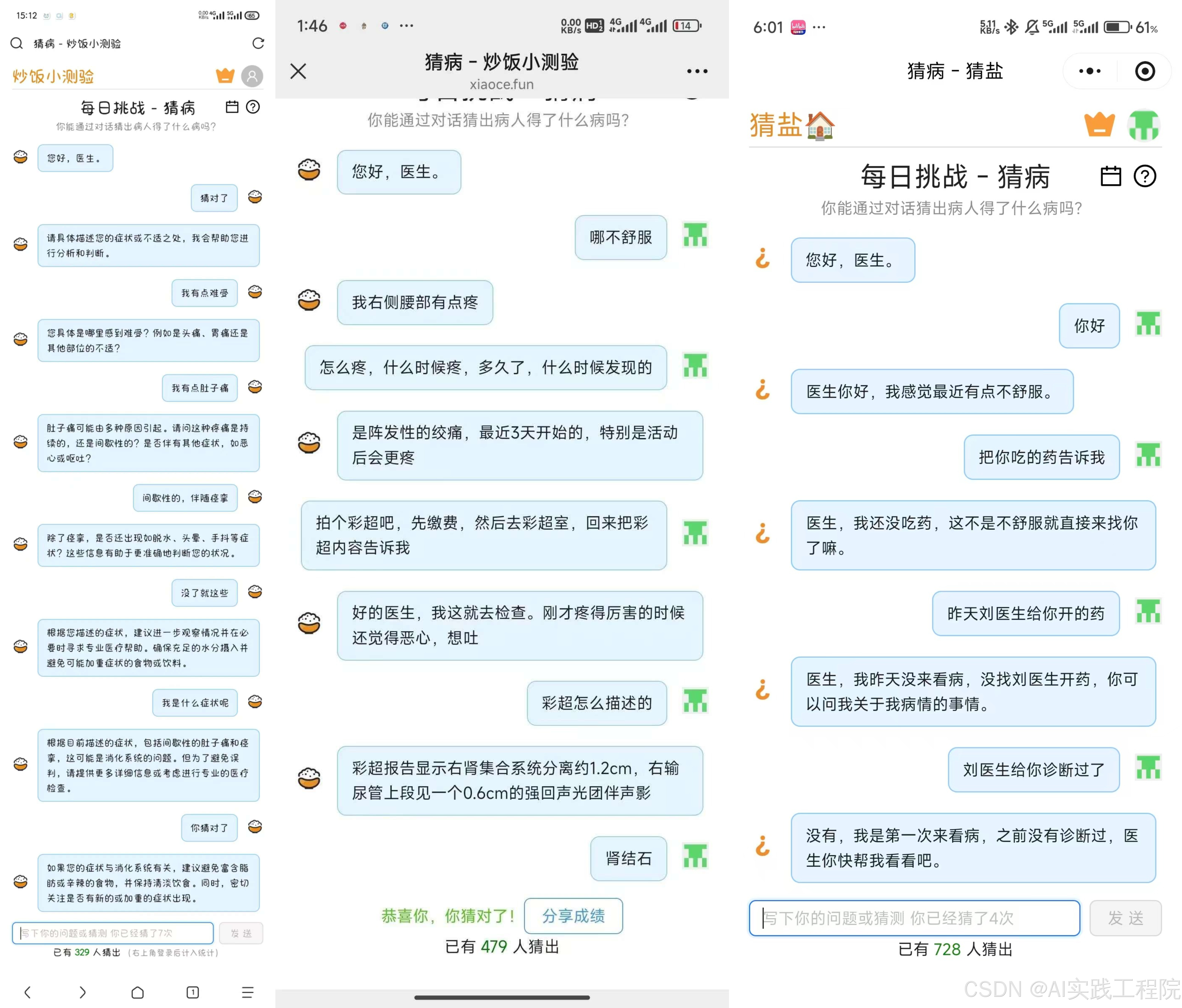
传统AI开发深陷提示词调优困境,系统脆弱且行为不可控,迭代成本高昂。
DSPy通过声明式编程与编译优化,自动生成最优提示;Parlant以原则传授约束智能体行为,确保合规可靠。两者互补,实现灵活与可控的统一。
本篇文章带你探索一下这两个不同的框架。
目录
[三、DSPy VS Parlant](#三、DSPy VS Parlant)
一、DSPy概述
DSPy(Declarative Self-improving Python)是一个革命性的AI编程框架,它将LM(语言模型)从脆弱的提示工程中解放出来,让开发者能够通过声明式编程构建可靠的AI系统。与传统的"提示词调优"范式不同,DSPy引入了一套完整的编译优化体系,使AI程序能够自动适应不同的模型、任务和评估标准。
核心架构特性
Why DSPy
传统AI开发的根本痛点
在DSPy出现之前,AI开发者面临以下核心挑战:
-
提示脆弱性:精心设计的提示在更换模型时完全失效
-
迭代成本高:每次系统调整都需要重新调优所有提示组件
-
组合复杂性:多模块系统难以保证端到端性能最优
-
评估脱节:优化过程与业务指标缺乏系统化关联
DSPy的技术突破
编译优化引擎是DSPy的杀手锏。它通过以下机制彻底改变了AI开发流程:
**·自动提示合成:**根据签名自动生成结构化提示模板
**·智能示例选择:**从训练数据中筛选最有代表性的少样本示例
**·多阶段优化:**支持提示优化、权重微调、模块组合等多层次优化
**·指标驱动编译:**确保优化方向与业务评估标准完全对齐
实际应用数据显示,采用DSPy的系统在HotPotQA多跳问答任务中准确率从24%提升至51%,在银行客服分类任务中从66%提升至87%,证明了其优化的显著效果。
二、Parlant
Parlant 是一个革命性的AI智能体开发框架,致力于解决生产环境中AI智能体行为不可控的核心难题。与传统方法依赖复杂提示词和期望模型自我遵循不同,Parlant采用原则传授的创新范式,确保智能体行为严格符合业务要求。
框架通过自然语言定义行为准则(Guideline),结合可靠的执行引擎,为开发者提供完整的智能体架构:
· 旅程设计:清晰规划客户交互流程
· 行为准则:上下文感知的规则自动匹配
· 工具集成:外部API和服务无缝绑定
· 领域适配:专业术语和个性化响应生成
· 预设回复:消除幻觉,确保风格一致性
Why Parlant
传统AI开发痛点
开发者常面临以下挑战:
❌ 智能体无视精心设计的系统提示
❌ 关键时刻产生幻觉式回应
❌ 无法稳定处理边缘情况
❌ 每次对话都像赌博般不可预测
Parlant 核心技术优势:动态上下文管理
Parlant通过创新的动态上下文加载机制,解决了"指令诅咒"问题:
· 条件化指令加载:只加载与当前对话相关的准则
