你肯定用过 ChatGPT 聊天,但你知道怎么让 AI 自己动手查天气、买火车票、发邮件吗?
今天,我们就来聊聊 AI 界的"全能数字员工"------AI Agent,并用超详细的代码带你亲手打造一个!
前言:大模型是"学霸",但 Agent 才是"项目经理"
先问一个问题:现在的 ChatGPT、文心一言等大语言模型已经很能聊天了,为什么我们还需要 AI Agent?
想象一下:
-
大模型
:就像一个知识渊博但"只会动嘴"的学霸。你可以问他"北京明天天气怎么样?"他会告诉你"可能会有雨,记得带伞。"------然后呢?没了。他不能帮你查实时天气,不能帮你买票,更不能帮你发邮件。
-
AI Agent
:则像一个"项目经理"。你告诉他"帮我安排明天去北京的行程,如果天气好就买票,然后把行程发邮件给我。"Agent 会自己拆解任务:先查天气 → 如果好就查车票 → 最后写邮件发出。全程不需要你一步一步指挥。
所以,大模型是"大脑",Agent 是"大脑+手+脚+工具箱"。本文将从零开始,用最通俗的语言和可运行的代码,带你理解并亲手打造 AI Agent。
一、AI 的"驾照等级":从 L1 到 L5
业界喜欢用自动驾驶的分级来类比 AI 的进化程度,一共 5 级:
|--------|---------|---------------------------|-------------------------------|
| 等级 | 名称 | 通俗解释 | 举个栗子 |
| L1 | Tool | AI 啥忙也不帮,全人类自己干 | 传统计算器、Word 软件 |
| L2 | Chatbot | 你问一句,AI 答一句,但不会替你做事 | 早期的 ChatGPT(只能聊天) |
| L3 | Copilot | 你指挥,AI 给你写草稿,你再来改 | GitHub Copilot 写代码、Jasper 写文案 |
| L4 | Agent | 你给个目标,AI 自己规划步骤、调用工具、搞定任务 | AutoGPT、我们本文要做的 |
| L5 | Species | 你都不用给目标,AI 自己发现问题并解决 | 传说中的通用人工智能(AGI) |
目前,我们大多数人用的还是 L2 和 L3。L4 的 Agent 才是当下工程落地的"终极形态"。
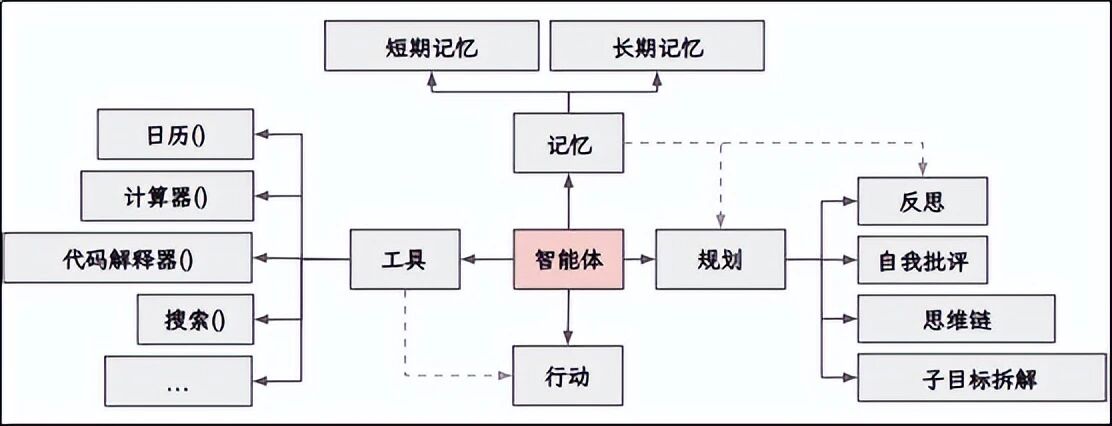
二、拆开一个 Agent:它的"五脏六腑"
一个完整的 Agent 通常包含 6 个核心部件,就像一个人的不同器官:
1. 大模型(LLM)------大脑
负责理解用户说什么,然后思考:我要分几步完成?需要用什么工具?所有的"智力"都来自这里。
2. 记忆(Memory)------笔记本
-
短期记忆
:记住刚才聊了啥,比如用户问过"北京天气",接着问"上海呢?",Agent 知道是在问上海天气。
-
长期记忆
:记住用户的历史偏好,比如"这个人喜欢高铁靠窗座位",下次买票自动选。
3. 工具(Tools)------手脚
Agent 要干活,必须能调用外部功能:搜索引擎、数据库、发送邮件 API、计算器......这些就是"工具"。
4. 规划(Planning)------拆解任务
把"帮我安排去北京"这种大任务,拆成"查天气→查票→发邮件"等小步骤。
5. 行动(Action)------执行
真正去调用工具,比如运行一个 send_email() 函数。
6. 协作(Collaboration)------团队配合
当任务太复杂,一个 Agent 搞不定时,可以让多个 Agent 分工合作,由一个"主管 Agent"来协调。
三、从零开始:给大模型装上"手和脚"(工具调用)
3.1 什么是"工具"?------AI 的 API 调用能力
工具就是一个可以被大模型调用的函数。比如我们写一个加法函数,然后告诉模型:"你可以调用这个函数来算加法"。模型收到用户问题"1+2 等于几?"后,就会自动决定调用这个函数,而不是自己乱算。
3.2 用 LangChain 创建第一个工具
LangChain 是当前最流行的 Agent 开发框架。我们用它的 @tool 装饰器,三步就能把普通函数变成"AI 可调用的工具"。
# 示例 1:用 @tool 创建一个加法工具(超详细注释)
from langchain.tools import tool
