26年5月来自复旦大学、上海AI实验室和新加坡国立的论文"World Action Models: The Next Frontier in Embodied AI"。
视觉-语言-动作(VLA)模型在具身策略学习方面已展现出强大的语义泛化能力,但它们往往仅学习反应式的"观测-动作"映射,而未显式建模物理世界在受到干预时如何演变。越来越多的研究工作正致力于通过将"世界模型"(即环境动态的预测模型)整合至动作生成流程中,来克服这一局限。这一新兴范式命名为"世界动作模型"(WAMs):这是一种具身基础模型,旨在统一状态预测建模与动作生成过程,其目标是建模未来状态与动作的联合分布,而非仅针对动作本身。然而,现有文献在模型架构、学习目标及应用场景方面仍显分散,缺乏统一的概念框架。本文正式定义 WAMs,并将其与相关概念进行明确区分;同时,追溯促成该范式诞生的 VLA 研究与世界模型研究的理论基础及其早期融合历程。现有方法归纳整理为结构化的分类体系,划分为"级联式 WAMs"与"联合式 WAMs"两大类,并依据生成模态、条件机制及动作解码策略进行了进一步细分。此外,系统性地分析了推动 WAMs 发展的数据生态系统,涵盖机器人遥控操作、便携式人类演示、仿真环境以及互联网规模的第一人称视角视频数据;并对新兴的评估协议进行了归纳总结,这些协议主要围绕视觉保真度、物理常识及动作合理性等维度展开。总体而言,本综述首次对 WAMs 领域的全景图谱进行了系统性梳理,阐明了关键的模型架构范式及其权衡取舍,并指出了这一快速演进领域所面临的开放性挑战与未来的发展机遇。
