继前分享的锂电池数据
精品数据分享 | 锂电池数据集(一)新能源汽车大规模锂离子电池数据集
精品数据分享 | 锂电池数据集(二)Nature子刊论文公开锂离子电池数据
精品数据分享 | 锂电池数据集(三)西安交通大学(XJTU)电池数据集
精品数据分享 | 锂电池数据集(四)PINN+锂离子电池退化稳定性建模和预测
精品数据分享 | 锂电池数据集(五)麻省理工-斯坦福-丰田研究中心电池数据集
精品数据分享 | 锂电池数据集(六)基于深度迁移学习的锂离子电池实时个性化健康状态预测
精品数据分享 | 锂电池数据集(八)CALCE电池数据集-圆柱形电池
精品数据分享 | 锂电池数据集(九)CALCE电池数据集-棱柱形电池
本期继续分享一篇Nature communicationTop论文公开锂离子电池数据,划重点-数据集开源, 代码开源!!!
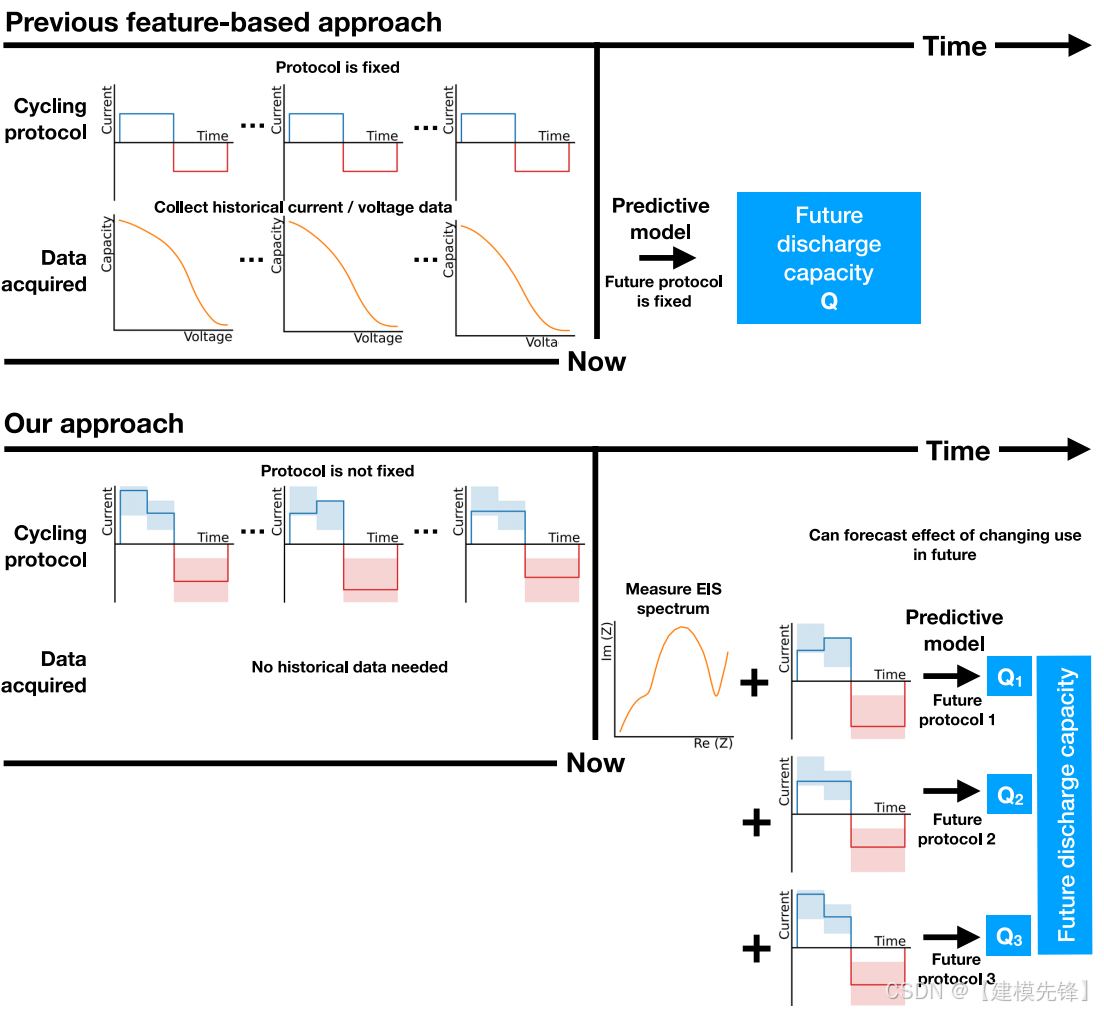
论文题目:《Impedance-based forecasting of lithium-ion battery performance amid uneven usage》
论文链接:
https://www.nature.com/articles/s41467-022-32422-w
数据集链接:
https://zenodo.org/records/6645536
论文代码:
https://github.com/PenelopeJones/battery-forecasting
注意:如果下载不了,后台回复"锂电池10",可获取我们已经打包好的论文、数据集和代码!

