%3.47 基于全向图像的孪生神经网络在室内机器人定位中的实验评估
@article{cabrera2024experimental,
title={An experimental evaluation of Siamese Neural Networks for robot localization using omnidirectional imaging in indoor environments},
author={Cabrera, Juan Jos{\'e} and Rom{\'a}n, Vicente and Gil, Arturo and Reinoso, Oscar and Pay{\'a}, Luis},
journal={Artificial Intelligence Review},
volume={57},
number={8},
pages={198},
year={2024},
publisher={Springer}
}
豆包阅读
这篇 2024 年发表于Artificial Intelligence Review 的论文,核心是用孪生神经网络(Siamese Neural Network, SNN)结合全景视觉,解决室内移动机器人全局定位问题,并通过大量实验验证网络结构、训练参数与数据增强对定位效果的影响。
一、研究背景与目标
- 核心问题 室内移动机器人自主导航的关键是全局定位,传统视觉定位依赖 SIFT/ORB 等局部特征或全局描述子,对光照变化、图像模糊鲁棒性差;全景相机虽能提供 360° 环境信息,但缺乏高效的特征匹配与相似度计算方法。
- 研究目标
- 验证孪生神经网络用全景图像建模室内环境、完成图像检索与定位的可行性。
- 实现两大任务:房间判别 (判断两张图是否来自同一房间)、全局定位(直接估计机器人位姿)。
- 优化网络结构、训练参数,提升对光照变化、模糊、旋转等真实场景干扰的鲁棒性。
- 创新点
- 首次将孪生神经网络系统性用于全景视觉的室内机器人全局定位。
- 设计专用光照增强数据增强策略,模拟真实环境光影变化。
- 完整对比不同 CNN 主干、全连接层、训练配比的效果,给出最优配置。
二、核心方法:孪生神经网络定位框架
1. 孪生网络基础结构
- 由两个共享权重的 CNN 分支组成,输入两张全景图(128×512 分辨率)。
- 每个 CNN 输出全局图像描述子 ,通过欧氏距离计算描述子差异,衡量图像相似度。
- 损失函数:对比损失(Contrastive Loss),让同位置 / 同房间描述子距离小,不同位置 / 房间距离大。
2. 两大定位任务设计
(1)房间判别(Room Discrimination)
- 输入:成对全景图,标签0 = 同房间 、1 = 不同房间。
- 输出:网络预测相似度,阈值 0.5 区分是否同房间。
- 目的:验证网络对环境语义区域的区分能力,为全局定位铺垫。
(2)全局定位(Global Localization)
- 前提:预先生成环境视觉地图(含全景图、对应位姿、房间信息)。
- 流程:测试图→孪生网络生成描述子→与地图描述子匹配→距离最小的地图位姿即为定位结果。
- 标签规则:同房间按位姿欧氏距离归一化赋值,不同房间直接标 1。
3. 网络组件与参数设置
- 特征提取主干 对比多种 CNN:AlexNet、DenseNet、VGG11/13/16/19(含 BN 版本)、2 种简易 3 层 CNN。