# @tool 装饰器会把这个函数"包装"成 AI 能理解的格式
@tool
def add_number(a: int, b: int) -> int:
"""两个整数相加""" # 这个 docstring 会变成工具的描述,AI 会根据它判断何时调用
return a + b
# 打印工具的基本信息
print("工具名称:", add_number.name) # add_number
print("工具描述:", add_number.description) # 两个整数相加
print("参数要求:", add_number.args)
# 输出参数 schema:{'a': {'title': 'A', 'type': 'integer'}, 'b': {...}}解释:
-
第 5 行:@tool 告诉 LangChain:"请把这个函数注册为一个工具"。
-
第 7 行的注释 """两个整数相加""" 非常重要!AI 就是靠这段话知道这个工具是干什么的。如果你写 """计算两数之和""",AI 也会理解。
-
第 10-12 行:打印出来的 args 是一个 JSON Schema,描述了函数需要哪些参数、参数类型。
如果你想给工具起个好名字、更详细地描述参数,可以这样:
# 示例 2:更精细地控制工具的名字和参数说明
from langchain.tools import tool
from pydantic import BaseModel, Field # Pydantic 用来定义参数结构
# 定义一个参数模型,让参数说明更清楚
class MyInput(BaseModel):
a: int = Field(description="第一个加数")
b: int = Field(description="第二个加数")
@tool(
name_or_callable="my_awesome_adder", # 工具的名字
description="计算两个整数的和,返回整数结果", # 工具描述
args_schema=MyInput, # 使用自定义参数结构
)
def add_number(a: int, b: int) -> int:
return a + b
print(add_number.name) # my_awesome_adder
print(add_number.description) # 计算两个整数的和...3.3 让大模型"知道"有这些工具:绑定工具
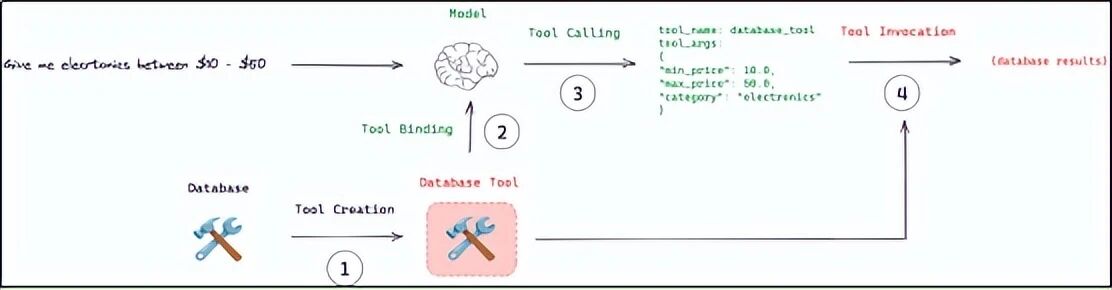
工具创建好了,但大模型默认不知道有它们。我们需要把工具"绑定"到大模型上。
# 示例 3:绑定工具到大模型,让模型能"看见"工具
import os
from langchain.tools import tool
from langchain.chat_models import init_chat_model
# 1. 先定义一个工具(查询用户信息)
@tool
def query_user_info(user_id: int) -> str:
"""根据用户ID查询用户名"""
# 模拟数据库
user_map = {1001: "张三", 1002: "李四", 1003: "王五"}
return user_map.get(user_id, "未知用户")
# 2. 初始化一个 LLM(这里使用 OpenRouter 上免费的 glm-4.5-air 模型)
llm = init_chat_model(
model="z-ai/glm-4.5-air:free",
model_provider="openai",
base_url="https://openrouter.ai/api/v1",
api_key=os.getenv("OPENROUTER_API_KEY"), # 你的 API Key 放在环境变量里
)
# 3. 将工具列表绑定到模型,生成一个新的模型对象
tools = [query_user_info]
llm_with_tools = llm.bind_tools(tools)
# 4. 问模型一个问题
response = llm_with_tools.invoke("帮我查一下用户 1002 叫什么?")
