关键词:自回归扩散、因果注意力、ODE蒸馏、分布匹配蒸馏、流映射学习
一、问题背景:双向到自回归的架构鸿沟与实时视频生成的需求
1.1 实时交互视频生成的核心挑战
当前视频扩散模型面临的根本性矛盾在于生成质量与实时性之间的权衡:
| 模型类型 | 注意力机制 | 生成特性 | 主要优势 | 核心局限 |
|---|---|---|---|---|
| 双向模型(Bidirectional) | 全连接时空注意力 | 固定时长、批量生成 | 全局一致性高、画质最优 | 非流式、延迟高、无法交互 |
| 自回归模型(Autoregressive, AR) | 因果(块)注意力 | 流式生成、任意时长 | 实时响应、支持交互、无限时长 | 直接训练质量显著落后 |
应用场景需求:
- 实时交互:用户输入需即时反馈(如游戏、虚拟角色对话)
- 无限时长:直播、长视频生成不能预设定长
- 低延迟:端到端延迟 < 100ms 方可感知实时
这些需求迫使研究者探索将高质量双向模型蒸馏为高效AR模型的技术路线 。

1.2 架构鸿沟的形式化描述
双向教师的全连接注意力:
设视频帧序列为 x=x1,x2,...,xL\mathbf{x} = \\mathbf{x}\^1, \\mathbf{x}\^2, \\ldots, \\mathbf{x}\^Lx=x1,x2,...,xL,双向模型的注意力权重为:
Abiij=exp(qi⊤kjdk)∑l=1Lexp(qi⊤kldk),∀i,j∈{1,...,L} \mathbf{A}_{\text{bi}}^{ij} = \frac{\exp\left(\frac{\mathbf{q}_i^\top \mathbf{k}j}{\sqrt{d_k}}\right)}{\sum{l=1}^L \exp\left(\frac{\mathbf{q}_i^\top \mathbf{k}_l}{\sqrt{d_k}}\right)}, \quad \forall i,j \in \{1,\ldots,L\} Abiij=∑l=1Lexp(dk qi⊤kl)exp(dk qi⊤kj),∀i,j∈{1,...,L}
即任意帧可 attending 到过去与未来所有帧。
AR学生的因果注意力:
Acausalij={exp(qi⊤kjdk)∑l=1iexp(qi⊤kldk)j≤i0j>i \mathbf{A}_{\text{causal}}^{ij} = \begin{cases} \frac{\exp\left(\frac{\mathbf{q}_i^\top \mathbf{k}j}{\sqrt{d_k}}\right)}{\sum{l=1}^i \exp\left(\frac{\mathbf{q}_i^\top \mathbf{k}_l}{\sqrt{d_k}}\right)} & j \leq i \\ 0 & j > i \end{cases} Acausalij=⎩ ⎨ ⎧∑l=1iexp(dk qi⊤kl)exp(dk qi⊤kj)0j≤ij>i
