目录
[二、Spring AI Alibaba Graph 介绍](#二、Spring AI Alibaba Graph 介绍)
[2.1 Spring AI Alibaba Graph 是什么](#2.1 Spring AI Alibaba Graph 是什么)
[2.2 Graph 核心概念](#2.2 Graph 核心概念)
[2.3 Graph 主要功能亮点](#2.3 Graph 主要功能亮点)
[2.4 Graph 应用场景](#2.4 Graph 应用场景)
[2.4.1 两大核心模式](#2.4.1 两大核心模式)
[2.4.2 具体落地场景与案例说明](#2.4.2 具体落地场景与案例说明)
[2.4.3 如何选择适合的模式](#2.4.3 如何选择适合的模式)
[三、Spring AI Alibaba Graph 项目实战整合](#三、Spring AI Alibaba Graph 项目实战整合)
[3.1 前置准备](#3.1 前置准备)
[3.1.1 技术栈](#3.1.1 技术栈)
[3.1.2 获取apikey](#3.1.2 获取apikey)
[3.2 Spring AI Alibaba Graph 基本使用](#3.2 Spring AI Alibaba Graph 基本使用)
[3.2.1 添加项目依赖](#3.2.1 添加项目依赖)
[3.2.2 添加配置文件](#3.2.2 添加配置文件)
[3.2.3 需求场景](#3.2.3 需求场景)
[3.2.4 代码集成过程](#3.2.4 代码集成过程)
[3.2.4.1 增加ChatClient 配置类](#3.2.4.1 增加ChatClient 配置类)
[3.2.4.2 增加3个自定义的Node](#3.2.4.2 增加3个自定义的Node)
[3.2.4.3 组织Node并编译](#3.2.4.3 组织Node并编译)
[3.2.4.4 增加测试接口](#3.2.4.4 增加测试接口)
[3.2.4.5 效果演示](#3.2.4.5 效果演示)
[3.3 实际业务案例代码实战过程](#3.3 实际业务案例代码实战过程)
[3.3.1 业务背景说明](#3.3.1 业务背景说明)
[3.3.2 前置准备](#3.3.2 前置准备)
[3.3.3 自定义Node节点类](#3.3.3 自定义Node节点类)
[3.3.4 定义图形编排配置类](#3.3.4 定义图形编排配置类)
[3.3.5 增加测试接口](#3.3.5 增加测试接口)
[3.3.6 效果测试](#3.3.6 效果测试)
一、前言
在过去一段时间,AI 工作流平台让很多人看到基于这种模式可以完成很多现实业务的编排,复杂业务的建模和协同工作。得益于大模型的飞速发展,以及各类AI智能体平台生态的完善,比如像Coze,Dify这类平台,就算是不懂技术的小白也可以在这类的AI工作流平台快速完成一个复杂的任务。在微服务领域,应用程序为了能够像AI工作流那样,发挥更大的作用,Spring AI Alibaba Graph 的出现,让AI工作流的编排模式融入到微服务开发领域,本文,将详细介绍Spring AI Alibaba Graph的使用。
二、Spring AI Alibaba Graph 介绍
2.1 Spring AI Alibaba Graph 是什么
Spring AI Alibaba Graph 是一个基于图(Graph)模型的工作流与多智能体编排框架,可以把它理解为 Java 生态中的 LangGraph。它的核心思想是将智能体的任务拆解为节点和边,通过灵活的编排来实现确定性工作流和复杂的多智能体协作,官网入口:http://java2ai.com/
2.2 Graph 核心概念
Spring AI Alibaba Graph 将智能体工作流建模为图,可以使用三个关键组件来定义智能体的行为:
-
- 共享的数据结构,表示应用程序的当前快照。它由
OverAllState对象表示。
- 共享的数据结构,表示应用程序的当前快照。它由
-
- 一个函数式接口 (
AsyncNodeAction),编码智能体的逻辑。它们接收当前的State作为输入,执行一些计算或副作用,并返回更新后的State。或者使用AsyncNodeActionWithConfig,它可以额外接收RunnableConfig用于传递上下文。
- 一个函数式接口 (
-
- 一个函数式接口 (
AsyncEdgeAction),根据当前的State确定接下来执行哪个Node。它们可以是条件分支或固定转换。或者使用AsyncEdgeActionWithConfig,它可以额外接收RunnableConfig用于传递上下文。
- 一个函数式接口 (
总结来说:
-
通过组合
Nodes和Edges,就可以创建复杂的循环工作流,工作流在工作过程中持续更新State,Spring AI Alibaba 会管理好State,并确保State在工作流中传递并持久化。 -
在 Graph 中,
Nodes和Edges就像函数一样 - 它们可以包含 LLM 调用或只是普通的 Java 代码。
2.3 Graph 主要功能亮点
Spring AI Alibaba Graph 提供了一系列开箱即用的高级功能,能有效提升开发效率:
-
多智能体(Multi-Agent)编排:
- 内置了 Supervisor、Sequential、Loop 等多种常见的多智能体协作模式,方便构建多个 AI 角色协同工作的应用。
-
人机协同(Human-in-the-Loop):
- 支持在工作流的特定节点设置"人工确认",流程会在此暂停,等待人工干预、修改状态或批准后才能继续执行。
-
持久化与记忆:内置检查点(Checkpointer)机制,可以自动保存工作流每一步的状态快照。这既实现了流程的断点续跑,也为多轮对话等场景提供了长期记忆能力。