# 5. 看看模型返回了什么
print(response.content) # 模型可能说"好的,我来查"之类的文字
print(response.additional_kwargs)
# 这里会包含一个 'tool_calls' 字段,内容类似:
# [{'name': 'query_user_info', 'args': {'user_id': 1002}, 'id': 'call_xxx'}]发生了什么?
-
用户问"用户 1002 叫什么",模型识别出需要调用 query_user_info 工具。
-
模型并没有真正执行工具,它只是在 additional_kwargs 里告诉你:"我想调用这个工具,参数是 user_id=1002"。
-
真正的工具执行需要我们自己写代码去完成。
3.4 手动执行工具:从"想法"到"行动"
拿到模型的工具调用请求后,我们需要解析并执行对应的函数。
# 示例 4:手动执行工具(接上面示例)
# 从 response 中提取工具调用信息
if hasattr(response, "tool_calls") and response.tool_calls:
for tool_call in response.tool_calls:
tool_name = tool_call["name"] # 例如 "query_user_info"
tool_args = tool_call["args"] # 例如 {"user_id": 1002}
# 通过 globals() 根据名字找到函数对象,然后调用它
# 注意:这里假设函数名和工具名一致,且已经在全局作用域
result = globals()[tool_name].invoke(tool_args)
print(f"工具执行结果:{result}") # 输出 "李四"这样,我们就完成了一次"模型决策 → 工具执行"的完整闭环。
四、打造一个能自动跑完多步任务的 Agent
上面我们手动执行了单次工具调用,但真正的 Agent 应该能自动循环:调用模型 → 如果需要工具就执行 → 把结果返回给模型 → 模型再决定下一步 → 直到任务完成。
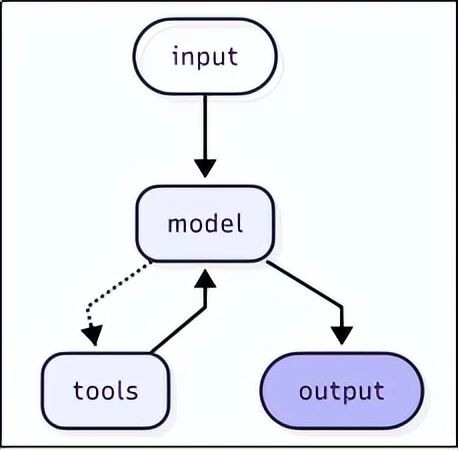
LangChain 提供了 create_agent 函数,它内部就是一个自动循环引擎。
4.1 创建一个能搜索实时信息的 Agent
假设我们要让 Agent 查询"今天北京的天气"。这需要它能上网搜索。我们可以用 Tavily 搜索引擎(一个专为 AI 设计的搜索 API)。
# 示例 5:创建第一个能搜索的 Agent(需要先注册 Tavily 获取 API Key)
import os
from langchain_tavily import TavilySearch
from langchain.agents import create_agent
from langchain.chat_models import init_chat_model
# 初始化模型
llm = init_chat_model(
model="z-ai/glm-4.5-air:free",
model_provider="openai",
base_url="https://openrouter.ai/api/v1",
api_key=os.getenv("OPENROUTER_API_KEY"),
)
# 创建搜索工具(TavilySearch 封装了搜索功能)
search_tool = TavilySearch(max_results=3) # 最多返回 3 条结果
# 创建 Agent
agent = create_agent(
model=llm,
tools=[search_tool],
system_prompt="你是一个助手,你可以使用搜索工具来查找实时信息。",
)
# 运行 Agent
result = agent.invoke({
"messages": [
{"role": "user", "content": "今天北京的天气怎么样?"}
]
})
# 打印最终输出
print(result["messages"][-1].content)内部发生了什么?