- 特征聚合层 用全连接层压缩高维特征为紧凑描述子,测试 3 组配置:
- 500--500--5、500--100--10、1000--1000--10。
- 训练超参 优化器:SGD(学习率 0.001,动量 0.9);批量大小:16/256;训练轮次:7--30 轮。
- 数据增强(核心创新) 专为光照变化、机器人运动 设计,分局部 / 全局 / 组合效果:
- 局部:模拟灯泡、方形 / 梯形光斑、阴影衰减。
- 全局:整体明暗、锐化 / 模糊、对比度、饱和度、任意角度旋转(适配全景 360°)。
- 组合:多光影效果叠加,提升泛化性。
4. 实验数据集
采用COLD-Freiburg 室内全景数据集 ,覆盖 9 个房间(走廊、办公室、图书馆、浴室等),含阴天、夜晚、晴天三种光照:
- 训练集 1:8486 张原始图(三种光照)。
- 训练集 2:977856 张增强图(仅阴天原图增强)。
- 测试集:阴天 / 夜晚 / 晴天各独立子集,共 7416 张;视觉地图:556 张阴天采样图。
三、实验结果与分析
1. 房间判别任务
- 最优主干 :VGG13/VGG16 表现最佳,全局准确率达 96.16%,同房间准确率 98.90%,不同房间 93.41%。
- 训练配比影响 :同房间 10%+ 不同房间 90% 配比效果最优,平衡两类判别精度。
- 批量大小:小批量(16)较大批量(256)精度更高。
- 全连接层:1000--1000--10 结构判别效果最好。
2. 全局定位任务
- 核心指标:平均绝对误差(MAE)、均方误差(MSE)、Top1% 召回率。
- 最优配置
- 主干:VGG16;全连接层:500--500--5(泛化性最强,跨光照稳定)。
- 训练配比:同房间 40%+ 不同房间 60% ,全局 MAE 最低至0.509m。
- 数据增强效果
- 阴天:误差降低约12cm ;夜晚:降低约20cm。
- 晴天:误差上升(增强无法完全模拟真实强光环境)。
- 结论:数据增强显著提升阴天 / 夜晚鲁棒性,是弱光定位的关键优化手段。
- 光照鲁棒性 网络在阴天、夜晚表现最优,晴天因光照剧烈变化精度下降,符合真实室内场景规律。
3. 与现有方法对比
- 本文方法在阴天、夜晚 定位误差低于 AlexNet、EfficientNet、HOG、GIST等传统 / 单 CNN 方法。
- 晴天场景精度略低于 EfficientNet,核心原因是损失函数与全景图预处理方式差异。
四、结论与局限
1. 核心结论
- 孪生神经网络非常适合全景视觉机器人定位,可高效完成图像检索与位姿估计。
- VGG16+500-500-5 全连接层 + 4:6 训练配比是室内定位最优配置。
- 专用光照数据增强大幅提升阴天 / 夜晚定位精度,是弱光环境必备策略。
- 对比损失函数存在优化空间,导致同 / 不同房间判别精度此消彼长。
2. 研究局限
- 对晴天强光等极端光照变化鲁棒性不足。
- 仅验证室内环境,未拓展至复杂室外场景。
- 仅使用视觉传感器,未融合 LiDAR 等多传感器信息。
3. 未来工作
- 将方法拓展至室外非结构化环境。
- 融合LiDAR与视觉数据,提升定位鲁棒性。
- 替换对比损失为Circle Loss等更灵活的损失函数,优化相似度学习。
