cur->data); // 移动到下一个节点 cur = cur->next; } printf("NULL\n"); } -
ListSize:计算链表有效节点数int ListSize(LNode* L) { assert(L); int size = 0; LNode* cur = L->next; while (cur) { size++; cur = cur->next; } return size; }
关键疑问解答
- 为什么不能用**
++cur** 代替**cur = cur->next** ?链表节点在内存中不连续 ,++cur只会移动到当前节点的下一块内存地址 ,而非下一个节点的地址,只有**cur->next**存储了下一个节点的真实地址。
五、查找
1. 按值查找:ListLocateElem
核心逻辑
遍历链表,找到第一个数据等于目标值 x 的结点并返回其地址 ;遍历完都没找到则返回 NULL。
代码解析
LNode* ListLocateElem(LNode* L, LDataType x) {
assert(L); // 断言:头指针不为空,避免非法访问
LNode* cur = L->next; // 从第一个数据结点开始遍历
while (cur) { // cur不为空就继续循环
if (cur->data == x)
return cur; // 找到目标值,直接返回当前结点地址
cur = cur->next; // 没找到,指针后移
}
return NULL; // 遍历结束仍未找到,返回空指针
}- 时间复杂度:
O(N),最坏情况要遍历整个链表 - 特点:只能找到第一个匹配的结点,适合快速定位已知值的场景
2. 按下标查找:ListGetElem
核心逻辑
从第一个数据结点开始,向后移动 i 次 ,找到第 i 个结点 (注意:这里下标从 0 开始 ,L->next 是第 0 个结点)。循环条件**iNode != NULL && j < i** 是关键:既要保证还没到目标下标 ,也要保证当前结点不为空,防止访问越界。
代码解析
LNode* ListGetElem(LNode* L, int i) {
assert(L); // 头指针非空
assert(i >= 0); // 下标不能为负数
int j = 0; // 计数器,记录当前是第几个结点
LNode* iNode = L->next; // 从第0个结点开始
while (iNode != NULL && j < i) {
++j;
iNode = iNode->next; // 指针后移,计数器+1
}
return iNode; // 找到则返回结点地址,没找到(下标越界)则返回NULL
}- 时间复杂度:
O(N),链表不支持随机访问,只能顺序遍历 - 注意:返回
NULL有两种情况:要么下标越界 (链表长度不足),要么链表为空
3. 两种查找的对比
| 操作类型 | 核心目标 | 关键逻辑 | 时间复杂度 | 适用场景 |
|---|---|---|---|---|
| 按值查找 | 找 "值等于 x" 的结点 | 遍历 + 值比较 | O(n) | 已知结点数据,需定位其位置 |
| 按下标查找 | 找 "第 i 个位置" 的结点 | 遍历 + 计数器 | O(n) | 已知结点位置,需访问其数据 |
💡 补充说明
- 哨兵位头结点的存在 ,让两种查找都能直接从
L->next开始遍历 ,不用单独处理空链表的特殊情况(除了assert(L)断言)。 - 按下标查找的循环条件
iNode != NULL && j < i缺一不可:如果只写j < i,当下标超过链表长度时,iNode会变成NULL,再执行iNode->next会导致程序崩溃。
六、插入
1. 链表插入的核心特点
和顺序表不同,链表插入不需要挪动数据 ,只需要修改结点间的链接关系 ,但关键前提是:✅ 要在第 i 个结点之前插入,必须先找到第 i-1 个结点(前驱结点),否则无法完成链接修改。
2. 插入的关键顺序(绝对不能搞反!)
这是链表插入最容易踩坑的地方!,两步操作顺序必须固定:
// 1. 先让新结点的next指向原来的第i个结点
newNode->next = i_1Node->next;
// 2. 再让前驱结点的next指向新结点
i_1Node->next = newNode;- 如果先执行第 2 步,
i_1Node->next会被直接改成newNode,原来的第i个结点 就找不到了,会直接导致链表断裂。 - 带头结点的写法可以统一处理头插 (
i=0)和中间 / 尾插,不需要单独写分支,代码更简洁。
3. 完整代码解析
// 在链表的第i个下标位置插入元素x
void ListInsert(LNode* L, int i, LDataType x) {
// 哨兵位头指针不为空
assert(L);
assert(i >= 0);
// 找到下标为i-1的结点(前驱结点)
int j = -1;
LNode* i_1Node = L;
while (i_1Node != NULL && j < i-1) {
++j;
i_1Node = i_1Node->next;
}
// 没有第i-1个结点,说明i非法(比如链表长度不足)
assert(i_1Node != NULL);
// 3. 插入新结点
LNode* newNode = BuyListNode(x);
// 关键两步,顺序不能交换!