-
Agent 收到用户问题。
-
模型判断:我需要搜索工具。
-
Agent 自动调用 search_tool,传入"北京天气"作为搜索词。
-
搜索工具返回结果(例如"晴,25°C")。
-
Agent 将搜索结果再喂给模型。
-
模型根据搜索结果生成最终回答:"今天北京天气晴朗,气温25°C,适合出行。"
-
输出最终答案。
4.2 观察 Agent 的思考过程(流式输出)
上面的 invoke 只返回最终结果,如果想看中间步骤,可以用 stream:
# 示例 6:流式输出,看 Agent 的每一步
for chunk in agent.stream({
"messages": [
{"role": "system", "content": "你是助手,可以使用搜索工具。"},
{"role": "user", "content": "今天北京的天气怎么样?"}
]
}):
print(chunk)
print("---")你会看到类似这样的输出:
-
第一个 chunk:模型输出的文字"我来查一下北京天气"
-
第二个 chunk:工具调用的请求
-
第三个 chunk:工具返回的结果
-
第四个 chunk:模型根据结果生成最终回答
这对于调试和理解 Agent 行为非常有用。
五、让 Agent 拥有"记忆":不忘记刚才聊过什么
默认情况下,每次调用 agent.invoke() 都是独立的,Agent 不记得上一轮对话。但很多时候我们需要连续对话,比如:
-
用户:北京天气怎么样?
-
Agent:今天晴。
-
用户:那上海呢? ← 这里 Agent 需要知道"上海"指的是"上海的天气"
要实现这个,需要给 Agent 加上短期记忆。LangChain 通过 checkpointer 和 thread_id 实现。
# 示例 7:给 Agent 添加记忆(记住之前的对话)
import os
import datetime
from langchain_tavily import TavilySearch
from langchain.agents import create_agent
from langgraph.checkpoint.memory import InMemorySaver # 内存检查点
# 创建带 checkpointer 的 Agent
agent = create_agent(
model=llm,
tools=[TavilySearch(max_results=3)],
checkpointer=InMemorySaver(), # ← 关键!开启记忆
)
# 第一轮对话,指定 thread_id = "user_123"
config = {"configurable": {"thread_id": "user_123"}}