1 摘要
对锂离子电池性能的准确预测对于缓解消费者对电动汽车安全性和可靠性的担忧至关重要。大多数关于电池健康预测的研究集中在电池受到相同使用模式的研究和开发环境。然而,在实际操作中,跨单元和跨周期的使用具有很大的变异性,因此预测具有挑战性。为了应对这一挑战,我们提出了一种结合电化学阻抗谱测量和概率机器学习的方法。利用88个商业锂离子硬币电池的数据集(循环之间的电流随机变化),我们表明,在给定未来循环方案和在充电前立即进行的单一电化学阻抗谱测量的情况下,在不了解任何使用历史的情况下,可以在校准的不确定性下预测未来的放电容量。结果对电池制造商、循环方案的分布和温度都是稳健的。研究结果还表明,电池健康状况更好地量化为多维向量,而不是标量健康状态。
2 前言
电池性能的短和长时间尺度预测在电池预测中都是有意义的。在短时间内,预测电池将如何响应特定的充放电协议可用于开发最佳充电协议。短期预测还包括SOH估计:这里的目的是预测电池在特定的标准化循环下的放电容量或内阻协议。在较长的时间范围内,重点是预测剩余的可用寿命、寿命结束或电池寿命轨迹中加速退化的"拐点"。
这两种类型的预测方法可以细分为经验模型、基于物理的模型和数据驱动的模型,其中一些模型是这些模型的混合体。经验方法被用来建立长期容量随幂定律衰减的模型,但假设电池寿命是固定的,并且没有考虑到电池寿命开始时电池状态的内在差异。这些方法假定相同化学成分的所有细胞在以相同的方式运行时都会以相同的方式褪色,这在实践中是没有观察到的。在基于物理的方法中,电池要么使用内部物理和电化学过程的第一原理分析进行机械建模,要么使用等效电路建模,后者将电池建模为包含代表潜在电化学过程的电阻和电容器的电路。机械模型旨在捕捉电池电压如何响应外部施加的电流(反之亦然),这可用于预测最佳充电协议。然而,这种模型的参数需要为每个单独的细胞进行更新,并且通常存在不可识别性--几组模型参数可以同样很好地解释观察到的数据,但对测试细胞或同一细胞生命后期的预测会有很大不同。对于基于电路的模型,电路的参数可以根据电流-电压数据、或电化学阻抗频谱、进行拟合。然后,可以使用电路参数来预测标准化使用条件下的容量退化或模拟不同使用条件对电池组性能的影响。然而,要捕捉分析模型中的每一种退化模式是具有挑战性的。此外,必须为每个细胞从一个周期到另一个周期学习一组新的模型参数,这使得推断一般的细胞到细胞模型具有挑战性。
