原文: mp.weixin.qq.com/s/C46jhKFNA...
欢迎关注公zh: AI-Frontiers
3年,从0到全球领跑:万字长文拆解DeepSeek大模型技术演进
从ResNet到mHC:DeepSeek重构残差连接,额外开销仅6.7%,附复现代码
收藏!LLM开发全链路:5大步骤+15大框架,从数据治理到RLHF一文通关
万字长文解读Qwen进化史:27篇论文深度复盘Qwen模型家族
在上一篇,我们以烹饪火候为类比,从感性的角度系统讲解了LLM API核心参数的的作用、场景化调优方法,强调了参数是控制输出精准度、创造性、多样性与成本的关键旋钮。
比如文中通过智能客服、内容创作、数据分析三类典型场景说明不同参数组合的适配逻辑,逐一拆解temperature、top_p、frequency_penalty、presence_penalty、max_tokens等核心参数的取值范围与效果,并结合代码示例与常见问题,给出实用建议,但并未给出底层原理,即参数调整为什么会带来不同的效果。
本篇将针对上一篇中的核心参数,从数学公式的角度为大家解释,参数的配置对模型到底意味着什么。
一、核心背景:Next Token Prediction
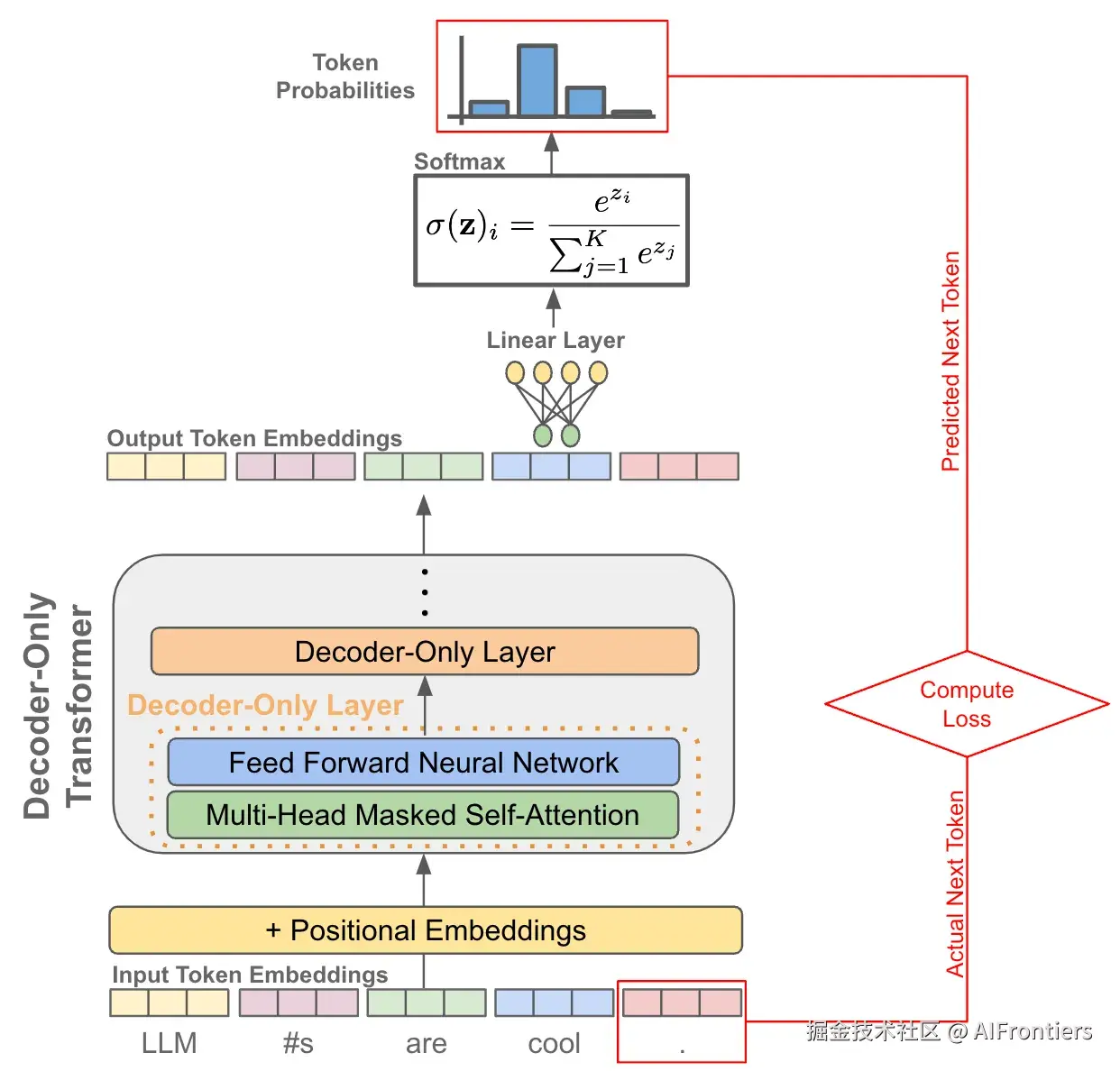
LLM 的强大能力相信已家喻户晓:写代码、吟诗作对、做PPT、写报告,无所不能。当剥开 LLM 的技术外壳,你会发现核心逻辑很简单:玩一场永无止境的「词语接龙」游戏。
如上面的架构图所示,LLM 的本质就是 Next Token Prediction(下一个词预测) 。它并不理解文字背后的深意,而是通过海量数据的「喂养」,掌握了人类语言的概率分布。当输入一句话,LLM 会像一个超级输入法,根据已经给出的词,在后台疯狂计算成千上万个备选词出现的几率,筛选那个最「顺理成章」的接下去。
实现该过程的精确控制,需要归功于图中顶部的那个数学魔法「Softmax 函数」。
σ(z)i=∑j=1Kezjezi (1)
该公式把模型输出的一堆数字,转换成「所有候选词的概率分布」,我们来拆成下公式(1)的计算过程:
-