如图 1 所示:关于"世界动作模型"(WAMs)代表性工作的演化历程与分类体系。左侧分支展示"联合式 WAM"架构的演进脉络------此类架构将世界状态预测与动作生成紧密耦合,并呈现出向自回归(Autoregressive)与扩散模型(Diffusion-based)两种表征范式的分化;其中,基于连续表征的方法进一步细分为"统一流"(Unified Stream)与"多流"(Multi-Stream)两种主干网络结构。右侧分支概述"级联式 WAM"流水线的演变历程------此类架构中,世界状态建模与动作执行环节主要呈解耦状态,其发展路径沿"显式"与"隐式"两种表征对齐策略展开。上述结构性策略代表了该领域在架构耦合方式上所探索的主流方向,而非单纯的严格按时间顺序进行的迭代更替。
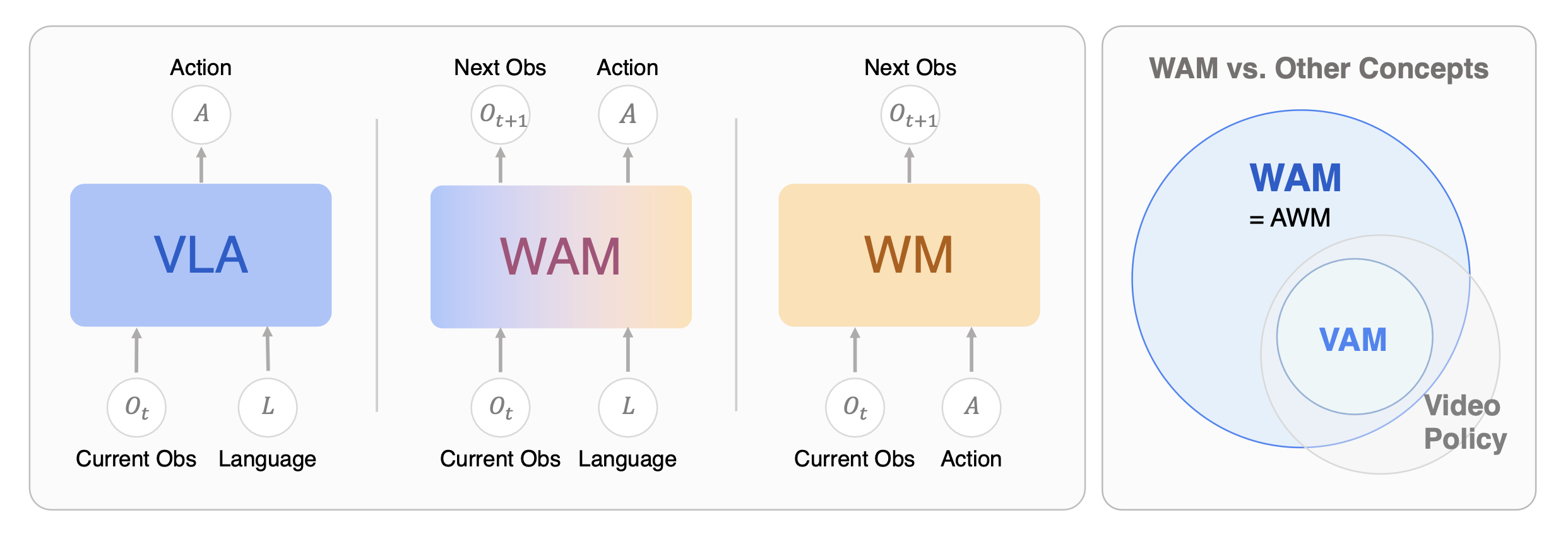
如图 3 所示:世界动作模型(WAMs)的概念定义与对比。左侧面板对比"视觉-语言-动作"(VLA)模型、WAMs 以及标准"世界模型"(WMs)的输入-输出范式,突显 WAM 联合预测行动与未来观测结果的能力。右侧面板展示了 WAM 相较于视频-动作模型(VAMs)和视频策略等其他范式的概念范畴。
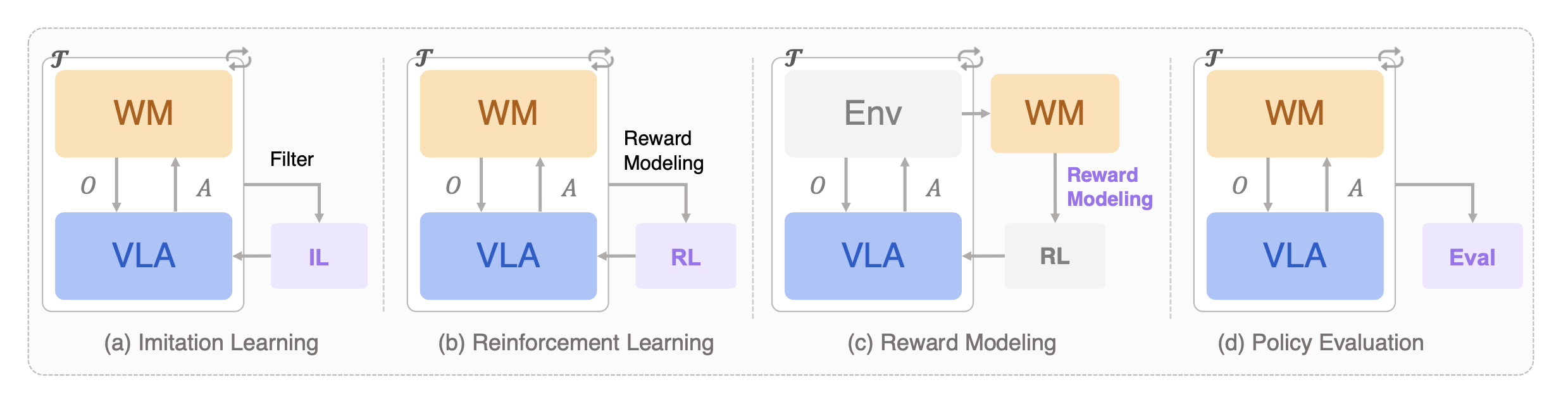
如图 4 所示用于 VLA 学习与评估的世界模型示意图。世界模型能够支持:(a) 模仿学习------通过生成或筛选训练轨迹来实现;(b) 强化学习------通过促成"想象交互"及基于奖励的策略优化来实现;© 奖励建模------通过基于习得的动力学模型或未来结果来生成奖励信号来实现;以及 (d) 策略评估------通过充当数据驱动的模拟器来进行虚拟推演与测试来实现。其中,𝒯 表示推演轨迹。