for chunk in agent.stream(
input={
"messages": [
{"role": "system", "content": f"当前时间:{datetime.datetime.now()}"},
{"role": "user", "content": "北京今天天气怎么样?"}
]
},
config=config
):
print(chunk)
# 第二轮对话,使用相同的 thread_id,Agent 就会记得刚才聊过北京
for chunk in agent.stream(
input={
"messages": [
{"role": "user", "content": "那上海呢?"} # 没有重复"天气"二字
]
},
config=config # 同一个 thread_id
):
print(chunk) # Agent 能正确理解为"上海的天气"通俗解释:
-
InMemorySaver() 就像一个笔记本,记下每次对话的状态。
-
thread_id 是笔记本的页码,相同页码代表同一段连续对话。
-
第二轮用户只说了"那上海呢?",Agent 翻看笔记本,想起刚才在聊天气,所以自动补全为"上海的天气"。
注意:InMemorySaver 重启程序后记忆消失。生产环境可用 RedisSaver 或数据库持久化。
六、LangSmith:Agent 的"黑匣子记录仪"
当 Agent 执行复杂任务时(比如调用三四个工具),一旦出错很难排查。LangSmith 是 LangChain 官方提供的可视化调试平台,能记录每一次模型调用、工具执行、耗时、Token 消耗。
6.1 配置 LangSmith
只需要设置几个环境变量:
export LANGSMITH_TRACING=true
export LANGSMITH_API_KEY="your_langsmith_api_key"
export LANGSMITH_PROJECT="my_first_agent" # 项目名称,会显示在网页上然后正常运行你的 Agent 代码,所有调用记录会自动上传到 LangSmith。打开 https://smith.langchain.com 就能看到详细的调用链,像这样:
用户输入 → 模型调用1(思考) → 工具调用(搜索) → 模型调用2(总结结果) → 输出每一层都可以点开,查看具体的 Prompt、响应内容、耗时。强烈推荐在生产环境中使用,否则调试 Agent 会让你崩溃。
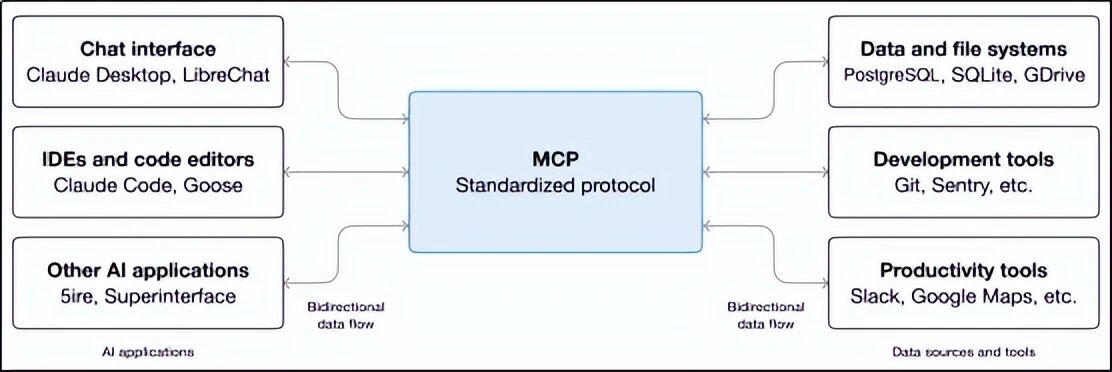
七、MCP:AI 界的"USB-C 接口"
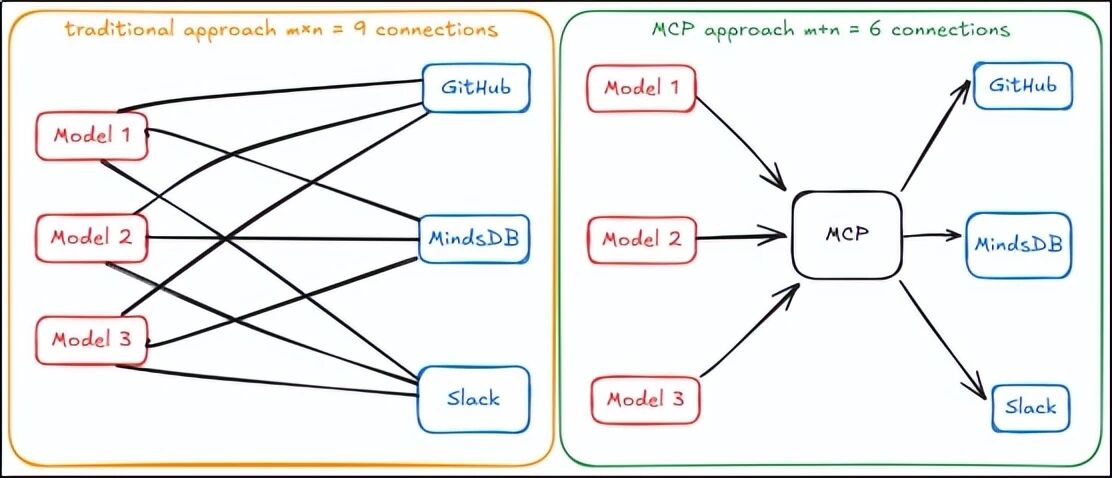
7.1 痛点:每个工具都要写适配代码,烦不烦?
