目录
[2.1 vector本质上是"可变长数组"](#2.1 vector本质上是“可变长数组”)
[2.2 vector和普通数组的区别](#2.2 vector和普通数组的区别)
[(2)vector 的特点:](#(2)vector 的特点:)
[2.3 vector为什么适合工程开发](#2.3 vector为什么适合工程开发)
[2.4 vector内部空间默认是什么状态](#2.4 vector内部空间默认是什么状态)
[3.1 vector使用的是模板类型](#3.1 vector使用的是模板类型)
[3.2 vector的几种初始化方式](#3.2 vector的几种初始化方式)
[4.1 push_back:在尾部追加元素](#4.1 push_back:在尾部追加元素)
[4.2 size:获取当前元素个数](#4.2 size:获取当前元素个数)
[4.3 下标访问和修改元素](#4.3 下标访问和修改元素)
[4.4 使用下标访问时要注意什么](#4.4 使用下标访问时要注意什么)
[5.1 下标遍历](#5.1 下标遍历)
[5.2 迭代器遍历](#5.2 迭代器遍历)
[1)std::vector ::iterator](#1)std::vector ::iterator)
[(3)begin 和 end 分别是什么](#(3)begin 和 end 分别是什么)
[(4)为什么要写 *itr](#(4)为什么要写 *itr)
[5.3 C++11范围for遍历](#5.3 C++11范围for遍历)
[(4)auto& d为什么常用](#(4)auto& d为什么常用)
[7.1 vector的核心特点](#7.1 vector的核心特点)
[7.2 本节必须掌握的几个操作](#7.2 本节必须掌握的几个操作)
[7.3 初学者最容易犯错的地方](#7.3 初学者最容易犯错的地方)
[(1)空 vector 直接用下标赋值](#(1)空 vector 直接用下标赋值)
[(2)把 end() 理解成最后一个元素](#(2)把 end() 理解成最后一个元素)
[(4)不理解 auto& d 中的 &](#(4)不理解 auto& d 中的 &)
一、前言
在前面的内容中,我们已经学习了普通数组,知道数组本质上是一块连续的内存空间,可以通过下标快速访问元素。
但是普通数组有一个明显特点:
长度一旦确定,后续就很难灵活改变。
比如:
cpp
int arr[5];这里数组大小就是 5,后面不能自动变成 10、20 或更多。
而在实际开发中,我们经常会遇到一种场景:
一开始并不知道到底要存多少个数据,只有在程序运行过程中,数据才会不断加入。
这时候,普通数组就不够方便了,于是 C++ 标准库给我们提供了一个非常常用的容器:
vector
vector 可以理解为:
一个长度可以动态变化的数组容器。
它既保留了数组"连续空间、访问速度快"的特点,又提供了更灵活的操作方式。因此,在工程开发中,vector 的使用频率非常高。
本节我们先不去讲查找、删除、插入和排序,而是专门把最基础也是最重要的内容讲清楚:
vector是什么vector如何定义和初始化vector如何访问和修改元素vector如何遍历- 什么是迭代器
begin()和end()是什么意思for (auto& d : datas)里的d和&到底是什么
二、vector是什么
2.1 vector本质上是"可变长数组"
vector 是 C++ 标准库中的一个 STL 容器,头文件是:
cpp
#include <vector>它本质上可以看成一个 动态数组。
普通数组例如:
cpp
int arr[5];长度在定义时就固定了,后面不能自动变大。
而 vector 不一样,例如:
cpp
vector<int> datas;这里虽然现在没有元素,但后面可以不断:
cpp
datas.push_back(10);
datas.push_back(20);
datas.push_back(30);这样数组大小就会自动增长。
它最核心的特点就是:
大小可以动态变化。
2.2 vector和普通数组的区别
(1)普通数组的特点:
(1)大小固定
(2)定义后长度通常不能改变
(3)访问速度快
(4)语法简单
(2)vector 的特点:
(1)大小可变
(2)可以动态增加元素
(3)同样支持下标访问
(4)内部仍然是连续空间,访问效率高
(5)更适合工程开发
所以你可以把 vector 理解为:
"比普通数组更灵活的升级版数组"。
2.3 vector为什么适合工程开发
因为 vector 解决了普通数组的几个痛点:
(1)长度可以动态变化
(2)自动管理内部内存
(3)支持很多现成操作