纯数据驱动的预测方法使用原始数据作为机器学习算法的输入,以预测长期容量衰减、电阻增加和剩余使用寿命。基于特征的数据驱动方法对从充电或放电曲线提取的特征应用机器学习,以预测放电容量、剩余使用寿命和容量突然衰减。在从充放电曲线中提取特征方面的创新,以及对时间序列数据进行建模的机器学习方法,使预测的准确性有了很大提高。进一步的研究表明,利用少数初始周期的放电曲线特征,有可能训练出适用于不同细胞化学的机器学习模型。除了充放电曲线之外,还使用了电化学阻抗谱(EIS)、早期循环库仑效率、电流中断和声学飞行时间分析等方法来预测降解。这些方法提供了对电池状态的更全面的描述--例如,EIS捕获电池在很宽的频率范围内的响应,不同的频率与活性材料、中不同的物理、化学和机械变化相关。数据驱动的方法通常利用实验室环境中产生的数据,在实验室环境中,电池在整个生命周期内以相同的方式充电和放电,因此可以忽略不同的电池使用对未来性能的影响(参见图1)。然而,将为实验室环境开发的模型外推到现场数据或其他实际使用情况,如全球协调轻型车测试循环(WLTC),其中电池在其寿命内以非常不同的方式循环,已被证明是一项重大挑战。
在这项工作中,我们试图确定是否存在一个足够信息的细胞健康标记,可以用于在历史和未来细胞使用不均衡的情况下预测短期和长期的未来表现。图1说明了我们的方法,以及它与以前的方法有何不同。我们发现,在充电前获取EIS频谱时,下一个周期和更长时间可以在测试误差小于10%的情况下预测术语电池容量。当对与用于训练模型的循环条件相似的细胞进行测试时,我们的模型达到了与最先进的预测模型相当的准确性(8.2%的测试误差对8.8%的测试误差),不同的是,我们的模型能够在不访问任何历史数据的情况下进行预测,而以前的最先进的模型需要来自细胞循环轨迹的历史数据。此外,当外推到不同的工作温度时,我们的模型显著优于最先进的模型,实现了57%的测试误差减少(从34.2%到14.6%)。
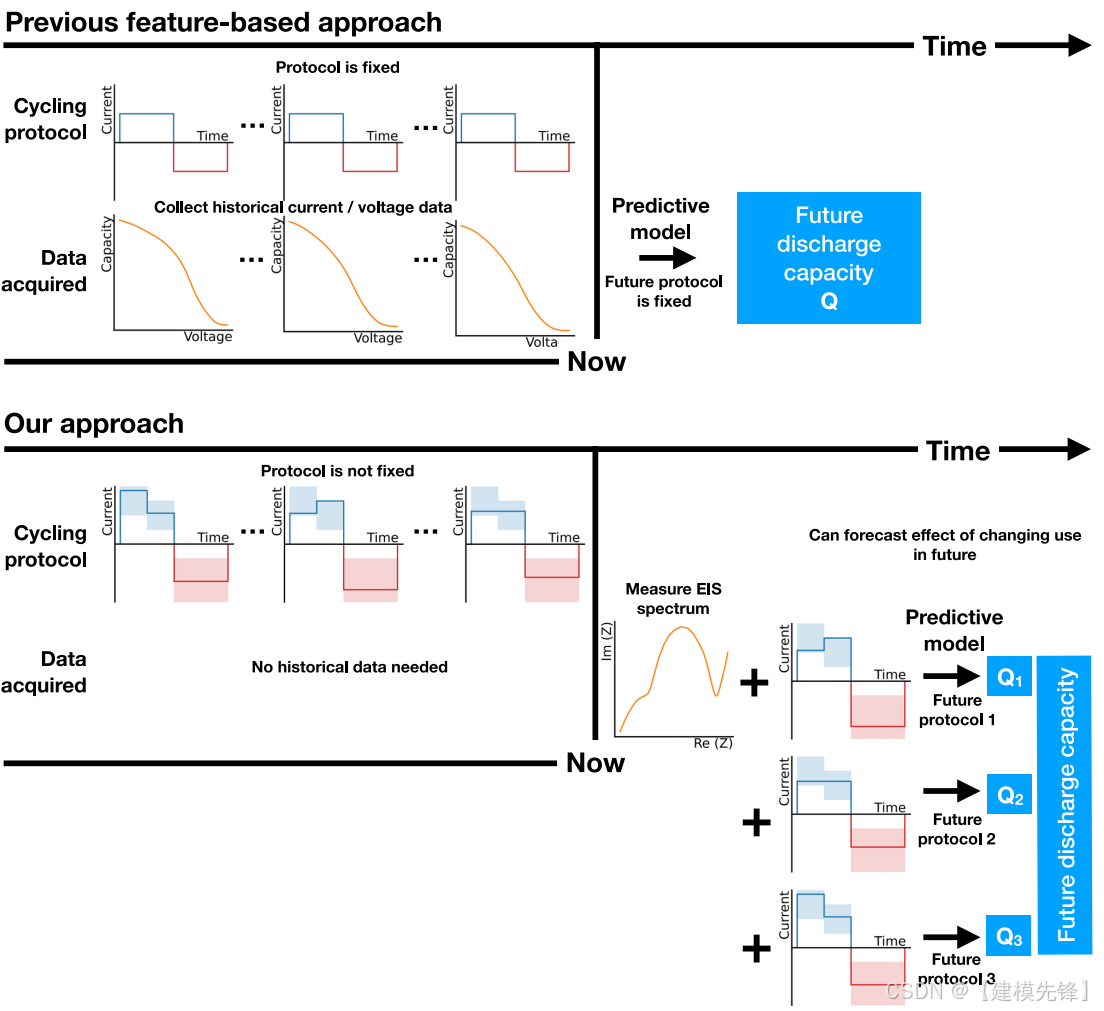
图1