- 代码开源:https://github.com/juanjo-cabrera/IndoorLocalizationSNN
五、关键贡献总结
- 验证了孪生神经网络在全景视觉室内定位的有效性,提供完整实验范式。
- 提出光照自适应数据增强,显著提升弱光定位性能。
- 给出可直接落地的网络结构与训练参数最优组合,为工程应用提供参考。
- 系统对比现有方法,证明该方案在阴天 / 夜晚场景的先进性。
摘要
本文的目的是利用安装在机器人上的折射式视觉系统获取的全方位图像来解决定位问题。为此,我们探索了暹罗神经网络在使用全景图像作为唯一信息源来建模室内环境方面的潜力。暹罗神经网络的特点是能够在两个输入数据之间生成相似性函数,在这种情况下,是在两个全景图像之间。本研究使用由两个卷积神经网络(CNN)组成的暹罗神经网络。每个CNN的输出是用于描述每个图像的描述符。通过测量这些描述符之间的距离来计算图像的相异度。这一事实使孪生神经网络特别适合执行图像检索任务。首先,我们评估一个与定位密切相关的初始任务,即检测两个图像是在同一个房间还是在不同的房间拍摄的。接下来,我们在全球本地化问题的背景下评估暹罗神经网络。在各种光照条件下,尤其是使用在多云和夜间条件下拍摄的图像时,该方法的结果优于以前使用COLD-Freiburg数据集解决定位任务的技术。定位;全方位成像;整体描述;移动机器人;暹罗神经网络
1.前言
在过去的几年里,视觉传感器在移动机器人的地图构建和定位领域得到了广泛的应用(Hu等人,2020年;钟等人,2018年)。特别是,在地图上进行定位的能力对于开发能够在真实运行条件下导航的自主机器人。人们对使用视觉传感器从环境中获取信息的兴趣仍然很高。摄像头可以以相对较低的成本从环境中捕捉大量信息,并且可以在室内和室外区域使用。此外,这些图像还允许执行其他高度专业化的任务,如目标识别和人物检测。
在可用来捕获视觉信息的配置中,全向视觉传感器在移动机器人中的使用已经变得普遍。全方位摄像机获取覆盖机器人周围360°视野的图像(Junior等人,2016)。因此,它们通常用于解决导航任务(Rituerto等人,2010)。
摄像机提供的大量信息需要强大的技术来提取和描述相关的视觉信息。已经考虑了不同的范例来提取这一相关信息。第一组技术集中于检测、描述和跟踪场景沿线的一些地标或局部特征(曹等人,2020年;林等人,2020)。地图绘制和本地化任务中使用了不同的本地特征,包括SIFT、SURF和ORB描述符(E.Rublee和Bradski,2011)。然后,例如,可以通过词袋模型(RaúL Mur-Artal和TardóS 2015)获得对每个图像的全球描述。第二组技术将每个场景作为一个整体进行处理,并为每个图像构建包含其全球外观信息的唯一描述符(KorRapati和Mezouar 2017;Khaliq等人)。2019年)。最后,硬件的发展导致许多作者使用人工智能(AI)技术从图像中提取相关信息。具体地说,卷积神经网络(CNN)已经被提出来解决不同的计算机视觉和机器人任务。例如,Xu等人。(2019)和Leyva-Vallina等人。(2019)提出了基于CNN的全局外观描述子,以获得机器人最可能的姿势。
总而言之,整体描述方法产生的地图中存储了一组机器人姿势及其关联的描述符。这样,机器人的每个姿态都由一个整体描述符来表示,这种表示法基于描述符间的两两比较得到了简单的定位算法。