第 iii 帧仅 attending 到历史帧 {x1,...,xi}\{\mathbf{x}^1, \ldots, \mathbf{x}^i\}{x1,...,xi},未来信息被因果掩码阻断 。
架构鸿沟的本质 :双向教师依赖未来信息做全局决策,AR学生必须在无未来信息条件下做局部决策,二者概率流的动力学结构存在根本性差异。

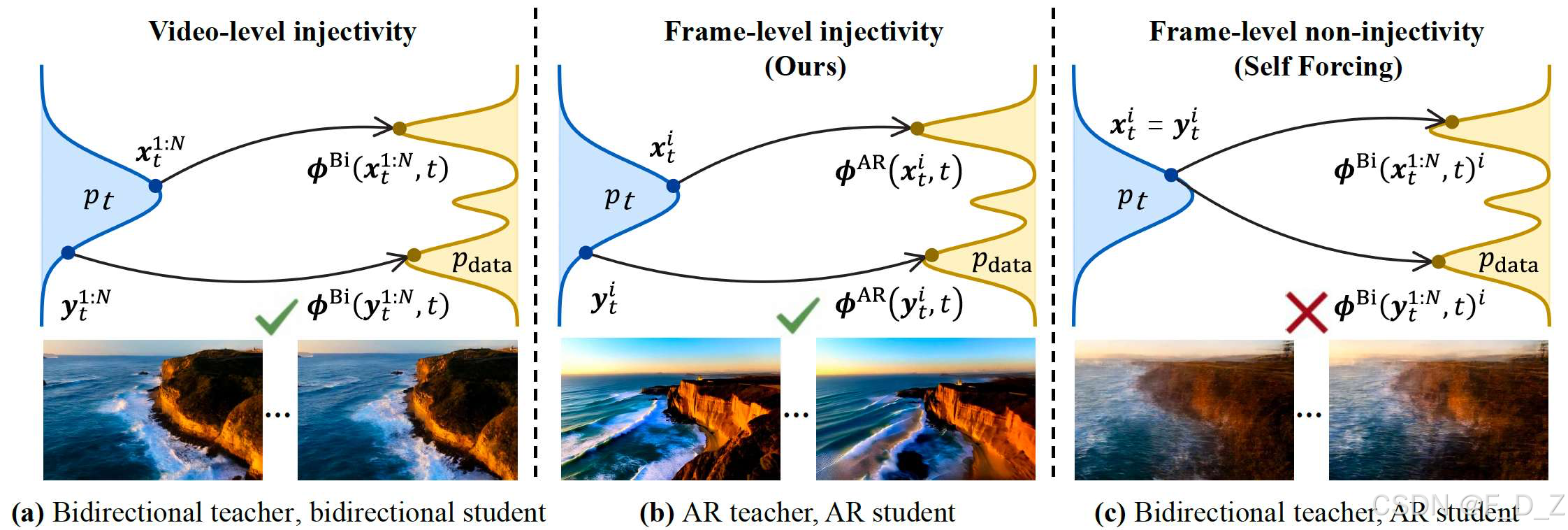
二、现有方法的理论缺陷:帧级单射性违反与流映射崩溃
2.1 ODE蒸馏的数学基础与单射性要求
扩散模型的概率流ODE(Probability Flow ODE)定义为 :
dxt=−12β(t)xt−β(t)∇xtlogpt(xt)dt d\mathbf{x}_t = \left-\\frac{1}{2}\\beta(t)\\mathbf{x}_t - \\beta(t)\\nabla_{\\mathbf{x}_t}\\log p_t(\\mathbf{x}_t)\\rightdt dxt=−21β(t)xt−β(t)∇xtlogpt(xt)dt
在标准ODE蒸馏(如DMD, Distribution Matching Distillation)中,核心假设是从噪声到数据的映射具有单射性(Injectivity) :
单射性条件 :对于任意噪声状态 xt\mathbf{x}_txt,存在唯一的干净状态 x0\mathbf{x}_0x0 使得 xt\mathbf{x}_txt 位于从 x0\mathbf{x}_0x0 出发的ODE轨迹上。
形式化表述:
∀xt∈supp(pt),∃!x0∈supp(p0):xt=ODEforward(x0,t) \forall \mathbf{x}_t \in \text{supp}(p_t), \quad \exists! \mathbf{x}_0 \in \text{supp}(p_0): \mathbf{x}t = \text{ODE}{\text{forward}}(\mathbf{x}_0, t) ∀xt∈supp(pt),∃!x0∈supp(p0):xt=ODEforward(x0,t)
2.2 双向蒸馏到双向:视频级单射性满足
当双向教师蒸馏到双向学生时,单射性在视频级别自然成立:
xtvideo=xt1,...,xtL→PF-ODEx01,...,x0L=x0video \mathbf{x}_t^{\text{video}} = \\mathbf{x}_t\^1, \\ldots, \\mathbf{x}_t\^L \xrightarrow{\text{PF-ODE}} \\mathbf{x}_0\^1, \\ldots, \\mathbf{x}_0\^L = \mathbf{x}_0^{\text{video}} xtvideo=xt1,...,xtLPF-ODE x01,...,x0L=x0video
