跨境电商行业正经历从"经验驱动"到"数据驱动"的深刻转型。亚马逊作为全球最大的电商平台,其海量的商品数据------包括价格、评分、评论数、销量排名、关键词热度------构成了选品决策、市场调研和竞争分析的核心素材。然而,数据的获取从来不是一件简单的事。
第一道门槛是地域限制。
亚马逊不同站点的商品推荐、价格展示、搜索排名会根据用户 IP 地址动态调整。换言之,中国 IP 访问亚马逊美国站,看到的内容往往与本地用户存在显著差异。更棘手的是,平台会针对来自数据中心 IP 的请求施加严格的反爬机制,轻则返回验证码(CAPTCHA),重则直接封禁 IP。
第二道门槛是数据采集的规模与持续性。
选品分析不是一次性行为,需要持续跟踪关键词排名变化、价格波动、竞品上新等多个维度。传统手动抓取效率极低,而写死在脚本里的固定 IP 在高频请求下几乎必然触发封禁。
第三道门槛是数据分析与决策链路。
采集到的原始数据如果不经过清洗、归因和洞察提炼,其价值极为有限。如何将数据转化为可执行的选品建议,一直是困扰中小卖家的问题。
目前市场上常见的解决方案主要依赖以下几种模式:或直接使用本地固定 IP 裸奔爬取,极易被封;或购买昂贵的商业数据服务,数据自主性差;或自行搭建代理池,但维护成本高、IP 质量参差不齐;或借助单一爬虫框架,缺乏与业务系统的集成能力,往往形成"数据孤岛"。这些方案的共同问题在于缺乏端到端的自动化链路------从数据采集到分析输出再到业务操作,往往需要大量人工介入。
本文旨在构建一套完整、开箱即用的端到端数据采集与协同分析方案,核心思路是:将 OpenClaw 的 Agent 编排能力、kookeey 的高质量动态住宅代理服务、Python 爬虫的灵活性,以及飞书渠道的即时协同能力有机结合。
具体而言,本文将达成以下目标:
第一,让 OpenClaw 理解并编排爬虫任务,使其能够根据自然语言指令自动触发亚马逊数据采集流程;
第二,借助 kookeey 动态代理确保采集过程稳定、隐匿、不被平台封禁;
第三,将采集到的商品数据进行结构化分析,生成有价值的选品洞察;
第四,打通飞书渠道,让整个流程的指令下发、状态反馈和结果推送都在飞书中完成,实现真正的"对话即服务"。
第一章 OpenClaw 安装与基础配置
1.1 什么是 OpenClaw
OpenClaw 是一个 AI Agent 运行时平台,其核心设计理念是让 AI 助手具备执行真实世界任务的能力。与单纯的对话式 AI 不同,OpenClaw 内置了丰富的工具生态(tools),包括文件读写、代码执行、浏览器自动化、API 调用、定时任务调度、多渠道消息收发等,Agent 可以像人一样"动手"完成任务,而不仅仅是"动嘴"给建议。
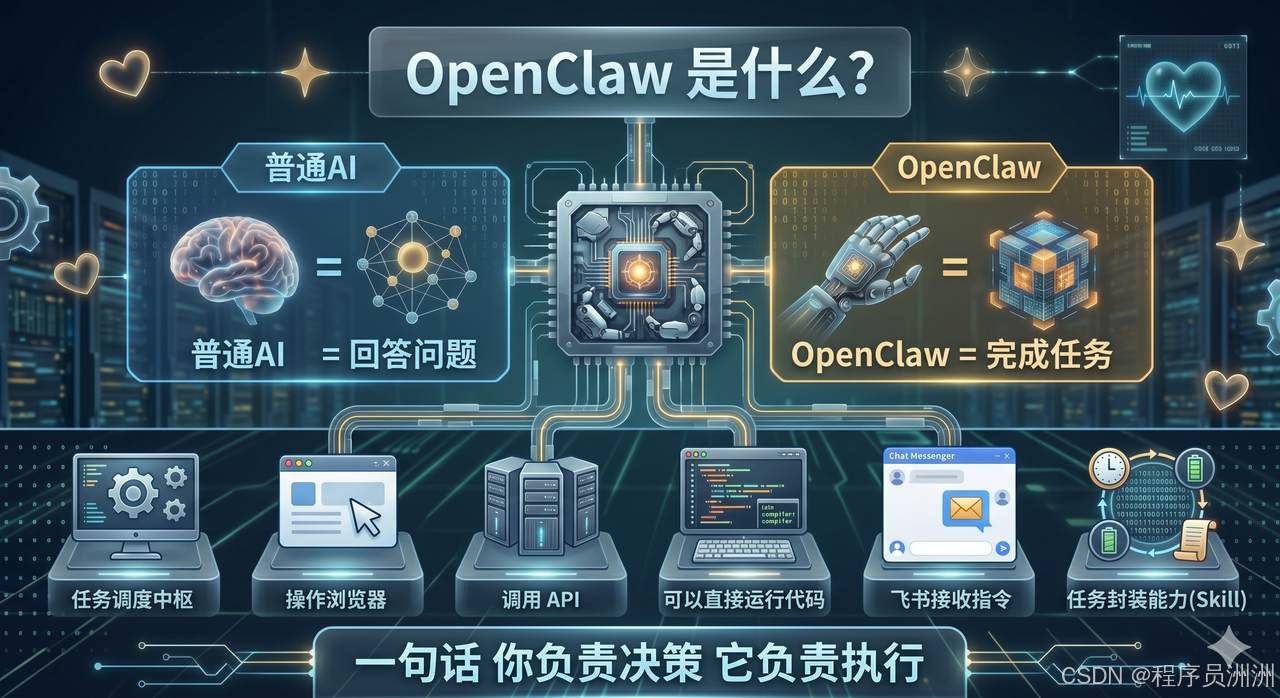