世界模型用于策略训练与评估的外生工具------充当仿真环境、奖励模型或鲁棒基准。但近期的研究进展已转向将世界建模直接整合进策略架构之中,这一转变将世界模型从离线的监督者转化为内部的预测核心,使"世界-动作模型"(World Action Models,简称 WAMs)能够实时地对世界动态进行推理。基于其结构流程及相应的训练机制,这些世界-动作模型架构归纳为两大主要范式:(1) 级联式 WAM采用一种序贯式的流水线结构,首先预测下一状态(例如在像素空间、潜空间或流空间中),随后依据该状态推导出相应的动作。由于这种结构上的解耦,该范式的特征在于其训练过程也是分离的,即世界模型与动作解码器作为相互独立的模块进行优化;(2) 联合式 WAM 将状态预测建模与动作生成统一整合于单一的整体模型之中,从而同步生成未来的状态与动作。在该范式下,世界建模与动作生成在统一的目标函数指引下进行联合训练,从而迫使模型将环境动态与控制信号之间存在的因果相互依赖关系内化于自身。
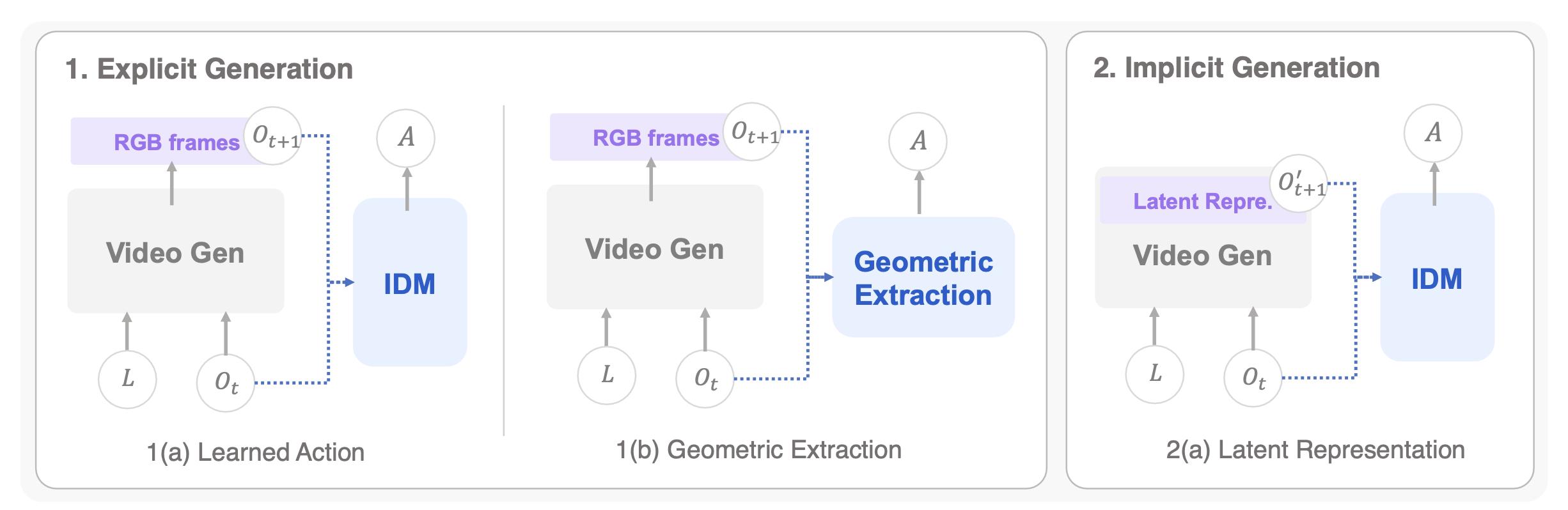
级联式世界-动作模型通过一种序贯的两阶段流水线机制来实现世界状态到动作的映射:首先,世界模型合成一份视觉规划,用以表征预期的未来状态;随后,一个独立的动作模型依据这份规划解码出可执行的机器人控制指令。这种任务分解方式提供一种天然的归纳偏置------即世界模型无需对机器人运动学进行推理,而动作模型也无需解决长时程的场景预测问题------但与此同时,这种分解也在两个阶段之间引入一种耦合关系,而这种耦合关系深刻地影响并塑造了该类方法家族中所有的设计决策。