zi :也叫 Logits,即上图中 「Linear Layer 」的输出分值,「Linear Layer 」通过矩阵运算,得到每个词的原始得分 zi。 zi可以是任何实数,数值越大,代表模型认为这个词出现的可能性越高。
-
ezi : 这个式子会放大高分词与低分词的差距,让模型更倾向于选 「更合理的词」。我们来举例说明,比如两个词 zi=10,zj=1,经过exp后, ezi=e10=6374.31,ezj=e1=2.72,两者从原来的10倍差距放大到2343.49。
-
∑j=1Kezj: 所有词的分数之和,其作用是让所有词的概率加起来刚好等于 1,就像我们说「这几个词里,句号有 70% 的概率,逗号有 20%,其他词加起来只有 10%」。
以上图中中输入「LLMs are cool」为例,模型经过「Linear Layer、Softmax 函数」运算后,映射为一组总和为 1 的概率分布:接「.」的概率可能是 80%,接「!」的概率是 15%,其他符号的概率为5%。通过这种方式,原本枯燥的数字转化成了模型对下一个词的「信心指数」。每预测出一个词,LLM 就会把这个词加入到输入序列里,再次循环上述过程。
二、核心参数讲解
2.1 temperature(温度)
该参数值越小,输出结果越确定;值越高,生成内容越随机、多样且富有创造性,取值范围 0~2,默认值为 1。
这是最核心的参数,直接作用于模型最后一层 Softmax 函数。
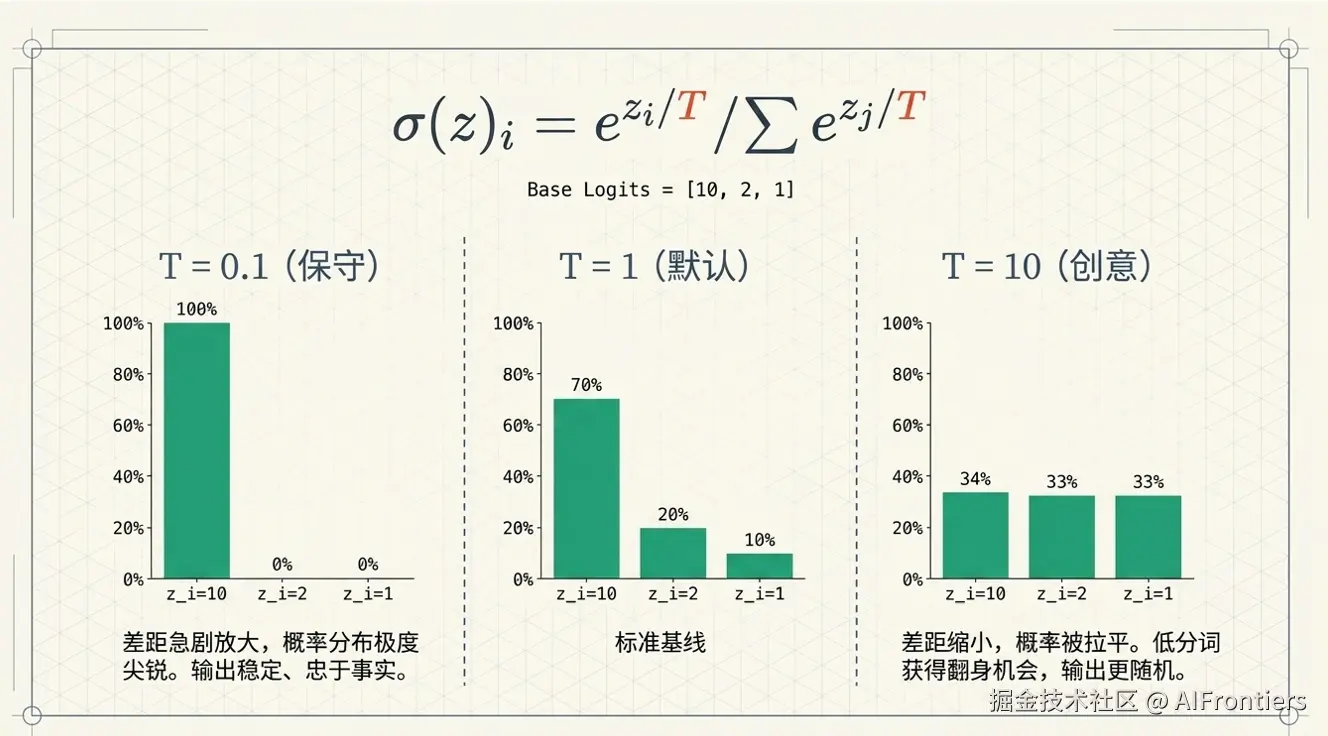
Linear Layer 输出的是逻辑得分(Logits),通过 Softmax 函数 转化为概率分布。加入Temperature ( T ) 后的候选词的概率分布
σ(z)i=∑j=1Kezj/Tezi/T (2)
假设 Linear Layer 输出三个词的原始 logits ,即 zi为:10, 2, 1
-
当 T<1 :拉大高分和低分之间的差距。概率分布变得尖锐,模型会非常保守地选择那个概率最高的词。以取 T=0.1为例, zi/T 分别为 100, 20, 10,差距被急剧放大 ,经过公式(2) Softmax 函数 后, σ(z)≈1,0,0,概率分布变得极度尖锐,输出稳定、确定、忠于事实。
