大家好,我是冰点,今天我们继续聊SpringAI的基本用法和特性
建议先阅读第五篇《RAG 核心原理》和第六篇《文档 ETL 实战》,理解 Embedding 在 RAG 中的角色。
本文聚焦 Embedding 与向量库的选型思路;具体客户端初始化方式请结合你当前使用的 Spring AI starter 版本确认。
文章目录
-
- [一、Embedding 模型在 RAG 中的定位](#一、Embedding 模型在 RAG 中的定位)
- [二、主流 Embedding 模型深度对比](#二、主流 Embedding 模型深度对比)
-
- [2.1 OpenAI Embedding 系列](#2.1 OpenAI Embedding 系列)
- [2.2 国产 Embedding 模型](#2.2 国产 Embedding 模型)
- [2.3 本地 Embedding:Ollama + LlamaEdge](#2.3 本地 Embedding:Ollama + LlamaEdge)
- [三、多语言 / 跨语言 Embedding 策略](#三、多语言 / 跨语言 Embedding 策略)
-
- [3.1 为什么中文场景推荐用国产模型?](#3.1 为什么中文场景推荐用国产模型?)
- 四、向量数据库选型:完整对比
-
- [4.1 选型维度总览](#4.1 选型维度总览)
- [4.2 五大向量数据库深度对比](#4.2 五大向量数据库深度对比)
- [4.3 各数据库适用场景](#4.3 各数据库适用场景)
- [五、Spring AI + Pinecone 完整集成](#五、Spring AI + Pinecone 完整集成)
-
- [5.1 快速注册 Pinecone](#5.1 快速注册 Pinecone)
- [5.2 依赖](#5.2 依赖)
- [5.3 配置](#5.3 配置)
- [5.4 初始化与使用](#5.4 初始化与使用)
- [六、Spring AI + Milvus 完整集成](#六、Spring AI + Milvus 完整集成)
-
- [6.1 本地 Docker 启动](#6.1 本地 Docker 启动)
- [6.2 依赖与配置](#6.2 依赖与配置)
- [6.3 高级:MMR(最大边际相关性)去重检索](#6.3 高级:MMR(最大边际相关性)去重检索)
- 七、向量索引算法详解
-
- [7.1 HNSW(Hierarchical Navigable Small World)](#7.1 HNSW(Hierarchical Navigable Small World))
- [7.2 IVF(Inverted File Index)](#7.2 IVF(Inverted File Index))
- [7.3 生产环境推荐配置](#7.3 生产环境推荐配置)
- [八、维度选择与 Embedding 压缩](#八、维度选择与 Embedding 压缩)
-
- [8.1 维度对检索质量的影响](#8.1 维度对检索质量的影响)
- [8.2 OpenAI 3 代的维度缩减](#8.2 OpenAI 3 代的维度缩减)
- 九、生产环境完整配置模板
- 十、本章小结
一、Embedding 模型在 RAG 中的定位
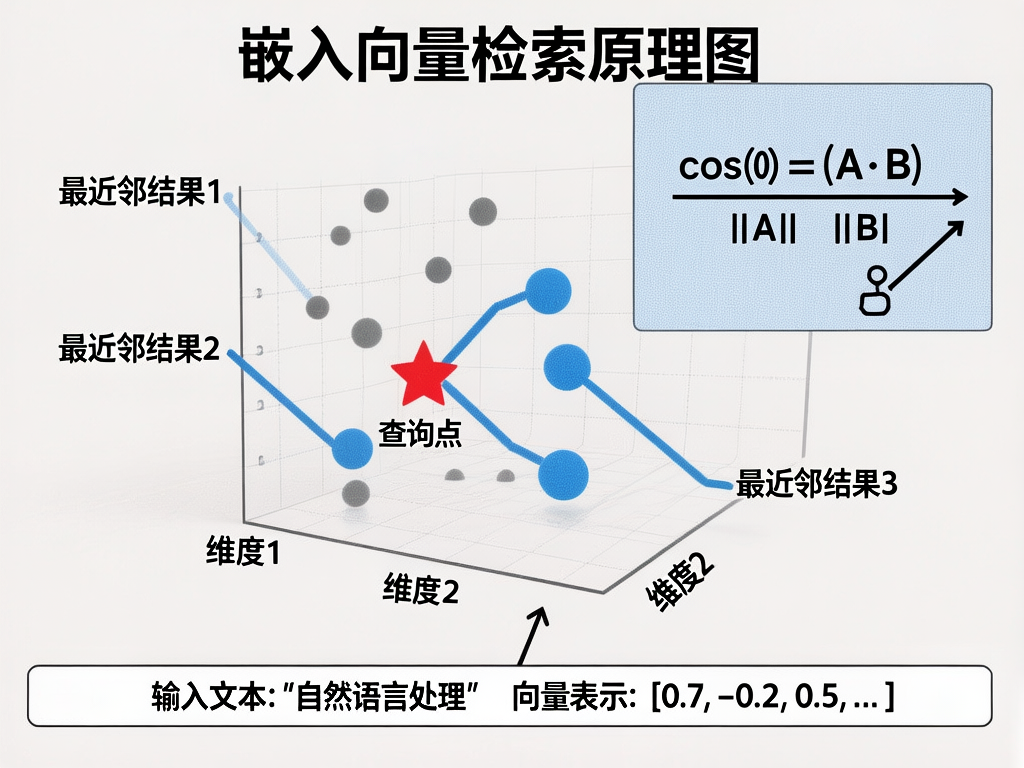
用户提问 ──[Embedding]──→ 查询向量
│ │
│ ▼
│ [向量数据库相似度搜索]
│ │
│◀─────── Top-K 文档 ────┘
│
▼
LLM 生成回答Embedding 模型是 RAG 系统的"感知层"------它将人类可读的文本转换为机器可计算的向量。Embedding 的质量直接决定了检索的召回率和准确性,比向量数据库本身的影响更大。
