0. 引言:为什么要学分词器
分词器常被视为LLM的一部分,但它其实有独立的训练生命周期。
Tokenizer本质上是将原始文本转换为模型可处理的离散符号序列的组件,它可以决定模型看到世界的基本粒度:是字符、单词、子词,还是字节片段,而这个粒度的选择会进一步影响序列长度、OOV、词表的规模还有训练效率等。
显然模型并不能直接处理文字,模型的上下文也并不是无限的,那么一个好的合适的Tokenizer便是影响模型效果甚至是否可用十分重要的因素。所以我们需要学习Tokenizer,了解其基本训练流程、种类和主要的评价指标。
1. 分词器的整体训练流程
- 准备语料
- 初始化基础单元
- 统计并迭代更新
- 输出产物并用于编码与解码
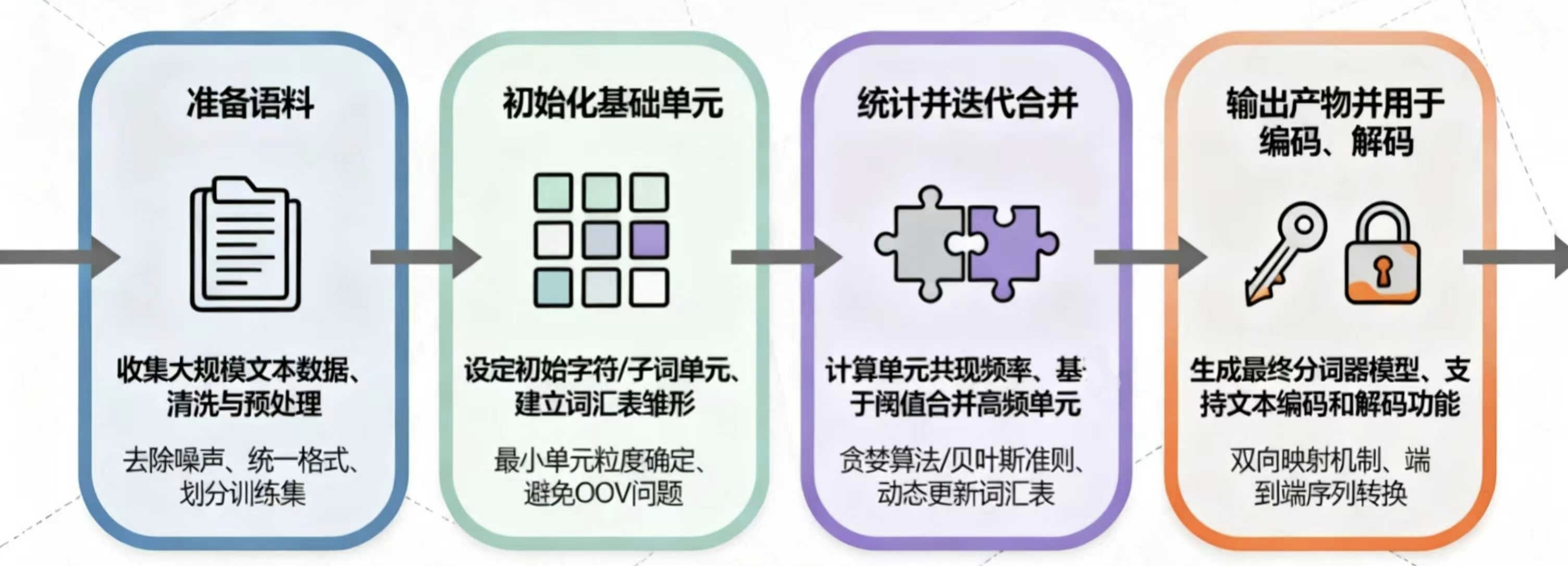
分词器训练是一个有如上四个步骤的完整流程。
不同分词算法的差异,将主要体现在"初始单元如何选"、"相邻片段如何合并"、"何时停止迭代"这三个问题上。
2. 预处理
Tokenizer的输入并不是原始文本本身,而是经过清洗、脱敏、预分词后得到的可统计序列。后续所有BPE、WordPiece、Unigram的统计学习,都是建立在这个输入之上。
2.1 数据脱敏
- 高确定性规则先处理,如手机号、邮箱;
- 中确定性规则再处理,如地址关键词;
- 低确定性规则最后兜底,如姓名模板;
- NER,即命名实体识别(Named Entity Recognition,NER)技术,则补充语义级脱敏。
脱敏不仅仅是出于隐私保护考虑,更是在降低高熵、低复用的信息对统计学习的干扰,有利于下面分词过程和模型的稳定性。
2.2 多语言语料
应该根据模型目标能力设定合适的采样策略,避免词表被高频的语言(英文/中文)主导,会挤占低频语言"merge"的机会,加剧token碎片化。
2.3 预分词
预分词的主要任务是将原始文本切分成可统计、可合并的基础单元,例如字符、字节或Unicode片段。
常见策略:
- 基于空格和标点的切分
- 按Unicode类别划分
- 字节级切分
并不是所有的分词器都需要显式进行预分词。例如基于SentencePiece的分词器将标准化和预分词逻辑内置,因此无需在外部额外执行预分词步骤。
3. 常见分词器的原理与优缺点
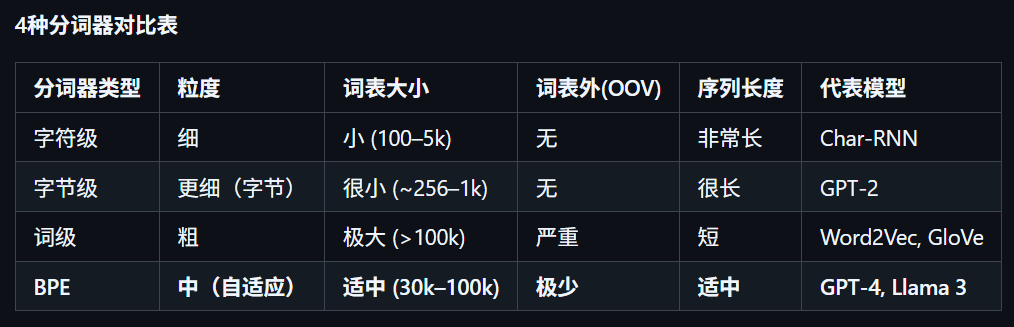
3.1 字符级
原理:将文本拆解为最小的字符单位即单个字符。
优点:词表小(英文26个字母,中文几千个汉字)、无OOV(任何词都是字符组成的)。
缺点:序列太长、语义稀疏(单个字符一般不具什么语义,需要更深的网络来组合出语义)。
适用场景:中文等无空格语言、低资源小语种、短文本对话。
3.2 字节级
原理:在UTF-8编码中,英文字母占1个字节,汉字占3个字节,直接对二进制字节进行操作。
优点:基础词表固定为256,天然覆盖所有字符和emoji,无OOV。
缺点:压缩率恒为1(一个字节就对应一个token),无压缩能力。
适用场景:多语言混合、生僻字、特殊字符。
3.3 词级
原理:深度学习早期(如RNN时代)最主流的方法。基于空格(英文)或分词算法(中文)将文本切成有独立语义的"词"。
