前言
从去年年初开始,我就一直陆陆续续的在搞我的小落同学:希望可以把它做成一个数字版的自己。到目前为止,小落同学都是在阿里云的99元一年的VPS上跑的,目标硬件是超低配服务器,所有的模型都只能选轻量级的、纯CPU推理的方案,同时把ASR、TTS、LLM都是用公网上的。
但最近我在思考一个问题:能不能升级一下路线?
如果把目标硬件换成消费级GPU,12GB显存左右(比如 RTX 3060 12GB、RTX 4070 Ti),那能选方案就完全不一样了。不止能跑 ASR、TTS,还能跑 3D 人物avatar(目前的小落同学用的是live2d的技术方案)。
这篇文章就是记录一下,12GB 显存的消费级 GPU 上,怎么配一套完整的小落同学虚拟人方案。
一、硬件准备
1.1 推荐配置
12GB 显存的消费级 GPU,现在有几个选择:
| GPU | 显存 | 价格区间 | 备注 |
|---|---|---|---|
| RTX 3060 | 12GB | 二手 1500-2000 元 | 消费级 12GB 标杆,性价比最高 |
| RTX 4070 Ti | 12GB | 二手 3000-4000 元 | 比 3060 强约 40% |
| Intel Arc B580 | 12GB | 新卡 1200-1500 元 | 2026 年性价比最高的入门级新卡 |
我目前的初步想法是:RTX 3060 12GB 是最具性价比的选择。二手市场多,价格稳定,而且 12GB 显存在 LongCat Avatar 的文档里明确写了是"最低配置"。

1.2 显存分配预算
12GB 显存怎么分配?大概是这样:
| 模块 | 显存需求 | 推荐模型 |
|---|---|---|
| ASR | 1-2 GB | FunASR / Paraformer |
| TTS | 1-2 GB | Kokoro |
| LLM | 4-6 GB | 7B 模型(需量化到 INT4,或者直接使用公网上的) |
| Avatar | 残余显存 | LongCat / LAM |
如果 LLM 用 7B 模型量化到 INT4,大概需要 4-6GB。这样 12GB 显存刚好够用,如果LLM用公网接入的话,可以再考虑给小落同学加一些其它的功能,或者给选个更好的ASR、TTS模型。
二、ASR 方案(语音识别)

2.1 推荐:FunASR + Paraformer
之前我们发过一篇 OddASR 的文章,详细介绍了 Paraformer 模型,在我的OddASR项目里也已经完整集成了此方案。简单说:
- 模型:Paraformer-zh(中文)+ Paraformer-en(英文)
- 中文效果:准确率基本可认为 100%
- 显存:~2GB(可以纯CPU跑)