newNode->next = i_1Node->next;
i_1Node->next = newNode;
}代码细节拆解
-
前驱结点查找
- 计数器
j初始为-1,从哨兵位头结点L开始遍历 ,直到j == i-1,此时**i_1Node就是第i-1个结点。** - 循环条件
i_1Node != NULL && j < i-1,防止下标越界访问空指针。
- 计数器
-
边界情况处理
- 头插(i=0) :此时**
i-1 = -1** ,循环不执行,i_1Node直接指向哨兵位头结点L,后续的两步插入操作自然完成头插,无需单独分支。 - 尾插(i 等于链表长度) :此时
i_1Node会走到最后一个结点,插入后newNode->next为NULL,符合尾结点的定义。
- 头插(i=0) :此时**
4. 带头结点 vs 不带头结点插入对比
| 场景 | 带头结点链表 | 不带头结点链表 |
|---|---|---|
| 头插(i=0) | 统一处理,无需单独分支 | 必须单独处理,需要用二级指针修改头指针 |
| 中间 / 尾插 | 直接找前驱结点即可 | 和带头结点逻辑一致 |
| 代码复杂度 | 低,逻辑统一 | 高,头插需要特殊判断 |
7. 删除
一、链表删除的核心特点
和插入类似,链表删除不需要像顺序表那样挪动数据 ,仅需修改结点间的链接关系,但必须先找到第 i-1 个结点(前驱结点) ,才能完成对第 i 个结点的删除。
二、删除的关键步骤(顺序绝对不能搞反!)
这是链表删除最容易踩坑的地方!,三步操作的顺序必须固定:
// 1. 先保存要删除的第i个结点的地址(关键!否则会丢失结点)
LNode* iNode = i_1Node->next;
// 2. 让前驱结点的next指向第i+1个结点,跳过被删除结点
i_1Node->next = iNode->next;
// 3. 释放被删除结点的内存,防止内存泄漏
free(iNode);- 如果跳过第 1 步直接执行第 2 步,被删除结点的地址会丢失 ,后续无法
free,造成内存泄漏; - 带头结点的写法可以统一处理头删(
i=0)和中间 / 尾删,不需要单独写分支,代码逻辑更简洁。
三、完整代码解析
// 删除链表中下标为i的结点,并返回被删除结点的值
LDataType ListDelete(LNode* L, int i) {
// 1. 参数合法性校验
assert(L);
assert(i >= 0);
// 2. 找到第i-1个结点(前驱结点)
int j = -1;
LNode* i_1Node = L;
while (i_1Node != NULL && j < i-1) {
++j;
i_1Node = i_1Node->next;
}
// 校验:前驱结点和要删除的结点都必须存在
assert(i_1Node != NULL && i_1Node->next != NULL);
// 3. 执行删除操作(顺序不能乱)
LNode* iNode = i_1Node->next; // 保存要删除的结点地址
i_1Node->next = iNode->next; // 前驱结点直接指向后继结点,跳过被删结点
LDataType val = iNode->data; // 保存被删除结点的值(可选)
free(iNode); // 释放内存
return val; // 返回被删除结点的值
}代码细节拆解
-
前驱结点查找
- 计数器
j初始为-1,从哨兵位头结点L开始遍历,直到j == i-1,此时i_1Node就是第i-1个结点。 - 循环条件
i_1Node != NULL && j < i-1,防止下标越界访问空指针。
- 计数器
-
边界情况处理
- 头删(i=0) :此时
i-1 = -1,循环不执行,i_1Node直接指向哨兵位头结点L,后续的删除操作自然完成头删,无需单独分支。 - 尾删(i 为链表最后一个结点下标) :此时
i_1Node会指向倒数第二个结点,iNode->next为NULL,i_1Node->next = NULL后,尾结点被成功删除。
- 头删(i=0) :此时
四、带头结点 vs 不带头结点删除对比
| 场景 | 带头结点链表 | 不带头结点链表 |
|---|---|---|
| 头删(i=0) | 统一处理,无需单独分支 | 必须单独处理,需要用二级指针修改头指针 |
| 中间 / 尾删 | 直接找前驱结点即可 | 和带头结点逻辑一致 |
| 代码复杂度 | 低,逻辑统一 | 高,头删需要特殊判断 |
2. 一些面试题及其详解
一、链表的中间结点
题目回顾
给定一个单链表,返回它的中间结点。如果有两个中间结点,返回第二个中间结点。
- 示例 1:
1→2→3→4→5,中间结点是3 - 示例 2:
1→2→3→4→5→6,中间结点是4
两种实现思路对比
| 思路 | 核心逻辑 | 时间复杂度 | 空间复杂度 | 优缺点 |
|---|---|---|---|---|
| 两次遍历法 | 第一次遍历求链表长度,第二次走到n/2位置 |
O(N) | O(1) | 实现简单,但需要两次遍历 |
| 快慢指针法 | slow每次走 1 步 ,fast每次走 2 步 ,fast到尾时slow就在中间 |
O(N) | O(1) | 一次遍历完成,效率更高 |
快慢指针法完整代码
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
