
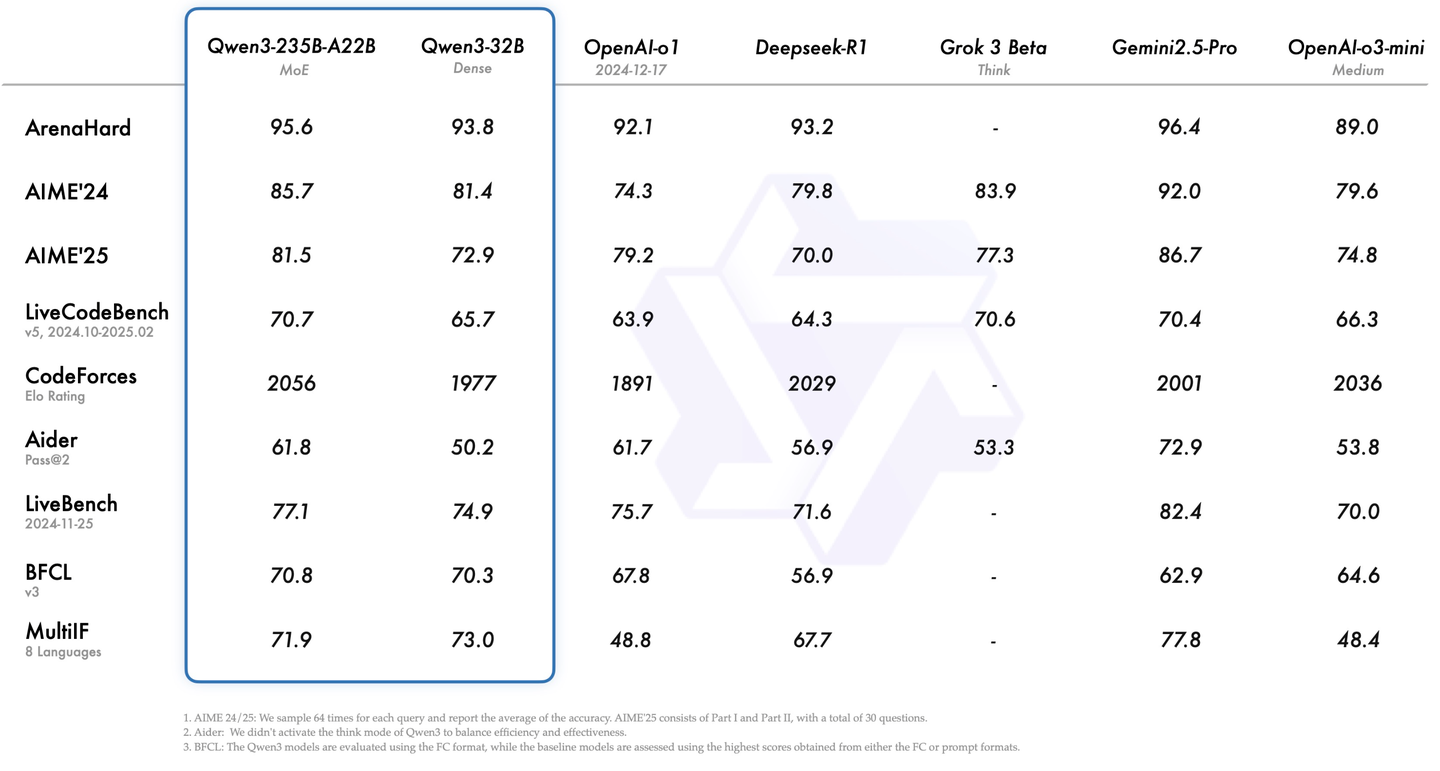
今日凌晨,阿里开源Qwen3,推理成本大幅下降,性能全面超越 DeepSeek-R1、OpenAI-o1 等,问鼎全球最强开源模型。在代码、数学、通用能力各项性能指标中,Qwen3都名列前茅。与 DeepSeek-R1、o1、o3-mini、Grok-3 和 Gemini-2.5-Pro 等顶级模型相比,表现出极具竞争力的结果。
而就在 4 天前,我们刚发布了业内首个图原生智能体系统系统 Chat2Graph,旨在通过智能体技术高效解决用图问题,同时深度融合「Graph+AI」技术增强智能体的推理效果。开源项目链接:https://github.com/TuGraph-family/chat2graph。
Chat2Graph视频介绍:https://www.bilibili.com/video/BV15CjPztEgg
Chat2Graph 届时已将 Qwen3 接入作为基础模型服务,并在第一时间对其在图领域的任务上的表现进行了评测。
对比模型
综合性能、推理能力、价格三个因素,我们从挑选如下三个模型做对比分析:
- Qwen3:最强开源大模型,支持 thinking/no-thinking 两种模式。
- OpenAI o3-mini:o 系列闭源模型,mini 版本推理速度快、tokens 价格适中。
- Gemini 2.5 flash:最新的 Gemini 系列闭源模型,flash 版本推理速度极快,tokens 价格非常便宜。
图领域任务
我们使用了同一个问题在Chat2Graph上进行测试:
根据「罗密欧与朱丽叶」的故事构建图谱。然后,你还要查询图数据库,告诉我故事中出现了多少人物角色。然后进行深度分析,计算出最有影响力的节点。
实验结果
整体实验结果如下表所示。
| Qwen3 | OpenAI o3-mini | Gemini 2.5 flash | |
|---|---|---|---|