假设你的 Agent 要连接 5 种工具:GitHub、Slack、数据库、谷歌地图、邮箱。传统方式下,你要为每个工具写一套"模型 → 工具"的适配代码。如果模型换一个,又得重新适配。这就像以前的手机:充电口五花八门,出门要带一堆线。
MCP(模型上下文协议) 就是 AI 界的 USB-C 标准。工具提供商只要实现一次 MCP 服务器,任何支持 MCP 的 AI 应用都能直接使用,无需再写适配代码。
7.2 MCP 的核心概念
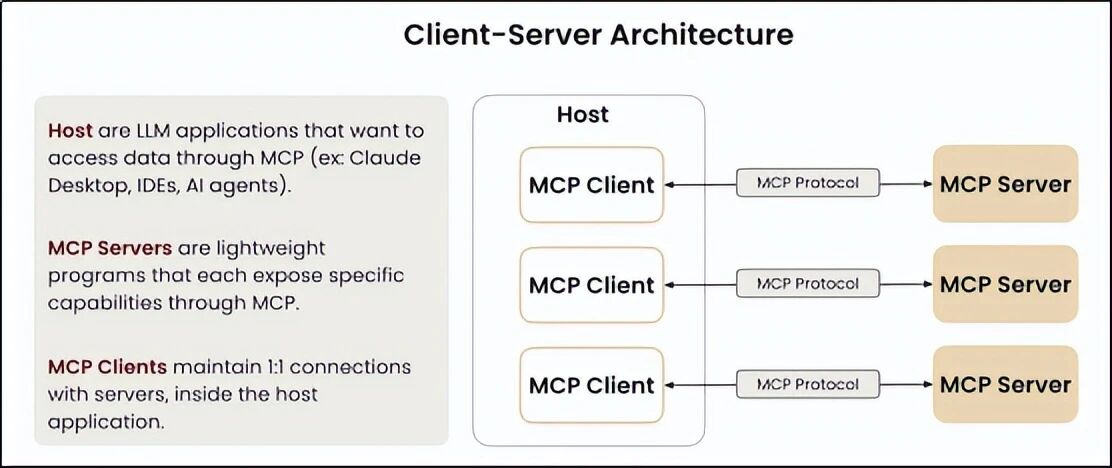
-
MCP 服务器
:一个独立程序,把工具、资源、提示模板暴露出来。
-
MCP 客户端
:嵌入在 AI 应用中,负责连接服务器,发现并调用工具。
-
传输方式
:支持本地 Stdio(命令行)、Streamable HTTP(网络)、SSE(服务器推送)。
7.3 手写一个 MCP 服务器(Stdio 方式)
# 示例 8:一个简单的 MCP 服务器(保存为 mcp_server.py)
from mcp.server.fastmcp import FastMCP
# 创建 MCP 实例
mcp = FastMCP("我的第一个MCP服务器")
# 暴露一个工具:加法
@mcp.tool()
def add(a: int, b: int) -> int:
"""计算两个数的和"""
return a + b
# 暴露一个资源(只读数据)
@mcp.resource("greeting://hello")
def get_greeting() -> str:
return "你好,欢迎使用MCP!"
# 暴露一个提示模板
@mcp.prompt()
def greet_user(name: str) -> str:
return f"请用友善的语气向{name}问好。"
if __name__ == "__main__":
mcp.run(transport="stdio") # 通过标准输入输出通信7.4 写一个 MCP 客户端来调用上面的服务器
# 示例 9:MCP 客户端(调用上面 Stdio 服务器)
import asyncio
from mcp.client.stdio import stdio_client
from mcp import ClientSession, StdioServerParameters
async def main():
# 告诉客户端如何启动服务器进程
server_params = StdioServerParameters(
command="python",
args=["mcp_server.py"], # 你的服务器脚本路径
)
# 建立连接
async with stdio_client(server_params) as (read, write):
async with ClientSession(read, write) as session:
await session.initialize() # 初始化握手
# 列出所有工具
tools = await session.list_tools()
print("可用工具:", [t.name for t in tools])
# 调用加法工具
result = await session.call_tool("add", {"a": 10, "b": 20})
print("10+20 =", result.content[0].text) # 输出 30
asyncio.run(main())7.5 LangChain 直接使用 MCP 工具(最爽的方式)
通过 langchain-mcp-adapters,你可以让 LangChain Agent 直接使用任何 MCP 服务器上的工具,就像使用本地工具一样。
# 示例 10:LangChain Agent 使用 MCP 工具
from langchain.agents import create_agent
from langchain_mcp_adapters.client import MultiServerMCPClient
import asyncio
async def run():
# 创建一个 MCP 客户端,连接多个服务器
client = MultiServerMCPClient({
"weather_api": {
"transport": "sse",
"url": "https://example.com/mcp/weather/sse",
"headers": {"Authorization": "Bearer xxx"}
},
"calculator": {
"transport": "stdio",
"command": "python",
"args": ["calc_server.py"]
}
})
# 自动发现所有工具(跨服务器)
tools = await client.get_tools()
# 创建 LangChain Agent
llm = ... # 你的模型
agent = create_agent(model=llm, tools=tools)
