引言:当数字游戏遇上人工智能
想象一下,你面对一个5×5的数字网格,数字1-25随机分布其中。你的任务很简单:按顺序点击1、2、3...直到25。这听起来很简单,对吗?但当你需要在30秒内完成,并且有AI对手与你竞争时,事情就变得有趣了。
今天,我们将用Python的Pyglet框架创建这个"数字猎人"游戏,并探索如何为它注入人工智能。这不仅仅是又一个游戏编程教程,而是从零开始构建一个可玩、可学、可AI优化的完整项目。
为什么选择Pyglet + AI的组合?
在开始之前,让我们先理解这个技术组合的优势:
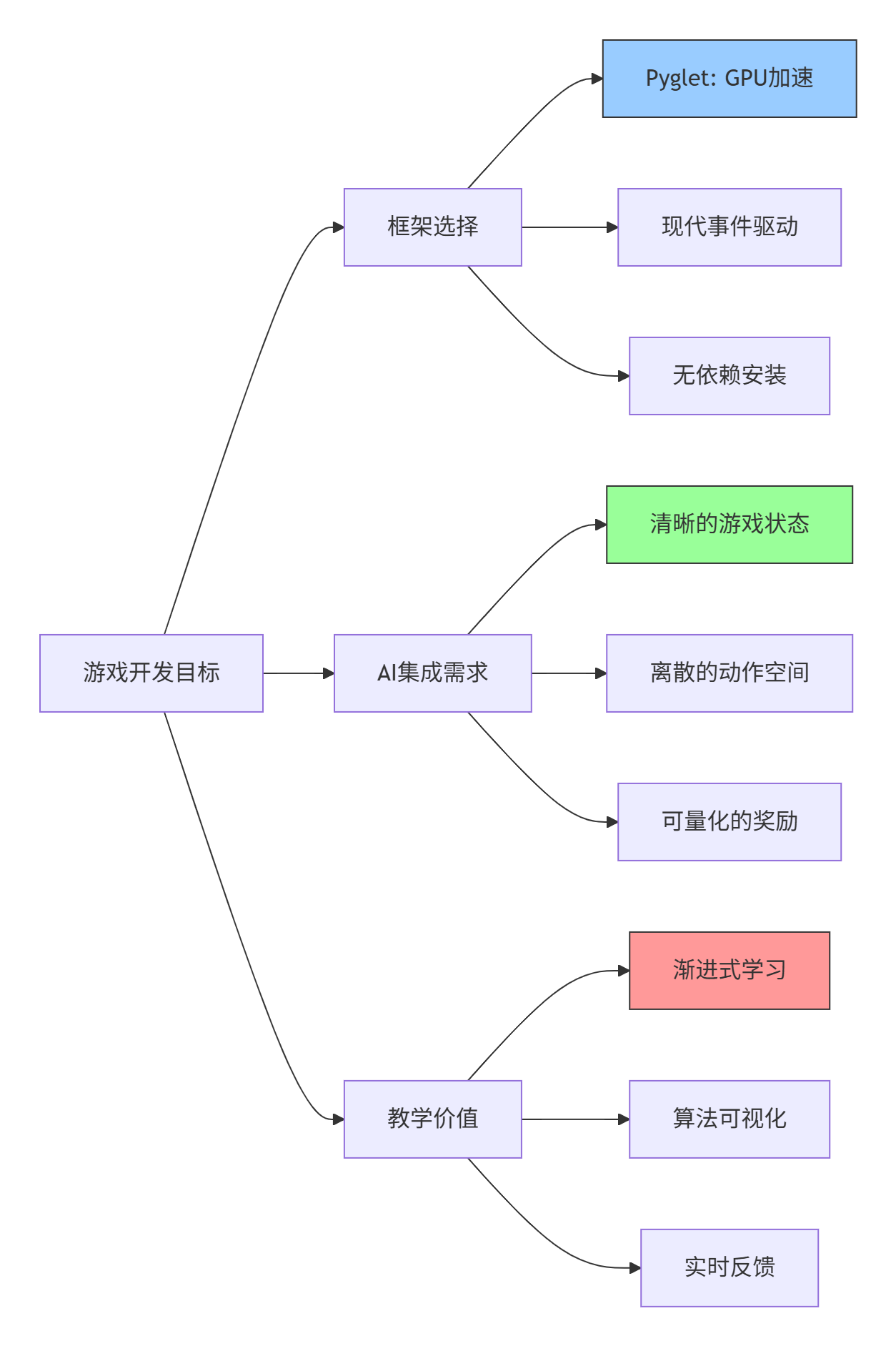
Pyglet的优势
-
纯Python实现:无需复杂的环境配置
-
硬件加速渲染:利用现代GPU性能
-
事件驱动架构:代码结构清晰,易于理解
-
轻量级:无额外依赖,专注于游戏逻辑
AI友好设计
数字猎人游戏特别适合AI学习,因为:
-
状态空间有限:25个格子,离散可枚举
-
动作空间明确:点击25个可能位置
-
奖励信号清晰:正确点击+10,错误-5,完成+100
-
训练速度快:一局游戏只需30秒
第一部分:游戏架构设计
1.1 系统架构概览
在开始编码之前,让我们用图表理解整个系统的架构:
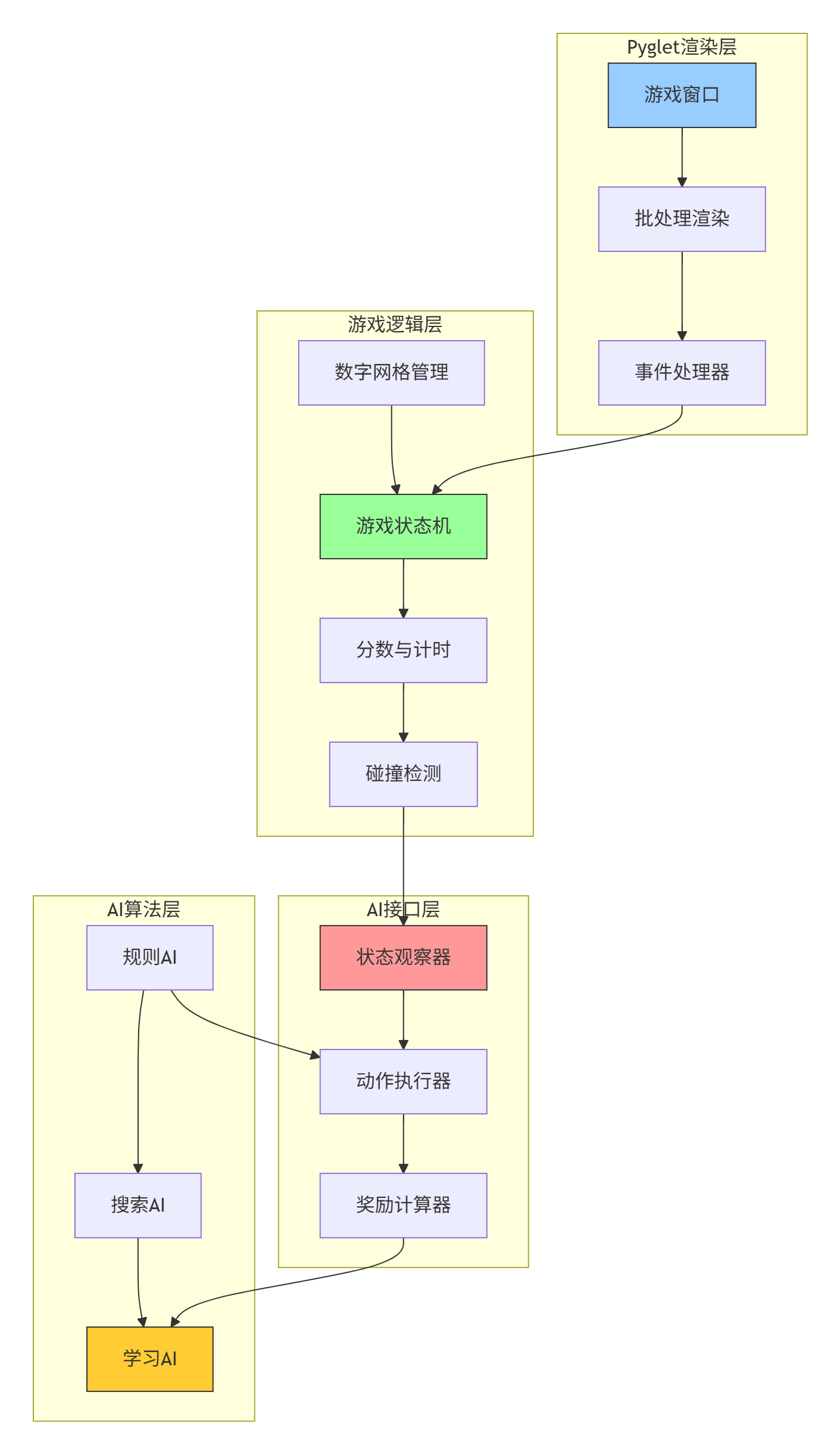
1.2 核心类设计
我们的游戏将围绕以下几个核心类构建:
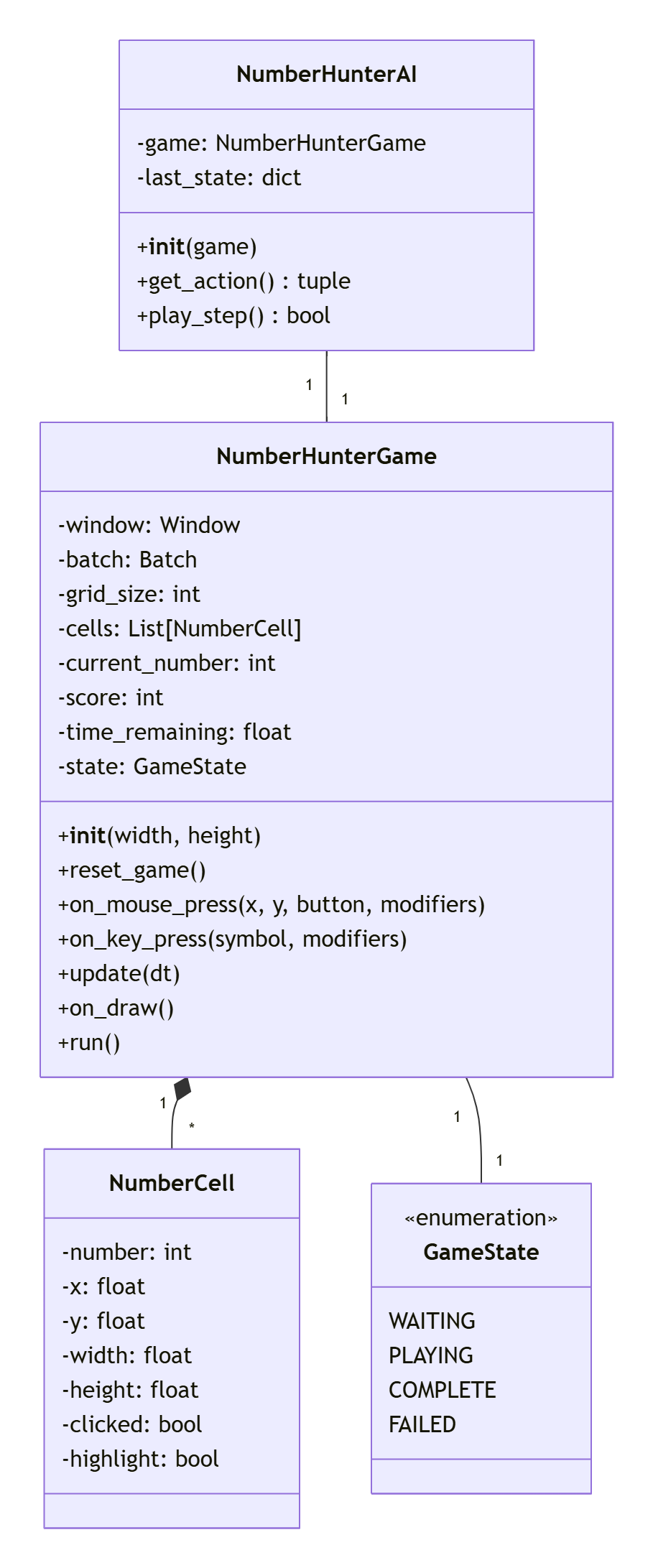
第二部分:代码实现详解
2.1 游戏初始化与配置
让我们从创建游戏窗口开始。Pyglet的核心优势在于它的简洁性:
python
import pyglet
from enum import Enum
from dataclasses import dataclass
from typing import List, Tuple, Optional
import random
import time
class GameState(Enum):
"""游戏状态枚举,清晰定义游戏流程"""
WAITING = 0 # 等待开始
PLAYING = 1 # 游戏中
COMPLETE = 2 # 完成
FAILED = 3 # 失败
@dataclass
class NumberCell:
"""数字格子数据类,封装单个格子的所有信息"""
number: int
x: float # 屏幕X坐标
y: float # 屏幕Y坐标
width: float # 格子宽度
height: float # 格子高度
clicked: bool = False # 是否已被点击
highlight: bool = False # 是否高亮显示
label: Optional[pyglet.text.Label] = None # 数字标签
class NumberHunterGame:
"""数字猎人游戏主类"""
def __init__(self, width: int = 800, height: int = 600):
# 创建游戏窗口
self.window = pyglet.window.Window(
width=width,
height=height,
caption="数字猎人 - AI训练游戏"
)
# 游戏参数配置
self.grid_size = 5 # 5x5网格
self.cell_size = 80 # 每个格子80像素
self.grid_margin = 50 # 边距
self.current_number = 1 # 当前目标数字
self.score = 0 # 当前分数
self.time_limit = 30.0 # 30秒时间限制
self.time_remaining = self.time_limit
self.state = GameState.WAITING
self.start_time = 0
# 颜色配置(使用RGBA元组)
self.colors = {
'background': (40, 44, 52, 255), # 深灰背景
'grid_line': (86, 98, 114, 255), # 网格线颜色
'cell_normal': (56, 58, 66, 255), # 普通格子
'cell_highlight': (97, 175, 239, 255), # 高亮格子
'cell_correct': (152, 195, 121, 255), # 正确点击
'text_normal': (220, 223, 228, 255), # 普通文字
'text_highlight': (255, 255, 255, 255) # 高亮文字
}
# 初始化游戏组件
self.numbers: List[NumberCell] = []
self.target_numbers = list(range(1, self.grid_size**2 + 1))
self.batch = pyglet.graphics.Batch()
self.grid_shapes = []
# 绑定事件处理器
self.setup_event_handlers()
# 创建UI元素
self.create_ui_elements()
# 重置游戏状态
self.reset_game()2.2 事件处理流程
理解Pyglet的事件驱动模型是关键。以下是事件处理的流程图:
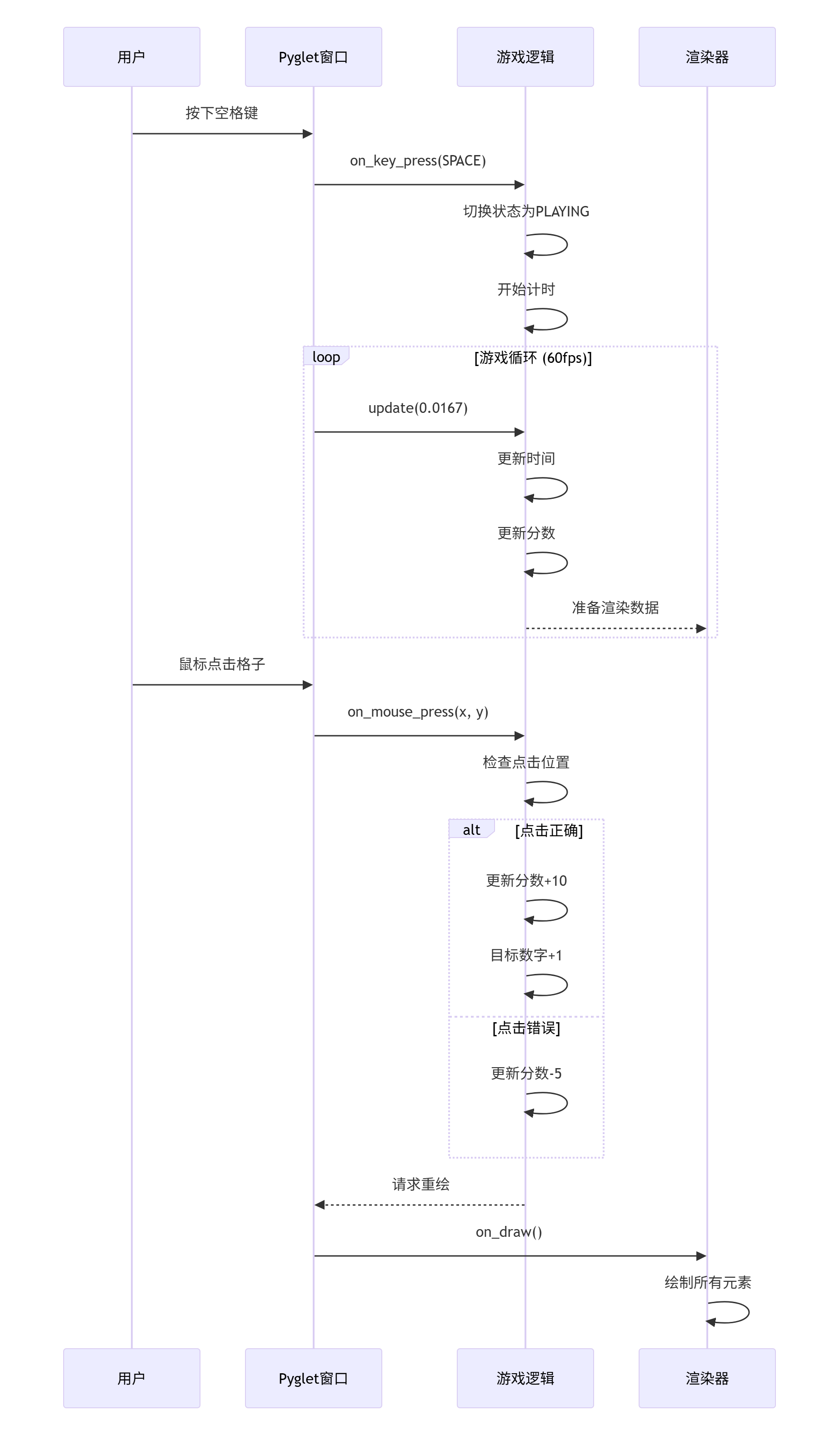
对应的代码实现:
python
def setup_event_handlers(self):
"""设置事件处理器"""
@self.window.event
def on_draw():
"""渲染事件 - 每帧调用"""
self.window.clear()
self.batch.draw()
@self.window.event
def on_mouse_press(x, y, button, modifiers):
"""鼠标点击事件处理"""
if self.state != GameState.PLAYING:
return
# 遍历所有格子,检查点击位置
for cell in self.numbers:
if (cell.x <= x <= cell.x + cell.width and
cell.y <= y <= cell.y + cell.height and
not cell.clicked):
if cell.number == self.current_number:
# 正确点击
cell.clicked = True
cell.highlight = True
self.current_number += 1
self.score += 10
# 播放音效(如果有)
if hasattr(self, 'correct_sound'):
self.correct_sound.play()
# 检查是否完成游戏
if self.current_number > self.grid_size**2:
self.state = GameState.COMPLETE
time_bonus = int(self.time_remaining * 10)