-
预置节点与可视化:
- 提供了
LlmNode、QuestionClassifierNode等大量实用的预置节点,可以直接拿来用。同时,框架支持将流程图导出为 PlantUML 或 Mermaid 格式,方便文档生成和调试。
- 提供了
2.4 Graph 应用场景
基于 Spring AI Alibaba Graph 的实际应用场景,主要集中在企业级工作流自动化和复杂多智能体协作两大方向。它很好地平衡了"流程的确定性"和"AI 的自主性",在多个场景下都有落地价值。
2.4.1 两大核心模式
在使用前,可以先理解 Graph 支持的两种核心模式:
|---------|----------------------------------------|------------------|
| 模式 | 核心理念 | 优势 |
| 确定性工作流 | 流程由人事先绘制,AI 只负责执行特定节点(如分类、生成) | 流程可控、结果稳定、易于调试。 |
| 自主性多智能体 | 多个 AI 智能体协作,通过规划、分工、执行完成任务,流程由 AI 动态决策 | 能处理高度复杂、动态变化的任务。 |
2.4.2 具体落地场景与案例说明
以下是几个典型的应用场景,前三个是官方提供的可运行示例,具有一定的参考价值:
智能客户服务与工单分类
这是确定性工作流的典型应用,系统接收到用户反馈后,会自动进行分类和路由:
-
工作原理:
-
一级分类:判断评价是正面还是负面。
-
二级分类:若为负面,进一步识别具体问题,如售后 (after-sale)、质量 (quality)、物流 (transportation)。
-
自动路由:根据分类结果,将任务自动分发给对应的处理节点,最终统一记录归档。
-
-
核心价值:
- 将重复性、规则明确的客服工作自动化,7x24 小时响应,大幅降低人工成本。
智能助手与工具调用
这是自主性多智能体中 ReAct 模式(思考-行动-观察循环)的典型应用:
-
工作原理:
- 用户提问后,Agent 会自主决定调用哪个工具来获取信息。例如,询问"杭州、上海、南京这三座城市周末的天气怎么样?",Agent 会自动规划,分别查询三个城市的天气,最后整合结果回复用户。
-
核心价值:
- 让 AI 不仅能"思考",更能通过调用外部工具(如搜索引擎、企业内部 API、数据库)来"行动",解决实际问题。
通用任务执行 (如 JManus)
这代表更复杂的多智能体协作,通过多个角色各司其职来完成一个宏大目标。
-
**工作原理:**典型的 Supervisor 模式包含三个核心 Agent:
-
规划代理 (Planning Agent):将复杂任务分解为多个子步骤。
-
监督代理 (Supervisor Agent):负责调度,按顺序将子任务分配给执行代理。
-
执行代理 (Executor Agent):配备浏览器、文件操作、代码执行等工具,具体执行每个子任务。
-
-
核心价值:
- 可以构建一个类似"数字员工"的通用智能体,来完成"帮我查一下阿里云过去一周的股票信息,并生成一份简要报告"这类跨应用、多步骤的复杂任务。
深度研究与报告生成 (DeepResearch)
这是多智能体协作的另一标杆应用,专注于自动化的信息搜集与分析。
-
工作原理:
- 系统能够接收一个研究主题,自主地进行多轮联网搜索、访问相关网页、阅读并提炼信息,最终整合成一份结构清晰、有理有据的深度研究报告。
-
核心价值:
- 将分析师、研究员从繁重的信息搜集工作中解放出来,极大提升信息获取和知识沉淀的效率。
自然语言查询 (ChatBI / NL2SQL)
这是将 AI 能力与结构化数据(数据库)结合的绝佳场景。
-
工作原理:用户直接用中文提问,如"上个月销量最高的产品是什么?"。智能体能够理解问题意图,自动生成对应的 SQL 查询语句,连接数据库执行查询,并将查询结果以自然语言形式返回给用户。
-
核心价值:降低数据查询门槛,让非技术人员也能轻松获取和分析业务数据,实现"数据民主化"。
2.4.3 如何选择适合的模式
结合下面的建议,你可以根据任务特征来选择合适的实现方式:
-
流程固定、结果可预期:选择确定性工作流。比如退货处理、审批流程、内容审核,Graph 能提供稳定高效的自动化处理。
-
任务复杂、路径多变:选择自主性多智能体。比如需要研究、规划、决策的开放性任务,Graph 的多智能体协作能力更具优势。
这些场景中,你有特别感兴趣的吗?比如我可以展开讲讲 DeepResearch 的报告生成流程,或者 ChatBI 如何实现 NL2SQL,告诉我你想深入了解哪一个。
三、Spring AI Alibaba Graph 项目实战整合
接下来通过一个实际需求场景来详细说明如何在项目开发中整合并使用Spring AI Alibaba Graph
3.1 前置准备
3.1.1 技术栈
搭建一个springboot工程,本次工程依赖环境
-
JDK17
-
Maven 3.6.3
-
Springboot 3.2.2
3.1.2 获取apikey
登录阿里云百炼平台,获取apikey,入口:https://bailian.console.aliyun.com/cn-beijing#/home
- 使用这里的apikey可以直接连接各种大模型,便于业务集成使用
3.2 Spring AI Alibaba Graph 基本使用
接下来,通过代码操作具体演示下如何使用Spring AI Alibaba Graph
3.2.1 添加项目依赖
在工程的pom文件中添加下面的依赖
- 数据库连接的操作是非必须的,可以根据实际需要进行选择
java
<properties>
<maven.compiler.source>17</maven.compiler.source>