# 然后正常使用 agent.invoke(),Agent 会自动调用来自不同 MCP 服务器的工具
result = await agent.ainvoke({"messages": [{"role": "user", "content": "北京天气怎么样?然后算一下 123+456"}]})
print(result)
asyncio.run(run())MCP 的好处:
-
工具和 Agent 解耦,更换模型或框架不影响工具调用。
-
社区会涌现大量现成的 MCP 服务器(数据库、Slack、邮件等),拿来即用。
-
支持远程调用、安全认证(Bearer Token、API Key)。
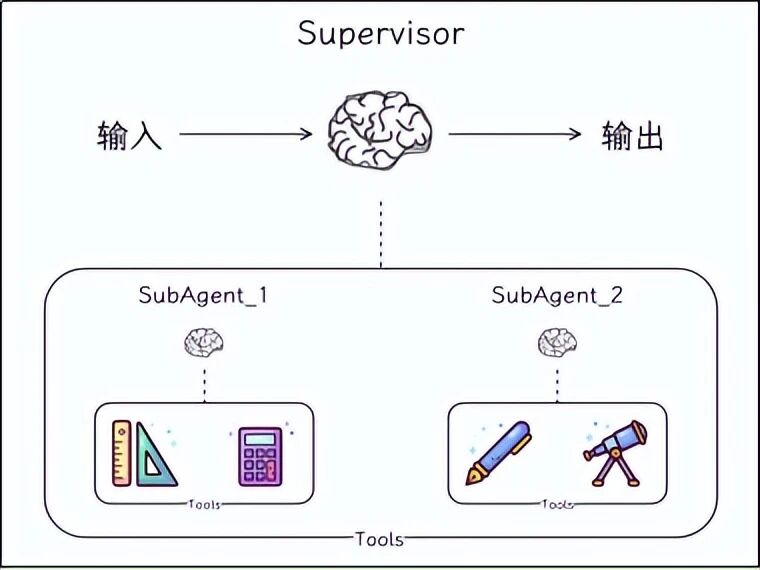
八、多 Agent 协同:老板 + 员工模式
当任务特别复杂时,一个 Agent 管理太多工具会变得混乱。更好的办法是:多个专业 Agent 各司其职,由一个"主管 Agent"来分配任务。
这就是"监督者模式"(Supervisor Pattern),架构如下:
8.1 实战:搜索 Agent + 邮件 Agent + 主管
我们实现一个场景:用户说"查一下明天北京的天气,如果晴天就买一张北京到上海的高铁票,然后把行程发邮件给我"。
主管 Agent 会:
-
调用搜索 Agent 查天气
-
根据天气结果决定是否调用车票查询 Agent(本例简化,用搜索代替)
-
调用邮件 Agent 发送通知
示例 11:监督者模式------主管+搜索子Agent+邮件子Agent
import os
import asyncio
import smtplib
from email.mime.text import MIMEText
from langchain.tools import tool
from langchain.agents import create_agent
from langchain.chat_models import init_chat_model
from langchain_tavily import TavilySearchllm = init_chat_model(
model="z-ai/glm-4.5-air:free",
model_provider="openai",
base_url="https://openrouter.ai/api/v1",
api_key=os.getenv("OPENROUTER_API_KEY"),
)---------- 子Agent 1:搜索专家 ----------
class SearchAgent:
def init(self):
self.agent = create_agent(
model=llm,
tools=[TavilySearch(max_results=3)],
system_prompt="你是一个搜索专家,只负责搜索信息,不要做其他事。"
)async def run(self, query: str) -> str: result = await self.agent.ainvoke({ "messages": [{"role": "user", "content": query}] }) return result["messages"][-1].content---------- 子Agent 2:邮件专家 ----------
@tool
async def send_email(to: str, subject: str, body: str) -> str:
"""发送邮件工具,需要提供收件人、主题、正文"""
# 这里使用 QQ 邮箱的 SMTP 为例(需提前开启 SMTP 并获取授权码)
SMTP_HOST = "smtp.qq.com"
SMTP_USER = os.getenv("SMTP_USER") # 你的邮箱地址
SMTP_PASS = os.getenv("SMTP_PASS") # 授权码,不是密码msg = MIMEText(body, "plain", "utf-8") msg["From"] = SMTP_USER msg["To"] = to msg["Subject"] = subject try: server = smtplib.SMTP_SSL(SMTP_HOST, 465, timeout=10) server.login(SMTP_USER, SMTP_PASS) server.sendmail(SMTP_USER, [to], msg.as_string()) server.quit() return "邮件发送成功" except Exception as e: return f"发送失败:{e}"class EmailAgent:
def init(self):
self.agent = create_agent(
model=llm,
tools=[send_email],
system_prompt="你是一个邮件助手,根据用户要求发送邮件。"
