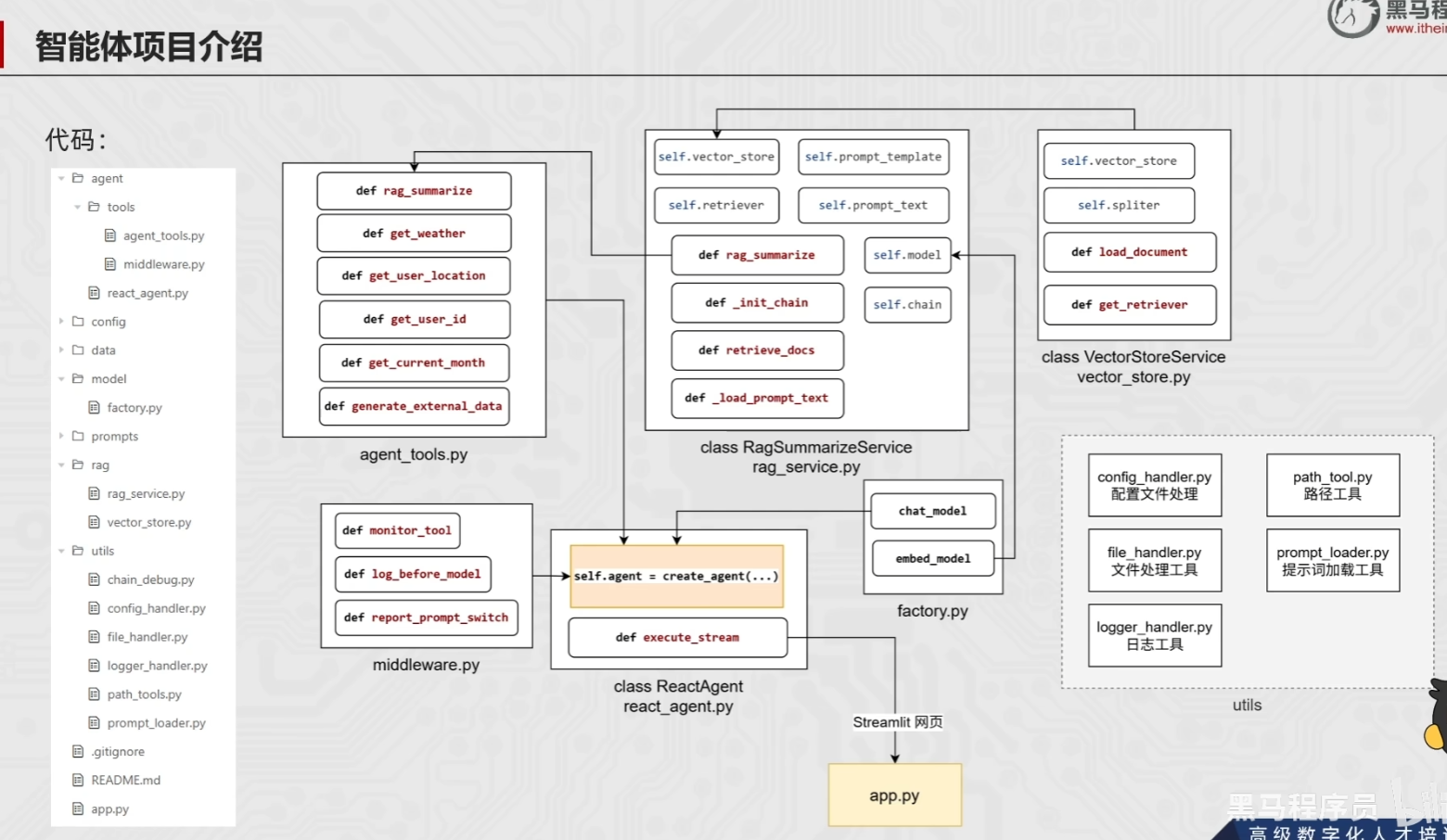
项目介绍

此时RAG也变成了一种工具
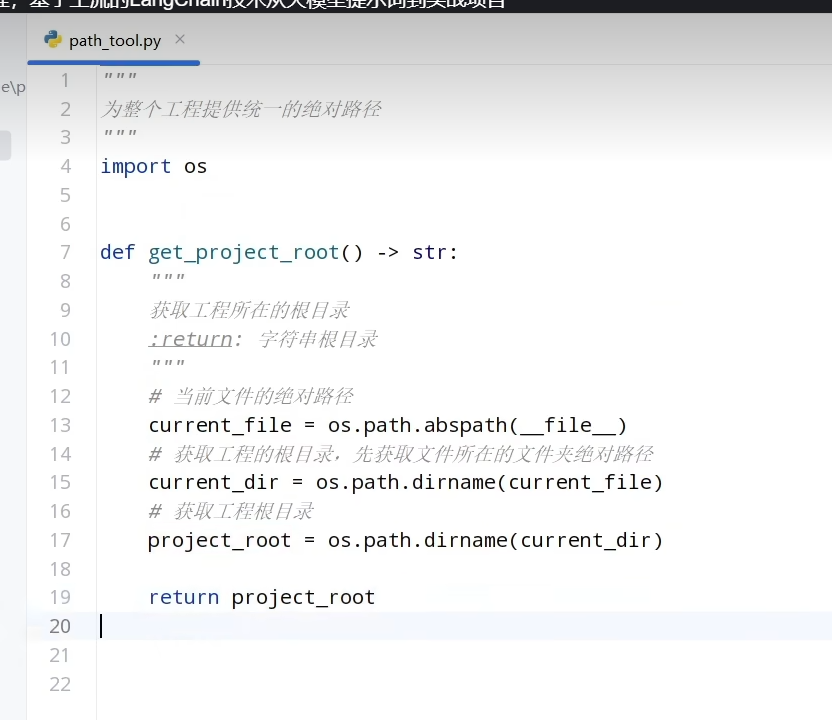
日志和路径工具开发
日志类没学过看不太懂,会用就行。这里不贴了。
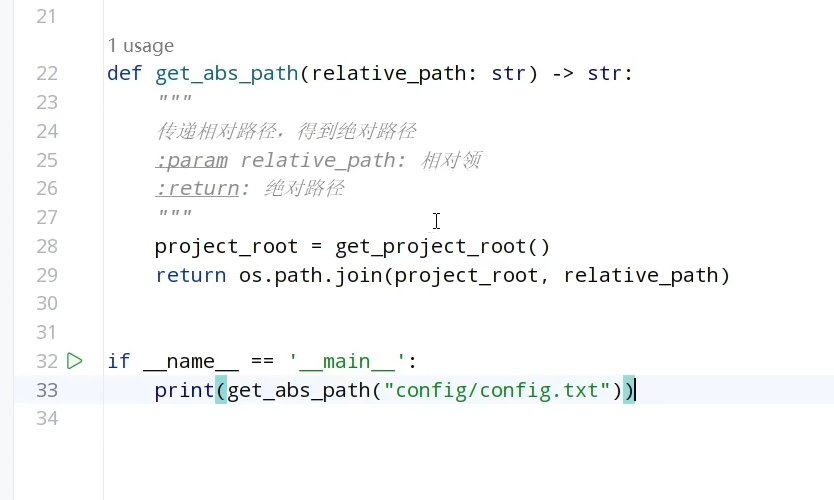
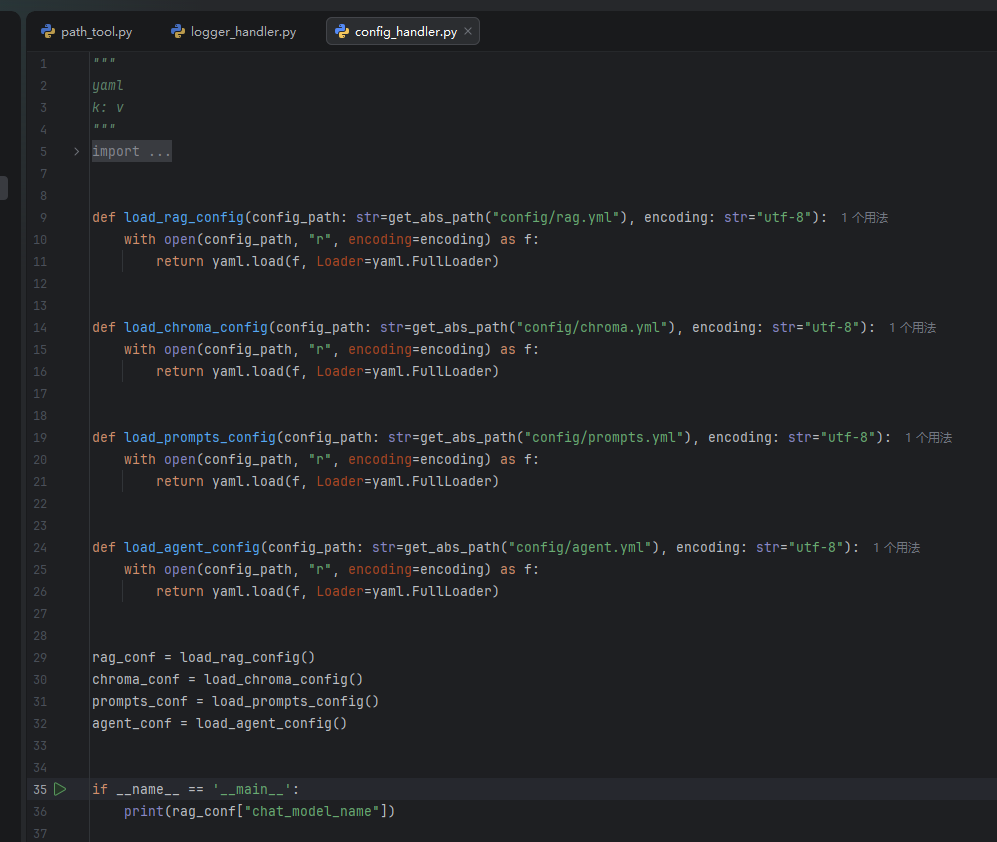
配置工具文件工具以及提示词加载文件的开发
这里的配置文件其实才是python的正经使用的配置文件,使用yaml库来进行配置
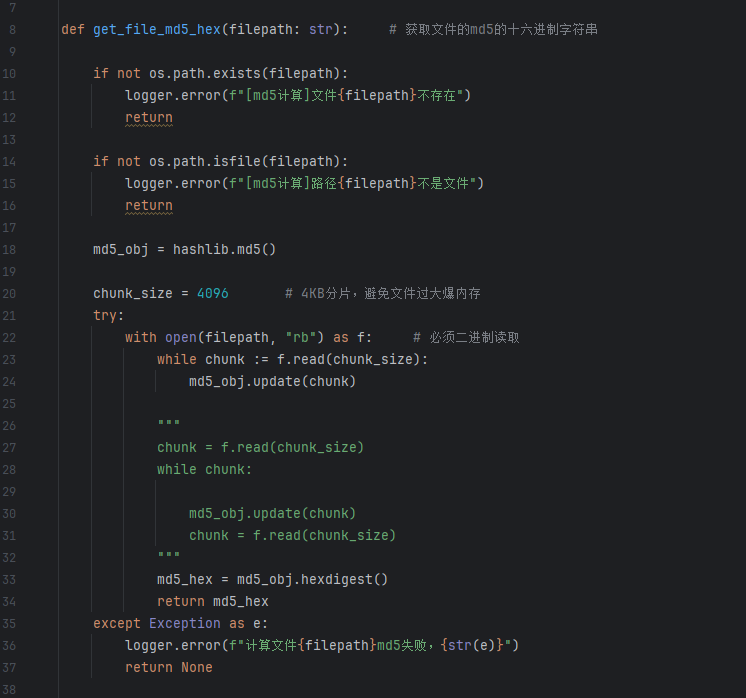
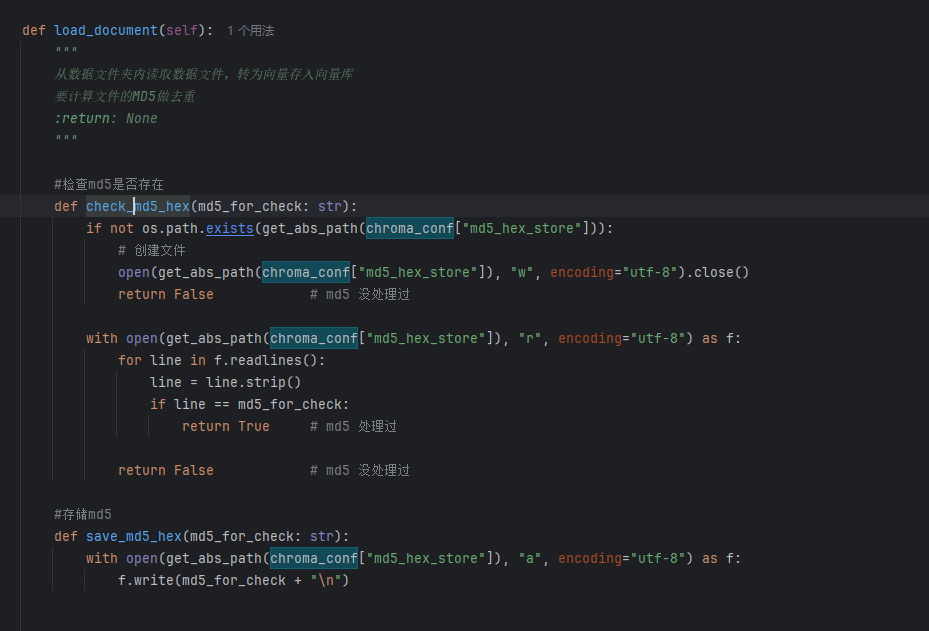