<maven.compiler.target>17</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<spring-ai.version>1.0.0-M6</spring-ai.version>
<spring-ai-alibaba.version>1.0.0-M6.1</spring-ai-alibaba.version>
</properties>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.3.3</version>
<relativePath/>
</parent>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-bom</artifactId>
<version>${spring-ai.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-starter</artifactId>
<version>${spring-ai-alibaba.version}</version>
</dependency>
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-graph-core</artifactId>
<version>1.0.0.4</version>
</dependency>
<!-- Mysql Connector -->
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
</dependency>
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>3.0.3</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.5.5</version>
<exclusions>
<exclusion>
<groupId>org.mybatis</groupId>
<artifactId>mybatis-spring</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
</dependencies>
<repositories>
<repository>
<name>Central Portal Snapshots</name>
<id>central-portal-snapshots</id>
<url>https://central.sonatype.com/repository/maven-snapshots/</url>
<releases>
<enabled>false</enabled>
</releases>
<snapshots>
<enabled>true</enabled>
</snapshots>
</repository>
<repository>
<id>spring-milestones</id>
<name>Spring Milestones</name>
<url>https://repo.spring.io/milestone</url>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
<repository>
<id>spring-snapshots</id>
<name>Spring Snapshots</name>
<url>https://repo.spring.io/snapshot</url>
<releases>
<enabled>false</enabled>
</releases>
</repository>
</repositories>
<build>
<finalName>${project.artifactId}</finalName>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>3.2.2 添加配置文件
在工程配置文件添加下面的配置信息,其中数据库的连接配置在示例中是非必须的,可以选择性添加
java
server:
port: 8082
spring:
ai:
dashscope:
api-key: sk-你的apikey
chat:
options:
model: qwen3-max
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://IP:3306/db?useUnicode=true&characterEncoding=utf8&zeroDateTimeBehavior=convertToNull&useSSL=true&serverTimezone=GMT%2B8&rewriteBatchedStatements=true&allowPublicKeyRetrieval=true&allowMultiQueries=true
username: root
password: 123456
mybatis-plus:
# 不支持多包, 如有需要可在注解配置 或 提升扫包等级
# 例如 com.**.**.mapper
mapperPackage: com.congge.mapper
# 对应的 XML 文件位置
mapperLocations: classpath*:mapper/**/*Mapper.xml
# 实体扫描,多个package用逗号或者分号分隔
typeAliasesPackage: com.congge.entity
global-config:
dbConfig:
# 主键类型
# AUTO 自增 NONE 空 INPUT 用户输入 ASSIGN_ID 雪花 ASSIGN_UUID 唯一 UUID
# 如需改为自增 需要将数据库表全部设置为自增
idType: ASSIGN_ID
# 逻辑已删除值(默认为 1)
logic-delete-value: 1
# 逻辑未删除值(默认为 0)
logic-not-delete-value: 03.2.3 需求场景
给出下面一个实际的场景,使用过Coze 或者 Dify的同学对AI 工作流应该不陌生,基于AI工作流,可以做很多复杂的业务流程编排,比如在下面的工作流中,根据用户输入的中文词汇,通过大模型的理解,最后转化为一个英语句子
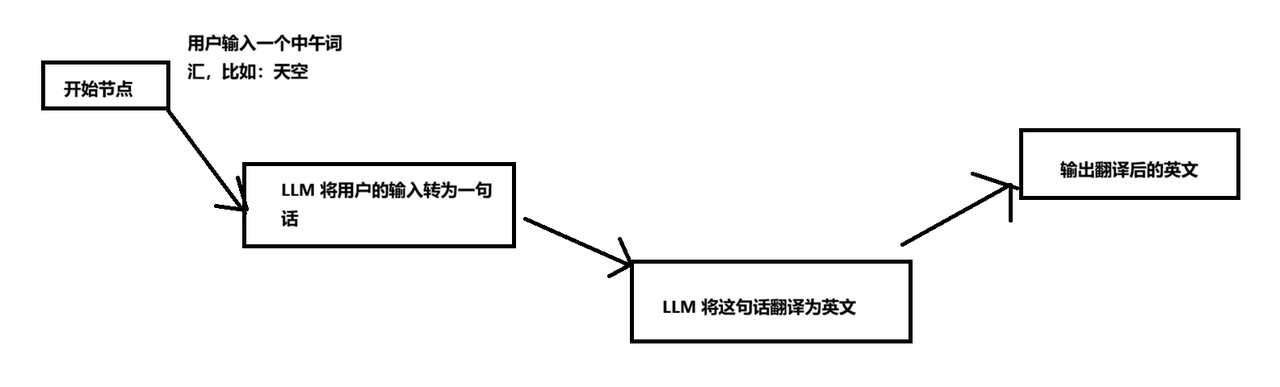
3.2.4 代码集成过程
基于上面的这个需求场景,下面用代码进行实现
3.2.4.1 增加ChatClient 配置类
自定义一个ChatClient 的配置类,方便后续其他类直接注入
java
package com.congge.config;
import jakarta.annotation.Resource;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.io.IOException;
@Configuration
public class ChatConfig {
@Bean
public ChatClient chatClient(ChatClient.Builder chatClientBuilder) throws IOException {
var chatClient = chatClientBuilder
//.defaultSystem("You are a helpful assistant.")
.build();
return chatClient;
}
}3.2.4.2 增加3个自定义的Node
和我们在AI工作流编排的时候效果一样,每个节点都需要处理一个各自的事项,在Graph中就是一个Node节点,这里按照上面的流程图依次定义2个Node,分别处理中文单词转为句子,再将中文一句话转为英文句子
- 在Graph中,只需要实现NodeAction 这个接口,重写里面的apply方法,在apply方法里面进行逻辑编写
1)第一个Node
java
package com.congge.config;
import com.alibaba.cloud.ai.graph.OverAllState;
import com.alibaba.cloud.ai.graph.action.NodeAction;
import org.springframework.ai.chat.client.ChatClient;
import reactor.core.publisher.Flux;
import java.util.Map;
public class GenSentenceNode implements NodeAction {
private final ChatClient chatClient;
public GenSentenceNode(ChatClient chatClient) {
this.chatClient = chatClient;
}
@Override
public Map<String, Object> apply(OverAllState state) throws Exception {
//获取用户输入的单词
String msg = state.value("msg","");
Flux<String> content = chatClient
.prompt()
.user(
t -> t.text(
"""
根据用户输入的单词 : {msg}
生成一个句子
"""
).param("msg", msg)
)
.stream()
.content();
StringBuilder sb = new StringBuilder();
//将收集到的数据放入sb
content.doOnNext(c -> sb.append(c)).blockLast();
return Map.of("sentence",sb.toString());
}
}2)第二个Node
java
package com.congge.config;
import com.alibaba.cloud.ai.graph.OverAllState;
import com.alibaba.cloud.ai.graph.action.NodeAction;
import org.springframework.ai.chat.client.ChatClient;
import reactor.core.publisher.Flux;
import java.util.Map;
public class TransferEnglishNode implements NodeAction {
private final ChatClient chatClient;
public TransferEnglishNode(ChatClient chatClient) {
this.chatClient = chatClient;
}
@Override
public Map<String, Object> apply(OverAllState state) throws Exception {
//获取用户输入的单词
String sentence = state.value("sentence","");
Flux<String> content = chatClient
.prompt()
