标签:人工智能 深度学习 Transformer 注意力机制 NLP 大模型基础
前言
在整个人类深度学习与序列建模的进化史上,Transformer 的诞生,无异于一场颠覆行业格局的技术革命 ,是真正意义上划时代的里程碑式创举。
2017 年,Google Brain 团队在神作《Attention Is All You Need》中,以石破天惊之势抛出这一全新架构------直接彻底摒弃统治时代的循环神经网络 RNN 与卷积神经网络 CNN,开创性地仅依靠自注意力机制,便实现了端到端的高性能序列建模。它一剑封喉,精准击碎了传统架构两大致命顽疾:
- RNN 天然串行桎梏,无法并行计算,长序列处理效率低下、速度缓慢,彻底成为性能瓶颈;
- CNN 局部感受野局限,建模视野狭窄,长距离依赖关系捕捉乏力,难以支撑复杂场景建模。
凭借碾压前代的并行计算能力、登峰造极的长程依赖建模实力,以及简洁到极致却威力无穷的架构美学,Transformer 横空出世、一统江湖,迅速登顶成为 NLP、CV、语音、多模态等全领域的底层基石架构。如今横扫世界的 BERT、GPT、ViT、Stable Diffusion 等里程碑模型,无一不是站在它的肩膀之上。
本文将死磕原论文、逐行拆解、逐公式推导、逐模块精讲 ,从数学本质到工程实现全覆盖,硬核公式严谨推导 + 通俗白话同步拆解,理论闭环、细节拉满、逻辑通透,让你真正做到一篇吃透、终身掌握。
论文地址:https://arxiv.org/abs/1706.03762
一、模型总览:Encoder-Decoder 架构
Transformer 是标准的 Seq2Seq 架构 ,由 编码器(Encoder) 与 解码器(Decoder) 堆叠而成。
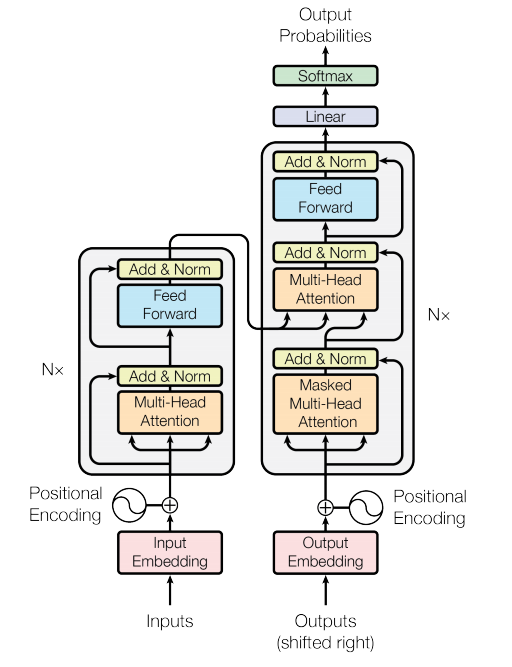
图1:Transformer模型架构
- Encoder :将输入序列映射为上下文特征表示
→ 通俗理解:相当于"阅读理解",把输入句子读懂、抓住重点。 - Decoder :基于编码器输出,自回归生成目标序列
→ 通俗理解:相当于"写作生成",根据理解的内容逐词写出答案。
整体结构遵循:
plaintext
输入嵌入 + 位置编码 → N层Encoder → N层Decoder → 线性层 + Softmax → 输出序列原论文设置:
- 堆叠层数 N = 6 N=6 N=6
- 模型维度 d m o d e l = 512 d_{model}=512 dmodel=512
- 前馈网络隐层维度 d f f = 2048 d_{ff}=2048 dff=2048
- 多头注意力头数 h = 8 h=8 h=8
二、编码器(Encoder)详细解析
编码器由 6 层完全相同的层 堆叠而成,每层包含两个子层:
- 多头自注意力(Multi-Head Self-Attention)
- 逐位置前馈网络(Position-Wise Feed-Forward Network)
每个子层都采用 残差连接 + 层归一化 :
LayerNorm ( x + Sublayer ( x ) ) \text{LayerNorm}(x + \text{Sublayer}(x)) LayerNorm(x+Sublayer(x))