OpenClaw 的另一个核心优势在于其技能(Skill)系统。开发者可以将特定领域的工具链、工作流和提示词封装为可复用的 Skill,平台提供了 SkillHub 技能市场,支持一键安装。用户可以根据自身需求,像搭积木一样组合不同的 Skill,快速扩展 Agent 的能力边界------从网页爬取到文档生成,从邮件管理到飞书集成,都可以找到对应的解决方案。

在本文的实践场景中,OpenClaw 将扮演"中枢大脑"的角色:接收来自飞书的自然语言指令,理解任务意图,编排爬虫脚本执行,管理代理 IP 生命周期,最终将分析结果推送回飞书。
1.2 安装 OpenClaw
OpenClaw 支持 Windows、macOS 和 Linux 三大平台,可以使用 npm 全局安装 OpenClaw CLI:
cpp
npm install -g openclaw第二章 kookeey 动态代理服务:原理与本地配置
2.1 为什么用住宅代理
在深入了解 kookeey 之前,有必要理解为什么简单的数据中心 IP 无法满足亚马逊数据采集的需求。
亚马逊的反爬系统并非简单的 IP 黑名单,而是一套基于行为分析的智能检测机制。当一个 IP 表现出以下特征时,就极有可能触发封禁:请求频率异常均匀(固定间隔),请求头特征与真实浏览器不符,IP 归属地为数据中心而非家庭网络,以及短时间内从同一 IP 发起大量跨品类请求。
数据中心 IP(如 AWS、阿里云等云服务器 IP 段)在亚马逊的安全系统眼中几乎是"可疑"的代名词,因为普通用户在日常上网中几乎不会使用这类 IP 访问电商平台。相比之下,**住宅代理 ** 来自真实的家庭网络用户,其 IP 归属信息与普通消费者无异,更容易通过平台的反爬验证。
此外,亚马逊不同站点(美国、英国、德国、日本等)对同一商品展示的价格、排名和推荐存在明显差异。使用住宅代理可以灵活切换目标站点的"本地视角",获取最真实的本地化数据。
2.2 kookeey 产品简介
kookeey是一家专注于提供高质量住宅代理服务的品牌,其核心产品线包括动态住宅代理和静态住宅代理两种类型,能够满足不同场景下的业务需求。
kookeey 的核心优势体现在以下几个方面。
1、在 IP 质量方面,其代理 IP 均来自真实的家庭网络用户,具备真实运营商 ASN 编号,IP 信誉度高,不易被主流网站识别为代理或爬虫。
2、在地域覆盖方面,kookeey 支持全球多个国家和地区的 IP 资源,包括美国、英国、德国、法国、日本、巴西等主要市场,用户可以按需选择目标采集地区。
3、在稳定性方面,kookeey 提供了高可用的代理网络架构,IP 可用率通常在 99% 以上,且支持 API 方式批量提取 IP,便于与自动化脚本集成。
4、在隐私保护方面,所有经过 kookeey 代理的请求均经过加密传输,用户真实 IP 地址对目标网站完全不可见。
动态住宅代理是 kookeey 的主打产品。其工作原理是通过一个覆盖全球的代理 IP 池,每次请求自动从真实家庭网络中分配一个出口 IP。这些 IP 的地理位置可以精确到国家甚至城市级别,用户也可以设置按固定时间间隔自动切换 IP。