优点:语义完整、token数少。
缺点:词表爆炸(语言中词很多),OOV严重(人名、新造词等)、中文分词容易产生歧义。
适用场景:语法规则规范、词汇固定的领域,如:新闻、公文、正规书面语。
3.4 BPE
原理:目前LLM最主流的分词算法,统计相邻字符对出现的频率,迭代地将最频繁出现的字符对合并成一个新的Token。
优点:在字符级和词级之间取得平衡,通过统计学习得到高频子词。
缺点:训练过程更复杂,需要迭代统计和合并。
适用场景:目前主流。
4. BPE核心逻辑
BPE(Byte Pair Encoding)是一种基于频率统计的贪心合并算法,是在字符级过细和词级过粗之间寻找平衡。其核心思想如3.4所说,非常简单。
BPE不是一次统计,然后一直合并,而是一个不断循环的过程:
- 定义初始基础单元
- 统计所有相邻pair的频率
- 找到最高频pair
- 合并为新token
- 用新token重写语料
- 重复直到达到目标词表大小或继续合并收益很小为止
因此,BPE的本质可以理解为一种数据驱动压缩:让高频同现的片段逐渐变成更长更稳定的子词单元,从而减少token数量,同时降低OOV。
5. DeepSeek 分词器细节:为什么字节级 BPE 要借助 latin1
DeepSeek风格tokenizer的一个关键工程点,是在字节级BPE中使用latin-1做了中间编解码。
原因在于BPE训练实现需要把字节按"字符"来操作,因为BPE完全不管你是不是一个完整的字而是字节片段高频同现就合并,所以一些中文的token的字节数可能不是3的倍数(一个汉字3个字节),压根就不是正常的中文词组,如果使用UTF-8解码,汉字、emoji等多字节字符的字节序列会因不完整而导致信息丢失。
而latin-1可以把0--255的每个字节值机械地映射为一个Unicode字符,并且这个映射是可逆的,这样就可以直接拿这些字符去操作,之后再反向还原。
所以:
- UTF-8负责把原始文本变成字节流
- latin1负责把字节流映射成"字符"
- BPE再在这个壳上做pair合并
使用latin1的目的,是为了确保任意字节序列都能完整、可逆地参与BPE训练与编码过程。
6. 压缩率、OOV 与效率评估
6.1 压缩率
压缩率可以理解为:同样一段文本,被编码后是否足够紧凑。
常用的口径是:
原始UTF-8字节长度 / token数量
token 越少,通常说明压缩率越高,表示效率越好。
字节级分词器的压缩率恒为1,而BPE的优势在于能够通过学习高频片段减少token数量,实现数据驱动压缩。
6.2 OOV
OOV是当LLM模型在处理新的、实际应用的文本时,如果遇到一个词汇表中没有的Token,那么这个Token就被视为一个OOV。
-
词级分词器最容易出现OOV,因为新词、人名等词一旦不在词表中,就只能映射成
<UNK> -
字符级和字节级天然没有OOV,因为任何文本都能拆成字符或字节
-
字节级BPE进一步通过"合并token→字节token→