-
当 T>1 :缩小差距。概率分布变得平滑,原本概率较低的词也有了翻身的机会,模型变得「有创意」或「胡言乱语」。以取 T=10为例, zi/T 分别为 1, 0.2, 0.1,经过公式(2) Softmax 函数 后, σ(z)≈0.539,0.242,0.219,概率被拉平,三个词都有明显机会被选中,输出更随机、更多样。。
2.2 frequency_penalty(频率惩罚)
frequency penalty 会按 token 在提示与回复中已出现的次数,对下一个待生成 token 施加比例惩罚;数值越高,重复出现的 token 概率越低,从而减少回复中的词汇重复。数值范围 -2.0~2.0,默认 0
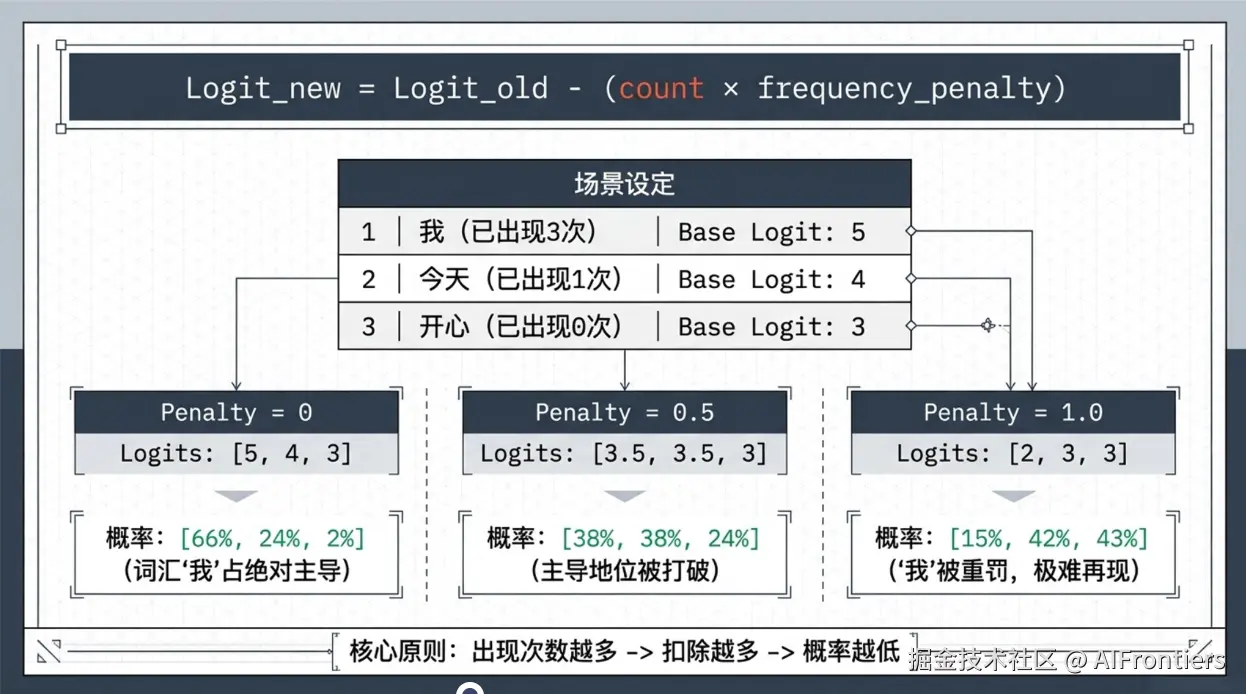
在原始 Logit 值上减去一个偏移量
Logitnew=Logitold−(count×frequency_penalty) (3)
其中, count 为候选词已出现次数,出现次数越多 → 扣得越多 → 概率越低 → 越不容易重复。
假设现在要生成下一个词,候选词是:
-
我:已出现 3 次
-
今天:已出现 1 次
-
开心:已出现 0 次
假设 Linear Layer 输出三个词的原始 logits ,即 zi为:5, 4, 3,我们分三类情况来讨论 frequency_penalty 的大小对候选词的概率分布的影响
-
frequency_penalty=0 : zi 分别为 5, 4, 3,经过公式(2) Softmax 函数 后, σ(z)≈0.665,0.245,0.024,模型很容易选择之前重复的词「我」
-
frequency_penalty=0.5 : zi 分别为 5−0.5×3, 4−0.5×1, 3−0=3.5, 3.5, 3,经过公式(2) Softmax 函数 后, σ(z)≈0.38,0.38,0.24,候选词「我」被明显打压,不再一家独大。
-
frequency_penalty=1.0 : zi 分别为5−1×3, 4−1×1, 3=2, 3, 3,经过公式(2) Softmax 函数 后, σ(z)≈0.15,0.42,0.43,候选词「我」概率变得很低,几乎不会再重复。