动态住宅代理非常适合需要高频请求、但不希望单个 IP 长时间在线的场景,可以有效分散请求压力,降低被识别为机器人行为的概率。

这里点击进入kookeey官网:https://www.kookeey.com/?aff=92790222:
可以通过手机号、邮箱或微信快速完成注册。kookeey也给我们新用户准备了免费体验福利:0MB 动态住宅流量 + 100MB 移动代理流量 + ¥288 体验券
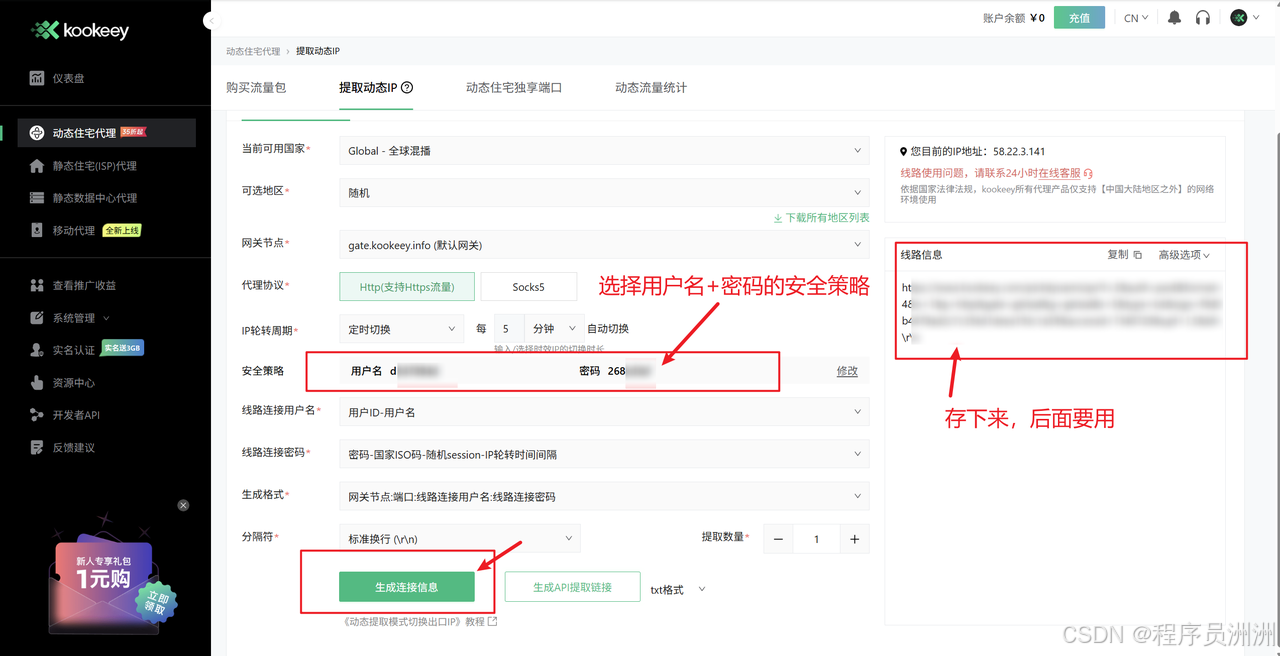
登录成功后,点击【动态住宅代理】,然后点击提取动态IP,生成连接参数,方便后续使用:
第三章 OpenClaw 驱动动态代理爬取亚马逊数据与智能分析
3.1 整体技术架构
在展开具体实现之前,有必要先梳理整个系统的技术架构和各组件之间的协作关系。
整个系统分为五个核心层次。渠道接入层 由飞书客户端构成,用户通过发送自然语言消息(如"帮我查一下美国站瑜伽垫的热门商品")发起任务请求。Agent 编排层 是 OpenClaw 的核心,负责理解用户意图、规划执行步骤、调用工具和技能、协调各模块的工作。代理管理层 负责与 kookeey API 交互,获取和管理动态 IP 资源,为爬虫脚本提供干净、隐匿的网络出口。数据采集层 由 Python 爬虫脚本构成,根据 Agent 的指令访问亚马逊各站点,抓取商品列表或详情页数据。数据分析层对采集到的原始数据进行清洗、结构化处理,并利用 AI 能力提炼选品洞察,最终将结果整理为可读的报告格式。
这种分层设计保证了系统的可扩展性和可维护性------任何一层的组件都可以独立升级或替换,而不影响其他层的正常运行。
3.2 爬虫脚本核心逻辑
亚马逊的数据接口分析是整个采集流程中最关键的环节,也是技术复杂度最高的部分。理解了这一步,就掌握了大半个跨境电商数据采集的底层方法论。
分析接口的第一步是观察网络请求。 以亚马逊美国站为例,打开 Chrome 浏览器访问 amazon.com。
按F12打开开发者工具,选择 Network(网络)标签。勾选Preserve log(保留日志)以防止页面跳转时请求记录丢失,同时勾选Disable cache(禁用缓存)确保获取最新数据。
在 Filter 过滤框中输入product、search或suggest关键词筛选;同时在Type(类型)列中优先勾选XHR和Fetch,聚焦异步数据接口。
在搜索框中输入目标关键词(如 "yoga mat")并执行搜索,观察 Network 面板中实时加载的新请求。
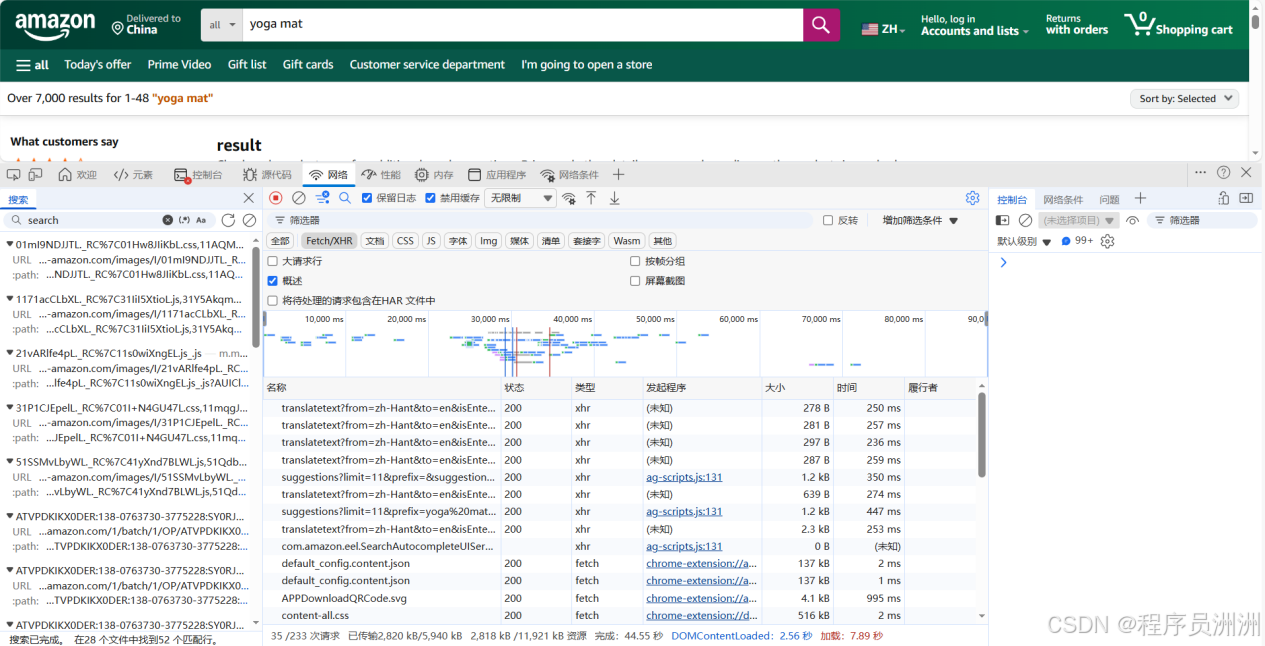
搜索执行后,Network 面板中会涌现大量请求。此时在 Filter 过滤框中输入 suggest、product 或 search 等关键词,同时将类型过滤条件优先聚焦于 XHR 和 Fetch 类型------这类请求通常是前端 JavaScript 动态加载的数据接口,比直接抓取 HTML 页面更加高效且数据更加结构化。