整个视频作为联合状态,ODE映射唯一确定。
2.3 双向蒸馏到AR:帧级单射性违反
核心问题 :现有方法(如Self-Forcing)直接用双向教师初始化AR学生,导致帧级单射性违反 。
形式化分析:
考虑双向教师生成第 iii 帧时的条件分布。由于双向注意力,第 iii 帧的生成依赖于未来帧的不同取值:
pbi(x0i∣xti,x0<i,x0>i)≠pbi(x0i∣xti,x0<i,x0>i′) p_{\text{bi}}(\mathbf{x}_0^i | \mathbf{x}_t^i, \mathbf{x}_0^{<i}, \mathbf{x}0^{>i}) \neq p{\text{bi}}(\mathbf{x}_0^i | \mathbf{x}_t^i, \mathbf{x}_0^{<i}, \mathbf{x}_0^{>i'}) pbi(x0i∣xti,x0<i,x0>i)=pbi(x0i∣xti,x0<i,x0>i′)
对于相同的噪声状态 xti\mathbf{x}_t^ixti 和相同的历史条件 x0<i\mathbf{x}_0^{<i}x0<i,但不同的未来条件 x0>i≠x0>i′\mathbf{x}_0^{>i} \neq \mathbf{x}_0^{>i'}x0>i=x0>i′,双向教师可能映射到不同的干净帧:
xti↦x0i,(1)或xti↦x0i,(2) \mathbf{x}_t^i \mapsto \mathbf{x}_0^{i,(1)} \quad \text{或} \quad \mathbf{x}_t^i \mapsto \mathbf{x}_0^{i,(2)} xti↦x0i,(1)或xti↦x0i,(2)
同一噪声帧对应多个可能干净帧,严格违反帧级单射性。
2.4 流映射学习的崩溃:条件期望解
由于单射性违反,AR学生无法准确学习双向教师的流映射。在优化过程中,学生网络被迫收敛到条件期望解:
x^0i=Ep(x0>i∣xti,x0<i)x0i∣xti,x0\
物理后果:
- 时间不一致性:相邻帧的期望解可能不连贯
- 运动模糊:期望操作抹平动态细节
- 质量退化:视觉模糊、语义漂移、人类偏好分数下降
实验观测:Self-Forcing等方法在VisionReward等指标上显著落后于理论预期,根源在于此结构性理论缺陷 。
三、Causal Forcing:理论矫正的三阶段方法论
3.1 核心洞察与方法论框架
核心命题 :桥接双向教师到AR学生的架构鸿沟,需在ODE初始化阶段 引入AR教师,而非直接使用双向教师 。
AR教师的理论优势:
AR模型生成第 iii 帧时,未来帧尚未生成,历史帧 x0<i\mathbf{x}_0^{<i}x0<i 已固定。给定噪声状态 xti\mathbf{x}_t^ixti 和历史条件 x0<i\mathbf{x}_0^{<i}x0<i,PF-ODE的解唯一确定:
∃!x0i:xti=ODEforward(x0i;x0<i,t) \exists! \mathbf{x}_0^i: \mathbf{x}t^i = \text{ODE}{\text{forward}}(\mathbf{x}_0^i; \mathbf{x}_0^{<i}, t) ∃!x0i:xti=ODEforward(x0i;x0<i,t)
帧级单射性严格满足,为准确的流映射学习奠定基础。
3.2 三阶段训练流程详解
| 阶段 | 阶段名称 | 核心目标 | 关键技术 | 数据分布 | 网络架构 |
|---|---|---|---|---|---|
| Stage 1 | AR扩散训练 | 获得高质量AR教师 | 教师强制(Teacher Forcing) | 双向教师生成数据 DBi\mathcal{D}_{\text{Bi}}DBi | 双向→AR初始化 |
| Stage 2 | 因果ODE蒸馏 | 获得可蒸馏的AR教师 | 因果PF-ODE采样 | AR教师生成数据 DCausal\mathcal{D}_{\text{Causal}}DCausal | AR教师→AR学生初始化 |
| Stage 3 | 非对称DMD | 训练少步AR学生 | 分布匹配蒸馏 | 真实数据 + AR学生生成数据 | AR学生优化 |
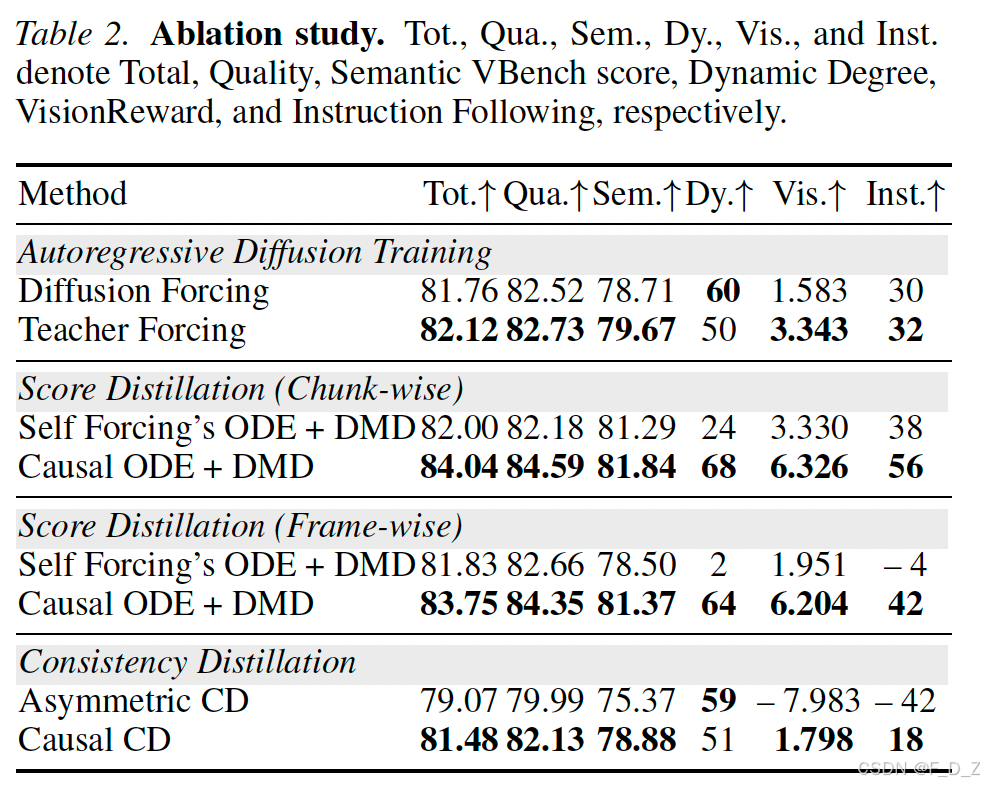
3.2.1 Stage 1:教师强制 vs 扩散强制的理论对比
扩散强制(Diffusion Forcing, DF)的问题 :
DF在训练第 iii 帧时,条件于加噪历史帧 xt<i\mathbf{x}_t^{<i}xt<i:
pθDF(xti∣xt<i,t)(训练分布) p_\theta^{\text{DF}}(\mathbf{x}_t^i | \mathbf{x}_t^{<i}, t) \quad \text{(训练分布)} pθDF(xti∣xt<i,t)(训练分布)
但推理时条件于干净历史帧 x0<i\mathbf{x}_0^{<i}x0<i:
pθDF(xti∣x0<i,t)(推理分布) p_\theta^{\text{DF}}(\mathbf{x}_t^i | \mathbf{x}_0^{<i}, t) \quad \text{(推理分布)} pθDF(xti∣x0<i,t)(推理分布)
训练-推理分布失配(形式化表述为 中的理论命题):
DTV(pθDF(⋅∣xt<i,t),pθDF(⋅∣x0<i,t))>0 D_{\text{TV}}\left(p_\theta^{\text{DF}}(\cdot | \mathbf{x}t^{<i}, t), p\theta^{\text{DF}}(\cdot | \mathbf{x}_0^{<i}, t)\right) > 0 DTV(pθDF(⋅∣xt<i,t),pθDF(⋅∣x0<i,t))>0