下面是计算md5码的代码,这个很显然相比于之前的版本严谨许多
注意:文件的md5计算必须是二进制读取。其中的:=就等价于后面的绿字的格式。
md5_obj.update(chunk) 不是把每一段的 MD5 字符串 拼接起来,而是把这段原始二进制数据继续喂给同一个 MD5 计算器,让它接着算下去。md5_obj 内部维护的是一个固定长度的中间状态,不是一个越来越长的字符串,所以无论文件多大,最终 md5_obj.hexdigest() 的结果长度都始终是固定的 32 个十六进制字符。你可以把它理解成:MD5 像一个"滚动计算器",第一次 update 处理前 4KB,第二次 update 在前一次结果基础上继续处理下一段,而不是把"前 4KB 的 md5 + 后 4KB 的 md5"拼起来;
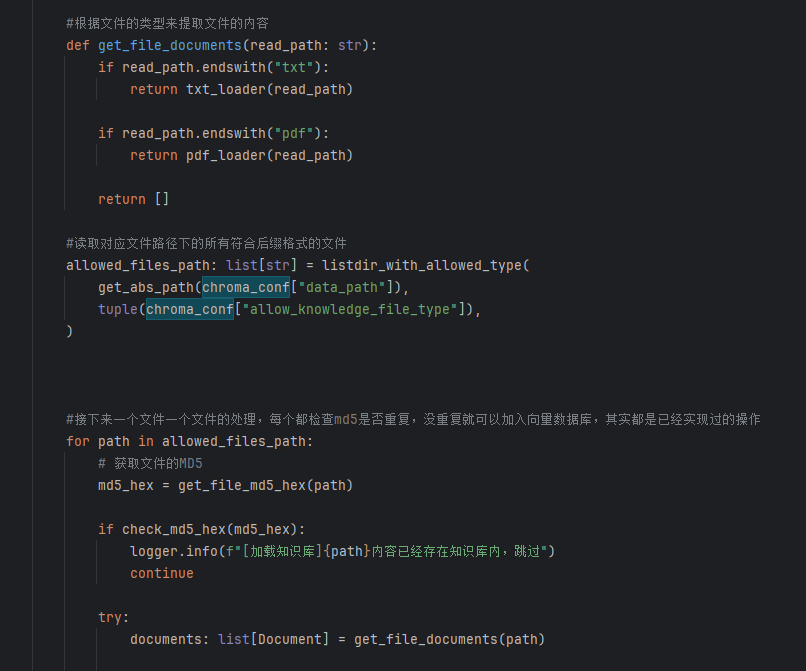
下面这个函数是返回目录中符合文件后缀的所有文件名
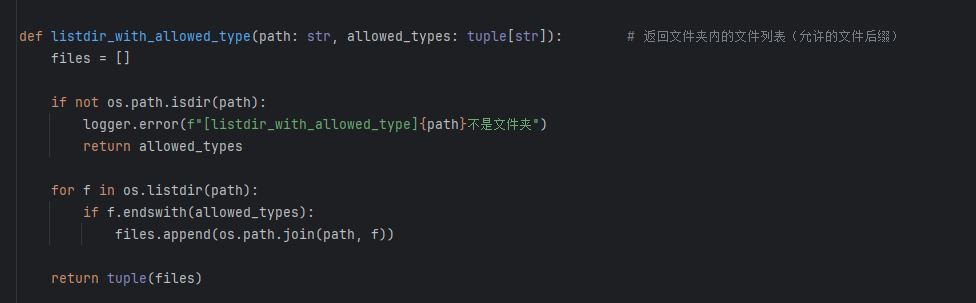
两个读文档函数
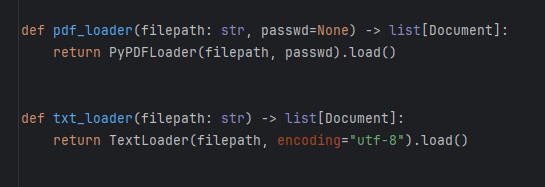
下面是各种加载提示词的函数,有一些是主提示词(系统提示词),还有rag总结提示词以及report提示词(报告提示词)。应该是集成了一些规范的提示词模板,然后把用户提问可以根据相似度转换成规范的提示词模板,这样可以提升询问大模型的效果。
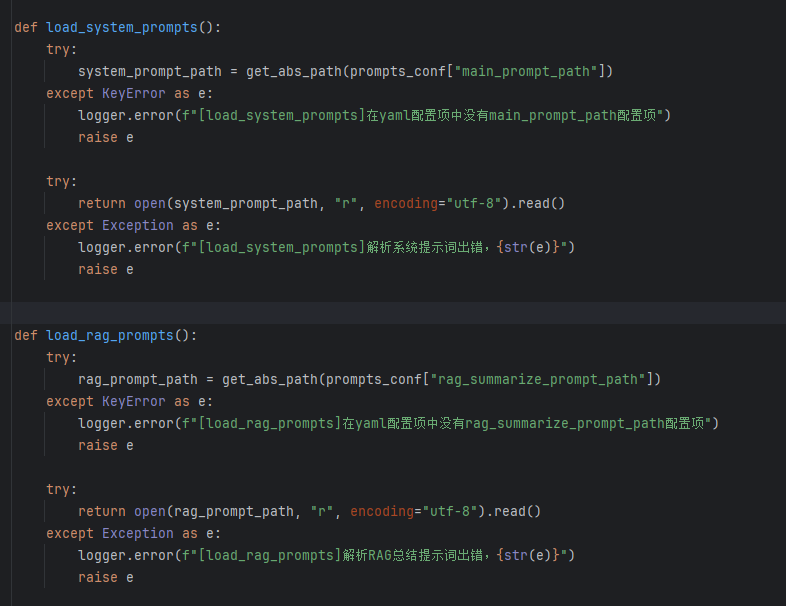
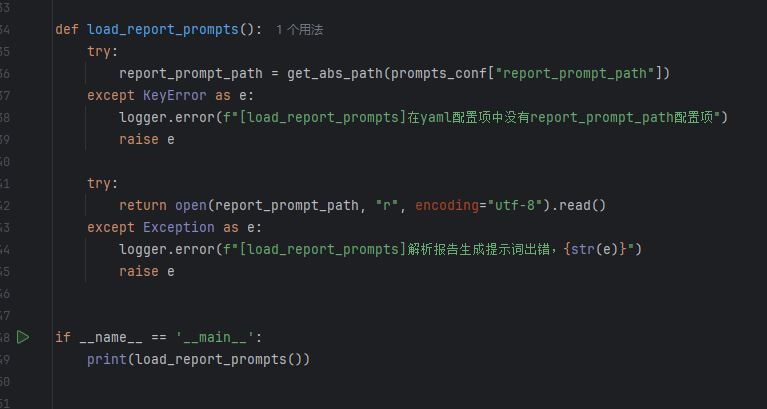
