这是一篇来自麻省理工学院(MIT)Kaiming He(何恺明)团队等人的最新重量级论文《ELF: Embedded Language Flows》。
这篇论文旨在解决如何用扩散模型/流匹配模型(Diffusion / Flow-based models)高效生成文本 的问题。它提出了一种极简且极其有效的连续型语言扩散模型架构------ELF,在生成质量、采样速度和训练数据效率上,全面超越了目前最先进的离散扩散语言模型。
以下是对这篇论文的详细深度解读:
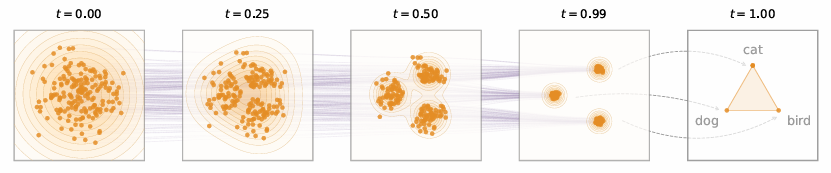
ELF 原理示意图。橙色圆点代表连续嵌入空间 中的语言数据;紫色线条表示从高斯噪声逐步还原至干净嵌入的去噪轨迹 。模型仅在最终时间步(t=1t=1t=1) ,通过权重共享网络完成离散化映射。
1. 研究背景与核心痛点
- 背景:扩散模型在图像和视频生成(如Sora, Midjourney)中取得了统治地位,但在自然语言处理(NLP)领域,自回归模型(如GPT系列)依然是绝对的主流。
- 痛点 :文本是离散 的(一个个单词/Token),而传统的扩散模型是建立在连续 空间上的。为了把扩散模型用在文本上,学术界分成了两派:
- 离散扩散模型(Discrete DLMs):直接在Token空间做扩散(如MASK、替换等)。目前这一派表现最好,是主流。
- 连续扩散模型(Continuous DLMs):把Token映射成连续的词向量(Embedding),加高斯噪声再降噪。但这一派因为离散-连续边界处理得不好,一直表现不佳。
- 论文假设 :连续扩散模型表现差,不是因为它天生不适合文本,而是算法设计没找对。
2. ELF 的核心创新机制(它是怎么做的?)
ELF(Embedded Language Flows)主打"极简主义",尽可能保留图像扩散模型中成熟的连续空间玩法,只在最后一步做离散化。
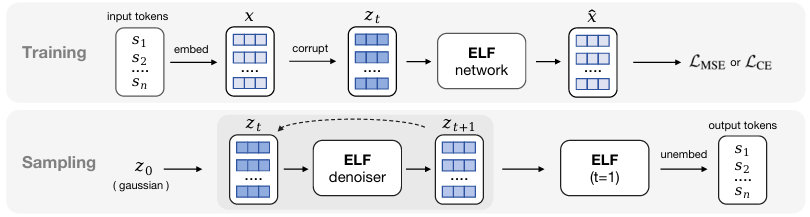
训练阶段,离散词元被编码为干净嵌入向量x\boldsymbol{x}x,再加噪得到带噪嵌入ztz_tzt,ELF 利用该带噪嵌入预测重构嵌入x^\hat{\boldsymbol{x}}x^。模型采用去噪均方误差损失LMSEL_{MSE}LMSE 或逐词元交叉熵损失LCEL_{CE}LCE 进行训练。推理阶段,ELF 从高斯噪声z0z_0z0出发,迭代地将嵌入向量从ztz_tzt去噪更新至zt+1z_{t+1}zt+1;仅在最后一步,ELF 切换为解码模式,通过反嵌入层将最终的连续嵌入向量映射回离散词元。
① 从离散到连续:冻结的上下文词向量
ELF 放弃了从头训练词向量,而是直接使用了一个预训练好的 T5 模型的 Encoder 来把文本变成连续的上下文向量(Embedding)。并且在整个训练过程中,这套转换规则是冻结(Frozen)的。这为扩散模型提供了一个非常稳定且富含语义的连续空间。
② 连续时间的流匹配(Flow Matching)
在连续空间里,ELF 没有用传统的 DDPM,而是采用了目前图像生成(如 Stable Diffusion 3, FLUX)最先进的 连续时间流匹配(Flow Matching, 具体为 Rectified Flow) 技术。它构建了一条从纯高斯噪声到干净文本向量的直线轨迹。
③ 关键设计:预测 xxx 而不是预测噪声/速度
在流匹配中,网络可以预测噪声(ϵ\epsilonϵ)、速度(vvv)或目标干净数据(xxx)。论文发现,在文本这种高维嵌入空间里,预测 ϵ\epsilonϵ 或 vvv 会直接崩溃,必须直接预测干净的文本向量(xxx-prediction)。这也是模型能成功的关键基石。
④ 摒弃独立解码器(Shared-weight Network)
以前的连续扩散模型,往往需要额外训练一个 Decoder 来把降噪后的向量变回文字。
ELF 的做法极其巧妙:降噪器和解码器是同一个网络。
- 在时间步 t<1t < 1t<1 时(降噪阶段),网络使用均方误差(MSE Loss)学习如何从噪声中预测干净的向量。
- 在时间步 t=1t = 1t=1 时(最后一步),网络切换到"解码模式",直接接一个线性层(Unembedding),使用交叉熵(Cross-Entropy Loss)预测离散的 Token。