总变差距离非零,导致泛化误差。
教师强制(Teacher Forcing, TF)的优势 :
始终条件于干净真实历史帧 xgt<i\mathbf{x}_{\text{gt}}^{<i}xgt<i:
pθTF(xti∣xgt<i,t)(训练与推理一致) p_\theta^{\text{TF}}(\mathbf{x}t^i | \mathbf{x}{\text{gt}}^{<i}, t) \quad \text{(训练与推理一致)} pθTF(xti∣xgt<i,t)(训练与推理一致)
训练分布与推理分布完全对齐:
DTV(pθTF, train,pθTF, inference)=0 D_{\text{TV}}\left(p_\theta^{\text{TF, train}}, p_\theta^{\text{TF, inference}}\right) = 0 DTV(pθTF, train,pθTF, inference)=0
实验验证 :在固定数据条件下,TF相比DF在VisionReward上提升111.2% 。尽管DF报告的动态度数(Dynamic Degree)更高,但分析表明这源于病理性的模式崩溃------高动态但低质量的生成 。
3.2.2 Stage 2:因果ODE蒸馏的数学形式化
从AR教师采样PF-ODE轨迹。设时间步集合为 S∪{0}\mathcal{S} \cup \{0\}S∪{0},其中 S\mathcal{S}S 为蒸馏时间步,0为干净数据。
AR教师的PF-ODE:
对于第 iii 帧,历史帧 xgt<i\mathbf{x}_{\text{gt}}^{<i}xgt<i 固定,从 xTi∼N(0,I)\mathbf{x}_T^i \sim \mathcal{N}(\mathbf{0}, \mathbf{I})xTi∼N(0,I) 出发:
xti=ODEsolve(xTi,T→t;sϕAR(⋅,⋅,xgt<i)),t∈S∪{0} \mathbf{x}t^i = \text{ODE}{\text{solve}}\left(\mathbf{x}T^i, T \to t; s\phi^{\text{AR}}(\cdot, \cdot, \mathbf{x}_{\text{gt}}^{<i})\right), \quad t \in \mathcal{S} \cup \{0\} xti=ODEsolve(xTi,T→t;sϕAR(⋅,⋅,xgt<i)),t∈S∪{0}
其中 sϕARs_\phi^{\text{AR}}sϕAR 为AR教师的分数估计器,显式条件于历史帧。
学生网络训练目标:
设学生网络为 Gθ(xti,xgt<i,t)G_\theta(\mathbf{x}t^i, \mathbf{x}{\text{gt}}^{<i}, t)Gθ(xti,xgt<i,t),优化目标为最小化ODE轨迹重构误差 :