我们观察到,我们的模型是数据高效型的,只需要8个单元就可以获得低于10%的测试误差。重要的是,我们的方法是健壮的数据集移动,在一个数据集上获得了不到7%的测试误差,其中训练集上的自行车模式分布不同。这对于在驾驶模式可能不同于用于训练模型的驾驶模式的现场部署非常重要。此外,我们还证明,如果可能,使用基于历史容量-电压数据的附加功能可以增强状态表示,并将平均测试误差减少高达25%。我们的方法在电池制造商、平均使用模式和工作温度方面是稳健的。
此外,我们的工作通过贡献动态工作条件下细胞的大量循环数据语料库,填补了公开可用数据的空白。我们的工作集中在一组理想化的使用分布上,而不是现实的驾驶轮廓上,以展示该模型的泛化程度。我们的工作偏离了NASA随机使用数据集,该数据集随机对电池进行50个循环,然后通过"参考"协议测量充电后的下一个循环的放电容量。尽管基于这些数据已经建立了几个在随机条件下预测退化的模型,但单一方案对下一周期放电容量的影响不能分开,并且需要每隔几个周期的参考充放电方案,这与典型的现场使用不一致。
3 结果
3.1 数据生成
对于这项研究,我们生成了两个独立的数据集,对应于从两个不同制造商购买的商业LIR硬币电池,这使我们能够测试我们的方法对于电池制造商是否稳健。

图2
第一个数据集对应于40个PowerStream LIR 2032个硬币单元(标称容量1C=35mAh.)。我们让24个电池接受随机选择的充放电电流序列,在23±2°C下进行110-120个完整的充放电循环。每个循环包括电池状态的初始诊断,包括恒流EIS谱的获取,然后是使用,包括充电和放电阶段。充电和放电分别由两级和一级恒流(CC)协议组成;电流分别在70-140 mA(2-4C)、35-105 mA(1-3C)和35-140 mA(1-4C)的范围内随机选择。为了测试模型对域漂移的稳健性,我们还在与上面相同的条件下对其余16个电池进行循环,只是现在将所有电池和循环的放电电流固定在52.5 mA(1.5C),而不是在每个循环随机改变放电电流。所考虑的协议空间如图2所示,补充图1提供了三个电池的容量轨迹的例子,以说明与典型的单调容量衰落实验的不同。在方法中提供了循环协议的完整描述,并且在补充表1中详细说明了每个电池所受的全套操作条件。
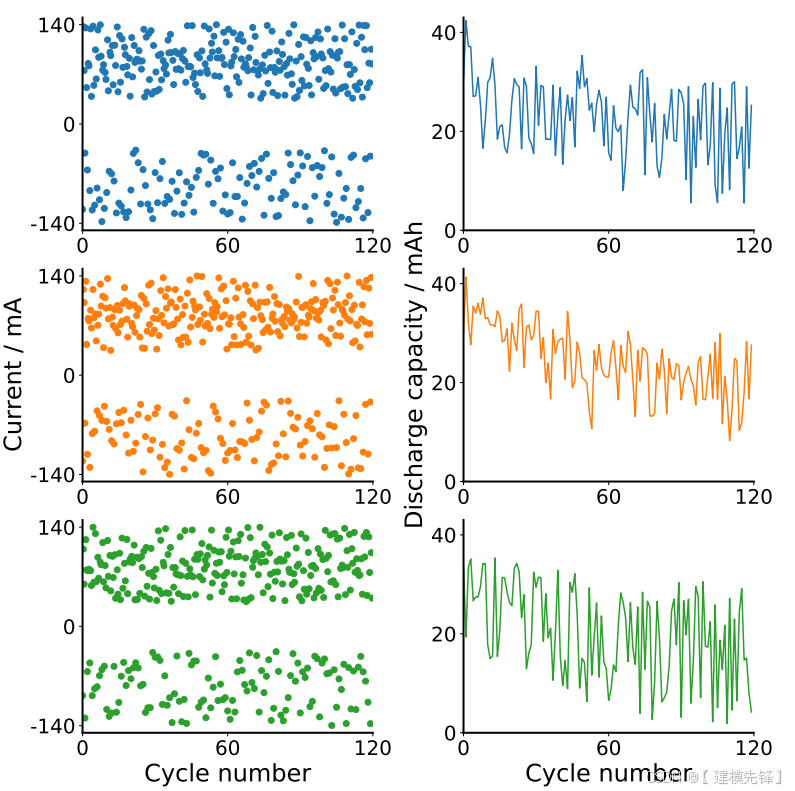
补充图1
补充表1
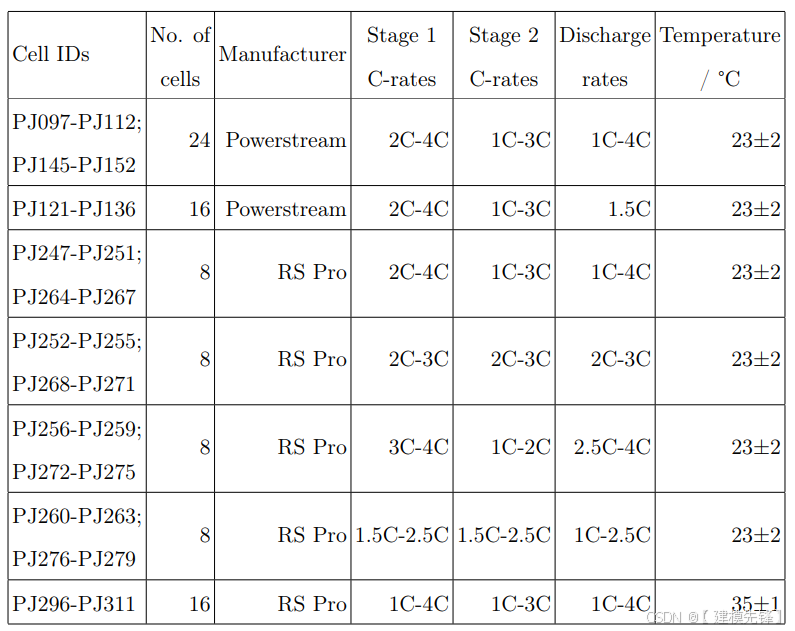