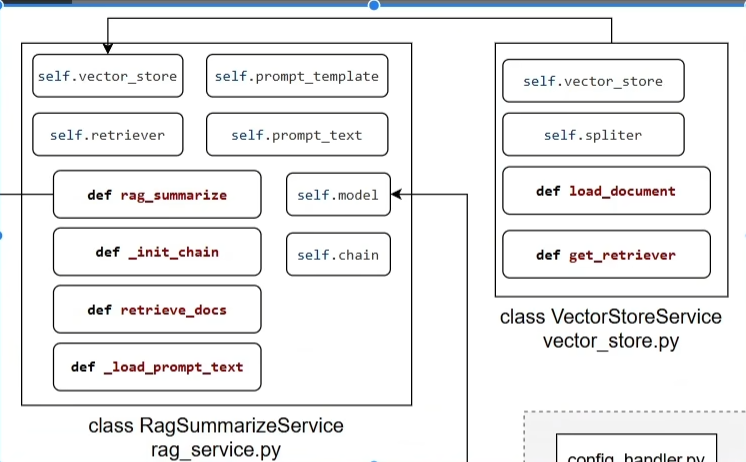
向量存储服务开发
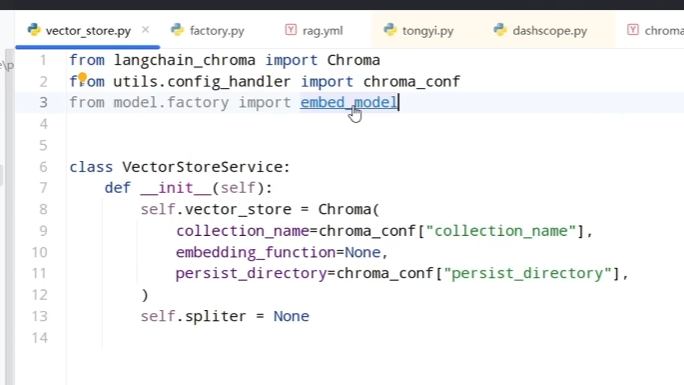
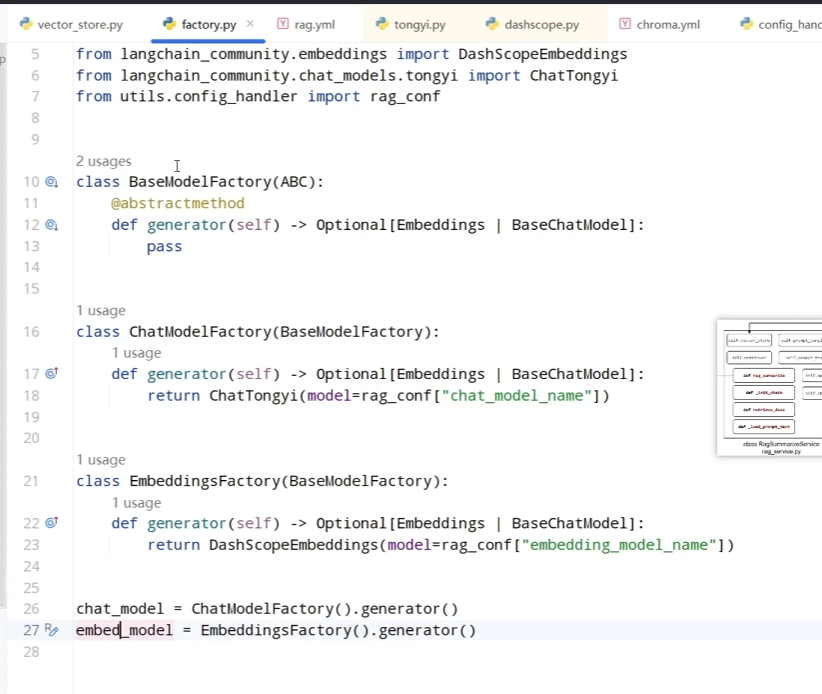
上面这一段简单进行了Chroma数据库的构建,但是我们发现还需要传入一个对应的嵌入模型,但是我们发现一个问题就是我们需要构建很多的模型,比如嵌入模型或者一些聊天模型等等。因此可以构建一个简单工厂类来直接生成对应的这些模型。具体实现如下。在函数输出的时候我们发现了一个比较怪的点就是OptionalEmbeddings \| BaseChatModel,这个其实是输出格式的一种规定。此时规定了我们的输出必须是Embedding或者BaseChatModel类及其子类。也就是规定了我们结果一定是嵌入模型或者聊天模型,而不会胡乱输出别的东西。