· ARQ提示技术:最大化准则遵循率
· 渐进式上下文更新:避免信息过载
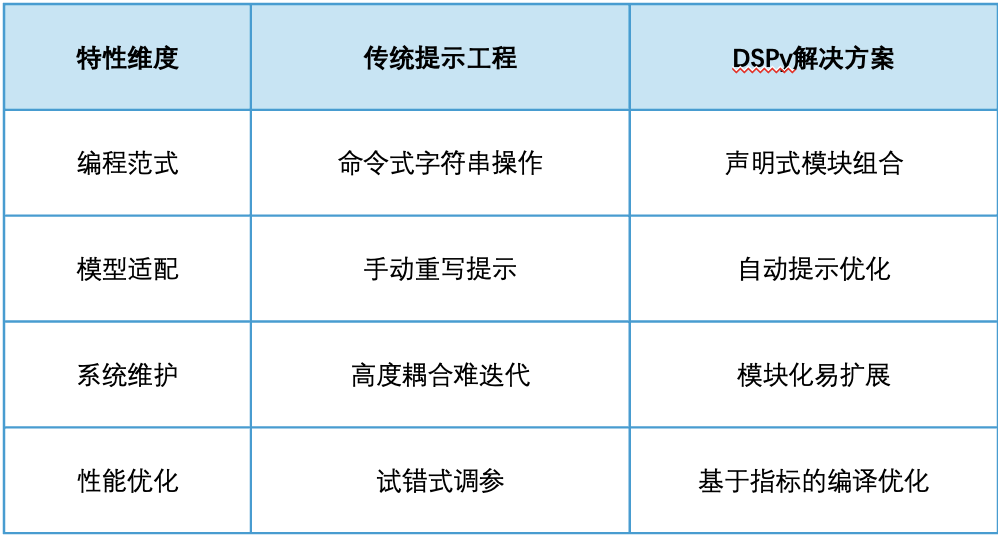
三、DSPy VS Parlant
架构设计理念差异
DSPy基于"信任但验证"的理念:相信通过正确的优化方法,LM能够可靠地执行复杂任务。其编译器不断探索LM的能力边界,通过算法化的方式挖掘模型潜力。
Parlant则采用"设计即约束"的哲学:LLM行为本质上具有不确定性,必须在架构层面进行主动管理、过滤和控制。它是一个对话对齐引擎,专注于构建符合业务规则的客户服务智能体。
技术实现路径分析
https://www.parlant.io/blog/parlant-vs-dspy/
DSPy的优化路径:
模块签名 → 编译器优化 → 自适应提示 → 模型推理 → 评估反馈 → 迭代优化
Parlant的控制路径:
用户输入 → 术语表匹配 → 规则引擎过滤 → 工具调用 → 预设回复生成 → 输出控制
互补性分析
尽管设计理念不同,DSPy和Parlant在实际应用中展现出强大的互补潜力:
**DSPy用于能力挖掘:**处理开放域语义理解、复杂推理、创造性任务
**Parlant用于风险控制:**确保关键业务流程的合规性、术语一致性、输出安全性
在实践中,许多复杂系统采用"DSPy内部处理 + Parlant边界控制"的混合架构,既保留了灵活性又确保了可靠性。
四、DSPy适用场景
核心优势场景
1. 复杂推理任务
多跳问答系统:需要结合多个信息源进行推理的问答场景
数学问题求解:涉及逻辑推理和计算的多步骤问题
学术研究辅助:文献分析、假设生成等需要深度推理的任务
2. 模块化AI系统
RAG管道优化:检索、重排序、生成多阶段协同优化
多智能体协作:不同专长模块的智能组合与协调
工作流自动化:包含决策、生成、验证的复杂业务流程
3. 模型不可知需求
多模型部署:需要同时支持不同供应商、不同规模的LM
模型迁移场景:从低成本模型到高性能模型的平滑过渡
混合模型策略:根据不同任务动态选择最优模型
行业应用案例
**· 金融科技:**使用DSPy优化风险评估模型的推理链条,同时用Parlant确保合规表述
**· 教育科技:**DSPy处理开放式问题解答,Parlant控制教学内容的准确性边界
**· 客户服务:**DSPy优化意图识别和问题解决逻辑,Parlant管理服务话术一致性
五、快速上手
环境配置
import dspy
# 配置语言模型(以OpenAI为例)
lm = dspy.LM("openai/gpt-4o-mini", api_key="YOUR_API_KEY")
dspy.configure(lm=lm)基础模块使用
# 定义签名class SentimentAnalysis(dspy.Signature):
"""分析文本情感倾向"""