需要注意:
-
temperature:缩放所有 logit,抹平 / 放大差距
-
frequency_penalty:只针对出现过的词做减法,专门防重复
2.3 presence_penalty(存在惩罚)
presence penalty 同样对重复词施加惩罚,但与 frequency penalty 不同,其惩罚力度固定,同一 词无论出现 2 次还是 10 次,惩罚均相同,可避免模型过度重复用词。高值利于生成多样创意文本,低值则让内容更聚焦。数值范围 -2.0~2.0,默认 0。
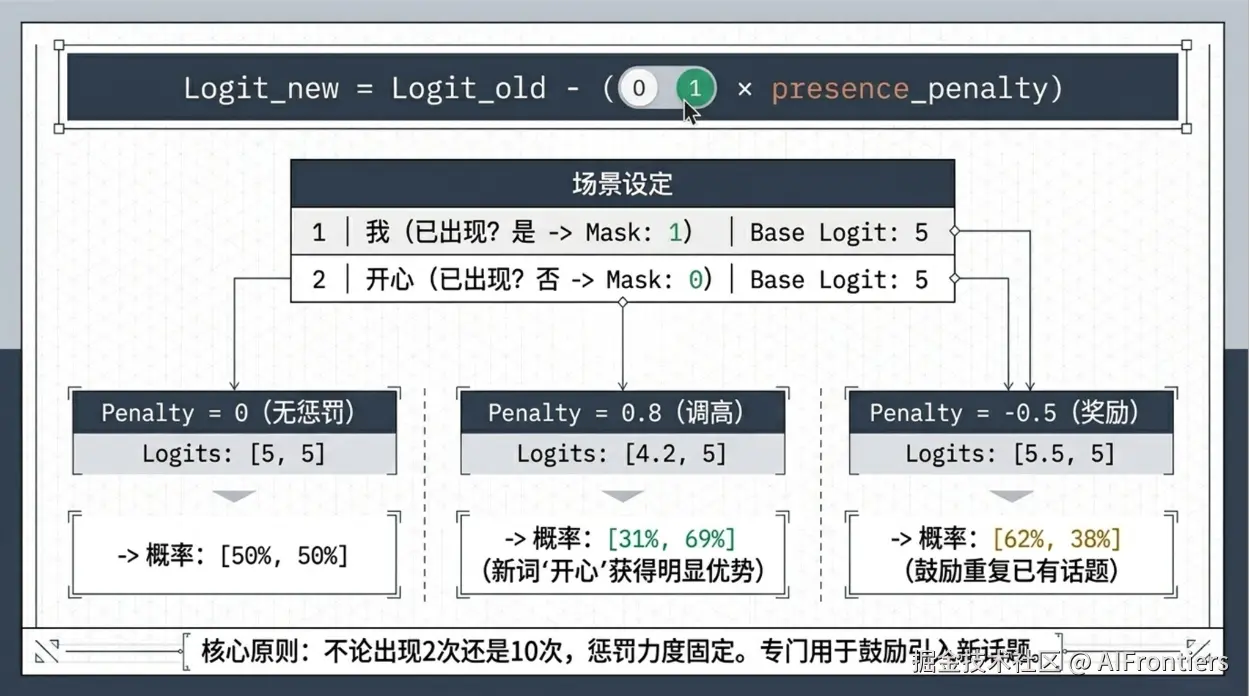
与 frequency_penalty 类似,也是在原始 Logit 值上减去一个偏移量
Logitnew=Logitold−(mask×presence_penalty) (4)
其中, mask 是一个布尔开关。如果候选词在之前出现过至少一次 ,则 mask=1 ;否则, mask=0 。
假设现在要生成下一个词,候选词是:
-
我:已出现 3 次
-
开心:已出现 0 次
假设两个词的原始 logits ,即 zi为:5, 5,我们分三类情况来讨论 presence_penalty 的大小对候选词的概率分布的影响
-
presence_penalty =0(无惩罚) : zi 分别为 5, 5,经过公式(2) Softmax 函数 后, σ(z)≈0.5,0.5,对候选词的选择没有影响
-
presence_penalty =0.8(调高) : zi 分别为 5−0.8,5=4.2,5,经过公式(2) Softmax 函数 后, σ(z)≈0.31,0.69,新词明显更可能被选。
-
presence_penalty =-0.5(调低 / 奖励) : zi 分别为 5+0.5,5=5.5,5,经过公式(2) Softmax 函数 后, σ(z)≈0.62,0.38,就候选词「我」被鼓励重复。
与 frequency_penalty 类似,presence_penalty 只针对出现过的词做减法,专门防重复。

2.4 top_p(概率截断)