而在最后还直接生成了这两种模型,因此当其他类引用这个工厂文件的时候,后面两个模型将会直接被自动创建。因此可以直接调用。
初始化以及构建检索器
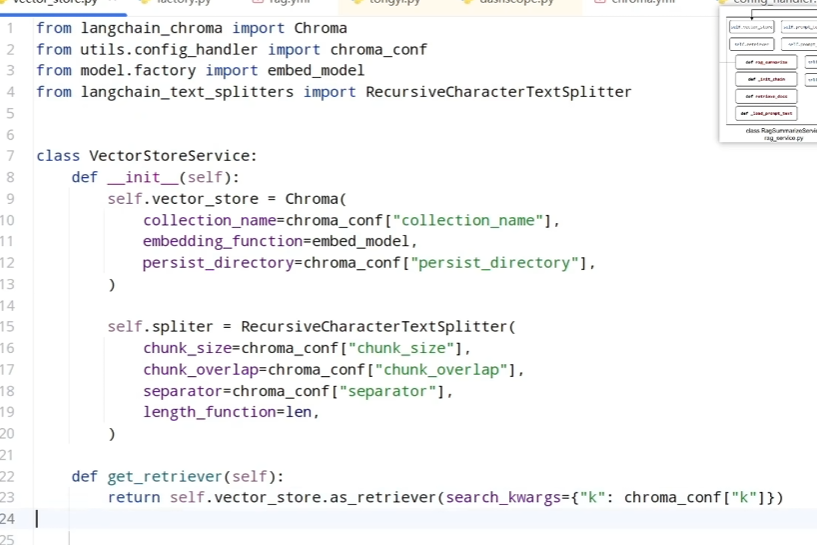
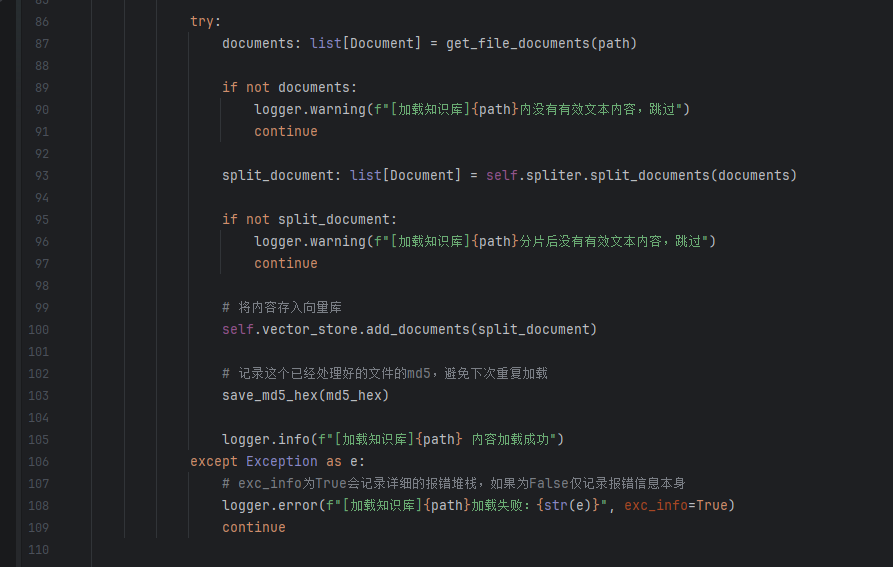
第二个函数其实我们也实现过,就是那个从文件中读取document类型内容,检查md5是否存在,不存在然后转换成对应的向量格式存入向量数据库。
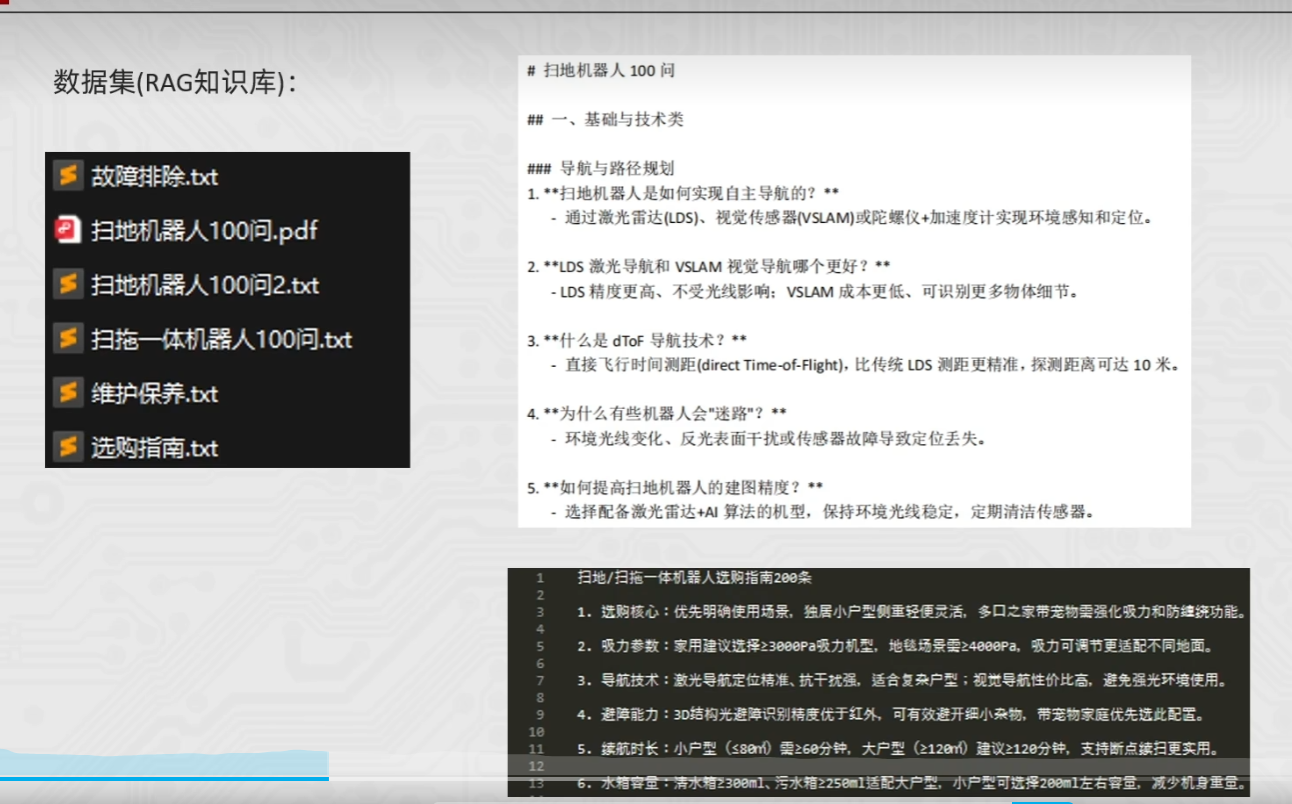
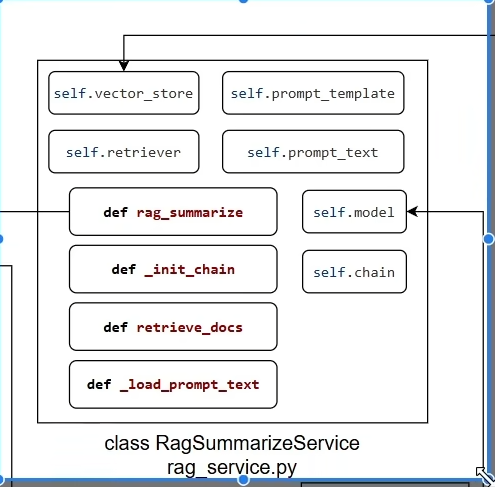