在使用第一个数据集确认该方法可以成功预测未来几个周期的放电容量之后,我们随后显著扩展了我们的分析,以探索该模型对电池制造商、使用模式和操作的稳健性温度。为了实现这一点,我们从第二家制造商RS Pro(标称容量40mAh)额外循环48个电池,在更广泛的使用模式下。在这种情况下,每个电池再次经历两级CC充电和一级CC放电的100个循环,在每个循环开始时随机选择三个速率。然而,我们现在通过为每个电池分配不同的电流来使问题更具挑战性,以复制不同电池用户彼此具有不同的平均使用模式,但仍然表现出随机的循环行为的情况。在这些电池中,有16个电池还在35°C的较高工作温度下循环。
3.2 利用EIS进行容量预测
我们首先考虑我们想要预测下一循环放电容量的设置,对于其使用历史(例如,周期或日历年龄,或历史容量-电压数据)完全未知的电池,如果我们应用特定的充电和卸货轮廓。我们将问题框定为一个回归任务,并训练一个概率机器学习模型来学习映射qn=f(sn,an),其中sn是第n个循环开始时的电池状态,An是未来的动作(第n个循环充放电协议),Qn是在循环结束时测量的放电容量。电池状态向量sn由57个频率测量的阻抗的实部(Zre)和虚部(Zim)分量串联而成,ω1,...,ω57,范围在0.02 Hz-20 kHz;sn=1/2 Zreüω1?,Zimüω1?,::,Zreüω57?,Zimçω57?作用矢量由第n个周期的充放电电流串联而成。
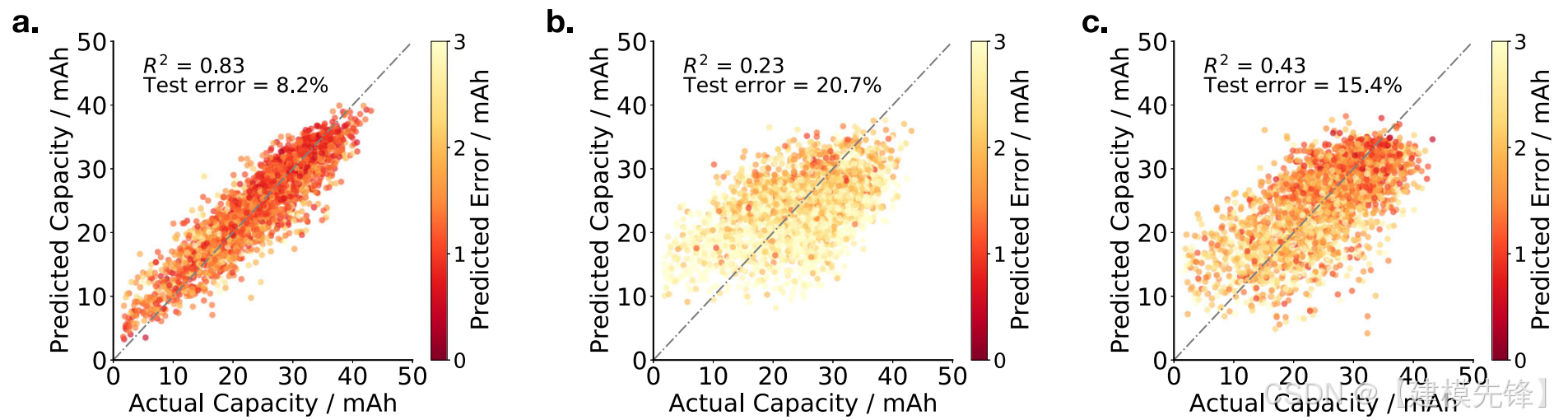
图3
图3说明了我们模型的准确性。同时采用状态和动作作为输入,预测下一循环的放电容量,平均误差为8.2%。重要的是,状态和动作(图3A)都被发现对预测未来电池的性能是必要的:如果仅使用状态(图3B)或动作(图3C)作为输入,测试误差大约翻一番,分别达到20.7%和15.4%。这说明电池的内部健康状况和外部选择的使用在确定实际电池性能方面的重要性。
对于优化充电和再利用分流等应用,重要的是电池寿命轨迹模型不仅可以预测下一个循环的放电容量,而且可以预测未来几个循环的容量。考虑到这一点,我们接下来研究模型的预测精度如何随着我们将模型推向未来而发生变化。在每种情况下,输入包括在第n个周期sn开始时的状态表示与包括将在周期n和周期n+j之间施加的所有充电和放电电流的'动作'向量an...n+j的串联。