.user(
t -> t.text(
"""
根据输入的句子 : {sentence}
翻译成英文
"""
).param("sentence", sentence)
)
.stream()
.content();
StringBuilder sb = new StringBuilder();
//将收集到的数据放入sb
content.doOnNext(c -> sb.append(c)).blockLast();
return Map.of("english",sb.toString());
}
}3.2.4.3 组织Node并编译
为了最终通过Graph输出目标的英文句子,需要通过一个配置类,即Graph中 CompiledGraph 这个Bean,将上面的各个Node 组织起来,参考下面的代码
- Node与Node之间的连接,是通过Graph中addEdge 这个方法完成的
java
package com.congge.config;
import com.alibaba.cloud.ai.graph.CompiledGraph;
import com.alibaba.cloud.ai.graph.KeyStrategy;
import com.alibaba.cloud.ai.graph.KeyStrategyFactory;
import com.alibaba.cloud.ai.graph.StateGraph;
import com.alibaba.cloud.ai.graph.action.AsyncNodeAction;
import com.alibaba.cloud.ai.graph.exception.GraphStateException;
import com.alibaba.cloud.ai.graph.state.strategy.ReplaceStrategy;
import jakarta.annotation.Resource;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.util.Map;
@Configuration
public class TestGraphConfig {
@Resource
private ChatClient chatClient;
@Bean
public CompiledGraph testGraph() throws GraphStateException {
KeyStrategyFactory keyStrategyFactory = new KeyStrategyFactory() {
@Override
public Map<String, KeyStrategy> apply() {
return Map.of(
"msg", new ReplaceStrategy(),
"sentence", new ReplaceStrategy(),
"english", new ReplaceStrategy()
);
}
};
//构造图
StateGraph stateGraph = new StateGraph(keyStrategyFactory);
//在图中增加节点
stateGraph.addNode("genSentence", AsyncNodeAction.node_async(new GenSentenceNode(chatClient)));
stateGraph.addNode("transferEnglish", AsyncNodeAction.node_async(new TransferEnglishNode(chatClient)));
//添加边操作
stateGraph.addEdge(StateGraph.START, "genSentence");
stateGraph.addEdge("genSentence", "transferEnglish");
stateGraph.addEdge("transferEnglish", StateGraph.END);
//图形编译
CompiledGraph compiledGraph = stateGraph.compile();
return compiledGraph;
}
}3.2.4.4 增加测试接口
为了方便后续看效果,增加一个测试接口
- 注意,接口参数中的msg,即为模拟用户输入到流程图中的开始节点接收的那个参数
java
package com.congge.web;
import com.alibaba.cloud.ai.graph.CompiledGraph;
import com.alibaba.cloud.ai.graph.OverAllState;
import jakarta.annotation.Resource;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import java.util.Map;
import java.util.Optional;
@RestController
public class TestGraphController {
@Resource
private CompiledGraph compiledGraph;
//localhost:8082/testGraph?msg=天空
@GetMapping("/testGraph")
public Object testGraph(@RequestParam String msg) {
OverAllState overAllState = compiledGraph.call(Map.of("msg", msg)).get();
return overAllState.data();