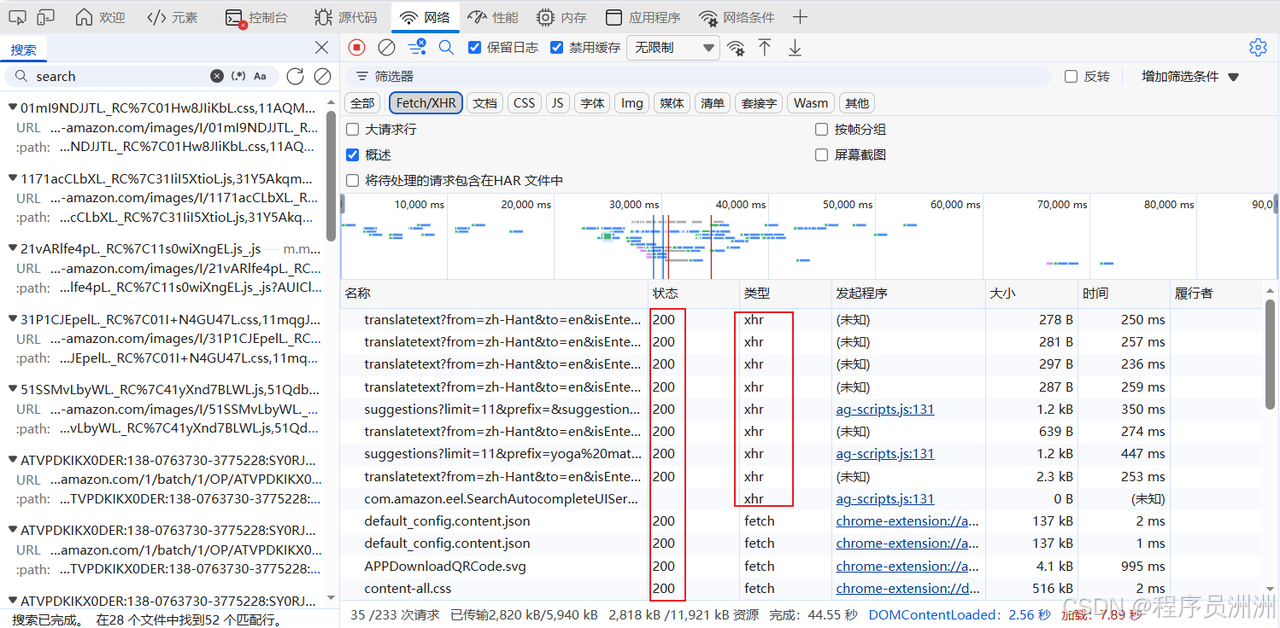
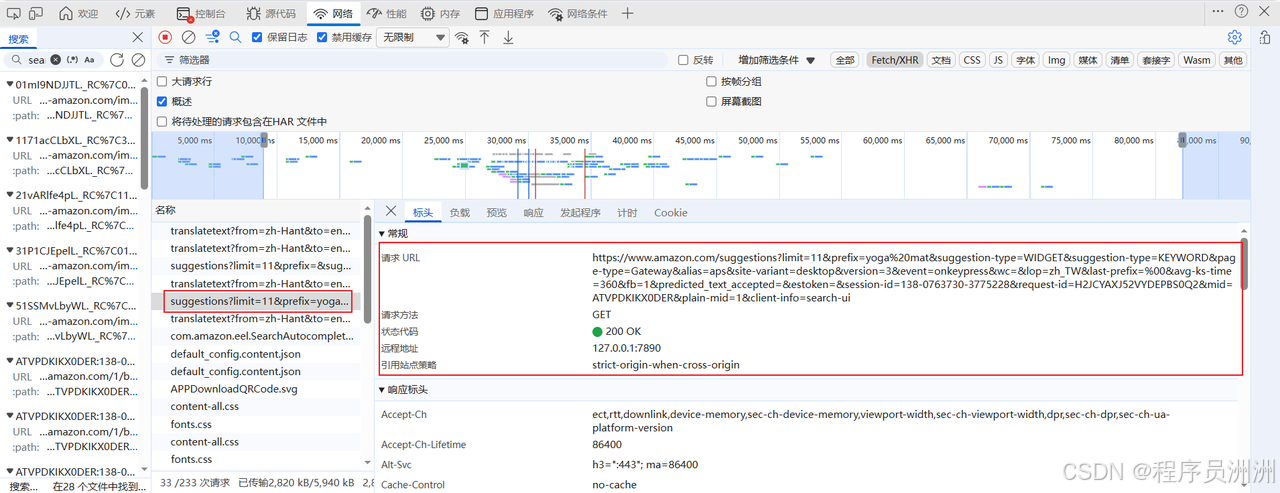
这里需要重点分析两个维度:请求参数(Params/Payload)和响应结构。 点击状态码为 200 的关键请求,查看 Headers 面板中的请求 URL 和 Query String Parameters。以一个典型的亚马逊搜索建议接口为例,其请求 URL 通常包含以下关键参数:k(关键词)、crid(搜索会话标识)、sprefix(关键词前缀)和 page(分页页码)。请求头中最重要的字段包括 User-Agent(必须模拟真实浏览器)、Accept-Language(建议设置为 en-US 以获取英文内容)和 Referer(来源页 URL,建议设为亚马逊主站以提高可信度)。
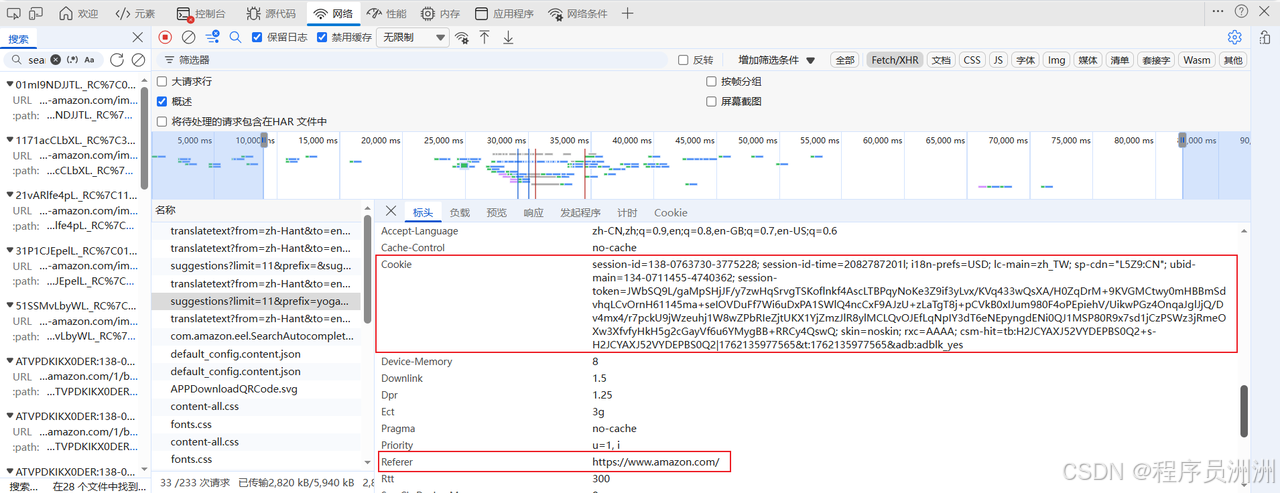
其中,Cookie 是亚马逊反爬系统最为敏感的检测维度之一。 亚马逊通过 Cookie 中的 session-id、ubid-main 等字段追踪用户会话的连续性。如果 Cookie 缺失或异常,平台很容易识别出请求来自程序而非真实用户。因此在编写爬虫时,建议维护一个稳定的 Cookie 池,可以通过先访问一次亚马逊首页来获取初始 Cookie,然后再携带这些 Cookie 访问具体的搜索接口。
响应数据的解析。 亚马逊的接口响应通常是 JSON 格式或嵌在 HTML 中的 JavaScript 变量。常见的提取方式有两种:对于 JSON 响应,使用 Python 的 json 或 jsonpath 库直接解析;对于 HTML 响应,使用 Beautiful Soup 配合 CSS 选择器提取目标元素,常见的 CSS 选择器包括 span.a-size-medium.a-color-base.a-text-normal(商品标题)、span.a-price-whole(整数价格)和 span.a-icon-alt(星级评分)。
3.3 配置 AI 模型
OpenClaw 本身不自带模型,所以还需要给它接一个"大脑"。像 OpenAI、Claude、Kimi、DeepSeek 这些模型都可以,具体选哪一个,看你自己的使用习惯和稳定性要求就行。在这套流程里,模型的主要作用不是"写内容",而是负责理解你的自然语言指令,把任务拆开,然后调用后面的 Skill 去执行。
如果你想使用海外模型(比如 OpenAI 或 Claude),网络环境会直接影响调用稳定性。高频请求和长连接场景下,一旦不稳定,就容易出现超时或失败。如果你本身也在使用 ChatGPT 或 Claude,配置静态 ISP 住宅 IP 会更合适。一方面可以降低 API 调用的延迟和失败率,另一方面也能减少网页端的"降智"和频繁验证问题。
我自己这边用的是 kookeey 的静态住宅isp,它和普通代理最大的区别在于,官方会给一份独享承诺书,保证在使用期间不会被二次分配,这在底层避开了多账号关联带来的风险。