top_p(与 temperature 同属核采样)可控制模型输出的确定性:需准确、事实性答案时调低参数,追求多样化响应则调高参数。取值 0~1,默认值为 1。
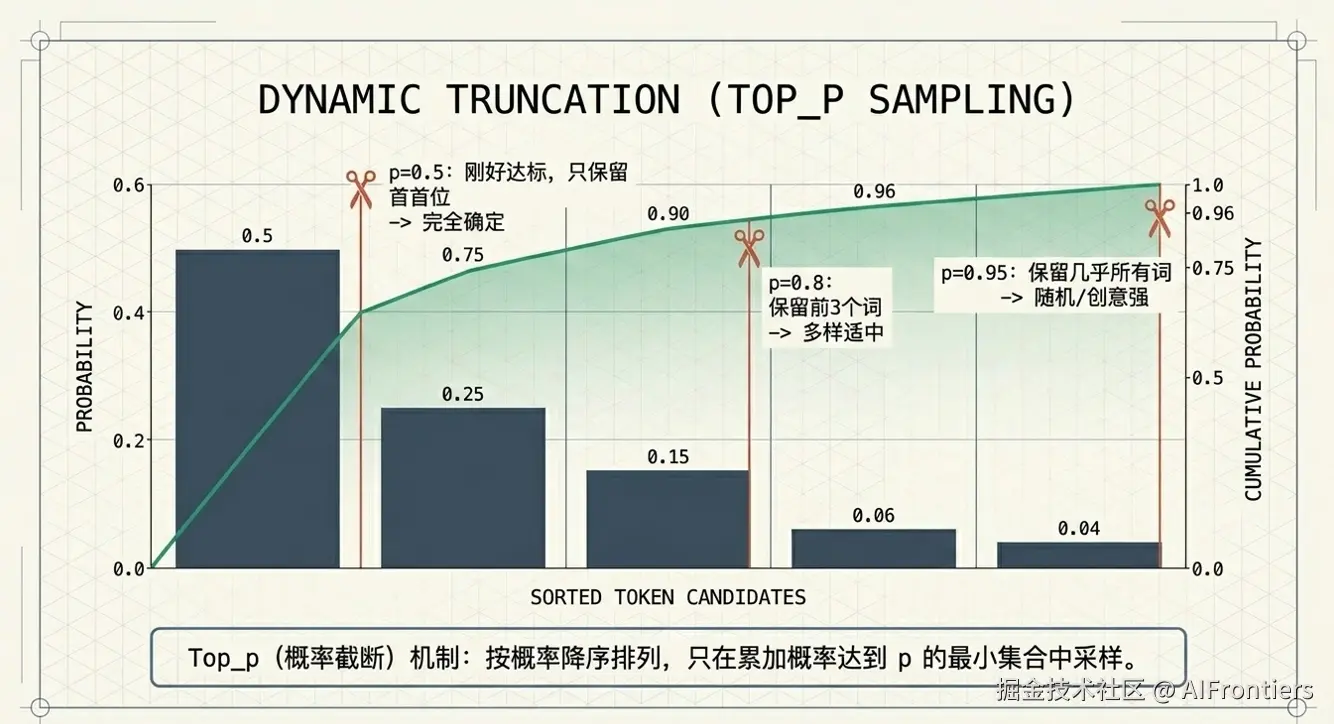
top_p 是动态的。它将词项按概率降序排列,只在累加概率达到 $$$$ 的最小集合中采样。
假设候选词排序后概率为:0.5, 0.25, 0.15, 0.06, 0.04(总和 = 1),讨论不同取值的影响:
-
top_p=0.5(调低 ):累加为0.5 → 刚好达标, 只保留 0.5 → 输出完全确定。
-
top_p=0.8(中等) :累加为 0.5+0.25+0.15=0.9 ≥0.8, 保留前 3 个词→ 输出自然、多样适中。
-
top_p=0.95(调高) :累加几乎到全部保留,几乎所有词→ 输出更随机、创意更强。
2.5 max_tokens(最大生成长度)
通过调整 max length 控制 LLM 生成的 token 数量,设置该值能避免冗长无关回复,同时控制成本。
max_tokens(max length)是控制大语言模型生成长度的核心参数,其数学本质:设定模型生成 token 的最大步数 N,当生成过程达到第 N 个 token 时强制终止,不改变每一步的概率分布与采样逻辑。调低 max_tokens 会缩小最大步数 N,使输出更简短克制,但易出现内容截断不完整;调高 max_tokens 则扩大 N,允许输出更完整、详细、篇幅更长的内容,同时会增加 token 消耗与调用成本。
max_length(max_tokens)在大语言模型底层以自回归 生成循环的步数上限 实现。模型每生成一个 token 即完成一次前向推理与采样,同时计数器加 1;当计数器达到 max_length 时,生成循环被强制终止,不再进行后续推理。该机制属于生成过程的控制逻辑,不改变模型的概率分布、logit 计算或采样策略,仅通过限制生成步数控制输出长度,调低会提前截断输出,调高则允许生成更长内容并消耗更多资源。
2.6 stop(停止标志)