<unk>"的回退链增强了鲁棒性,从以下代码中可以体现:pythondef encode_chunk(self, chunk: str) -> List[str]: """ 对一个预分词做BPE编码: - 转字节token - 逐步应用merges - 处理OOV:未知token拆回字节或标记为<unk> """ ...... # OOV token拆回字节 out = [] for t in tokens: if t in self.token2id: out.append(t) else: # 拆分成字节token,如果字节token也不在词表 → <unk> out.extend([ch if ch in self.token2id else self.unk_token for ch in t]) return out
6.3 效率评估指标
训练完成后,应关注这些指标:
- 平均token数
- 最大长度分布
- 碎片化程度
- 跨语言token平衡度
这些指标会直接影响模型的上下文利用率、训练显存开销和推理速度。
7. 理解与反思
Tokenizer本身并不理解语义,它更像一个基于统计规律和工程约束来构建离散输入空间的模块。真正的"语言理解"发生在后续Transformer中,但显然更合理的token划分,会直接影响模型训练的稳定性、上下文窗口的利用率以及处理多语言和特殊字符的能力。
我认为最有价值的并不只是BPE的合并逻辑,而是它背后的工程问题:如何处理多字节字符,如何保证编码可逆,如何处理OOV,如何平衡压缩率与跨语言能力,以及如何进行版本管理和回归测试保证训练与推理的一致性。
最后提出的思考也很有启发性:tokenizer不一定只是静态前处理模块,可以与更动态的选择机制结合,例如借鉴MoE的思想,在不同任务之间自适应选择更合适的表示方式;或者通过某些机制使训练好的分词器仍能在下游任务中动态优化;还可以利用强化学习等方法让分词器能从少量样本中学习最合适的token划分方式。
最后又回到开头,Tokenizer并不是一个附属小模块,而是连接原始文本与大模型训练之间的重要桥梁。
8. 关键代码解析
原文"2.3.2 DeepSeek分词器的处理逻辑"下面关于训练BPE的代码很值得一看,但是并不需要摸清每一行的细节,重要的是这些函数如何组成完整的流水线。
pretokenize
作用:先按正则把文本切成chunk。
意义:避免整句直接进入BPE,减少无意义的跨块合并。
build_corpus
作用:把每个chunk转成UTF-8字节序列,再进一步转成可操作token序列。
意义:构建BPE训练使用的底层语料。
pair_freq
作用:统计整个语料中所有相邻token pair的频率。
意义:决定当前最值得合并的方向。
merge_pair
作用:把指定pair在token序列中替换成新token。
意义:完成一轮合并,并重写语料。
train_bpe
作用:把"统计→选最高频 pair→合并→重写语料"串成完整训练循环。
意义:这是BPE的核心训练过程。
encode_chunk
作用:对单个chunk应用已学到的merges规则进行编码。
意义:除了正常合并外,它还体现了工程上的OOV处理逻辑:如果合并后的token不在词表中,先拆回字节token,再不行才退化到 <unk>。
所以从代码层面看,BPE的核心不只是贪心合并,而是一条可训练、可编码、可逆、可解码的闭环。