图4显示了决定系数R2如何随j变化。正如预期的那样,模型的精度通常随着预测区间的增加而降低。然而,当预测未来40个周期时,该模型仍然达到R2=0.75。
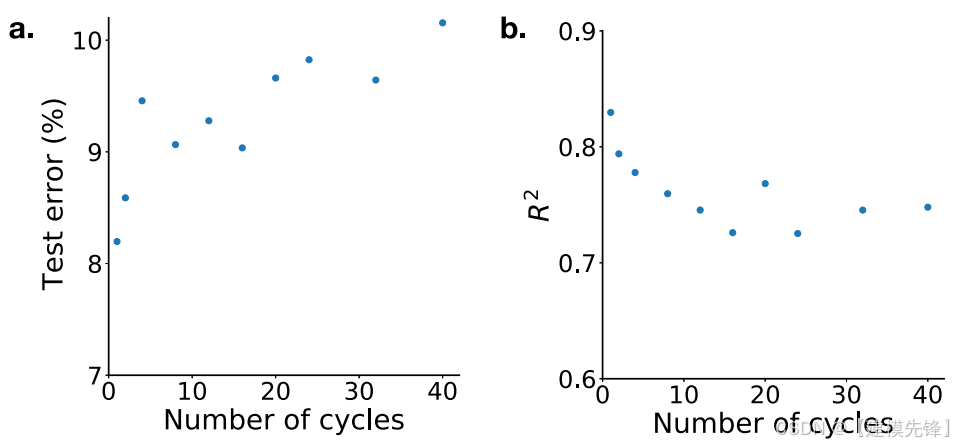
图4
3.3 数据效率和对域转换的稳健性
接下来,我们通过调查数据效率和模型泛化来测试我们方法的健壮性。为了测试数据效率,我们测量了随着用于训练模型的单元数量的增加,性能如何变化。如图5所示,随着单元数量从2个增加到22个,测试误差从23.8%显著降低到8.2%。然而,该模型显然是数据高效的,只需要8个单元就可以获得低于10%的测试误差。
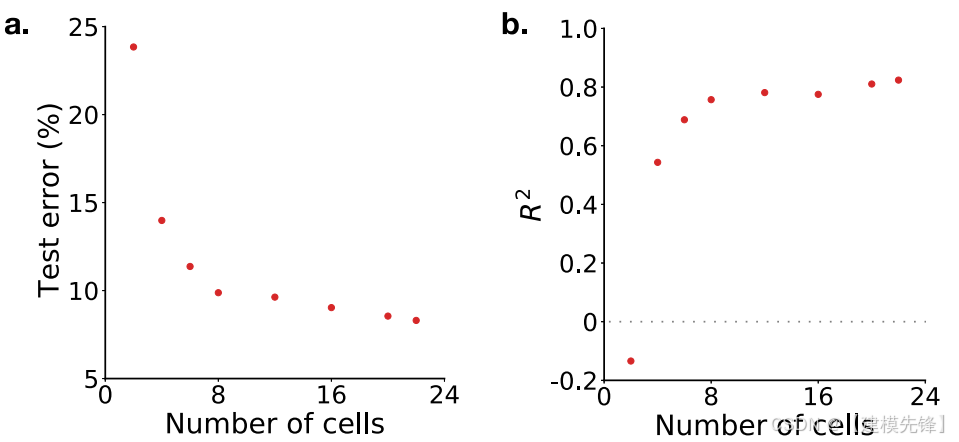
图5
模型通用性的一个重要测试是研究当域分布发生变化时,即当模型部署在与训练数据不同的环境中时的模型准确性。这对现场部署很重要,因为该方法需要对可能与培训数据不同的驾驶模式保持健壮。我们通过循环来自同一制造商的另外16个电池来测试模型的稳健性,但现在通过将每个电池在其整个生命周期中的放电电流固定为1.5C来调整循环协议。我们使用一个只使用在其生命周期中受到随机放电电流的电池来训练的模型来预测受到固定放电的电池的下一周期放电容量。为了说明训练和测试数据集的差异,图6A显示了每个数据集的放电容量分布。
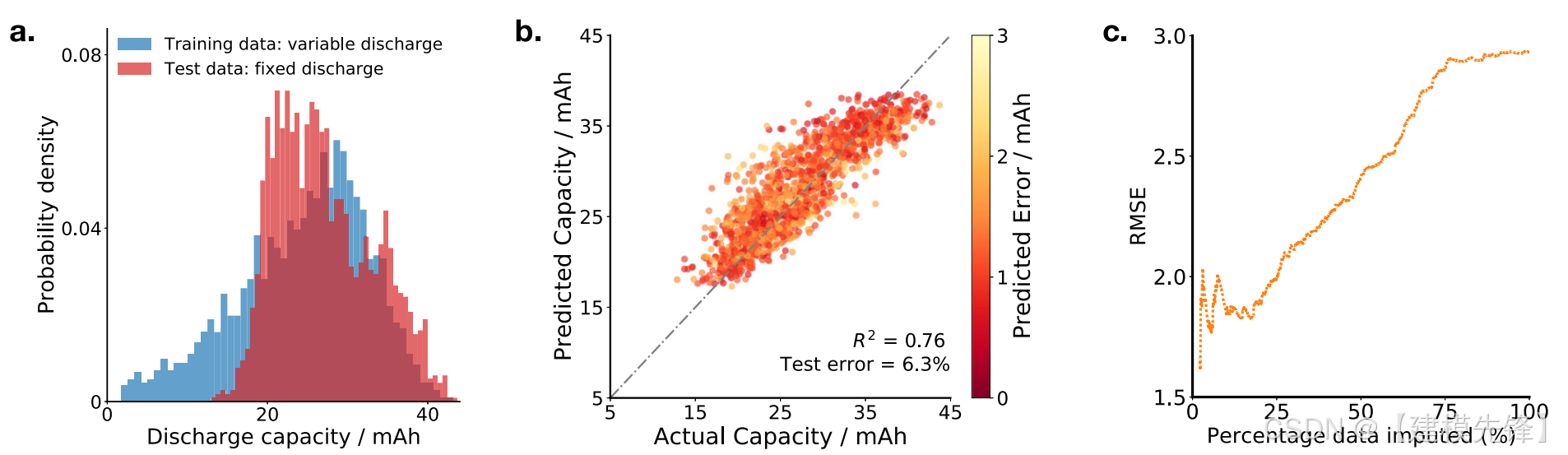
图6
模型在固定流量数据集上的预测精度如图6B所示。有希望的是,该模型在这个域移动的数据集上的测试误差仅为6.3%,对应于R2=0.76。
我们的模型还输出预测不确定性,这表明该模型对其预测质量的确定程度。在域转移的设置中,尤其重要的是,模型"知道它不知道的东西",并估计关于它可能获得高误差的数据点的高预测不确定性。我们可以通过观察平均测试误差随着数据点的数量减少而变化,以仅包括模型最有信心的数据点,来测试模型估计其不确定性的能力。如果A模型可以成功地估计其确定性水平,那么随着数据的比例减少到只包括最有信心的预测点,平均测试误差应该会减少。图6C显示了当数据比例从100%减少到最有信心的25%时,均方根误差(RMSE)减少了32%,这表明我们的模型已经学习了它应该相信的预测。