stop 可为字符串或字符串列表,模型遇到指定标志时会立即停止生成。例如设置 stop="\\n\\nHuman:",可在对话模型准备生成下一轮用户提示时强制停止。合理设置能避免跑题与多余输出,默认无强制停止符,模型会按内置停止符或 max_tokens 耗尽结束生成。
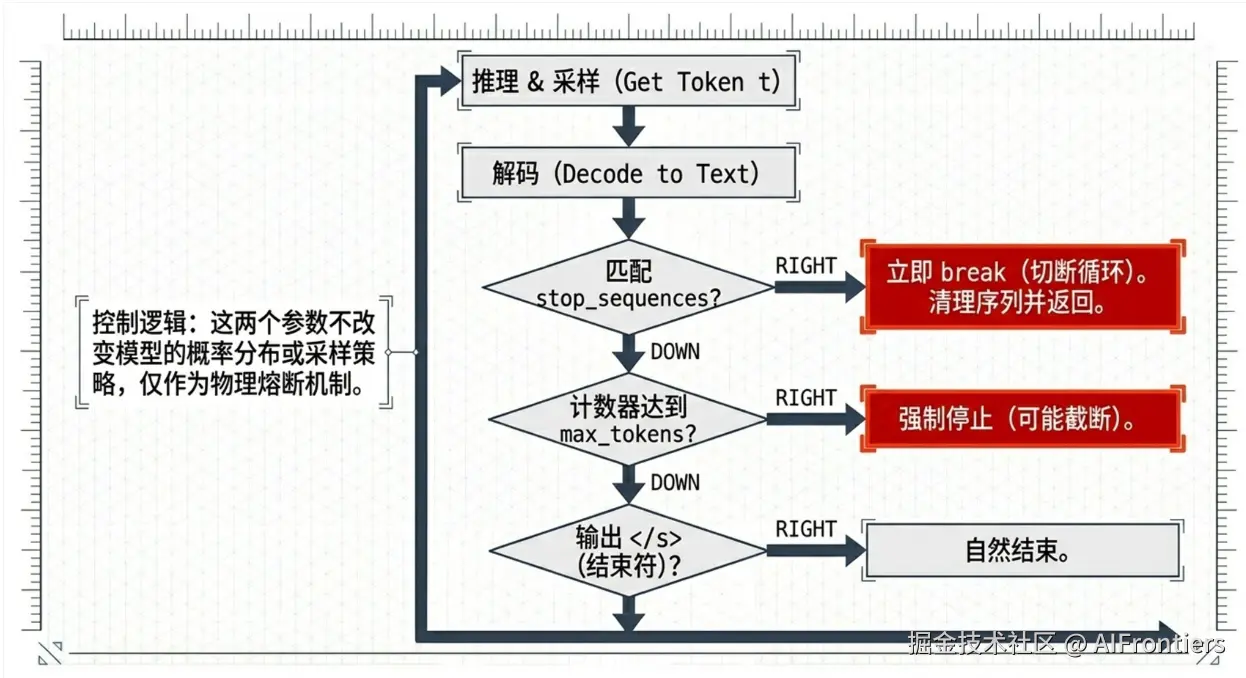
Stop(停止标志)在 LLM 自回归生成过程中,以实时文本后缀匹配 的方式实现。模型每生成一个 token 并解码为文本后,会检查当前输出文本末尾是否包含预设的停止字符串;若命中任一停止序列,生成循环立即强制终止。该机制属于生成过程的控制逻辑,不改变模型推理、概率分布与采样策略,仅通过字符串匹配触发提前停止;设置更多停止序列会让输出更易提前结束、更克制,减少冗余与跑题。
模型依然是一步生成 1 个 token,流程如下:
-
初始化
- 输出 tokens = \[\]
- 输出文本 = ""
- step = 0
- stop_sequences = "\\n", "###", "结束", "用户:"
-
进入生成循环
① 模型推理 → 采样 → 得到下一个 token t
② 将 t 加入输出 tokens
③ 将 tokens 解码为完整文本
④ step + 1
⑤ 判断当前输出文本的末尾是否包含任意 stop sequence
-
- 如果 包含 → 立即 break,停止生成
-
- 如果 不包含 → 继续循环
⑥ 同时判断:是否达到 max_length → 达到停止生成
⑦ 同时判断:是否生成结束符 → 停止生成
-
最后一步:
- 截断 停止后,把命中的 stop sequence 从输出中删掉(可选) 返回干净文本。
和 max_length 一样,stop属于生成控制逻辑,不是数学采样参数。
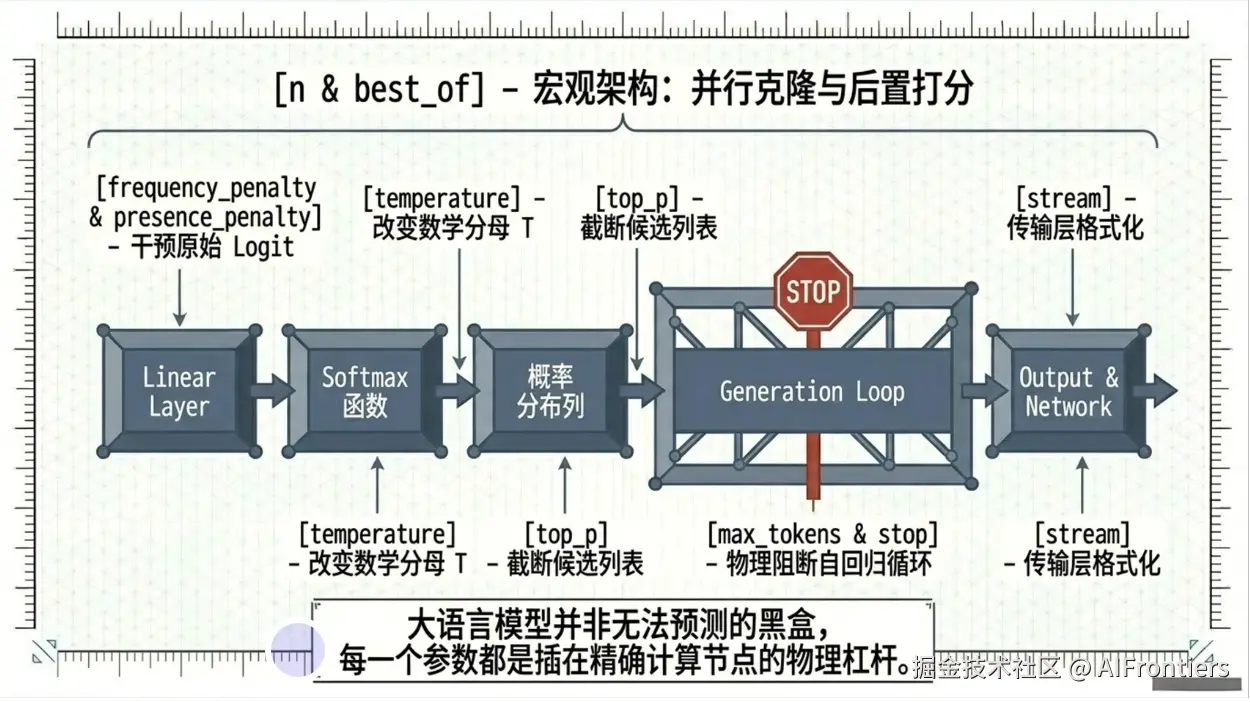
2.7 n(返回结果数量)
n 就是让模型并行执行 n 次独立的自回归生成流程,最终返回 n 份彼此无关的完整结果。默认 1。
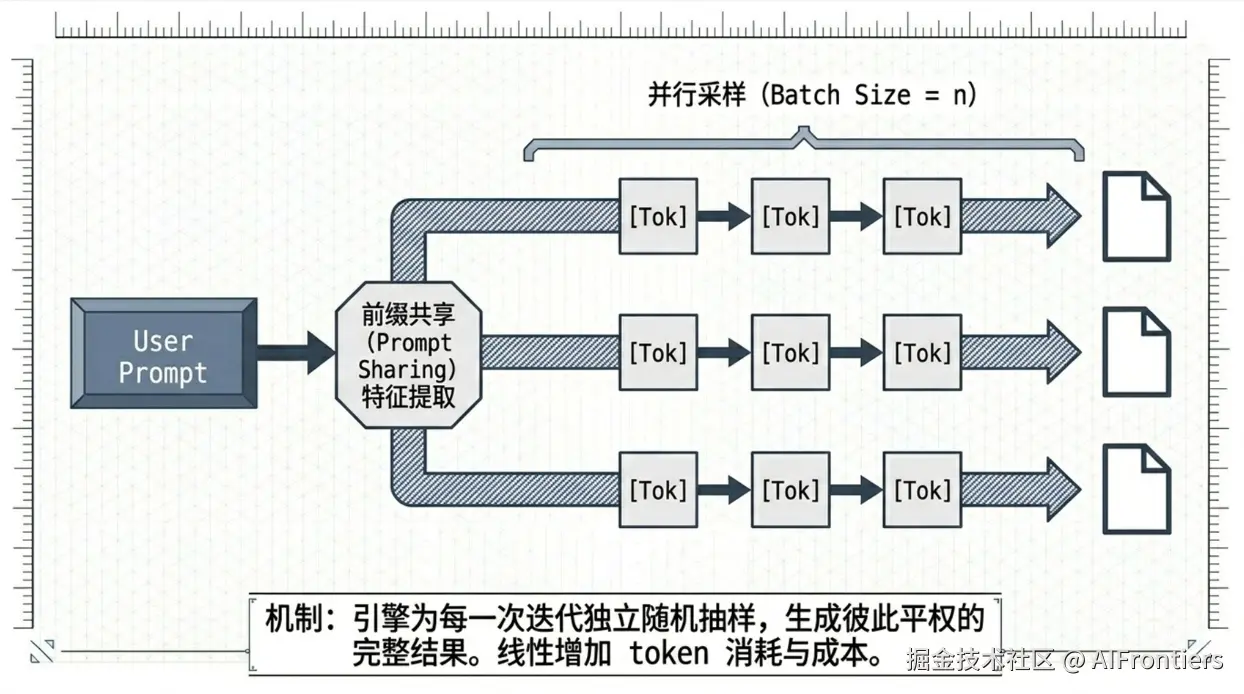