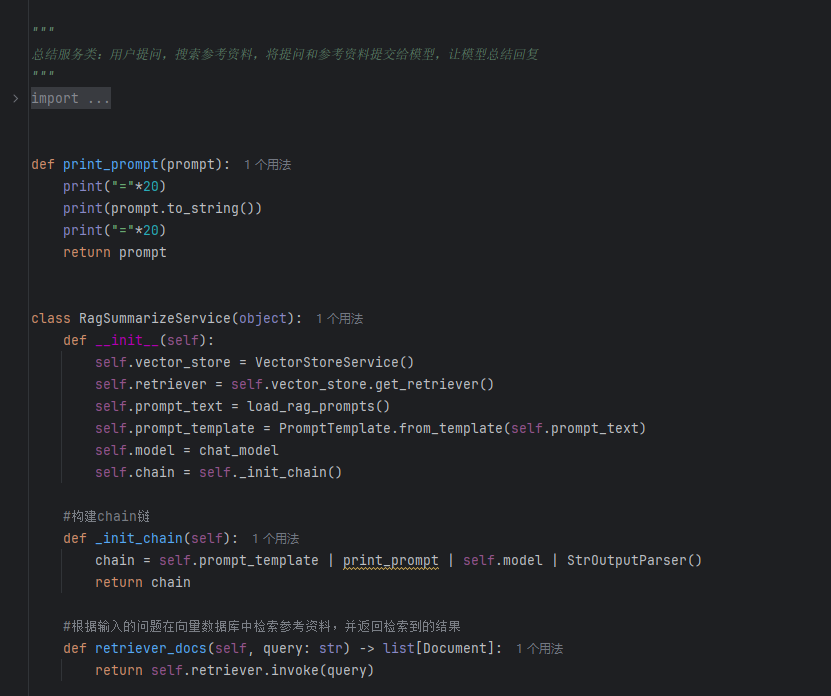
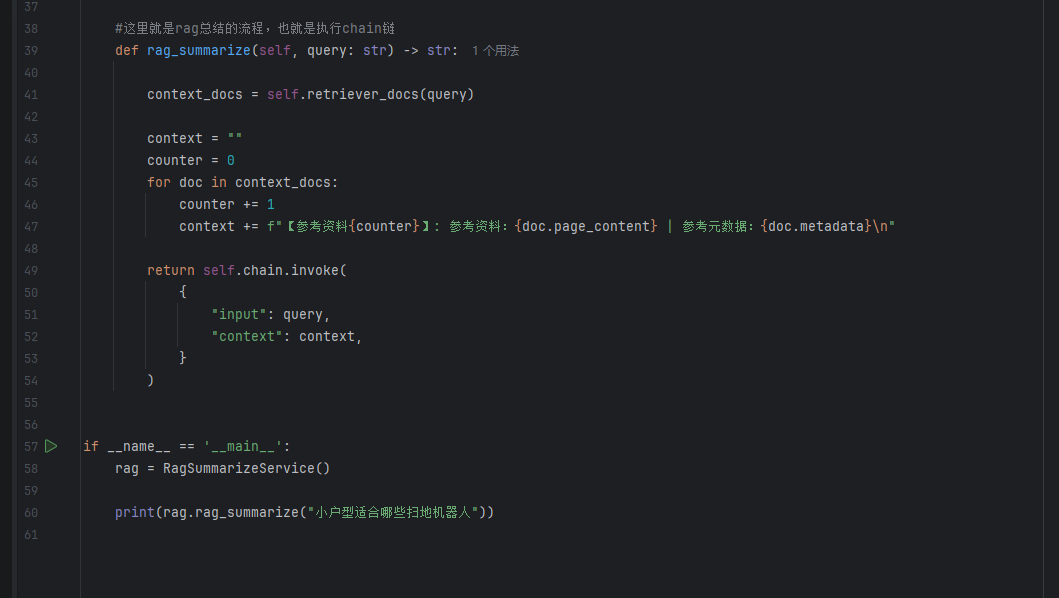
RAG总结服务开发
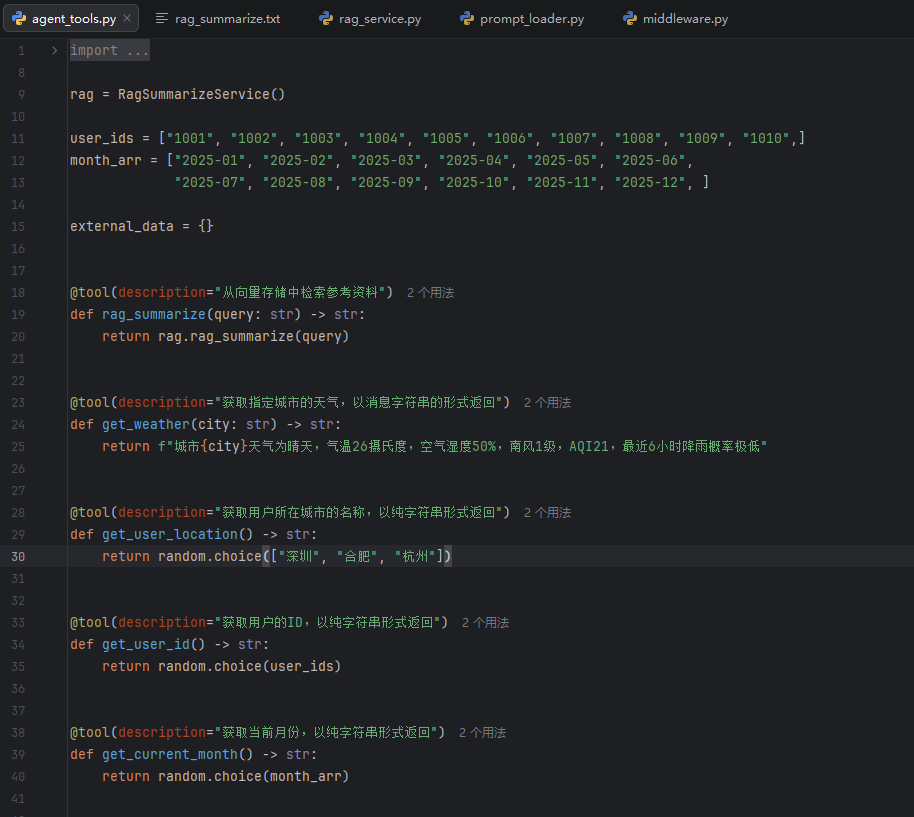
tool工具开发
这个写法里的 @tool(description="从向量存储中检索参考资料"),本质上是一个装饰器:它会把你下面定义的普通 Python 函数,包装成一个可被 Agent / 大模型调用的"工具"对象,而不再只是一个单纯的函数。LangChain 官方文档明确说明,tool 的作用就是把 Python 函数或 Runnable 转换成 LangChain tool,并且可以用装饰器形式直接写在函数上面。