在这篇手稿中,我们评估了孪生神经网络在图像描述和机器人定位方面的应用。孪生神经网络允许同时评估两个图像,其方式是在输出端提供相似性度量。因此,它们有可能解决位置的视觉识别和估计移动机器人的位置。在本文中,我们对这一潜力进行了评估。本文的主要贡献可以概括为以下几点。
1.利用全景图像作为唯一的信息源,探讨了暹罗神经网络对室内环境建模的能力。
2.我们对暹罗神经网络进行了训练和评估,目的是检测两个图像是在同一个房间还是在不同的房间拍摄的。
3.将暹罗神经网络训练成一个全局图像检索问题来估计机器人的位置。
4.详细研究了暹罗神经网络的结构和相关参数对网络性能的影响。此外,我们还分析了对实际操作条件下可能出现的一些常见视觉现象的鲁棒性,如光照条件的变化或图像模糊。
2 相关工作
如前所述,孪生神经网络能够从输入数据对中生成相似性函数。它们可以看作是由两个神经网络组成的上层建筑。这些架构接受两个不同的输入,并提供单一输出。底层网络共享相同的权重,并且可以使用不同的函数来确定单个输出。它们最初是在1993年提出的,目的是区分正确的签名和伪造的签名(Bromley等人,1993年)。从那时起,这些体系结构在不同的知识领域被提出。例如,Thiolliere等人,2015提出了一种用于音频和语音信号处理的暹罗神经网络,郑等人,2019)将此体系结构用于比较DNA序列或Jeon等人,2019)将其用于药物发现目的。此外,Parajuli et al.(2017)开发了孪生神经网络来跟踪心脏运动,Sandouk和Chen(2017)提出了一种暹孪生架构来识别音乐标签。最近,苏尔贾西奇等人提出了自己的看法。(2022)使用这种架构进行多目标跟踪(MOT)和人员重新识别。
在过去的几年里,人工智能总体上,特别是CNN,已经被用于移动机器人领域的各种目的。例如,用于地图绘制(Sinha等人,2018年;Moolan-Feroze等人。2019年)、定位(Weinzaepfel等人2019年;卡塔内奥等人。2019年)、导航(赵等人2018年;Ma等人。2019)和同步本地化和地图绘制(Lu和Lu 2019;Liu et al.2019年)。关于基于人工智能使用的移动机器人任务的完整最先进的审查可以在(Cebollada等人)中找到。2020)。人工智能在移动机器人领域的其他应用包括:自动驾驶导航(Polvara等人)。2018年;Organisciak等人。2020)、人脸检测和识别(Wang等人2017年;胡等人。2021)、对象识别和分类(Zaki等人2019年;冯等人。以及地图绘制和定位(Holliday和Dudek 2018;Ruan等人)。2019年)。
卷积神经网络(CNN)是人工智能工具中最流行的技术。目前,由于它们在许多实际应用中的成功表现,它们被用于许多地图和定位任务。它们被设计成接收图像作为输入,它们的结构是专门创建的,以获得合成其中信息的描述符(Chollet等人。2018年)。因此,它们可以用来描述图像的全局外观。从这个意义上讲,Cebollada等人。(2019)提出了用CNN获得的整体描述符在拓扑模型中进行定位,研究它们对光照变化的抵抗能力。此外,Xu等人也提出了自己的观点。(2019)和Leyva-Vallina等人。(2019)提出了这些技术来获得最可能的机器人位置。此外,Ballesta et al.(2021)研究了使用CNN和回归层作为全局外观描述符的本地化任务。最近,Rostkowska和Skrzypczyński(2023年)使用高效网模型(Tan和Le 2019)将全向图像嵌入到单个描述符中,然后使用K最近邻算法来稳健预测给定数据库(MAP)中的拓扑位置。对此,本工作实现了Facebook AI相似度搜索(Faiss)图书馆(Johnson等人2019)以使用KD-树高效地执行最近邻居搜索。