依据中间规划载体的类型不同,级联式 WAMs 大致可划分为两大类别:(1) 基于像素空间表征的"显式规划";(2) 基于潜空间表征的"隐式规划"。
如图 5 所示提供对上述级联模式的概览示意图:1(a) 学习式动作:世界模型生成一个显式的像素空间未来规划,该规划通过一个经学习获得的逆动力学模型或动作模型被映射为具体动作。1(b) 几何提取:显式的视觉规划通过几何提取过程被转化为动作或轨迹。2(a) 潜表征:中间规划载体并非未来的RGB图像帧,而是一种潜未来表征;下游动作模型将从中解码出可执行的指令。
"联合世界-动作模型"(Joint World-Action Models)是指一类架构家族,在该类架构中,未来的世界状态与动作均在单一的统一模型内部进行预测,且世界建模与动作生成在训练过程中均作为联合监督目标 16, 19--22, 95--98, 101, 107, 108。因此,此类联合架构的核心设计问题在于:在这一共享的预测系统中,世界状态的生成与动作的生成究竟是如何相互耦合的。基于这一统一的定义,现有的联合世界-动作模型可依据实现世界-动作预测所依赖的底层基础,进一步划分为两大类生成范式:(1) 自回归生成:将未来的世界变量与动作变量序列化并映射至"token空间"中,进而通过自回归预测的方式对其进行建模;(2) 基于扩散的非自回归生成:通过基于扩散模型或流模型(flow-based models)的生成过程,来生成未来的观测数据、潜在世界状态或动作轨迹,从而实现在连续潜空间内,或通过并行的去噪流,对这两种模态进行联合的迭代精化。