下面这个函数中其实是将原本的这个rag总结函数注册成为一个agent的tool工具,可以让agent直接调用。
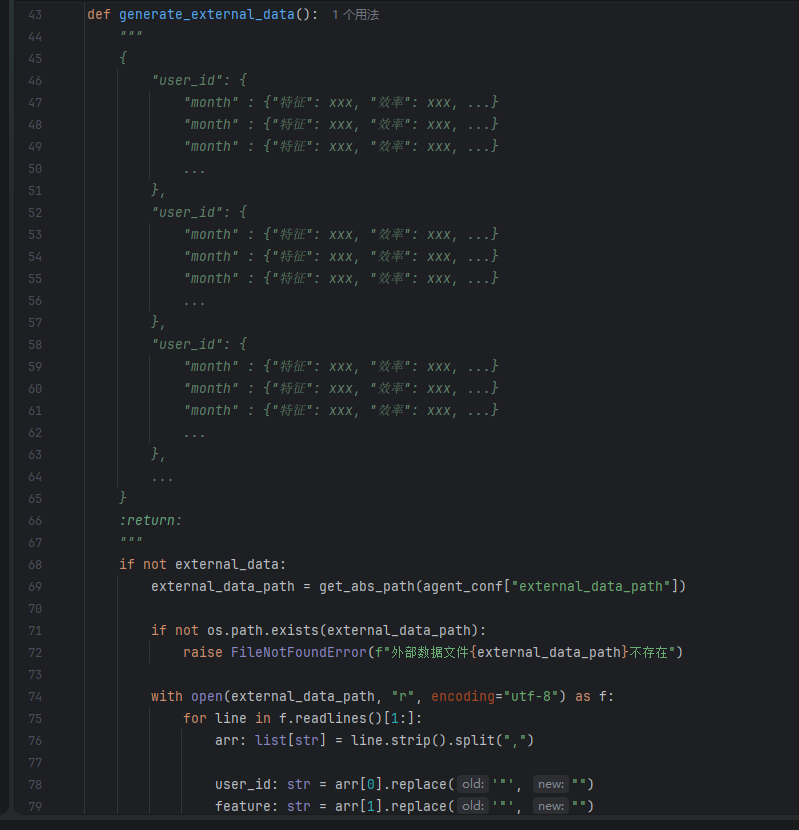
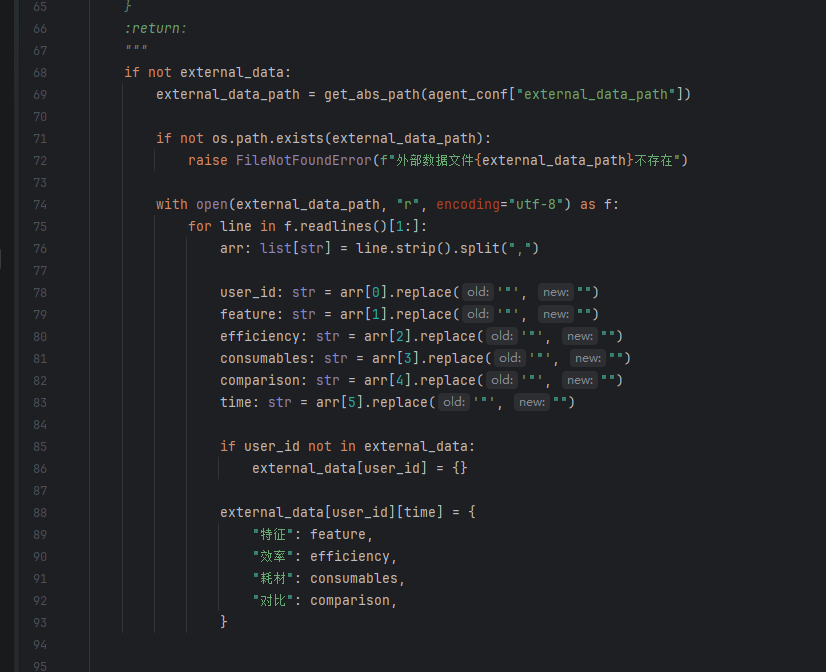

中间件和Agent创建
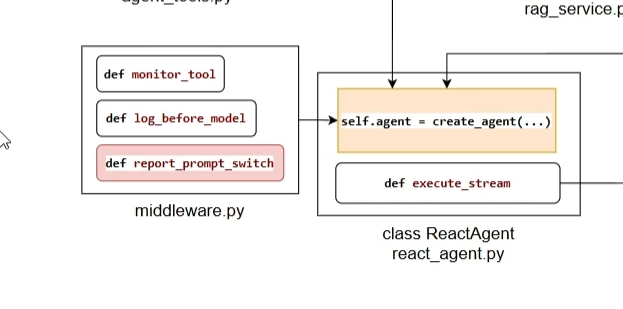
下面第一个函数是一个调用tool的时候执行的函数。在这个流程中其实就是监控是否执行了tool以及传输了什么参数。有点类似于java的拦截器
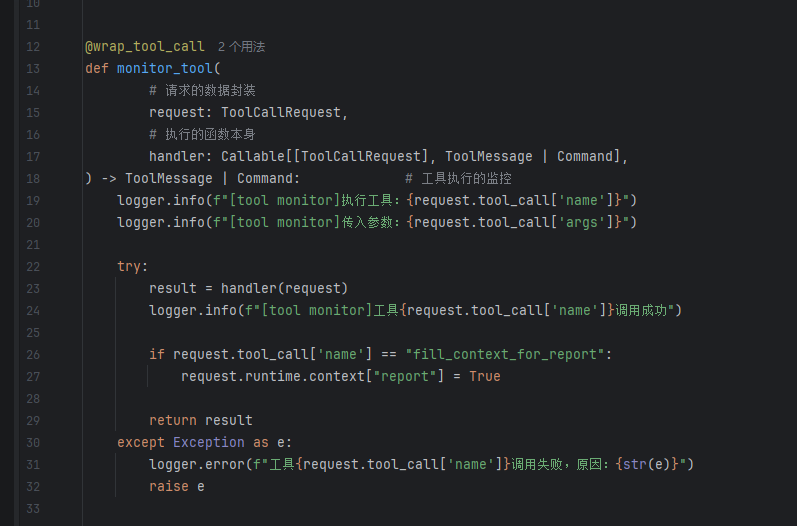
下面是在执行模型之前输出记录