一些众所周知的体系结构已经被用作基本结构来开发用于机器人导航目的的新的改进型网络。AlexNet(Krizevsky等人)2012年)、VGG16(Simonyan和Zisserman 2014)、GoogLeNet(Szegedy等人)。2015)或NetVLAD(Arandjelovic等人2016)是其中的一部分。
本文提出的卷积神经网络可用于构成孪生神经网络。在机器人学领域,它们很少被使用,下面提到在该领域提出这种结构的一些研究。例如,Utkin等人。(2017)使用孪生神经网络通过检测机器人行为中的异常来支持机器人的安全控制。(2018)提出了一种机器人拾取和放置系统,能够使用暹罗神经网络在杂乱的环境中识别和抓住已知和新的物体。此外,Li和Zhang(2019)使用VGG16网络来整合用于目标检测和跟踪的孪生结构。此外,张和鹏(2019)提出了一项研究,在该研究中,孪生网络之后是实时视觉跟踪背景下的完全连接层或区域建议网络结构。
关于机器人定位任务,Leyva-Vallina等人已经提出使用暹罗神经网络来解决花园环境中的位置识别问题(Leyva-Vallina等人)。2019年、2021年)。此外,该架构已被提出用于使用LiDAR扫描进行定位(Yen等人。2018年;Chen等人。2022年)。
本文研究了基于全景图像的移动机器人定位问题,详细研究了孪生神经网络的不同结构和训练结构。为此,我们提出了一种初步的方法来训练和测试网络区分在同一房间和不同房间捕获的图像的能力。此外,在本研究中,我们还使用孪生神经网络来解决全局定位问题。
3 基于孪生神经网络的视觉定位
孪生神经网络可以被描述为一个上层建筑,它至少包括下面的两个不同的神经网络。权重在网络之间共享,并且通过组合两个网络的输出来生成单个输出。图1显示了孪生神经网络体系结构的一般表示。
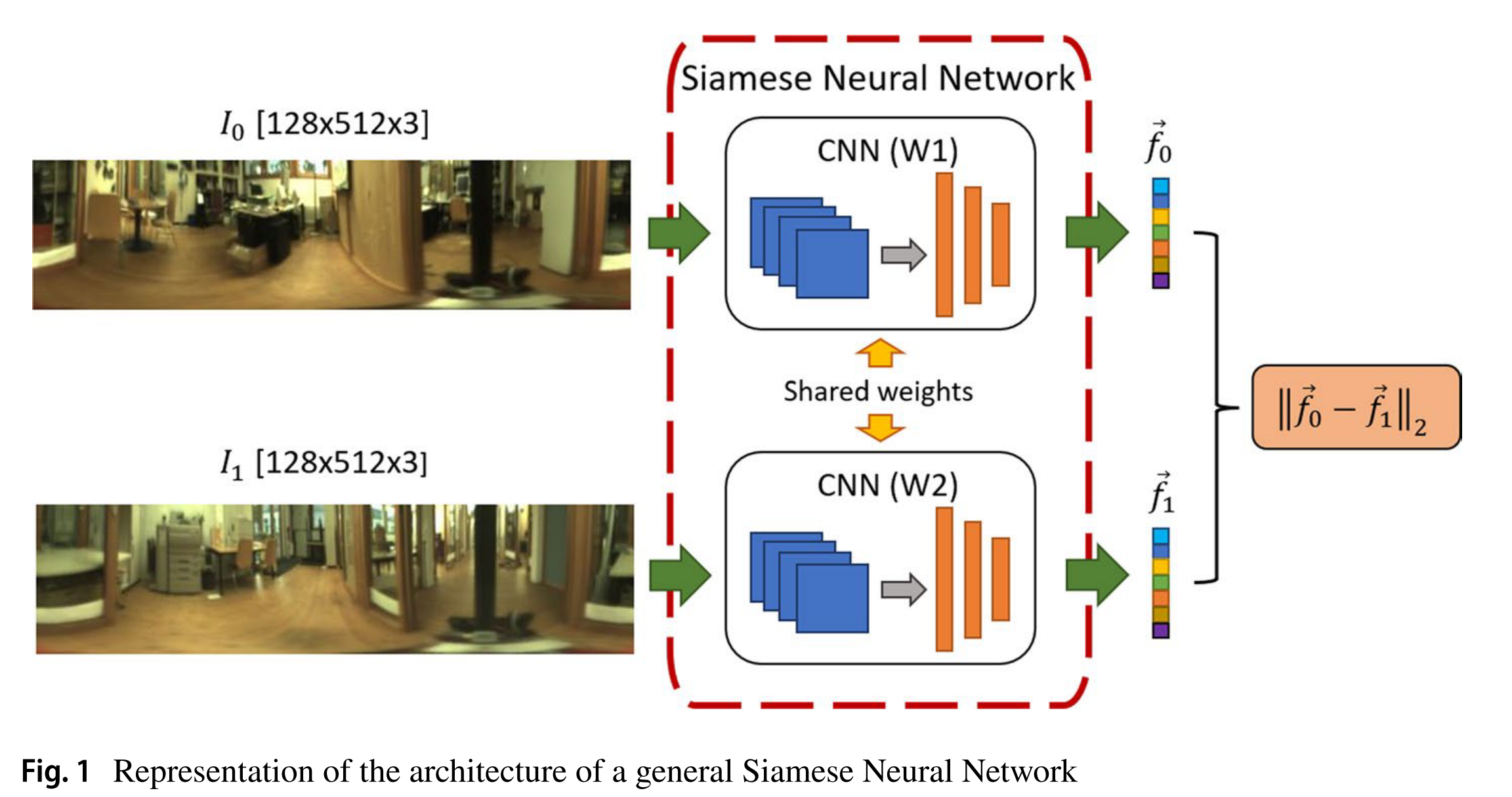
图 1 就是孪生神经网络的标准结构:两个共享权重的 CNN,输入两张图,输出两个特征,用特征距离表示图像相似度,用来做机器人定位。
在本工作中,我们使用卷积神经网络来整合暹罗神经网络的两个分支。每个CNN的输出是用于表征每个输入图像的描述符。通过测量这些描述符之间的距离来计算输入图像的相异度。这样,当训练的图像属于同一类别时,暹罗神经网络就可以被训练成类似的描述符。这一事实使暹罗神经网络特别适合执行图像检索任务。
此外,值得注意的是,网络的输出、训练和性能直接取决于:
·用于提取图像主要特征的子网络W1和W2中使用的体系结构。
·将特征映射从卷积层转换为描述符矢量。
·嵌入这对输入图像的输出描述符的维度。
·使用可用图像进行的培训。特别是,每个类别的图像的标签和比例。
在本文中,我们分析了这些项目对机器人视觉定位的影响。在这个意义上,我们假设环境的可视地图最初是可用的。为了获得这张地图,机器人在整个区域内移动,沿着轨迹捕捉全方位的图像。首先,将图像转换为全景格式(在本工作中大小为128×512),得到集合