self.score += time_bonus
self.status_label.text = f"完成!最终分数: {self.score}"
# 更新显示
self.update_display()
else:
# 错误点击
self.score = max(0, self.score - 5)
cell.highlight = False
if hasattr(self, 'wrong_sound'):
self.wrong_sound.play()
break
@self.window.event
def on_key_press(symbol, modifiers):
"""键盘按键处理"""
if symbol == pyglet.window.key.SPACE:
if self.state == GameState.WAITING:
self.start_game()
elif self.state in [GameState.COMPLETE, GameState.FAILED]:
self.reset_game()
# 调试快捷键
elif symbol == pyglet.window.key.D:
self.debug_mode = not getattr(self, 'debug_mode', False)
elif symbol == pyglet.window.key.A:
# 切换AI模式
self.toggle_ai_mode()2.3 网格生成算法
数字猎人的核心是随机但可预测的数字网格。我们使用Fisher-Yates洗牌算法:
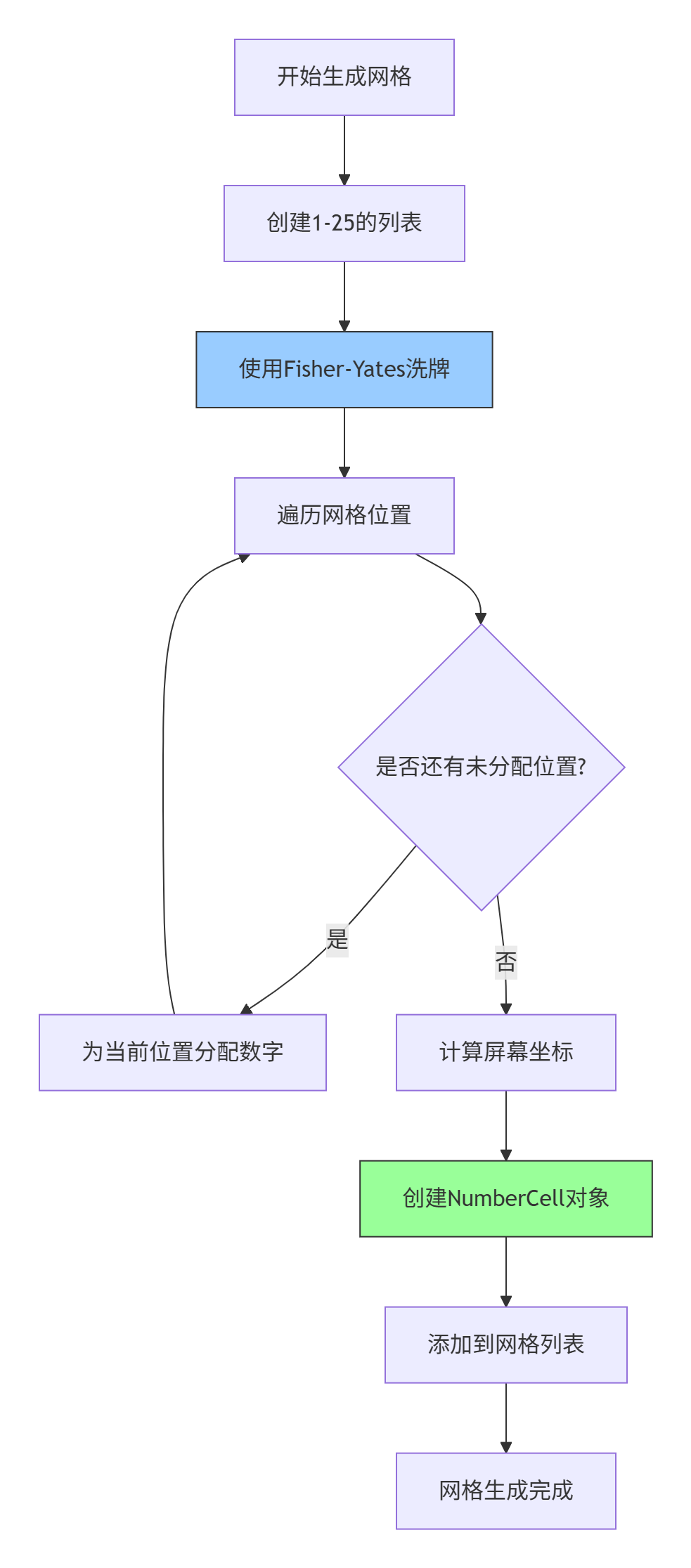
实现代码:
python
def reset_game(self):
"""重置游戏状态并生成新网格"""
self.current_number = 1
self.score = 0
self.time_remaining = self.time_limit
self.state = GameState.WAITING
# 清空现有格子
self.numbers.clear()
# 生成1-25的随机排列
numbers = list(range(1, self.grid_size**2 + 1))
# Fisher-Yates洗牌算法
for i in range(len(numbers)-1, 0, -1):
j = random.randint(0, i)
numbers[i], numbers[j] = numbers[j], numbers[i]
# 计算网格在屏幕上的位置
grid_width = self.grid_size * self.cell_size
start_x = (self.window.width - grid_width) // 2
start_y = (self.window.height - grid_width) // 2 + 50
# 创建数字格子
for i in range(self.grid_size):
for j in range(self.grid_size):
number_idx = i + j * self.grid_size
x = start_x + i * self.cell_size
y = start_y + j * self.cell_size
cell = NumberCell(
number=numbers[number_idx],
x=x,
y=y,
width=self.cell_size,
height=self.cell_size
)
self.numbers.append(cell)
# 创建或更新图形元素
if not self.grid_shapes:
self.create_grid_shapes()
else:
self.update_grid_shapes()
# 更新状态标签
self.status_label.text = "按空格键开始游戏"
self.update_display()
def create_grid_shapes(self):
"""创建网格的图形表示"""
self.grid_shapes.clear()
for idx, cell in enumerate(self.numbers):
# 计算行和列
row = idx // self.grid_size
col = idx % self.grid_size
# 创建矩形背景
rect = pyglet.shapes.Rectangle(
cell.x, cell.y, cell.width, cell.height,
color=self.colors['cell_normal'],
batch=self.batch
)
self.grid_shapes.append(rect)
# 创建数字标签
cell.label = pyglet.text.Label(
str(cell.number),
font_name="Arial",
font_size=32,
x=cell.x + cell.width // 2,
y=cell.y + cell.height // 2,
anchor_x='center',
anchor_y='center',
color=self.colors['text_normal'],
batch=self.batch
)2.4 游戏循环与状态管理
游戏状态的管理是游戏逻辑的核心:
python
def start_game(self):
"""开始游戏"""
self.state = GameState.PLAYING
self.start_time = time.time()
self.status_label.text = f"点击: {self.current_number}"
# 启动游戏循环
pyglet.clock.schedule_interval(self.update, 1/60.0)
def update(self, dt):
"""游戏更新函数,每秒调用60次"""
if self.state == GameState.PLAYING:
# 更新时间
elapsed = time.time() - self.start_time
self.time_remaining = max(0, self.time_limit - elapsed)
# 检查时间是否用完
if self.time_remaining <= 0:
self.state = GameState.FAILED
self.status_label.text = f"时间到!分数: {self.score}"
pyglet.clock.unschedule(self.update)
# 更新显示
self.update_display()第三部分:AI集成与实践
3.1 AI决策流程
现在让我们为游戏添加AI能力。AI的决策流程如下:
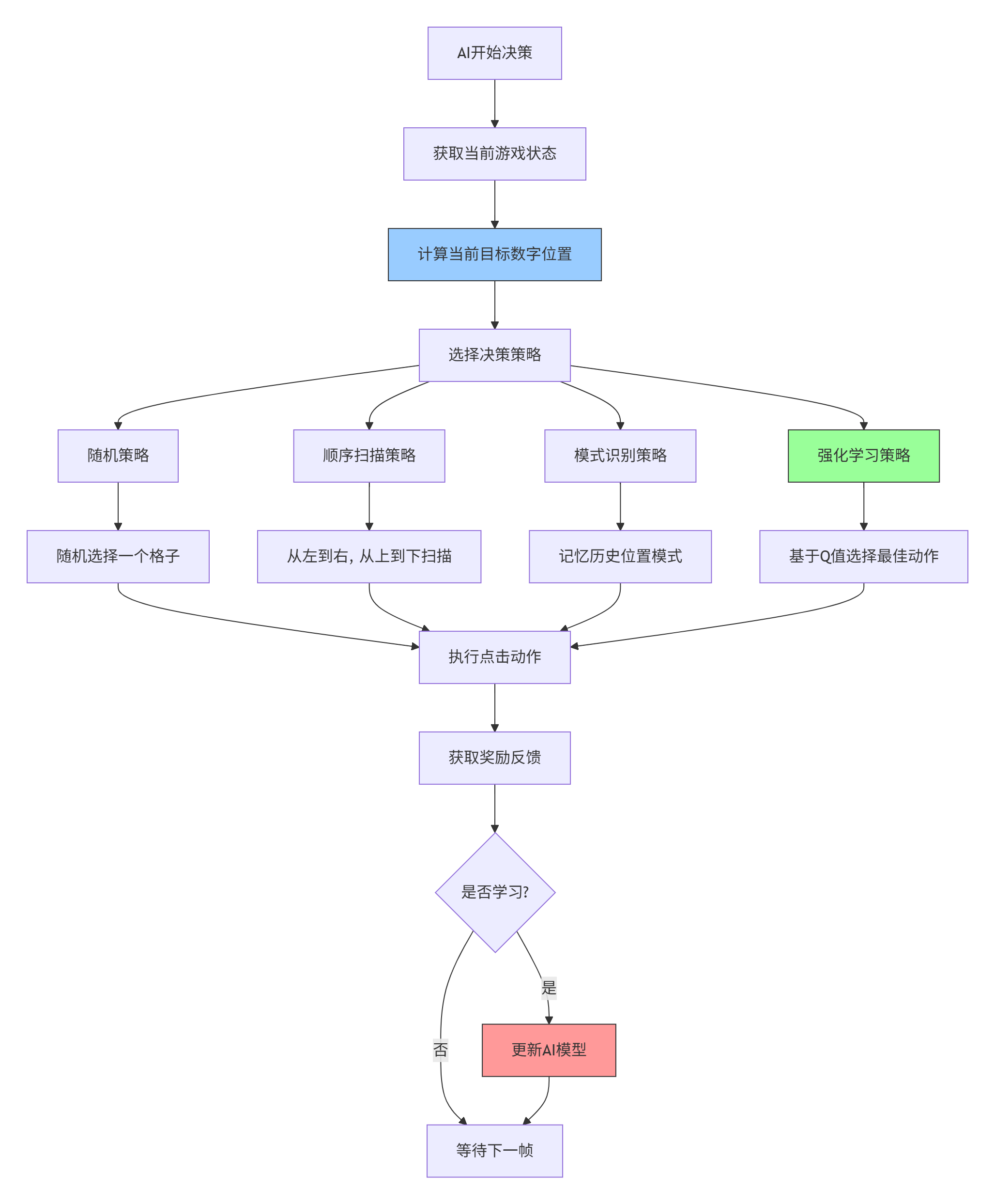
3.2 基础AI代理实现
首先实现一个简单的规则AI:
python
class NumberHunterAI:
"""数字猎人AI代理"""
