https://arxiv.org/abs/2604.10096
摘要
OpenClaw提供了一个具有完整系统权限的本地化运行时,但缺乏长时间、多机器人执行所需的具身控制架构。
因此,我们提出了 ABot-Claw,这是 OpenClaw 的一个具身扩展版本,它集成了:
-
统一的具身接口,具有能力驱动的调度功能,用于异构机器人的协同;
-
以视觉为中心的跨具身多模态记忆,用于持久的上下文保留和具身基础检索;
-
基于评估者(critic)的闭环反馈机制,结合通用奖励模型,用于在线进度评估、局部纠正和重规划。
通过跨越 OpenClaw 层、共享服务层和机器人具身层的解耦架构,ABot-Claw 实现了真实世界的交互,闭合了从自然语言意图到物理动作的循环,并支持在开放、动态环境中逐步自我进化的机器人智能体。
方法
我们在 ABot-Claw 中的目标并不是从头开始构建一个独立的具身智能体框架。相反,我们将最初为高级软件操作和任务编排设计的 OpenClaw 运行时,扩展为一个适用于真实世界环境的通用具身运行时。
我们围绕三个密切相关的组件构建了 ABot-Claw,如图2所示。
首先通过一个统一的具身接口扩展了 OpenClaw,该接口连接了多种类型的机器人,并通过一个共享的技能层暴露它们的能力。
然后,我们引入了一个以视觉为中心的多模态记忆,它在共享记忆空间中存储位置锚点、物体观察和语义图像,从而使智能体能够基于扎根于环境的上下文进行推理,而不仅仅是依赖当前的观察。
最后,我们结合了一个基于通用奖励模型的评估者(critic)风格反馈模块,它在执行过程中提供任务进度的明确信号,并在需要时支持终止、局部纠正或重规划。
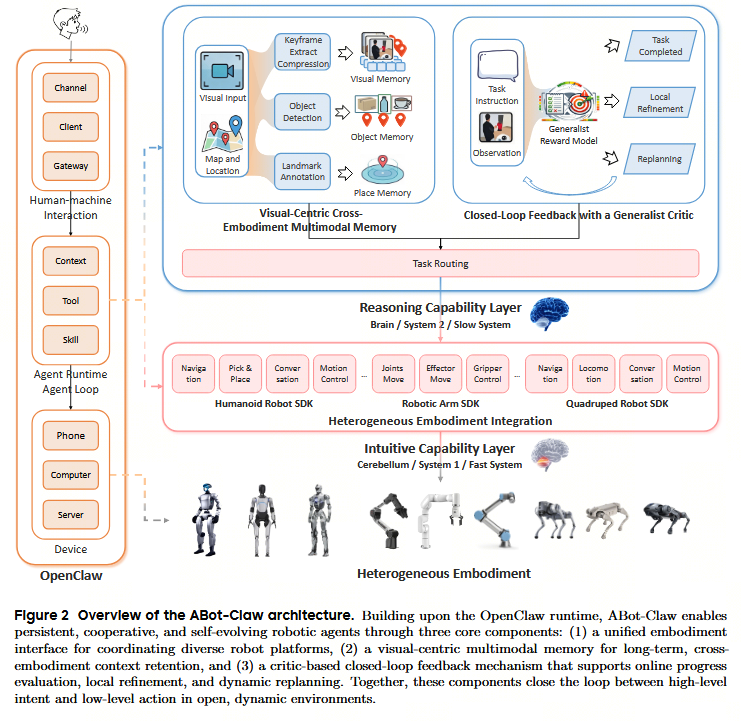
视觉为中心的跨本体多模态记忆
为了解决这一鸿沟,我们构建了一个以视觉为中心的多模态记忆 ,它在一个共享的记忆空间中存储来自不同机器人的观察结果。我们没有将所有感知输出强制转换为纯文本,而是保留了视觉、语义和空间信息 ,使其保持在对后续检索和执行有用的水平。这种记忆充当了高级推理和物理执行之间的基础知识(grounding knowledge) :它为智能体提供了一个持久的概念,即物体在哪里 、观察到了什么 ,以及如何将检索到的结果转化为用于导航或操作的具体目标。
记忆类型
我们围绕四种类型的实体来组织记忆,每种实体对应不同粒度的具身上下文。
视觉记忆存储场景级别的观察结果及其语义和时空上下文。 每个条目包含由视觉-语言编码器提取的视觉嵌入,从而实现了对无约束观察的开放词汇检索。同时,系统根据信息密度和场景新颖度,维护从长视觉流中选择的稀疏关键帧 1。每个关键帧都与时间戳和位姿元数据相关联,使得运行时不仅能够检索语义相关的场景,还能为环境初始化、历史回顾和跨机器人的视角重访检索信息丰富的视觉快照 。通过将语义嵌入与关键帧级别的结构相结合,视觉记忆同时支持语言驱动的搜索 和高效的轨迹摘要。
**以物体为中心的记忆锚定与下游交互相关的实体。**连续视觉检测器识别场景中的显著物体,并存储它们的类别标签、观察时间戳、源机器人标识符以及相关的空间信息(如3D位姿)。这种记忆对于抓取和放置等任务特别有用,在这些任务中,运行时需要物体级别的基础(object-level grounding)以及恢复目标最后已知观察结果的能力。
**位置锚点记忆代表环境中具有语义意义的位置。**通过自动注册或用户注释,选定的坐标与诸如厨房、入口或沙发区等名称相关联。这些锚点将连续空间离散化为对语言友好的节点,使规划器更容易对目的地、邻近区域和任务相关区域进行推理。
检索机制
由于不同的记忆实体捕获不同种类的上下文,我们支持两种互补的检索范式。
**对于图像-语义记忆,我们采用潜在空间跨模态检索。**视觉-语言编码器将视觉观察和文本查询映射到一个共享的嵌入空间中,并通过使用余弦相似度的最近邻搜索来执行检索。这允许智能体直接通过自然语言搜索记忆,即使查询涉及仅通过预定义标签难以指定的属性和关系的组合。
**对于以物体为中心和位置锚点记忆,我们对离散元数据(如物体类别、源机器人、时间窗口和空间约束)使用结构化检索。**在实践中,这些结构化过滤器可以与语义检索相结合。例如,运行时可以首先检索语义相关的帧,然后将结果缩小到来自最近时间窗口或环境特定区域的观察结果。
可导航返回协议。只有当记忆系统的输出可以直接被下游控制器使用时,它对具身执行才是有用的。为了避免给语言模型增加特定模态解析逻辑的负担,我们将所有检索结果归一化为一个统一的可执行动作表示,其中包括语义类别、置信度分数、视觉证据,以及最重要的是全局坐标系中稳定的3D位姿。因此,运行时可以直接将返回的位姿传递给所选机器人具身的导航栈或运动规划器。可以对持久的环境上下文进行推理,而不是仅仅对即时的观察做出反应。