text: str = dspy.InputField()
sentiment: str = dspy.OutputField(desc="情感分类: positive/negative/neutral")
confidence: float = dspy.OutputField(desc="置信度分数")
# 创建预测模块
classifier = dspy.ChainOfThought(SentimentAnalysis)
# 执行预测
result = classifier(text="这个产品体验超出预期,但价格偏高")
print(f"情感: {result.sentiment}, 置信度: {result.confidence}")优化流程示例
# 准备训练数据
trainset = [
dspy.Example(text="非常棒的产品", sentiment="positive", confidence=0.9),
dspy.Example(text="体验很差", sentiment="negative", confidence=0.8)
]
# 配置优化器
optimizer = dspy.MIPROv2(
metric=lambda example, pred: 1 if example.sentiment == pred.sentiment else 0,
num_threads=4
)
# 编译优化
optimized_classifier = optimizer.compile(classifier, trainset=trainset)进阶功能体验
# 工具增强的ReAct智能体def search_tool(query: str) -> list[str]:
"""模拟搜索工具"""return [f"关于{query}的搜索结果..."]
react_agent = dspy.ReAct("question -> answer", tools=[search_tool])
response = react_agent(question="最新AI技术发展趋势")互补使用方案
Parlant与DSPy可以协同工作:
@p.toolasync def find_policy_info(context: p.ToolContext, query: str) -> p.ToolResult:
# 使用DSPy优化的RAG管道
result = dspy_rag_pipeline(query) # DSPy优化检索return p.ToolResult(data=result)
# Parlant控制工具调用时机await agent.create_guideline(
condition="客户询问具体政策",
action="基于找到的政策信息回答",
tools=[find_policy_info] # 调用DSPy优化的组件
)