- 速度:实时
- 特色:支持流式识别,中文效果远超 Moonshine
bash
# 安装 OddASR
pip install oddasr
# 启动服务
oddasr-server
# 打开测试界面
# http://localhost:9002经过我在小落同学上的实际测试,Paraformer 在中文上的效果远超 Moonshine。Moonshine 虽然参数少、延迟低,但中文识别是弱项。如果你做中文项目,一定要用 Paraformer。
2.2 备选:FunASR-SenseVoice
如果需要更低的延迟和更好的噪声鲁棒性:
- 模型:SenseVoice
- 特点:更强的噪声抑制
- 场景:嘈杂环境下的语音识别
2.3 GPU备选:Whisper Large v3 Turbo
如果需要外语支持:
- 参数量:809M
- 显存:~6GB
- 速度:6x faster than Large v3
- 语言:99+
2.4 轻量备选:Moonshine(CPU 方案)
如果显存特别紧张,可以切回纯 CPU 方案:
- Tiny:27M 参数,26MB,延迟 34ms
- 特点:树莓派都能跑
三、TTS 方案(语音合成)
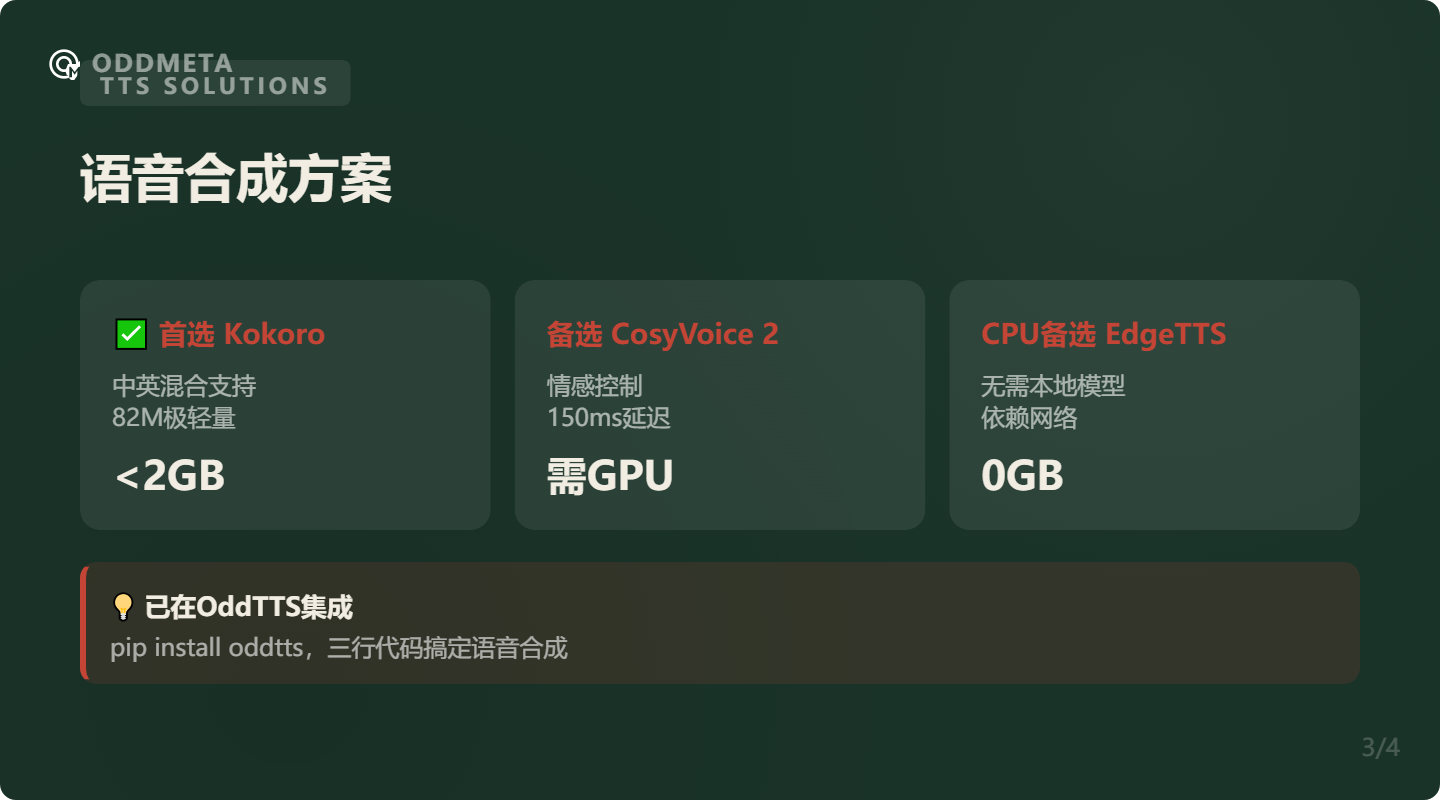
3.1 推荐:Kokoro-82M
Kokoro 是我现在 OddTTS 项目已经集成的模型,支持中英混合:
- 参数量:82M
- 显存:< 2GB(CPU也能跑)
- 速度:实时或更快(十年前老笔记本3.5秒合成11字)
- 音色:8 种内置音色(美英/英英、男/女)
- 中英混合:通过创建两个 pipeline 实现完美中英混合
- License:Apache 2.0,免费商用
python
# 只需要简单三行代码搞定语音合成
client = OpenAI(api_key="dummy", base_url="http://localhost:9001/v1")
response = client.audio.speech.create(model="oddtts-1", input="中英混合文本", voice=voice_id)
response.write_to_file("output.mp3")OddTTS 项目里已经集成了 Kokoro,直接 pip install oddtts 就能用,而且支持 OpenAI 兼容接口。
3.2 备选:CosyVoice 2
如果需要情感控制和更多语言:
- 参数量:0.5B
- 延迟:150ms(streaming mode)
- 语言:中英日韩(包括方言)
- 特色:情感控制、细粒度控制
- 注意:需要 GPU
3.3 备选:Fish Speech V1.5