def __init__(self, game, strategy="sequential"):
"""
初始化AI代理
Args:
game: NumberHunterGame实例
strategy: AI策略,可选值:
- 'random': 随机选择
- 'sequential': 顺序扫描
- 'memory': 记忆位置
"""
self.game = game
self.strategy = strategy
self.memory = {} # 记忆数字位置
self.last_action_time = 0
self.action_delay = 0.5 # AI每0.5秒执行一次动作
def get_action(self) -> Optional[Tuple[int, int]]:
"""根据策略选择动作"""
current_time = time.time()
# 控制AI执行频率
if current_time - self.last_action_time < self.action_delay:
return None
if self.strategy == "random":
return self._random_strategy()
elif self.strategy == "sequential":
return self._sequential_strategy()
elif self.strategy == "memory":
return self._memory_strategy()
else:
return self._sequential_strategy()
def _random_strategy(self) -> Optional[Tuple[int, int]]:
"""随机策略:随机选择未点击的格子"""
unclicked = [cell for cell in self.game.numbers if not cell.clicked]
if not unclicked:
return None
target_cell = random.choice(unclicked)
row = self._find_cell_position(target_cell)[0]
col = self._find_cell_position(target_cell)[1]
return (row, col)
def _sequential_strategy(self) -> Optional[Tuple[int, int]]:
"""顺序扫描策略:从左到右,从上到下寻找目标数字"""
target_number = self.game.current_number
for idx, cell in enumerate(self.game.numbers):
if cell.number == target_number and not cell.clicked:
row = idx // self.game.grid_size
col = idx % self.game.grid_size
return (row, col)
return None
def _memory_strategy(self) -> Optional[Tuple[int, int]]:
"""记忆策略:记录数字位置,快速定位"""
target_number = self.game.current_number
# 如果已经记忆了这个数字的位置
if target_number in self.memory:
row, col = self.memory[target_number]
cell_idx = row * self.game.grid_size + col
cell = self.game.numbers[cell_idx]
if not cell.clicked:
return (row, col)
# 如果没有记忆,使用顺序扫描并记住位置
for idx, cell in enumerate(self.game.numbers):
if cell.number == target_number and not cell.clicked:
row = idx // self.game.grid_size
col = idx % self.game.grid_size
# 记住这个数字的位置
self.memory[target_number] = (row, col)
return (row, col)
return None
def _find_cell_position(self, cell: NumberCell) -> Tuple[int, int]:
"""根据格子对象找到其在网格中的位置"""
for idx, c in enumerate(self.game.numbers):
if c is cell:
row = idx // self.game.grid_size
col = idx % self.game.grid_size
return (row, col)
return (-1, -1)
def play_step(self) -> bool:
"""AI执行一步动作"""
action = self.get_action()
if action is None:
return False
row, col = action
success, reward = self.game.ai_click(row, col)
if success:
self.last_action_time = time.time()
return success3.3 AI性能对比分析
让我们设计一个实验,比较不同AI策略的表现:
python
class AIPerformanceAnalyzer:
"""AI性能分析器"""
def __init__(self, num_trials: int = 100):
self.num_trials = num_trials
self.results = {}
def run_experiment(self):
"""运行AI性能对比实验"""
strategies = ['random', 'sequential', 'memory']
for strategy in strategies:
scores = []
completion_times = []
completion_rates = []
print(f"测试策略: {strategy}")
for trial in range(self.num_trials):
# 创建新的游戏实例
game = NumberHunterGame(width=800, height=600)
ai = NumberHunterAI(game, strategy=strategy)
# 运行游戏直到结束
start_time = time.time()
completion = self._run_ai_game(game, ai)
end_time = time.time()
# 记录结果
scores.append(game.score)
completion_times.append(end_time - start_time)