struct ListNode* middleNode(struct ListNode* head) {
struct ListNode *slow = head, *fast = head;
// 循环条件:fast和fast->next都不为空时继续移动
while (fast != NULL && fast->next != NULL) {
slow = slow->next;
fast = fast->next->next;
}
return slow;
}关键细节说明
- 循环条件 :
fast != NULL && fast->next != NULL- 奇数 长度链表:
fast最终指向尾结点 ,退出循环,slow指向正中间 - 偶数 长度链表:
fast最终指向 NULL,退出循环,slow指向第二个中间结点
- 奇数 长度链表:
- 无头结点处理 :题目给的链表不带哨兵位头结点,直接用
head作为起始结点即可。如果是带哨兵位的链表,需要让slow和fast从head->next开始移动。 - 为什么这个逻辑有效? 当
fast走的速度是slow的 2 倍时,fast到达终点时,slow刚好走了一半的路程,正好停在中间位置。
两次遍历法代码
struct ListNode* middleNode(struct ListNode* head) {
struct ListNode* cur = head;
int len = 0;
// 第一次遍历求长度
while (cur != NULL) {
len++;
cur = cur->next;
}
cur = head;
// 第二次遍历走到中间位置
for (int i = 0; i < len / 2; i++) {
cur = cur->next;
}
return cur;
}扩展:带哨兵位头结点的写法(学校考试 / 408 风格)
如果题目明确说明链表带头结点,代码需要调整起始位置:
// 假设链表定义为:带头结点head,有效结点从head->next开始
struct ListNode* middleNodeWithDummy(struct ListNode* head) {
struct ListNode *slow = head->next, *fast = head->next;
while (fast != NULL && fast->next != NULL) {
slow = slow->next;
fast = fast->next->next;
}
return slow;
}二、返回倒数第K个结点
题目回顾
给定一个单链表,返回倒数第 k 个结点的值(题目保证 k 有效,无需额外校验)。示例:1→2→3→4→5,k=2,返回 4。
两种思路对比
| 思路 | 核心逻辑 | 时间复杂度 | 空间复杂度 | 优缺点 |
|---|---|---|---|---|
| 两次遍历法 | 第一次遍历求链表长度n,第二次走到第n-k个结点 |
O(N) | O(1) | 实现简单,但需要两次遍历 |
| 快慢指针法 | fast先走k步,再和slow同步走,fast到尾时slow就是目标结点 |
O(N) | O(1) | 一次遍历完成,效率更高 |
解法 1:两次遍历法
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
int kthToLast(struct ListNode* head, int k) {
struct ListNode* cur = head;
int len = 0;
// 第一次遍历:计算链表长度
while (cur != NULL) {
len++;
cur = cur->next;
}
// 第二次遍历:走到第 len - k 个结点
cur = head;
for (int i = 0; i < len - k; i++) {
cur = cur->next;
}
return cur->val;
}解法 2:快慢指针法(推荐,一次遍历)
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
int kthToLast(struct ListNode* head, int k) {
struct ListNode *slow = head, *fast = head;
// 1. fast 先走 k 步
for (int i = 0; i < k; i++) {
fast = fast->next;
}
// 2. fast 和 slow 同步走,直到 fast 走到 NULL
while (fast != NULL) {
slow = slow->next;
fast = fast->next;
}
// 此时 slow 指向倒数第 k 个结点
return slow->val;
}关键细节说明
-
快慢指针的原理 让
fast和slow之间保持**k个结点的距离** 。当fast走到链表末尾(NULL)时,slow距离末尾正好是k步 ,也就是倒数第k个结点。 -
为什么题目说 k 是有效的? 这意味着你不需要处理
k > 链表长度、k ≤ 0这类边界情况,代码可以更简洁。 -
和带哨兵位链表的区别 题目给的链表是无头结点 的,所以直接用
head作为起始结点即可 。如果是带哨兵位的链表,需要让slow和fast从head->next开始移动 ,同时调整fast先走的步数。
扩展:带哨兵位头结点的写法(学校考试 / 408 风格)