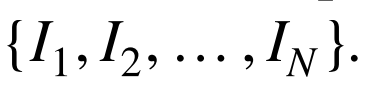
这些图像是从N个视点捕获的,其姿势是已知的并被存储
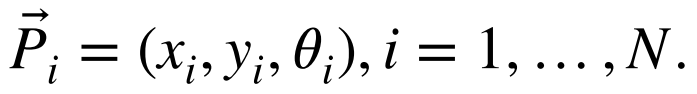
此外,拍摄照片的房间也是已知的,因此可以使用一组标签
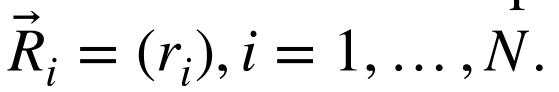
在定位期间,使用所建议的架构,每个图像将被嵌入到单个描述符中,从而产生
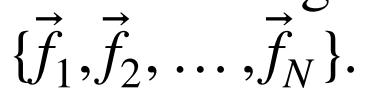
机器人所遵循的轨迹包括具有不同视觉信息的不同房间。
在我们的工作中,这些房间包括一条走廊,一些办公室,一个图书馆和一个浴室。考虑到这些事实,初始地图由图像集合、它们的姿势和捕获图像的房间组成
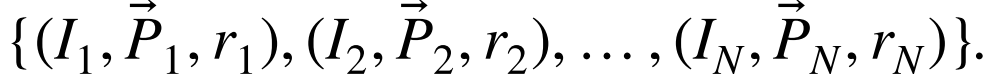
利用这些信息,一些孪生神经网络被训练来解决定位问题。
3.1 房间判别
在本小节中,我们评估一项与定位相关的基础任务,以研究孪生神经网络 能否区分在同一房间拍摄的图像 与在不同房间拍摄的图像 。为此,我们使用随机抽取的、来自同一房间和 / 或不同房间的图像对对模型进行训练与测试。
3.2 全局定位
在本研究中,我们假设环境地图已预先建立 (如前文所述)。绝对定位问题 通过将测试图像与地图中的所有图像直接进行比对来解决。这一比对过程借助地图中每张图像对应的描述fi完成。机器人的位姿由地图中相似度最高 的描述子所对应的位姿确定。本方法仅使用纯视觉信息 求解问题,并假设机器人先前位姿的信息不可用。
4 深度学习工具的体系结构和训练
用于分类任务的经典CNN的结构可以分为两个不同的阶段(Cebollada等人。2019):特征学习和分类阶段。使用多个卷积层来提取特征,而分类任务可以使用完全连通层和最终的Softmax函数来构建。在我们的方法中,分类阶段被特征聚集阶段所取代。在这个意义上,特征提取阶段输出多个特征图,这些特征图被平坦化为向量,并通过完全连通的层来降维。该阶段允许为每个输入图像生成单个描述向量。因此,该模型提供了两个向量⃗f0和⃗f1(每个输入图像一个)。在比较阶段使用欧几里得距离
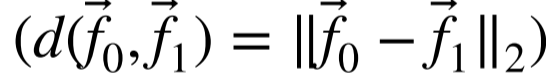
比较这些描述符。这种结构如图2所示。
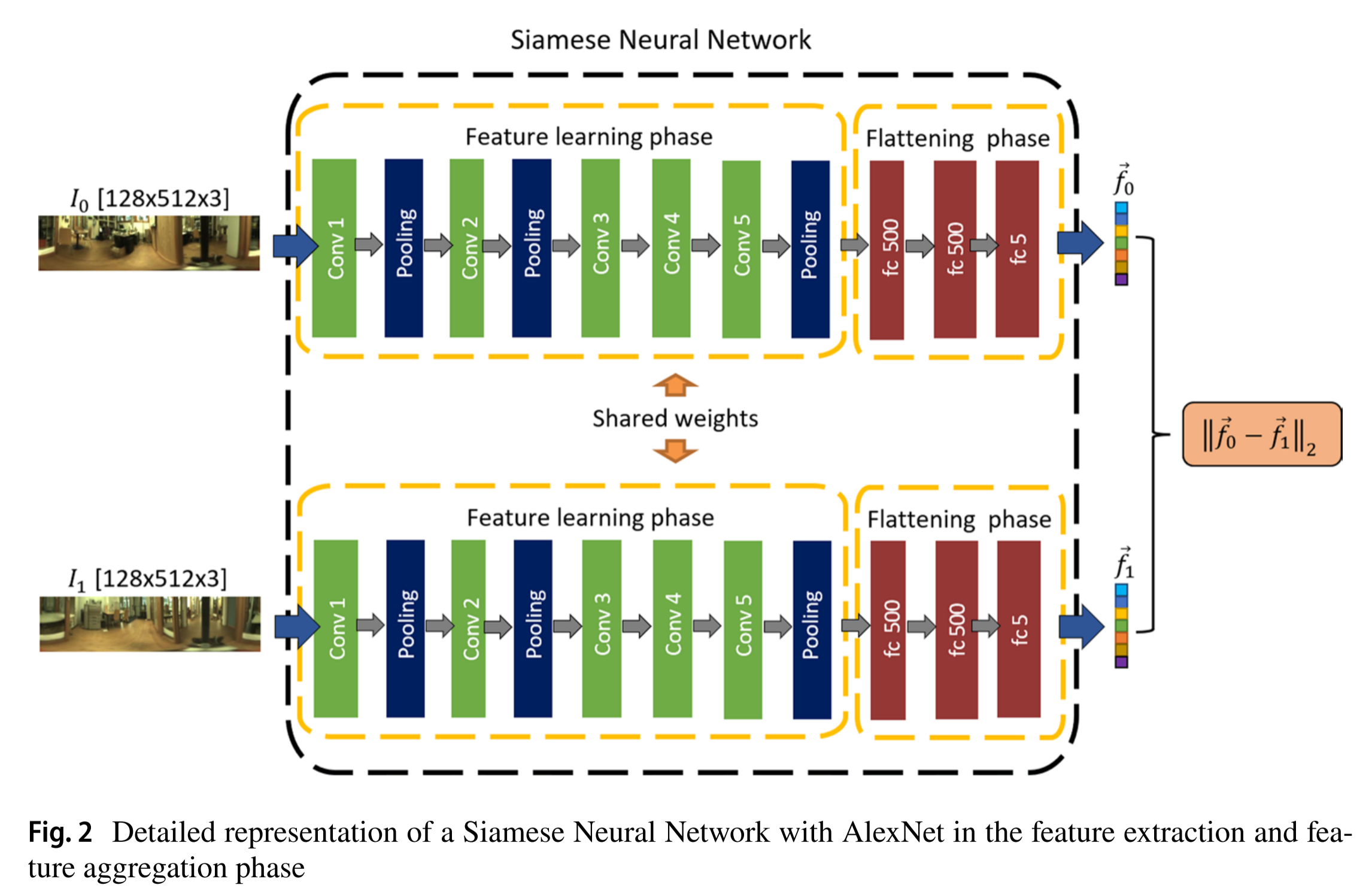
图2
图 2 展示了本文用于室内机器人全景视觉定位的孪生神经网络详细架构。网络包含两个共享权重的分支,每个分支由基于 AlexNet 的特征学习模块与三层全连接的特征聚合模块组成,将输入的全景图像转化为紧凑的全局描述子,并通过计算描述子间的欧氏距离实现图像相似度判断,最终完成房间判别与全局定位。
一、图 2 整体是什么
图 2 = 孪生神经网络 + 以 AlexNet 为特征提取器 + 特征聚合层 + 相似度计算 专门用来把两张全景图 → 变成两个特征向量 → 算距离 → 判断是否同房间 / 同位置。
二、图里每一部分逐行解释
- 两个输入图像
-
I₀(128×512×3) 、I₁(128×512×3)
-
机器人拍摄的全景图,固定尺寸 128×512,彩色 3 通道。
-
可能是:同位置 / 不同位置 / 同房间 / 不同房间。