LCausal-ODE=Exgt<i∼Dreal,i,t∈S∥Gθ(xti,xgt\
理论保证 :由于AR教师的帧级单射性,(xti,xgt<i)↦xgti(\mathbf{x}t^i, \mathbf{x}{\text{gt}}^{<i}) \mapsto \mathbf{x}_{\text{gt}}^i(xti,xgt<i)↦xgti 为确定性映射,学生网络可准确学习而非被迫近似条件期望。
块级 vs 帧级初始化 :
- 块级(Chunk-level) :以 KKK 帧为块进行ODE蒸馏,平衡效率与粒度
- 帧级(Frame-level):逐帧精细蒸馏,最大化单射性利用
3.2.3 Stage 3:非对称分布匹配蒸馏(Asymmetric DMD)
沿用Self-Forcing的非对称DMD设置,但基于Stage 2的AR初始化 :
分数估计器配置:
- 真实分数估计器 sreals_{\text{real}}sreal:Wan2.1-14B(大规模双向教师)
- 学生分数估计器 sfakes_{\text{fake}}sfake:Wan2.1-1.3B(轻量级AR学生)
非对称蒸馏损失:
LDMD=Ex,t∥sfake(x,t)−sg(sreal(x,t))∥2+λregLreg \mathcal{L}{\text{DMD}} = \mathbb{E}{\mathbf{x}, t}\left\\left\\\|s_{\\text{fake}}(\\mathbf{x}, t) - \\text{sg}(s_{\\text{real}}(\\mathbf{x}, t))\\right\\\|\^2\\right + \lambda_{\text{reg}} \mathcal{L}_{\text{reg}} LDMD=Ex,t∥sfake(x,t)−sg(sreal(x,t))∥2+λregLreg
其中 sg(⋅)\text{sg}(\cdot)sg(⋅) 为停止梯度操作,Lreg\mathcal{L}_{\text{reg}}Lreg 为防止学生崩溃的正则项。
关键差异 :由于Stage 2的因果初始化,学生网络 sfakes_{\text{fake}}sfake 已具备合理的AR流映射,DMD阶段专注于分布匹配精细化 而非架构鸿沟桥接。
四、实验验证与性能分析
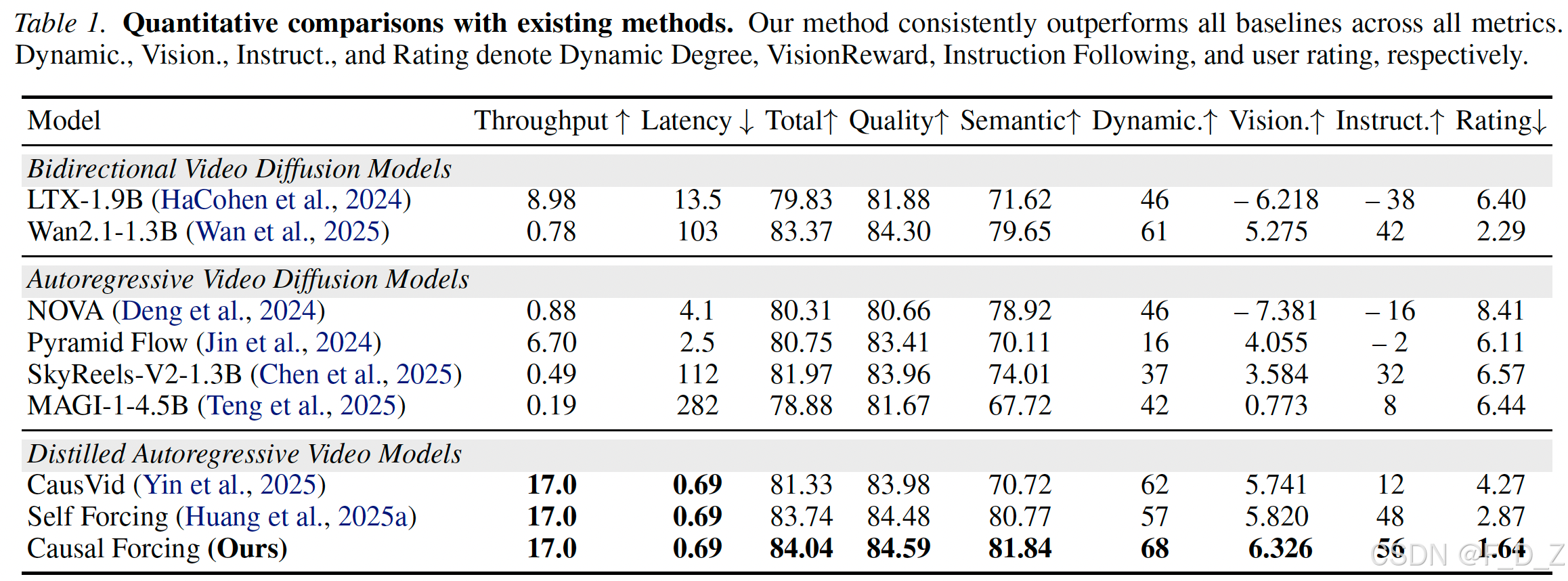
4.1 主实验结果:全面超越SOTA

4.2 消融实验:理论分析的实证验证
实验设置:严格控制数据质量------所有配置使用相同3K样本,相同VidProM提示分布,确保公平比较 。
4.3 核心消融:初始化 vs 数据构造
研究问题 :Causal ODE蒸馏的优势源于AR初始化 还是因果数据构造?