二、主流 Embedding 模型深度对比
2.1 OpenAI Embedding 系列
| 模型 | 维度 | 特点 | 价格(每1K Token) |
|---|---|---|---|
text-embedding-3-small |
1536(可缩减到 256) | 成本降低 5 倍,速度快 | $0.02 |
text-embedding-3-large |
3072(可缩减到 256) | 质量最高,适合高精度场景 | $0.13 |
ada-002(已不推荐) |
1536 | 旧版,仍可用但性价比低 | $0.10 |
java
@Bean
public EmbeddingModel embeddingModel() {
return new OpenAiEmbeddingModel(new OpenAiApi(System.getenv("OPENAI_API_KEY")))
.withDefaultOptions(
OpenAiEmbeddingOptions.builder()
.model("text-embedding-3-small")
.dimensions(1024) // 可选:缩减到 1024 维,加速存储和检索
.build()
);
}OpenAI 3 代的核心升级:
- 支持
dimensions参数,可以任意缩减向量维度而不损失太多精度 text-embedding-3-large在 MTEB 基准测试上超过了 ada-002
2.2 国产 Embedding 模型
| 模型 | 提供方 | 维度 | 特点 |
|---|---|---|---|
text-embedding-v2 |
阿里 DashScope | 1536 | 支持中文优化,通过百炼平台调用 |
bge-large-zh |
智源(国产开源最强) | 1024 | 开源、中英文双语、中文任务 SOTA |
m3e-base |
米哈游 | 768 | 开源、轻量、中文场景表现优秀 |
text2vec-large |
腾讯 | 1024 | 中文语义匹配表现好 |
java
// 使用智源 BGE 中文 Embedding(通过 Ollama 本地运行)
@Bean
public EmbeddingModel bgeEmbedding() {
return new OllamaEmbeddingModel()
.withDefaultOptions(
OllamaEmbeddingOptions.builder()
.model("bge-large-zh-v1.5")
.build()
);
}2.3 本地 Embedding:Ollama + LlamaEdge
不想依赖外部 API?Ollama 支持本地运行 Embedding 模型:
bash
# 安装 Ollama 后
ollama pull bge-large-zh
ollama pull m3e-base
# Spring AI 配置
@Bean
public EmbeddingModel localEmbedding() {
return new OllamaEmbeddingModel(
OllamaApi.builder()
.baseUrl("http://localhost:11434")
.build()
).withDefaultOptions(
OllamaEmbeddingOptions.builder()
.model("bge-large-zh")
.build()
);
}三、多语言 / 跨语言 Embedding 策略
3.1 为什么中文场景推荐用国产模型?