n(返回结果数量)在大语言模型底层通过并行批量执行多次独立自回归生成实现。模型接收参数 n 后,会创建 n 组相互独立的生成状态,共享输入提示词的编码与推理,并行执行采样、长度控制、停止序列检查等流程;所有路径生成完成后,返回 n 份彼此独立的文本结果。n 仅控制生成的副本数量,不改变模型推理逻辑、概率分布与采样策略,调高 n 会线性增加输出 token 消耗与计算成本。
从计算流来看,当 n > 1 时,推理引擎并不是串行地运行 n 次生成任务,而是将单个用户请求在批处理维度上进行了逻辑扩展。
-
Prompt Sharing(前缀共享) :在 Pre-fill(预填充) 阶段,模型仅对输入 Prompt 进行一次特征提取。但在 Decoding(解码) 阶段,引擎会克隆出 n 个独立的隐向量副本。
-
并行采样(Parallel Sampling) :在每一轮自回归迭代中,GPU 实际上是在处理一个 Batch Size = n 的批次。对于每一个副本,采样器会根据当前的Temperature、Top-p等参数独立进行随机抽样,产生 n 条独立的生成路径。
和 best_of 参数的区别
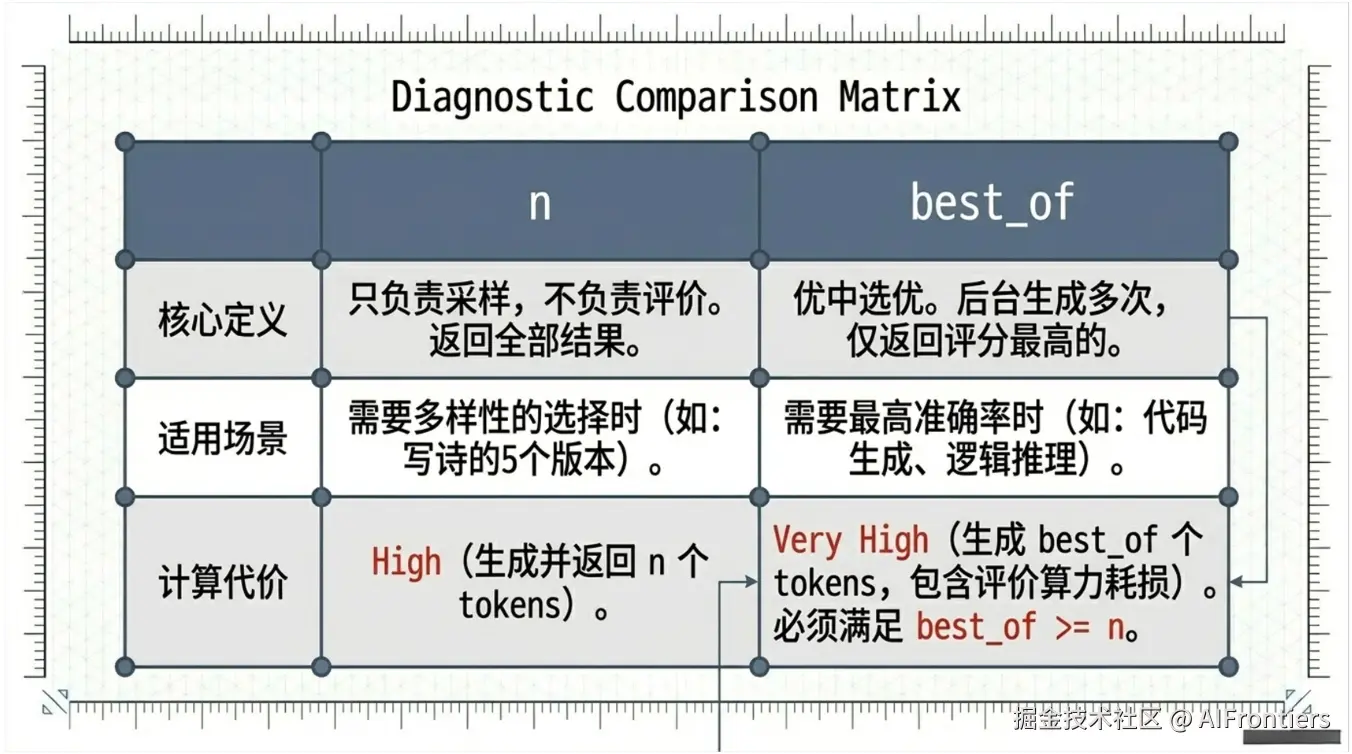
定义与输出目标
-
n :返回全部n条结果,即你要求模型生成 n 个结果,模型就实实在在地返回 n 个结果给用户。适用于多样性场景,比如写诗时想要 5 个不同的版本供你挑选。
-
best_of :优中选优。模型在后台生成 best_of 个结果,但返回其中得分最高的那几个(通常由 n 决定返回数量,且要求 best_of >= n)。适用于需要最准确的答案(如代码或逻辑推理),但希望模型多试几次,挑个最靠谱的。
背后的计算
-
n:只负责采样,不负责评价。每条路径是平权的,引擎不关心哪条更好。
-
best_of :引入了评价函数。 对于生成的每一条序列,引擎会计算其累积对数概率,系统会根据这个分数对 best_of 条路径进行排序,剔除掉那些概率较低(可能是胡言乱语)的序列,只保留前
n个高分结果。
累积对数概率的数学公式可简单理解
total_score=scoreold+logσ(z)i (5)
即对于生成序列中的每个新 Token,就将新的对数概率加进去,其中 σ(z)i为公式(1)计算的概率。