completion_rates.append(1 if completion else 0)
# 保存策略结果
self.results[strategy] = {
'avg_score': sum(scores) / len(scores),
'avg_time': sum(completion_times) / len(completion_times),
'completion_rate': sum(completion_rates) / len(completion_rates),
'scores': scores,
'times': completion_times
}
print(f" 平均分数: {self.results[strategy]['avg_score']:.1f}")
print(f" 平均时间: {self.results[strategy]['avg_time']:.2f}s")
print(f" 完成率: {self.results[strategy]['completion_rate']*100:.1f}%")
print()
def _run_ai_game(self, game, ai) -> bool:
"""运行单局AI游戏"""
# 模拟游戏循环
game.start_game()
# 运行最多60秒(实际游戏是30秒限制)
max_sim_time = 60
start_time = time.time()
while (game.state == GameState.PLAYING and
time.time() - start_time < max_sim_time):
ai.play_step()
time.sleep(0.1) # 模拟帧延迟
return game.state == GameState.COMPLETE
def visualize_results(self):
"""可视化实验结果"""
import matplotlib.pyplot as plt
import numpy as np
strategies = list(self.results.keys())
# 准备数据
avg_scores = [self.results[s]['avg_score'] for s in strategies]
avg_times = [self.results[s]['avg_time'] for s in strategies]
completion_rates = [self.results[s]['completion_rate'] for s in strategies]
# 创建子图
fig, axes = plt.subplots(1, 3, figsize=(15, 5))
# 平均分数柱状图
bars1 = axes[0].bar(strategies, avg_scores, color=['#FF6B6B', '#4ECDC4', '#45B7D1'])
axes[0].set_title('平均分数')
axes[0].set_ylabel('分数')
axes[0].set_ylim(0, max(avg_scores) * 1.2)
# 在柱子上添加数值
for bar in bars1:
height = bar.get_height()
axes[0].text(bar.get_x() + bar.get_width()/2., height + 5,
f'{height:.1f}', ha='center', va='bottom')
# 平均时间柱状图
bars2 = axes[1].bar(strategies, avg_times, color=['#FF6B6B', '#4ECDC4', '#45B7D1'])
axes[1].set_title('平均完成时间')
axes[1].set_ylabel('时间(秒)')
for bar in bars2:
height = bar.get_height()
axes[1].text(bar.get_x() + bar.get_width()/2., height + 0.1,
f'{height:.2f}', ha='center', va='bottom')
# 完成率饼图
wedges, texts, autotexts = axes[2].pie(
completion_rates,
labels=strategies,
autopct='%1.1f%%',
colors=['#FF6B6B', '#4ECDC4', '#45B7D1']
)
axes[2].set_title('完成率')
plt.tight_layout()
plt.show()第四部分:强化学习进阶
4.1 Q-learning算法实现
现在让我们实现一个更高级的强化学习AI。Q-learning是一种无模型的强化学习算法:
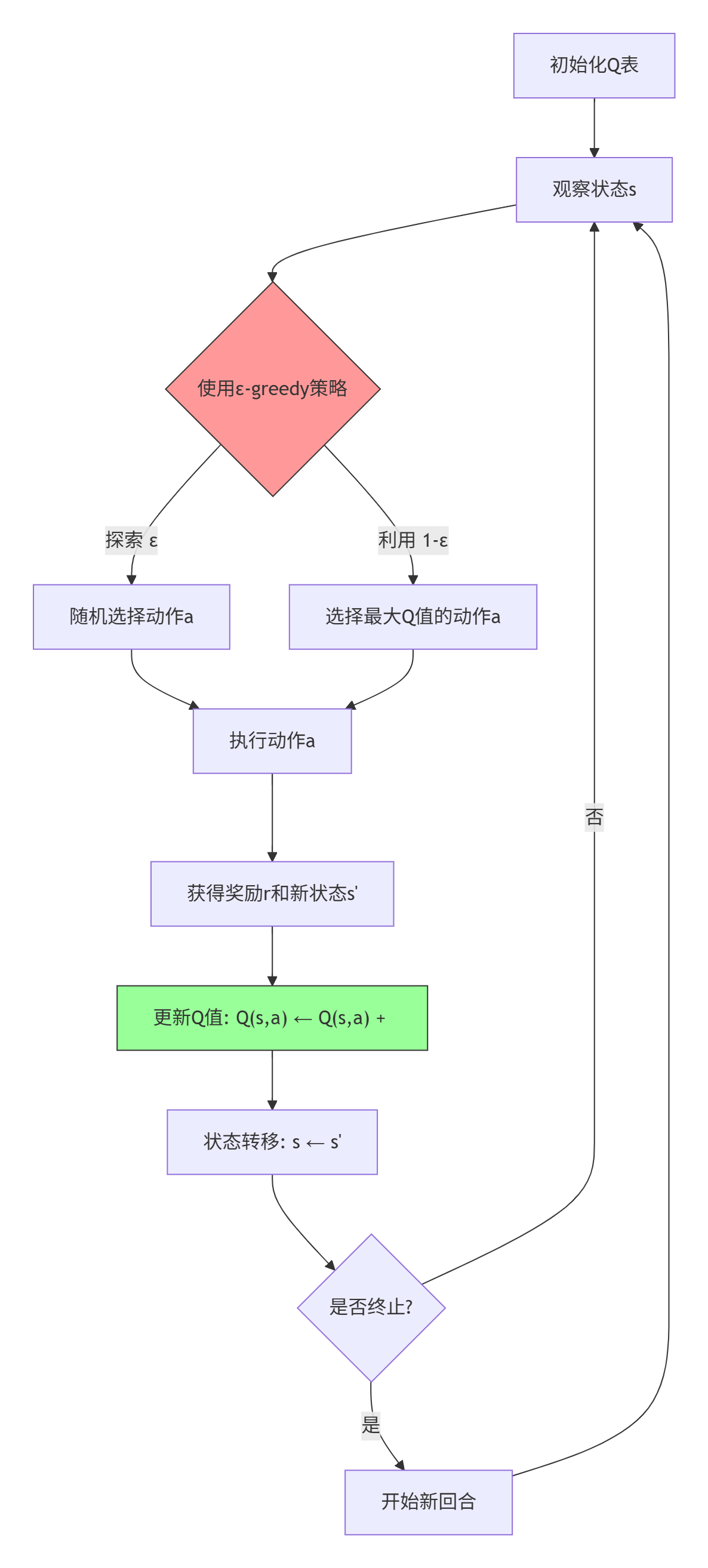
实现代码:
python
class QLearningAI:
"""Q-learning强化学习AI"""
def __init__(self, game, learning_rate=0.1, discount_factor=0.9,
epsilon=0.1, epsilon_decay=0.995, epsilon_min=0.01):
self.game = game
self.learning_rate = learning_rate
self.discount_factor = discount_factor
self.epsilon = epsilon
self.epsilon_decay = epsilon_decay
self.epsilon_min = epsilon_min
# Q表:状态 -> 动作 -> Q值
self.q_table = {}
# 状态编码维度
self.state_size = self.game.grid_size ** 2
self.action_size = self.game.grid_size ** 2
# 训练统计
self.episode_rewards = []
self.episode_lengths = []
self.q_table_sizes = []
def encode_state(self) -> str:
"""将游戏状态编码为字符串表示"""
# 创建状态表示:数字位置 + 已点击状态
state_parts = []
for cell in self.game.numbers:
# 编码:数字_是否已点击
state_parts.append(f"{cell.number}_{1 if cell.clicked else 0}")
# 添加当前目标数字
state_parts.append(f"target_{self.game.current_number}")
return ",".join(state_parts)
def get_available_actions(self) -> List[int]:
"""获取可用的动作索引列表"""
available = []