→ 通俗理解 :
残差连接防止网络太深"学不动",层归一化让训练更稳定、不震荡。
2.1 多头自注意力(Multi-Head Attention)
注意力本质是:根据 Query 与 Key 的相似度,对 Value 加权求和 。
→ 通俗理解:像人看书一样,自动给重要的词分配更高权重。
2.1.1 缩放点积注意力(Scaled Dot-Product Attention)
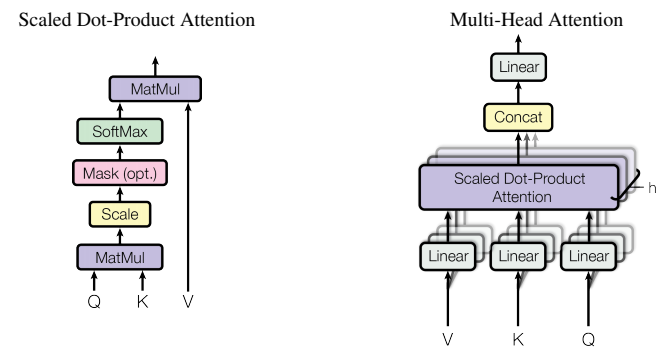
图 2:(左)缩放点积注意力机制。(右)多头注意力机制由多个并行运行的注意力层组成。
公式(论文原式):
Attention ( Q , K , V ) = softmax ( Q K ⊤ d k ) V \text{Attention}(Q,K,V) = \text{softmax}\left(\frac{QK^\top}{\sqrt{d_k}}\right)V Attention(Q,K,V)=softmax(dk QK⊤)V
- Q(Query) :查询向量,表征"当前要找什么信息"
→ 通俗:我想查什么? - K(Key) :键向量,表征"我有什么信息"
→ 通俗:句子里有哪些内容? - V(Value) :值向量,表征"我实际的信息内容"
→ 通俗:真正要提取的内容。 - √d_k :缩放因子,防止点积过大导致 Softmax 饱和梯度消失,可以看这篇文章:Softmax、Sigmoid、CrossEntropy Loss介绍
→ 通俗:避免数值太大,把 softmax"撑到没梯度"。
2.1.2 多头机制(Multi-Head)
将 Q、K、V 通过线性投影分为 h 组,并行计算注意力,再拼接输出:
MultiHead ( Q , K , V ) = Concat ( head 1 , . . . , head h ) W O \text{MultiHead}(Q,K,V) = \text{Concat}(\text{head}_1,...,\text{head}_h)W^O MultiHead(Q,K,V)=Concat(head1,...,headh)WO
其中每组注意力:
head i = Attention ( Q W i Q , K W i K , V W i V ) \text{head}_i = \text{Attention}(QW_i^Q,KW_i^K,VW_i^V) headi=Attention(QWiQ,KWiK,VWiV)
论文参数:
- h = 8 h=8 h=8
- d k = d v = d m o d e l / h = 64 d_k=d_v=d_{model}/h=64 dk=dv=dmodel/h=64
→ 通俗理解 :
多头 = 开多个"观察视角" ,有的看语法、有的看指代、有的看长距离关系,
相当于 8 个专家同时理解一句话,比单视角更全面。
2.2 逐位置前馈网络(FFN)
注意力层后,对每个位置独立使用两层线性变换 + 激活函数:
FFN ( x ) = max ( 0 , x W 1 + b 1 ) W 2 + b 2 \text{FFN}(x) = \max(0, xW_1+b_1)W_2 + b_2 FFN(x)=max(0,xW1+b1)W2+b2
即:
Linear → ReLU → Linear \text{Linear} \rightarrow \text{ReLU} \rightarrow \text{Linear} Linear→ReLU→Linear
→ 通俗理解 :
注意力看完全局后,前馈网络对每个词单独做一次"特征升级" ,
不依赖其他词,独立提炼信息。
2.3 残差连接与层归一化
每个子层都遵循:
Output = LayerNorm ( x + SubLayer ( x ) ) \text{Output} = \text{LayerNorm}(x + \text{SubLayer}(x)) Output=LayerNorm(x+SubLayer(x))
作用:
- 残差连接解决深度网络梯度消失;
→ 通俗:防止网络太深"学废了"。 - 层归一化稳定训练。
→ 通俗:让数据分布更规矩,训练更快更稳。
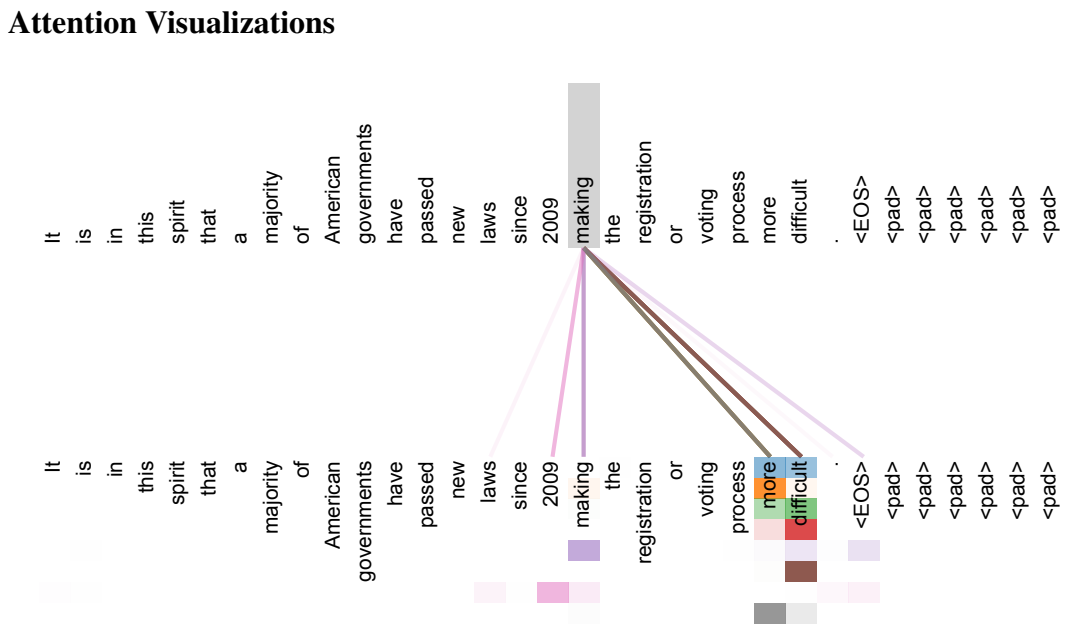
图 3:在第 6 层第 5 层的编码器自注意力机制中,遵循长距离依赖关系的一个示例。许多注意力头关注动词"制作"的远距离依赖关系,从而完成短语"制作......更困难"。此处展示的注意力仅针对"制作"这个词。不同的颜色代表不同的注意力头。以彩色方式查看效果最佳。
三、解码器(Decoder)详细解析
解码器同样堆叠 6 层 ,每层包含三个子层:
- 掩码多头自注意力(Masked Multi-Head Attention)
- 编码器-解码器注意力(Encoder-Decoder Attention)
- 逐位置前馈网络(FFN)
3.1 掩码自注意力(Masked Self-Attention)
为保证自回归生成 ,模型不能看到未来位置信息,因此在 Softmax 前将非法位置设为负无穷:
Attention ( Q , K , V ) = softmax ( Q K ⊤ d k + M ) V \text{Attention}(Q,K,V) = \text{softmax}\left(\frac{QK^\top}{\sqrt{d_k}} + M\right)V Attention(Q,K,V)=softmax(dk QK⊤+M)V
其中 M 为掩码矩阵 ,上三角为 − ∞ -∞ −∞,下三角为 0。
→ 通俗理解 :
写作文时不能偷看还没写的句子,mask 就是把未来信息全部挡住,防止作弊。
3.2 编码器-解码器注意力
Q 来自解码器上一层输出,K、V 来自编码器最终输出。
作用:让生成位置对齐输入序列的相关部分(如机器翻译的词对齐)。
→ 通俗理解 :
写作时随时回头看原题,保证输出和输入对应上,不跑偏。
四、位置编码(Positional Encoding)
Transformer 无循环与卷积,无法感知序列顺序,因此必须显式注入位置信息。
原论文使用正弦余弦位置编码 :