动态提示词切换:在主提示词中,有一个用户需求生成报告,这个其实是一个强约束的报告。下面python其实就是实现的这一个提示词切换的流程,也就是说当我们的用户需要生成报告的时候,会进行提示词切换,然后切换成生成报告的提示词。

有一个完整的调用流程

流程实现其实也是比较的简单,其实就是在上下文runtime中插入一个参数用来标志是否切换提示词。
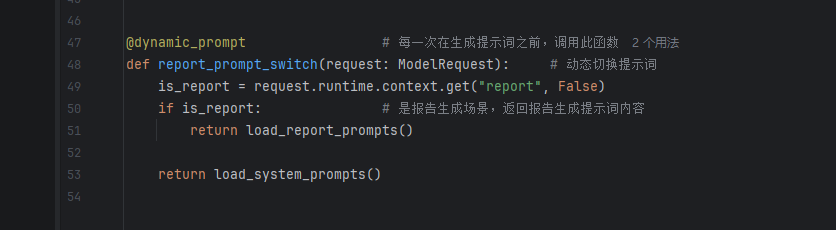
同时修改前面的函数:

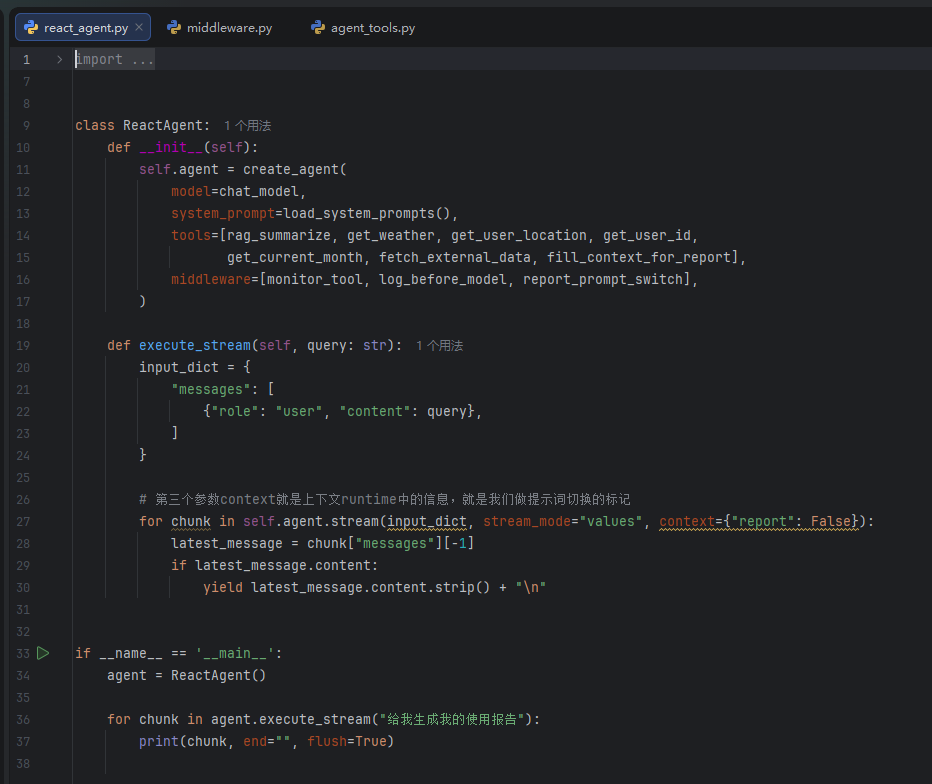
最后实现agent的ReAct
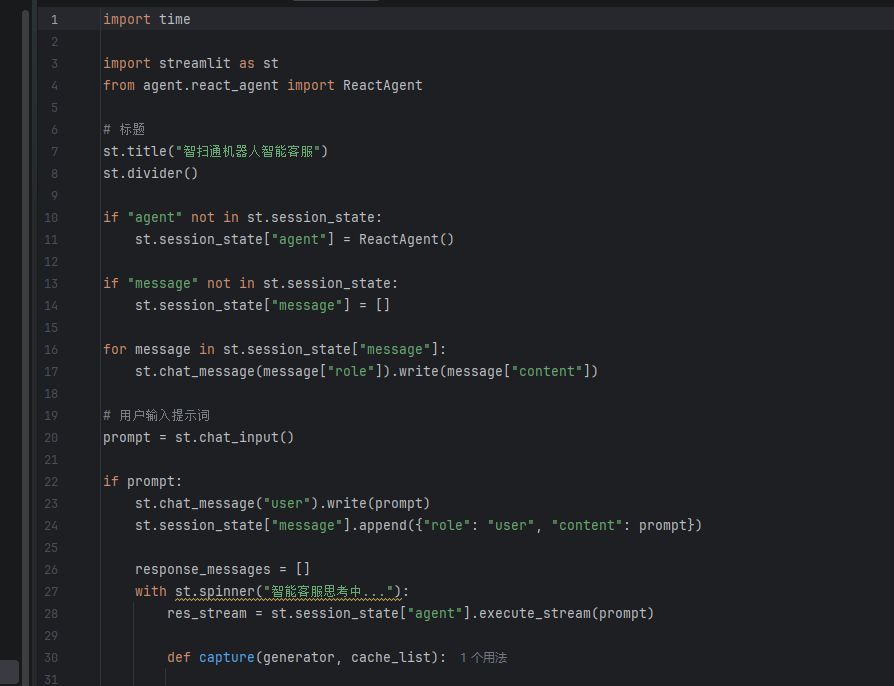
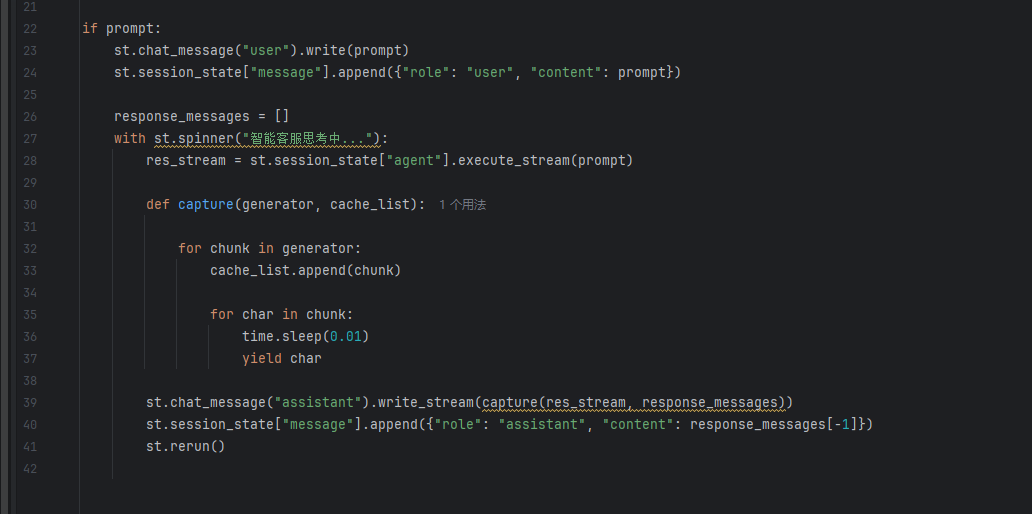
用户界面开发
这里其实也进行了增强,就是最后流式输出,实现了一个一个字一个字的蹦的效果