}
}3.2.4.5 效果演示
启动工程后,调用一下接口,输入的参数为:天空,最后返回了一个英语句子

3.3 实际业务案例代码实战过程
3.3.1 业务背景说明
在下面这样一个比较实际的场景中,通过实际的业务分析与业务建模后,就能基于Graph,通过代码进行实现了,下面我们将通过代码来完成这样一个场景下的代码实现过程
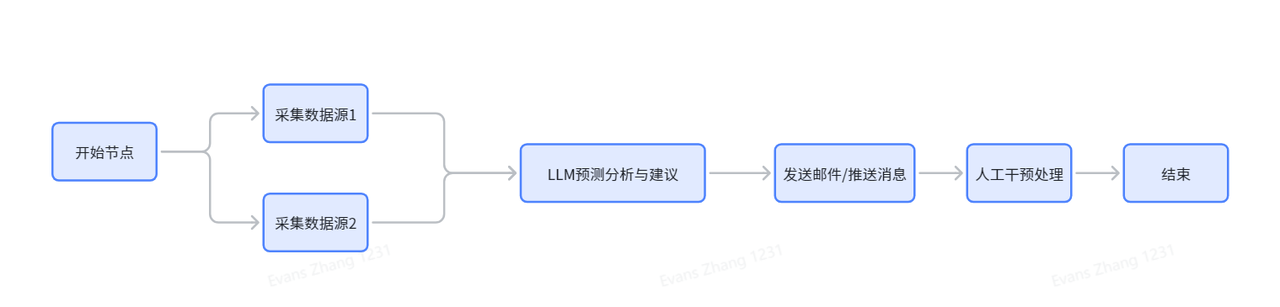
3.3.2 前置准备
为了后续代码中的效果演示,提前增加一个mysql的数据表,建表sql如下
bash
CREATE TABLE `sales_area_order` (
`id` bigint NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`store_name` varchar(32) NOT NULL COMMENT '销售门店',
`sales_time` datetime DEFAULT NULL COMMENT '统计月份',
`sales_count` int DEFAULT NULL COMMENT '销售额',
`best_selling_sku` varchar(32) NOT NULL COMMENT '最畅销的SKU',
`best_selling_sku_sum` int NOT NULL COMMENT '最畅销的SKU销售额',
PRIMARY KEY (`id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COMMENT='门店销售统计表';增加一些测试数据
sql
INSERT INTO `gh_log`.`sales_area_order`(`id`, `store_name`, `sales_time`, `sales_count`, `best_selling_sku`, `best_selling_sku_sum`) VALUES (1, '杭州分店', '2026-01-16 22:51:35', 20, '小米手机', 12);
INSERT INTO `gh_log`.`sales_area_order`(`id`, `store_name`, `sales_time`, `sales_count`, `best_selling_sku`, `best_selling_sku_sum`) VALUES (2, '杭州分店', '2026-04-09 22:53:01', 35, '华为蓝牙耳机', 8);
INSERT INTO `gh_log`.`sales_area_order`(`id`, `store_name`, `sales_time`, `sales_count`, `best_selling_sku`, `best_selling_sku_sum`) VALUES (3, '杭州分店', '2026-02-05 22:53:34', 27, '小米手机', 15);
INSERT INTO `gh_log`.`sales_area_order`(`id`, `store_name`, `sales_time`, `sales_count`, `best_selling_sku`, `best_selling_sku_sum`) VALUES (4, '杭州分店', '2026-03-06 22:54:16', 16, 'Ipad', 6);
INSERT INTO `gh_log`.`sales_area_order`(`id`, `store_name`, `sales_time`, `sales_count`, `best_selling_sku`, `best_selling_sku_sum`) VALUES (5, '金华分店', '2026-01-17 22:54:16', 19, 'Ipad', 8);
INSERT INTO `gh_log`.`sales_area_order`(`id`, `store_name`, `sales_time`, `sales_count`, `best_selling_sku`, `best_selling_sku_sum`) VALUES (6, '金华分店', '2026-02-09 11:54:16', 33, '联想笔记本', 11);
INSERT INTO `gh_log`.`sales_area_order`(`id`, `store_name`, `sales_time`, `sales_count`, `best_selling_sku`, `best_selling_sku_sum`) VALUES (7, '金华分店', '2026-03-25 11:54:16', 9, '小米电视', 6);
INSERT INTO `gh_log`.`sales_area_order`(`id`, `store_name`, `sales_time`, `sales_count`, `best_selling_sku`, `best_selling_sku_sum`) VALUES (8, '金华分店', '2026-04-10 11:53:16', 29, '华为蓝牙耳机', 17);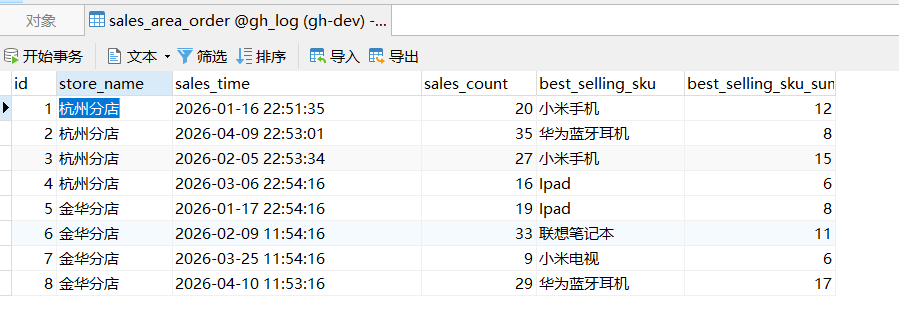
3.3.3 自定义Node节点类
按照上面的业务场景分析和流程图,本次的案例需要2个Node节点,加上开始和结束节点,一共4个,需要编写业务代码处理的节点有2个,分别是,查询数据表数据节点,以及根据查询的数据进行分析的LLM节点,参考下面的代码
1)第一个自定义节点
- 注意代码中的storeArea这个参数为接口中传递过来的,确保唯一性
java