还有一个很实用的点,就是它支持按业务场景分配 IP。比如在购买时选择ChatGPT,系统会优先匹配近期没有跑过同类业务的资源,从而降低被平台识别或触发风控的概率。
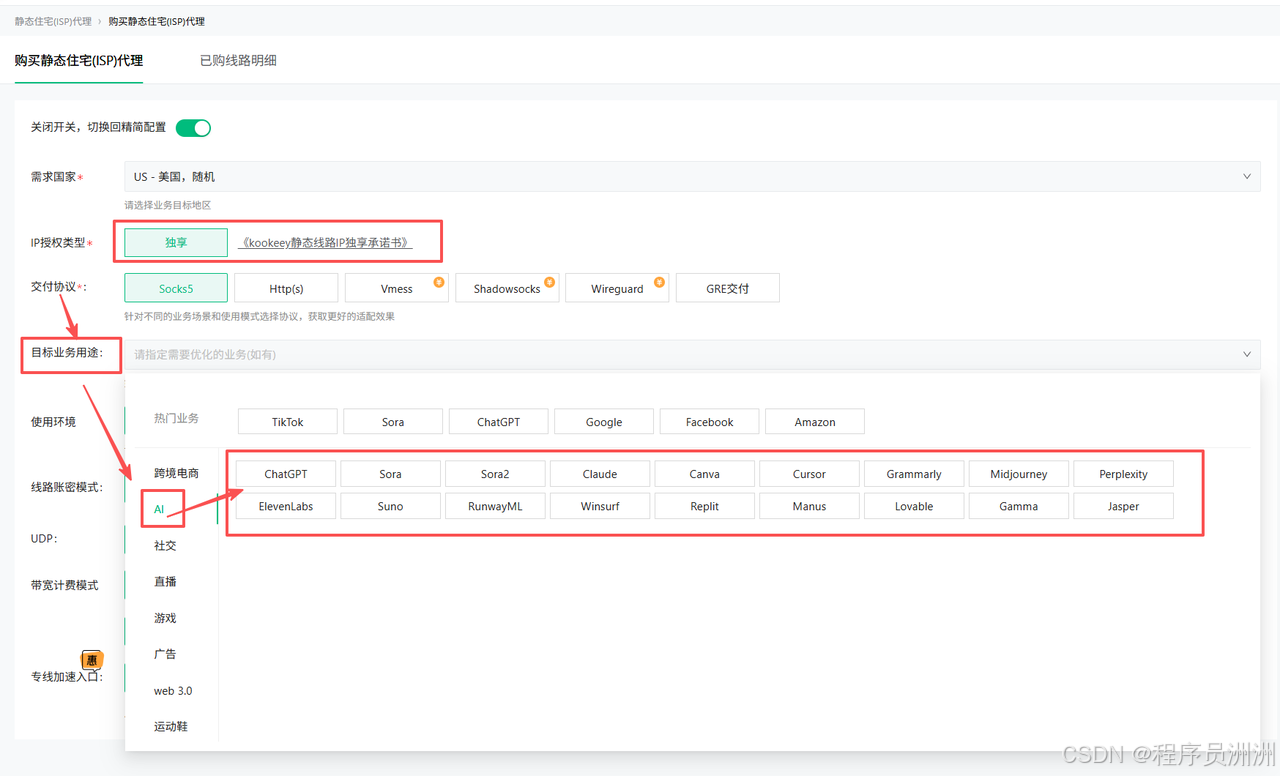
3.4 封装为 OpenClaw 可调用的技能
基于上面的分析,我们下一步就可以将这样的步骤封装为 OpenClaw 可以理解和调用的 Skill。这样做的好处是:Agent 可以通过自然语言指令触发爬虫执行,无需每次手动运行脚本;爬虫的执行结果可以自动流转到后续的分析步骤;整个流程可以被持久化记录和复现。
打开Openclaw页面,把我们刚刚分析得出的结论和整体的工作流告诉Openclaw,这里是我分析出来的需求和工作流,可供参考:
cpp
请你编写一个用于采集亚马逊商品数据的openclaw技能skills。核心目标是模拟真实用户从Amazon.com搜索并浏览商品列表的行为,稳定地获取商品名称、价格、评分、评论数和ASIN等关键信息,并将结果保存为CSV文件。
首先,为解决地域限制和反爬问题,你需要通过调用kookeey的动态代理API来获取并轮换代理IP。根据其API规范,你需要构建一个包含必要参数的GET请求URL。一个基础的获取代理列表的请求示例格式可能为:https://www.kookeey.com/pickdynamicips?accessid=ACCESSID&signature=签名&ts=时间戳&n=所需IP数量&p=代理类型&g=地区代码&format=4&dl=\r\n。其中,accessid、signature(基于密钥和参数通过HMAC-SHA1算法生成)和ts是认证核心。关键格式参数format=4和dl=\r\n决定了API返回的代理列表是明文文本格式,且每个代理IP地址之间以回车换行符分隔,这非常便于脚本直接读取和分割成IP列表。请务必查阅kookeey最新API文档以确认所有参数(如t=2,auth=pwd等)的准确值。脚本应首先调用此API获取一批可用的代理,并在后续对亚马逊的请求中轮流使用这些IP,以模拟不同地理位置的访问并有效规避IP封禁。
采集策略是针对给定关键词列表(例如 ["yoga mat", "resistance bands"])各采集其搜索结果的前3页。要实现这一点,你需要先手动分析亚马逊的搜索接口。请打开浏览器开发者工具,在Network面板中观察执行搜索时产生的网络请求,找到那个返回商品列表数据的核心接口。重点分析其URL中的查询参数,例如k参数对应URL编码后的关键词,分页则由page或s等参数控制,同时接口可能包含session-id、crid等用于会话和请求追踪的动态参数,你需要理解并模拟这些参数的构造规律。