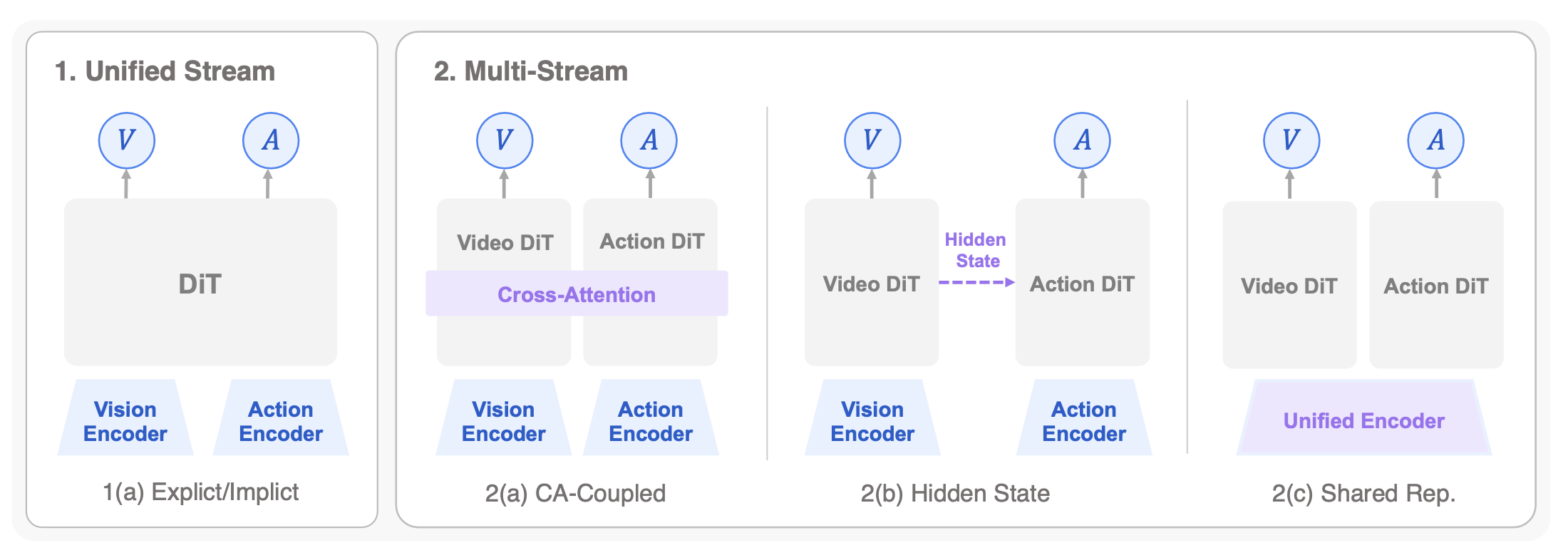
为了系统地刻画基于扩散的联合模型所呈现的多元化图景,依据其预测流的结构耦合方式来组织讨论内容:(1) 统一流架构:这类模型将世界状态变量与动作变量整合进单一且同质化的预测主干网络中(例如,单一的 DiT 模型)。在此范式下,世界建模与动作生成被视为在共享隐空间内执行的一项联合去噪任务,并通过统一的注意机制确保两者之间实现尽可能紧密的同步。(2) 多流架构:这类设计将生成任务分配至相互协调的分支网络或针对特定模态的专家模块中。世界状态分支与动作分支之间的交互是通过显式的耦合机制来实现的,例如交叉注意、隐状态条件化或共享编码器。这种基于主干网络层面的区分,构成理解世界状态分支与动作分支在结构上如何融合------究竟是通过单一流中的共享表征,还是通过多流之间的模块化交互------从而实现连贯的联合预测的核心维度。图 6 提供对此类架构及其主要子模式的概览示意图: CA - 交叉注意
训练鲁棒且具有泛化能力的"世界动作模型"(WAMs)面临的根本瓶颈在于具身数据的可用性与质量。与主要依靠被动抓取的互联网文本而蓬勃发展的大语言模型不同,WAMs 需要严格的物理基础(physical grounding)来捕捉复杂的状态转移、动作条件依赖以及直观物理学原理。更重要的是,WAMs 对数据的需求与传统的机器人范式存在显著差异。标准的"视觉-语言-动作"(VLA)模型严格要求成对的 (o_t, a_t) 轨迹数据;鉴于远程操控演示数据的高昂成本和稀缺性,这一要求严重限制模型的扩展能力。相反,纯粹的"世界模型"(World Models)虽然能够充分利用来自互联网视频的无动作 (o_t, o_t+1) 序列数据,但却缺乏在物理控制层面的基础支撑。