// 假设链表带头结点,有效结点从 head->next 开始
int kthToLastWithDummy(struct ListNode* head, int k) {
struct ListNode *slow = head->next, *fast = head->next;
// fast 先走 k 步
for (int i = 0; i < k; i++) {
fast = fast->next;
}
while (fast != NULL) {
slow = slow->next;
fast = fast->next;
}
return slow->val;
}三、 移除链表的元素
题目回顾
删除 链表中所有满足 Node.val == val 的结点,并返回新的头结点。
- 示例 1:
[1,2,6,3,4,5,6],val=6→ 输出[1,2,3,4,5] - 示例 3:
[7,7,7,7],val=7→ 输出空链表
核心思路:哨兵位头结点
这道题的关键难点是头结点本身就是要删除的结点 ,如果不用哨兵位,需要单独处理头结点的删除逻辑 ,代码会更复杂。哨兵位头结点的优势:
- 让所有结点的删除逻辑统一,不用单独处理头结点
- 保证
prev指针永远不为空,避免空指针报错
完整可运行代码
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
struct ListNode* removeElements(struct ListNode* head, int val) {
// 1. 创建哨兵位头结点
struct ListNode* newhead = (struct ListNode*)malloc(sizeof(struct ListNode));
newhead->next = head;
struct ListNode* prev = newhead;
struct ListNode* cur = head;
// 2. 遍历链表删除结点
while (cur != NULL) {
if (cur->val == val) {
// 找到要删除的结点:prev直接跳过cur,指向cur的下一个结点
prev->next = cur->next;
free(cur); // 释放被删除结点的内存,避免内存泄漏
cur = prev->next; // cur移动到下一个结点,继续判断
} else {
// 不删除的情况:两个指针一起往后走
prev = cur;
cur = cur->next;
}
}
// 3. 保存新的头结点,释放哨兵位,避免内存泄漏
struct ListNode* ret = newhead->next;
free(newhead);
return ret;
}关键细节拆解
-
为什么要释放哨兵位
newhead?newhead是我们手动malloc出来的 ,它不是链表的一部分,函数结束前必须free,否则会造成内存泄漏。 -
删除结点时
cur的更新逻辑 当删除cur结点后,cur不能直接cur = cur->next,因为cur已经被free了,访问它的成员会导致野指针报错。正确做法是cur = prev->next,直接拿到新的下一个结点。 -
边界情况处理
- 空链表(
head == NULL):代码依然能正常运行 ,newhead->next为NULL,直接返回空 - 所有结点都要删除(比如示例 3):
cur会逐个被删除,最后newhead->next为NULL,返回空链表
- 空链表(
易错点提醒
- 忘记释放被删除的结点和哨兵位,导致内存泄漏
- 删除结点后,错误地
cur = cur->next,访问了已经被释放的内存 - 不使用哨兵位,单独处理头结点时逻辑混乱,漏删或多删结点
拓展:不使用哨兵位的写法(对比参考)
struct ListNode* removeElements(struct ListNode* head, int val) {
// 先处理头结点本身就是val的情况
while (head != NULL && head->val == val) {
struct ListNode* temp = head;
head = head->next;
free(temp);
}
struct ListNode* cur = head;
while (cur != NULL && cur->next != NULL) {
if (cur->next->val == val) {
struct ListNode* temp = cur->next;
cur->next = temp->next;
free(temp);
} else {
cur = cur->next;
}
}
return head;
}这种写法需要先循环处理头结点 ,再处理中间结点 ,逻辑不如哨兵位统一,也更容易出错
四、反转链表
迭代法完整代码(C 语言 反转单链表)(头插法)
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
struct ListNode* reverseList(struct ListNode* head) {
struct ListNode* prev = NULL; // 前驱节点
struct ListNode* curr = head; // 当前遍历节点
struct ListNode* next = NULL; // 临时保存后继节点
