概述
论文地址:https://arxiv.org/pdf/2402.16124v1.pdf
逼真的人脸三维动画在娱乐业中至关重要,包括数字人物动画、电影视觉配音和虚拟化身的创建。以往的研究曾试图建立动态头部姿势与音频节奏之间的关联模型,或使用情感标签或视频剪辑作为风格参考,但这些方法的表现力有限,无法捕捉到情感的细微差别。它们还要求用户手动选择风格源,这往往会导致应用不自然。
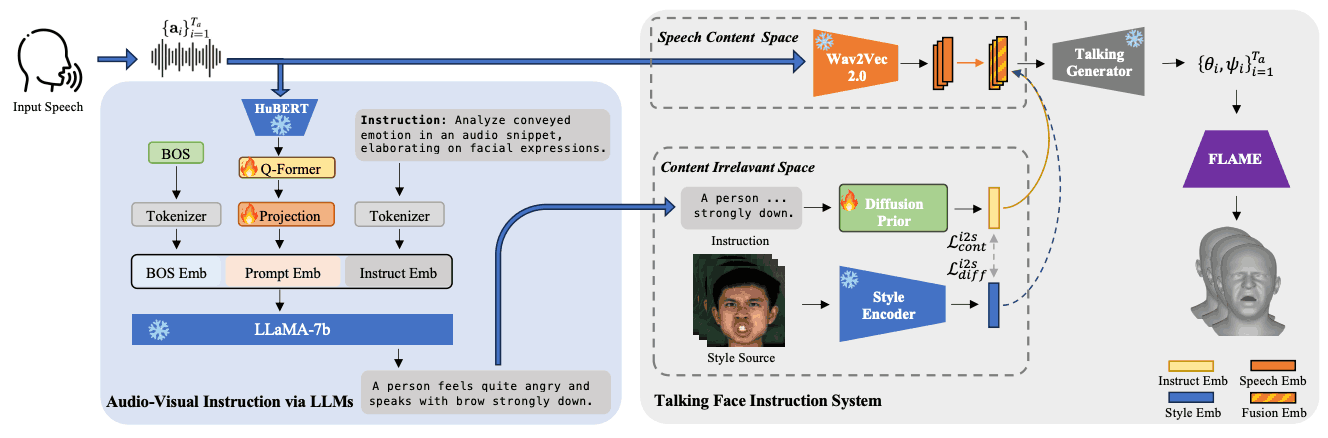
本文提出了一种更自然的方法。它旨在利用人类语音中的风格信息,生成能直接反映说话者情绪和风格的富有表现力的说话表情。从音频中合成各种逼真的面部动作是一项复杂而具有挑战性的任务,同时还要保持准确的唇部同步。为了解决这个问题,我们正在开发一个名为 AVI-Talking 的新系统。该系统可通过视听引导系统生成富有表现力的说话表情。
AVI-Talking 通过使用中间视觉教学表征而不是直接从音频中学习,有效地弥补了视听差距。具体来说,该框架将生成过程分为两个阶段,每个阶段都有一套明确的目标,从而大大降低了优化的复杂性。此外,将视觉指令作为中间输出的呈现方式提高了模型的可解释性,并为用户根据自己的意愿进行指令和修改提供了灵活性。
这项技术有望开辟娱乐技术的新天地。
AVI-Talking 概述
AVI-Talking 的目标是根据语音片段生成具有同步嘴唇动作和一致面部表情的三维动画人脸。它不是根据直接语音合成会说话的人脸,而是利用大规模语言模型来有效指导生成过程。
下图概述了 AVI-Talking 系统的流程。该系统由两个主要阶段组成:第一个阶段是 "通过 LLMs 进行视听教学"。第二个阶段是 "会说话的面部 指令系统"。在这里,三维面部动作是根据指导实时合成的。其目的是从输入语音中生成三维参数系数的时间序列。
这种方法能够真实地再现说话者的自然面部表情和嘴部动作,为观众提供更逼真的视觉体验。