3.4 状态表示的比较
在展示了EIS频谱捕获电池状态的能力后,我们现在将这种电池健康状况的表示与文献中使用的其他方法进行基准比较,包括最先进的基于特征的方法,并考虑EIS频谱是否有其他功能可以用于增强电池状态。用于预测或估计电池SOH的简单方法包括使用前一个循环的放电容量,或循环开始以来的容量吞吐量。更高级的方法包括提取历史容量-电压放电曲线的特征,如图1所示。Severson等人实现了最先进的特征提取方法,并启发了Attia等人最近使用的特征提取方法。和Paulson等人的。我们基准我们的基于EIS的方法相对于那些最先进的功能表现如何。
表1
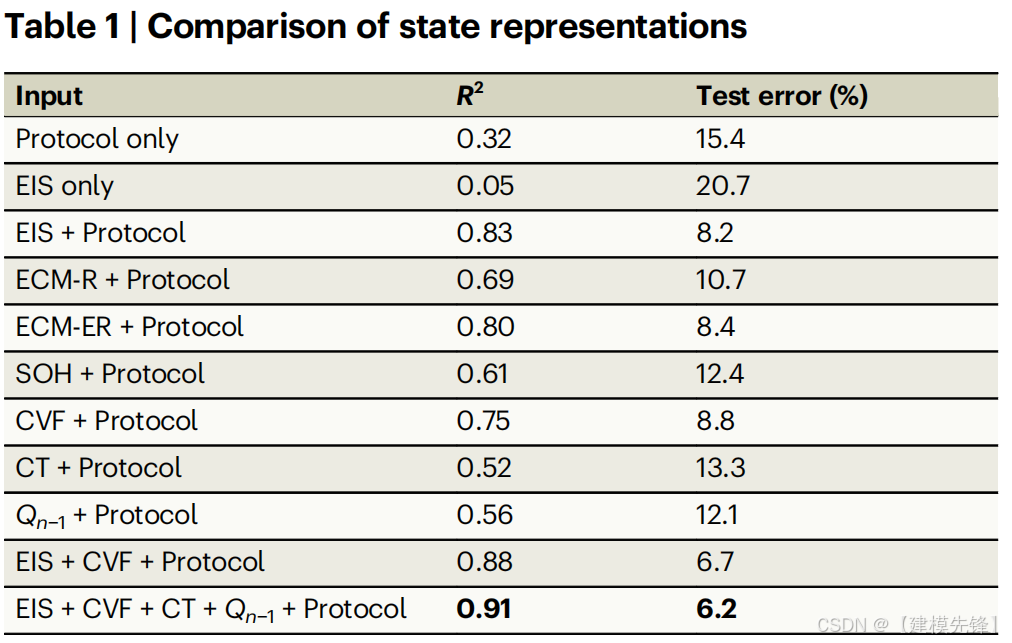
表1显示了状态表示如何影响测试误差和模型的拟合优度。在所有情况下,在给定下一周期协议和所选状态表示的情况下,对模型进行训练以预测下一周期的放电容量。在询问功能的相对重要性时,我们首先考虑仅使用EIS(不包括协议)和仅使用协议(不包括EIS)的基线。也许并不令人惊讶的是,电池退化是当前状态和未来充放电协议的函数。因此,同时使用EIS和协议显著优于仅使用EIS或仅使用协议。
3.5 对不同电池制造商的稳健性
我们现在扩展我们的分析,以探索我们的方法在改变电池制造商、调整运行温度和调整平均使用模式方面的健壮性。我们在另一家制造商RS Pro的新一批32个商用锂离子电池(额定容量1C=40mAh)上重复我们的实验,除了我们现在通过将不同的细胞亚组置于四种不同的使用分布中的一种来使问题变得更加具有挑战性。这些使用情况的分布载于补充表1。
表2
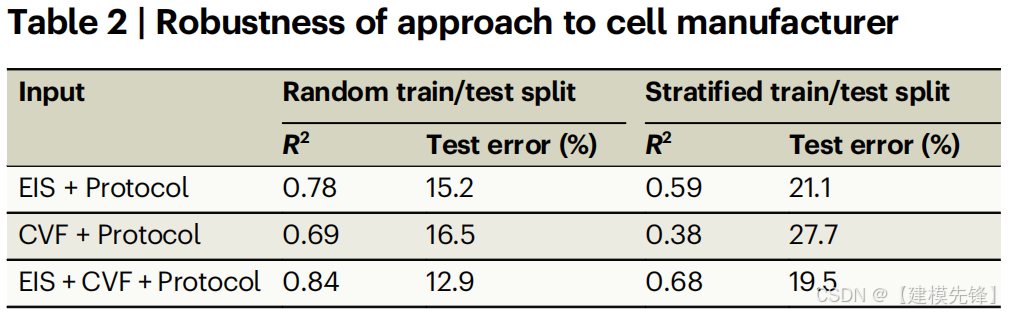
表2显示了不同状态表示的结果,既有列车/测试拆分是随机的情况,也有拆分分成不同使用模式的情况。对从第二制造商购买的电池进行了类似的观察:即,当使用EIS谱的特征与从放电曲线(CVF)形成的特征一起形成状态表示时,做出最准确的预测。正如预期的那样,当模型使用来自一些细胞的数据进行训练时,该模型的性能要好得多,这些细胞暴露在与模型测试的细胞相似的循环模式分布中。然而,该模型在脚手架分裂的情况下仍然表现良好,在这种情况下,当使用EIS谱与放电曲线的特征一起形成状态表示时,测试误差减少了30%,而不是仅使用放电曲线的特征。这些额外的结果进一步证明,如果有的话,EIS谱和放电曲线都可以作为电池内部状态的信息标记,但它们是相辅相成的。