)async def run(self, instruction: str) -> str: result = await self.agent.ainvoke({ "messages": [{"role": "user", "content": instruction}] }) return result["messages"][-1].content实例化子Agent
search_agent = SearchAgent()
email_agent = EmailAgent()将子Agent包装成工具,供主管调用
@tool
async def search_web(query: str) -> str:
"""搜索互联网信息。输入:搜索关键词"""
return await search_agent.run(query)@tool
async def send_email_tool(to: str, subject: str, body: str) -> str:
"""发送邮件。参数:to=收件人邮箱, subject=主题, body=正文"""
return await send_email(to, subject, body) # 直接调用底层工具---------- 主管 Agent ----------
supervisor = create_agent(
model=llm,
tools=[search_web, send_email_tool],
system_prompt="""你是主管。你有两个下属工具:
1. search_web:可以搜索任何信息
2. send_email_tool:可以发送邮件当用户提出复杂需求时,请合理调用这些工具完成任务。例如: - 先查天气 - 根据结果决定下一步 - 最后发送邮件总结 """)
async def main():
user_request = """
请帮我查一下北京明天(2026年4月20日)的天气。
如果天气是晴天或者多云,就给我买一张北京到上海的高铁票(你只需要告诉我车票信息,不用真的买),
然后把天气情况和车票信息通过邮件发送到 myfriend@example.com。
如果天气不好,就只发邮件告诉我明天不适合出行。
"""# 流式输出主管的决策过程 async for chunk in supervisor.astream({ "messages": [{"role": "user", "content": user_request}] }): print(chunk) print("---")asyncio.run(main())
代码详解:
-
我们定义了两个"专家":SearchAgent(专门搜索)和 EmailAgent(专门发邮件)。它们本身也是 Agent,可以调用自己的工具。
-
为了让主管能调用它们,我们将它们的 run 方法包装成了普通工具 search_web 和 send_email_tool。
-
主管 Agent 的工具列表里只有这两个"高级工具",它不需要知道搜索具体怎么实现,也不需要知道 SMTP 怎么配置。
-
用户一个复杂请求,主管会自动拆解:先调用 search_web 查天气 → 分析结果 → 如果天气好,再调用 send_email_tool 发邮件,邮件内容里包含车票信息(车票信息也是通过搜索获得的)。
这种模式的优点:
-
职责分离:每个子 Agent 只关注自己的领域,代码更清晰。
-
易于扩展:想增加"订餐"功能?只需新建一个 RestaurantAgent,包装成工具,主管就能用。
-
降低 Prompt 复杂度:主管的 Prompt 不用列举几十个细粒度工具,只需知道几个高级能力。
总结:AI Agent 开发的黄金法则
我们从头到尾走了一遍 Agent 的核心知识,现在把关键点串起来:
|--------------|-----------------------------------------------------------------------------|
| 知识点 | 一句话总结 |
| Agent 等级 | L2 聊天、L3 副驾、L4 自动干活、L5 全自主 |
| 核心组件 | 大脑(LLM)+ 记忆(Memory)+ 手脚(Tools)+ 规划(Planning)+ 行动(Action)+ 协作(Collaboration) |
| 工具调用 | 用 @tool 装饰器包装函数,用 bind_tools 挂载到模型,模型返回工具调用请求,你负责执行 |
| Agent 循环 | create_agent 自动处理"思考→调用工具→再思考"的循环 |
| 记忆 | checkpointer + thread_id 实现短期记忆,记住对话上下文 |
| 调试 | LangSmith 记录每一步,必装的生产力工具 |
| MCP | 工具调用的 USB-C 标准,一次实现,到处使用 |
| 多 Agent | 主管模式让专家 Agent 各司其职,系统更健壮、易扩展 |
最后送上一句心得:
不要试图让一个大模型做所有事,而是让它学会"使用工具"和"找人帮忙"。这才是 Agent 的精髓。
你现在已经拥有了从 0 到 1 构建 AI Agent 的完整地图。拿起键盘,试着让第一个 Agent 帮你查天气、发邮件吧!如果你在实战中遇到问题,欢迎回来交流。