(4)和算法库配合方便,例如 find、sort
所以在工程里,如果你只是需要一个"能放很多同类型数据的线性表",通常优先考虑 vector。
2.4 vector内部空间默认是什么状态
例如:
cpp
vector<int> datas;这时候只是创建了一个 vector 对象,但它里面还没有元素。
也就是说:
datas.size()为 0- 当前没有实际存储任何
int元素
可以把它理解成:
先把"容器对象"建好了,但里面还没装数据。
当你第一次
push_back()时,它才会根据需要去申请内部存储空间。这个空间通常是分配在 堆区 的。
这里要注意一个表述:
并不是说"完全没有任何开销",而是说:
不会一开始就按很大数组去申请空间,而是随着使用逐步申请。
这也是 vector 灵活的重要原因。
三、vector的定义与初始化
3.1 vector使用的是模板类型
vector 的写法是:
cpp
vector<类型> 容器名;这里的 <类型> 表示这个 vector 里要存什么类型的数据。
例如:
cpp
vector<int> vi;
vector<string> vs;
vector<float> vf;分别表示:
vi:存整数vs:存字符串vf:存浮点数
这就是模板的意义:
同样一个 vector 容器,可以通过不同类型参数,存不同类型的数据。
3.2 vector的几种初始化方式
代码如下:
cpp
std::vector<int> vi;
vector<string> vs;
vector<float> vf;
vector<int> vd1(10); //设置数组大小
vector<int> vd2{ 1,2,3,4,6 };
vector<string> vs1{ "ss1","ss2","ss3" };下面分别解释。
(1)空vector
cpp
vector<int> vi;表示定义一个空的 int 类型动态数组。
此时:
cpp
vi.size()结果为 0。
(2)指定初始大小
cpp
vector<int> vd1(10);表示创建一个大小为 10 的 vector<int>。
注意:
这里不是"容量是10但没有元素",而是 已经有 10 个元素了,只是这些元素会被默认初始化。
对于 int 来说,通常默认值为 0。
也就是说,这个 vector 逻辑上已经有 10 个位置可以通过下标访问:
cpp
vd1[0] ~ vd1[9](3)列表初始化
cpp
vector<int> vd2{ 1,2,3,4,6 };
vector<string> vs1{ "ss1","ss2","ss3" };这表示在定义时直接给初始内容。
例如:
cpp
vector<int> vd2{ 1,2,3,4,6 };里面一开始就有 5 个元素。
四、vector增加、修改与大小获取
4.1 push_back:在尾部追加元素
代码:
cpp
std::vector<int> datas;
datas.push_back(10);
datas.push_back(11);
datas.push_back(12);push_back() 的作用是:
把元素追加到 vector 的最后面。
执行完后,datas 的内容就是:
cpp
10 11 12此时:
cpp
datas.size()结果为 3。
所以 push_back 可以理解为:
尾插法、尾部追加元素。
这是 vector 最常用的增加元素方式之一。
4.2 size:获取当前元素个数
代码:
cpp
datas.size()表示当前 vector 中有多少个元素。
要注意,size() 反映的是 当前实际元素个数,不是普通数组那种写死的长度概念。
4.3 下标访问和修改元素
代码:
cpp
datas[0] = 99;表示把第 0 个元素改为 99。
原本:
bash
10 11 12修改后变成:
bash
99 11 12这说明 vector 和普通数组一样,也支持:
容器名下标
进行访问。
4.4 使用下标访问时要注意什么
例如:
cpp
datas[0]前提是 datas 里真的有第 0 个元素。
也就是说,下面这种写法是危险的:
cpp
vector<int> datas;
datas[0] = 99; // 错误,越界因为此时 datas.size() == 0,根本没有元素 0。
所以要记住:
vector 的下标访问,只能访问已经存在的元素。
如果你只是空定义了一个 vector,一定要先 push_back,或者先指定大小,再通过下标去改。
五、vector的三种遍历方式
在实际开发中,vector 最常用的操作之一就是遍历。
这里一共展示了三种遍历方法:
- 下标遍历
- 迭代器遍历
- C++11 范围 for 遍历