- 两个完全相同的分支(共享权重)
左右两边结构一模一样、权重完全共享,这是孪生网络的核心。 每个分支分为两大阶段:
-
Feature learning phase(特征学习阶段)
-
Flattening phase(特征展平 & 聚合阶段)
- 第一阶段:Feature learning(特征提取)
论文这里用的是 AlexNet 结构:
-
Conv1 → Pooling → Conv2 → Pooling → Conv3 → Conv4 → Conv5 → Pooling
-
作用:从图像里提取高级视觉特征(墙角、门、桌子、光照纹理等)。
-
输出:一堆特征图(feature maps),不是向量。
- 第二阶段:Flattening phase(特征展平与压缩)
把高维特征图变成紧凑的一维描述子:
-
Flatten(展平):把多维特征图拉成一条长向量。
-
全连接层 FC:
-
第一层 FC-500
-
第二层 FC-500
-
第三层 FC-5
-
-
最终输出:一个长度为 5 的特征向量 F
- 这就是图像的全局描述子。
- 最终计算:相似度 / 距离
两个分支分别输出 F₀ 和 F₁ 后:
-
计算 欧氏距离
-
距离越小 → 图像越相似 → 位置越近
-
距离越大 → 图像越不相似 → 位置越远
这就是论文做房间判别 和全局定位的核心依据。
因此,在训练过程中,网络的权重被更新,以获得最优的全局描述符。比较后,将它们与相似性标签(1:相异,0:相似)之间的距离作为损失函数的数据。在我们的例子中,使用的损失函数是对比损失函数。
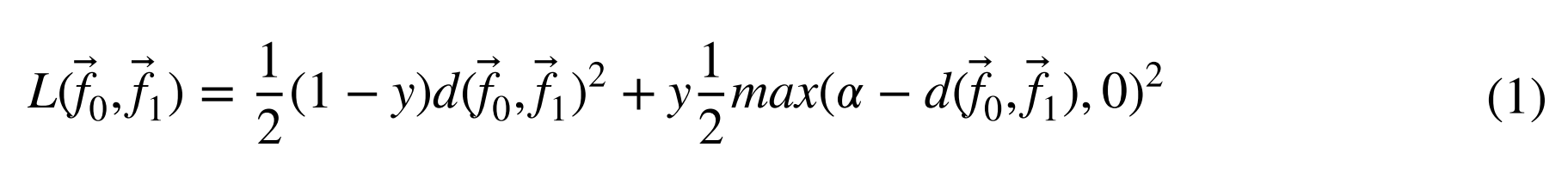
其中y是相似性标签,\(\alpha\)是边界。间隔定义了描述符周围的边界,因此只有当不同的图像对的距离在该边界内时,它们才对损失函数有贡献(Hadsell等人。2006)。
对比损失的核心思想是:让 "同类样本" 的特征距离尽量小,让 "异类样本" 的特征距离至少达到一个边界值\(\alpha\),从而学习到具有区分性的图像描述子,实现房间判别与定位。
对比损失(Contrastive Loss)公式,是孪生神经网络训练的核心目标函数

4.1 参数和网络
在这篇手稿中,我们比较了特征学习阶段的不同网络。作为特征聚集阶段的输入,我们考虑在Alexnet的最后一卷积层中计算的表示(Krizhevsky等人。2012),DenseNet(他等人VGG11、VGG13、VGG16和VGG19(Simonyan和Zisserman,2014年)。AlexNet是CNN的开创性架构,因其在ImageNet大规模视觉识别挑战赛(ILSVRC)2012中的成功而闻名。视觉几何组(VGG)网络进一步促进了图像分类问题的进展,在ImageNet以外的各种任务和数据集上的表现优于基准(Bayraktar等人。2019年、2020年)。VGG网络的主要区别在于卷积层的数量:分别为11、13、16和19层。表1给出了这些CNN的特征提取层。此外,还评估了用三个常规2D层创建的两个简单网络(表2)。为简洁起见,未示出REU激活层,但它们已在每一个Cv2d层之后使用。特征提取层在表1和表2中用黑色表示。不同的特征学习结构在第5节中被评估。
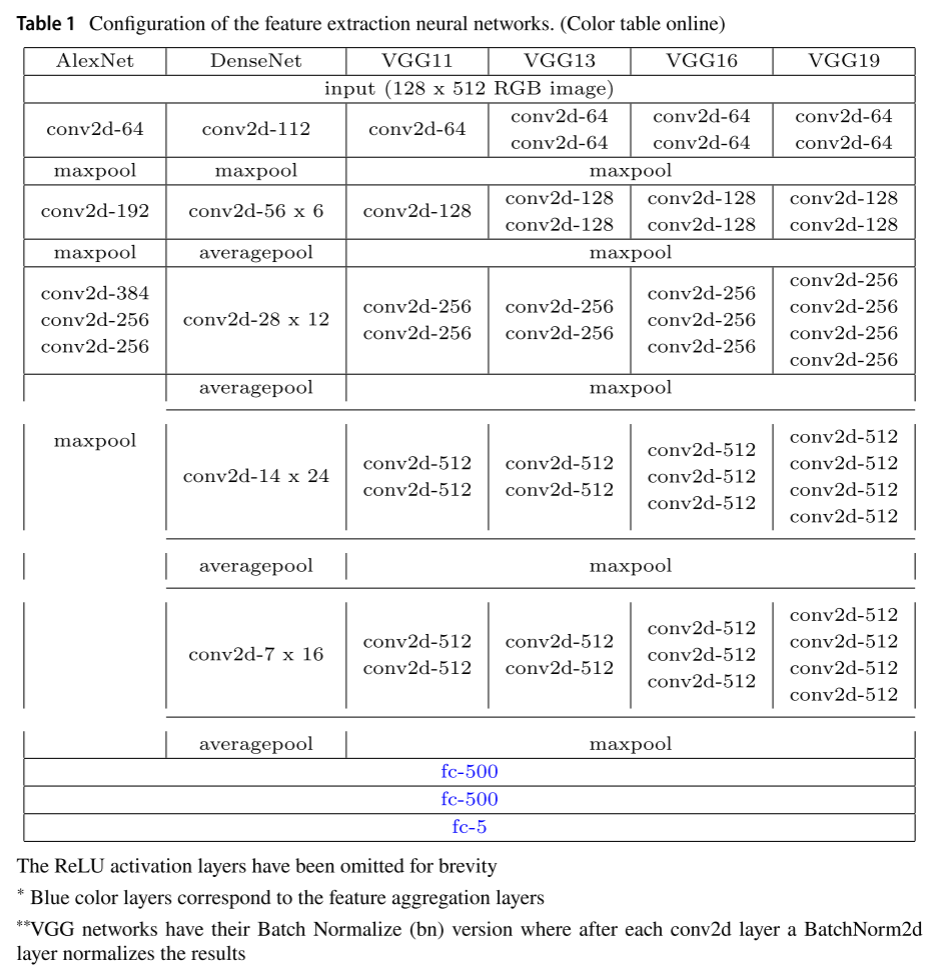