实验设计 :
- 使用因果数据 DCausal\mathcal{D}_{\text{Causal}}DCausal(AR教师生成)
- 但学生网络从双向模型而非AR模型初始化
结果:性能与AR初始化相当,均远超Self-Forcing基线
结论 :数据构造(AR教师生成)是性能提升的核心来源 ,初始化方式非瓶颈。这进一步验证理论分析------正确的数据分布(满足单射性)比网络初始化更关键。
五、理论贡献与方法论意义
5.1 形式化理论框架的建立
Causal Forcing建立了AR扩散蒸馏的首个正确数学基础:
| 理论要素 | 现有方法(Self-Forcing等) | Causal Forcing(本文) |
|---|---|---|
| 教师模型类型 | 双向扩散模型 | 自回归扩散模型 |
| ODE单射性 | 违反(帧级多对一) | 严格满足(帧级一对一) |
| 流映射学习 | 条件期望解(模糊崩溃) | 准确恢复(确定性映射) |
| 训练-推理一致性 | DF存在分布失配 | TF完全一致 |
| 架构鸿沟处理 | 忽视(直接初始化) | 显式桥接(三阶段) |
5.2 对视频生成领域的范式启示
1. 架构匹配原则 :
蒸馏过程中教师-学生架构的兼容性不可随意忽视。ODE单射性等数学条件需显式验证,而非仅依赖工程调优。
2. 单射性的核心地位 :
流映射学习的成功 fundamentally 依赖于状态空间映射的唯一性。多对一映射导致的信息损失无法通过增大网络容量补偿。
3. 训练-推理一致性的重新审视 :
教师强制在AR生成中的优越性被重新确立。扩散强制的动态度数优势被证明为病理性假象,实际伴随严重的模式崩溃。
4. 因果性的正确引入时机 :
因果性需在ODE初始化阶段处理,而非仅在最终的DMD阶段。早期引入确保流映射学习的正确基础,后期优化专注于分布精细匹配。
5.3 方法论扩展性
Causal Forcing的三阶段框架具有一般性方法论价值:
- 其他模态:音频生成、3D序列生成、时空数据预测
- 其他架构:流匹配(Flow Matching)、一致性模型(Consistency Models)、随机插值
- 其他任务:实时交互、长视频生成、条件生成控制
核心思想------在初始化阶段显式处理架构鸿沟,确保单射性条件满足------可推广至广泛的序列生成蒸馏场景。
六、相关工作对比与技术演进脉络
6.1 视频扩散蒸馏的技术谱系
| 年份 | 方法 | 核心创新 | 架构 | 主要局限 |
|---|---|---|---|---|
| 2023 | DMD | 分布匹配蒸馏 | 双向→双向 | 不适用于AR |
| 2023 | Consistency Models | 一致性函数学习 | 双向 | 视频扩展困难 |
| 2024 | Self-Forcing | 非对称DMD应用于视频 | 双向→AR(直接) | 单射性违反 |
| 2025 | Causal Forcing | 因果ODE蒸馏 | 双向→AR→AR | 理论正确 |
6.2 与一致性模型(CM)的关系
Consistency Models同样追求单步或少步生成,但采用纯函数逼近路径 :
fθ(xt,t)=fθ(xt′,t′),∀t,t′∈0,T f_\theta(\mathbf{x}t, t) = f\theta(\mathbf{x}_{t'}, t'), \quad \forall t, t' \in 0, T fθ(xt,t)=fθ(xt′,t′),∀t,t′∈0,T
Causal Forcing的Stage 2可视为序列化的一致性约束 ,但显式利用AR结构的历史条件,避免CM在视频上的模式崩溃问题。
6.3 与流匹配(Flow Matching)的关系
流匹配直接参数化速度场,绕过分数估计 :
vt(x)=ψ˙t(ψt−1(x)) \mathbf{v}_t(\mathbf{x}) = \dot{\psi}_t(\psi_t^{-1}(\mathbf{x})) vt(x)=ψ˙t(ψt−1(x))
Causal Forcing的因果ODE蒸馏可与流匹配结合,形成因果流匹配,进一步简化训练动态。
七、结论与未来方向
7.1 核心贡献总结
Causal Forcing通过严格的理论分析识别帧级单射性要求 ,提出三阶段因果强制训练流程,首次正确桥接了双向教师到AR学生的架构鸿沟:
- 理论层面:建立AR扩散蒸馏的正确数学基础,明确单射性条件与训练-推理一致性的重要性
- 方法层面:设计可复现的三阶段流程,实现高质量实时交互视频生成
- 实验层面:在所有关键指标上超越SOTA,消融实验验证理论预测
7.2 未来研究方向
1. 理论深化:
- 量化分析单射性违反程度与生成质量退化的精确关系
- 探索更一般的架构兼容性条件,超越双向-AR二分
2. 方法扩展:
- 结合流匹配与因果蒸馏,实现更高效的训练
- 引入强化学习进行人类偏好微调,进一步提升VisionReward
3. 系统优化:
- 硬件-算法协同设计,专用加速器支持因果注意力
- 边缘部署优化,移动端实时视频生成
4. 应用拓展:
- 多模态实时交互(视频+音频+文本)
- 物理仿真嵌入的因果视频生成
- 长视频一致性保持的扩展机制
最终结论 :Causal Forcing为实时交互视频生成奠定了理论正确、实验有效、方法可扩展的技术基础,标志着扩散模型蒸馏从工程探索走向理论指导的新阶段。