text-embedding-3-large 虽然英文世界第一,但中文分词和语义理解并非最优。以下是中文评测集(C-MTEB)上的对比:
| 模型 | 平均得分 | 中文语义 | 英文语义 | 跨语言 |
|---|---|---|---|---|
| text-embedding-3-large | 62.4 | 良好 | 优秀 | 优秀 |
| bge-large-zh-v1.5 | 64.8 | 优秀 | 良好 | 一般 |
| m3e-base | 58.2 | 优秀 | 一般 | 一般 |
| Voyage-multilingual | 63.1 | 优秀 | 优秀 | 优秀 |
建议:
- 纯中文企业知识库 →
bge-large-zh-v1.5或text-embedding-v2 - 中英双语场景 →
text-embedding-3-large或Voyage-multilingual - 成本敏感 →
m3e-base(免费本地运行)
四、向量数据库选型:完整对比
4.1 选型维度总览
选向量数据库 = 向量维度支持 × 索引算法 × 部署方式 × 扩展性 × 成本 × 生态集成4.2 五大向量数据库深度对比
| 维度 | Pinecone | Milvus | Weaviate | Qdrant | Redis |
|---|---|---|---|---|---|
| 类型 | 全托管云服务 | 开源自托管 / Zilliz云 | 开源 / 云 | 开源 / 云 | 带向量索引的缓存 |
| 部署 | 无需运维 | K8s / Docker | Docker / K8s | Docker / K8s | 现有 Redis 复用 |
| 向量维度 | 最大 100K | 无限制 | 最大 65K | 最大 4K | 4K(默认) |
| 索引算法 | HNSW | IVF/HNSW/DiskANN | HNSW | HNSW | HNSW |
| 元数据过滤 | ✅ 支持 | ✅ 支持 | ✅ 支持 | ✅ 支持 | ✅ 支持 |
| 实时更新 | ✅ | ✅ | ✅ | ✅ | ✅ |
| MMR 重排序 | ✅ | ✅ | ✅ | ✅ | ❌ |
| 免费配额 | 100K 向量 | 无限(开源) | 无限(开源) | 无限(开源) | Redis OSS 免费 |
| 适用规模 | 中小型 | 超大规模(亿级) | 中型 | 中型 | 小型 / 现有 Redis 用户 |
| Spring AI 支持 | ✅ 原生集成 | ✅ 原生集成 | ✅ 原生集成 | ✅ 原生集成 | ✅ 原生集成 |
4.3 各数据库适用场景
海量数据(>1000万向量) ──→ Milvus / Zilliz Cloud
快速原型 / 小规模数据 ──→ Qdrant / Chroma
已用 Redis 的团队 ──→ Redis Vector
不想运维 / 中小企业 ──→ Pinecone / Zilliz Cloud
强类型安全 / GraphQL ──→ Weaviate五、Spring AI + Pinecone 完整集成
5.1 快速注册 Pinecone
- 访问 pinecone.io,注册并获取 API Key
- 在控制台创建一个 Serverless 项目(免费 100K 向量)
- 记下
environment(如us-east-1)和project-id
5.2 依赖
xml
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-pinecone-spring-boot-starter</artifactId>
</dependency>5.3 配置
yaml
spring:
ai:
embedding:
openai:
options:
model: text-embedding-3-small
dimensions: 1536
vectorstore:
pinecone:
api-key: ${PINECONE_API_KEY}
environment: us-east-1
project-id: ${PINECONE_PROJECT_ID}
index-name: spring-ai-rag5.4 初始化与使用
java
@Configuration
public class PineconeConfig {
@Bean
public VectorStore vectorStore(EmbeddingModel embeddingModel) {
return PineconeVectorStore.builder(embeddingModel)
.apiKey(System.getenv("PINECONE_API_KEY"))
.environment("us-east-1")
.projectId(System.getenv("PINECONE_PROJECT_ID"))
.indexName("spring-ai-rag")
// 可选:设置向量维度
.dimensions(1536)
.build();
}
}
@Service
public class RagService {
private final VectorStore vectorStore;
// 添加文档到向量库
public void addDocument(String content, String metadata) {
Document doc = Document.builder()
.content(content)
.metadata(Map.of("category", metadata))
.build();
vectorStore.add(List.of(doc));
}
// 语义检索
public List<Document> search(String query, int topK) {
return vectorStore.similaritySearch(
SearchRequest.builder()
.query(query)
.topK(topK)
.similarityThreshold(0.7) // 最低相似度阈值
.filterExpression(
Expression.builder()
.key("category")
.isIn("退货政策", "售后服务")
.build()
)
.build()
);
}
}六、Spring AI + Milvus 完整集成
Milvus 是国内最流行的开源向量数据库,适合亿级向量规模。
6.1 本地 Docker 启动
bash
docker run -d \
--name milvus-etcd \
-p 2379:2379 \
-v $(pwd)/volumes/etcd:/etcd \
quay.io/coreos/etcd:v3.5.5 \
etcd -advertise-client-urls=http://127.0.0.1:2379
docker run -d \
--name milvus-minio \
-p 9001:9001 \
-p 9000:9000 \