for idx, cell in enumerate(self.game.numbers):
if not cell.clicked:
available.append(idx)
return available
def choose_action(self, state: str) -> int:
"""ε-greedy策略选择动作"""
# 确保状态在Q表中
if state not in self.q_table:
self.q_table[state] = {a: 0.0 for a in range(self.action_size)}
available_actions = self.get_available_actions()
if not available_actions:
return -1
# 探索:随机选择动作
if random.random() < self.epsilon:
return random.choice(available_actions)
# 利用:选择Q值最大的动作
state_q_values = self.q_table[state]
# 只考虑可用动作
available_q_values = {a: state_q_values[a] for a in available_actions}
if not available_q_values:
return random.choice(available_actions)
max_q = max(available_q_values.values())
best_actions = [a for a, q in available_q_values.items() if q == max_q]
return random.choice(best_actions)
def learn(self, state: str, action: int, reward: float,
next_state: str, done: bool):
"""Q-learning更新规则"""
# 确保状态在Q表中
if state not in self.q_table:
self.q_table[state] = {a: 0.0 for a in range(self.action_size)}
if next_state not in self.q_table:
self.q_table[next_state] = {a: 0.0 for a in range(self.action_size)}
# 当前Q值
current_q = self.q_table[state][action]
if done:
# 终止状态的目标Q值就是奖励
target_q = reward
else:
# 非终止状态的目标Q值
next_max_q = max(self.q_table[next_state].values())
target_q = reward + self.discount_factor * next_max_q
# Q-learning更新公式
new_q = current_q + self.learning_rate * (target_q - current_q)
self.q_table[state][action] = new_q
# 衰减探索率
if self.epsilon > self.epsilon_min:
self.epsilon *= self.epsilon_decay
def train_episode(self) -> Tuple[float, int]:
"""训练一个回合"""
total_reward = 0
steps = 0
max_steps = 100
# 重置游戏
self.game.reset_game()
self.game.start_game()
state = self.encode_state()
while steps < max_steps and self.game.state == GameState.PLAYING:
# 选择动作
action = self.choose_action(state)
if action == -1: # 无可用动作
break
# 执行动作
row = action // self.game.grid_size
col = action % self.game.grid_size
_, reward = self.game.ai_click(row, col)
next_state = self.encode_state()
done = (self.game.state != GameState.PLAYING)
# 学习
self.learn(state, action, reward, next_state, done)
# 更新状态
state = next_state
total_reward += reward
steps += 1
# 添加小延迟,使训练可见
time.sleep(0.01)
return total_reward, steps
def train(self, num_episodes: int = 1000):
"""训练多个回合"""
print("开始Q-learning训练...")
for episode in range(num_episodes):
reward, steps = self.train_episode()
self.episode_rewards.append(reward)
self.episode_lengths.append(steps)
self.q_table_sizes.append(len(self.q_table))
if (episode + 1) % 100 == 0:
avg_reward = sum(self.episode_rewards[-100:]) / 100
avg_steps = sum(self.episode_lengths[-100:]) / 100
print(f"回合 {episode + 1:4d} | "
f"平均奖励: {avg_reward:6.1f} | "
f"平均步数: {avg_steps:5.1f} | "
f"Q表大小: {len(self.q_table):5d} | "
f"探索率: {self.epsilon:.4f}")4.2 训练过程可视化
让我们可视化Q-learning的训练过程:
python
def visualize_training_progress(q_learning_ai: QLearningAI):
"""可视化Q-learning训练过程"""
import matplotlib.pyplot as plt
import numpy as np
episodes = list(range(1, len(q_learning_ai.episode_rewards) + 1))
# 创建子图
fig, axes = plt.subplots(2, 2, figsize=(12, 10))
# 1. 奖励曲线
axes[0, 0].plot(episodes, q_learning_ai.episode_rewards,