表 1 展示了论文中对比的 6 种 CNN 主干网络(AlexNet、DenseNet、VGG11/13/16/19)的完整结构配置,包括:
- 卷积层(conv2d)
- 池化层(maxpool/averagepool)
- 全连接层(fc)
- 以及后续的特征聚合层(蓝色标出)
所有网络的输入都是128×512 的 RGB 全景图像

表2的目的: 对比预训练的大型 CNN(AlexNet/VGG/DenseNet),测试两个从零训练的简易 CNN,看轻量化模型能否胜任室内定位任务。
- 输入:和其他网络一样,固定为
128×512 RGB全景图像。 - 结构:
- 3 层卷积层 + 1 层池化层 + 3 层全连接特征聚合层(蓝色标出)
- 无预训练权重,所有参数随机初始化。
关键细节说明:
-
ReLU 激活 :和表 1 一样,表中省略了 ReLU 层,但每个
conv2d之后都接了 ReLU 激活函数。 -
蓝色层含义 :
fc-500、fc-500、fc-5是特征聚合层,和表 1 的配置完全一致,保证了不同 CNN 主干在输出描述子时的维度统一。 -
无预训练:两个 Simple 网络都是随机初始化,从零训练,没有用 ImageNet 预训练权重,这样可以和预训练的 AlexNet/VGG 等形成公平对比,验证 "是否必须用预训练模型"。
在所有情况下,特征提取阶段输出通过展平来自最后的MaxPool或AveragePool层的特征地图而获得的高维向量。因此,如果描述符是从该层提取的,则通过最近邻搜索来比较描述符的计算量将是昂贵的。为了缓解这个问题,我们使用完全连通的层将平坦的矢量压缩成紧凑的全局矢量描述符,这可以用于有效的检索,如(Schaupp等人)所示。2019年)。这些层在表1和表2中显示为蓝色。作为全局基线,使用了三个完全连通的层,但考虑了不同的版本,具有不同数量的神经元。在评估过程中使用的不同层如表3所示。

表3定义了 3 种不同的全连接层(FC)结构,用于把 CNN 主干输出的高维特征,压缩成低维的全局图像描述子,方便后续做相似度匹配与定位。 所有配置都是 3 层全连接层,只是每层的神经元数量不同。
4.2 数据集和数据扩充
4.2.1训练和测试数据集
实验中使用的图像来自室内数据集(Pronobis和Caputo,2009)。这个数据库是由安装在移动机器人上的全方位视觉传感器捕获的,该传感器跟踪访问了9个不同房间的不同轨迹。考虑了各种照明条件来捕捉这组图像。
表4显示了本研究中使用的每个数据集的每个房间的图像数量。考虑了两个训练集:训练集1包括在多云、晴朗和夜间光照条件下捕获的8486幅图像(冷-弗莱堡部分A路径2云3,弗莱堡部分A路径2夜间1,弗莱堡部分A路径2晴天3)。通过对训练集1的云序列应用数据增强来获得训练集2,从而生成977,856个图像。关于测试集,考虑了四个不同的集:测试集1由2595个多云光照条件下的图像(冷弗赖堡A部分路径2云2)组成,测试集2包含在夜间光照条件下捕获的图像并由2707个图像组成(冷弗赖堡A部分路径2夜间2),测试集3由2114个阳光光照条件下的图像组成(冷弗赖堡A部分路径2晴天2),以及测试集4由先前测试集中的所有图像组成。应当注意,在所有情况下,测试集中的图像都不同于构成训练集的图像。最后,对测试集1在多云光照条件下的路径进行采样,得到视觉地图,共获得556张图像。