实验和结果
对生成的指南和会说话的面孔的质量进行量化评估。评估分为两类:第一类是视听指令预测。在这里,自然语言生成领域广泛采用的指标被用来评估使用 BLEU1、BLEU4、METEOR、ROUGE-L、CIDEr 和 SPICE 生成的指南的准确性。使用 GAN 指标 FID 和 KID 评估面部保真度,并通过多样性得分进一步衡量特定语音片段的面部表情多样性。它还通过计算不同噪音条件下风格特征之间的距离来量化生成面部表情的变化,并使用 LSE-D 来衡量唇部同步的准确性。
在 MeadText 和 RAVEDESS 数据集上获得的 "三维会说话的人脸合成 "结果如下表所示。在许多评估指标上,AVI-Talking 都表现出色。不过,在唇音同步的准确性方面,它可能略逊于其他方法,这主要是由于 SyncNet 是基于无表情视频预先训练的,因此偏向于中性面部表情。
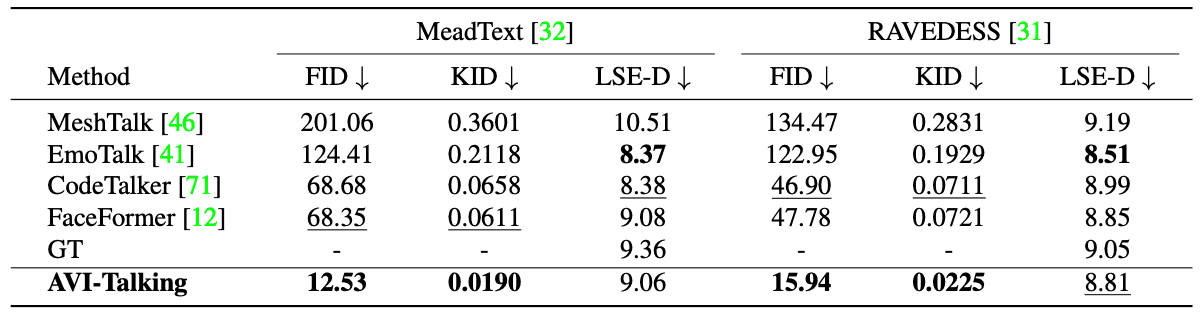
AVI-Talking 的重点是面部表情,这是影响得分的一个因素。不过,它获得的 LSE-D 分数接近参考视频,这表明生成精确的唇音同步视频是可能的。
本文还进行了定量评估。主观评估对于验证模型在生成任务中的表现至关重要。下图显示了AVI-Talking 与传统技术在三种不同情况下的比较结果。结果表明,AVI-Talking可根据说话者的状态生成可靠的视听指令和富有表现力的面部细节。
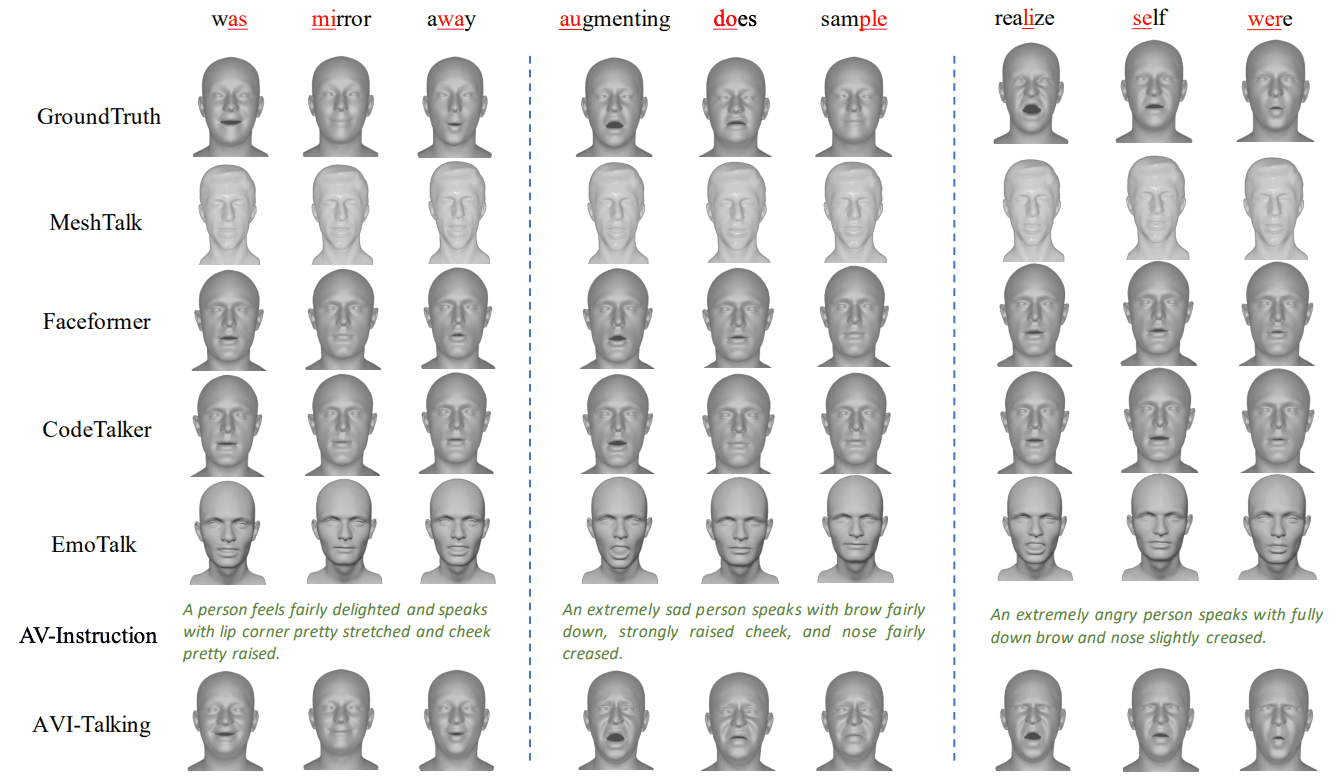
关于唇语同步的性能,据观察,CodeTalker 和 Faceformer 等其他方法可以在没有面部表情的情况下产生更自然的发音。然而,根据这项研究,在涉及情绪的场景中,可以观察到唇部动作的轻微失真。这一观察结果与上述表格中的 LSE-D 分数也是一致的,后者是一种定量评估。