alpha=0.6, linewidth=0.5, color='#4ECDC4')
# 计算移动平均
window_size = 50
if len(episodes) > window_size:
moving_avg = np.convolve(q_learning_ai.episode_rewards,
np.ones(window_size)/window_size, mode='valid')
axes[0, 0].plot(episodes[window_size-1:], moving_avg,
linewidth=2, color='#45B7D1', label='移动平均')
axes[0, 0].set_xlabel('回合数')
axes[0, 0].set_ylabel('奖励')
axes[0, 0].set_title('每回合奖励')
axes[0, 0].grid(True, alpha=0.3)
axes[0, 0].legend()
# 2. 步数曲线
axes[0, 1].plot(episodes, q_learning_ai.episode_lengths,
alpha=0.6, linewidth=0.5, color='#FF6B6B')
if len(episodes) > window_size:
moving_avg = np.convolve(q_learning_ai.episode_lengths,
np.ones(window_size)/window_size, mode='valid')
axes[0, 1].plot(episodes[window_size-1:], moving_avg,
linewidth=2, color='#FF8E8E', label='移动平均')
axes[0, 1].set_xlabel('回合数')
axes[0, 1].set_ylabel('步数')
axes[0, 1].set_title('每回合步数')
axes[0, 1].grid(True, alpha=0.3)
axes[0, 1].legend()
# 3. Q表大小增长
axes[1, 0].plot(episodes, q_learning_ai.q_table_sizes,
linewidth=2, color='#96CEB4')
axes[1, 0].set_xlabel('回合数')
axes[1, 0].set_ylabel('状态数')
axes[1, 0].set_title('Q表状态数增长')
axes[1, 0].grid(True, alpha=0.3)
# 4. 探索率衰减
# 模拟探索率衰减曲线
epsilons = []
epsilon = q_learning_ai.epsilon
for _ in range(len(episodes)):
epsilons.append(epsilon)
epsilon = max(q_learning_ai.epsilon_min,
epsilon * q_learning_ai.epsilon_decay)
axes[1, 1].plot(episodes, epsilons, linewidth=2, color='#FFCC5C')
axes[1, 1].set_xlabel('回合数')
axes[1, 1].set_ylabel('探索率 (ε)')
axes[1, 1].set_title('探索率衰减')
axes[1, 1].grid(True, alpha=0.3)
axes[1, 1].set_yscale('log')
plt.suptitle('Q-learning训练过程分析', fontsize=16, fontweight='bold')
plt.tight_layout()
plt.show()第五部分:项目测试与优化
5.1 测试框架设计
为了确保代码质量,我们需要编写全面的测试:
python
import unittest
import tempfile
import os
class TestNumberHunter(unittest.TestCase):
"""数字猎人游戏单元测试"""
def setUp(self):
"""每个测试前的设置"""
self.game = NumberHunterGame(width=800, height=600)
def test_game_initialization(self):
"""测试游戏初始化"""
self.assertEqual(self.game.grid_size, 5)
self.assertEqual(self.game.cell_size, 80)
self.assertEqual(self.game.current_number, 1)
self.assertEqual(self.game.score, 0)
self.assertEqual(self.game.state, GameState.WAITING)
self.assertEqual(len(self.game.numbers), 25)
def test_number_grid_generation(self):
"""测试数字网格生成"""
# 检查所有数字1-25都存在
numbers = [cell.number for cell in self.game.numbers]
self.assertEqual(set(numbers), set(range(1, 26)))
# 检查无重复数字
self.assertEqual(len(numbers), len(set(numbers)))
# 检查所有格子位置正确
for idx, cell in enumerate(self.game.numbers):
expected_col = idx % 5
expected_row = idx // 5
self.assertEqual(cell.x, expected_col * 80 + 50)
self.assertEqual(cell.y, expected_row * 80 + 50)
def test_correct_click(self):
"""测试正确点击"""
# 找到数字1的格子
target_cell = None
for cell in self.game.numbers:
if cell.number == 1:
target_cell = cell
break
self.assertIsNotNone(target_cell)
# 开始游戏
self.game.start_game()
# 模拟点击数字1
click_x = target_cell.x + target_cell.width / 2
click_y = target_cell.y + target_cell.height / 2
self.game.on_mouse_press(click_x, click_y, 1, 0)
# 验证结果
self.assertTrue(target_cell.clicked)
self.assertEqual(self.game.current_number, 2)