这样做不仅省去了额外的参数,还让连续降噪和离散解码在同一个表征空间内对齐。
⑤ 引入无分类器引导(CFG)与训练时 CFG
在连续扩散模型(尤其是图像扩散模型,如 Stable Diffusion等)中,无分类器指导(Classifier-Free Guidance, CFG) 已经是标配。然而,传统的离散文本扩散模型由于无法自然处理"连续的扰动/引导",很难引入这一技术。ELF(Embedded Language Flows) 正是因为将生成轨迹完全保持在连续的嵌入空间(Continuous Embedding Space)中,因此能够直接且完美地迁移图像领域的 CFG 训练和推理机制。
在 ELF 中,Training-time CFG(训练阶段的无分类器指导) 的核心就是"随机给模型断网/不给提示",让同一个网络同时学会"看提示生成"和"盲盒盲猜":
- 设定概率: 在训练时,每次有 15% 的概率把上文提示(Context)藏起来,替换为空白(Null);剩下 85% 的概率正常提供上文。
- 混合训练: 让同一个去噪网络在有提示和没提示(空白)的数据上混合训练,从而同时学会条件生成 和无条件生成两种本领。
推理(生成)时怎么用:
生成文本时,让模型把"有提示的结果"减去"没提示的结果",得到上文对生成的"净引导方向",然后乘以一个大于 1 的放大系数。这样能大幅强化生成内容与上文的关联性,让逻辑更连贯。
3. 实验结果(它有多强?)
论文在无条件生成(OpenWebText)和条件生成(机器翻译 WMT14、文本摘要 XSum)上进行了测试。
- 全面碾压现有 Baseline:无论是对比最强的离散扩散模型(MDLM, Duo),还是同期的连续扩散模型(FLM, LangFlow),ELF 都取得了更低的生成困惑度(Generative Perplexity)和更好的多样性(Entropy)。
- 极高的数据效率(Data Efficient) :现有的扩散语言模型动辄需要 500B(5000亿)个 Token 来训练。ELF 仅仅使用了 45B(450亿)个 Token(大约十分之一的数据),就达到了更好的效果。
- 步数更少(Few-step Generation):不使用任何蒸馏技术的情况下,ELF 在 32 步采样时就能达到极佳的质量,甚至打败了其他经过"少步数蒸馏"的基线模型。
- 机器翻译与摘要:在同等参数规模下(105M),ELF 在 BLEU(翻译)和 ROUGE(摘要)指标上均创下最佳成绩。
4. 为什么 ELF 能成功?(核心 Ablations 分析)
作者做了一系列详尽的消融实验,揭示了成功的几个秘密武器:
- SDE 采样器 > ODE 采样器:在采样时,如果纯靠确定性的 ODE 采样,误差容易累积。如果在每一步注入一点点随机噪声(SDE 采样),可以在步数较少时显著提升文本质量。
- 瓶颈结构(Bottleneck):模型输入是 512 维的向量,ELF 先将其压缩到 128 维,再放大回 768 维输入 Transformer。这种"沙漏"结构强制网络学习低维流形,过滤了高维空间的无用信息。
- Logit-Normal 时间调度 :推理时不去均匀切分时间,而是把更多的步数分配给高噪声阶段(ttt 接近 0 的阶段),这大大提高了采样效率。
- Muon 优化器:使用最新的 Muon 优化器比传统的 AdamW 效果更好(尤其在 SDE 采样下)。
5. 论文的意义与总结
过去两年,由于离散扩散语言模型(如 MASK 扩散)的强势表现,学术界很多人开始对"连续向量空间"的语言扩散模型感到悲观。
但 Kaiming He 团队的这篇《ELF》证明了:只要解决好连续-离散边界(用共享权重的单网络处理最后一步)、选对参数化目标(xxx-prediction)、并引入高质量的预训练上下文特征(T5 Encoder),连续扩散语言模型完全可以打败离散扩散模型。
这为统一视觉(连续)和语言(离散)的生成范式(如未来的原生多模态大模型)铺平了一段重要的道路。文本不再需要一套特殊的离散扩散算法,我们完全可以用生成图像的同一套数学工具(流匹配 + CFG + 连续向量)来生成极高质量的文章。