在实际工程(如 best_of)中,直接使用累积和会导致一个问题:长文本的得分总是比短文本低(每多生成一个 Token,就是在总分里加上一个值为负的对数概率)。为了公平竞争,推理引擎通常会对总分进行长度归一化处理:
Final_Score=Lα∑log(Pi) (5)
其中,$$$$ 是序列长度, α 是惩罚因子(通常在 0.6 到 1.0 之间)。
对于best_of的进一步解释,可参考下面的例子

| 候选序列 | 生成路径 | 累积对数概率 | 解释 |
|---|---|---|---|
| 路径 A | "I", "am", "fine" | -1.2 + (-0.5) + (-0.1) = -1.8 | 最高分 (最符合统计学逻辑) |
| 路径 B | "I", "is", "good" | -1.2 + (-2.8) + (-0.9) = -4.9 | 中得分 |
| 路径 C | "I", "be", "well" | -1.2 + (-4.5) + (-1.5) = -7.2 | 低得分 (语法概率极低) |
2.8 stream(流式输出)
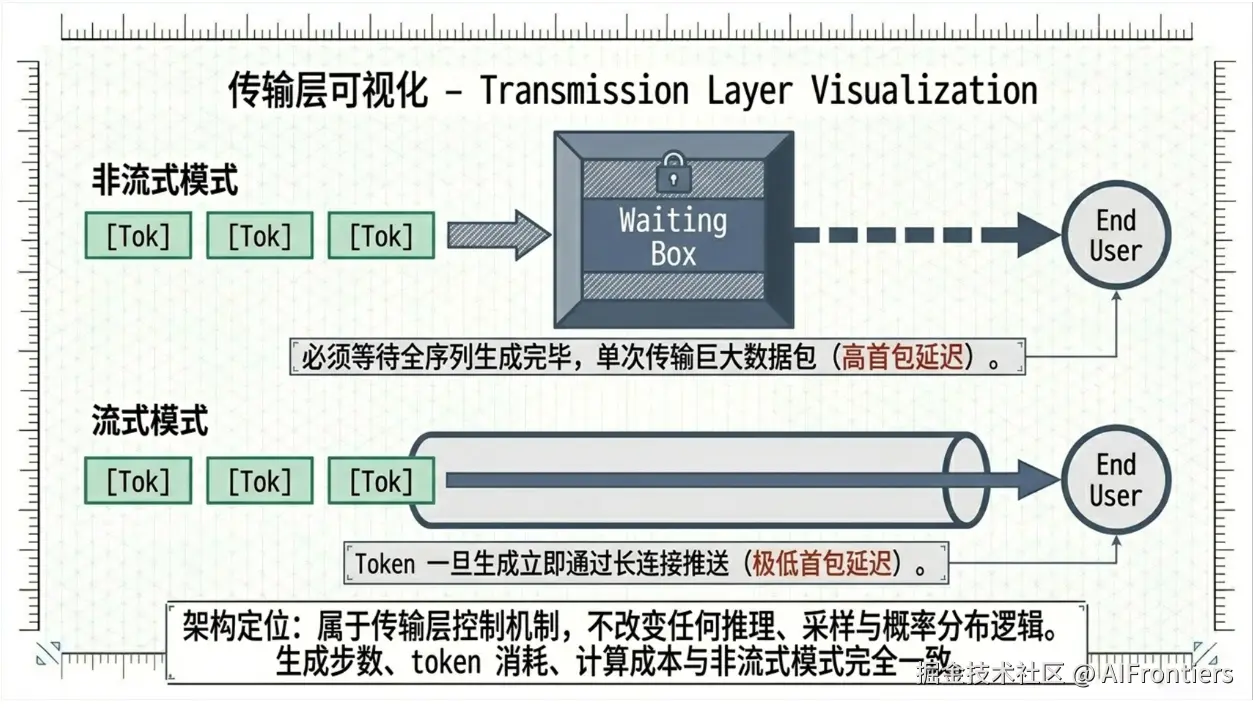
stream(流式输出)是大语言模型的传输层控制机制,不改变自回归生成的推理、采样与概率分布逻辑。底层实现为:模型每生成一个 token,立即通过长连接以数据块(chunk)形式实时推送给客户端,而非等待全部生成完成后一次性返回。开启 stream 可降低首包响应延迟,提升交互体验,但生成步数、token 消耗、计算成本与非流式模式完全一致。
三、总结
本篇从底层原理出发,以 Next Token Prediction 为核心,拆解了 LLM API 核心参数的作用:从 Linear Layer、 Softmax 函数出发,系统解析了 temperature、top_p、frequency_penalty、presence_penalty 对概率分布的调控逻辑,以及 max_tokens、stop、n、best_of、stream 对生成流程与输出形式的控制机制,揭示了各参数如何通过精准干预模型计算节点,实现对输出确定性、多样性、长度与成本的灵活调节。