代码如下:
cpp
for (int i = 0; i < datas.size(); i++)
cout << datas[i] << " ";
cout << "\n";
//迭代器
std::vector<int>::iterator itr = datas.begin();
for (auto itr = datas.begin();itr != datas.end();itr++)
cout << *itr << ",";
cout << "\n";
//c++11
for (auto& d : datas)
{
cout << d << "|";
}
cout << "\n";下面分别讲。
5.1 下标遍历
代码:
cpp
for (int i = 0; i < datas.size(); i++)
cout << datas[i] << " ";这是最容易理解的一种方式。
(1)执行过程
假设:
cpp
datas = {99, 11, 12}那么:
i = 0时输出datas[0]i = 1时输出datas[1]i = 2时输出datas[2]
最终输出:
bash
99 11 12(2)这种方式的优点
优点是非常直观,适合初学者理解。
同时,如果你还需要"当前位置下标",那么这种方式非常方便。
例如:
cpp
cout << "下标:" << i << " 值:" << datas[i] << endl;(3)这种方式的缺点
缺点是写法稍微繁琐,而且每次都要写:
cpp
datas[i]如果只是单纯遍历所有元素,不一定是最简洁的方式。
5.2 迭代器遍历
这是 vector 很重要的知识点。
代码:
cpp
std::vector<int>::iterator itr = datas.begin();
for (auto itr = datas.begin(); itr != datas.end(); itr++)
cout << *itr << ",";(1)iterator是什么
iterator 翻译过来就是:
迭代器
它可以理解为:
专门用来在容器中移动、定位和取值的一种工具类型。
对于**vector 这种连续存储的容器来说,迭代器的使用体验很像指针**。
比如:
- 可以加
*取值 - 可以
++往后移动 - 可以和
end()比较 - 可以相减求距离
(2)这一句要怎么拆开理解
cpp
std::vector<int>::iterator itr = datas.begin();可以拆成三部分。
1)std::vector<int>::iterator
表示:vector<int> 这种容器对应的"迭代器类型"。
2)itr
表示:定义一个名为 itr 的变量。
3)datas.begin()
表示:把 itr 指向 datas 的第一个元素位置。
所以整句意思就是:
定义一个专门用于遍历 vector<int> 的迭代器变量,并让它先指向开头。
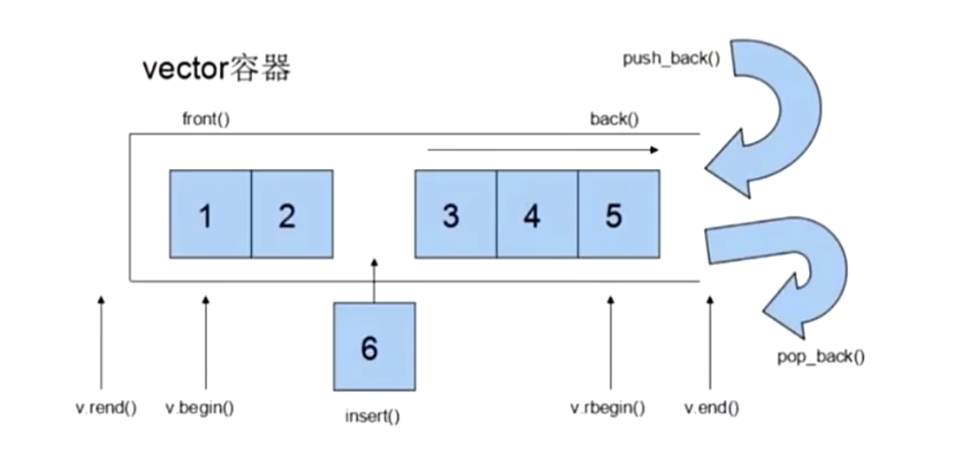
(3)begin 和 end 分别是什么
1)begin():
cpp
datas.begin()表示指向第一个元素的位置。
2)end():
cpp
datas.end()注意:
它不是最后一个元素,而是"最后一个元素的下一个位置"。
也叫:
尾后位置
这一点非常重要。
例如:
cpp
vector<int> datas{10,20,30};那么:
begin()指向10end()指向30后面的那个"越过末尾的位置"
所以遍历通常写成:
cpp
for (auto itr = datas.begin(); itr != datas.end(); itr++)意思是:
从第一个元素开始,一直往后走,直到还没走到结尾的下一个位置。
(4)为什么要写 *itr
代码:
cpp
cout << *itr << ",";这里的**itr 是迭代器,它本身表示"位置"**。
而 *itr 才表示:
取出这个位置上的元素值。
这和指针很像:
itr:像地址、像位置*itr:像取地址里的值
(5)itr++是什么意思
cpp
itr++表示把迭代器往后移动一个位置。
对于 vector 来说,就是从当前元素走到下一个元素。
例如:
- 一开始指向第 0 个元素
- 执行
itr++后,指向第 1 个元素 - 再执行一次,就指向第 2 个元素
(6)为什么说vector迭代器很像指针
因为对于 vector 这种连续空间容器:
- 可以
*itr取值 - 可以
itr++往后移动 - 可以做减法求位置差
例如:
cpp
f - datas.begin()这就能算出当前位置是第几个元素。
所以初学阶段,你可以先把 vector 迭代器理解成:
"一种行为很像指针的遍历工具"。
5.3 C++11范围for遍历
代码:
cpp
for (auto& d : datas)
{
cout << d << "|";
}这是现代 C++ 里非常常用的写法。
(1)这句代码怎么理解
cpp
for (auto& d : datas)意思是:
把 datas 中的每一个元素,依次拿出来,当前这个元素用变量 d 来表示。
也就是说:
如果 datas 里有:
cpp
99 11 12那么循环时:
- 第一次,
d代表99 - 第二次,
d代表11 - 第三次,
d代表12
(2)这里的d到底是什么
d 就是**"当前遍历到的元素"**。
你可以把它看成是循环过程中,系统自动帮你拿到的每一个值。
例如:
cpp
for (auto d : datas)这里 d 就是一份拷贝值,是 d 这个临时副本,不会影响原来的 datas。
而你代码里写的是:
cpp
for (auto& d : datas)这里 d 就不是拷贝,而是原元素本身的引用。
(3)&引用是什么意思
& 表示 引用。
引用可以理解为:
给原来的变量起一个别名。
例如:
cpp
int a = 10;
int& b = a;这时候**b 不是新开辟一个独立变量,而是 a 的另一个名字**。
所以:
cpp
b = 20;实际上改的是 a。
(4)auto& d为什么常用
cpp
for (auto& d : datas)这样写的好处有两个:
1)不会拷贝元素,效率更高
2)可以直接修改原容器中的元素
例如:
cpp
for (auto& d : datas)
{
d += 1;
}执行后,datas 中每个元素都会加 1。
(5)如果不想修改元素怎么办
如果你只是读取,不想改值,工程里更推荐:
cpp
for (const auto& d : datas)
{
cout << d << " ";
}这样既避免拷贝,也防止误修改原数据。
六、本节代码完整示例
cpp
#include <iostream>
#include <vector>
#include<string>
using namespace std;
int main()
{
//vector的定义及初始化
std::vector<int> vi;
vector<string> vs;
vector<float> vf;
vector<int> vd1(10); //设置数组大小
//初始化
vector<int> vd2{ 1,2,3,4,6 };
vector<string> vs1{ "ss1","ss2","ss3" };
//增加\删除\修改\查找
{
std::vector<int> datas;
datas.push_back(10); //结尾处插入内容
datas.push_back(11);
datas.push_back(12);
datas[0] = 99; //直接修改
//三种遍历
for (int i = 0; i < datas.size(); i++)
cout << datas[i] << " ";
cout << "\n";
//迭代器
std::vector<int>::iterator itr = datas.begin();
for (auto itr = datas.begin();itr != datas.end();itr++)
cout << *itr << ",";
cout << "\n";
//c++11
for (auto& d : datas)
{
cout << d << "|";
}
cout << "\n";
}七、重要知识点
7.1 vector的核心特点
(1)vector 是动态数组
(2)大小可以变化
(3)内部通常是连续空间
(4)支持快速访问
(5)工程中使用非常广泛
vector 就是一个可变长的数组容器,它既能像数组一样通过下标访问,也能通过迭代器和范围 for 更灵活地遍历。
7.2 本节必须掌握的几个操作
(1)定义 vector<类型>
(2)使用 push_back() 增加元素
(3)使用 size() 获取大小
(4)使用 [] 下标访问与修改
(5)掌握三种遍历方式
(6)理解 iterator、begin()、end()
(7)理解 auto& d 中 d 和 & 的含义
7.3 初学者最容易犯错的地方
(1)空 vector 直接用下标赋值
错误示例:
cpp
vector<int> datas;
datas[0] = 99;(2)把 end() 理解成最后一个元素
其实 end() 是尾后位置
(3)把迭代器当成元素值
其实迭代器是位置,*迭代器 才是元素值
(4)不理解 auto& d 中的 &
这里 & 是引用,不是取地址