质量最高的开源 TTS 之一:
- 架构:DualAR
- WER:3.5%
- 语言:多语言
3.4 CPU备选:Edge TTS
如果不想用模型,可以用 Edge 浏览器的在线 TTS:
- 特点:无需 GPU,纯云端
- 延迟:依赖网络
四、3D Avatar 方案
这是最关键的部分。之前低配服务器跑不了 avatar,现在 12GB 显存可以了。
4.1 推荐:LongCat Avatar
LongCat 是一个开源的 AI talking head 方案,ComfyUI 工作流:
- 最低配置:RTX 3060 12GB
- 生成时间:5 秒视频约 4 分钟(3060)
- 质量:commercial-grade
- 特色 :
- 完美 lip-sync
- 自然表情
- 无时长限制
- 无限自定义角色
- 完全本地运行
安装和使用需要看 LongCat 官方文档,核心是用 ComfyUI。
4.2 备选:LAM(Large Avatar Model)
阿里 SIGGRAPH 2025 的工作:
- 特点:一张照片生成 3D 头像
- 速度:A100 上 562.9 FPS,手机 110+ FPS
- 渲染:跨平台(Windows、Linux、Mac)
- License:Apache 2.0
bash
git clone https://github.com/aigc3d/LAM.git
cd LAM
# 需要 CUDA 12.1+4.3 高配备选:LPM 1.0
目前最强的开源方案,但参数量大:
- 参数量:17B
- 延迟:0.35s(3x 快于竞品)
- 特色:full-duplex 对话、lip-sync、情感、姿态
- 限制:12GB 显存可能跑不动
4.4 研究方向:AGORA
Google 的论文方案:
- 技术:3D Gaussian Splatting + FLAME
- 速度:250fps GPU,9fps CPU
- 限制:目前主要是研究论文
五、Pipeline 设计
5.1 完整流程
用户说话 → ASR(Paraformer) → LLM(7B Qwen) → TTS(Kokoro) → Avatar(LongCat) → 视频输出5.2 模块可选组合
| 组合 | ASR | TTS | Avatar | 显存 |
|---|---|---|---|---|
| 轻量版 | Paraformer | Kokoro | 无 | ~4GB |
| 标准版 | Paraformer | Kokoro | 无 | ~6GB |
| 完整版 | Paraformer | Kokoro | LongCat | ~10GB |
5.3 实际部署建议(中文项目)