脚本的核心在于高度模拟真人浏览。这意味着必须正确设置HTTP请求头。User-Agent需设置为一个常见的现代浏览器标识,这是你的"数字指纹"。Cookie需要被妥善管理并在会话中保持,以维持与网站的登录和偏好状态。Referer头则应设置为亚马逊的域名,使每次搜索请求看起来都从站内页面自然跳转而来。正确设置这些头部信息是绕过网站基础反爬机制的关键。
此外,在连续请求之间,必须插入time.sleep(random.uniform(1, 3))这样的随机延迟。这个步骤至关重要,它模拟了人类操作的停顿,能有效避免因请求频率过高而触发网站的风控系统导致IP被封。在数据解析上,应优先尝试从接口的JSON响应中提取结构化数据,并准备好基于HTML解析的备用方案以确保鲁棒性。
最后,请将采集到的所有数据规整地保存到amazon_products.csv文件中,并确保代码包含完善的异常处理逻辑。请基于以上要求,生成完整、可运行的技能skills,完成后我将告诉你线路信息,从里面提取授权。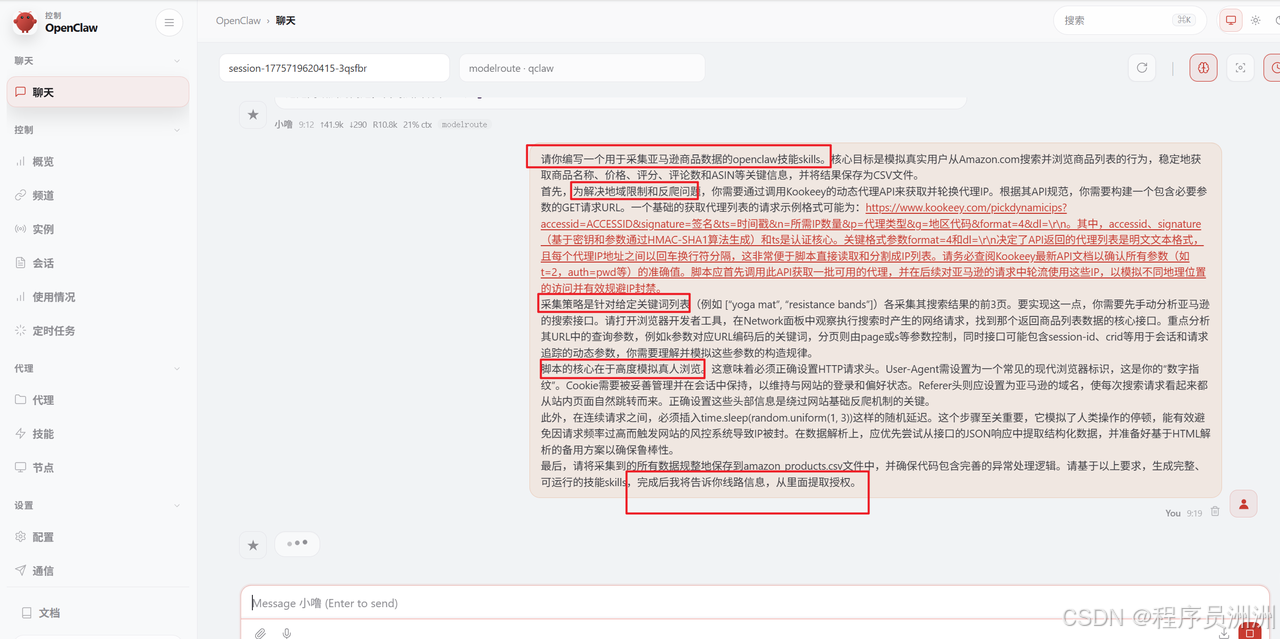
发给openclaw后,他就会自己开始封装 Skill ,skills核心是定义自然语言接口和参数映射。 一个典型的 Skill 结构包含三个部分:描述文件(SKILL.md)用于说明这个 Skill 能做什么、接受什么参数、输出什么结果;执行脚本负责接收参数、调用爬虫逻辑并返回结构化结果;配置文件用于定义环境变量(如 kookeey API 凭证)。
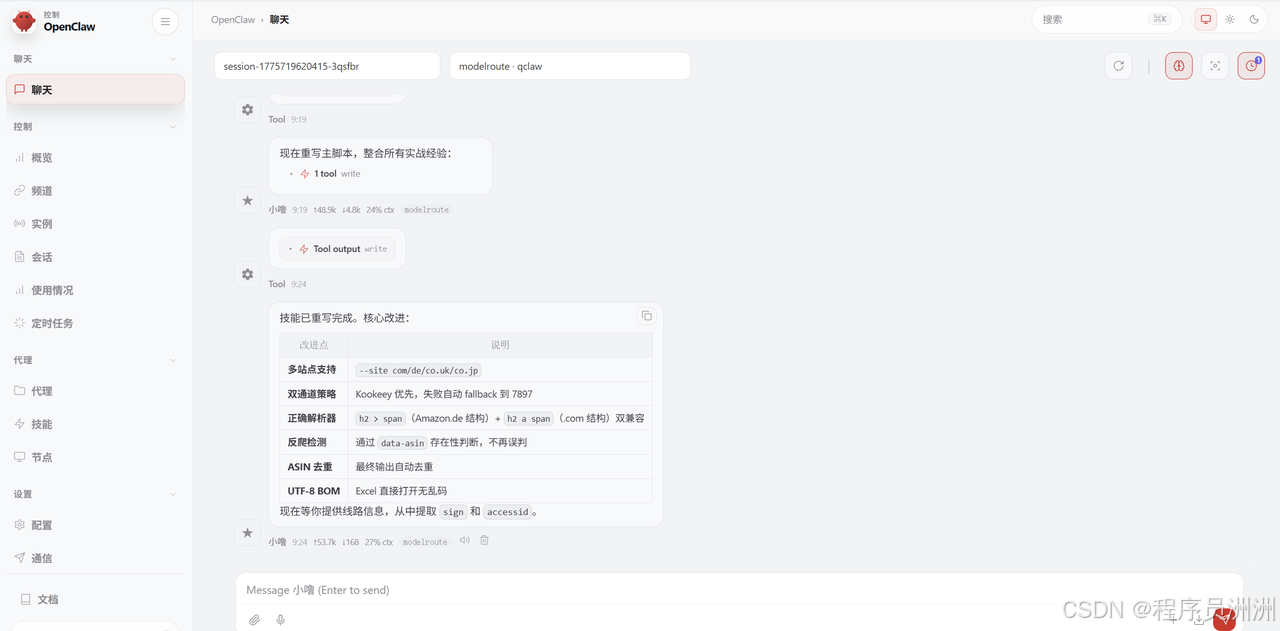
最后,我们将之前搜集的连接参数告诉他,让他帮我们配置好环境变量。
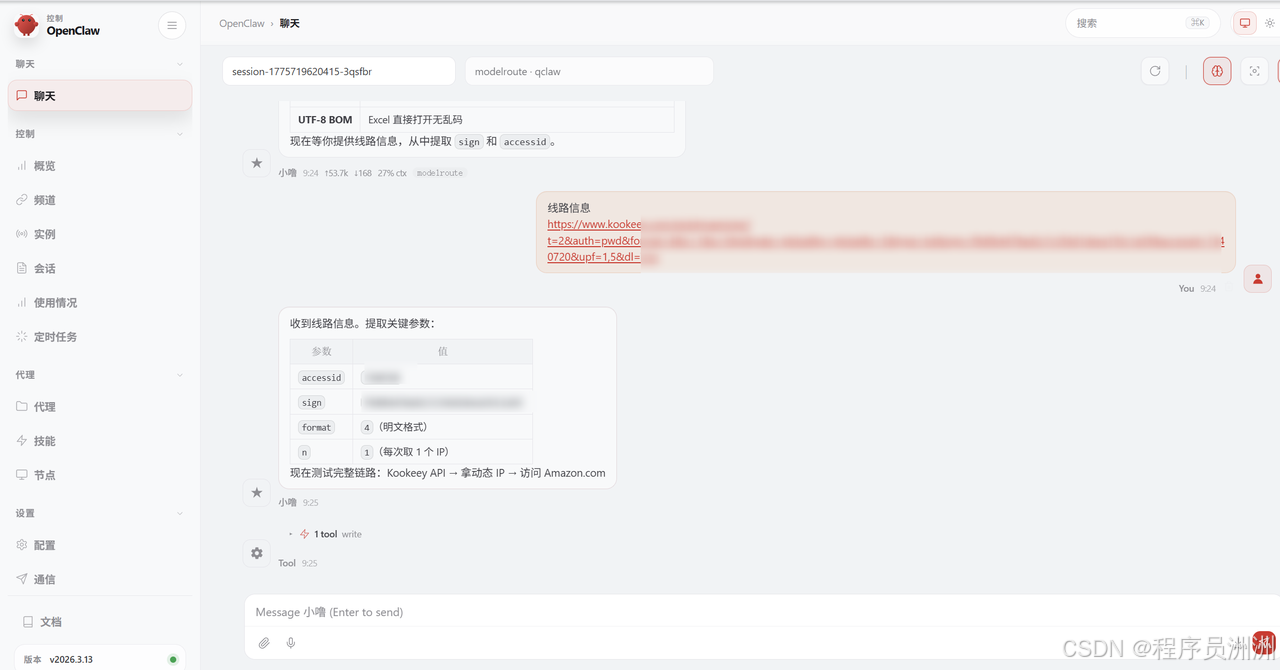
配置好后就可以正式运行了,可以试试类似"帮我爬取亚马逊德国站厨具类目前 5 页数据"的指令。
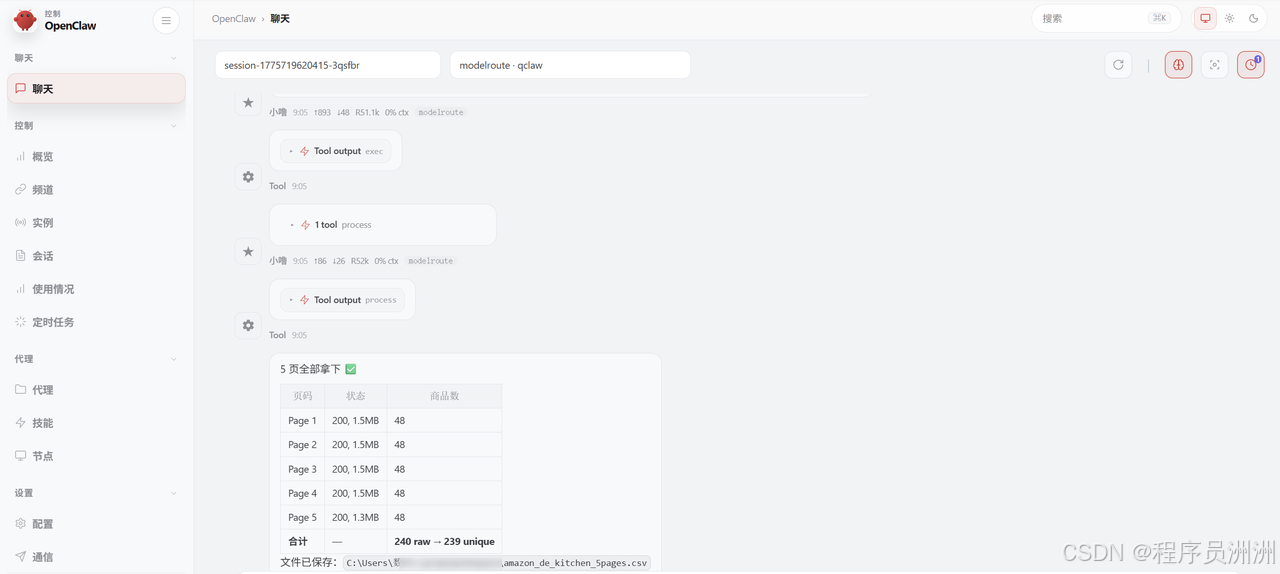
Openclaw就会自动解析出关键词(厨具)、目标站点(德国)、分页数量(5),将这些参数传递给爬虫脚本,然后接收脚本的 JSON 输出,再进入下一步的数据分析流程。这种设计让整个系统的使用门槛降低到了"发送一条消息"的级别。
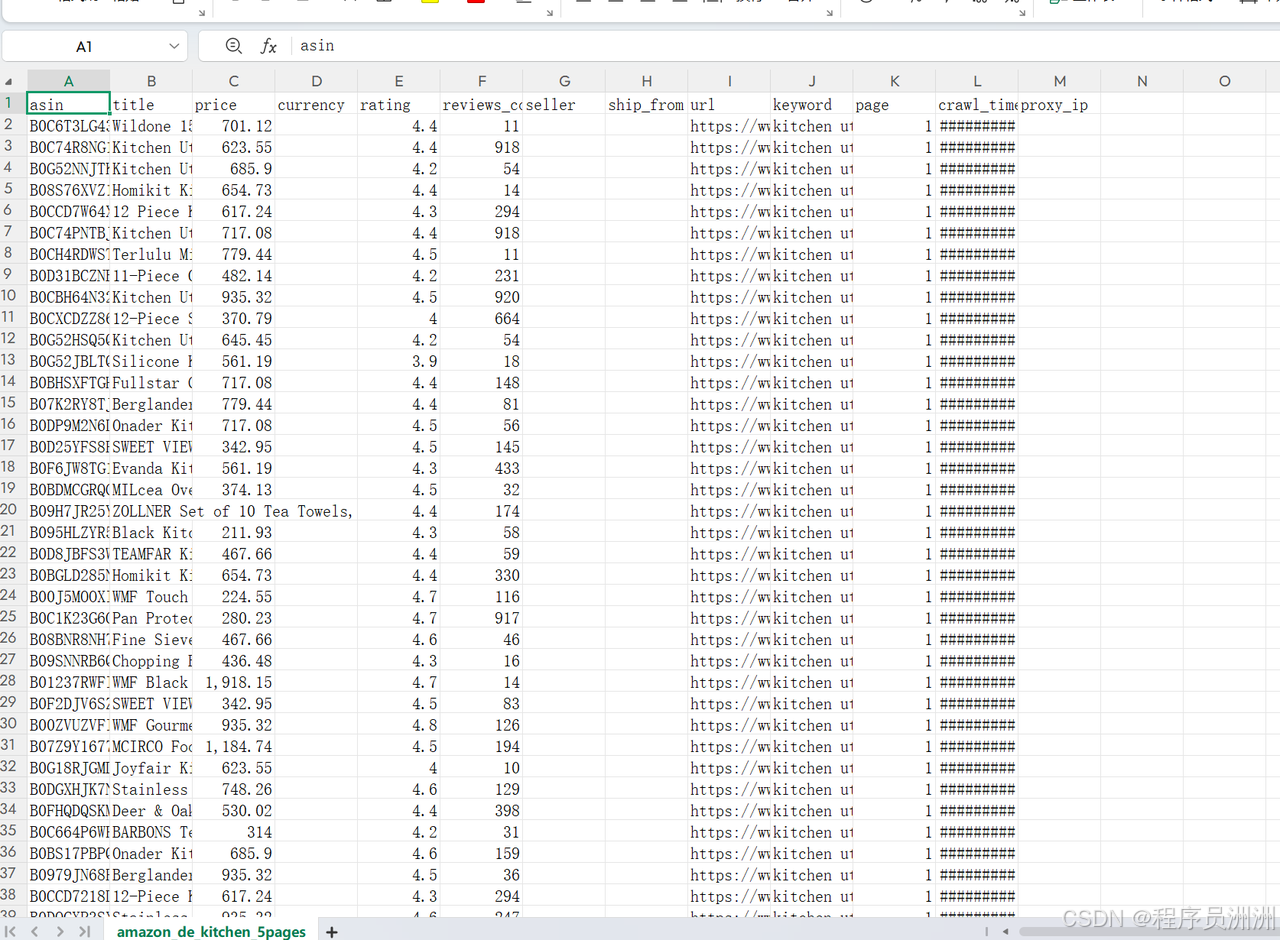
3.5 数据结构化分析与洞察提炼
采集到原始商品数据后,下一步我们可以让OpenClaw将零散的商品记录转化为有商业价值的选品建议。
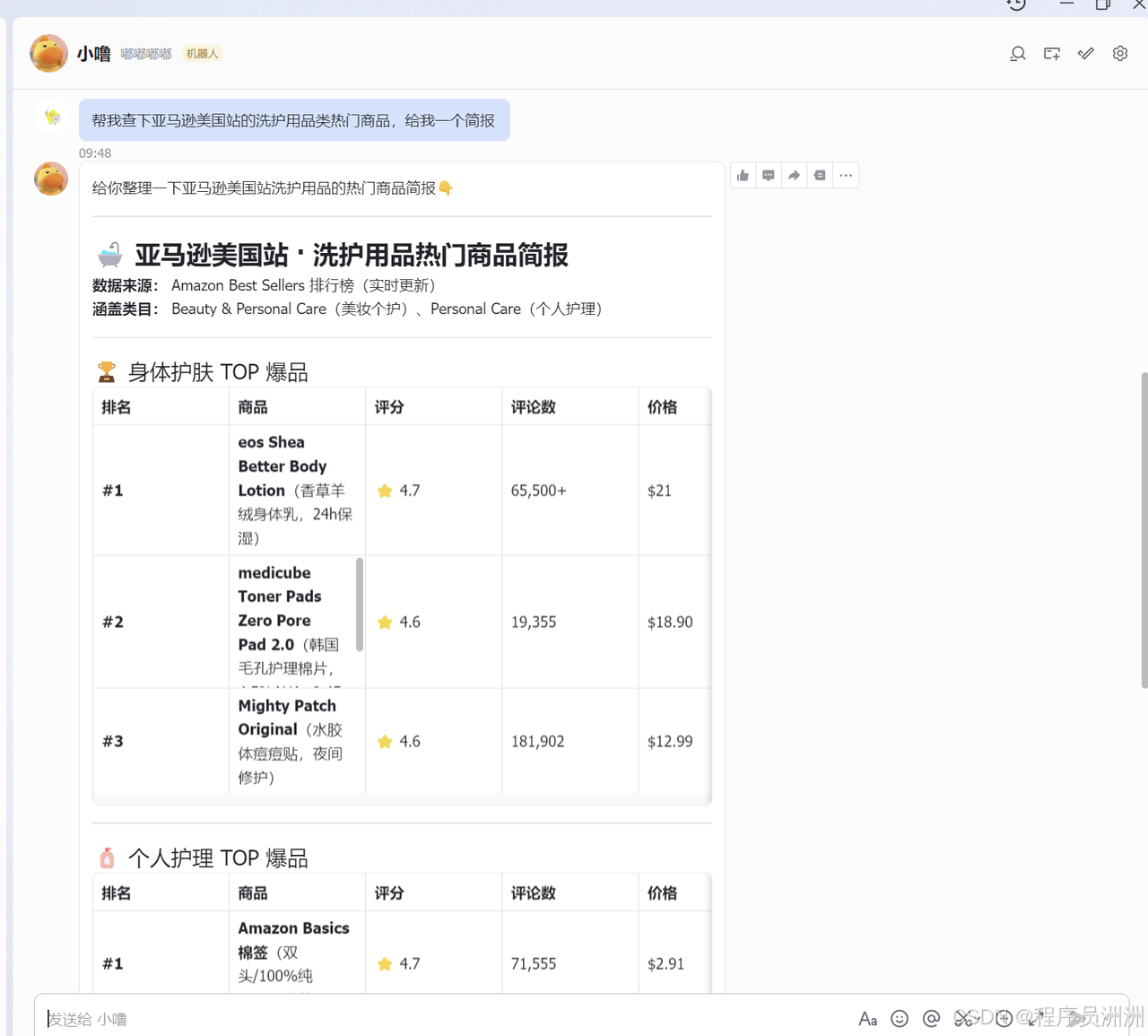
在采集概况方面,OpenClaw完整记录了数据采集的元信息。本次针对"kitchen utensils"、"cooking tools"、"kitchen gadgets"三个关键词各采集了5页,累计15页的商品列表页,共获得732个原始商品条目,经过去重后得到639个独立商品。

在品牌分布上,OpenClaw自动识别并统计了商品品牌。本次数据显示,TOP 10品牌中以Homikit、Berglander等品牌为主,其代表产品多为硅胶或不锈钢厨具套装。