| 图谱规模 | 10 实体 11 关系 | 4 实体 3 关系 | 25 实体 30 关系 |
| 抽取人物数(共14位) | 8 位 | 2 位 | 13 位 |
| 调用图算法 | PageRank、BC | PageRank | PageRank |
| 工具调用次数 | 32 次 | 30 次(失败 1 次) | 50 次 |
| 总执行时间 | 30 分钟 | 13 分钟 | 15 分钟 |
| 输出格式丰富度 | 高 | 中 | 中 |
具体分析来看:
- Qwen3:
- 抽取:能力一般,主要弱点在于数据提取阶段,只识别了8/14的人物,构建的图谱规模相对较小,影响了后续任务的基础。
- 分析:能力突出,Qwen3 在图分析阶段表现最好,不仅调用了PageRank 算法,还调用了 BC 算法,并结合两者进行了深度分析,展现了较强的分析解释能力。输出格式也最丰富。
- **效率:**一般,Qwen3 在三个模型中执行时间最长(30分钟)。但是在平均执行效率(执行时间/图谱规模)上和 OpenAI o3-mini 基本持平。
- 综合评定:★★★
- OpenAI o3-mini:
- 抽取:能力较差,仅提取了极少量的实体和关系(4实体,3关系),人物提取准确率最低(2/14)。构建的知识图谱过于稀疏,无法有效支持后续任务。
- **分析:**能力一般,在 Schema 设计、复杂工具(多参数的 PageRank 算法)调用、图查询语句生成方面表现尚可,但整体效果因数据基础薄弱而大打折扣。输出格式丰富度一般。
- 效率:一般,o3-mini 虽然总时间最短,但其极低的图谱质量产出,导致效率指标并不理想。但这可能是牺牲了信息提取完整性的结果(被评价为学习了"偷懒"技能)。
- 综合评定:★★
- Gemini 2.5 flash:
- **抽取:**能力最好,在此次测试中,Gemini 2.5 flash 表现最为出色。它成功构建了规模最大、最接近完整的知识图谱(25个实体,30条关系),并且在人物角色提取方面准确率最高(13/14,仅遗漏1位)。长文本幻觉率低,尽管逐步导入了相当规模的图谱,但没有出现节点重复导入的问题。