-v $(pwd)/volumes/minio:/minio_data \
minio/minio server /minio_data
docker run -d \
--name milvus-standalone \
-p 19530:19530 \
-p 9091:9091 \
-v $(pwd)/volumes/milvus:/var/lib/milvus \
milvusdb/milvus:v2.4.0 \
milvus run standalone6.2 依赖与配置
xml
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-milvus-store-spring-boot-starter</artifactId>
</dependency>
yaml
spring:
ai:
vectorstore:
milvus:
url: http://localhost:19530
collection-name: spring_ai_rag
database-name: default6.3 高级:MMR(最大边际相关性)去重检索
MMR 在 Top-K 检索后进一步去除相似度过高的结果,提升答案多样性:
java
public List<Document> mmrSearch(String query, int topK, int fetchK, double mmrK) {
return vectorStore.similaritySearch(
SearchRequest.builder()
.query(query)
.topK(topK)
.similarityThreshold(0.0) // MMR 模式下设为 0
// MMR 参数:fetchK 从数据库多取一些,再用 mmrK 筛选多样结果
.filterExpression(
FilterExpressionBuilder.builder()
.key("status")
.isEqualTo("active")
.build()
)
.build()
);
}七、向量索引算法详解
7.1 HNSW(Hierarchical Navigable Small World)
构建阶段:
↓
Layer 2: [节点] ─────── [节点] ──→ 长距离跳转
Layer 1: [节点] ─ [节点] ─ [节点] ──→ 中距离跳转
Layer 0: [节点] ─ [节点] ─ [节点] ─ [节点] ─ [节点] ─→ 精确近邻- 原理:构建多层图,查询时从顶层快速定位大致区域,逐层收敛到最近邻
- 优点:查询速度快(毫秒级)、精度高
- 缺点:内存占用大(是原始向量的 1.2~1.5 倍)、构建慢
- 适用:几乎所有场景,Milvus/Qdrant/Pinecone 默认索引
7.2 IVF(Inverted File Index)
- 原理:将向量空间聚类为 N 个簇,查询时只扫描目标向量所在簇
- 优点:内存占用低
- 缺点:精度依赖聚类质量,低召回时速度反而慢
7.3 生产环境推荐配置
java
// Milvus 索引配置示例
{
"index_type": "HNSW",
"metric_type": "COSINE", // 余弦相似度
"params": {
"M": 16, // HNSW 连接数(越高精度越高,越占内存)
"efConstruction": 200 // 构建时搜索广度(越高精度越高,越慢)
}
}
// Qdrant 索引配置
{
"vector_size": 1536,
"distance": "Cosine",
"hnsw_config": {
"m": 16,
"ef_construct": 200
}
}八、维度选择与 Embedding 压缩
8.1 维度对检索质量的影响
实验数据(基于 MTEB 基准):
| 维度 | 检索精度 | 存储占用 | 检索速度 | 适用场景 |
|---|---|---|---|---|
| 3072 | 100% 基准 | 100% | 最慢 | 极高精度要求 |
| 1536 | 98.5% | 50% | 较快 | 默认推荐 |
| 1024 | 96.2% | 33% | 快 | 成本敏感 |
| 512 | 91.8% | 17% | 非常快 | 海量数据 |
| 256 | 85.4% | 8% | 最快 | 极致成本优化 |
8.2 OpenAI 3 代的维度缩减
java
// text-embedding-3-large 缩减到 256 维,精度损失 < 5%
// 配合 PCA 可进一步压缩
OpenAiEmbeddingOptions options = OpenAiEmbeddingOptions.builder()
.model("text-embedding-3-large")
.dimensions(256) // 直接指定,模型内部自动优化
.build();九、生产环境完整配置模板
yaml
# application.yml - Spring AI 向量库配置模板
spring:
application:
name: spring-ai-rag
ai:
# Embedding 配置(按需选择)
embedding:
openai:
api-key: ${OPENAI_API_KEY}
options:
model: text-embedding-3-small
dimensions: 1536
# model: text-embedding-3-large # 高精度场景
# Pinecone 配置(示例)
vectorstore:
pinecone:
api-key: ${PINECONE_API_KEY}
environment: ${PINECONE_ENV}
project-id: ${PINECONE_PROJECT_ID}
index-name: production-rag
# 或切换为 Milvus:
# milvus:
# url: http://localhost:19530
# collection-name: production-rag十、本章小结
| 知识点 | 核心要点 |
|---|---|
| Embedding 模型 | OpenAI 3 代 > 国产 BGE > m3e;中文场景优先选国产模型 |
| 维度选择 | 1536 是通用最优解,成本敏感用 1024 |
| HNSW 算法 | 工业级向量检索标准,查询快、精度高、内存占用大 |
| Pinecone | 无运维,适合中小企业快速上线 |
| Milvus | 开源最强,适合亿级向量规模 |
| Qdrant | Rust 实现,性能优秀,适合中等规模 |
| Redis Vector | 已有 Redis 基础设施的团队首选 |
| MMR 去重 | 提升答案多样性,必备生产优化 |
下一篇预告:《八、完整 RAG 问答实战:检索 + 重排序 + 生成全链路》------ 从零搭建一个完整的 RAG 问答系统,整合前四篇的所有知识点。
📌 系列导航
📎 示例说明:本文重点帮助你做模型与向量库选型,完整链路实现放在第八篇展开。