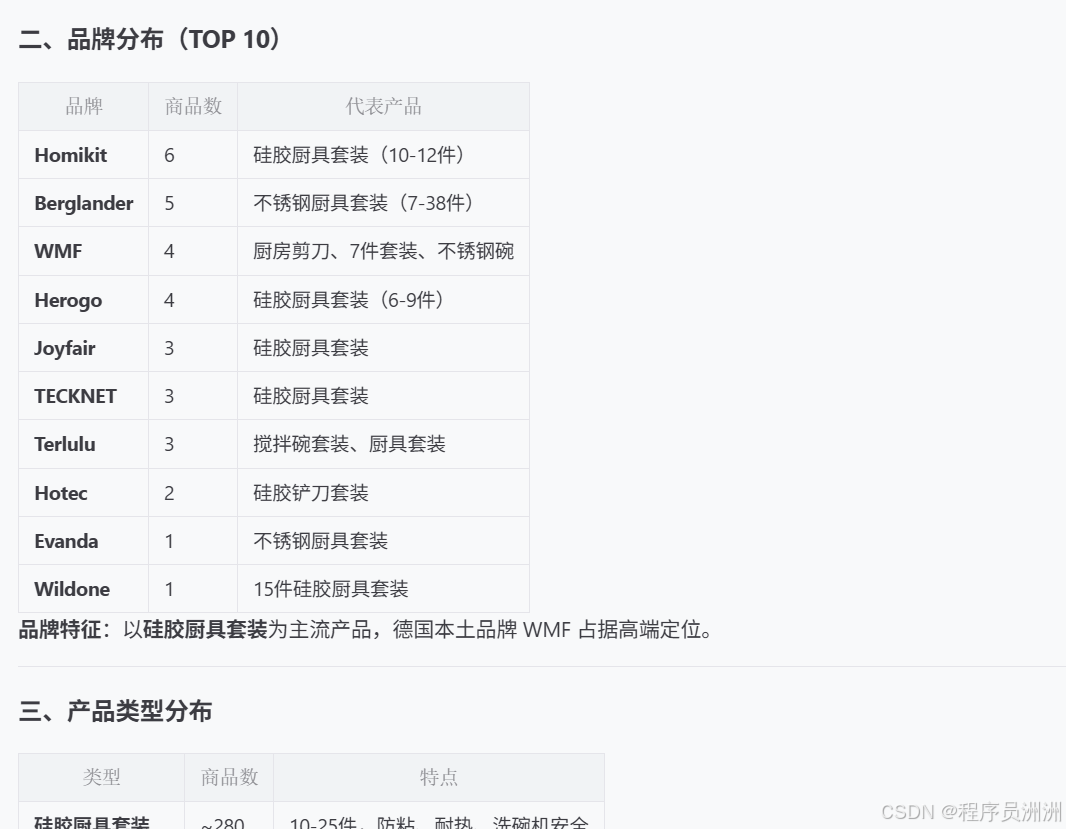
产品类型分布维度对市场品类结构进行了清晰梳理。数据显示,硅胶厨具套装是绝对主流,商品数占比最高,其卖点集中在防粘、耐热和洗碗机安全;不锈钢厨具套装定位更耐用、高端;木质厨具套装则主打环保概念。此外,市场还存在相当数量的单项工具、收纳配件及锅具套装,展现了品类的多样性。
评分分布反映了市场的整体口碑水平。约75%的商品评分集中在4星,平均评分约4.0星,表明该细分市场整体口碑良好。

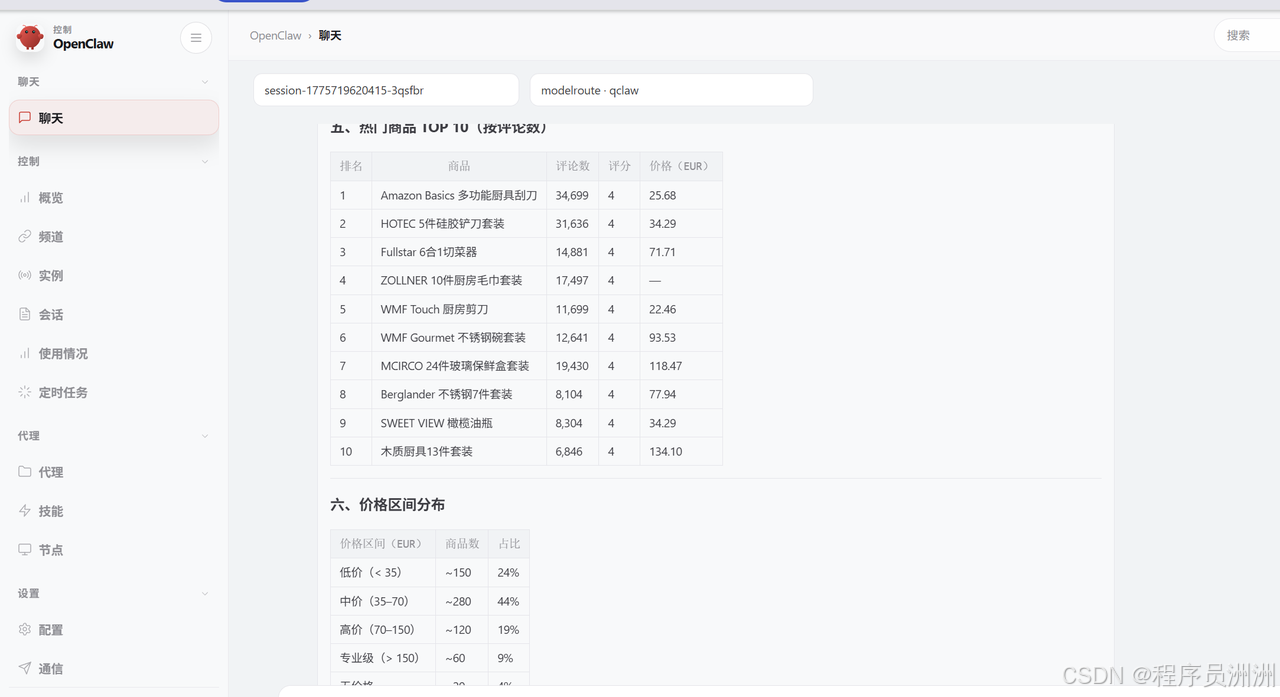
热门商品排名(按评论数)直接揭示了市场的爆款和用户关注焦点。排名前列的商品,如Amazon Basics多功能刮刀、HOTEC硅胶套装等,拥有数万条评论,是巨大的流量入口。分析其价格、评分与海量评论数的关系,能为打造潜在爆款提供关键定价与功能参考。
价格区间分布刻画了市场的价格带格局。主流商品价格集中在35-70欧元的中价区间,占比达44%,这可能是家用入门级厨具套装最密集的竞争地带。同时,工具也清晰展示了低价走量、高价专业等不同细分价格区间的市场容量。
最后,OpenClaw能基于Kookey提供的地域站点数据提炼出本地化特色洞察。针对德国站的分析发现,硅胶材质和套装化是显著趋势;品牌竞争格局分散,除WMF外少有占主导地位的品牌;且评论数量与价格呈现一定的负相关关系。这些洞察紧密结合了本地消费习惯(如对"洗碗机安全"的重视)和语言特征(德语关键词),为制定本土化运营策略提供了关键依据。

第四章 飞书渠道集成:实现对话即服务
4.1 为什么选择飞书作为协同入口
飞书是字节跳动推出的企业协作平台,在国内跨境电商圈和科技创业公司中有大量用户基础。相比其他渠道,飞书具有以下显著优势:消息格式丰富,支持文本、图片、卡片、按钮等元素,可以承载复杂的分析报告和数据可视化内容;开放生态完善,提供 Chatbot API 和 Webhook 机制,支持与第三方系统深度集成;多端同步稳定,PC 和移动端体验一致,适合随时随地查看数据任务状态;通知触达及时,分析结果可以通过飞书消息即时推送给相关人员。
将飞书与 OpenClaw 打通后,整个数据采集与分析系统的使用门槛降低到了"发消息"的级别------任何会用飞书的人都能够驱动一个强大的跨境电商数据采集 Agent。
4.2 飞书 Chatbot 配置与 OpenClaw 对接
飞书 Chatbot(自定义机器人)是实现消息收发的基础。以下是详细的配置步骤。
第一步:创建飞书自建应用。 登录飞书开放平台(open.feishu.cn),进入"开发者后台",创建一个自建应用。填写应用名称(如"亚马逊数据助手")、应用描述和图标。
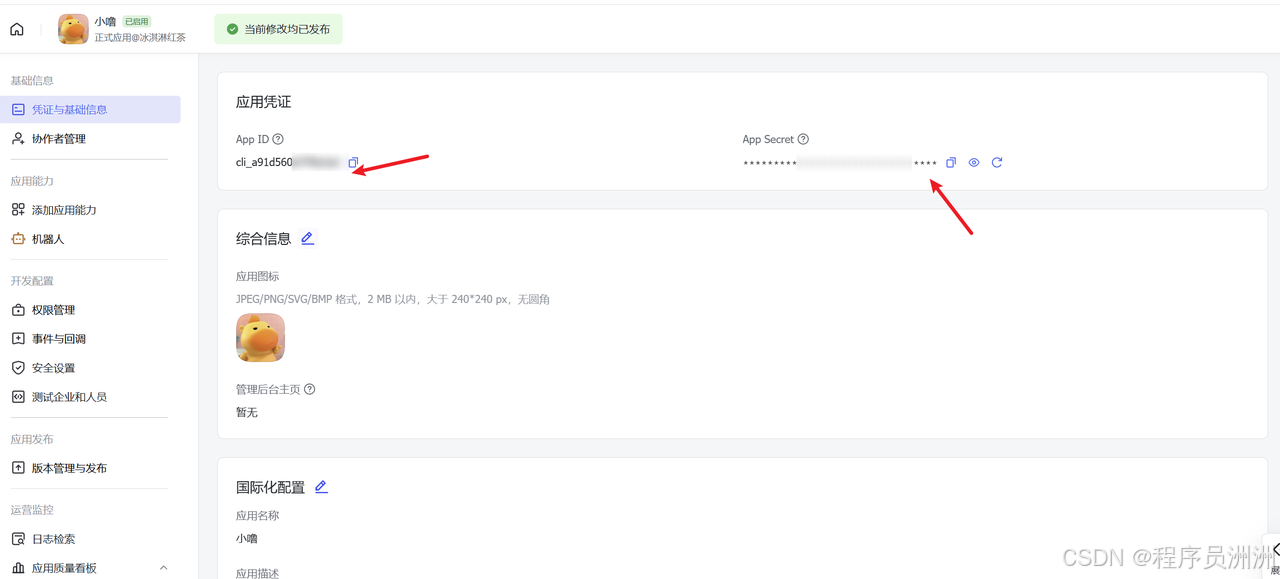
在应用的"凭证与基础信息"页面获取 App ID 和 App Secret,这两个值是后续调用飞书 API 的身份凭证。
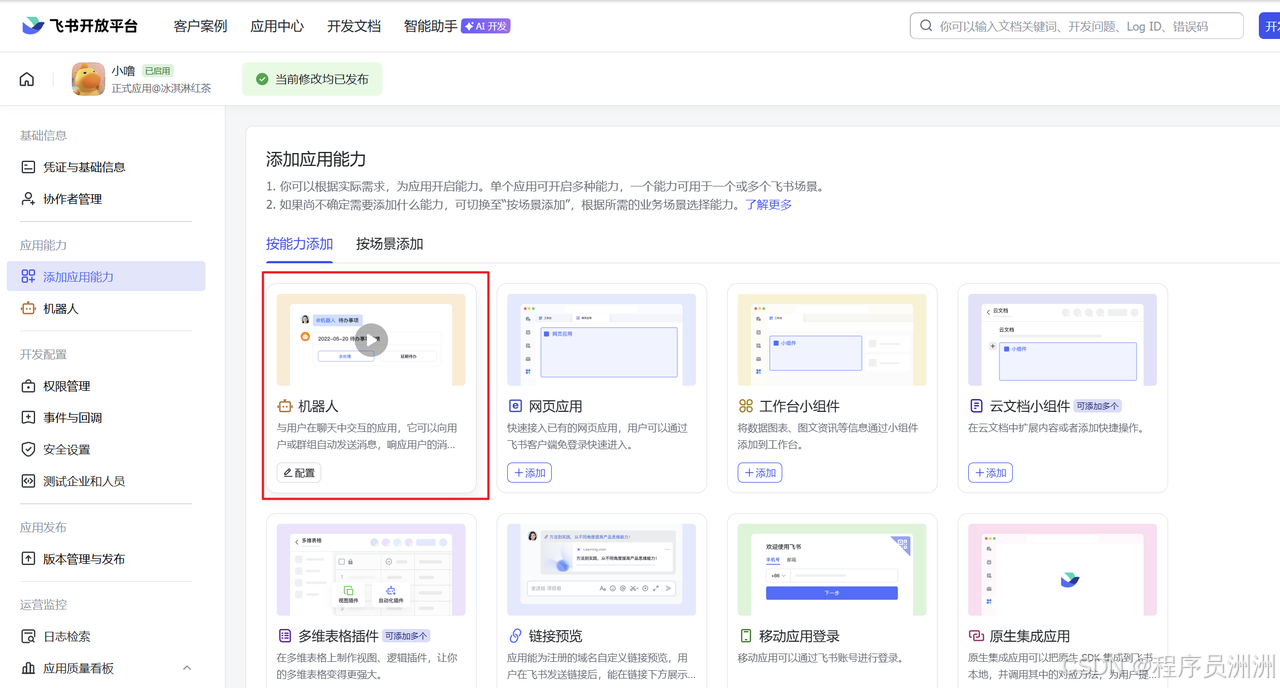