- ASR 优先级 :Paraformer > FunASR > Whisper(中文必选 Paraformer)
- TTS 优先级 :Kokoro(已集成) > CosyVoice
- Avatar 优先级:LongCat(最成熟)> LAM
- LLM:用 vLLM 加载 7B 模型,INT4 量化(拟使用公网上的LLM API)
六、注意事项
6.1 量化是必须的
12GB 跑 7B LLM 必须量化:
bash
# INT4 量化示例(vLLM)
llamafactory-cli serve qwen2.5-7b-instruct-awq6.2 Avatar 批量 vs 实时
LongCat 目前主要是批量生成,不是实时。如果需要实时对话:
- 可以先生成音频,再用 avatar
- 或者用 LAM 的实时版本
6.3 中文支持
- ASR:Paraformer 中文效果最佳(本文推荐)
- TTS:Kokoro 中英混合(本文推荐)
- Avatar:LongCat 对语言无限制(只看 lip-sync)
七、总结
12GB 显存的消费级 GPU,也能跑一套完整的虚拟人方案:
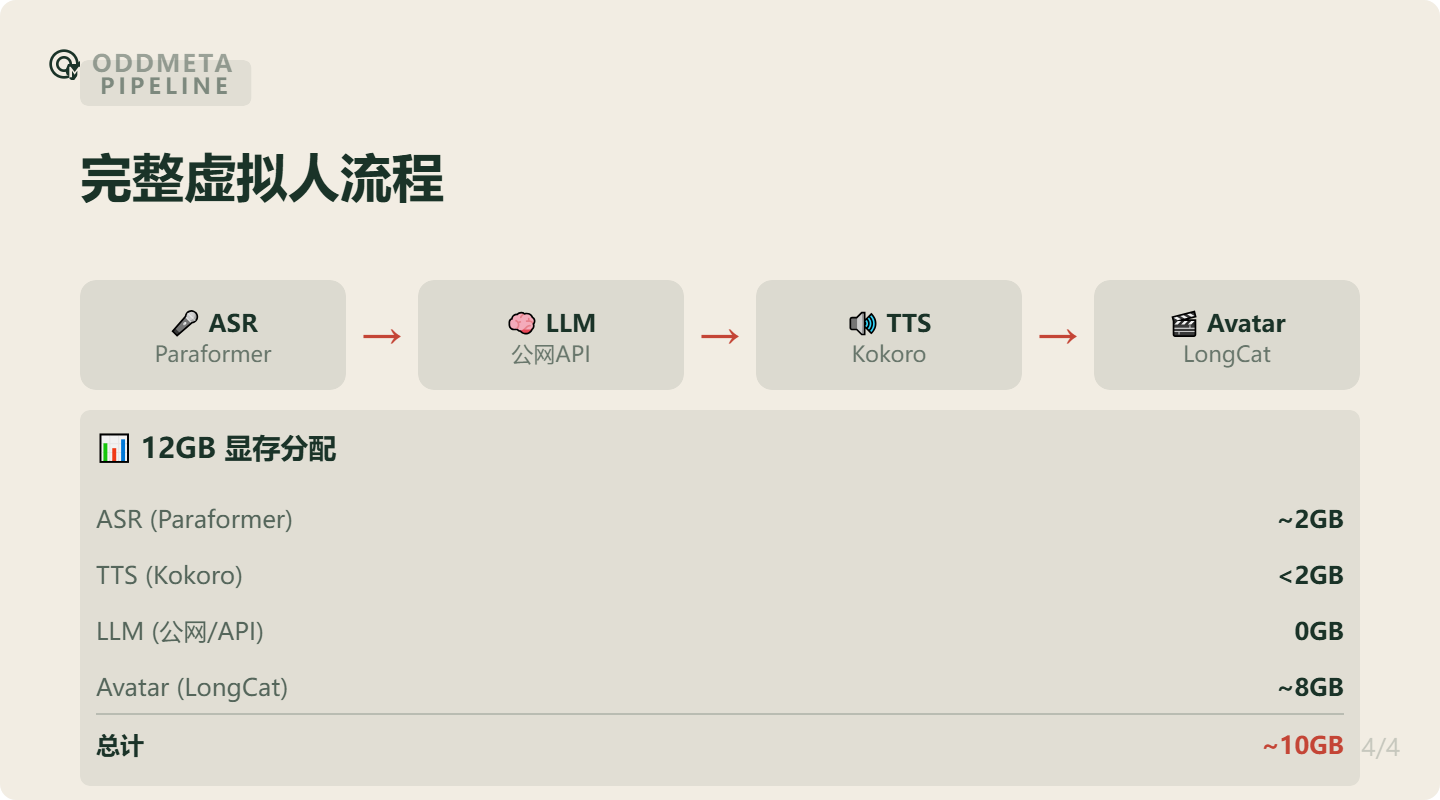
| 模块 | 推荐方案 | 显存 |
|---|---|---|
| ASR | Paraformer-zh | ~2GB |
| TTS | Kokoro-82M | <2GB |
| LLM | Qwen2.5-7B(INT4) | ~4-6GB |
| Avatar | LongCat Avatar | 剩余 |
核心思路是模型量化 + 合理分配显存。如果不追求 3D avatar,纯 ASR + TTS 可以在更低配的机器上跑;如果要上 3D avatar,12GB 是一个门槛,RTX 3060 12GB 是最具性价比的选择。
本方案的核心优势:
- 中文支持:ASR 用 Paraformer(实测准确率接近100%),TTS 用 Kokoro(中英混合)
- 本地运行:全链路本地,无需联网
- 成本低:RTX 3060 12GB 二手 1500-2000 元
这套方案后续会陆陆续续尝试集成到小落同学上,看看实际效果怎么样。也欢迎有经验的各位一起探讨。
相关资源
- OddASR:https://github.com/oddmeta/oddasr
- OddTTS:https://github.com/oddmeta/oddtts
- Kokoro:https://github.com/hexgrad/Kokoro
- LongCat Avatar:https://longcat-video.org/
- LAM:https://github.com/aigc3d/LAM