P E ( p o s , 2 i ) = sin ( p o s / 10000 2 i / d m o d e l ) PE_{(pos,2i)} = \sin\left(pos \big/ 10000^{2i/d_{model}}\right) PE(pos,2i)=sin(pos/100002i/dmodel)
P E ( p o s , 2 i + 1 ) = cos ( p o s / 10000 2 i / d m o d e l ) PE_{(pos,2i+1)} = \cos\left(pos \big/ 10000^{2i/d_{model}}\right) PE(pos,2i+1)=cos(pos/100002i/dmodel)
将位置编码直接加到词嵌入 上:
Input = Embedding + PositionalEncoding \text{Input} = \text{Embedding} + \text{PositionalEncoding} Input=Embedding+PositionalEncoding
→ 通俗理解 :
Transformer 是"瞎子",看不见词的先后顺序。
位置编码给每个位置一个唯一坐标,告诉模型谁在前、谁在后。
五、嵌入与输出层
5.1 词嵌入
将词映射为 d_model 维向量,并乘以 √d_model 缩放:
Embedding × d m o d e l \text{Embedding} \times \sqrt{d_{model}} Embedding×dmodel
→ 通俗:让嵌入数值大小合适,不太小不爆炸。
5.2 输出层
解码器最终输出经过线性变换+Softmax,得到词表概率:
P ( y ) = softmax ( Linear ( DecoderOutput ) ) P(y) = \text{softmax}(\text{Linear}(\text{DecoderOutput})) P(y)=softmax(Linear(DecoderOutput))
→ 通俗:把模型输出转成"每个词概率",选概率最大的输出。
六、损失函数
使用标签平滑(Label Smoothing) 交叉熵损失:
L = − ∑ y i log p i \mathcal{L} = -\sum y_i \log p_i L=−∑yilogpi
标签平滑值 ε=0.1,提升泛化性。
→ 通俗:不让模型"死记硬背",适当模糊标签,更不容易过拟合。
七、优化器与学习率策略
采用Adam 优化器 ,并使用论文定制学习率:
lrate = d m o d e l − 0.5 ⋅ min ( step − 0.5 , step ⋅ warmup − 1.5 ) \text{lrate} = d_{model}^{-0.5} \cdot \min(\text{step}^{-0.5},\ \text{step} \cdot \text{warmup}^{-1.5}) lrate=dmodel−0.5⋅min(step−0.5, step⋅warmup−1.5)
- warmup_steps=4000
- 先线性增,后反比例平方根衰减
→ 通俗:
刚开始学习率慢慢升高,避免一开始训崩;
后期慢慢降低,精细调整。
八、核心优势:为什么 Self-Attention 更强?