self.assertEqual(self.game.score, 10)
def test_wrong_click(self):
"""测试错误点击"""
# 找到不是数字1的格子
wrong_cell = None
for cell in self.game.numbers:
if cell.number != 1:
wrong_cell = cell
break
self.assertIsNotNone(wrong_cell)
# 开始游戏
self.game.start_game()
initial_score = self.game.score
# 模拟点击错误数字
click_x = wrong_cell.x + wrong_cell.width / 2
click_y = wrong_cell.y + wrong_cell.height / 2
self.game.on_mouse_press(click_x, click_y, 1, 0)
# 验证结果
self.assertEqual(self.game.score, max(0, initial_score - 5))
self.assertEqual(self.game.current_number, 1) # 目标数字不变
def test_game_completion(self):
"""测试游戏完成"""
# 按顺序点击所有数字
self.game.start_game()
for target in range(1, 26):
# 找到目标数字
for cell in self.game.numbers:
if cell.number == target and not cell.clicked:
click_x = cell.x + cell.width / 2
click_y = cell.y + cell.height / 2
self.game.on_mouse_press(click_x, click_y, 1, 0)
break
# 验证游戏完成
self.assertEqual(self.game.state, GameState.COMPLETE)
self.assertEqual(self.game.current_number, 26) # 超过25
def test_ai_basic_strategies(self):
"""测试基础AI策略"""
strategies = ['random', 'sequential', 'memory']
for strategy in strategies:
with self.subTest(strategy=strategy):
ai = NumberHunterAI(self.game, strategy=strategy)
# 重置游戏
self.game.reset_game()
self.game.start_game()
# 运行几步AI
for _ in range(5):
success = ai.play_step()
if not success:
break
# 验证AI至少执行了一些动作
self.assertGreater(self.game.score, 0)
def test_performance_benchmark(self):
"""测试性能基准"""
import time
# 测试游戏更新性能
start_time = time.time()
for _ in range(1000): # 模拟1000帧
self.game.update(0.016) # 60fps的帧时间
elapsed = time.time() - start_time
# 1000次更新应该在1秒内完成
self.assertLess(elapsed, 1.0,
f"性能不达标:1000次更新耗时{elapsed:.3f}秒")
def test_state_encoding(self):
"""测试状态编码"""
# 测试Q-learning AI的状态编码
ai = QLearningAI(self.game)
state_str = ai.encode_state()
# 验证状态字符串格式
self.assertIsInstance(state_str, str)
self.assertGreater(len(state_str), 0)
# 验证包含所有必要信息
self.assertIn(f"target_{self.game.current_number}", state_str)
# 验证状态可逆性
state_parts = state_str.split(',')
self.assertEqual(len(state_parts), 26) # 25个格子 + 目标数字
class TestAIIntegration(unittest.TestCase):
"""AI集成测试"""
def test_q_learning_convergence(self):
"""测试Q-learning收敛性"""
game = NumberHunterGame()
ai = QLearningAI(game, learning_rate=0.1, discount_factor=0.9,
epsilon=0.2, epsilon_decay=0.99)
# 训练少量回合
initial_rewards = []
for _ in range(10):
reward, _ = ai.train_episode()
initial_rewards.append(reward)
# 继续训练
later_rewards = []
for _ in range(10):
reward, _ = ai.train_episode()
later_rewards.append(reward)
# 验证训练后性能提升
avg_initial = sum(initial_rewards) / len(initial_rewards)
avg_later = sum(later_rewards) / len(later_rewards)
# 注意:由于随机性,这个测试可能有时失败
# 在真实项目中,我们会使用更严格的收敛测试
self.assertGreaterEqual(avg_later, avg_initial - 50, # 允许一定误差
f"Q-learning没有收敛:{avg_initial:.1f} -> {avg_later:.1f}")
if __name__ == '__main__':
# 运行测试
unittest.main(verbosity=2)5.2 性能优化技巧
基于Pyglet的特性,我们可以实施以下优化:
python
class OptimizedNumberHunterGame(NumberHunterGame):
"""优化版的数字猎人游戏"""
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
# 预计算渲染数据
self._precompute_rendering_data()
# 使用顶点列表优化
self._setup_vertex_lists()