package com.congge.config.node;
import com.alibaba.cloud.ai.graph.OverAllState;
import com.alibaba.cloud.ai.graph.action.NodeAction;
import com.congge.entity.SalesAreaOrder;
import com.congge.service.ISalesAreaOrderService;
import com.fasterxml.jackson.databind.ObjectMapper;
import org.springframework.ai.chat.client.ChatClient;
import java.util.List;
import java.util.Map;
public class StoreAreaNode implements NodeAction {
private final ChatClient chatClient;
private final ISalesAreaOrderService salesAreaOrderService;
public StoreAreaNode(ChatClient chatClient,ISalesAreaOrderService salesAreaOrderService) {
this.chatClient = chatClient;
this.salesAreaOrderService = salesAreaOrderService;
}
@Override
public Map<String, Object> apply(OverAllState state) throws Exception {
String storeArea = state.value("storeArea", "");
List<SalesAreaOrder> storeAreaList = salesAreaOrderService.getList(storeArea);
ObjectMapper objectMapper = new ObjectMapper();
String storeAreaListStr = objectMapper.writeValueAsString(storeAreaList);
return Map.of("storeAreaData",storeAreaListStr);
}
}2)第二个自定义节点
- 注意代码中的参数storeAreaData这个参数,为第一个节点的返回数据对应的key,在上一个节点中有定义
java
package com.congge.config.node;
import com.alibaba.cloud.ai.graph.OverAllState;
import com.alibaba.cloud.ai.graph.action.NodeAction;
import org.springframework.ai.chat.client.ChatClient;
import java.util.Map;
public class AnalysisLlmNode implements NodeAction {
private final ChatClient chatClient;
public AnalysisLlmNode(ChatClient chatClient) {
this.chatClient = chatClient;
}
@Override
public Map<String, Object> apply(OverAllState state) throws Exception {
//取出前面2个节点的数据
String storeArea = state.value("storeArea", "");
String storeAreaData = state.value("storeAreaData", "");
Map<String, Object> params = Map.of("storeArea", storeArea, "storeAreaData", storeAreaData);
String content = chatClient
.prompt()
.user(t -> t.text(
"""
根据用户输入的店铺名称 : {storeArea}
和店铺在2026年第一季度的销售数据 : {storeAreaData}
生成一份分析建议
"""
).params(params)
).call().content();
System.out.println("分析结果 :" + content);
return Map.of("llmData", content);
}
}3.3.4 定义图形编排配置类
最后,通过一个自定义的配置类,将上面的节点进行组织并编排起来
java
package com.congge.config;
import com.alibaba.cloud.ai.graph.CompiledGraph;
import com.alibaba.cloud.ai.graph.KeyStrategy;
import com.alibaba.cloud.ai.graph.KeyStrategyFactory;
import com.alibaba.cloud.ai.graph.StateGraph;
import com.alibaba.cloud.ai.graph.action.AsyncNodeAction;
import com.alibaba.cloud.ai.graph.exception.GraphStateException;