论文从三个维度对比:
| 结构 | 序列操作数 | 最大路径长度 | 复杂度 |
|---|---|---|---|
| Self-Attention | O(1) | O(1) | O(n²·d) |
| RNN | O(n) | O(n) | O(n·d²) |
| CNN | O(1) | O(log n) | O(k·n·d²) |
结论:
- 自注意力并行度最高 ,完全可并行;
→ 通俗:RNN 排队干活,Transformer 全员一起上。 - 长距离依赖路径最短 ,任意位置直接相连;
→ 通俗:句子再长,任意两个词都能"直接对话"。 - 长序列下可通过局部注意力进一步优化。
九、实验结果(论文原版)
机器翻译任务
- WMT 2014 英→德:BLEU 28.4(超越所有模型)
- WMT 2014 英→法:BLEU 41.8(单模型 SOTA)
英语句法分析
在 WSJ 数据集上取得 SOTA 级别表现,证明泛化能力极强。
十、核心代码(PyTorch 精简可运行版)
python
import torch
import torch.nn as nn
import math
# ================================
# 0. 位置编码(论文标准版)
# ================================
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_len=5000):
super().__init__()
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2) * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer('pe', pe)
def forward(self, x):
seq_len = x.size(1)
return x + self.pe[:, :seq_len] # 跟公式的「词嵌入 + 位置编码」对应
# ================================
# 1. 缩放点积注意力
# ================================
class ScaledDotProductAttention(nn.Module):
def forward(self, q, k, v, mask=None):
d_k = q.size(-1)
scores = torch.matmul(q, k.transpose(-2, -1)) / math.sqrt(d_k)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
attn = scores.softmax(dim=-1)
return torch.matmul(attn, v)
# ================================
# 2. 多头注意力
# ================================
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, n_heads):
super().__init__()
self.d_k = d_model // n_heads
self.n_heads = n_heads
self.wq = nn.Linear(d_model, d_model)
self.wk = nn.Linear(d_model, d_model)
self.wv = nn.Linear(d_model, d_model)
self.out = nn.Linear(d_model, d_model)
self.attn = ScaledDotProductAttention()
def forward(self, q, k, v, mask=None):
B = q.size(0)
q = self.wq(q).view(B, -1, self.n_heads, self.d_k).transpose(1, 2)
k = self.wk(k).view(B, -1, self.n_heads, self.d_k).transpose(1, 2)
v = self.wv(v).view(B, -1, self.n_heads, self.d_k).transpose(1, 2)
out = self.attn(q, k, v, mask)
out = out.transpose(1, 2).contiguous().view(B, -1, self.n_heads * self.d_k)
return self.out(out)
# ================================
# 3. 前馈网络 FFN
# ================================
class FeedForward(nn.Module):
def __init__(self, d_model, d_ff, dropout=0.1):
super().__init__()
self.linear1 = nn.Linear(d_model, d_ff)
self.linear2 = nn.Linear(d_ff, d_model)
self.relu = nn.ReLU()
self.dropout = nn.Dropout(dropout)
def forward(self, x):
return self.linear2(self.dropout(self.relu(self.linear1(x))))
# ================================
# 4. Encoder Layer
# ================================
class EncoderLayer(nn.Module):
def __init__(self, d_model, n_heads, d_ff, dropout=0.1):
super().__init__()
self.attn = MultiHeadAttention(d_model, n_heads)
self.ffn = FeedForward(d_model, d_ff, dropout)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
def forward(self, x, mask=None):
attn_out = self.attn(x, x, x, mask)
x = self.norm1(x + self.dropout1(attn_out))
ffn_out = self.ffn(x)
x = self.norm2(x + self.dropout2(ffn_out))
return x
# ================================
# 5. Decoder Layer
# ================================
class DecoderLayer(nn.Module):