第二步:添加机器人能力。 在应用配置页面的"添加应用能力"中,找到"机器人"选项并启用。启用后,应用就具备收发消息的能力了。
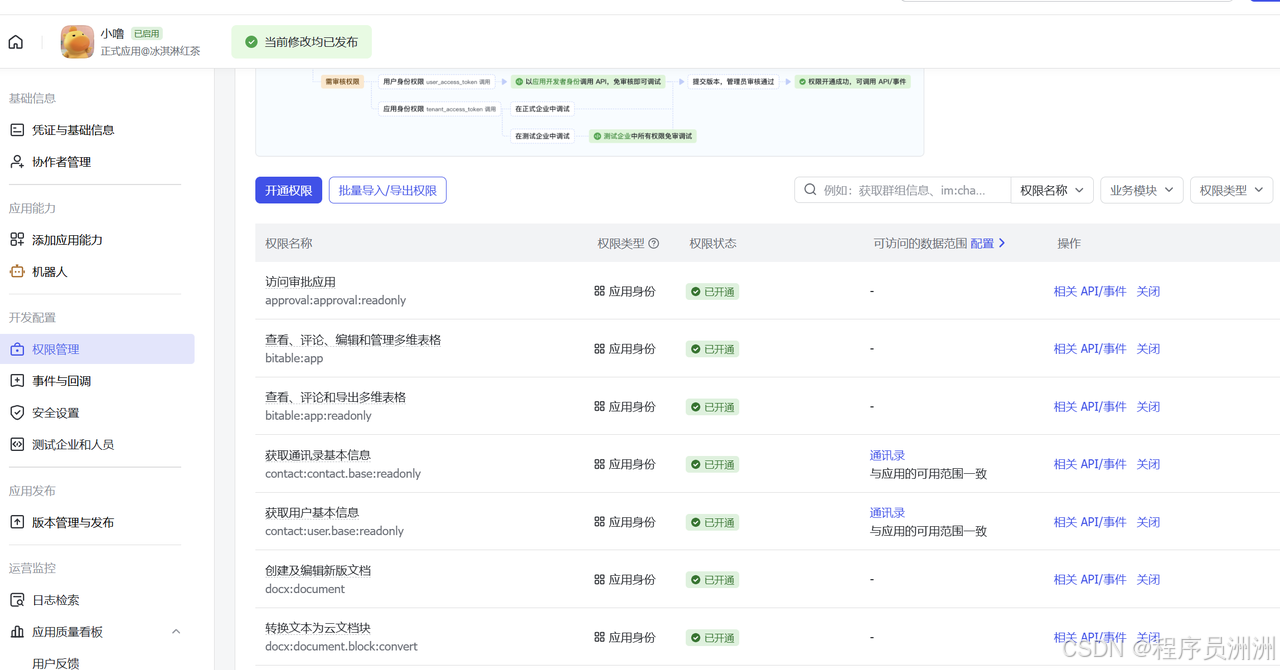
第三步:配置权限。 机器人需要获得相应的权限才能读取和发送消息。在"权限管理"页面,申请以下权限:im:message(读取和发送消息)、im:message.group_at_msg(接收群聊中 @ 机器人的消息)以及 im:chat(获取群组信息)。权限申请后,需要发布应用版本才能生效------如果是企业自建应用,管理员审批通过即可;如果是个人开发者,可以先将应用添加为测试版本。
第四步 :在 OpenClaw 中配置飞书插件。 OpenClaw 的飞书集成通过插件(Plugin)机制实现。在 OpenClaw 的配置文件(通常为 openclaw.json)中,找到 plugins 配置项,添加飞书插件并填入刚才获取的 App ID 和 App Secret,同时指定机器人的目标会话(可以是单聊会话或群聊会话)。
第五步:验证连通性。 完成上述配置后,在 OpenClaw 中执行一条测试消息,确认飞书能够成功接收。也可以在飞书客户端中 @ 机器人发送一条简单消息(如"你好"),观察 OpenClaw 是否正确响应。
以下是与 OpenClaw 在飞书中完成一次完整数据采集任务的交互示例:
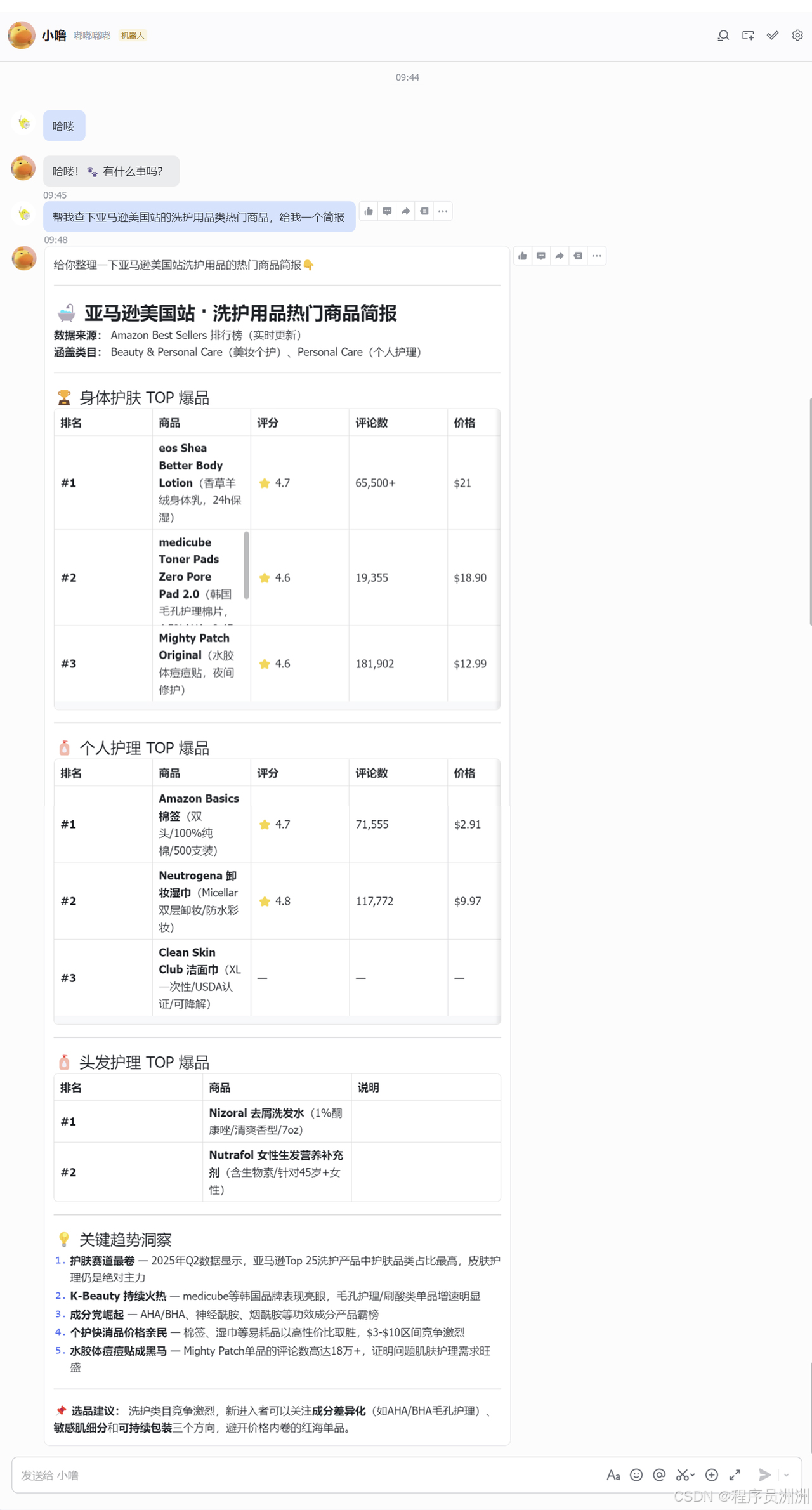
总结与展望
本文从实践出发,完整梳理了一套基于 OpenClaw + kookeey + 飞书的跨境电商数据采集与协同分析方案。
整套方案的核心思路,是利用 OpenClaw 作为 Agent 编排层,将原本分散在爬虫脚本、AI 分析工具和消息渠道中的能力串联为一个统一的自动化工作流;借助 kookeey 高质量的动态住宅代理解决亚马逊反爬的核心痛点,确保数据采集的稳定性和数据视角的真实性;通过飞书渠道实现任务的下发、跟踪和结果接收,将复杂的技术流程转化为自然语言交互体验。
这套方案适用于多种跨境电商场景,包括但不限于:
- 竞品动态监控:持续追踪目标品类的价格、排名和销量变化
- 选品调研:在新品立项前,通过数据验证市场容量与竞争强度
- 价格策略制定:基于全品类价格分布,制定更具竞争力的定价方案
- 用户反馈分析:利用 AI 深度解析评论内容,挖掘用户真实需求与痛点
如果你也想快速复现这套流程,不妨先领取 kookeey 给我们新用户准备的免费体验福利:
200MB 动态住宅流量 + 100MB 移动代理流量 + ¥288 体验券
这部分体验额度,已经足够你把整套自动化流程完整跑通好几遍。
与其停留在"看懂了"的阶段,不如亲自上手试一次。只有真正跑起来,你才能体会到那种"发个关键词就能搞定选品"的爽感。
👉 点击领测试额度:**https://www.kookeey.com/?aff=92790222**