WAMs 的独特优势在于其统一的数据整合能力。它们能够独具匠心地从上述各个数据领域的交汇点中获益:一方面,利用高质量的 (o_t, a_t, o_t+1) 三元组数据来紧密耦合其内部表征;另一方面,凭借其灵活的架构设计,通过联合训练策略,同时摄取海量的非成对数据(例如,用于学习视觉物理学的无动作视频)。因此,构建 WAMs 的数据生态不仅仅是简单地扩充以机器人为中心的数据规模;它更需要一种战略性的数据混合策略,将严格耦合的演示数据与非受限的观测数据巧妙地结合起来。
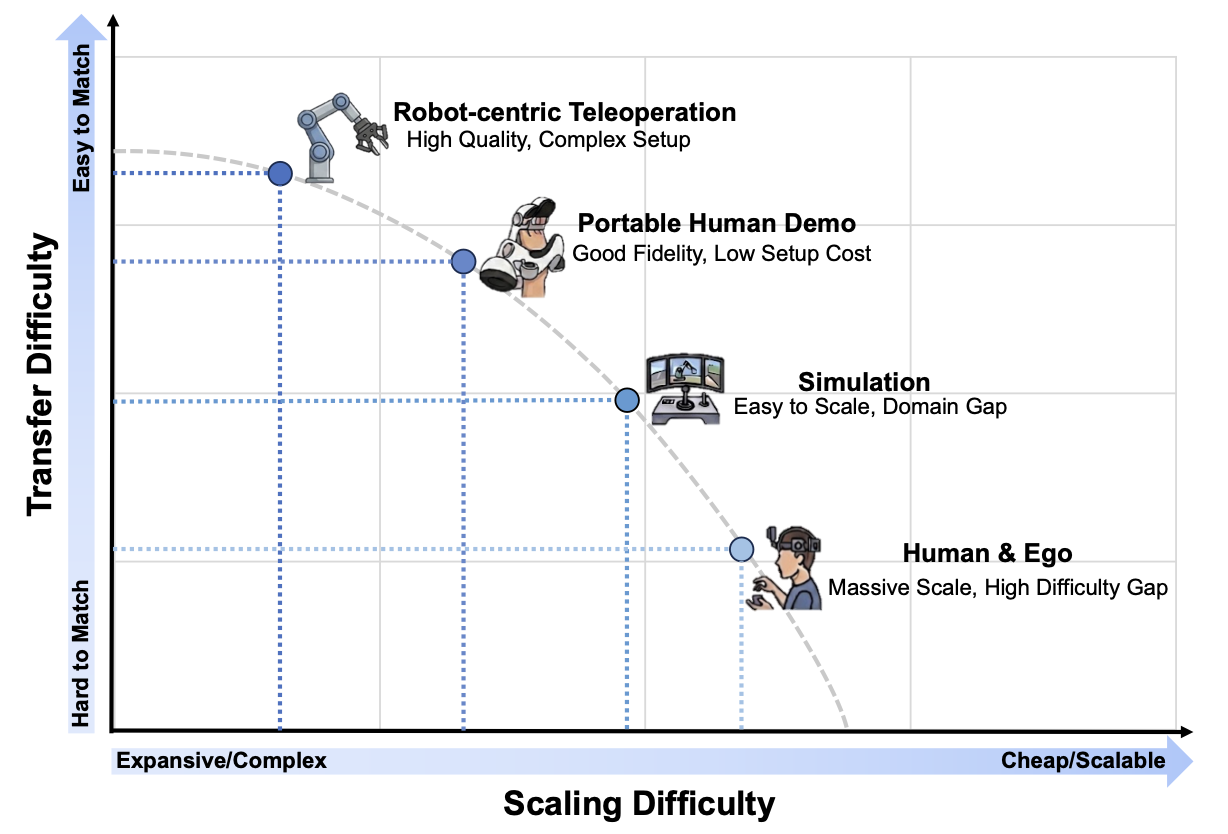
WAMs 训练有四种主要数据范式:(1) 高保真度的"以机器人为中心的远程操控数据",此类数据提供精确的运动学基础;(2) 灵活便捷的"便携式人类演示数据",此类数据将人类的灵巧操作能力与现实世界的交互体验相连接(例如 UMI 数据集);(3) 极具扩展潜力的"仿真数据",此类数据能够提供无限的程序化变化组合以及具有特权视角的空间监督信息;(4) 覆盖广泛的"人类视角与自我中心视角数据",此类数据为被动的世界动态演化提供近乎无限的先验知识。如图7所描绘的内在权衡之间进行取舍------其范围涵盖从以机器人为中心的远程操作那种复杂、僵化的设置,到互联网视频那种低成本且极具规模扩展性的特性------研究人员正日益利用这些数据集的互补组合,以弥合精确的低层级机器人控制与广阔的开放世界泛化能力之间的鸿沟。