def __init__(self, d_model, n_heads, d_ff, dropout=0.1):
super().__init__()
self.self_attn = MultiHeadAttention(d_model, n_heads)
self.cross_attn = MultiHeadAttention(d_model, n_heads)
self.ffn = FeedForward(d_model, d_ff, dropout)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.norm3 = nn.LayerNorm(d_model)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
self.dropout3 = nn.Dropout(dropout)
def forward(self, x, enc_out, tgt_mask=None):
# 掩码自注意力
attn_out = self.self_attn(x, x, x, tgt_mask)
x = self.norm1(x + self.dropout1(attn_out))
# 交叉注意力
cross_out = self.cross_attn(x, enc_out, enc_out)
x = self.norm2(x + self.dropout2(cross_out))
# FFN
ffn_out = self.ffn(x)
x = self.norm3(x + self.dropout3(ffn_out))
return x
# ================================
# 6. 完整 Transformer
# ================================
class Transformer(nn.Module):
def __init__(self, d_model=512, n_heads=8, n_layers=6, d_ff=2048, vocab_size=1000):
super().__init__()
self.d_model = d_model
self.embedding = nn.Embedding(vocab_size, d_model) # 1000 = 词表大小(vocab_size),你字典里一共有多少个 "词 / 符号"。512 = 模型维度(d_model),每个词要被表示成多长的向量。
self.pos_enc = PositionalEncoding(d_model)
# 堆叠 N 层 Encoder / Decoder
self.encoders = nn.ModuleList([
EncoderLayer(d_model, n_heads, d_ff) for _ in range(n_layers)
])
self.decoders = nn.ModuleList([
DecoderLayer(d_model, n_heads, d_ff) for _ in range(n_layers)
])
# 输出层
self.linear = nn.Linear(d_model, vocab_size)
self.softmax = nn.Softmax(dim=-1)
def forward(self, src, tgt, src_mask=None, tgt_mask=None):
# 1. 嵌入 + 位置编码
src_emb = self.embedding(src) * math.sqrt(self.d_model) # 输入维度为[2,10],embedding后维度为[2,10,512]
tgt_emb = self.embedding(tgt) * math.sqrt(self.d_model)
src_emb = self.pos_enc(src_emb)
tgt_emb = self.pos_enc(tgt_emb)
# 2. Encoder 前向
enc_out = src_emb
for layer in self.encoders:
enc_out = layer(enc_out, src_mask)
# 3. Decoder 前向
dec_out = tgt_emb
for layer in self.decoders:
dec_out = layer(dec_out, enc_out, tgt_mask)
# 4. 输出预测
output = self.linear(dec_out)
return output
# ================================
# MAIN 函数:可直接运行
# ================================
if __name__ == '__main__':
# 超参数(论文原版)
d_model = 512
n_heads = 8
n_layers = 6
d_ff = 2048
vocab_size = 1000
batch_size = 2
src_len = 10
tgt_len = 8
# 随机输入(模拟token序列)
src = torch.randint(0, vocab_size, (batch_size, src_len)) # [2,10]
tgt = torch.randint(0, vocab_size, (batch_size, tgt_len)) # [2,8]
# 构建模型
model = Transformer(d_model, n_heads, n_layers, d_ff, vocab_size)
# 前向传播
output = model(src, tgt)
# 输出信息
print("输入 src shape:", src.shape)
print("输入 tgt shape:", tgt.shape)
print("输出 logits shape:", output.shape)
print("\n✅ Transformer 完整运行成功!")
print("✅ 包含:位置编码 | Encoder×6 | Decoder×6 | 掩码 | LayerNorm | 残差")十一、总结
Transformer 的核心创新可以概括为以下五点:
- 完全基于自注意力机制,抛弃 RNN/CNN,实现高度并行;
- 多头注意力,从多个子空间捕捉依赖关系;
- Encoder-Decoder 架构,通用 Seq2Seq 建模;
- 位置编码,显式注入序列顺序信息;
- 残差 + 层归一化,支持深度网络稳定训练。
它不仅重新定义了序列建模,更成为整个深度学习时代的基础组件,支撑了从 NLP 到 CV、从语音到多模态、从 AIGC 到大模型的全面爆发。
可以说,Transformer 重新定义了深度学习的架构范式,其影响力仍在持续扩展。