- 分析:能力一般,仅仅调用一个 PageRank 算法来找出最影响力的节点,不过作出了较为合理算法结果的解释,且结果符合基本常识。输出格式丰富度一般。
- 效率:最好,工具调用次数最多(50次),且执行时间仅为 15分钟,显示出较高的效率和彻底性。
- 综合评定:★★★★
最后补充一下部分关键测试效果。
任务规划
总体来看,三个模型在 Agent 任务规划能力上差异并不明显,基本上都能做到细致精确的子任务拆分。
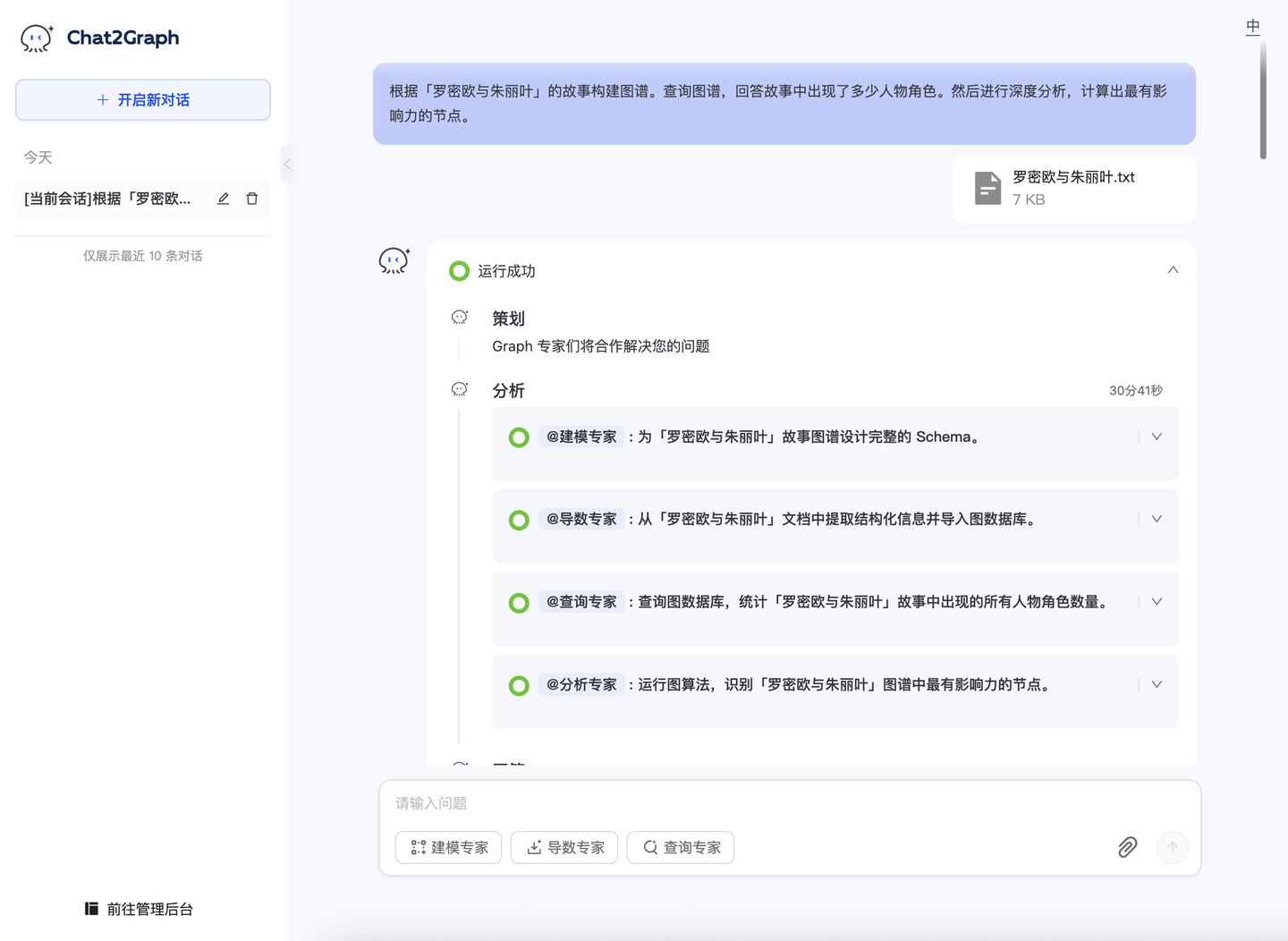
输出格式
从执行结果的输出格式来看,Qwen3 的输出格式相对丰富,可读性更加友好。

评测结论
整体来看,Gemini 2.5 flash 综合表现最佳,在执行效率和图抽取能力上优势明显;Qwen3 凭借对图领域工具的熟练运用展现了突出的深度分析能力,但在数据抽取和执行效率上表现一般;相比之下,o3-mini 整体表现最差。
因此,虽然 Qwen3 在各项开源测试榜单上表现出色,但经过对实际图任务的测试,与当下的领先的闭源模型能力仍有一定的差距。所以,通过特定的图领域知识和工具,基于通用大模型构建图原生智能体系统仍旧十分必要,这也是 Chat2Graph 一直以来要解决的问题。
技术展望
Qwen3的混合推理模型,无缝支持了thinking&no-thinking模式,为上层应用提供了灵活控制思考成本的能力。在Chat2Graph中可以尝试通过打开"thinking"模式来增强 Leader 的规划能力 / Thinker 的推理效果。同时也可以通过关闭"thinking"模式,降低 Expert/Actor 执行开销和时延。
此外 Qwen3 对 MCP 的支持,让我们看到大模型正在逐步过渡到以 Agent 为中心的训练,这更督促 Agent 的开发者需要深度反思大模型能力界限之外的 Agent 的工程设计策略,进一步挖掘在工程层面协助大模型改进智能应用端到端体验的创新与方案。