表3
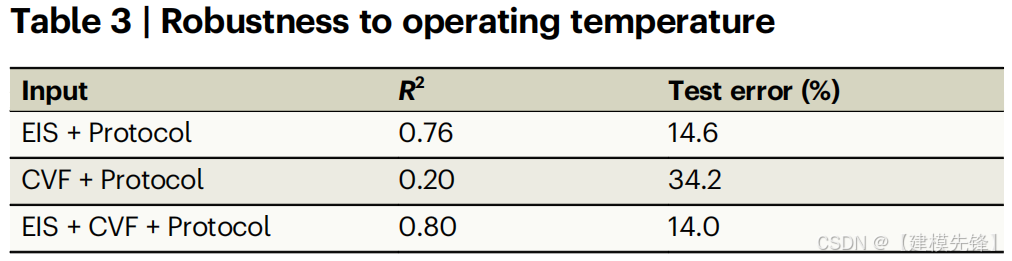
接下来,我们验证了模型对于外部工作温度变化的健壮性。我们在35°C下循环另外16个电池,并使用室温循环电池的数据来测试训练的模型。表3显示,我们的模型可以外推到在更高温度下运行的电池,但在表征电池不在相同温度下运行时的电池状态方面,EIS光谱起着特别重要的作用。当仅用放电曲线特征描述状态时,该模型的测试误差为34.2%,而当同时使用交流阻抗谱和放电曲线特征时,该模型的测试误差为14.0%。这进一步证明了EIS信号包含的相对于充放电曲线的附加信息,并支持EIS隐含跟踪温度的假设53。
4 讨论
在本文中,我们证明了电化学阻抗谱可以准确地描述电池的内部状态,并且可以训练机器学习模型来准确地预测具有预测不确定性的电池的短期和长期性能,即使在不均匀和未知的历史电池使用的情况下也是如此。我们的模型实现了当测试单元的运行条件分布与用于训练模型的单元相同时,准确度(8.2%测试误差)与最先进的预测方法(8.8%测试误差)相当。然而,如图1所示,最先进的方法需要访问历史循环数据,而我们的模型可以在没有历史数据的情况下进行预测。此外,当外推到更高的工作温度时,我们的模型显著优于最先进的模型,测试误差降低了57%(从34.2%降低到14.6%)。
我们的方法是数据高效的,仅用8个单元的训练数据就实现了9.9%的下一周期测试误差,并且对数据集分布的变化具有很强的鲁棒性。此外,我们发现,如果历史循环数据可用,则可以将模型性能提高25%;这些数据可用于派生增强单元状态表示的功能。我们证明,我们的方法可以用于不同的电池化学,并且该模型对不同的操作温度是稳健的。
我们注意到,在给定当前电池状态和未来动作的情况下,我们为预测未来电池性能而制定的通用框架具有在广泛的电池诊断和控制设置中应用的范围。例如,预测所建议的充电协议对下一周期放电容量以及长期退化的影响对于优化快速充电应用51非常重要,在快速充电应用中必须在充电时间和电池退化速率57之间取得平衡。我们的工作还可以扩展到考虑更复杂的动态使用协议,如WLTC。
后台回复"锂电池10",可获取我们已经打包好的论文、数据集和代码!