import com.alibaba.cloud.ai.graph.state.strategy.ReplaceStrategy;
import com.congge.config.node.AnalysisLlmNode;
import com.congge.config.node.StoreAreaNode;
import com.congge.service.ISalesAreaOrderService;
import jakarta.annotation.Resource;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.util.Map;
@Configuration
public class GraphConfig {
@Resource
private ChatClient chatClient;
@Resource
private ISalesAreaOrderService salesAreaOrderService;
@Bean("storeGraphConfig")
public CompiledGraph graphConfig() throws GraphStateException {
KeyStrategyFactory keyStrategyFactory = new KeyStrategyFactory() {
@Override
public Map<String, KeyStrategy> apply() {
return Map.of(
"storeArea", new ReplaceStrategy(),
"storeAreaData", new ReplaceStrategy(),
"llmData", new ReplaceStrategy()
);
}
};
//构造图
StateGraph stateGraph = new StateGraph(keyStrategyFactory);
//在图中增加节点
stateGraph.addNode("storeAreaNode", AsyncNodeAction.node_async(new StoreAreaNode(chatClient,salesAreaOrderService)));
stateGraph.addNode("llmNode", AsyncNodeAction.node_async(new AnalysisLlmNode(chatClient)));
//添加边操作
stateGraph.addEdge(StateGraph.START, "storeAreaNode");
stateGraph.addEdge("storeAreaNode", "llmNode");
stateGraph.addEdge("llmNode", StateGraph.END);
//图形编译
CompiledGraph compiledGraph = stateGraph.compile();
return compiledGraph;
}
}3.3.5 增加测试接口
为了方便看效果,增加一个测试接口,参考下面的代码
java
package com.congge.web;
import com.alibaba.cloud.ai.graph.CompiledGraph;
import com.alibaba.cloud.ai.graph.OverAllState;
import com.congge.entity.SalesAreaOrder;
import com.congge.service.ISalesAreaOrderService;
import jakarta.annotation.Resource;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import java.util.List;
import java.util.Map;
@RestController
@RequestMapping("/storeArea")
public class StoreAreaController {
@Resource
private CompiledGraph compiledGraph;
@Resource
private ISalesAreaOrderService salesAreaOrderService;
//localhost:8082/storeArea/testGraph?storeArea=杭州分店
@GetMapping("/testGraph")
public Object testGraph(@RequestParam String storeArea) {
OverAllState overAllState = compiledGraph.call(Map.of("storeArea", storeArea)).get();
return overAllState.data();
}
}3.3.6 效果测试
工程启动之后,调用一下接口,最终得到下面的效果,可以看到,通过将数据表中查询到的数据最终传递给大模型,大模型给出了一个分析报告,如果数据样本足够大,给出的分析建议就会更有参考价值
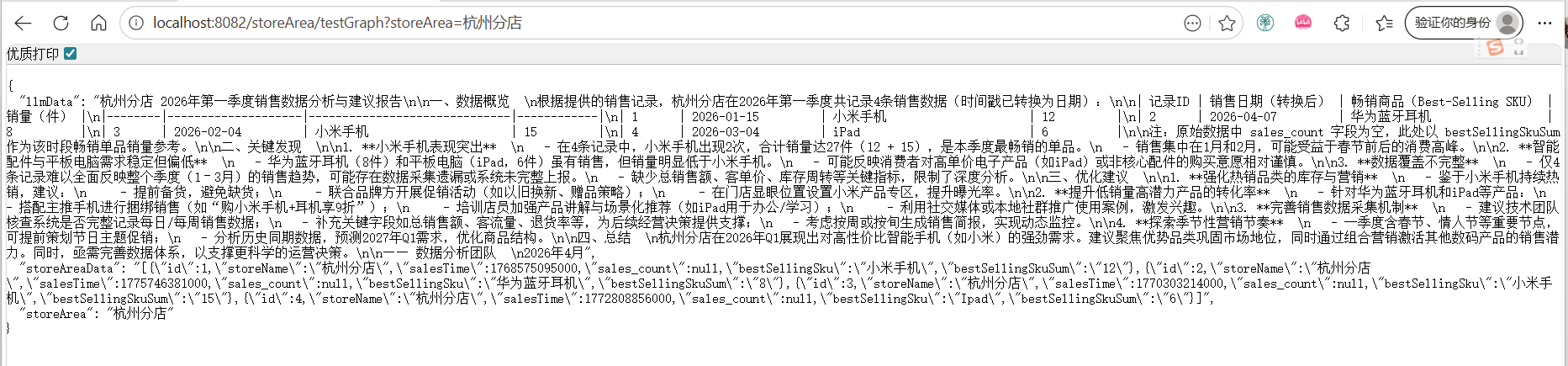
小结:
- 通过上面的案例实操不难发现,其实Graph的编码并不难,可以说整个代码的编写流程是模板化,比较固定的,难得是,如何对业务进行分析后的抽象建模,这也是考验我们做架构设计的水平
四、写在文末
本文通过较大的篇幅详细介绍了Spring AI Alibaba Graph这个组件的详细使用,并通过实际案例演示了其使用过程,希望对看到的同学有帮助,本篇到此结束,感谢观看。