while (curr != NULL) {
next = curr->next; // 先存下一个节点,防止断链
curr->next = prev; // 当前节点反向指向前驱
prev = curr; // 前驱后移
curr = next; // 当前节点后移
}
return prev; // 循环结束prev是新头结点
}思路解析(迭代法)
- 三指针定义 :
prev存前一个节点(初始空)、curr遍历链表(从 head 开始)、next临时保存原后继。 - 循环逻辑 :
- 先用
next保存curr->next,防止修改指针后丢失后续链表 curr->next = prev完成节点反向prev和curr同步向后挪动,重复操作
- 先用
- 返回结果 :遍历结束时
curr==NULL,prev指向原链表最后一个节点,即反转后的头节点。
补充:递归写法(备选方案)
struct ListNode* reverseList(struct ListNode* head) {
if(head == NULL || head->next == NULL) return head;
struct ListNode* newHead = reverseList(head->next);
head->next->next = head;
head->next = NULL;
return newHead;
}递归思路:递归到链表尾作为新表头,回溯时让后一个节点指向自己,逐个反向。
💡 示例验证 :1→2→3→4→5迭代依次:NULL←1 → NULL←1←2 → ... → NULL←1←2←3←4←5,最终prev=5作为新表头返回。
五、合并两个有序链表
写法 1:哨兵虚拟头节点迭代(处理空链表不用特判)
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
struct ListNode* mergeTwoLists(struct ListNode* list1, struct ListNode* list2) {
// 虚拟哨兵头,不存数值,统一链表头部逻辑
struct ListNode dummy;
dummy.next = NULL;
struct ListNode* tail = &dummy;
// 两个链表都有剩余节点
while(list1 != NULL && list2 != NULL)
{
if(list1->val < list2->val)
{
tail->next = list1;
list1 = list1->next;
}
else
{
tail->next = list2;
list2 = list2->next;
}
tail = tail->next;
}
// 剩余链表直接拼在尾部
tail->next = list1 ? list1 : list2;
return dummy.next;
}思路说明💡
dummy哨兵规避list1/list2其中一个为空的边界判断;tail永远指向新链表末尾 ,用来拼接节点。- 循环每次选取更小值的节点接到
tail后面 ,对应样例[1,2,4]、[1,3,4]逐步拼接:1→1→2→3→4→4。 - 任一链表遍历完毕,剩下整条链表直接挂载尾部。
写法 2:无哨兵版合并有序链表(手动处理首节点)
struct ListNode* mergeTwoLists(struct ListNode* list1, struct ListNode* list2) {
// 边界:某一条链表为空直接返回另一条
if(list1 == NULL) return list2;
if(list2 == NULL) return list1;
struct ListNode* head = NULL; // 最终新链表头
struct ListNode* tail = NULL; // 新链表尾指针
// 第一步:先选出整体最小节点作为新链表首元素(代替哨兵作用)
if(list1->val < list2->val){
head = tail = list1;
list1 = list1->next;
}else{
head = tail = list2;
list2 = list2->next;
}
// 正常尾插剩余节点
while(list1 && list2){
if(list1->val < list2->val){
tail->next = list1;
list1 = list1->next;
}else{
tail->next = list2;
list2 = list2->next;
}
tail = tail->next; // 尾巴后移
}
// 剩余链表直接拼接
tail->next = list1 ? list1 : list2;
return head;
}核心逻辑拆解💡
- 无哨兵的痛点:必须单独选第一个节点 哨兵
dummy可以天然充当初始tail;去掉哨兵后,要手动挑最小节点作为head和初始tail,确定链表开头。
示例
l1[1,2,4],l2[1,3,4]:首次两节点都是 1,任选一个做 head=1,tail=1。
-
后续逻辑和哨兵版完全一致:尾插
tail->next = 更小节点→tail = tail->next,持续在末尾追加。 -
边界处理必须前置 如果
list1/l2有一个是空,直接返回另一个,否则取->val会空指针报错。