def _precompute_rendering_data(self):
"""预计算渲染数据,减少运行时计算"""
# 预计算格子颜色
self.cell_colors = {}
for i, color_name in enumerate(['cell_normal', 'cell_highlight', 'cell_correct']):
self.cell_colors[color_name] = self.colors[color_name]
# 预计算字体
self.font_cache = {}
def _setup_vertex_lists(self):
"""使用顶点列表优化批处理渲染"""
# 创建所有格子的顶点列表
self.vertex_lists = []
for cell in self.numbers:
x, y = cell.x, cell.y
w, h = cell.width, cell.height
# 创建矩形的4个顶点
vertices = [
x, y, # 左下
x + w, y, # 右下
x + w, y + h, # 右上
x, y + h, # 左上
]
# 创建顶点列表
vl = self.batch.add(
4, pyglet.gl.GL_QUADS, None,
('v2f', vertices),
('c4B', self.colors['cell_normal'] * 4)
)
self.vertex_lists.append(vl)
def update_display_fast(self):
"""快速更新显示(优化版)"""
# 批量更新所有顶点的颜色
for idx, cell in enumerate(self.numbers):
if cell.clicked:
color = self.colors['cell_correct']
elif cell.highlight:
color = self.colors['cell_highlight']
else:
color = self.colors['cell_normal']
# 更新顶点颜色
self.vertex_lists[idx].colors[:] = color * 4
# 批量更新标签
self.score_label.text = f"分数: {self.score}"
self.time_label.text = f"时间: {self.time_remaining:.1f}s"
if self.state == GameState.PLAYING:
self.status_label.text = f"点击: {self.current_number}"第六部分:扩展与展望
6.1 更多AI算法集成
我们已经实现了基础AI和Q-learning,但还有更多AI算法可以尝试:
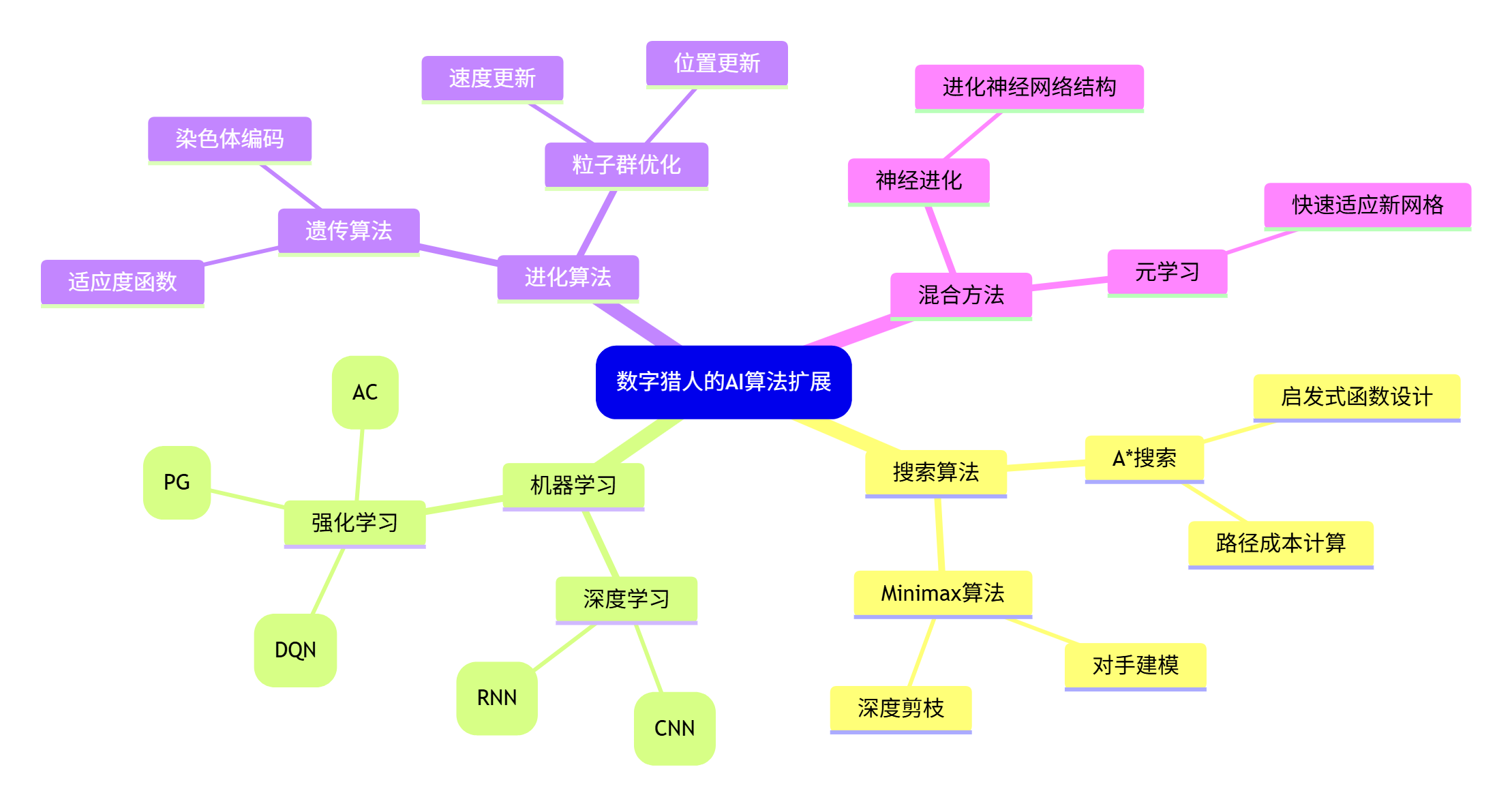
6.2 游戏机制扩展
原始游戏可以扩展为多种变体,增加趣味性和挑战性:
| 扩展变体 | 核心机制 | AI挑战 | 教学价值 |
|---|---|---|---|
| 时间攻击 | 越来越短的时间限制 | 决策速度优化 | 实时决策算法 |
| 记忆模式 | 数字短暂显示后隐藏 | 记忆与预测 | 工作记忆模型 |
| 数学运算 | 需要计算后点击结果 | 符号推理 | 算术逻辑单元 |
| 多人对战 | 多个玩家/AI同时竞争 | 竞争策略 | 博弈论基础 |
| 动态网格 | 网格大小和形状变化 | 泛化能力 | 适应新环境 |
6.3 教育应用场景
这个项目可以应用于多种教育场景:

第七部分:总结与资源
7.1 关键学习要点
通过这个项目,我们掌握了:
-
Pyglet游戏开发:从窗口创建到事件处理的完整流程
-
游戏架构设计:状态管理、渲染优化、模块化设计
-
AI算法实现:从规则AI到强化学习的渐进式学习
-
测试驱动开发:单元测试、性能测试、集成测试
-
数据分析可视化:训练过程监控、算法性能对比
7.2 完整项目结构
bash
number-hunter-ai/
├── README.md # 项目说明
├── requirements.txt # 依赖列表
├── setup.py # 安装配置
├── src/ # 源代码
│ ├── __init__.py
│ ├── game/ # 游戏核心
│ │ ├── __init__.py
│ │ ├── core.py # 游戏主类
│ │ ├── cell.py # 格子类
│ │ └── constants.py # 常量定义
│ ├── ai/ # AI算法
│ │ ├── __init__.py
│ │ ├── base_ai.py # AI基类
│ │ ├── rule_based.py # 规则AI
│ │ ├── q_learning.py # Q-learning
│ │ └── dqn.py # 深度Q网络
│ ├── ui/ # 用户界面
│ │ ├── __init__.py
│ │ ├── renderer.py # 渲染器
│ │ ├── sounds.py # 音效管理
│ │ └── animations.py # 动画系统
│ └── utils/ # 工具函数
│ ├── __init__.py
│ ├── config.py # 配置管理
│ ├── logger.py # 日志系统
│ └── visualizer.py # 可视化工具
├── tests/ # 测试代码
│ ├── __init__.py
│ ├── test_game.py # 游戏测试
│ ├── test_ai.py # AI测试
│ └── test_integration.py # 集成测试
├── assets/ # 游戏资源
│ ├── sounds/ # 音效文件
│ ├── fonts/ # 字体文件
│ └── images/ # 图片资源
├── examples/ # 示例代码
│ ├── basic_game.py # 基础游戏
│ ├── ai_demo.py # AI演示
│ ├── training.py # 训练脚本
│ └── benchmark.py # 性能测试
├── docs/ # 文档
│ ├── tutorial.md # 教程
│ ├── api.md # API文档
│ └── algorithm.md # 算法说明
└── notebooks/ # Jupyter笔记本
├── 01_game_analysis.ipynb
├── 02_ai_training.ipynb
└── 03_performance.ipynb通过这个完整的项目,您不仅学会了如何用Pyglet创建一个有趣的数字游戏,还掌握了如何为它注入人工智能。从简单的规则AI到复杂的强化学习,您看到了AI如何从零开始学习并优化游戏策略。
最重要的是,这个项目展示了理论与实践的结合------您不仅学习了算法原理,还亲手实现了它们,看到了它们在实际游戏中的表现。
现在,是时候开始您自己的AI游戏开发之旅了!尝试修改游戏规则,实现新的AI算法,或者创建完全不同的游戏。记住,每一个复杂的AI系统都是从这样简单的项目开始的。
编码愉快,学习不止!