此外,论文还包括一项用户研究,15 名参与者对AVI-Talking 和三种竞争方法生成的共 30 个视频进行了评分。这些视频是使用从 MeadText 测试集中随机抽取的 20 段口语音频和从 RAVEDESS 中抽取的 10 段音频生成的。
评估采用业内广泛使用的 MOS。参与者从三个维度对每段视频进行 1 到 5 分的评分。
- 唇语同步质量:评估与口语内容同步的嘴部动作。
- 动作的表现力:评估面部细节的丰富程度。
- 面部表情的一致性:评估面部动作与说话者表情的一致性。
结果如下表所示,由于 MeshTalk 采用了简单的 UNet 架构设计,因此在各方面的得分都最低。另一方面,EmoTalk 和 CodeTalker(引入了转换器块)的唇音同步质量得分较高。

在动作的表现力和面部表情的一致性方面,AVI-Talking明显优于其他方法。总体而言,AVI-Talking 在表现力合成方面优于其他模型,清楚地表明了该方法的有效性。

总结
本文提出的 AVI-Talking 是一种基于语音生成富有表现力的三维说话表情的新型系统。该系统首先将语音-视觉生成分解为两个不同的学习步骤,并通过使用中间视觉引导来促进语音驱动的说话表情生成。它还引入了一种新颖的软提示策略,利用大规模语言模型的语境知识来捕捉说话者的语音状态。此外,我们还建立了一个预训练程序,以整合唇语同步和视听指令。最后,我们利用扩散预网络将视听指令有效映射到潜在空间中,以实现高质量的生产。
不过,也发现了一些局限性。对特定语音状态的低灵敏度和说话人脸合成网络对有限视觉指示的依赖被认为是挑战。这归因于数据集的异质性,以及说话者的语音没有得到很好的识别。
未来的研究还将考虑使用检索增强生成(RAG)技术进行进一步的微调和知识注入。这将使大规模语言能够专门用于特定的跨模态视听生成任务,从而生成更具表现力的会说话的人脸。此外,通过使用强大的视觉标记器和对一般视觉基础设施模型进行微调,有望获得更通用和更有竞争力的结果。这些发展有望成为未来会说话的人脸生成技术的重要步骤。